传统的 Browser-Use 多依赖于固定选择器和流程编排,难以应对界面变化与复杂逻辑。随着大模型驱动的智能体技术兴起,Browser-Use 正迈向智能化新阶段:LLM 作为"大脑"负责任务规划与语义理解,结合视觉识别、DOM 分析、动作预测等模块,实现对浏览器环境的感知、决策与执行闭环,从而完成注册、比价、填报、监控等多步骤复杂任务的自主自动化。

一 引言
Browser Use 是一种基于 AI 模型的浏览器自动化技术,其核心目标是通过大模型进行推理和决策,解析用户指令,然后模拟人类操作行为,通过浏览器执行具体的操作(如点击、输入、页面跳转),从而实现对浏览器的自动控制。常用场景例如自动化浏览网页、提取信息、模拟用户操作、自动化测试等。
Browser Use 是基于 LangChain 生态构建的,需要遵循 LangChain 的接口规范,其核心价值在于将 LLM 的语义理解能力与浏览器自动化深度结合。
1、Vision+HTML Extraction
融合视觉理解和HTML结构(DOM树)解析,实现对网页内容的精准定位与交互。
2、Multi-tab Management
自动管理多个浏览器标签页,支持复杂流程(如跨页面数据抓取)和并行任务处理。
3、Element Tracking
记录用户操作的元素 XPath 路径,并复现 LLM 的精确动作,确保自动化的一致性。
4、Custom Actions
可扩展自定义操作(如保存文件、数据库操作、通知)。
5、Self-correcting
自纠错机制,自动检测操作失败(如元素未找到、超时),并尝试恢复流程。
6、Any LLM Support
支持所有 LangChain 兼容的 LLM,实现模型无关的指令解析。
二 历史发展
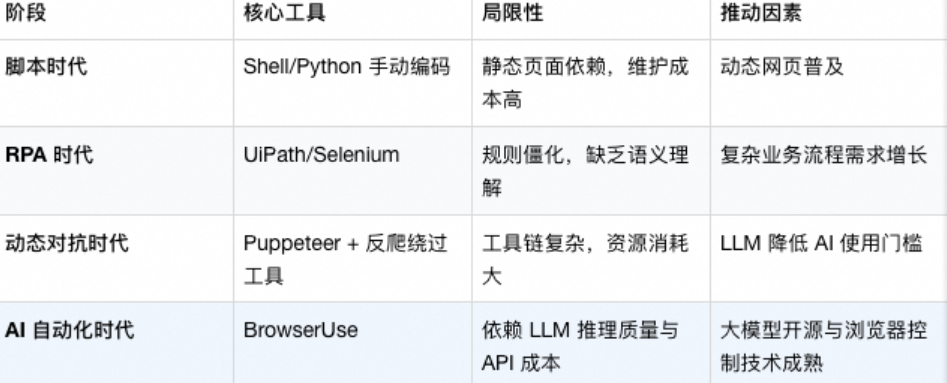
在 BrowserUse 等 AI 驱动的浏览器自动化工具出现之前,传统 RPA(Robotic Process Automation)、爬虫框架和自动化测试工具已长期服务于数据抓取、页面操作模拟等场景,下面从技术发展历史角度,分阶段解析这些需求的实现方式及演变逻辑。
2.1 早期阶段:脚本化和人工编码
- 技术手段
- 对于实时单次数据获取,通常依赖开发者手动编写 Python 脚本(如 requests + BeautifulSoup),需要精确解析 HTML 结构;
- 对于离线批量数据,可以使用 Scrapy 开源框架,通过定义 Spider 规则批量抓取网页,存储为结构化数据,需要利用 Xpath/CSS 选择器来手动配置字段提取规则;
- 对于自动化测试场景,使用 Selenium,通过代码模拟点击、输入等操作,验证网页能力,虽然支持录制用户操作生成脚本,但仅支持简单流程;
- 局限性
-
针对静态页面,无法处理 JS 动态渲染内容,每次页面结构调整需要人工修改爬取逻辑的代码,维护成本高;
-
对动态内容(如单页 SPA )支持有限,需要额外集成 Selenium 等无头浏览器,反爬机制需人工绕过,自动化程度低;
-
缺乏智能决策能力,无法自动化处理分支逻辑。
2.2 RPA阶段:规则驱动的自动化
- 技术手段
- 基于 UI 元素识别(如按钮、输入框的坐标或属性)和预设流程,通过模拟鼠标键盘操作实现自动化,代表工具有 UiPath、Automation Anywhere、Blue Prism;
- 局限性
-
依赖固定 UI 元素定位,网页布局变动易导致流程中断;
-
缺乏语义理解,无法处理需要逻辑推理的任务(比如根据页面内容选择下一步操作);
-
维护成本高,企业通常需要投入大量资源更新流程脚本以适应系统变更迭代。
2.3 动态网页和反爬对抗阶段:工具链逐渐复杂化
- 技术手段
-
无头浏览器普及,Selenium + Chrome Headless 成为动态网页抓取标配,但资源消耗大;轻量级的工具,像 Puppeteer(Node.js)提供更轻量级控制,但仍需硬编码操作步骤;
-
反爬攻防战,网站采用验证码、IP 限流、动态 Token 等机制,迫使爬虫开发者引入打码平台或代理池。
- 局限性
-
资源消耗和性能瓶颈,浏览器实例占用内存高,难以大规模并行抓取,其对 CPU 和内存的消耗显著高于传统 HTTP 请求;
-
浏览器兼容性限制,Puppeteer 仅原生支持Chromium内核浏览器,而Selenium虽然支持多浏览器,但不同浏览器驱动的API差异导致跨平台脚本维护成本增加;
-
反爬对抗的复杂性升级。
当前工具链本质是模拟人类操作浏览器,无法突破「浏览器沙箱」限制。即便结合代理IP和Puppeteer,面对浏览器指纹检测等新型反爬技术时,仍需引入Puppeteer-extra等插件进行特征伪装,导致工具链复杂度指数级上升
2.4 AI 驱动的范式跃迁
- 需求驱动因素
SPA(单页应用)和 WebAssembly 普及,传统爬虫难以解析完整 DOM;业务场景碎片化,任务需求复杂化,人力成本压力等等。
- 技术成熟条件
大语言模型如 GPT-4 等具备自然语言指令解析与任务规划能力,可将抽象需求转化为操作序列;浏览器自动化框架如 Playwright 提供浏览器控制接口;视觉理解模型可解析屏幕内容,补充 Dom 解析获取的页面信息不足。
2.5 内容小结
BrowserUse 的出现是技术矛盾(动态网页复杂性 vs 传统工具僵化性)与技术进步(LLM+浏览器控制)共同作用的结果,也标志了浏览器自动化从 "规则驱动" 向 "认知驱动" 的范式跃迁。总的来说,其实际价值在于,通过 LLM 的泛化能力减少因网页改版导致的脚本失效问题,支持自动化复杂处理(处理弹窗),以及加速开发效率。
三 核心技术解析
Browser-Use 项目中:
service.py 和 views.py 遵循了经典的分层架构设计模式。
View 层 - 数据定义层:Pydantic 数据模型定义、数据验证、数据格式转换、模块间数据传递的标准格式。
Service 层 - 业务逻辑层:实现核心的功能和算法、管理复杂的操作流程、第三方服务集成、维护对象生命周期。
├── agent # AI 代理
│ ├── gif.py # 历史记录可视化
│ ├── memory # 记忆模块
│ │ ├── __init__.py
│ │ ├── service.py
│ │ └── views.py
│ ├── message_manager # 消息管理
│ │ ├── service.py
│ │ ├── tests.py
│ │ ├── utils.py
│ │ └── views.py
│ ├── playwright_script_generator.py
│ ├── playwright_script_helpers.py
│ ├── prompts.py # 提示词相关
│ ├── service.py
│ ├── system_prompt.md
│ ├── tests.py
│ └── views.py
├── browser # 浏览器相关
│ ├── __init__.py
│ ├── browser.py
│ ├── context.py
│ ├── extensions.py
│ ├── profile.py # 浏览器配置
│ ├── session.py # 核心会话管理
│ └── views.py
├── cli.py
├── controller # 工具Action相关
│ ├── registry
│ │ ├── service.py
│ │ └── views.py
│ ├── service.py
│ └── views.py
├── dom # Dom 树解析&可交互元素处理
│ ├── __init__.py
│ ├── buildDomTree.js
│ ├── clickable_element_processor
│ │ └── service.py
│ ├── history_tree_processor
│ │ ├── service.py
│ │ └── view.py
│ ├── service.py
│ ├── tests
│ │ └── test_accessibility_playground.py
│ └── views.py
├── exceptions.py
├── logging_config.py
├── telemetry # 产品使用情况追踪,数据收集&分析模块
│ ├── __init__.py
│ ├── service.py
│ └── views.py └── utils.py
3.1.0 模块概览
- agent
-
gif.py:用于将 AI Agent 的执行历史转换成可视化的动态 GIF 动画,展示整个任务执行过程的,每一步的屏幕截图、任务目标和步骤信息、执行进度和状态;
-
message_manager 模块:管理大模型交互过程中所有通信内容,包括系统提示词、用户输入、模型输出、工具输出等;
-
memory 模块:记忆管理模块(基于 Mem0 的向量存储),专门用于优化长期任务执行中的上下文窗口使用,核心是解决 Token 限制问题(长期任务会产生大量对话历史),智能记忆压缩(对上面的 message 总结&压缩,被压缩的信息不涵盖系统提示词和memory相关的信息)。
-
browser:核心基础设施,负责管理和控制浏览器实例,为 AI Agent 提供与真实浏览器交互的能力,本质上是对 Playwright 进行了一层封装;
-
controller:整个框架的动作执行引擎&Action注册管理,负责将 AI Agent 的决策转换为具体的浏览器操作;
-
dom:整个框架的感知引擎,负责理解和处理网页结构,将复杂的 HTML DOM 转换为 Agent 可以理解和操作的结构化数据;
-
telemetry:追踪 Browser-Use 产品本身使用情况,用于收集用户使用情况,性能指标和错误信息;比如像那个模型成功率更高,哪种任务耗时过长,vision 功能使用频率,常见失败原因,最常用的自定义功能等等;
-
事件发送:将遥测服务发送到分析服务;
-
隐私保护:匿名化敏感数据;
-
配置管理:控制遥测开关和参数;
3.1.1 Dom 树解析
Dom 层核心功能
-
Dom 结构解析与抽象
-
智能元素识别与索引
其中 buildDomTree.js 是 Dom 层的核心组件,运行在浏览器环境中,负责智能识别和处理页面元素。
-
通过递归方式对DOM树进行深度遍历,确保每一个节点都能被准确访问与处理,为标注提供全面的元素信息
// 函数入口
function buildDomTree(node, parentIframe = null, isParentHighlighted = false){
// node: 当前要处理的 DOM 节点
// parentIframe: 父级 iframe(用于跨 iframe 处理)
// isParentHighlighted: 父节点是否已被高亮(状态传递)
}
// 递归终止条件 - 防止无限递归
if (!node || node.id === HIGHLIGHT_CONTAINER_ID ||
(node.nodeType !== Node.ELEMENT_NODE && node.nodeType !== Node.TEXT_NODE)) {
if (debugMode) PERF_METRICS.nodeMetrics.skippedNodes++;
return null; // 终止当前分支的递归
}
// 根节点特殊处理
if (node === document.body) {
const nodeData = {
tagName: 'body',
attributes: {},
xpath: '/body',
children: [],
};
// 核心递归点1:处理 body 的所有子节点
for (const child of node.childNodes) {
const domElement = buildDomTree(child, parentIframe, false); // 🔄 递归调用
if (domElement) nodeData.children.push(domElement);
}
const id = `${ID.current++}`;
DOM_HASH_MAP[id] = nodeData;
return id;
}
// 核心递归点2:根据节点类型进行不同的递归处理
if (node.tagName) {
const tagName = node.tagName.toLowerCase();
// 场景1:iframe 递归处理
if (tagName === "iframe") {
try {
const iframeDoc = node.contentDocument || node.contentWindow?.document;
if (iframeDoc) {
for (const child of iframeDoc.childNodes) {
const domElement = buildDomTree(child, node, false); // 🔄 跨 iframe 递归
if (domElement) nodeData.children.push(domElement);
}
}
} catch (e) {
console.warn("Unable to access iframe:", e);
}
}
// 场景2:富文本编辑器递归处理
elseif (
node.isContentEditable ||
node.getAttribute("contenteditable") === "true" ||
node.id === "tinymce" ||
node.classList.contains("mce-content-body")
) {
// 处理富文本内容 - 保持高亮状态传递
for (const child of node.childNodes) {
const domElement = buildDomTree(child, parentIframe, nodeWasHighlighted); // 🔄 递归
if (domElement) nodeData.children.push(domElement);
}
}
// 场景3:常规元素递归处理
else {
// Shadow DOM 处理
if (node.shadowRoot) {
nodeData.shadowRoot = true;
for (const child of node.shadowRoot.childNodes) {
const domElement = buildDomTree(child, parentIframe, nodeWasHighlighted); // 🔄 Shadow DOM 递归
if (domElement) nodeData.children.push(domElement);
}
}
// 最重要的递归处理:常规子节点
for (const child of node.childNodes) {
// 关键:高亮状态的递归传递
const passHighlightStatusToChild = nodeWasHighlighted || isParentHighlighted;
const domElement = buildDomTree(child, parentIframe, passHighlightStatusToChild); // 🔄 递归调用
if (domElement) nodeData.children.push(domElement);
}
}
}
# service.py - _construct_dom_tree 方法
@time_execution_async('--construct_dom_tree')
async def _construct_dom_tree(self, eval_page: dict) -> tuple[DOMElementNode, SelectorMap]:
"""从 JavaScript 结果构建 Python DOM 树 - 核心递归处理"""
js_node_map = eval_page['map']
js_root_id = eval_page['rootId']
selector_map = {}
node_map = {}
# 🔄 第一轮遍历:创建所有节点
for id, node_data in js_node_map.items():
node, children_ids = self._parse_node(node_data)
if node is None:
continue
node_map[id] = node
# 建立可交互元素的索引映射
if isinstance(node, DOMElementNode) and node.highlight_index is not None:
selector_map[node.highlight_index] = node
# 🔄 第二轮遍历:建立父子关系(递归结构)
for id, node_data in js_node_map.items():
node = node_map.get(id)
if isinstance(node, DOMElementNode):
# 关键:递归建立父子关系
for child_id in node_data.get('children', []):
if child_id in node_map:
child_node = node_map[child_id]
child_node.parent = node # 设置父节点
node.children.append(child_node) # 添加子节点
return node_map[str(js_root_id)], selector_map对元素的可交互性和可见性进行精准判断,确保标注仅应用于符合条件的目标元素,提升标注的准确性
classClickableElementProcessor:
"""可点击元素处理器"""
@staticmethod
def get_clickable_elements_hashes(dom_element: DOMElementNode) -> set[str]:
"""获取所有可点击元素的哈希值集合"""
clickable_elements = ClickableElementProcessor.get_clickable_elements(dom_element)
return {ClickableElementProcessor.hash_dom_element(element) for element in clickable_elements}
@staticmethod
def hash_dom_element(dom_element: DOMElementNode) -> str:
"""为 DOM 元素生成唯一哈希标识"""
# 1. 父级路径哈希
parent_branch_path = ClickableElementProcessor._get_parent_branch_path(dom_element)
branch_path_hash = ClickableElementProcessor._parent_branch_path_hash(parent_branch_path)
# 2. 属性哈希
attributes_hash = ClickableElementProcessor._attributes_hash(dom_element.attributes)
# 3. XPath 哈希
xpath_hash = ClickableElementProcessor._xpath_hash(dom_element.xpath)
# 4. 组合哈希
return ClickableElementProcessor._hash_string(f'{branch_path_hash}-{attributes_hash}-{xpath_hash}')
视觉标注实现(高亮系统)
// 元素高亮 - 为 AI 提供视觉索引
function highlightElement(element, index, parentIframe = null){
// 1. 创建高亮容器
let container = document.getElementById(HIGHLIGHT_CONTAINER_ID);
if (!container) {
container = document.createElement("div");
container.id = HIGHLIGHT_CONTAINER_ID;
container.style.zIndex = "2147483640"; // 最高层级
}
// 2. 为每个元素创建彩色边框和数字标签
const colors = ["#FF0000", "#00FF00", "#0000FF", "#FFA500"];
const baseColor = colors[index % colors.length];
// 3. 多矩形支持 (处理复杂布局)
const rects = element.getClientRects();
for (const rect of rects) {
const overlay = document.createElement("div");
overlay.style.border = `2px solid ${baseColor}`;
overlay.style.backgroundColor = baseColor + "1A"; // 10% 透明度
// 设置位置和尺寸...
}
}
Dom 树格式化输出
[1]<header class='app-header' >
[2]<div class='logo' >
公司 LOGO
[3]<nav class='main-nav' >
[4]<a href='/dashboard' >控制台 />
[5]<a href='/projects' >项目管理 />
[6]<div class='user-menu' >
[7]<button class='user-avatar' >
[8]<img alt='用户头像' />
[9]<div class='dropdown-menu' >
[10]<a href='/profile' >个人资料 />
[11]<a href='/settings' >账户设置 />
[12]<button >退出登录 />
[13]<main class='app-content' >
[14]<aside class='sidebar' >
[15]<ul class='nav-list' >
[16]<li >
[17]<a href='/tasks' >任务列表 />
[18]<li >
[19]<a href='/calendar' >日历视图 />
[20]<section class='content-area' >
[21]<div class='toolbar' >
[22]<button class='btn-primary' >新建任务 />
[23]<input type='search' placeholder='搜索任务' />
[24]<select name='filter' >
[25]<option value='all' >全部任务 />
[26]<option value='pending' >待处理 />
[27]<div class='task-list' >
任务列表内容
[28]<div class='task-item' >
[29]<input type='checkbox' />
完成网站设计
[30]<button class='edit-btn' >编辑 />
[31]<button class='delete-btn' >删除 />
*[32]*<button >新出现的按钮 /> # 用 * 标记新元素
# views.py - clickable_elements_to_string 方法
def clickable_elements_to_string(self, include_attributes: list[str] | None = None) -> str:
"""将 DOM 树递归转换为 LLM 可理解的文本格式"""
formatted_text = []
def process_node(node: DOMBaseNode, depth: int) -> None:
"""📍 递归处理函数 - 深度优先遍历和格式化"""
next_depth = int(depth)
depth_str = depth * '\t' # 缩进表示层级
if isinstance(node, DOMElementNode):
# 处理可交互元素
if node.highlight_index is not None:
next_depth += 1
# 格式化当前节点信息
text = node.get_all_text_till_next_clickable_element()
# ... 属性处理和格式化逻辑
formatted_text.append(formatted_line)
# ⭐ 递归处理所有子节点
for child in node.children:
process_node(child, next_depth) # 递归调用
elif isinstance(node, DOMTextNode):
# 处理文本节点
if (not node.has_parent_with_highlight_index() and
node.parent and node.parent.is_visible):
formatted_text.append(f'{depth_str}{node.text}')
process_node(self, 0) # 从根节点开始递归
return '\n'.join(formatted_text)下一章继续解读