2026年五一杯数学建模B题:多工序协同作业问题
开篇摘要:这次复盘围绕 2026 五一数学建模 B 题"多工序协同作业问题"展开。项目没有停留在手算或单脚本层面,而是把题目拆成数据解析、工序展开、设备分配、事件驱动解码、启发式搜索、结果校验和可视化输出几个模块。本文所有数值、图表和代码片段均来自当前项目目录中的真实文件,重点记录从单车间解析调度到多车间运输调度,再到双班组协同调度的完整建模过程。
封面图建议:可以使用 ./blog_assets/figures/question3_gantt_global.png 作为封面。它直接展示了第 3 问双班组、多车间、多设备协同调度的全局甘特图,比单纯放题目截图更能体现项目的工程完成度。
目录
- [1. 这道题真正难在哪里](#1. 这道题真正难在哪里)
- [2. 从题目到调度模型](#2. 从题目到调度模型)
- [3. 模型是如何逐层升级的](#3. 模型是如何逐层升级的)
- [4. 数学模型设计](#4. 数学模型设计)
- [5. 代码工程结构](#5. 代码工程结构)
- [6. 关键代码片段解析](#6. 关键代码片段解析)
- [7. 结果图表复盘](#7. 结果图表复盘)
- [8. 结果表格分析](#8. 结果表格分析)
- [9. 我最想强调的几个建模点](#9. 我最想强调的几个建模点)
- [10. 踩坑与优化经验](#10. 踩坑与优化经验)
- [11. 总结](#11. 总结)
1. 这道题真正难在哪里
这道 B 题表面上是在安排 A、B、C、D、E 五个车间的整修任务,但它不是普通的"把工序排个顺序"问题。题目同时给了固定工序链、设备类型需求、设备移动速度、班组初始位置、车间距离,以及"某些工序需要两类设备共同完成"的同步完工规则。
最容易低估的是运输和同步。设备在同一车间连续作业时运输时间可以忽略,但跨车间移动必须计入;一道工序如果同时需要两类设备,不能只看先完成的那一台,而要等所有参与设备都完成对应工程量后,后续工序才可以释放。
因此,我最后把它抽象成一个带运输时间、资源互斥和同步完工约束的资源受限调度问题。第 1 问可以解析化简,第 2 问开始进入多车间资源竞争,第 3 问进一步加入双班组设备池。
2. 从题目到调度模型
题目附件 B-附件.xlsx 中有三个核心表:
工序流程表:记录各车间工序、工程量、所需设备类型和设备效率。班组配置表:记录班组 1、班组 2 的设备编号、数量、移动速度和设备单价。车间距离表:记录班组到车间、车间到车间的距离。
业务上可以理解成:每个车间是一条固定工序链,每道工序可能需要一台或多台设备,设备从当前位置移动到目标车间后才能开工,同一台设备不能同时服务两道工序。
第 3 问的全局设备调度甘特图能直观看到这种"设备池 + 车间链 + 时间轴"的结构:
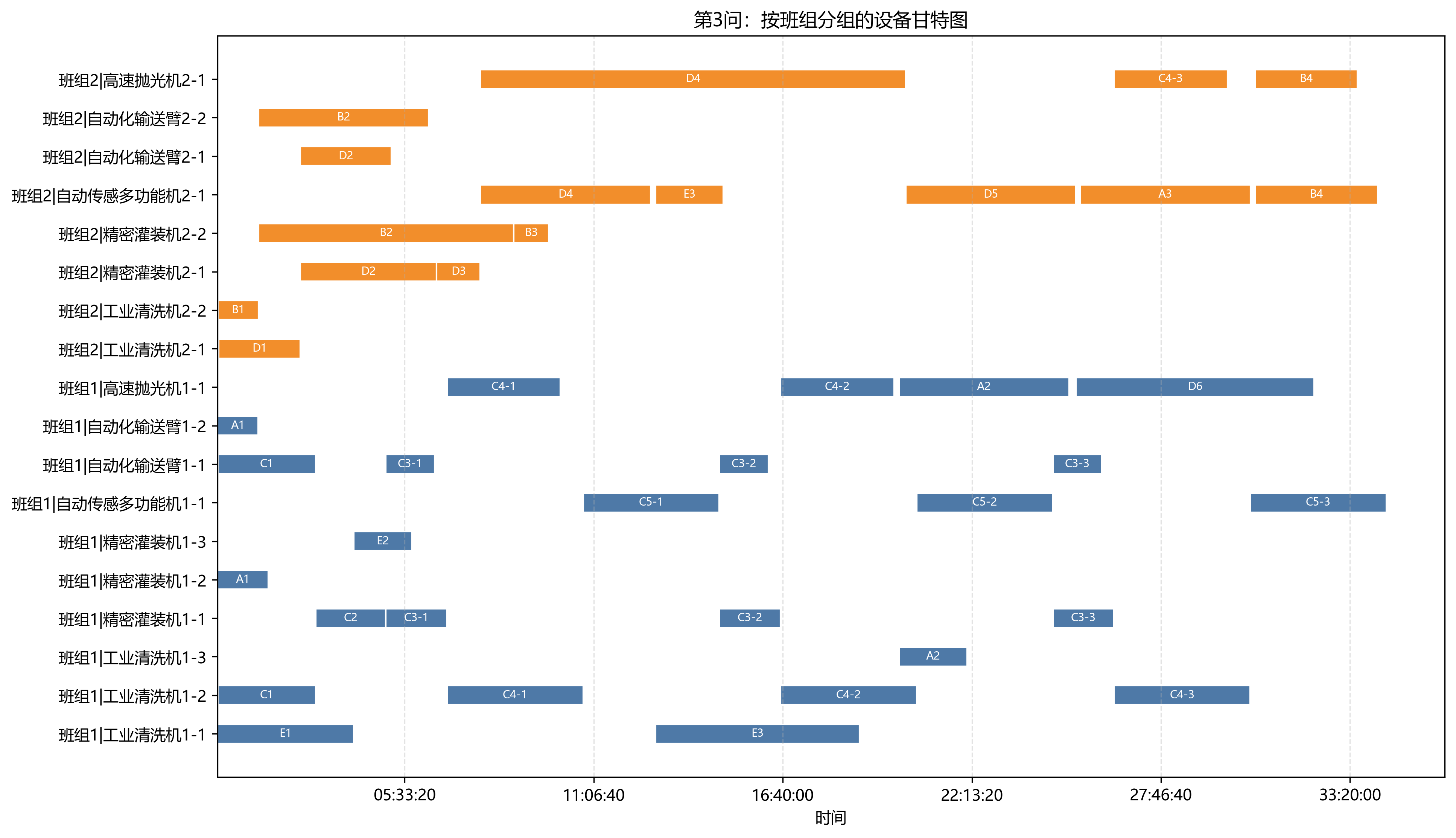
这张图中,每一行是一台设备,横向条块是设备在某道工序上的工作区间,颜色对应不同车间。相比只输出最终总工期,甘特图更容易暴露设备瓶颈、车间等待和跨车间切换带来的局部空档。
3. 模型是如何逐层升级的
本项目实际完成了前 3 问的求解与结果输出。第 4 问涉及设备购置决策,当前目录中没有 result_question4/ 或对应求解结果,因此本文只把它作为可扩展方向,不虚构购置方案和表 4、表 5 数值。
| 阶段 | 问题抽象 | 项目中的处理方式 |
|---|---|---|
| 第 1 问 | 班组 1 独立完成 A 车间,工序链为 A1 -> A2 -> A3 |
固定顺序下最早开工,得到解析最优调度 |
| 第 2 问 | 班组 1 完成 A-E 五个车间,存在设备竞争和跨车间运输 | 贪心构造 + 随机扰动 + 局部搜索 |
| 第 3 问 | 班组 1、2 共同完成 A-E 五个车间,设备池扩大且初始位置不同 | 双班组 GA + 贪心解码 + 局部搜索 |
| 第 4 问 | 预算约束下的设备购置 + 调度联合优化 | 当前目录未发现结果文件,本文不写具体数值 |
第 2 问和第 3 问都没有在日志中声明"已证明全局最优",项目输出的是当前最好可行解。博客里我也只按"启发式当前最好可行解"来表述。
4. 数学模型设计
集合与索引
设车间集合为 W = { A , B , C , D , E } W=\{A,B,C,D,E\} W={A,B,C,D,E},车间 w w w 内的有序工序集合为 I w I_w Iw。设备集合为 E E E,设备类型集合为 K K K。若工序 i i i 需要设备类型 k k k,则记 k ∈ K i k \in K_i k∈Ki。
第 3 问中还需要班组集合 G = { 1 , 2 } G=\{1,2\} G={1,2},设备 e e e 属于某个班组 g ( e ) g(e) g(e)。
参数
- q i q_i qi:工序 i i i 的工程量。
- v i k v_{ik} vik:工序 i i i 使用设备类型 k k k 时的作业效率。
- d u v d_{uv} duv:位置 u u u 到位置 v v v 的距离。
- s e s_e se:设备 e e e 的移动速度。
- w ( i ) w(i) w(i):工序 i i i 所属车间。
- l o c e 0 loc^0_e loce0:设备 e e e 的初始位置,第 2 问为班组 1,第 3 问按设备所属班组确定。
加工时间按题目"精确到秒且向上取整"处理:
p i k = ⌈ q i v i k × 3600 ⌉ p_{ik} = \left\lceil \frac{q_i}{v_{ik}} \times 3600 \right\rceil pik=⌈vikqi×3600⌉
运输时间同样向上取整:
τ e u v = ⌈ d u v s e ⌉ \tau_{euv} = \left\lceil \frac{d_{uv}}{s_e} \right\rceil τeuv=⌈seduv⌉
这两个公式对应代码中的 compute_processing_time() 和 compute_travel_time(),也是整套调度时间计算的基础。
决策变量
- S i S_i Si:工序 i i i 的开始时间。
- C i C_i Ci:工序 i i i 的同步完工时间。
- x i e x_{ie} xie:若设备 e e e 被分配给工序 i i i,则 x i e = 1 x_{ie}=1 xie=1。
- y i j e y_{ije} yije:若设备 e e e 同时参与工序 i , j i,j i,j,且 i i i 先于 j j j,则 y i j e = 1 y_{ije}=1 yije=1。
- C max C_{\max} Cmax:全部任务的总工期。
若做启发式求解,编码层面不直接搜索所有 x , y , S , C x,y,S,C x,y,S,C,而是搜索一个"车间释放序列"。解码器根据序列逐步选择下一道可排工序,并在候选设备组合中挑选当前最优的可行分配。
目标函数
目标是最小化所有车间最后一道工序的最大完工时间:
min C max \min C_{\max} minCmax
C max ≥ C i , ∀ i ∈ ⋃ w ∈ W I w C_{\max} \ge C_i,\quad \forall i \in \bigcup_{w\in W} I_w Cmax≥Ci,∀i∈w∈W⋃Iw
在实现中,makespan 等于各车间完工时间的最大值。
关键约束
车间内工序顺序固定:
S i r + 1 ≥ C i r , ∀ i r , i r + 1 ∈ I w S_{i_{r+1}} \ge C_{i_r},\quad \forall i_r,i_{r+1}\in I_w Sir+1≥Cir,∀ir,ir+1∈Iw
每个"工序-设备类型需求"必须选择一台对应类型设备:
∑ e ∈ E k x i e = 1 , ∀ i , k ∈ K i \sum_{e\in E_k}x_{ie}=1,\quad \forall i,\ k\in K_i e∈Ek∑xie=1,∀i, k∈Ki
设备唯一占用与跨车间运输约束可以写成如下形式。若设备 e e e 先做工序 i i i,再做工序 j j j:
S j ≥ C i e + τ e , w ( i ) , w ( j ) S_j \ge C_{ie} + \tau_{e,w(i),w(j)} Sj≥Cie+τe,w(i),w(j)
其中 C i e C_{ie} Cie 是设备 e e e 在工序 i i i 上的结束时间。若两道工序在同一车间,则运输时间为 0。
多设备同步完工约束是本题最关键的一条:
C i = max k ∈ K i , e ∈ E k : x i e = 1 { S i + p i k } C_i = \max_{k\in K_i,\, e\in E_k:x_{ie}=1}\{S_i+p_{ik}\} Ci=k∈Ki,e∈Ek:xie=1max{Si+pik}
这意味着较快设备完成后也不能释放后续工序,工序链只能在最慢参与设备完成后继续推进。
5. 代码工程结构
第 1、2 问在根目录下分别有 question1_solver.py 和 question2_solver.py。第 3 问被整理成了更完整的工程目录:
text
question3_project/
├─ main.py
├─ config.py
├─ data_loader.py
├─ entities.py
├─ preprocess.py
├─ time_utils.py
├─ decoder.py
├─ exact_solver.py
├─ heuristic_solver.py
├─ local_search.py
├─ validator.py
├─ reporter.py
├─ visualization.py
├─ io_utils.py
├─ logger_utils.py
├─ requirements.txt
└─ README.md几个模块的职责很清晰:
data_loader.py:读取附件 Excel,解析工序、班组和距离数据。preprocess.py:构造设备池、候选设备映射,展开重复工序。decoder.py:把车间序列解码成具体设备分配、开始时间和结束时间。heuristic_solver.py/local_search.py:生成初始解,并通过扰动、交叉、局部搜索改进。validator.py:检查工序顺序、设备重叠、运输时间、同步完工和表格字段。visualization.py:输出甘特图、运输热力图、利用率图、收敛曲线等。reporter.py:生成结果表、摘要表和日志说明。
这种拆分的好处是:调度逻辑、结果校验和图表输出互不缠绕。后续要做第 4 问购置决策时,可以在设备池生成阶段加入新增设备变量,而不必重写整个可视化和校验链路。
6. 关键代码片段解析
6.1 时间计算:把题目单位统一成秒
下面代码来自 question3_project/time_utils.py:
python
def compute_processing_time(quantity: float, efficiency: float) -> int:
if efficiency <= 0:
raise ValueError(f"设备效率必须为正数,当前为:{efficiency}")
return int(math.ceil(quantity / efficiency * 3600))
def compute_travel_time(distance_m: float, speed_mps: float) -> int:
if speed_mps <= 0:
raise ValueError(f"设备移动速度必须为正数,当前为:{speed_mps}")
return int(math.ceil(distance_m / speed_mps))这段代码对应题目中"小时、米、秒"和"向上取整"的要求。所有后续调度都只处理秒,避免在算法里反复处理单位换算。
6.2 构建设备池与候选设备映射
下面代码来自 question3_project/preprocess.py:
python
def build_devices(team_df: pd.DataFrame) -> tuple[dict[str, Device], dict[str, list[str]]]:
devices: dict[str, Device] = {}
candidates_by_type: dict[str, list[str]] = {}
for _, row in team_df.iterrows():
device = Device(
device_id=str(row["设备编号"]),
equipment_type=str(row["设备类型"]),
team=str(row["班组"]),
speed_mps=float(row["移动速度(m/s)"]),
unit_price=float(row["设备单价(元/台)"]),
)
devices[device.device_id] = device
candidates_by_type.setdefault(device.equipment_type, []).append(device.device_id)
for key in candidates_by_type:
candidates_by_type[key] = sorted(candidates_by_type[key])
return devices, candidates_by_type第 3 问的设备来自两个班组。这里没有把班组写死在调度逻辑里,而是把设备编号、设备类型、所属班组和移动速度统一封装成 Device,再按设备类型建立候选列表。解码器后面只需要根据工序需求取候选设备即可。
6.3 展开重复工序与多设备需求
仍然来自 question3_project/preprocess.py:
python
for _, row in group.iterrows():
equipment_type = str(row["设备类型"])
if equipment_type not in candidates_by_type:
raise ValueError(f"两个班组中均没有工序 {base_process_id} 所需设备类型:{equipment_type}")
requirements.append(
Requirement(
equipment_type=equipment_type,
efficiency=float(row["效率(m3/h)"]),
duration_s=int(row["加工时长(s)"]),
)
)附件里一道工序可能对应多种设备类型。这里把它们统一变成 Requirement 列表,所以解码时可以自然处理"单设备工序"和"双设备同步工序"。
6.4 设备分配:枚举候选组合并按完成时间排序
下面代码来自 question3_project/decoder.py:
python
candidate_lists = [candidates_by_type[req.equipment_type] for req in op.requirements]
evaluated = []
for combo in product(*candidate_lists):
if len(set(combo)) < len(combo):
continue
assignments = []
ready_times = []
total_travel = 0
for req, device_id in zip(op.requirements, combo):
device = devices[device_id]
from_pos = device_location[device_id]
travel_s = travel_for_device(device, from_pos, op.workshop, distance_df)
ready_s = device_available[device_id] + travel_s
ready_times.append(ready_s)
total_travel += travel_s
assignments.append(
{
"requirement": req,
"device_id": device_id,
"team": device.team,
"from_pos": from_pos,
"to_pos": op.workshop,
"travel_s": int(travel_s),
"ready_s": int(ready_s),
}
)
start_s = max([workshop_ready] + ready_times)
completion_s = max(start_s + item["requirement"].duration_s for item in assignments)
team_balance = len(set(item["team"] for item in assignments))
evaluated.append((completion_s, start_s, total_travel, -team_balance, combo, assignments))这段是解码器的核心之一:对一道工序所需的设备类型做笛卡尔积,枚举候选设备组合;计算每台设备从当前位置到目标车间的运输时间;再用最晚就绪时间作为工序开始时间,用参与设备的最大结束时间作为同步完工时间。
排序关键字中包含 completion_s、start_s、total_travel 和 team_balance。这不是严格数学证明意义上的最优选择,但在启发式解码中可以稳定生成可行且质量较好的调度。
6.5 解码序列:从车间释放顺序到完整调度表
下面代码来自 question3_project/decoder.py:
python
workshop_ready = {w: 0 for w in operations_by_workshop}
device_available = {device_id: 0 for device_id in devices}
device_location = {device_id: initial_location(device) for device_id, device in devices.items()}
next_index = {w: 0 for w in operations_by_workshop}
def schedule_next(workshop: str) -> bool:
if workshop not in operations_by_workshop or next_index[workshop] >= len(operations_by_workshop[workshop]):
return False
op = operations_by_workshop[workshop][next_index[workshop]]
start_s, completion_s, assignments = select_assignment(
op, workshop_ready[workshop], device_available, device_location,
candidates_by_type, devices, distance_df, random_tie=random_tie
)
commit_operation(
op, start_s, completion_s, assignments, workshop_ready, device_available,
device_location, records, process_records, routes, operation_times, devices
)
next_index[workshop] += 1
return True编码层只关心"下一次尝试释放哪个车间的一道工序"。真正的开始时间、设备选择、运输时间和同步完工都在解码器里算出来。这样做的好处是,搜索空间比直接枚举所有设备排序要小得多。
6.6 局部搜索:扰动序列而不是直接改时间表
下面代码来自 question3_project/local_search.py:
python
def mutate_sequence(sequence: list[str], rng: random.Random) -> list[str]:
candidate = sequence[:]
if len(candidate) < 2:
return candidate
op = rng.choice(["swap", "insert", "reverse"])
i, j = sorted(rng.sample(range(len(candidate)), 2))
if op == "swap":
candidate[i], candidate[j] = candidate[j], candidate[i]
elif op == "insert":
item = candidate.pop(j)
candidate.insert(i, item)
else:
candidate[i : j + 1] = reversed(candidate[i : j + 1])
return candidate局部搜索没有直接修改设备开始时间,因为那样很容易破坏可行性。它只扰动车间序列,再交给解码器重新生成可行调度。可行性压力集中在解码器和校验器上,搜索逻辑就更轻。
6.7 自动校验:比"看起来合理"更重要
下面代码来自 question3_project/validator.py:
python
for device_id, group in raw.sort_values(["设备编号", "起始秒"]).groupby("设备编号"):
device = devices[device_id]
prev = None
for _, row in group.iterrows():
if prev is None:
required_travel = travel_for_device(device, device.team, row["所属车间"], distance_df)
if int(row["起始秒"]) < required_travel:
errors.append(f"设备 {device_id} 首次从{device.team}到{row['所属车间']}的运输时间未计入。")
else:
required_travel = travel_for_device(device, prev["所属车间"], row["所属车间"], distance_df)
if int(row["起始秒"]) < int(prev["结束秒"]) + required_travel:
errors.append(f"设备 {device_id} 从{prev['所属车间']}到{row['所属车间']}运输时间不足。")
prev = row这段检查的是同一台设备连续作业之间是否留足运输时间。调度题最怕"结果看起来排满了,但其实设备瞬移了"。所以项目里把校验报告作为正式输出,三问日志都显示校验通过。
6.8 可视化:甘特图不是装饰,而是诊断工具
下面代码来自 question3_project/visualization.py:
python
def plot_gantt_global(result: SolutionSummary) -> plt.Figure:
setup_chinese_font()
df = pd.DataFrame(result.records).sort_values(["设备编号", "起始秒"])
devices = list(df["设备编号"].drop_duplicates())
y_map = {device: idx for idx, device in enumerate(devices)}
fig, ax = plt.subplots(figsize=(13, max(5, 0.32 * len(devices) + 1.8)))
for _, row in df.iterrows():
y = y_map[row["设备编号"]]
ax.barh(y, row["持续工作时间(s)"], left=row["起始秒"], height=0.5,
color=WORKSHOP_COLORS.get(row["所属车间"], "#999999"), edgecolor="white", label=row["所属车间"])
ax.text(row["起始秒"] + row["持续工作时间(s)"] / 2, y, row["工序编号"], ha="center", va="center", fontsize=7, color="white")甘特图在这个项目里不是最后美化用的,而是用来反查瓶颈设备、空闲间隙、车间完工顺序和异常等待的诊断工具。
7. 结果图表复盘
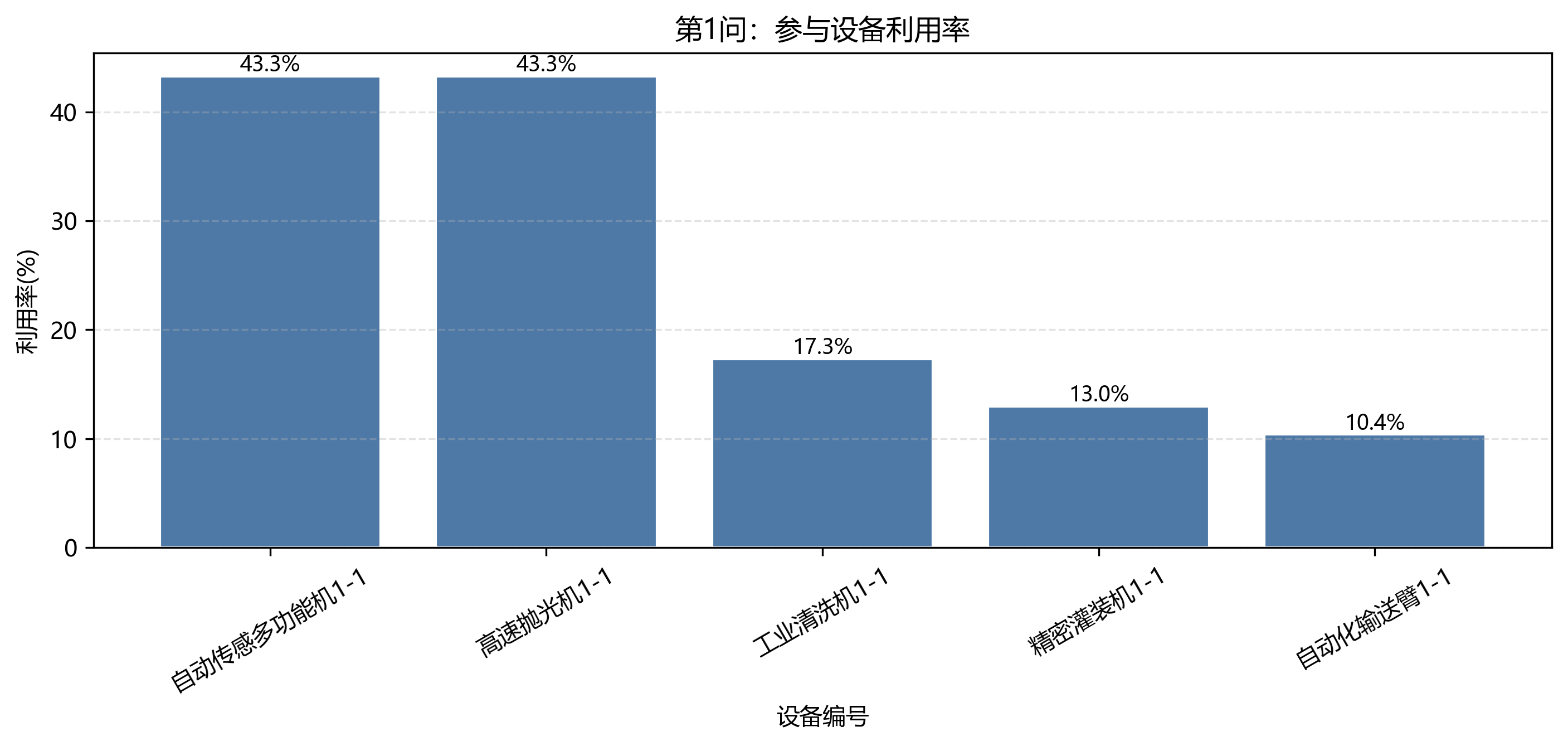
7.1 第 1 问:单车间固定链可以解析化简
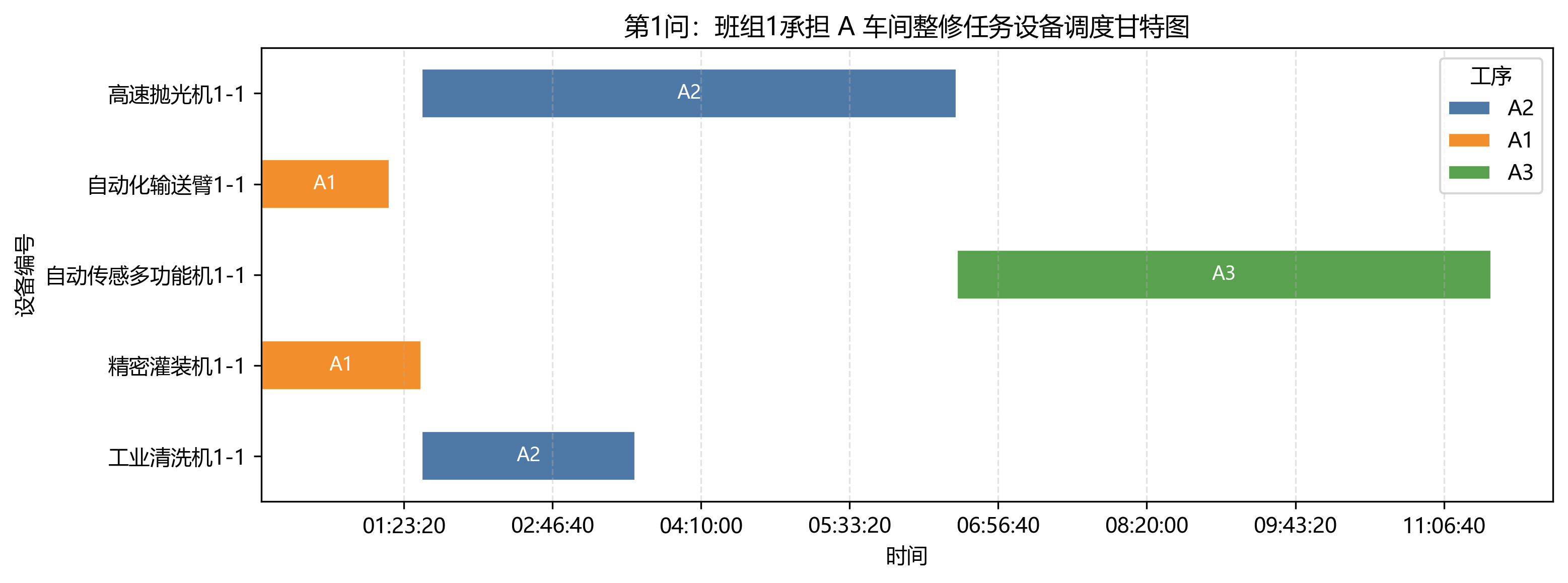
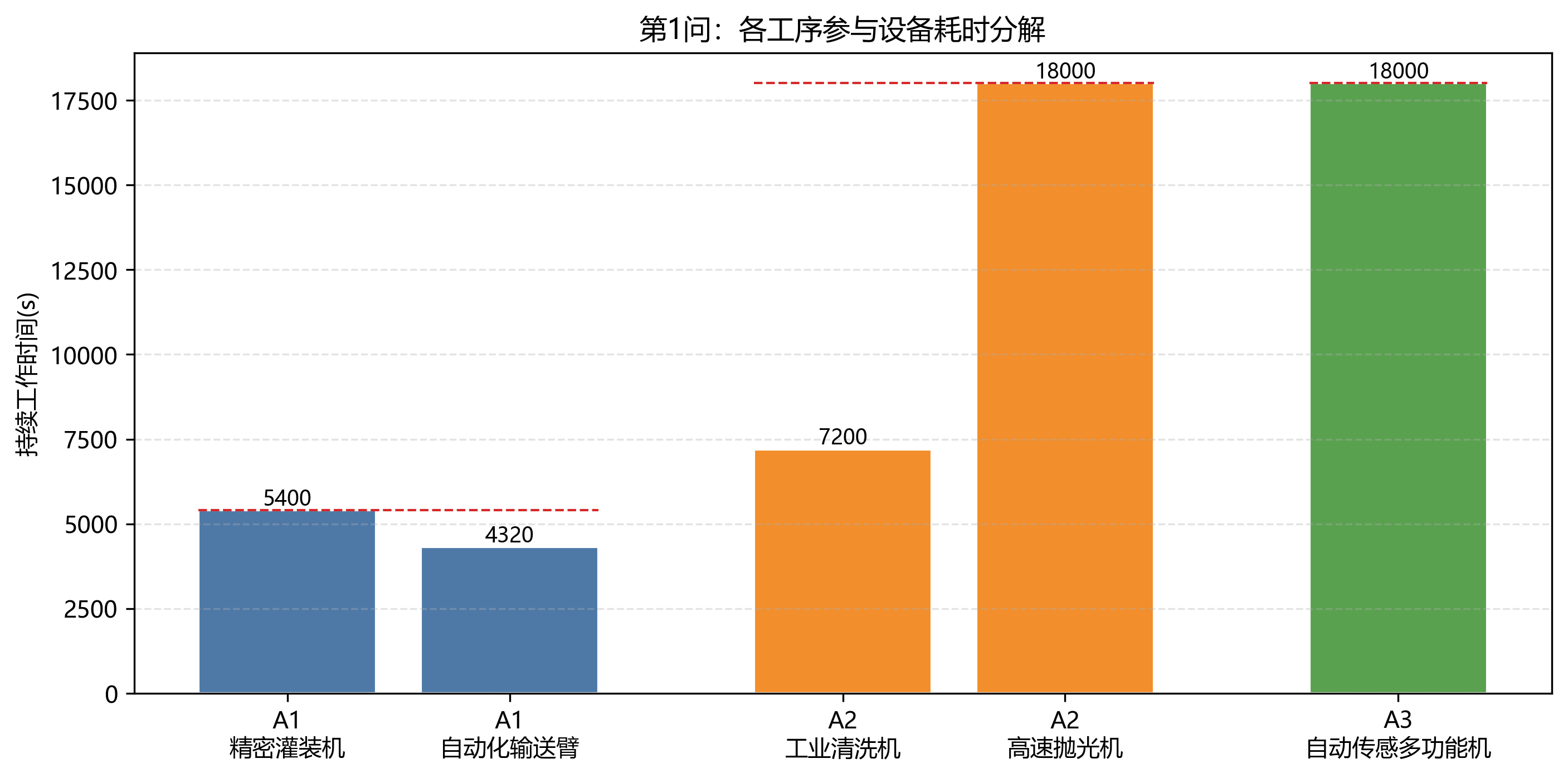
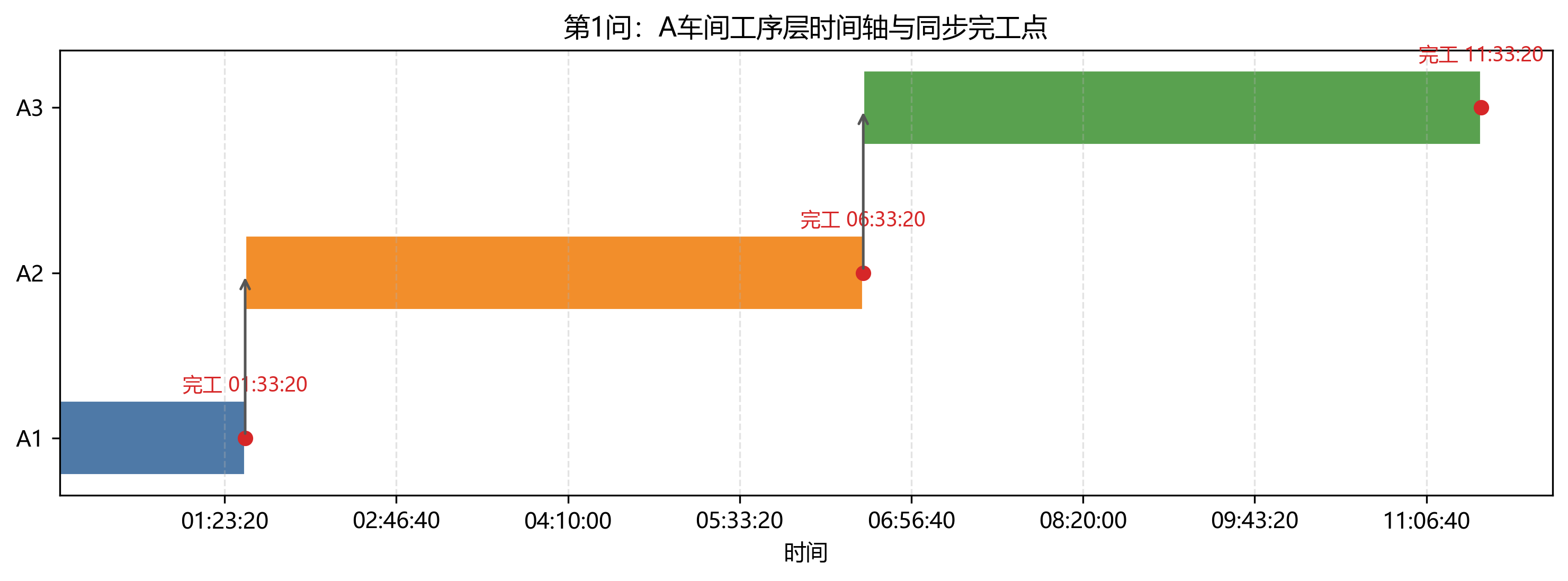
第 1 问只有 A 车间,工序链固定为 A1 -> A2 -> A3,同车间内部设备转运忽略。结果日志显示最短总时长为 41600 s = 11:33:20。其中 A1 在 01:33:20 同步完工,A2 在 06:33:20 同步完工,A3 在 11:33:20 完工。
第 1 问设备利用率最高的是 高速抛光机1-1 和 自动传感多功能机1-1,均为 43.27%。这与表格中 A2、A3 的长加工时间一致。
7.2 第 2 问:单班组多车间,瓶颈集中在少数关键设备
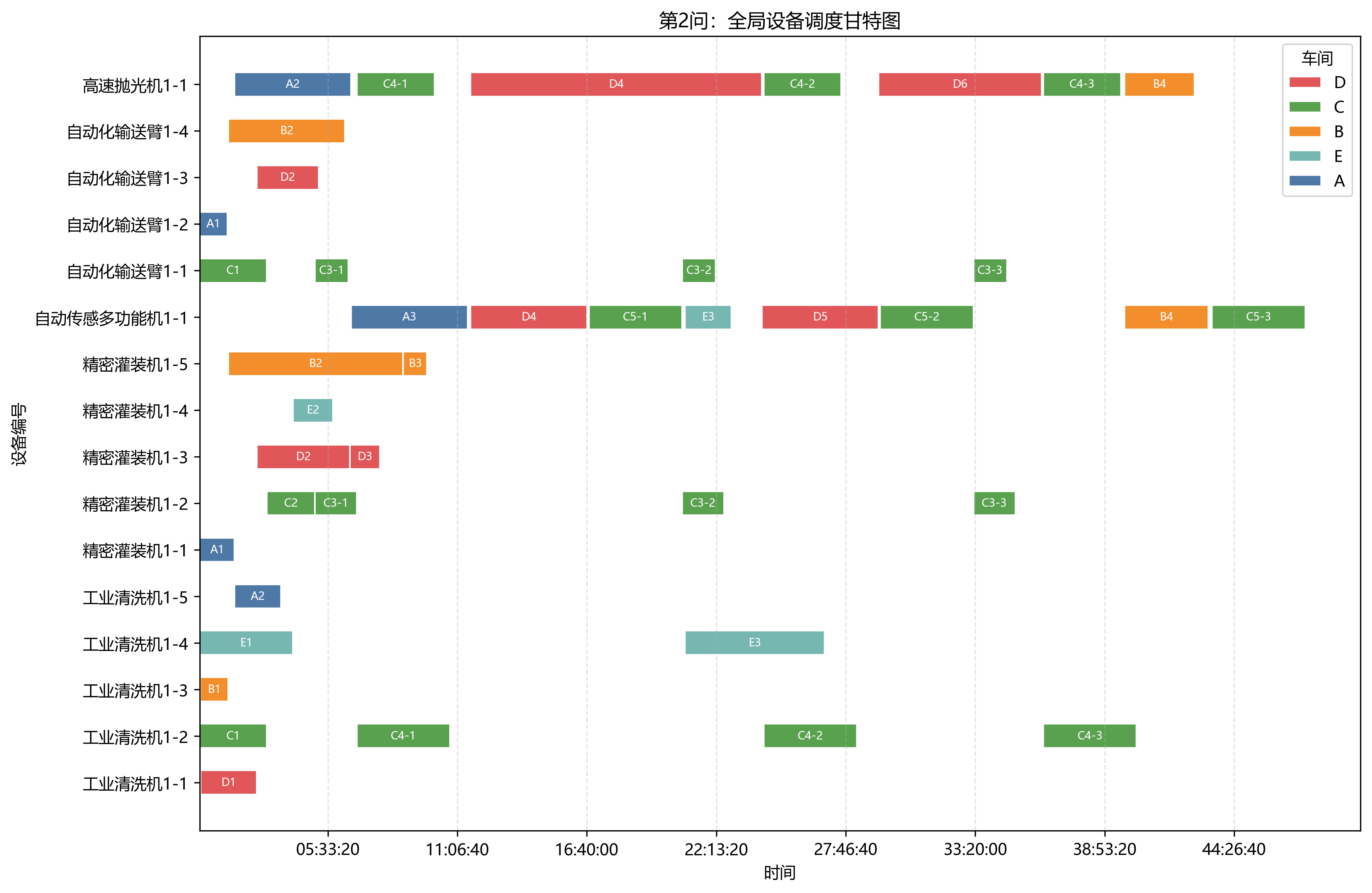
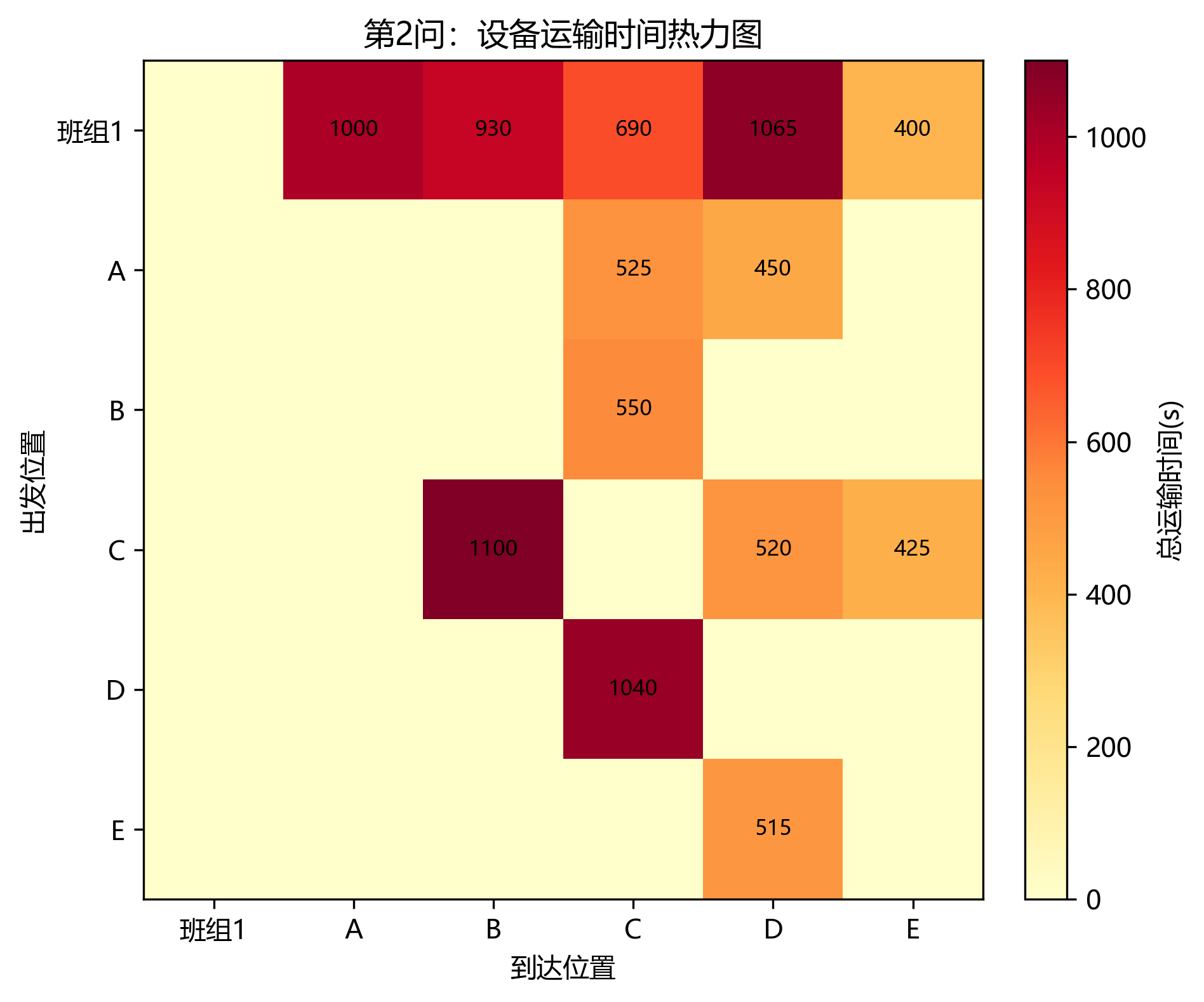
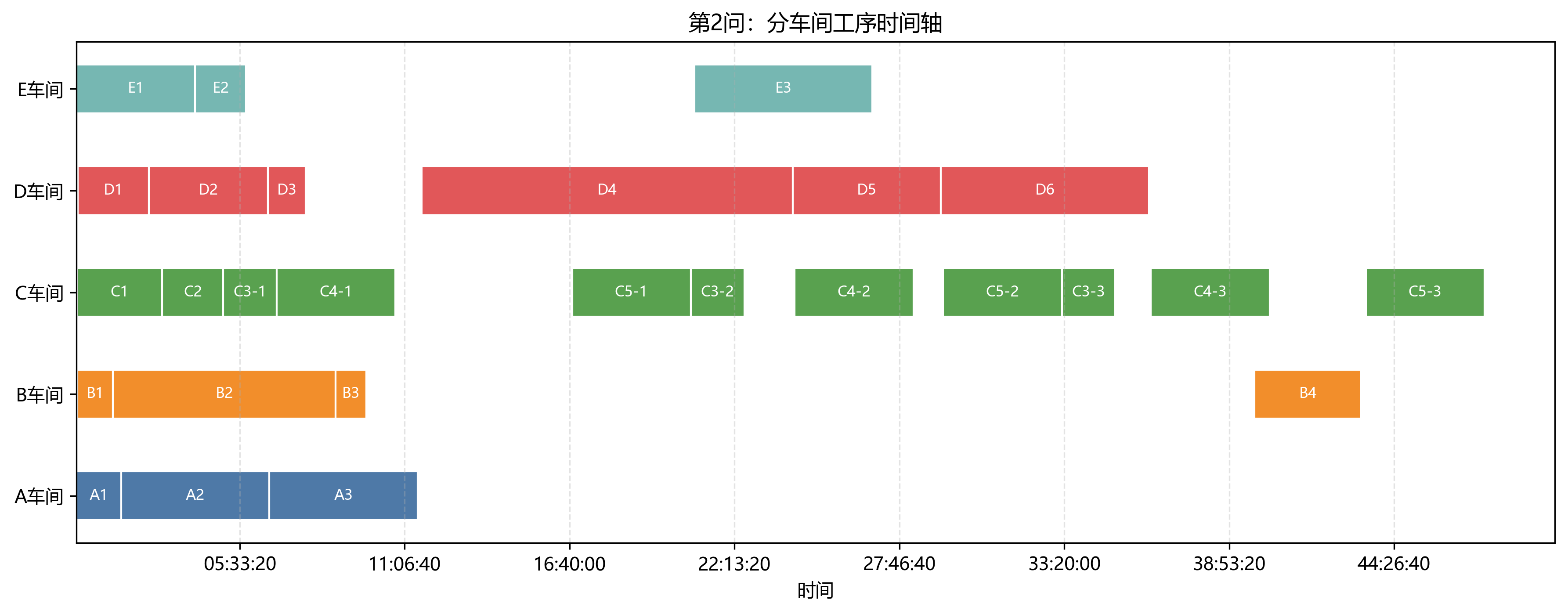
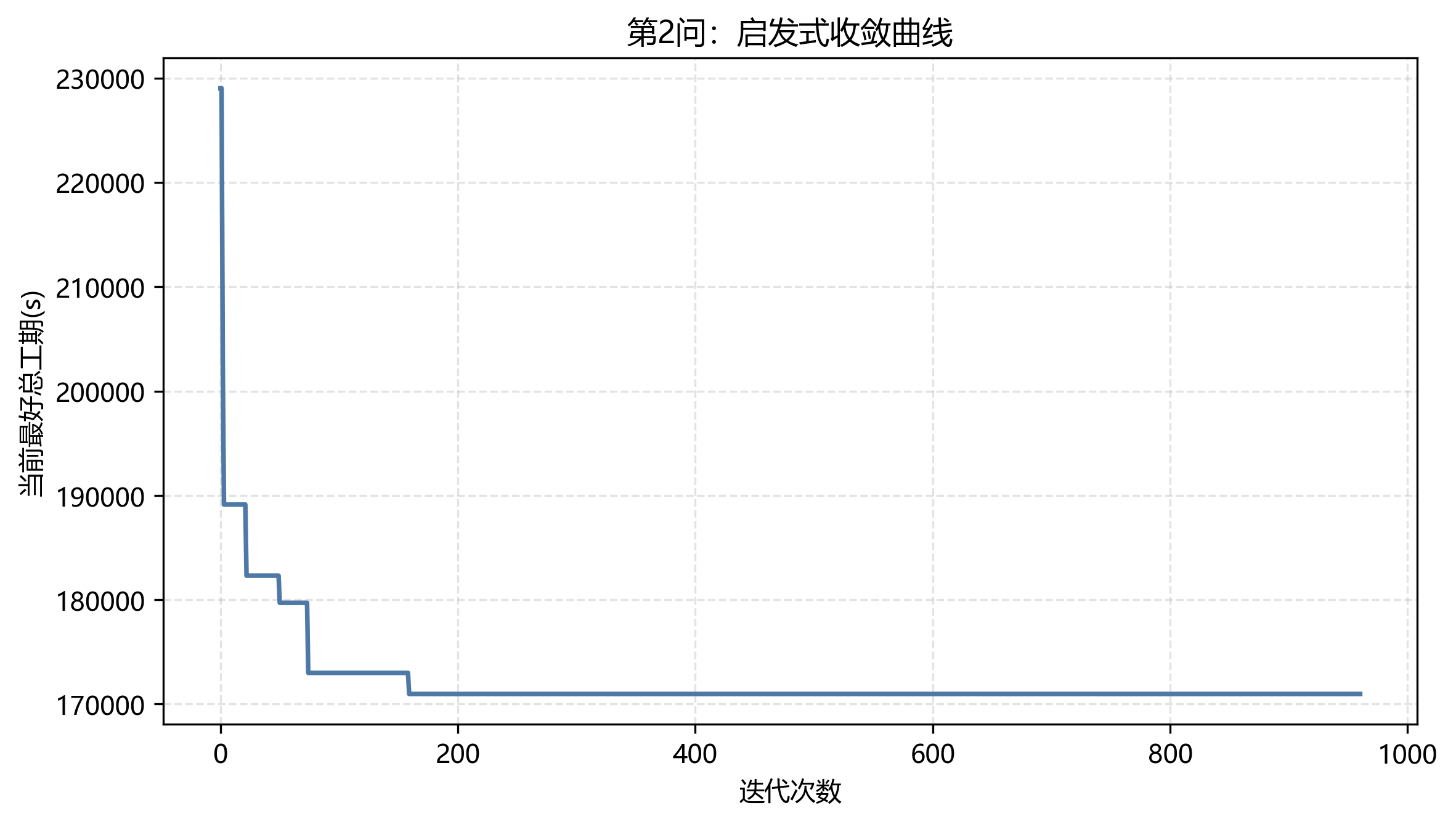
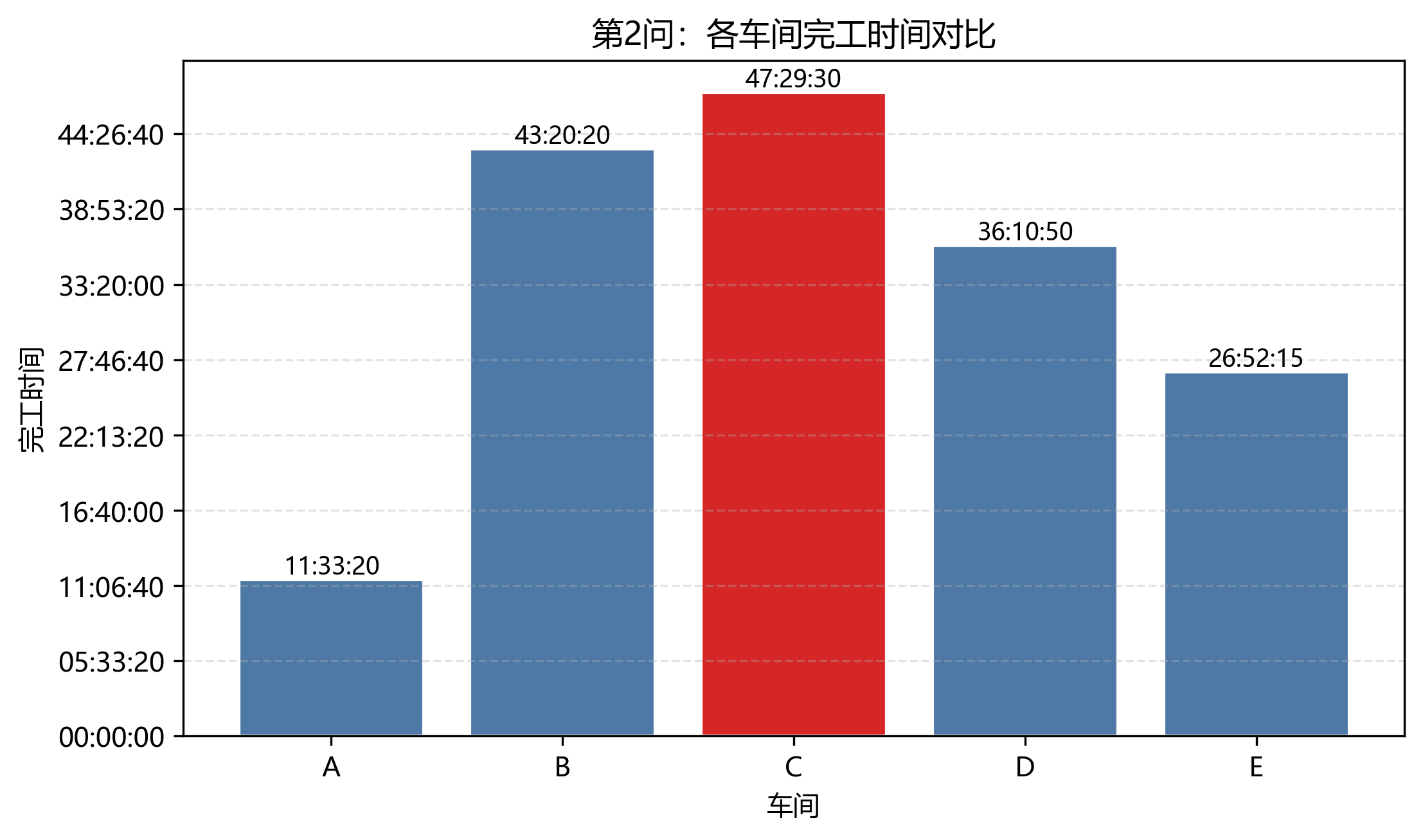
第 2 问只使用班组 1 的设备完成五个车间。日志给出的最终总工期为 170970 s = 47:29:30,求解方法为"贪心构造+随机扰动+局部搜索",状态为"Gurobi 不可用或未采用精确解,输出启发式当前最好可行解"。
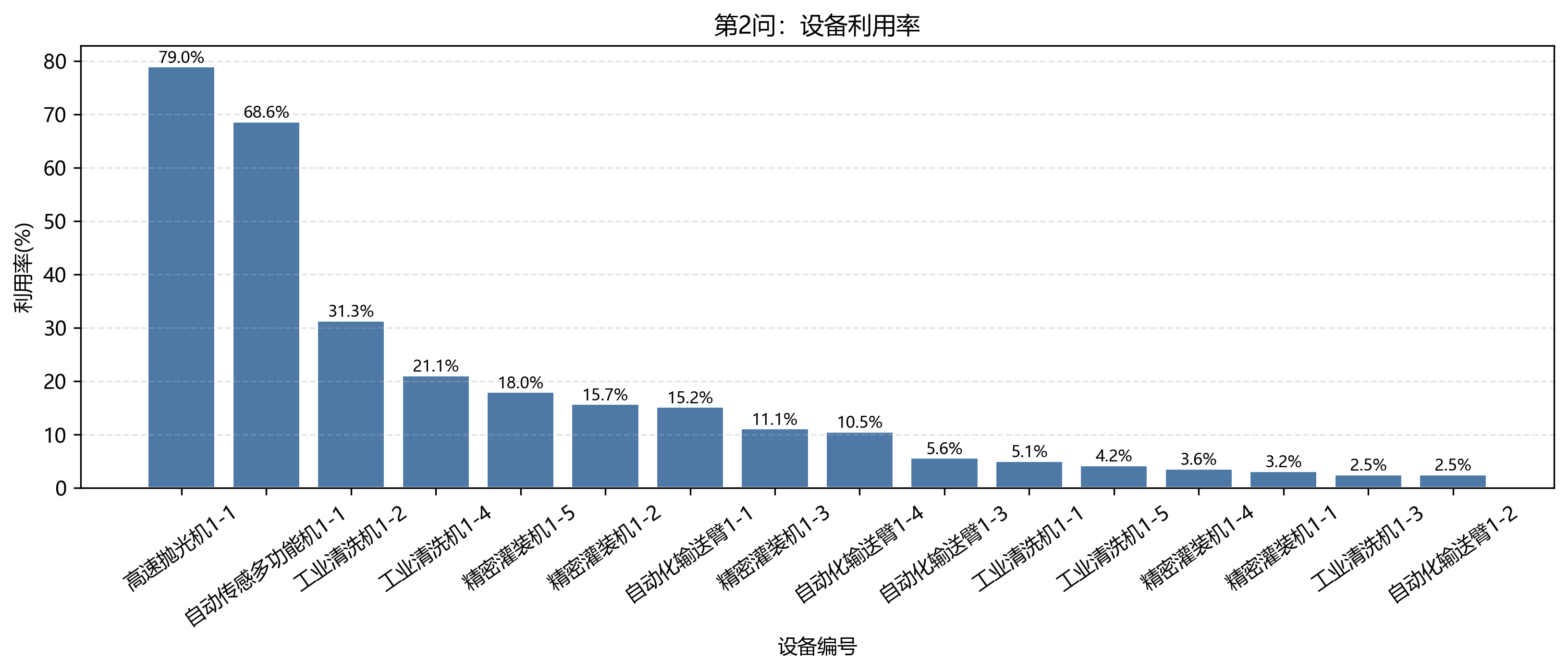
从设备利用率看,第 2 问的瓶颈非常集中:高速抛光机1-1 工作 135000 s,利用率 78.96%;自动传感多功能机1-1 工作 117360 s,利用率 68.64%。这说明单班组条件下,少数稀缺设备主导了总工期。
运输时间合计为 9210 s,占总工期约 5.39%。占比看似不高,但它会影响设备何时可用,从而改变关键设备的排队顺序。第 2 问中 C -> B、D -> C、班组1 -> D 等路径的累计运输时间较突出。
第 2 问迭代记录数为 961,初始记录总工期为 229040 s,最终降到 170970 s,下降 58070 s,下降比例 25.35%。这说明扰动和局部搜索确实在改善初始贪心解。
7.3 第 3 问:双班组协同缓解了单设备瓶颈
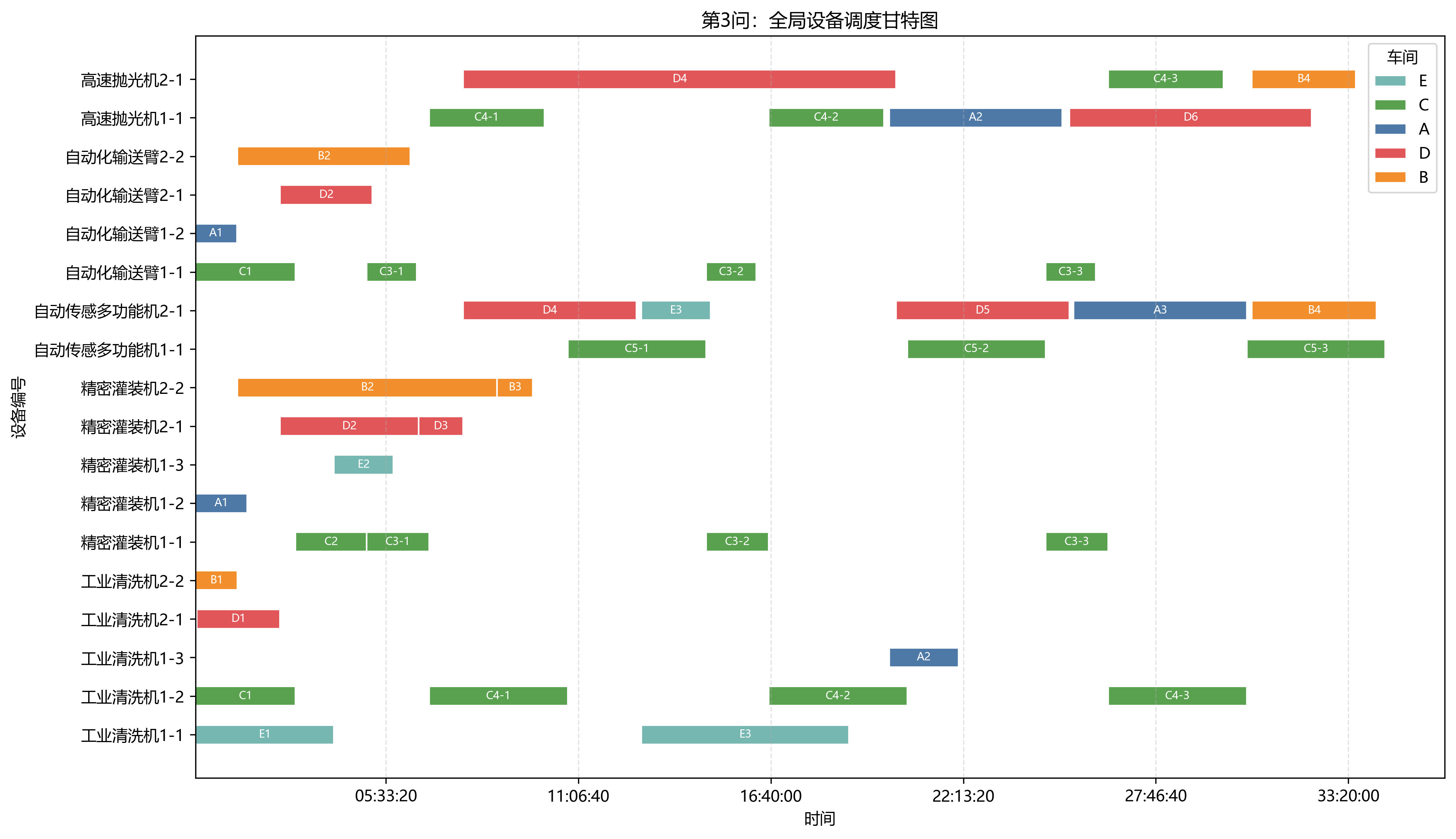
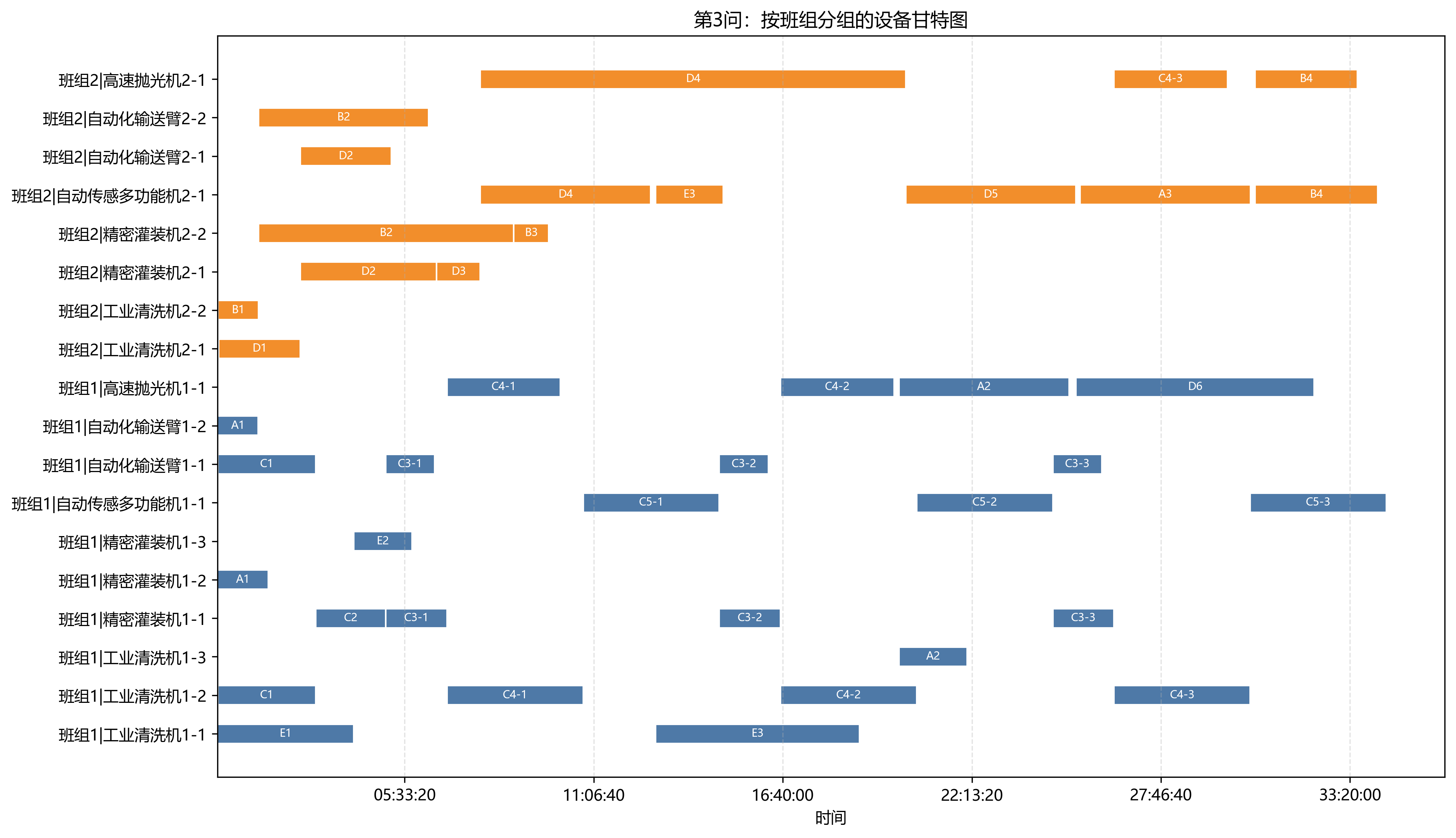
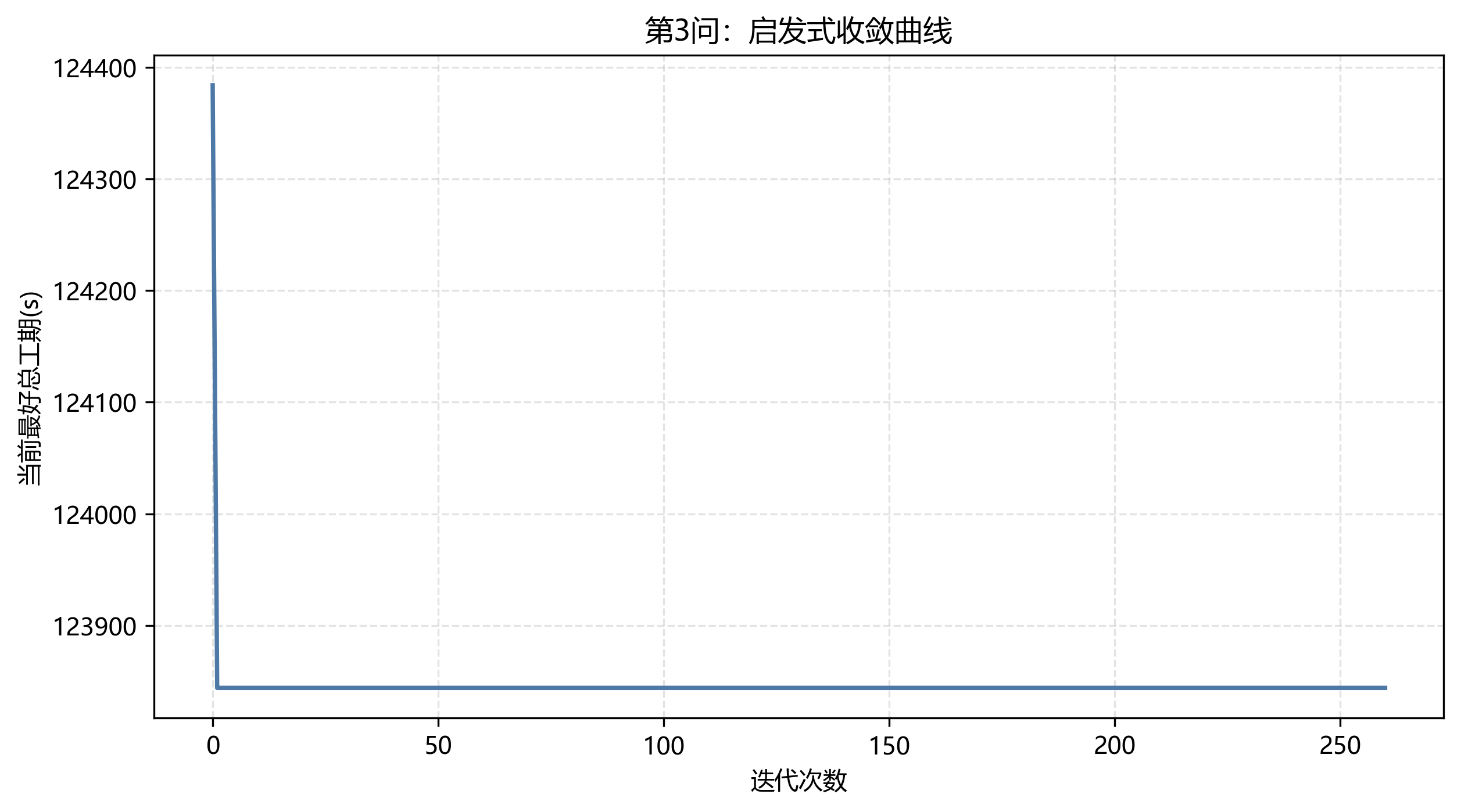
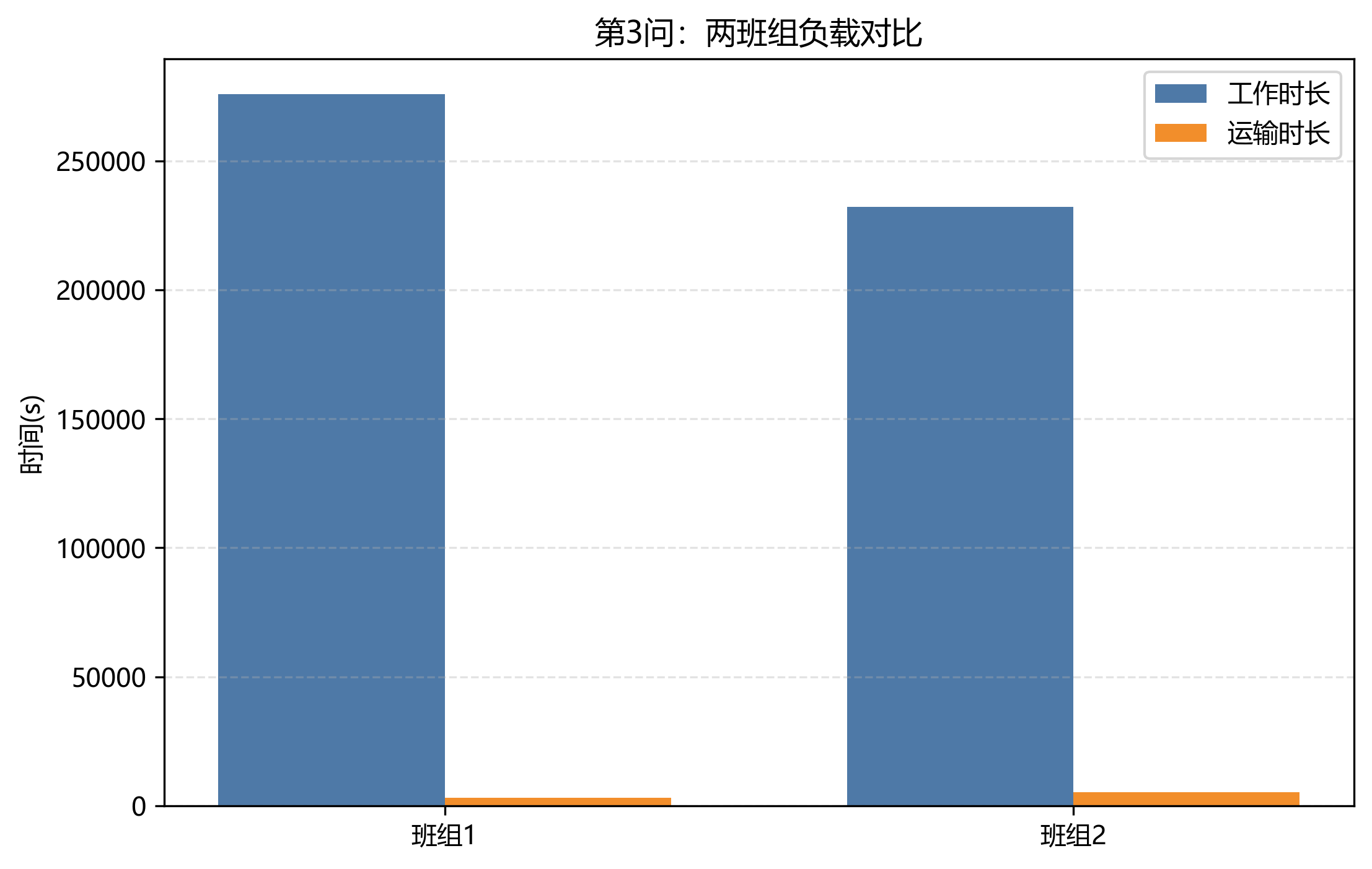
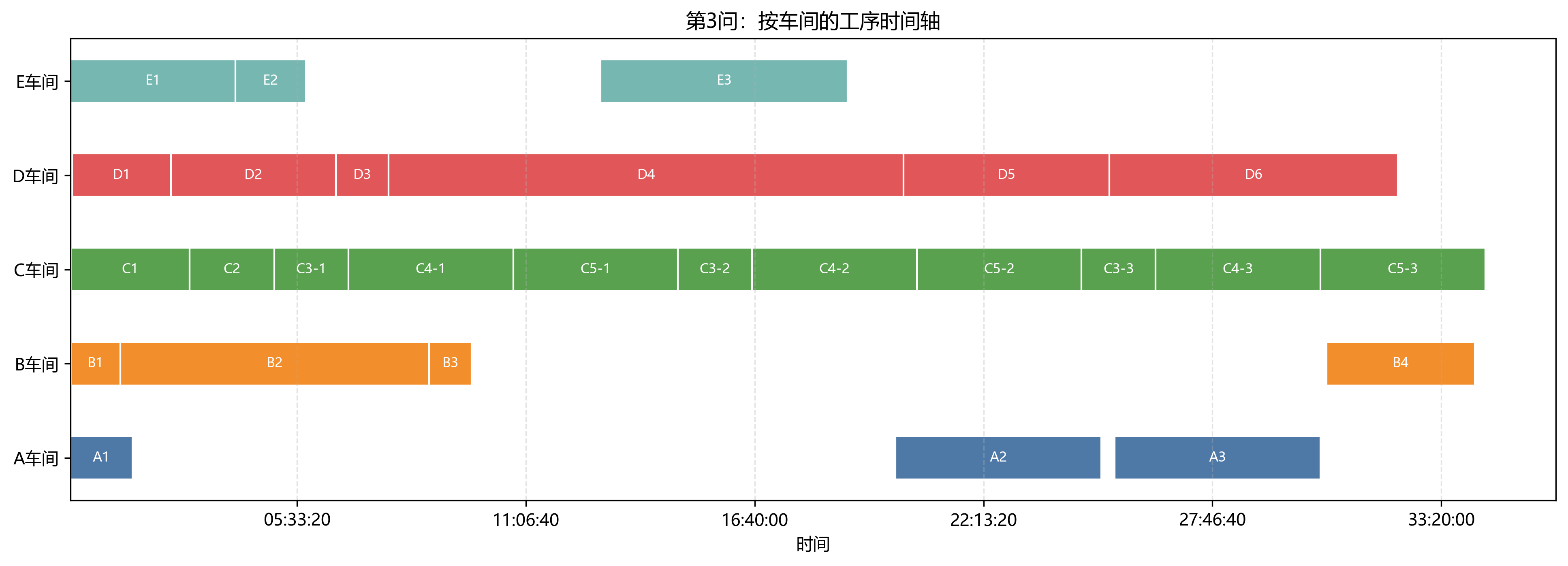
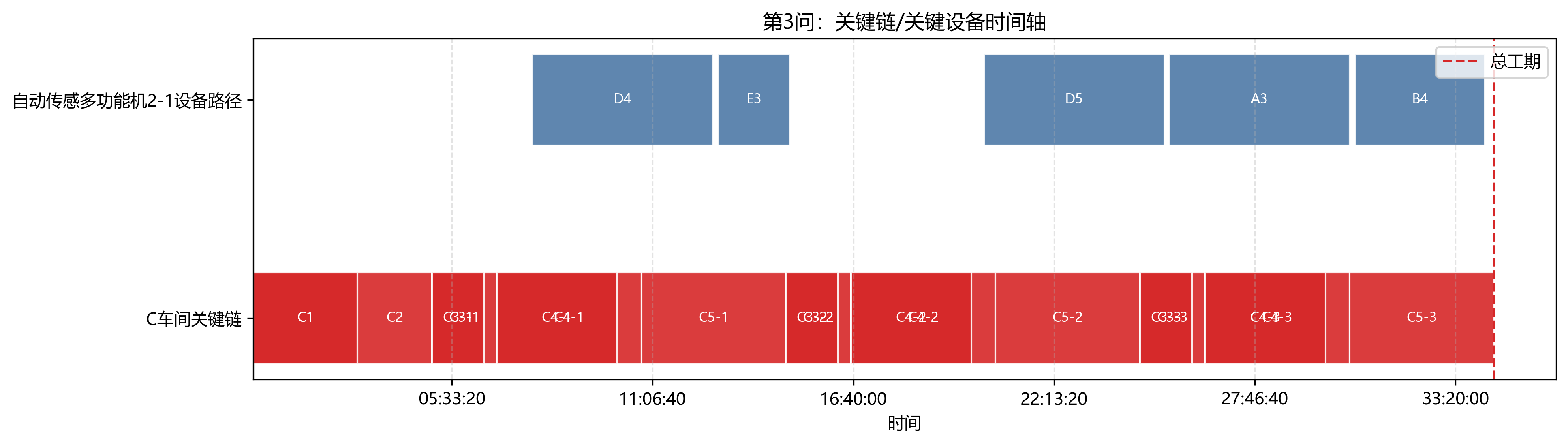
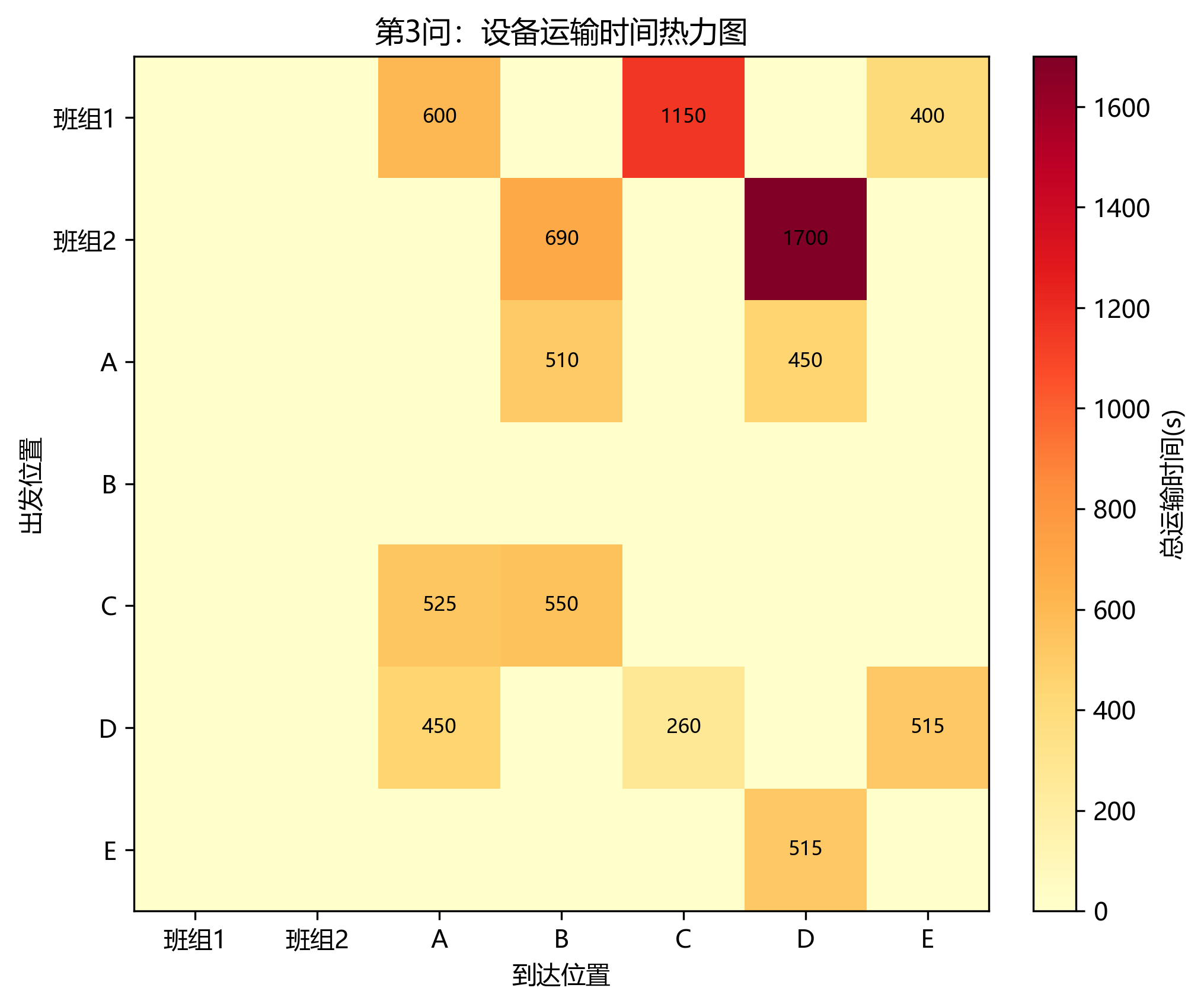
第 3 问使用两个班组的设备,最终总工期为 123844 s = 34:24:04。相较第 2 问缩短 47126 s,降幅约 27.56%。
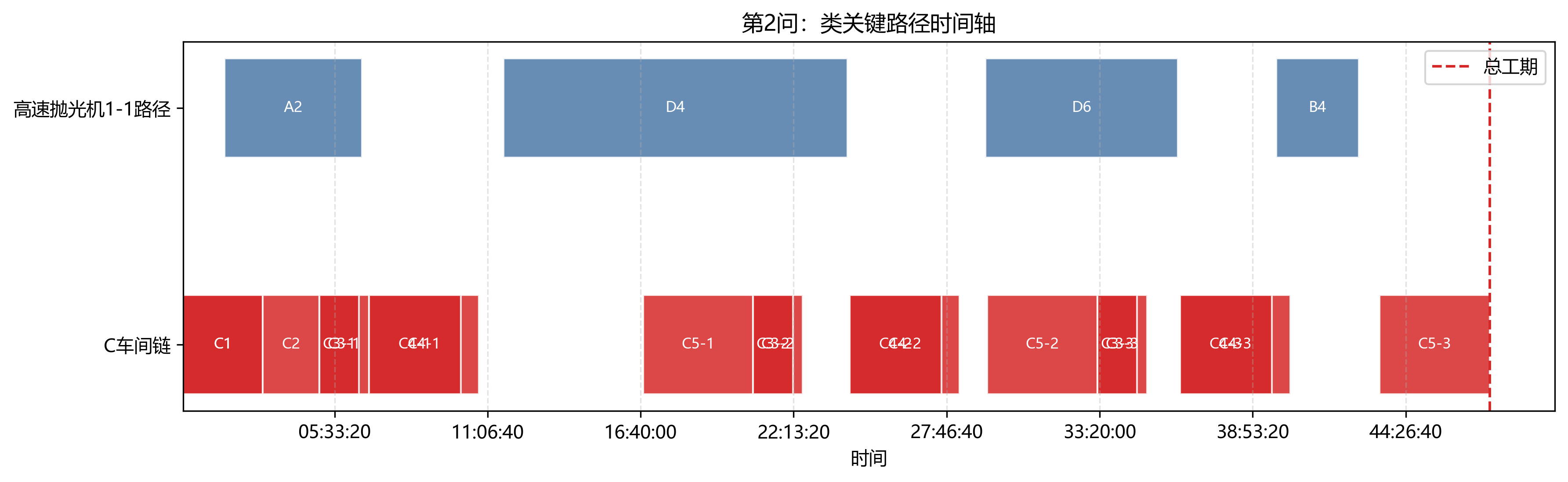
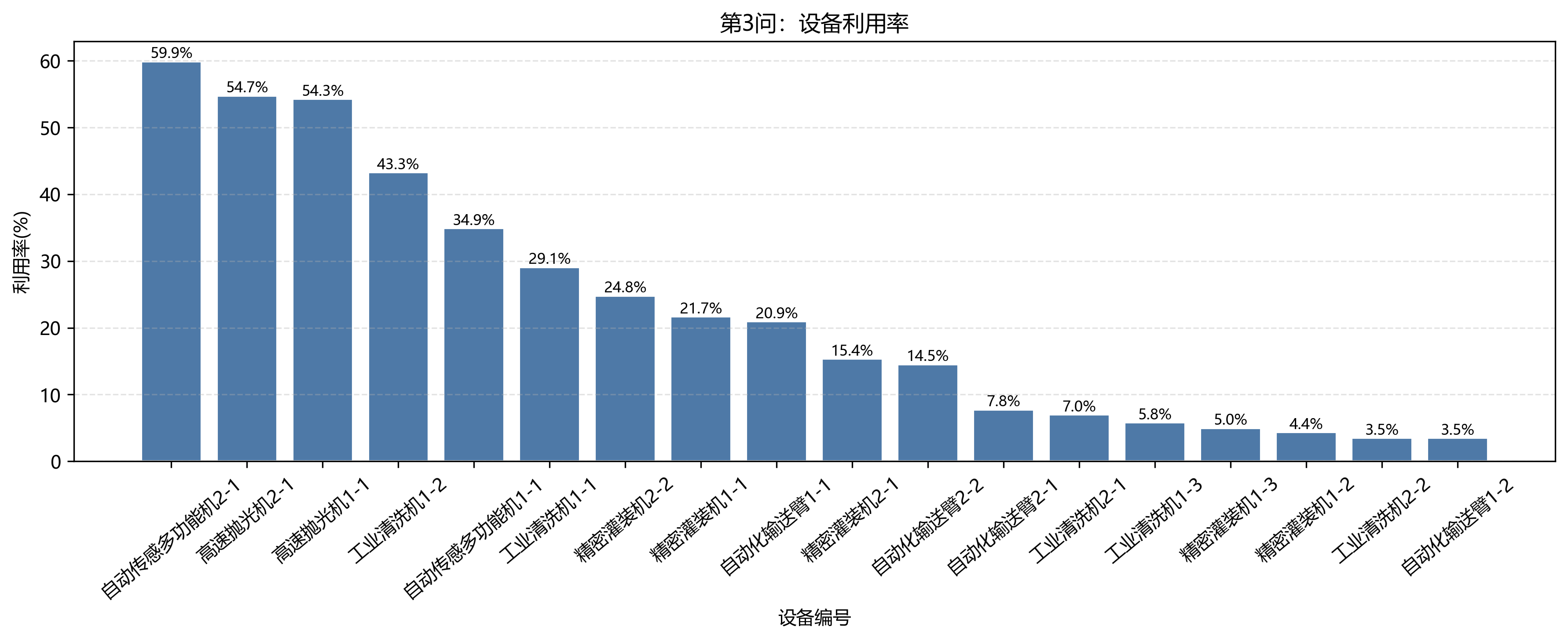
第 3 问瓶颈设备变为 自动传感多功能机2-1,工作 74160 s,利用率 59.88%。同时 高速抛光机2-1 与 高速抛光机1-1 的利用率分别为 54.75% 和 54.26%。这说明第二个班组的加入确实分散了原本集中在单台高速抛光机和单台自动传感多功能机上的压力。
班组 1 的工作时长为 275826 s,运输时长为 3125 s;班组 2 的工作时长为 232252 s,运输时长为 5190 s。班组 1 承担更多作业,班组 2 的运输负担更重一些,这和双班组初始位置不同、设备跨车间路径不同有关。
第 3 问运输时间合计为 8315 s,占总工期约 6.71%。虽然运输占比高于第 2 问,但总工期明显下降,说明扩充设备池带来的并行收益超过了额外路径协调成本。
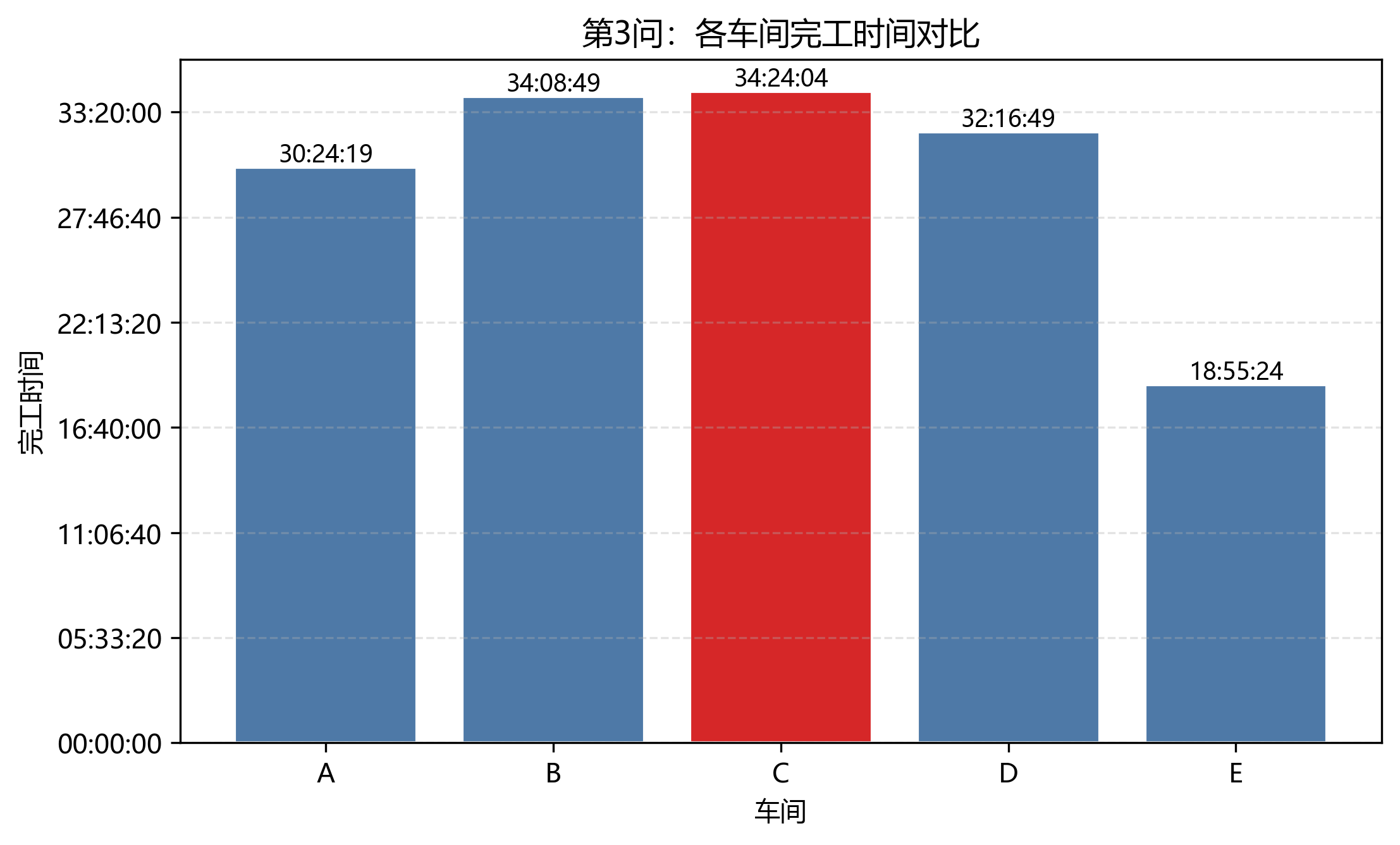
第 3 问瓶颈车间仍然是 C 车间,完工时间为 34:24:04。B 车间完工时间为 34:08:49,距离瓶颈也很近;E 车间最早完成,为 18:55:24。
关键链图把瓶颈车间和瓶颈设备放到一张时间轴里看。可以看到,第 3 问虽然通过双班组缓解了单设备压力,但多设备同步完工和 C 车间重复工序仍然把总工期锁在 C 车间附近。
第 3 问迭代记录数为 261,初始记录总工期 124384 s,最终 123844 s,下降 540 s。这个幅度比第 2 问小,说明第 3 问的初始解质量已经较高,局部搜索主要做细节修正。
8. 结果表格分析
8.1 分问总工期对比
| question | scope | method | makespan_s | makespan | change_vs_previous | validation |
|---|---|---|---|---|---|---|
| Q1 | Team 1, workshop A | Analytical earliest-start schedule | 41600 | 11:33:20 | - | pass |
| Q2 | Team 1, workshops A-E | Greedy construction + random perturbation + local search | 170970 | 47:29:30 | complexity upgrade; not directly comparable with Q1 | pass |
| Q3 | Teams 1-2, workshops A-E | Bi-team GA + greedy decoder + local search | 123844 | 34:24:04 | 47126 s shorter than Q2 (27.56%) | pass |
第 1 问和第 2 问不是同一任务规模,不能直接用总工期比较优劣;真正有意义的是第 2 问到第 3 问:资源从单班组扩展到双班组后,总工期从 47:29:30 降到 34:24:04。
8.2 第 2 问瓶颈设备
| device | type | work_s | travel_s | operations | utilization_pct |
|---|---|---|---|---|---|
| 高速抛光机1-1 | 高速抛光机 | 135000 | 2315 | 7 | 78.96 |
| 自动传感多功能机1-1 | 自动传感多功能机 | 117360 | 3210 | 8 | 68.64 |
| 工业清洗机1-2 | 工业清洗机 | 53568 | 230 | 4 | 31.33 |
| 工业清洗机1-4 | 工业清洗机 | 36000 | 200 | 2 | 21.06 |
| 精密灌装机1-5 | 精密灌装机 | 30703 | 310 | 2 | 17.96 |
| 精密灌装机1-2 | 精密灌装机 | 26846 | 230 | 4 | 15.70 |
| 自动化输送臂1-1 | 自动化输送臂 | 25920 | 230 | 4 | 15.16 |
| 精密灌装机1-3 | 精密灌装机 | 19029 | 355 | 2 | 11.13 |
单班组下,高速抛光机和自动传感多功能机数量少、工序负担重,因此它们是最直接的瓶颈。
8.3 第 3 问瓶颈设备
| team | device | type | work_s | travel_s | operations | utilization_pct |
|---|---|---|---|---|---|---|
| 班组2 | 自动传感多功能机2-1 | 自动传感多功能机 | 74160 | 2330 | 5 | 59.88 |
| 班组2 | 高速抛光机2-1 | 高速抛光机 | 67800 | 1150 | 3 | 54.75 |
| 班组1 | 高速抛光机1-1 | 高速抛光机 | 67200 | 1205 | 4 | 54.26 |
| 班组1 | 工业清洗机1-2 | 工业清洗机 | 53568 | 230 | 4 | 43.25 |
| 班组1 | 自动传感多功能机1-1 | 自动传感多功能机 | 43200 | 230 | 3 | 34.88 |
| 班组1 | 工业清洗机1-1 | 工业清洗机 | 36000 | 200 | 2 | 29.07 |
| 班组2 | 精密灌装机2-2 | 精密灌装机 | 30703 | 230 | 2 | 24.79 |
| 班组1 | 精密灌装机1-1 | 精密灌装机 | 26846 | 230 | 4 | 21.68 |
双班组后,原本过载的关键设备被拆分到两台同类设备上,但瓶颈没有消失,只是从"单台设备极高利用率"变成了"若干关键设备共同偏高利用率"。
8.4 各车间完工时间对比
| workshop | q2_finish | q2_finish_s | q2_bottleneck | q3_finish | q3_finish_s | q3_bottleneck | shorter_s | shorter_ratio |
|---|---|---|---|---|---|---|---|---|
| A | 11:33:20 | 41600 | False | 30:24:19 | 109459 | False | -67859 | -163.12% |
| B | 43:20:20 | 156020 | False | 34:08:49 | 122929 | False | 33091 | 21.21% |
| C | 47:29:30 | 170970 | True | 34:24:04 | 123844 | True | 47126 | 27.56% |
| D | 36:10:50 | 130250 | False | 32:16:49 | 116209 | False | 14041 | 10.78% |
| E | 26:52:15 | 96735 | False | 18:55:24 | 68124 | False | 28611 | 29.58% |
这个表里 A 车间在第 3 问反而更晚完成,不能简单理解为"所有车间都变快"。启发式调度为了压缩整体 makespan,会把关键资源优先让给更影响总工期的车间。最终 C、B、D、E 的完工时间得到压缩,整体目标改善。
8.5 第 3 问班组负载
| team | work_s | travel_s | operations | makespan_s | avg_load_intensity |
|---|---|---|---|---|---|
| 班组1 | 275826 | 3125 | 25 | 123844 | 2.23 |
| 班组2 | 232252 | 5190 | 16 | 123844 | 1.88 |
班组负载不是完全均衡的。班组 1 作业次数更多、工作时长更长;班组 2 运输时长更高。这个结果说明双班组协同并不等于简单平均分工,设备类型和当前位置都会影响最终分配。
9. 我最想强调的几个建模点
第一,模型核心不是"排序",而是带同步完工约束的资源受限调度。多设备工序必须等所有参与设备都完成,后续工序才可开始。
第二,运输时间虽然占总工期比例不算最高,但它会改变设备可用时刻,从而影响关键设备排序。第 2 问运输时间为 9210 s,第 3 问为 8315 s,都被纳入了自动校验。
第三,解码器比启发式名字更重要。只要解码器能稳定把编码转成可行调度,遗传、扰动、局部搜索这些搜索策略就可以逐步替换和升级。
第四,结果校验必须工程化。项目输出的校验报告覆盖工序顺序、设备重叠、运输时间、设备类型、同步完工和总工期定义,三问结果均校验通过。
第五,图表不是附属品。甘特图、利用率图、运输热力图和收敛曲线共同解释了为什么第 3 问能比第 2 问更短,也解释了瓶颈为什么仍然落在 C 车间。
10. 踩坑与优化经验
一开始最容易忽略的是"首次从班组到车间"的运输时间。第 1 问里班组 1 到 A 车间距离为 400 m,设备移动速度为 2 m/s,所以首道工序开始时间不是 00:00:00,而是 00:03:20。
第二个坑是双设备工序不能按单设备工序处理。例如 A1 需要精密灌装机和自动化输送臂共同参与,两类设备都要完成对应工程量,工序完工时间取两者结束时间的最大值。
第三个坑是可行性比"看起来短"更难。启发式很容易生成一个 makespan 很小但运输时间不足、设备重叠或工序顺序违规的方案,所以后来把 validator.py 独立出来,每次输出都自动检查。
11. 总结
这次项目最终形成了一条比较完整的建模工程链路:从附件数据解析开始,构造工序和设备数据结构;再用事件驱动解码器处理设备分配、跨车间运输和同步完工;最后通过启发式搜索、自动校验和可视化输出形成可复盘结果。
真实结果上,第 1 问得到 A 车间最短时长 41600 s = 11:33:20;第 2 问单班组完成五车间的当前最好可行解为 170970 s = 47:29:30;第 3 问双班组协同后降至 123844 s = 34:24:04,比第 2 问缩短 47126 s,约 27.56%。
对我来说,这道题最值得保留的不是某一个公式,而是"模型抽象 + 可行性解码 + 结果校验 + 图表解释"的完整闭环。它让比赛题不只是交一份答案,而是变成一个之后还能继续扩展、复盘和展示的工程项目。
需要代码的,请在评论区下留言,制作不易,请各位看官老爷点个赞!!!