文章目录
- 前言
- [Agent业务设计:应用多渠道发布数据收集监控 & 自动化AI分类分析实现](#Agent业务设计:应用多渠道发布数据收集监控 & 自动化AI分类分析实现)
- 一、问题场景
- 二、整体方案设计
-
- [2.1 核心目标](#2.1 核心目标)
- [2.2 架构流程图](#2.2 架构流程图)
- [2.3 核心设计决策](#2.3 核心设计决策)
- 三、表结构设计
-
- [3.1 用户对话消息表(最核心)](#3.1 用户对话消息表(最核心))
- [3.2 分类和归因配置表](#3.2 分类和归因配置表)
- [3.3 分析结果中间表](#3.3 分析结果中间表)
- 四、核心实现:数据收集中间件
-
- [4.1 中间件设计思路](#4.1 中间件设计思路)
- [4.2 核心代码实现](#4.2 核心代码实现)
- [4.3 触发异步分析](#4.3 触发异步分析)
- 五、核心实现:AI自动化分类归因
-
- [5.1 分析Prompt设计](#5.1 分析Prompt设计)
- [5.2 分类归因执行流程](#5.2 分类归因执行流程)
- [5.3 一个真实的执行示例](#5.3 一个真实的执行示例)
- 六、监控大屏实现
-
- [6.1 统计汇总卡片](#6.1 统计汇总卡片)
- [6.2 分类统计(饼图数据)](#6.2 分类统计(饼图数据))
- [6.3 待补全问题清单](#6.3 待补全问题清单)
- 七、总结
- 资料获取

前言
博主介绍:✌目前全网粉丝4W+,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质作者、专注于Java后端技术领域。
涵盖技术内容:Java后端、大数据、算法、分布式微服务、中间件、前端、运维等。
博主所有博客文件目录索引:博客目录索引(持续更新)
CSDN搜索:长路
视频平台:b站-Coder长路
Agent业务设计:应用多渠道发布数据收集监控 & 自动化AI分类分析实现
当AI Agent从实验室走向生产环境,如何衡量它的真实效果?如何持续优化它的回答质量?本文带你完整实现一套多渠道数据监控与自动化分析闭环。
一、问题场景
想象一下这个画面:你花了一周时间精心配置了一个企业知识库Agent,把它发布到了钉钉和官网两个渠道。上线第一周,用户访问量蹭蹭往上涨,你心里美滋滋的。
然后问题来了------老板问你:"这个Agent效果怎么样?"产品经理问你:"用户都在问什么问题?"你自己也想搞清楚:"哪些问题AI回答得不好?哪里需要优化?"
你发现自己对这些一无所知。
- 不知道每天有多少人在用
- 不知道用户问得最多的是什么类型的问题
- 不知道AI的回答质量怎么样
- 不知道哪些问题需要补充到知识库
这就是我们面临的核心问题:Agent上线了,但没有数据反馈,你就是一个"盲人"。
本文从实战角度出发,分享我们如何在云端平台实现一套完整的Agent多渠道监控体系,包含数据收集、自动分类归因、可视化大屏,最终形成"数据驱动优化"的闭环能力。
二、整体方案设计
2.1 核心目标
在开始写代码之前,我们先把目标说清楚:
| 目标 | 具体描述 |
|---|---|
| 多渠道统一收集 | 云端Web和钉钉渠道的用户问答数据统一存储 |
| 自动化分类归因 | AI自动分析每条问答的类别和问题类型 |
| 可视化数据大屏 | 运营人员可以直观看到各项指标 |
| 闭环优化能力 | 发现的问题可追踪、可处理、可验证 |
2.2 架构流程图
整个系统分为四个核心环节:
用户问答 → 数据收集 → 自动分析 → 可视化管理
↓ ↓ ↓ ↓
多渠道 统一存储 AI分类归因 监控大屏+待办清单更详细的数据流转是这样:
钉钉用户 ──→ 钉钉渠道SDK ──┐
├──→ Agent → 记录消息 → 触发异步分析
网页用户 ──→ Web API ────┘ ↓
AI分析服务
↓
┌────────────┴────────────┐
↓ ↓
分类结果 归因结果
(维度标签) (优化建议)
↓ ↓
存入中间表 生成待办清单2.3 核心设计决策
在具体实现前,有两个关键的设计决策需要先讲清楚。
决策一:多渠道消息的统一存储模型
网页和钉钉的交互方式不同:网页是流式响应,钉钉是非流式。这意味着我们能获取的时间指标不一样。但我们不能让上层业务关心这些差异,所以在存储层做了统一抽象:
- 所有渠道都用同一张表存储
channel_code字段标识来源ttft_start_time和ttft_count_time在非流式场景下设为同一个值
这样监控大屏查询时,完全不用关心数据来自哪个渠道。
决策二:实时分析 vs 异步分析
这是个很实际的问题:是在用户问答完成后立即用AI分析,还是攒一批再处理?
我们最终选择了对话完成时生成记录 + 异步消费的方案。原因很简单:
| 场景 | 实时分析 | 异步分析 |
|---|---|---|
| 单个Agent少量问答 | ✅ 简单直接 | ❌ 过度设计 |
| 多个Agent大量问答 | ❌ 容易打爆AI并发 | ✅ 可水平扩展 |
| 历史数据处理 | ❌ 需要跑全量 | ✅ 按记录消费 |
考虑到平台可能有几十上百个Agent同时在用,异步方案更稳妥。而且异步分析使用的AI模型和主Agent是隔离的,不会影响用户正常的问答体验。
三、表结构设计
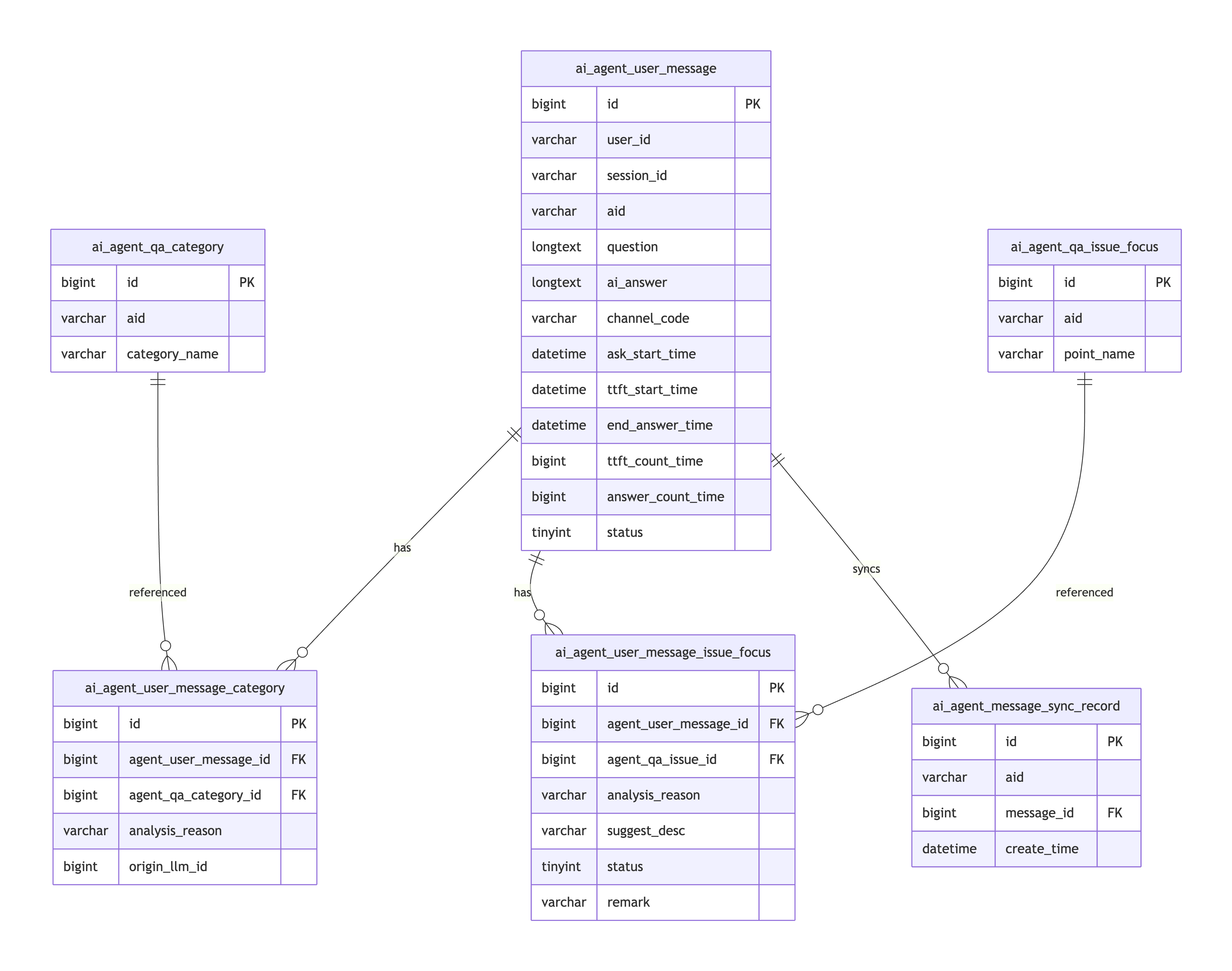
erDiagram
ai_agent_user_message {
bigint id PK
varchar user_id
varchar session_id
varchar aid
longtext question
longtext ai_answer
varchar channel_code
datetime ask_start_time
datetime ttft_start_time
datetime end_answer_time
bigint ttft_count_time
bigint answer_count_time
tinyint status
}
ai_agent_qa_category {
bigint id PK
varchar aid
varchar category_name
}
ai_agent_qa_issue_focus {
bigint id PK
varchar aid
varchar point_name
}
ai_agent_user_message_category {
bigint id PK
bigint agent_user_message_id FK
bigint agent_qa_category_id FK
varchar analysis_reason
bigint origin_llm_id
}
ai_agent_user_message_issue_focus {
bigint id PK
bigint agent_user_message_id FK
bigint agent_qa_issue_id FK
varchar analysis_reason
varchar suggest_desc
tinyint status
varchar remark
}
ai_agent_message_sync_record {
bigint id PK
varchar aid
bigint message_id FK
datetime create_time
}
ai_agent_user_message ||--o{ ai_agent_user_message_category : has
ai_agent_user_message ||--o{ ai_agent_user_message_issue_focus : has
ai_agent_user_message ||--o{ ai_agent_message_sync_record : syncs
ai_agent_qa_category ||--o{ ai_agent_user_message_category : referenced
ai_agent_qa_issue_focus ||--o{ ai_agent_user_message_issue_focus : referenced核心关系:
┌─────────────────────────┐
│ ai_agent_user_message │ ← 源头:用户每一次问答
│ (主表) │
└───────────┬─────────────┘
│
┌───────┴───────┐
↓ ↓
┌───┴───┐ ┌───┴───┐
│category│ │ issue │
│ 中间表 │ │ 中间表 │
└───┬───┘ └───┬───┘
↓ ↓
┌───┴───┐ ┌───┴───┐
│category│ │ issue │
│ 配置表 │ │ 配置表 │
└───────┘ └───────┘先贴出核心表结构,后续实现都围绕它们展开。
3.1 用户对话消息表(最核心)
sql
CREATE TABLE `ai_agent_user_message` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`user_id` varchar(128) NOT NULL COMMENT '用户ID',
`session_id` varchar(255) NOT NULL COMMENT '会话ID',
`aid` varchar(64) NOT NULL COMMENT 'agent唯一标识',
`question` longtext COMMENT '用户提问内容',
`ai_answer` longtext COMMENT 'AI回答内容',
`channel_code` varchar(50) DEFAULT NULL COMMENT '来源渠道:dingtalk/website',
`ask_start_time` datetime DEFAULT NULL COMMENT '用户提问开始时间',
`ttft_start_time` datetime DEFAULT NULL COMMENT 'AI首次响应开始时间',
`end_answer_time` datetime DEFAULT NULL COMMENT 'AI回答结束时间',
`ttft_count_time` bigint(20) DEFAULT NULL COMMENT 'TTFT耗时(毫秒)',
`answer_count_time` bigint(20) DEFAULT NULL COMMENT '回答总耗时',
`status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '0进行中、1成功、2失败',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户对话消息表';设计要点:
- 时间字段拆得细,是为了后续能计算TTFT(首字延迟)和总响应时间这两个关键性能指标
channel_code让后续统计可以按渠道下钻分析status字段帮我们过滤掉失败的回答,避免污染分析数据
3.2 分类和归因配置表
sql
-- 维度分类配置(如:产品咨询、技术支持、价格咨询...)
CREATE TABLE `ai_agent_qa_category` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`aid` varchar(64) NOT NULL COMMENT 'agent标识',
`category_name` varchar(255) NOT NULL COMMENT '分类名称',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='问答分类配置表';
-- 问题关注点配置(如:回答不准确、知识缺失、逻辑错误...)
CREATE TABLE `ai_agent_qa_issue_focus` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`aid` varchar(64) NOT NULL COMMENT 'agent标识',
`point_name` varchar(255) NOT NULL COMMENT '关注点名称',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='问题关注点配置表';这两个表是给运营人员配置的,每个Agent可以有自己的一套分类和归因体系。
3.3 分析结果中间表
sql
-- 消息-分类关联表
CREATE TABLE `ai_agent_user_message_category` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`agent_user_message_id` bigint(20) NOT NULL,
`agent_qa_category_id` bigint(20) NOT NULL,
`analysis_reason` varchar(1024) DEFAULT NULL COMMENT 'AI分析原因',
`origin_llm_id` bigint(20) DEFAULT NULL COMMENT '来源模型ID',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='消息分类关联表';
-- 消息-关注点关联表(带处理状态)
CREATE TABLE `ai_agent_user_message_issue_focus` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`agent_user_message_id` bigint(20) NOT NULL,
`agent_qa_issue_id` bigint(20) NOT NULL,
`analysis_reason` varchar(1024) DEFAULT NULL,
`suggest_desc` varchar(1024) DEFAULT NULL COMMENT '优化建议',
`status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '0待处理、1处理中、2已处理、3已忽略',
`remark` varchar(1024) DEFAULT NULL COMMENT '处理备注',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='消息关注点关联表';关键设计 :关注点表带了 status 字段,这意味着每一个被标记为"需要优化"的问题都可以变成一个可追踪的工单,运营人员可以跟进处理,形成真正的闭环。
四、核心实现:数据收集中间件
数据收集是整个监控体系的"水管",必须稳定、低侵入、不影响主流程。
4.1 中间件设计思路
我们用一个拦截器/切面来实现,在Agent调用的各个关键节点插入记录逻辑:
用户发起问答 → 【记录开始】→ 调用Agent → 【记录TTFT】→ 等待响应 → 【记录结束】每次对话最多三次数据库操作:
INSERT:对话开始时插入初始记录UPDATE:收到首字响应时更新TTFT时间UPDATE:对话结束时更新最终结果和耗时
4.2 核心代码实现
java
@Component
public class AiAgentMonitorInterceptor {
private final AiAgentUserMessageMapper messageMapper;
// 用一个ThreadLocal存储当前消息ID,方便后续更新
private final ThreadLocal<Long> currentMessageId = new ThreadLocal<>();
/**
* 对话开始:插入初始记录
*/
public void onStart(String aid, String userId, String sessionId,
String channelCode, String question) {
AiAgentUserMessagePojo message = AiAgentUserMessagePojo.builder()
.aid(aid)
.userId(userId)
.sessionId(sessionId)
.channelCode(channelCode)
.question(question)
.askStartTime(new Date())
.status(0) // 进行中
.build();
messageMapper.insertUserMessage(message);
currentMessageId.set(message.getId());
}
/**
* 首字响应:记录TTFT时间
*/
public void onFirstToken() {
Long messageId = currentMessageId.get();
if (messageId != null) {
AiAgentUserMessagePojo message = new AiAgentUserMessagePojo();
message.setId(messageId);
message.setTtftStartTime(new Date());
messageMapper.updateUserMessage(message);
}
}
/**
* 对话结束:更新最终结果和耗时
*/
public void onComplete(String answer, Long originLlmId) {
Long messageId = currentMessageId.get();
if (messageId != null) {
Date endTime = new Date();
AiAgentUserMessagePojo message = messageMapper.selectUserMessageById(messageId);
if (message.getTtftStartTime() != null) {
message.setTtftCountTime(
endTime.getTime() - message.getTtftStartTime().getTime()
);
}
message.setAnswerCountTime(
endTime.getTime() - message.getAskStartTime().getTime()
);
message.setAiAnswer(answer);
message.setEndAnswerTime(endTime);
message.setOriginLlmId(originLlmId);
message.setStatus(1); // 成功
messageMapper.updateUserMessage(message);
// 关键:触发异步分析
triggerAsyncAnalysis(messageId, aid);
}
currentMessageId.remove();
}
}4.3 触发异步分析
对话完成后,我们插入一条同步记录,由独立的消费者去处理AI分析:
java
private void triggerAsyncAnalysis(Long messageId, String aid) {
AiAgentMessageSyncRecordPojo record = AiAgentMessageSyncRecordPojo.builder()
.messageId(messageId)
.aid(aid)
.build();
syncRecordMapper.insertMessageSyncRecord(record);
// 这里可以发消息队列,也可以直接调异步线程池
}这样做的好处是:
- 解耦:主流程不会被AI分析拖慢
- 可控:可以控制AI分析的并发度
- 可重试:分析失败了可以重新消费
五、核心实现:AI自动化分类归因
这是整个系统最有技术含量的部分------让AI自己分析AI的回答质量。
5.1 分析Prompt设计
java
@AICall(
systemPrompt = """
你是AI问答系统的分析与优化专家,擅长从用户问答中判断分类、识别问题根因、提出优化建议。
你需要保持客观、准确,分析要有深度,建议要可落地。
""",
question = """
请分析以下用户问答内容及对话上下文,完成分类分析与归因分析:
## 用户问题:
{{question}}
## 系统回答:
{{answer}}
## 分类选项配置:
{{categoryOptions}}
## 归因选项配置:
{{issueFocusOptions}}
==================== 分析任务 ====================
## 一、分类分析
根据问题的核心意图,判断本次对话最匹配的分类ID。
## 二、归因与优化分析
判断回答是否存在问题:
- needOptimize = true:回答有问题,需要优化
- needOptimize = false:回答质量良好
如果 needOptimize = true,进一步判断归因类型并给出优化建议。
请严格按照以下 JSON 格式输出:
{
"categoryAnalysis": {
"agentQaCategoryId": 1001,
"analysisReason": "分类分析原因"
},
"attributionAnalysis": {
"needOptimize": true,
"agentQaIssueId": 2003,
"analysisReason": "归因分析原因",
"suggestDesc": "优化建议"
}
}
"""
)
UserMessageAnalysisResultDto analyzeUserMessage(...);Prompt设计要点:
- 动态注入配置:Agent自己的分类和归因配置会作为选项传给AI,让AI从预设选项中选择
- 结构化输出:强制JSON格式,方便解析入库
- 分析原因必填:要求AI解释判断依据,便于人工复核
5.2 分类归因执行流程
整个异步分析流程的核心逻辑:
java
@Service
public class UserMessageAnalysisService {
@Autowired
private AIUserMessageAnalysisTool analysisTool;
public void analyzeMessage(Long messageId, String aid) {
// 1. 构建分析上下文(包含问题、回答、分类选项、归因选项)
UserMessageAnalysisContextDto context =
contextService.buildAnalysisContext(messageId, aid, null, null);
// 2. 调用AI进行分析
UserMessageAnalysisResultDto result = analysisTool.analyzeUserMessage(
context.getQuestion(),
context.getAnswer(),
null, // 对话上下文
null, // 历史消息
contextService.buildCategoryOptionsPrompt(context),
contextService.buildIssueFocusOptionsPrompt(context)
);
// 3. 存储分类结果
if (result.getCategoryAnalysis().getAgentQaCategoryId() != null) {
saveCategoryMapping(messageId, aid,
result.getCategoryAnalysis().getAgentQaCategoryId(),
result.getCategoryAnalysis().getAnalysisReason());
}
// 4. 存储归因结果
if (result.getAttributionAnalysis().getNeedOptimize()) {
saveIssueFocusMapping(messageId, aid,
result.getAttributionAnalysis().getAgentQaIssueId(),
result.getAttributionAnalysis().getAnalysisReason(),
result.getAttributionAnalysis().getSuggestDesc());
}
// 5. 删除同步记录,标记处理完成
syncRecordMapper.deleteMessageSyncRecordById(recordId);
}
}5.3 一个真实的执行示例
假设用户问:"你们的Agent支持私有化部署吗?"
AI回答:"目前我们支持云端SaaS版本,私有化部署正在规划中,预计Q3上线。"
AI分析后的输出:
json
{
"categoryAnalysis": {
"agentQaCategoryId": 1005,
"analysisReason": "用户询问的是产品部署方式相关的能力,属于'产品能力咨询'分类"
},
"attributionAnalysis": {
"needOptimize": false,
"agentQaIssueId": null,
"analysisReason": "回答准确告知了当前不支持私有化,并给出了规划时间,信息完整",
"suggestDesc": ""
}
}如果AI回答得不好,比如答非所问,分析结果就会是:
json
{
"categoryAnalysis": {
"agentQaCategoryId": 1005,
"analysisReason": "用户询问部署方式,属于产品能力咨询"
},
"attributionAnalysis": {
"needOptimize": true,
"agentQaIssueId": 2001,
"analysisReason": "AI回答未针对用户问题提供有效信息,回答与问题不相关,属于'问题理解错误'",
"suggestDesc": "优化RAG检索策略,确保用户问部署相关问题能匹配到知识库中的部署相关文档"
}
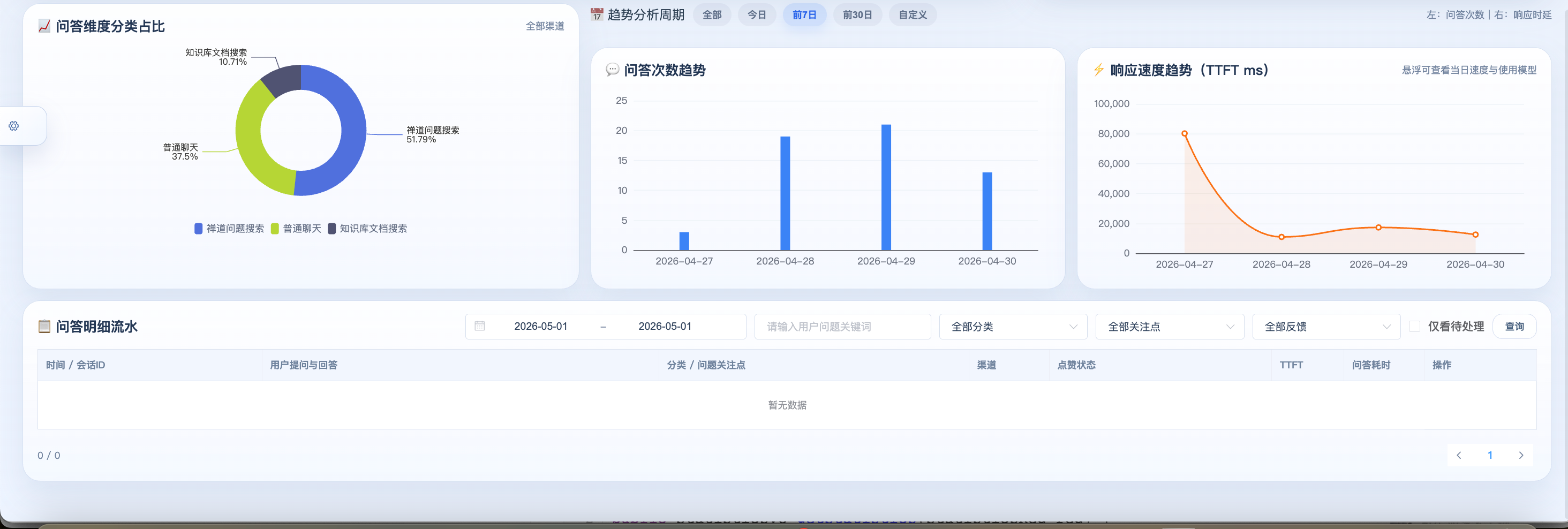
}六、监控大屏实现
有了数据,怎么呈现?我们做了几个核心视图。
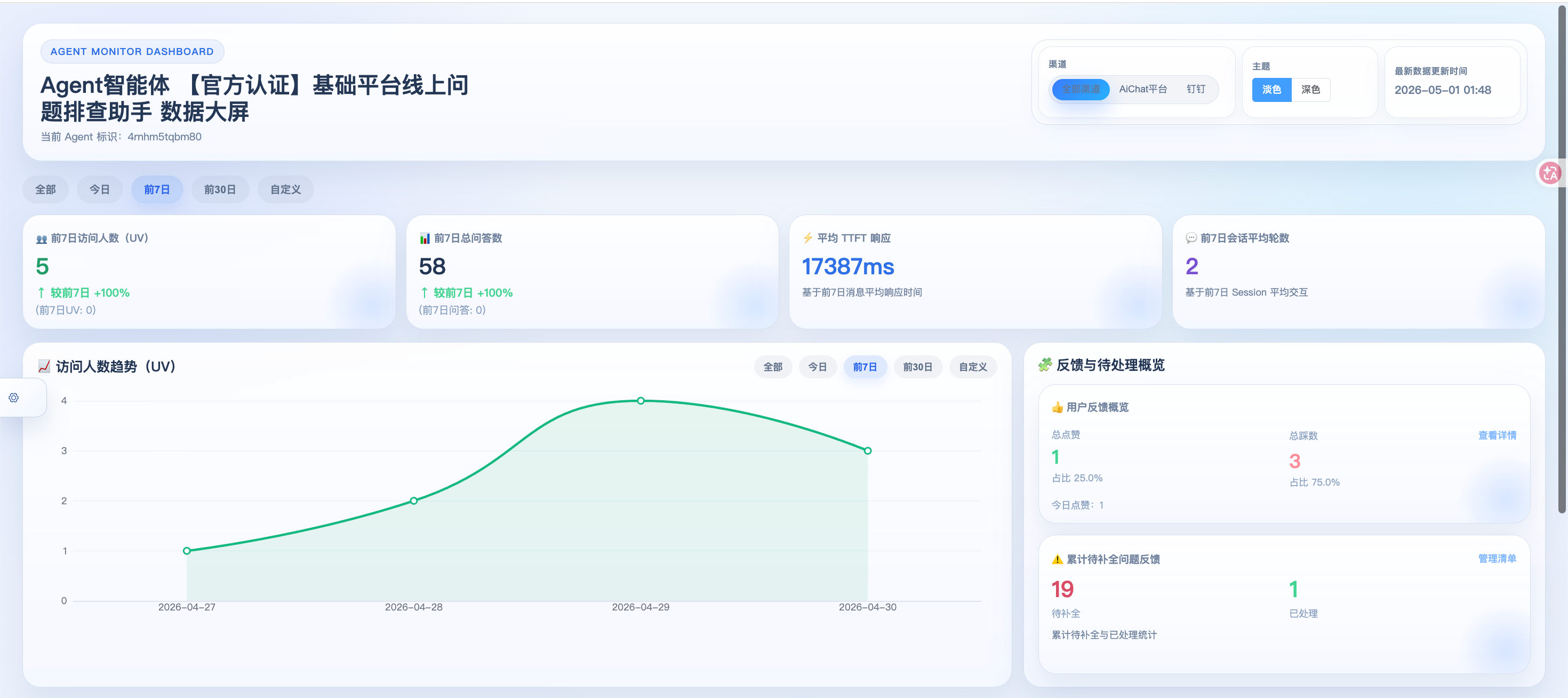
6.1 统计汇总卡片
java
@Override
public StatisticsVo getStatistics(StatisticsReq req) {
StatisticsVo vo = new StatisticsVo();
// UV(访问人数)
vo.setCurrentUv(userMessageMapper.countUv(aid, channelCode, start, end));
// 总问答数
vo.setCurrentTotalCount(userMessageMapper.countTotal(aid, channelCode, start, end));
// 平均TTFT
vo.setAvgTtft(userMessageMapper.avgTtft(aid, channelCode, start, end));
// 会话平均轮数(衡量用户粘性)
vo.setAvgSessionRounds(userMessageMapper.avgSessionRounds(aid, channelCode, start, end));
// 点赞/点踩统计
vo.setTotalLikeCount(userFeedbackMapper.countFeedbackByType(aid, FEEDBACK_TYPE_LIKE));
vo.setTotalDislikeCount(userFeedbackMapper.countFeedbackByType(aid, FEEDBACK_TYPE_DISLIKE));
// 待补全问题数(未处理的归因工单)
vo.setPendingIssueCount(userMessageIssueFocusMapper.countPending(aid));
return vo;
}6.2 分类统计(饼图数据)
java
@Override
public List<CategoryStatisticsVo> getCategoryStatistics(StatisticsReq req) {
List<Map<String, Object>> result =
userMessageCategoryMapper.countByCategory(aid, channelCode, startDate, endDate);
int total = result.stream().mapToInt(m -> ((Number) m.get("count")).intValue()).sum();
return result.stream().map(map -> {
CategoryStatisticsVo vo = new CategoryStatisticsVo();
vo.setCategoryId(((Number) map.get("category_id")).longValue());
vo.setCategoryName(String.valueOf(map.get("category_name")));
vo.setCount(((Number) map.get("count")).intValue());
vo.setPercentage(total > 0 ? vo.getCount() * 100.0 / total : 0.0);
return vo;
}).collect(Collectors.toList());
}6.3 待补全问题清单
这是闭环的关键页面------运营人员在这里处理AI识别出的问题:
java
@Override
public PageResult<List<IssueFocusPageVo>> getIssueFocusPage(IssueFocusPageReq req) {
// 查询待处理/处理中的关注点记录
List<AiAgentUserMessageIssueFocusPojo> pojoList =
userMessageIssueFocusMapper.selectIssueFocusPage(
start, pageSize, aid, List.of(0, 1), // 只查待处理和进行中
req.getIssueId(), startDate, endDate
);
return pojoList.stream().map(pojo -> {
IssueFocusPageVo vo = new IssueFocusPageVo();
vo.setPointName(getIssueName(pojo.getAgentQaIssueId()));
vo.setUserQuestion(truncate(message.getQuestion(), 100));
vo.setSuggestDesc(pojo.getSuggestDesc());
vo.setStatus(pojo.getStatus());
return vo;
}).collect(Collectors.toList());
}
// 运营人员处理后更新状态
public void handleIssueFocus(IssueFocusHandleReq req) {
// status: 1-处理中, 2-已处理, 3-已忽略
userMessageIssueFocusMapper.updateStatus(req.getId(), req.getStatus(), req.getRemark());
}七、总结
回头看最初的问题:Agent上线后如何衡量效果?如何持续优化?
这套监控体系给出的答案是:
- 数据收集层:用中间件无侵入记录多渠道的完整问答过程
- 分析层:让AI分析AI的回答,自动分类和归因
- 展示层:提供可视化大屏,让运营人员一眼看清全局
- 闭环层:把识别出的问题变成可追踪的工单
一个Agent的价值不是上线那一刻决定的,而是由后续不断的数据反馈和持续优化决定的。
这套方案的核心思想可以复用:任何需要"观察-分析-行动"循环的场景,都可以参考这个模式------用异步解耦保证稳定性,用AI分析降低人工成本,用工单流转保证问题不被遗漏。
资料获取
大家点赞、收藏、关注、评论啦~
精彩专栏推荐订阅:在下方专栏👇🏻
- 长路-文章目录汇总(算法、后端Java、前端、运维技术导航):博主所有博客导航索引汇总
- 开源项目Studio-Vue---校园工作室管理系统(含前后台,SpringBoot+Vue):博主个人独立项目,包含详细部署上线视频,已开源
- 学习与生活-专栏:可以了解博主的学习历程
- 算法专栏:算法收录
更多博客与资料可查看👇🏻获取联系方式👇🏻,🍅文末获取开发资源及更多资源博客获取🍅