企业对 GUI 自动化的需求从未像今天这样强烈。从财务系统的批量录单,到 ERP 跨模块的数据流转,再到测试工程师希望用自然语言描述一条端到端的测试用例------驱动这一切的底层诉求是一致的:让机器像人一样操作软件界面,从而释放人的精力。
但"操作界面"这件事,实现路径差异极大。目前业界主要有三条技术路径:RPA 脚本、API/DOM 注入、纯视觉 Agent。三者在适用场景、脆弱点和工程成本上各有侧重,选错路径往往意味着大量的维护债务。
本文从技术原理出发,梳理三条路径的核心机制与边界,希望对正在做技术选型的工程师有所参考。
路径一:RPA 脚本
RPA(Robotic Process Automation)是最成熟的一条路,UiPath、Automation Anywhere、Blue Prism 等商业平台在企业级市场积累了超过十年的落地经验。
工作原理: RPA 通过录制用户操作或手动编写脚本,将 UI 元素的坐标、控件 ID、XPath 等标识符固化下来,在运行时定位并模拟操作。执行引擎与应用进程并行运行,不需要修改目标应用的源代码。
优势在哪里:
- 生态成熟,企业级功能齐全(审计日志、权限管控、异常处理框架)
- 对运维团队友好,可视化流程设计器降低了编写门槛
- SAP、Oracle 等主流 ERP 有专项适配,开箱即用
脆弱点在哪里:
RPA 的阿喀琉斯之踵是元素定位的脆弱性。脚本依赖控件 ID、位置坐标或 XPath 路径,一旦目标应用升级、皮肤更换或分辨率变化,这些标识符就可能全部失效。在版本迭代频繁的 SaaS 应用面前,RPA 脚本的维护成本会随应用变更线性增长。
此外,RPA 天然不擅长处理动态 UI------弹窗顺序随状态变化、元素按条件显隐、拖拽排序等交互逻辑,往往需要大量硬编码分支来兜底,脚本规模和复杂度迅速膨胀。
适合场景: 界面稳定、流程固定、元素标识清晰的传统企业系统(如内网 ERP、OA 审批流)。
路径二:API / DOM 注入
随着 Web 技术成为企业应用的主流栈,基于 DOM 操作和浏览器协议的自动化方案逐渐成为第二条主流路径。Playwright、Selenium、Puppeteer 是这条路的代表工具;在 AI Agent 领域,基于 CDP(Chrome DevTools Protocol)的浏览器 Agent 也属于这一类。
工作原理: 通过调用浏览器的调试接口或直接操作 DOM 树,自动化程序可以以编程方式读取页面结构、触发事件、获取数据,而无需像人眼那样"看"界面。
优势在哪里:
- 执行速度快,不依赖视觉识别,操作精确
- 可访问完整的页面数据结构,适合数据提取和状态验证
- 与 CI/CD 流水线集成成熟,是 Web 测试自动化的事实标准
脆弱点在哪里:
这条路有一个硬约束:只在 Web 应用上有效。一旦目标是桌面软件(Win32、Electron、Qt)、移动端 App 或嵌入式系统界面,DOM 注入就完全失去了抓手。
另一个隐性问题是需要了解应用内部结构。如果目标系统使用了 Shadow DOM、动态 class 命名(如 CSS Modules 生成的哈希类名)或自定义 Web Components,选择器的稳定性会大幅下降,维护难度不亚于 RPA。
在安全沙箱环境中,某些企业应用会主动检测和屏蔽调试协议接入,这也是实际部署时常见的障碍。
适合场景: Web 应用的测试自动化、数据爬取、公开网页的 AI Agent 操作任务。
路径三:纯视觉 Agent
纯视觉 Agent 是三条路径中最年轻的一条,也是近两年 AI 领域关注度增长最快的方向。它的核心思路与 RPA 和 DOM 注入截然不同:完全通过截图来感知界面状态,不依赖任何内部结构信息。
工作原理:
截图 → 视觉理解(元素定位 + 意图理解)→ 动作预测 → 执行 → 截图验证Agent 在每一步操作前获取当前屏幕截图,通过视觉语言模型(VLM)理解界面语义和当前任务状态,预测下一步操作(点击、输入、滚动等),执行后再次截图确认结果。整个循环不需要注入任何钩子,也不需要访问应用的 DOM 或进程。
优势在哪里:
- 通用性最强:Web、桌面(Windows/macOS)、移动端、游戏界面、工控屏,只要能截图,就能操作
- 无需内部知识:不需要了解目标应用的代码结构、API 接口或元素标识
- 天然处理动态 UI:视觉模型每次都重新理解当前截图,界面变化不会导致路径失效
- 接近人类操作模式:便于用自然语言描述任务,降低使用门槛
挑战在哪里:
- 对视觉模型的元素定位精度要求很高------点击坐标偏差 10 像素可能导致操作完全错误
- 推理延迟高于 DOM 注入,实时性要求极高的场景需要专项优化
- 小字、低对比度、复杂重叠 UI 对视觉模型是难题
GUI Grounding 是关键能力
纯视觉 Agent 的核心技术挑战是 GUI Grounding------给定一段自然语言描述(如"点击提交按钮"),模型需要在截图中精确定位目标元素的像素坐标。这项能力的强弱直接决定了 Agent 的可用性。
横向对比
| 维度 | RPA 脚本 | API / DOM 注入 | 纯视觉 Agent |
|---|---|---|---|
| 适用平台 | Web + 桌面(有限) | Web 为主 | Web + 桌面 + 移动端 + 任意 GUI |
| 对应用的依赖 | 元素 ID / 坐标 | DOM 结构 / 调试协议 | 截图(零依赖) |
| UI 变更抗性 | 低 | 中 | 高 |
| 动态 UI 处理 | 弱(需大量分支) | 中(依赖 DOM 稳定性) | 强(每步重新感知) |
| 执行速度 | 快 | 快 | 中(受推理延迟影响) |
| 维护成本 | 高(UI 变更即维护) | 中 | 低(无需维护路径) |
| 部署门槛 | 中(需平台许可证) | 低 | 中(需视觉模型推理资源) |
| 适合任务类型 | 固定流程、稳定系统 | Web 测试、数据提取 | 复杂跨应用、自然语言驱动任务 |
行业方向:视觉路径的泛化优势
三条路径并非互斥,在实际工程中往往组合使用------例如用 Playwright 处理 Web 部分,用视觉 Agent 兜底处理无法 DOM 注入的桌面弹窗。
但从长期技术演进的方向来看,纯视觉路径具备其他两条路径难以复制的泛化优势:
- 平台无关性:随着企业应用向混合架构(SaaS + 本地桌面 + 移动端)演进,单一平台方案的覆盖率天花板越来越明显
- 维护成本曲线:RPA 和 DOM 注入的维护成本与 UI 变更频率正相关;视觉 Agent 的这条曲线基本是平的
- 自然语言接口:LLM 的发展使得"用人话描述任务"成为可能,而视觉 Agent 是最自然的承载形式
当然,视觉路径的成熟度提升依赖于视觉模型能力的持续进步,尤其是在 Grounding 精度和推理效率两个维度。这也是当前研究和工程投入最为密集的方向。
Mano-P:开源视觉 Agent 的一个实现参考
作为明略科技开源的 GUI Agent 项目,Mano-P 采用纯视觉路径(GUI-VLA 架构),实现了 Think-Act-Verify 的三阶段循环:模型在每次操作前显式推理当前状态,操作后截图验证结果,异常时触发回退逻辑。
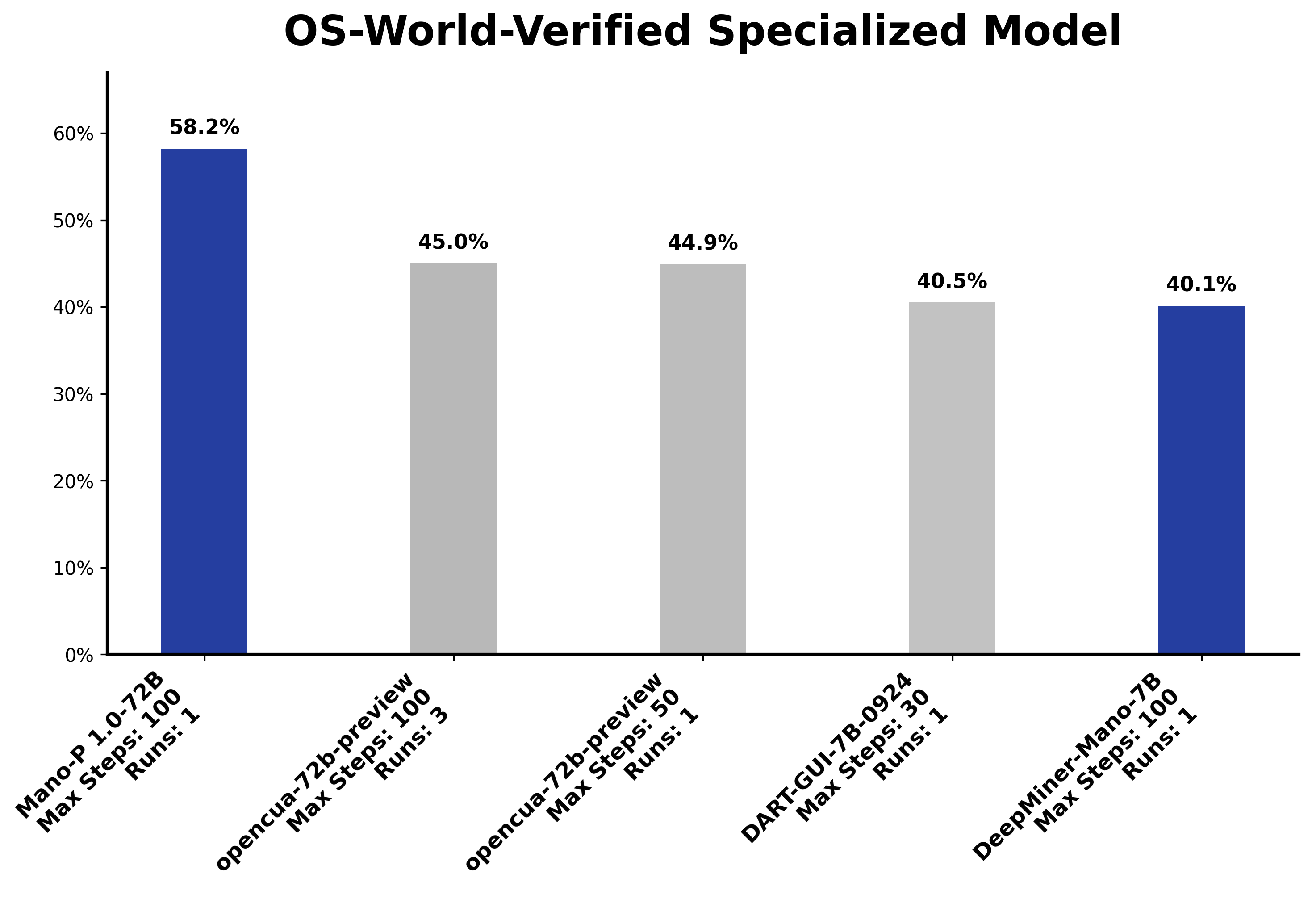
在 OSWorld 基准 (专项模型类别)中,Mano-P 72B 评测版本达到 58.2% 的任务完成率 ,位列榜首。目前面向开发者开源的是 4B 量化版本,专为端侧实际运行优化。
在端侧部署方面,Mano-P 1.0-4B 配合 Cider 推理加速 SDK,在 Apple M5 Pro(64GB)上实测 decode 速度约 80 tok/s (W8A16),启用 W8A8 激活量化后 prefill 加速约 12.7%(数据来源:README Performance Evaluation)。支持在 M4 芯片 + 32GB 内存的 Mac 上完全本地运行,数据不出本机。
对于希望在自己的基础设施上运行 GUI Agent、或希望研究视觉路径技术细节的工程师,Mano-P 提供了一个可直接运行的开源参考实现:
👉 https://github.com/Mininglamp-AI/Mano-P
小结
GUI 自动化的三条路径各有其设计哲学:RPA 用元素标识锁定操作,API 注入用程序接口绕过界面,纯视觉 Agent 用感知代替依赖。没有哪条路径适合所有场景,技术选型的关键是理解目标系统的特点、任务的稳定性要求和团队的维护能力。
随着视觉模型在 Grounding 精度和推理效率上的持续提升,纯视觉路径在跨平台、动态 UI、自然语言驱动场景下的优势将越来越明显。这个方向值得持续关注。