文章简介
Disruptor文章全称是《Disruptor: High performance alternative to bounded queues for exchanging data between concurrent threads》。
作者为Martin Thompson、Dave Farley、Michael Barker、Patricia Gee、Andrew Stewart。
主要解决了在高并发系统中,传统队列因"锁竞争"和"伪共享"导致的性能瓶颈问题。
作者简介
LMAX Group是一家全球金融科技公司,专注于外汇和数字资产交易。
在金融交易领域,对于系统的延迟要求很高,而当时现有的系统无法满足他们的需求,所以有了Disruptor。
借此,LMAX在2011年获得了Oracle颁发的杜克奖(Duke's Choice Award)。
Martin Thompson,除Disruptor,还有Aeron和SBE等项目。
著名想法有"Mechanical Sympathy",即软件开发者只有了解硬件的工作模式时,软件性能才能达到极致。
Dave Farley,与Jez Humble合著《Continuous Delivery(持续交付)》一书。
Michael Barker,关注并发中的性能挑战。
离开离开LMAX后,他继续与Martin Thompson合作,参与了高性能网络传输项目Aeron。
Patricia Gee,资料较少。
有一位Trisha Gee,有过一系列介绍Disruptor的博客和演讲,曾在JetBrains担任核心技术职位,但不知是否是同一个人。
与Andrew Stewart,资料较少。
并发性能分析:写竞争是性能杀手
并发不仅意味着多个任务同时进行,为了安全修改数据,这更意味着对资源访问权的争夺。
从数据安全的角度考虑需要:
- 任何一个时间只能有一个线程修改数据
- 修改后的结果要同步到其他所有线程
而不同的并发手段,都有它们各自的代价。
锁竞争的成本
使用锁时,竞争的成本在于改变线程时的上下文切换,以及缓存失效。
CAS的成本
CAS(Compare And Swap,比较并交换),是一种乐观锁,它不假设冲突,而是直接尝试更新,直到成功。
它需要一个内存地址M、一个预期旧值A,和一个新值B。
当它访问内存地址M时,如果M上的值为A,那么就把它修改为B;如果M上的值不为A,说明这个地址已经被其他线程改过了,表示操作失败,那就啥也不干。
循环往复。
CAS比锁高效,因为它完全在用户态执行,是一条CPU原子指令,不需要切换线程。
而CAS的代价在于:
- CAS是CPU指令级锁,会导致CPU缓存行锁定
- 需要采用内存屏障使结果对其他CPU立刻可见
从实现上来说,使用CAS来实现lock-free算法比较复杂,尤其是要原子化地修改多个变量,逻辑容易出错。
CAS经典的ABA问题:当某个内存地址M上的值从A变为B,再变回A,CAS操作可能认为这个值没变过,从而更新它。但这次更新是不符合预期的,可能带来问题。
内存屏障
当某些指令的结果需要等待时,如果按照程序的原始顺序严格执行指令,CPU中的某些功能单元会因为等待而浪费性能。
而为了更有效地利用这些等待空闲的单元,CPU会同时执行彼此不依赖的指令,以减少等待时间和提升效率。
所以出于性能原因,现代CPU只保证结果符合预期,而不保证其中的指令一定按照开发者设定的顺序访问内存。
这对单线程程序不是问题,但对于多线程时,这种乱序访问容易带来逻辑上的错误。
与此同时,现代CPU由于性能上远高于现有的内存系统。
这导致了大量缓存系统被设计出来弥补速度差距,所以这意味着任何值在写入后的任何阶段都可能存在于寄存器、各种缓存,或主存任一位置。
而内存屏障就是保证指令按照顺序访问内存的手段。
Disruptor文章里列了三种内存屏障:
- 读屏障:确保当前线程读取到的是最新的、被其他线程更新的数据
- 写屏障:确保在当前线程写入操作完成之前,其他线程无法对该资源进行读取或修改
- 全屏障:防止读写操作前后重排,确保读写顺序没问题
缓存行
用好CPU缓存,是提升性能的关键。
CPU通常不是以字或字节形式来操作内存,而是以缓存行形式操作。
缓存行的大小通常为32-256字节,最常见的是64字节。
缓存一致性是以缓存行为单位的。
这也就意味着,如果两个不同线程的变量共享一个缓存行,哪怕它们在不同线程、是不同变量,看起来应该是毫无关系的,但因为它们在一个缓存行上,也会出现写竞争问题。
这就是"伪共享"。
所以为了最小化争用,防止"伪共享",确保本应独立的并发变量写入不同的缓存行至关重要。
同时,CPU并非被动地从内存读取数据,而是会预测下一步最有可能访问的内存,并将其预先导入缓存。
这只有在内存地址是规律变换,且距离小于2048字节的时候才生效。
例如访问地址100,然后是108,再是116,那么它就会识别出"步长为8"的规律,下一步就会把124、132等处的数据提前加载进缓存。
而2048字节的限制,往往来源于页内存限制和跨度限制,如果跨度太大,可能就不被认为是"有规律"的取址。
从这方面来看,数组性能会好一点,因为它是可预测的;而像链表、树这些在逻辑上是有序的,而在内存中往往是碎片化存放的数据结构,就会慢一点。
它们之间的性能差距往往能达到100倍左右。
队列问题
队列通常使用数组或链表实现。
无界队列虽然写法简单,但一旦生产者超过消费者,占用的内存就会一直增长,直到内存耗尽。
而有界队列通常通过数组实现,需要手动维护大小。
它有头head、尾tail、大小size等几个变量,这些变量哪怕是通过不同的并发对象(锁或CAS等)隔离,但往往也会被分配到同一个缓存行。
这就导致了,因"伪共享"而造成的"写竞争"问题。
尤其是在队列状态接近满或接近空的极限状态下,这个问题越发明显。
而为了处理这个问题,如果使用大粒度的锁,虽然易于实现,但是吞吐量极差,与"串行"没啥区别。
否则,除了单生产者单消费者(SPSC)的情况下,实现就会变得很复杂。
同时,如果频繁为队列分配内存对象并回收,会造成很大的GC压力。
流水线与图
在系统中,如果有多个处理阶段,可以将每个处理阶段串联起来,形成流水线。
这些流水线中可能会有并行阶段,并被组织成类似图的拓扑结构。
每个阶段都有自己的线程,并且每个阶段之间通过队列相连。
但由于每个阶段都需要以队列连接,那么入队/出队、以及每个阶段开始/结束时多个线程试图读取/写入同一个队列的竞争,都是不小的开销。
最好的办法就是,找到一个既能满足这种依赖关系的处理方法,又能够避免这种开销。
总结
在上述整个分析中,先是从实现角度指出了锁、CAS、内存屏障和缓存行所存在的局限性,然后将其映射到宏观的数据结构中,指出传统队列在并发环境下因锁、伪共享等而存在的写竞争瓶颈。
所以整个Disruptor的思路在于,不是用更高级的锁来提升性能,而是尽量避免写竞争。
并且它认为最理想的情况是,只有一个线程负责对单个资源的所有写入,其他线程读取结果。
Disruptor设计:避免写竞争
解决上述问题的办法是,确保任何数据有且仅有一个线程拥有写访问权限,从而避免写竞争。
Disruptor机制的核心是创造一个预分配的环形缓冲区(RingBuffer),即一种有界的数据结构。
数据通过一个或多个生产者添加到环形缓冲区中,并由一个或多个消费者进行处理。
内存分配
Disruptor实现一个预分配的RingBuffer,这个环形缓冲区就像一个预先划分好房间(Entry)的仓库,每个房间都可以存储货物,这些货物就是进出RingBuffer的数据。
这些数据既可以是指针,也可以是具体的数据类型/结构体。
当数据被写入Entry时,就好像货物被存放进仓库中的房间;当数据被擦除时,就好像货物被搬出仓库的房间。
在这个过程中,Entry并不随着数据的写入而创造,也并不随着数据的擦除而被删除。
从逻辑上说,Entry(一般被翻译成条目)是存放数据的一个容器,可以复用;从物理层面来说,它是内存中的一个连续且固定的槽位(Slot)。
由于这些条目可以重复使用,且与Disruptor的实例存续周期一致,所以避免了频繁GC的问题。
而同时,由于,这些条目所占用的内存是同时分配的,因此它们极有可能在主内存中连续布局,从而支持跨步缓存。
Java GC与高并发的恶性循环
Java垃圾回收有一种分代收集算法,一般情况下根据对象生命周期分为老年代和新生代,新生代的GC频率高,回收快;当新生代经历过多次GC仍旧存活之后,就会被移入老年代,老年代的特征是GC频率低,回收慢。
当新生代变为老年代时,会在内存中实打实地进行数据拷贝。
所以,当进入高负载状态时,本来应该很快处理并被回收的"新生代"数据,可能会一直排队等待处理,然后GC在扫描好几次后,发现这些数据仍旧存在,就会将它们移入"老年代"。
而变成老年代后,不论是变化时的数据拷贝还是之后更大的回收开销,都会让性能肉眼可见地变慢,甚至在大内存堆中,这种停顿可能达到每 GB 数秒之久。
分离关注点
LMAX团队发现,许多队列的实现之所以慢,是因为它们将许多本应被独立处理的问题混为一谈。
这些问题分别为为:
- 存储被交换的数据
- 协调生产者获取下一个可被写入的位置
- 协调消费者让其在新数据到来时被通知
存储:使用基于数组的队列
在使用GC的语言中,过多的内存分配会导致问题,所以基于链表的队列并不是一个好选择。
而如果能一次性为上述RingBuffer分配一块连续的内存,那么CPU缓存的命中率会很高。
从这个角度来看,一个预先分配所有内存槽位(Slot)的数组,是最合适的数据结构。
在创建时,Disruptor通过抽象工厂模式,在RingBuffer上预先创建一个数组,当生产者拿到一个序号(sequence)时,就可以把数据写入对应的数组槽位。
抽象工厂模式
抽象工厂模式是一种创建型模式,创建型模式在于解耦对象的创建与使用。
抽象工厂提供接口,用于创建一系列相关对象,而无需指定它们具体的类。
抽象工厂一共有四个组成角色:
- 抽象工厂:声明创建产品的方法,可以是接口或抽象类
- 抽象产品:定义产品的标准或功能,可以是接口或抽象类
- 具体工厂:实现抽象工厂接口,具体创建产品
- 具体产品:实现抽象产品接口,具体定义产品的属性和功能行为
假如现有一个快餐店接口(抽象工厂),规定了只要是快餐店都可以提供汉堡(抽象产品)和饮料(抽象产品)。
那么实在的快餐店,例如肯某基和麦某劳就是实现了快餐店接口的具体工厂。前者提供板烧堡和可乐,后者提供鸡腿堡和橙汁。
而汉堡和饮料就是两个抽象产品,前者提供了吃(eat)这个功能,后者提供了喝(drink)这个功能。
抽象工厂模式可以防止你走进麦某劳却点了一个肯某基才会生产的鸡腿堡(产品族不匹配)。
运算:取模性能优化
由于队列使用了RingBuffer,而序列号(sequence)是不断递增的,所以为了找到这个序号在数组中对应的下标,就要用sequence % ringSize来求对应结果,ringSize指的是RingBuffer的总容量。
然而,取模运算实际上是除法,本质是a % b = a - (a / b) * b,而除法根据不同复杂度,大概需要10-90个时钟周期不等,而加减乘法一般都在5个时钟周期以内。
所以,常规的取模运算是很慢的一个操作。
而在这里,强制将RingBuffer的大小设置为bufferSize = 2^n,实际上是为了将取模运算转化成位运算sequence & (bufferSize - 1),这里的&是按位与。
假设环形缓冲区大小为8,即bufferSize = 2^3,那么,bufferSize - 1为7,二进制为00000111。
当用任何数字与00000111进行&运算时,只会留下最后三位的值,效果等同于取模运算。
而位运算速度很快,在CPU硬件电路中几乎是瞬间完成的,所以从这个角度来讲大大优化了性能。
协调生产者
一般有界队列的头和尾会产生严重竞争,而Disruptor为了避免这些问题,它把角色拆分了,通过生产者和消费者来管理不同功能的并发访问。
单生产者是Disruptor经常遇到的情况,例如文件读取、网络监听。在这种情况下,没有竞争,可以直接分配sequence。
多生产者是少见但特殊的情况,多个生产者会竞争RingBuffer中的一个序列,这时可以通过CAS来抢占sequence,从而预定槽位。
当生产者抢到序列号sequence之后,就会往对应槽位slot中写入数据,写入完成后就可以提交序列号,使该数据可以被消费者使用。
然而,提交序列号之前,需要先确认在自己之前的所有序列号都已经写入完数据,才能推进游标(cursor)来使消费者对数据可见。
例如现在有两个线程,线程1占据sequence = 10的槽位来写数据,线程2占据sequence = 11,此时游标cursor = 9。当线程2写完时,线程1还在写入当中,线程2就得通过自旋(无需CAS)等待线程1写完,才能使cursor = 11,这样,消费者才能真正读取sequence = 11这个槽位的数据。
所以,cursor的值,表示消费者可以读到哪里。
因为,如果在序号为11的的槽位更新完数据,而序号为10的槽位没更新完数据的时候,直接把游标的值更新到11,就很有可能会让消费者读到10槽位中没有被更新好的脏数据。
然而,RingBuffer是个环形缓冲区,它的大小是固定的。如果生产者写得比消费者快,就会导致生产者会在环形槽位中反向追上消费者的进度(套圈),从而覆盖还未被消费者处理的数据。
cursor只能防止消费者读到脏数据,不能保证解决"套圈"问题。
Disruptor解决的办法是,nextSequence - minConsumerSequence < bufferSize,nextSequence是即将写入的生产者序号,bufferSize是环形缓冲区大小,minConsumerSequence是当前最慢的消费者序号。
只有当生产者和消费者的实际距离小于环形缓冲区大小时,才能保证还没有被消费者读取的数据不被新的生产者覆盖。
例如当前最慢的消费者序号为2,最快生产者序号为10,环形缓冲区大小为8,而10 - 2 = 8,不满足上面的条件,所以这个生产者暂时无法写入,除非消费者序号增加。
协调消费者
在生产者还没把数据放入队列时,消费者必须等待,这期间有多种等待策略。
如果CPU资源比较珍贵,那么可以使用锁和条件变量,但需要生产者在数据准备就绪时唤醒消费者。
这么做的优点是省CPU,但是缺点也同样明显,就是会带来竞争。
另外,消费者也可以选择,不断地循环检查cursor的值。
由于消费者一直关心值的变化,所以优点是延迟极低,无锁;但缺点就是自旋操作容易吃满CPU。
同时,消费者也可以选择上述两种折中的策略,即在不断的循环检查中,适当地让出线程,一般是Thread.yield()之类的。
但不论如何,Disruptor并不强制消费者使用哪种策略,也不是一般的"折中"建议。它的机制和策略是可以分离的,所以可以在不同的使用场景下,按需选出最合适的策略。
另外,每个消费者都单独维护自己的sequence,这样,生产者在需要知道消费进度的时候,就可以直接读取每个消费者自己维护的序列号。
这个sequence与上面生产者使用CAS竞争的sequence是不同的对象。
前者是每个消费者线程自己单独维护的,用于记录当前消费者正在处理哪个位置的数据;而后者是需要生产者竞争的全局sequence,通常由RingBuffer持有。
而与传统的有锁队列相比,Disruptor的生产者和消费者并不共享锁,而通过一个变量cursor来共享状态,所以避免了锁竞争。
而对传统的无锁队列来说,多个生产者之间和多个消费者之间也会存在CAS竞争,而在Disruptor中,生产者只在抢全局sequence时存在CAS;而消费者中不存在CAS,因为它们只读取消费到的槽位的全局sequence,并将它同步到自己的sequence值,这样当生产者要判断是否"套圈"时,也可以读取sequence来进行操作,从而避免竞争。
序列号
序列是Disruptor并发控制的核心概念。
当生产者和消费者在环形缓冲区交互时,都依赖sequence来协调。
当生产者要写入数据时,它会申请(claim)下一个序列号(sequence),这个序列号对应环形缓冲区中的一个槽位(slot)。
在单生产者情况下,这个序号可以只用一个简单的计数器实现;在多生产者情况下,可以用CAS来保证并发安全。
一旦某个序号被生产者占用成功,那么它所代表的槽位就只归它写入,其他生产者线程不能碰。
直到这个生产者写入成功后,会更新某个独立计数器/游标(cursor)来提交更改,游标表示当前可以被消费者读取的最大序列。
生产是使用内存屏障以自旋形式来更新cursor,这个过程中没有用到CAS。
java
// 来自原文
long expectedSequence = claimedSequence - 1;
while (cursor != expectedSequence)
{
// busy spin
}
cursor = claimedSequence;而消费者也会通过内存屏障读取cursor,一旦游标更新,内容对于消费者就是可见的。
同时,每个消费者都会维护它们自己单独的sequence,来表明自己当前读取的数据来自于哪个序号。
这样既能防止生产者写入过快,以至于覆盖消费者未写入的数据,同时也可以控制消费者的处理顺序。
另外,消费者并不是通过序列号去"取走"数据,而是"读取"数据,消费者读取完后,环形缓冲区中存储的数据并不会被移除,而只会随着游标更新被覆盖。
所以从这个角度看,Disruptor是支持多个消费者同时访问同一个数据的。 就好像生产者写到sequence = 100的位置,消费者A读到sequence = 60,消费者B读到sequence = 95,那么理论上sequence 60~100都还可以被读取,因为数据有效。
由于之前一直和队列比,因为队列的数据先进先出,取出就没了,所以我总是下意识地觉得Disruptor中一个数据也只要一个消费者处理一次。但是从后面来看,Disruptor支持的是事件驱动而非任务分发,从这个角度看,Disruptor支持多个消费者同时访问同一个数据的设计好像也不奇怪。
而在单生产者的情况下,无论消费者处理方式多么复杂,都不需要锁或者CAS。
批处理效应
当消费者在等待游标更新的过程中发现,cursor一次性前进了好几个位置,那么它就可以直接处理直到该序列为止的所有数据,而无需再介入任何并发控制机制。
就好像cursor = 50突然更新到cursor = 100,那么消费者就可以一次性把51-100的这些数据一次性按顺序处理掉。
这种批处理行为,可以在生产者突然爆发提速时,让消费者速度快速跟上,从而使系统重新达到平衡。 同时在提高吞吐量的同时,降低并且平滑了延迟。
根据Disruptor团队观察,这种延迟使得内存子系统在达到饱和之前,无论如何增加负载,使得延迟都几乎保持恒定。一旦内存子系统饱和,延迟曲线将按照利特尔法则(Little's Law)呈线性增长。
这与在传统队列中观察到的"J"型曲线截然不同,在传统队列中延迟随着负载增加急剧上升。
利特尔法则(Little's Law)和"J"型曲线
核心公式 :L=λ×W
在并发系统中,L指的是并发数,λ指的是吞吐量,W指的是延迟。
上述公式可以变形为: W=L/λ
在实际过程中,L并不是线性增长的。
当系统负载增加时,低负载阶段,请求来了就处理,所以L很小;当接近拐点时,处理请求的速度到达临界点,于是开始排队,L数量上升;当并发数远超过系统处理能力时,L会陡升。
"J"型曲线的本质是系统前期延迟变化很小,到某个临界点后迅速恶化。
依赖图
队列表示的是单生产者和单消费者之间的单步管道依赖关系。
如果生产者和消费者之间构成了复杂的链式或者图结构的依赖关系,那么在这个图的每一个阶段之间都需要通过队列来连接。
这些队列会带来固定的开销。
根据该团队在设计LMAX交易软件的结果的分析,如果采用基于队列的方式,那么上述队列的固定开销会占据一次交易的主要成本。
而在Disruptor的设计中,由于生产者和消费者是解耦的,所以可以在仅使用一个环形缓冲区的情况下,表示消费者之间复杂的依赖关系图。
这大大减少了固定成本,提高吞吐量并降低了延迟。
一个单一的RingBuffer由于可以存储具有复杂结构的条目(Entry),从而可以在一个统一的位置表示工作流。
然而,在设计这种Entry的结构时,要确保避免不同生产者/消费者改变状态时不会导致"伪共享"问题。
Disruptor类图
Disruptor框架中的核心关系如下图(图来自原文)所示:
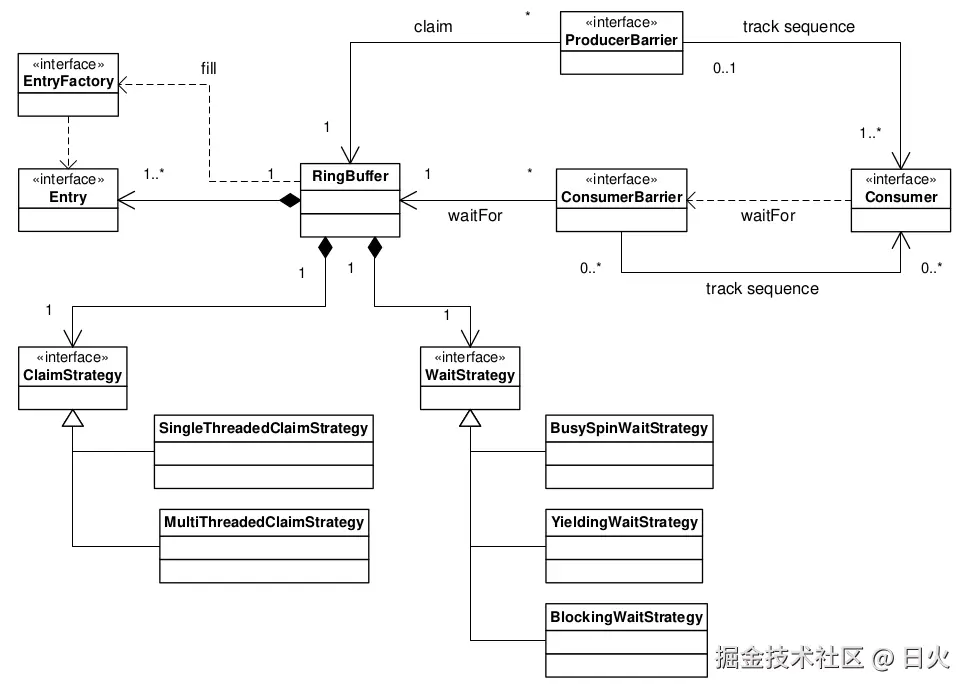
依赖图构建完成后,编程模型变得简单。
生产者(Producer)通过ProducerBarrier按顺序申请(claim)一个条目(Entry),然后将更改写入到申请到的位置,随后通过ProducerBarrier提交,使其对消费者可见。
而对于消费者来说,只需要提供一个BatchHandler实现,当有新的数据可用时,就会收到回调通知。 这种基于事件驱动的编程模型与Acotr模型有很多相似之处。
通过将传统队列中职责拆分,以实现更灵活的设计。
RingBuffer是Disruptor的核心。它用于存储,并实现无竞争的数据交换。
并发控制被拆分,分别由生产者和消费者处理。
ProducerBarrier处理与申请环形缓冲区槽位相关的并发问题,并追踪消费者进度防止未处理的数据被覆盖。
ConsumerBarrier在有新数据可用时通知消费者,同时支持多个消费者组织成一个依赖图,形成多阶段处理流程。
事件驱动架构
事件驱动架构(EDA),系统之间不直接互相调用,而是通过"事件"来通信。
事件代表状态的变更。
一般EDA有三个典型角色:
- 事件生产者(Producer):用于产生事件
- 事件通道(Broker):用于传输事件
- 事件消费者(Comsumer):用于订阅并处理事件
例如生产者A发布事件1后,消费者BCD都可同步接收到事件1并各自处理。
生产者A在发布事件后,并不需要关心有多少个消费者以及它们如何处理。
消费者BCD之间彼此是互相解耦且可以是异步的,并且消费者的数量可以是不固定的,还可以有消费者E和消费者F。
事件驱动的好处在于,可以通过解耦来实现系统中组件的独立扩展,并且防止因为某一个组件的崩溃而影响其他组件;同时有利于敏捷开发等。
Actor模型Actor模型是一种并发模型。
Actor是系统中的基础对象,每个Actor都包含了计算、存储、通信等能力,一个系统里有多个Actor。
不同的Actor之间不共享数据,而是通过异步消息通信来获取或改变其他Actor的状态。
代码示例
下面的代码使用了单生产者(Single Producer)和单消费者(Single Consumer)模式,并利用 BatchHandler 接口来实现消费者。
消费者运行在一个独立的线程上,当Entry变为可用状态时,消费者即可接收并处理它们。
java
// 代码来自原文
// Callback handler which can be implemented by consumers
final BatchHandler<ValueEntry> batchHandler = new BatchHandler<ValueEntry>() {
@Override
public void onAvailable(final ValueEntry entry) throws Exception {
// process a new entry as it becomes available.
}
@Override
public void onEndOfBatch() throws Exception {
// useful for flushing results to an IO device if necessary.
}
@Override
public void onCompletion() {
// do any necessary clean up before shutdown
}
};
RingBuffer<ValueEntry> ringBuffer = new RingBuffer<ValueEntry>(
ValueEntry.ENTRY_FACTORY,
SIZE,
ClaimStrategy.Option.SINGLE_THREADED,
WaitStrategy.Option.YIELDING
);
ConsumerBarrier<ValueEntry> consumerBarrier = ringBuffer.createConsumerBarrier();
BatchConsumer<ValueEntry> batchConsumer =
new BatchConsumer<ValueEntry>(consumerBarrier, batchHandler);
ProducerBarrier<ValueEntry> producerBarrier =
ringBuffer.createProducerBarrier(batchConsumer);
// Each consumer can run on a separate thread
EXECUTOR.submit(batchConsumer);
// Producers claim entries in sequence
ValueEntry entry = producerBarrier.nextEntry();
// copy data into the entry container
// make the entry available to consumers
producerBarrier.commit(entry);吞吐量性测试
对比基准
该团队选择了Doug Lea编写的java.util.concurrent.ArrayBlockingQueue,作为对比基准。
理由是,根据他们测试,它是目前性能最好的有界队列。
测试采用阻塞式编程模型,与Disruptor保持一致。
测试环境要求:系统至少支持4线程并行执行
详细的测试用例可在Disruptor开源项目中获取。
测试模型
测试模型一共有五种:P代表生产者,C代表消费者
-
单播(Unicast):1生产者-1消费者
graph LR P1--> C1 -
三段流水线(Three Step Pipeline):1生产者-3消费者(串行)
graph LR P1--> C1 C1--> C2 C2--> C3 -
序列竞争(Sequencer):3生产者-1消费者
graph LR P1--> C1 P2--> C1 P3--> C1 -
广播(Multicast):1生产者-3消费者(并行)
graph LR P1--> C1 P1--> C2 P1--> C3 -
菱形拓扑(Diamond):1生产者-3消费者(先并行,后汇总)
graph LR P1--> C1 P1--> C2 C1--> C3 C2--> C3
在上述测试中,ArrayBlockingQueue部署在每个数据流的每个连接点(弧边)上,而Disruptor则使用屏障(Barrier)配置。
早期硬件测试结果
运行时环境为Java 1.6.0_25,64位Sun JVM。
操作系统分别为Windows7和Ubuntu 11.04,用于排除不同操作系统调度差异。
Windows系统的CPU为Intel Core i7 860 @ 2.8 GHz,架构为Nehalem。虽然是4核8线程,但是这里关闭了超线程(无HT),用以排除虚拟线程带来的干扰。
Ubuntu系统的CPU为Intel Core i7-2720QM,架构为Sandy Bridge。
每次测试将会处理5亿条消息,对于结果,将会取运行三次中的最佳值。
结果如下(数据来自原文):数据为吞吐量对比(每秒操作数)
| 测试模型 | Nehalem 2.8GHz Win7 SP1 64-bit (ABQ) | Nehalem 2.8GHz Win7 SP1 64-bit (Disruptor) | Sandy Bridge 2.2GHz Linux 2.6.38 64-bit (ABQ) | Sandy Bridge 2.2GHz Linux 2.6.38 64-bit (Disruptor) |
|---|---|---|---|---|
| Unicast: 1P -- 1C | 5,339,256 | 25,998,336 | 4,057,453 | 22,381,378 |
| Pipeline: 1P -- 3C | 2,128,918 | 16,806,157 | 2,006,903 | 15,857,913 |
| Sequencer: 3P -- 1C | 5,539,531 | 13,403,268 | 2,056,118 | 14,540,519 |
| Multicast: 1P -- 3C | 1,077,384 | 9,377,871 | 260,733 | 10,860,121 |
| Diamond: 1P -- 3C | 2,113,941 | 16,143,613 | 2,082,725 | 15,295,197 |
从表格上不难看出,对比ABQ,Disruptor的性能在不同情境下均提升。
尤其是在一个生产者多个消费者的情境下,性能大多提升七八倍,在Sandy Bridge/Multicast的情况下,甚至还提升了几十倍。
这可能是规避了队列开销以及允许多个消费者同时访问数据带来的提升。
不过在多生产者一个消费者的情况下,对比Windows和Ubuntu总体来说提升得没有其他情景大,可能是因为多生产者写入时会对序列号产生竞争导致的。
现代硬件测试结果
Java环境为OpenJDK 11.0.24,操作系统为Linux 5.4.277,CPU为AMD EPYC 9374F。
结果如下(数据来自原文):数据为吞吐量对比(每秒操作数)
| 测试模型 | ABQ | Disruptor 3 | Disruptor 4 |
|---|---|---|---|
| Unicast: 1P -- 1C | 20,895,148 | 134,553,283 | 160,359,204 |
| Pipeline: 1P -- 3C | 5,216,647 | 76,068,766 | 101,317,122 |
| Sequencer: 3P -- 1C | 18,791,340 | 16,010,759 | 29,726,516 |
| Multicast: 1P -- 3C | 2,355,379 | 68,157,033 | 70,018,204 |
| Diamond: 1P -- 3C | 3,433,665 | 61,229,488 | 63,123,343 |
延迟性能测试
为了测量延迟,Disruptor团队采用了一个三阶段流水线,并以低于系统饱和的速率生成事件。
"低于饱和速率"本质上是刻意不给系统压力,避免数据堆积之类的情况影响测试结果。
具体做法是,每注入一个事件1微秒后,再注入下一个事件,如此重复5000万次。
为了在这种精度水平下进行计时,需要用到CPU的时间戳计时器(TSC, Time Stamp Counter)。
因此,可以选择具有不变时间戳计时器(Invariant TSC)的CPU。因为旧款处理器会因为节能和休眠状态导致频率变化,从而影响计时准确性。
而Intel Nehalem及之后的处理器都支持invariant TSC,并且可以在运行于Oracle JVM(Ubuntu 11.04)上访问,所以可以用于测试。
本次测试环境如下:
- CPU:2.2GHz Core i7-2720QM
- Java:1.6.0_25(64位)
- 系统:Ubuntu 11.04
并且在此次测试中并未进行CPU绑定。
同时为了对比结果,仍旧采用了ArrayBlockingQueue(ABQ)来进行测试。
虽然使用ConcurrentLinkedQueue可能会获得更好的结果,但为了引入背压(Back Pressure),防止生产者跑得比消费者快,所以还是使用有界队列来实现。
ConcurrentLinkedQueue是Java并发包(java.util.concurrent)中提供的一个高性能、无界、线程安全的队列。
结果如下(数据来自原文):
| 延迟指标 | Array Blocking Queue (ns) | Disruptor (ns) |
|---|---|---|
| 最小延迟 | 145 | 29 |
| 平均延迟 | 32,757 | 52 |
| P99延迟 | 2,097,152 | 128 |
| P99.99延迟 | 4,194,304 | 8,192 |
| 最大延迟 | 5,069,086 | 175,567 |
结果显示,Disruptor的每一跳平均延迟仅为52ns,而ABQ则高达32,757ns。
经分析,后者的延迟主要来自于锁和基于条件变量的信号机制(Condition Variable)。
CPU绑定(CPU Affinity)
限制某个进程或线程只能在指定的CPU核心上运行,不会再被操作系统调度到其他核上去。
CPU绑定可以提高缓存命中率,减少调度开销,同时也对时间敏感的程序友好。
时间戳计时器TSCTSC是x86/x86_64架构处理器内部的一个64位硬件计数器,虽然其他CPU架构有类似的功能,但是这个术语是x86专属。
TSC从某个起点开始(一般是开机),没经过一个CPU时钟周期,计数就+1。
Disruptor测试用固定频率的TSC,主要是为了计数稳定,从而使结果准确。
P99和P99.99P99延迟是衡量系统性能的指标,代表99%的请求响应时间都小于或等于该数值,仅有1%的请求延迟高于它。
同理,P99.99表示99.99%的请求响应时间都小于或等于该数值。
背压是当系统处理不过来时,避免被数据流压垮的一种机制。
总结
Disruptor优化了吞吐量、延迟,以及延迟稳定性。
它通过环形缓冲区(RingBuffer)一次性分配内存,减少了后续反复创建删除对象带来的开销。
同时,它着手于现代处理器缓存机制,采用填充缓存行的策略来防止存在的"伪共享"问题,优化性能。
而在这个过程中,它实现了关注点分离,生产者关注生产者该干的事,消费者关注消费者该干的事,将对数据的控制从队列这个数据结构中分离开,并通过序列号(Sequence)来协调这一个流程。
从而避免写竞争(单写多读),最小化读竞争,减少或者避免了锁竞争带来的开销。
但如果有多个生产者,还是会不可避免地涉及到CAS。
同时,批处理效应允许消费者在给定阈值内批量处理数据且无争用,为高性能系统引入了一个新特性。
这让负载增加时,Disruptor的延迟可以保持稳定,直到内存子系统饱和,而非传统的"J"型延迟增长曲线。