https://www.doubao.com/thread/ae3ef0ca0a28a
本文面向希望转型AI全栈的开发者,系统梳理AI时代全栈工程师的前后端知识框架,从宏观架构到微观实现,结合企业级RAG智能问答系统完成全链路拆解,附带可直接落地的架构设计与工程规范。
前言
AI时代的全栈工程师,早已不是「前端切图+后端CRUD」的简单叠加,而是具备全链路技术视野、能独立完成AI产品从需求设计到落地部署、兼顾用户体验与AI能力落地、把控工程质量与成本管控的复合型技术人才。
本文将先从宏观层面理清AI全栈的整体技术架构,再分别拆解前端、后端的核心知识体系,最终通过一个企业级AI项目完成全流程、全模块的深度拆解,帮助读者建立完整的AI全栈知识地图。
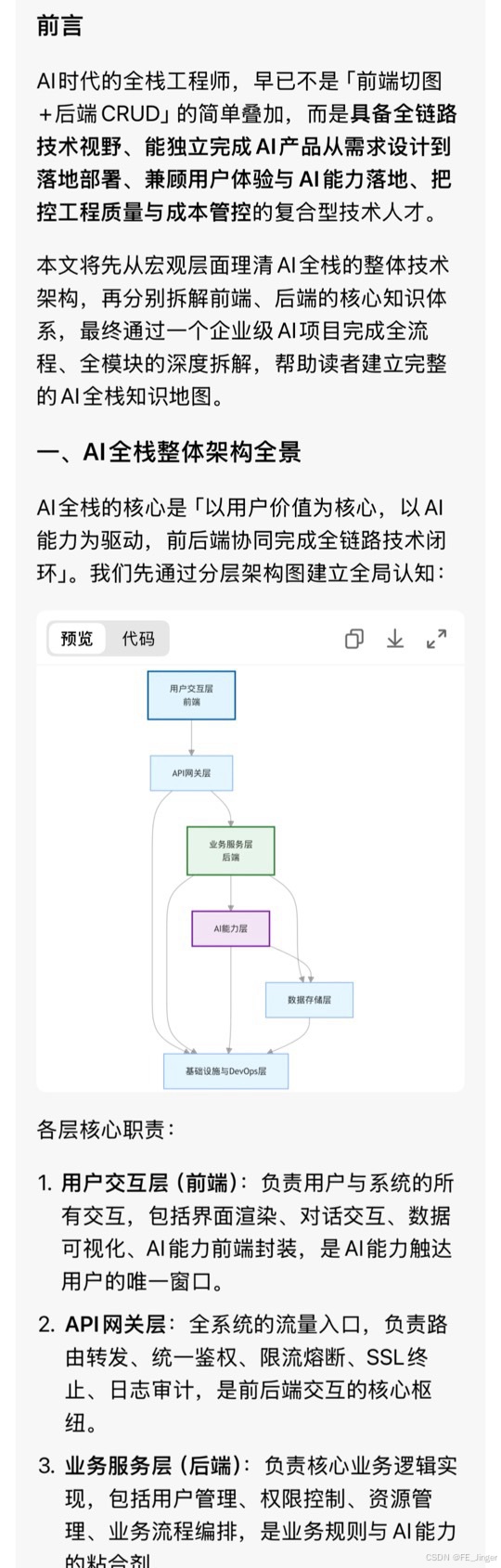
一、AI全栈整体架构全景
AI全栈的核心是「以用户价值为核心,以AI能力为驱动,前后端协同完成全链路技术闭环」。我们先通过分层架构图建立全局认知:
flowchart TB
A[用户交互层
前端] --> BAPI网关层
B --> C[业务服务层
后端]
C --> DAI能力层
C & D --> E数据存储层
B & C & D & E --> F基础设施与DevOps层
style A fill:#e1f5fe,stroke:#01579b,stroke-width:2px
style C fill:#e8f5e9,stroke:#2e7d32,stroke-width:2px
style D fill:#f3e5f5,stroke:#7b1fa2,stroke-width:2px各层核心职责:
-
用户交互层(前端):负责用户与系统的所有交互,包括界面渲染、对话交互、数据可视化、AI能力前端封装,是AI能力触达用户的唯一窗口。
-
API网关层:全系统的流量入口,负责路由转发、统一鉴权、限流熔断、SSL终止、日志审计,是前后端交互的核心枢纽。
-
业务服务层(后端):负责核心业务逻辑实现,包括用户管理、权限控制、资源管理、业务流程编排,是业务规则与AI能力的粘合剂。
-
AI能力层:AI全栈的核心差异化层,负责大模型调用、RAG检索、Agent编排、向量化处理、多模态解析、推理优化,是产品的核心竞争力。
-
数据存储层:负责全系统的数据持久化,包括关系型数据、向量数据、缓存数据、文件资源、日志数据,是AI系统的根基。
-
基础设施与DevOps层:负责系统的部署、运维、监控、扩缩容、成本管控,保障系统的高可用、高性能、高安全。
二、AI全栈前端知识框架(AI原生视角)
AI场景下的前端开发,核心差异在于从「静态页面渲染」转向「流式交互体验」,从「纯UI开发」转向「AI能力前端封装与体验优化」,知识体系分为6大核心模块。
2.1 核心基础能力
这是前端开发的根基,AI场景下对类型安全、异步处理、原生API能力要求更高:
• 语言核心:HTML5、CSS3、JavaScript(ES6+)、TypeScript(必备,AI项目全链路类型安全)
• 核心能力:异步编程(Promise/async-await)、流式数据处理(Fetch API/ReadableStream)、事件循环、浏览器渲染原理、Web API(File/Blob/Canvas/Web Audio)
• CSS进阶:Flex/Grid布局、TailwindCSS(企业级首选)、CSS动画、响应式设计、暗黑模式适配
2.2 主流框架与工程生态
AI项目首选支持SSR/流式渲染的全栈框架,兼顾开发效率与用户体验:
• 核心框架:
◦ React 19 + Next.js 15(App Router):AI项目首选,支持React Server Components、流式渲染、Edge Runtime,完美适配大模型流式对话场景
◦ Vue 3 + Nuxt.js 3:国内主流选型,组合式API+SSR能力,适合中小团队快速落地
• 周边生态:
◦ UI组件库:shadcn/ui、Ant Design、Element Plus
◦ 状态管理:Zustand、Jotai、Pinia、Redux Toolkit
◦ 路由管理:Next.js/Nuxt.js内置路由、React Router
◦ 构建工具:Vite、Turbopack、Webpack
2.3 AI前端核心差异化能力
这是普通前端与AI全栈前端的核心区别,也是AI产品体验的核心抓手:
-
大模型流式交互能力:SSE/WebSocket流式数据读取、对话中断与重试、Markdown/代码块/公式实时渲染、打字机效果优化、多轮对话上下文管理
-
AI能力前端封装:基于Vercel AI SDK、LangChain JS完成Prompt工程前端封装、多模型统一调用、Token计数与消耗展示、对话历史管理
-
多模态交互实现:图片/音频/视频文件上传与预览、大文件分片上传与断点续传、WebRTC实时音视频交互、OCR前端预处理、语音转文字(STT)/文字转语音(TTS)前端集成
-
端侧推理优化:基于WebGPU/ONNX Runtime Web实现轻量模型浏览器端推理(如Embedding模型、Rerank模型、小参数大模型)、降低服务端压力、提升响应速度
-
RAG前端交互设计:引用来源展示与溯源、文档分块可视化、检索结果高亮、文档预览与定位、知识库管理交互
2.4 工程化与质量保障
AI项目迭代速度快,对工程化、可维护性、稳定性要求极高:
• 代码规范:ESLint、Prettier、TypeScript ESLint、Husky + lint-staged 代码提交校验
• 测试体系:单元测试(Vitest/Jest)、组件测试(React Testing Library)、E2E测试(Playwright/Cypress)、接口Mock(MSW)
• 性能优化:首屏加载优化、流式渲染减少白屏、React渲染优化(memo/useMemo/useCallback)、图片懒加载、资源预加载、大列表虚拟滚动
• 兼容性处理:浏览器兼容性适配、移动端响应式适配、暗黑模式适配、无障碍访问(ARIA)
2.5 前端安全体系
AI场景下前端安全风险更高,重点防范Prompt注入、敏感信息泄露等问题:
• 基础安全:XSS/CSRF防护、输入内容过滤与转义、CSP内容安全策略
• AI专项安全:Prompt注入防护、前端敏感信息脱敏、禁止API Key硬编码、用户输入合法性校验
• 权限安全:路由级权限控制、按钮级权限管控、未授权访问拦截、会话管理
2.6 前端工程化进阶
• SSR/SSG/ISR:Next.js/Nuxt.js服务端渲染、静态站点生成、增量静态再生,优化SEO与首屏体验
• Edge Runtime:边缘函数部署,降低大模型流式接口延迟,提升全球用户访问体验
• 微前端:针对大型AI平台,实现多业务模块解耦、独立部署、灰度发布
• 跨端开发:React Native、Taro,实现AI产品Web/移动端多端复用
三、AI全栈后端知识框架(AI原生视角)
AI场景下的后端开发,核心差异在于从「业务CRUD」转向「AI能力工程化落地」,从「接口开发」转向「高并发推理调度、全链路RAG实现、成本与性能平衡」,知识体系分为8大核心模块。
3.1 核心编程语言与Runtime
AI全栈后端推荐多语言协同,兼顾开发效率、AI生态适配、高性能要求:
• TypeScript + Node.js:全栈首选,与前端技术栈统一,实现类型全链路打通,适合业务服务、API代理、轻量AI服务封装,主流框架NestJS/Fastify/Express
• Python:AI生态王者,适合AI核心服务开发,包括RAG实现、Agent编排、模型推理、文档解析,主流框架FastAPI/Django/Flask
• Go:高性能首选,适合API网关、高并发调度服务、异步任务处理,主流框架Gin/Echo
• 补充:Java(适合大型企业级微服务架构)、Rust(适合高性能推理引擎、向量数据库周边开发)
3.2 后端框架与工程规范
企业级AI项目优先选择类型安全、工程化完善、生态丰富的框架:
• Node.js 企业级框架:NestJS(首选,IOC架构、TypeScript原生、模块化设计、全链路类型安全,适合大型业务系统)、Fastify(高性能、低开销,适合大模型流式接口代理)、Express/Koa(轻量灵活,适合小型项目)
• Python AI服务框架:FastAPI(首选,高性能、异步支持、自动生成OpenAPI文档、类型提示,完美适配AI接口开发)、LlamaIndex/LangChain 服务化封装
• Go 高性能框架:Gin/Echo,适合API网关、限流服务、高并发任务调度
3.3 AI后端核心差异化能力
这是普通后端与AI全栈后端的核心区别,也是AI系统的核心壁垒:
-
大模型工程化管理:多厂商大模型统一接口封装(OpenAI/Anthropic/阿里云通义/百度文心/开源Llama 3/Qwen 2等)、失败重试与Fallback降级、模型路由与负载均衡、Token计数与成本管控、批量推理优化
-
RAG全链路工程化实现:文档解析(PDF/Word/Excel/PPT/图片等多格式)、文本分块策略、Embedding向量化、向量检索、多路召回、重排(Rerank)、Prompt工程、上下文管理、检索效果评估与优化
-
Agent编排与调度:基于LangChain/LlamaIndex/Autogen实现工具调用、多智能体协作、任务拆解与规划、长流程任务执行、记忆管理、函数调用封装
-
流式响应与高并发处理:SSE/WebSocket流式接口实现、推理请求调度、异步任务队列、并发限流、长连接管理、请求中断与资源释放
-
推理优化与成本控制:Prompt缓存、KV缓存、模型量化、批处理推理、冷热数据分离、Token压缩、闲时资源降配、成本监控与告警
3.4 API设计与网关架构
API是前后端交互的桥梁,AI场景下对接口的流式支持、高可用、可观测性要求极高:
• API设计规范:RESTful API 设计规范、GraphQL(适合复杂查询场景)、gRPC(内部微服务通信)、SSE/WebSocket(流式对话必备)
• API网关核心能力:Nginx/APISIX/Kong 网关部署、路由转发、统一鉴权、限流熔断、SSL终止、请求日志、灰度发布、跨域处理
• 接口治理:接口版本管理、参数校验、统一响应格式、统一异常处理、接口文档自动生成、接口性能监控
• 高可用保障:限流熔断降级(Sentinel/Resilience4j)、集群部署、负载均衡、故障隔离、灾备切换
3.5 数据库与存储体系
AI场景下的存储体系,核心新增了向量数据库,形成多引擎协同的存储架构:
存储类型 主流选型 核心应用场景
关系型数据库 PostgreSQL(+pgvector 首选)、MySQL 用户数据、权限数据、业务元数据、文档元数据、对话记录,PostgreSQL可通过pgvector直接支持向量存储
向量数据库 Milvus、Pinecone、Weaviate、Chroma 文档向量存储、语义检索、RAG召回,是AI系统的核心存储
缓存数据库 Redis 会话管理、接口限流、Prompt缓存、热点数据缓存、分布式锁、消息队列
对象存储 MinIO、阿里云OSS、AWS S3 文档、图片、音视频、模型文件等大文件存储
搜索引擎 Elasticsearch 全文检索、关键词召回、多路召回补充、日志存储
3.6 系统架构与分布式能力
企业级AI系统需要支持高并发、弹性扩缩容,主流采用微服务/Serverless架构:
• 架构模式:
◦ 微服务架构:按业务域拆分服务(用户服务、文档服务、AI服务、系统服务),服务解耦、独立部署、弹性扩缩容
◦ Serverless架构:基于Vercel Edge Functions/AWS Lambda/阿里云函数计算,按需付费、自动扩缩容,适合创业团队快速落地
◦ 单体架构:适合小型项目、MVP验证,基于Next.js/NestJS/FastAPI快速实现全栈应用
• 分布式核心能力:
◦ 消息队列:RabbitMQ/Kafka,处理异步任务(文档解析、向量化、模型微调、批量推理)
◦ 服务治理:服务注册与发现、配置中心、分布式锁、分布式事务
◦ 容器化:Docker 镜像打包、环境一致性保障
◦ 编排调度:Kubernetes 集群管理、Pod弹性扩缩容、服务滚动更新
3.7 运维与DevOps体系
AI系统的稳定性、成本管控高度依赖DevOps能力,核心包括:
• CI/CD流水线:基于GitHub Actions/GitLab CI/Jenkins,实现代码提交→自动校验→单元测试→构建打包→镜像推送→自动部署的全流程自动化
• 监控与可观测性:Prometheus + Grafana 指标监控(接口延迟、模型调用量、Token消耗、服务器资源)、ELK/Loki 日志管理、Jaeger 链路追踪、异常告警
• 云原生与部署:公有云(AWS/阿里云/腾讯云)、私有云/私有化部署、混合云架构、边缘节点部署
• 成本管控:大模型Token消耗监控与告警、资源弹性扩缩容、闲时资源降配、存储冷热分离、成本分摊与统计
3.8 后端安全与合规体系
AI系统涉及大量企业数据与用户隐私,安全与合规是生命线:
• 基础安全:输入校验、SQL注入防护、XSS防护、CSRF防护、接口权限控制
• AI专项安全:Prompt注入防护、越狱攻击防范、敏感信息过滤、模型输出内容审核、数据泄露防护
• 权限安全:RBAC 权限模型、最小权限原则、接口级权限管控、操作日志审计、多因素认证
• 数据安全:传输加密(HTTPS)、存储加密、敏感信息脱敏、数据备份与恢复、数据留存合规
• 合规性:符合《生成式人工智能服务管理暂行办法》、GDPR、等保2.0要求,用户隐私保护、数据合规使用
四、实战项目:企业级RAG智能问答系统全架构拆解
理论结合实战是掌握AI全栈的最佳方式,我们以企业级RAG智能问答系统为例,从需求分析到架构设计、前后端模块实现、部署运维,完成全链路深度拆解。
4.1 项目需求与目标
本项目面向企业内部知识库场景,核心目标是:
• 支持多格式企业文档上传与解析,构建企业私有知识库
• 实现基于私有知识库的精准智能问答,支持多轮对话、流式响应
• 支持多租户、多角色权限管理,保障数据安全
• 支持多模型切换、私有化部署,满足企业合规要求
• 高可用、高性能,支持百人同时在线问答
4.2 项目整体架构设计
flowchart LR
subgraph 前端层
ANext.js 15 前端应用
A1对话交互模块
A2文档管理模块
A3权限管理模块
A4系统管理模块
A --> A1 & A2 & A3 & A4
end
subgraph 网关层
B[APISIX 网关]
B1[路由转发]
B2[统一鉴权]
B3[限流熔断]
B4[日志审计]
B --> B1 & B2 & B3 & B4
end
subgraph 业务服务层[NestJS 业务服务]
C[用户认证服务]
D[文档管理服务]
E[系统管理服务]
F[对话管理服务]
end
subgraph AI核心层[FastAPI AI服务]
G[RAG检索引擎]
H[大模型管理服务]
I[向量化服务]
J[文档解析服务]
G --> H & I
end
subgraph 消息队列层
K[RabbitMQ 消息队列]
K1[文档处理队列]
K2[异步任务队列]
K --> K1 & K2
end
subgraph 存储层
L[(PostgreSQL + pgvector)]
M[(Redis)]
N[MinIO 对象存储]
O[(Elasticsearch)]
end
A --> B
B --> C & D & E & F
F --> G
D --> J & K
K --> J & I
J --> I
I --> L
G --> L & O
C & D & E & F --> L & M
J --> N4.3 前端架构详细设计与实现
4.3.1 技术选型
技术栈 选型 选型原因
核心框架 Next.js 15(App Router) 支持React Server Components、流式渲染、Edge Runtime,完美适配大模型对话场景,全栈TypeScript支持
开发语言 TypeScript 5.4 全链路类型安全,减少运行时错误,提升代码可维护性
UI框架 TailwindCSS + shadcn/ui 原子化CSS,高度可定制,组件库无依赖,适配企业级设计系统
状态管理 Zustand 轻量、高性能、TypeScript友好,适合AI对话场景的复杂状态管理
AI SDK Vercel AI SDK 开箱即用的流式对话封装,支持多模型统一调用,与Next.js深度集成
表单处理 React Hook Form + Zod 高性能表单处理,类型安全的参数校验,适配文档上传、用户管理等场景
测试工具 Vitest + Playwright 单元测试与E2E测试,保障核心业务逻辑稳定性
4.3.2 项目目录结构
ai-rag-frontend
├── app/ # Next.js App Router 路由目录
│ ├── (auth)/ # 认证相关路由(登录/注册/忘记密码)
│ ├── (dashboard)/ # 主应用路由
│ │ ├── chat/ # 对话页面
│ │ ├── documents/ # 文档管理页面
│ │ ├── admin/ # 系统管理页面
│ │ └── layout.tsx # 主应用布局
│ ├── api/ # API 路由(Edge Runtime)
│ ├── layout.tsx # 全局布局
│ └── page.tsx # 首页
├── components/ # 通用组件
│ ├── ui/ # shadcn/ui 基础组件
│ ├── chat/ # 对话相关组件
│ ├── document/ # 文档相关组件
│ └── common/ # 通用业务组件
├── lib/ # 核心工具库
│ ├── ai.ts # Vercel AI SDK 封装
│ ├── api.ts # 请求接口封装
│ ├── auth.ts # 认证相关工具
│ └── utils.ts # 通用工具函数
├── hooks/ # 自定义 Hooks
│ ├── use-chat.ts # 对话逻辑封装
│ ├── use-upload.ts # 文件上传封装
│ ├── use-auth.ts # 认证相关Hook
│ └── use-permission.ts # 权限控制Hook
├── store/ # 全局状态管理
│ ├── chat-store.ts # 对话状态
│ ├── user-store.ts # 用户状态
│ └── app-store.ts # 应用全局状态
├── types/ # TypeScript 类型定义
├── tests / # 测试用例
└── 配置文件 # next.config.ts、tailwind.config.ts、eslint.config.js等
4.3.3 核心模块与实现
- 对话交互核心模块
这是项目的核心体验模块,基于Vercel AI SDK实现流式对话,核心能力包括:
◦ 流式响应实时渲染,支持Markdown、代码块、表格、公式的实时渲染
◦ 多轮对话上下文管理,支持对话新建、切换、删除、清空
◦ 对话中断与重试,支持用户随时停止生成,异常自动重试
◦ 引用来源展示,支持点击引用溯源到对应文档片段
◦ 附件上传,支持对话中上传文档、图片,实现多模态问答
核心实现代码片段:
// hooks/use-chat.ts
import { useChat as useVercelChat } from 'ai/react';
import { useChatStore } from '@/store/chat-store';
export const useChat = (chatId?: string) => {
const { currentChat, setMessages, addMessage } = useChatStore();
const chat = useVercelChat({
api: '/api/chat',
id: chatId,
initialMessages: currentChat?.messages || \[\],
onFinish: (message) => {
addMessage(message);
},
onResponse: (response) => {
if (!response.ok) {
throw new Error('对话请求失败');
}
},
});
return {
...chat,
// 扩展能力:引用来源解析、Token计数、权限校验等
};
};
- 文档管理模块
核心能力包括:多格式文档上传、大文件分片上传与断点续传、文档列表管理、文档预览、文档处理状态实时同步、文档权限管理。
◦ 分片上传:基于Web API将大文件拆分为2MB分片,支持断点续传、上传进度展示、失败重传
◦ 状态同步:基于SSE实时接收后端文档解析、分块、向量化的进度状态
◦ 权限管理:支持文档私有、公开、指定角色访问的权限配置
- 权限与认证模块
基于NextAuth.js实现,支持账号密码登录、SSO单点登录,基于RBAC模型实现权限控制:
◦ 路由级权限:未登录用户自动跳转登录页,无权限用户禁止访问管理页面
◦ 按钮级权限:根据用户角色控制操作按钮的显示与禁用
◦ 会话管理:基于JWT实现无状态会话,Redis存储会话黑名单,支持登出与会话过期
- 性能与安全优化
◦ 渲染优化:使用React.memo、useMemo、useCallback优化对话列表渲染,避免频繁重渲染
◦ 流式渲染:基于Next.js Streaming SSR实现首屏秒开,减少白屏时间
◦ 安全防护:前端输入过滤与转义,防范XSS与Prompt注入,敏感信息脱敏,禁止API Key暴露
◦ 体验优化:对话列表虚拟滚动,支持上万条历史消息流畅渲染,图片懒加载,资源预加载
4.4 后端架构详细设计与实现
本项目后端采用多语言微服务架构,NestJS负责业务服务,FastAPI负责AI核心服务,实现业务与AI能力解耦,独立扩缩容。
4.4.1 技术选型
服务模块 技术选型 核心职责
业务主服务 NestJS 10 + TypeScript 用户认证、文档管理、对话管理、系统管理、权限控制
AI核心服务 FastAPI + Python RAG检索引擎、大模型管理、向量化处理、文档解析
API网关 APISIX + Nginx 路由转发、统一鉴权、限流熔断、SSL终止、日志审计
消息队列 RabbitMQ 异步文档处理、向量化任务、批量推理任务
主数据库 PostgreSQL 16 + pgvector 用户数据、业务数据、文档元数据、向量数据统一存储
缓存 Redis 7 会话管理、接口限流、热点数据缓存、分布式锁
对象存储 MinIO 文档、图片、音视频等文件存储
搜索引擎 Elasticsearch 全文检索、关键词多路召回
监控告警 Prometheus + Grafana 系统指标监控、Token消耗监控、异常告警
4.4.2 业务主服务(NestJS)设计
目录结构
ai-rag-backend-nest
├── src/
│ ├── main.ts # 项目入口
│ ├── app.module.ts # 根模块
│ ├── common/ # 通用模块
│ │ ├── decorators/ # 自定义装饰器
│ │ ├── filters/ # 异常过滤器
│ │ ├── guards/ # 守卫(鉴权/权限)
│ │ ├── interceptors/ # 拦截器(日志/响应转换)
│ │ ├── pipes/ # 管道(参数校验)
│ │ └── utils/ # 通用工具函数
│ ├── modules/ # 业务模块
│ │ ├── auth/ # 认证模块
│ │ ├── user/ # 用户模块
│ │ ├── role/ # 角色权限模块
│ │ ├── document/ # 文档管理模块
│ │ ├── chat/ # 对话管理模块
│ │ ├── system/ # 系统管理模块
│ │ └── ai-client/ # AI服务调用客户端
│ ├── config/ # 配置模块
│ └── database/ # 数据库模块(TypeORM)
├── test/ # 测试用例
└── 配置文件 # nest-cli.json、tsconfig.json、dockerfile等
核心模块实现
- 认证与权限模块
基于JWT + RBAC模型实现,核心流程:
◦ 用户登录成功后,签发包含用户ID、角色信息的JWT令牌,返回给前端
◦ 全局AuthGuard守卫,拦截所有请求,校验JWT令牌的合法性,解析用户信息
◦ 自定义Permissions装饰器,声明接口所需权限,PermissionGuard守卫校验用户是否拥有对应权限
◦ 支持多租户隔离,不同企业用户数据完全隔离
-
文档管理模块
负责文档全生命周期管理,核心流程:
-
接收前端上传的文件分片,校验文件权限与完整性,合并分片后写入MinIO对象存储
-
生成文档元数据,写入PostgreSQL,状态更新为「待处理」
-
发送消息到RabbitMQ的document_process队列,触发异步文档处理
-
提供文档列表查询、预览、下载、删除、权限修改、处理状态查询等接口
-
基于SSE向前端实时推送文档处理进度
-
对话管理模块
负责对话生命周期管理,衔接前端与AI核心服务:
◦ 提供对话的新建、查询、删除、历史消息查询等接口
◦ 封装流式对话接口,接收前端用户问题,转发给AI核心服务的RAG接口,通过SSE将大模型生成的内容实时转发给前端
◦ 记录对话日志、Token消耗、用户反馈,用于后续模型效果优化与成本统计
◦ 实现用户级限流,防止单用户过量请求导致系统压力过大
- AI服务客户端模块
封装AI核心服务的HTTP调用,实现统一的异常处理、重试机制、超时控制,与FastAPI服务的接口类型完全对齐,实现全链路类型安全。
4.4.3 AI核心服务(FastAPI)设计
这是项目的核心大脑,负责RAG全链路实现、大模型管理、向量化处理,是AI能力的核心载体。
目录结构
ai-rag-backend-fastapi
├── app/
│ ├── main.py # 项目入口
│ ├── api/ # API路由
│ │ ├── v1/
│ │ │ ├── rag.py # RAG问答接口
│ │ │ ├── embed.py # 向量化接口
│ │ │ ├── document.py # 文档处理接口
│ │ │ └── model.py # 模型管理接口
│ ├── core/ # 核心配置
│ │ ├── config.py # 配置管理
│ │ ├── exceptions.py # 异常处理
│ │ └── security.py # 安全校验
│ ├── services/ # 核心服务
│ │ ├── rag_service.py # RAG检索服务
│ │ ├── embed_service.py # 向量化服务
│ │ ├── document_service.py # 文档解析服务
│ │ ├── model_service.py # 大模型管理服务
│ │ └── rerank_service.py # 重排服务
│ ├── schemas/ # Pydantic 数据模型
│ ├── db/ # 数据库连接
│ ├── mq/ # 消息队列消费者
│ │ ├── document_consumer.py # 文档处理消费者
│ │ └── embed_consumer.py # 向量化消费者
│ └── utils/ # 工具函数
├── test/ # 测试用例
└── 配置文件 # requirements.txt、dockerfile、.env等
核心流程实现
-
文档处理全链路流程
这是RAG系统的基础,直接决定问答的准确率,全流程异步化处理,核心步骤:
sequenceDiagram
participant 前端
participant Nest业务服务
participant MinIO
participant RabbitMQ
participant FastAPI消费者
participant PostgreSQL
participant 向量化服务
前端->>Nest业务服务: 上传文档分片
Nest业务服务->>MinIO: 合并分片,存储文档
MinIO-->>Nest业务服务: 返回文件URL
Nest业务服务->>PostgreSQL: 写入文档元数据
Nest业务服务->>RabbitMQ: 发送文档处理消息
RabbitMQ->>FastAPI消费者: 推送文档处理任务
FastAPI消费者->>MinIO: 下载文档
FastAPI消费者->>FastAPI消费者: 文档解析,提取纯文本
FastAPI消费者->>FastAPI消费者: 文本分块(递归分块+重叠)
FastAPI消费者->>向量化服务: 批量生成文本块向量
向量化服务-->>FastAPI消费者: 返回向量数据
FastAPI消费者->>PostgreSQL: 写入文本块与向量数据
FastAPI消费者->>PostgreSQL: 更新文档状态为「已就绪」
FastAPI消费者->>RabbitMQ: 发送处理完成通知
RabbitMQ-->>Nest业务服务: 推送完成通知
Nest业务服务-->>前端: SSE推送处理完成状态
核心优化点:
◦ 文档解析:支持PDF/Word/Excel/PPT/TXT/Markdown/图片等20+格式,图片基于OCR提取文本,保留文档层级结构
◦ 文本分块:采用递归字符分块,基于语义分隔符拆分,保留15%的重叠率,避免上下文断裂
◦ 批量向量化:采用批处理生成向量,提升处理效率,降低接口调用成本
◦ 异常处理:分步骤记录处理状态,失败自动重试,支持断点续处理
-
RAG问答核心流程
这是系统的核心能力,直接决定问答的精准度与用户体验,全流程如下:
sequenceDiagram
participant 前端
participant Nest业务服务
participant FastAPI RAG服务
participant 向量化服务
participant PostgreSQL向量库
participant 重排服务
participant 大模型服务
前端->>Nest业务服务: 发送用户问题 + 会话ID
Nest业务服务->>Nest业务服务: 鉴权、限流、参数校验
Nest业务服务->>FastAPI RAG服务: 转发问题 + 上下文配置
FastAPI RAG服务->>大模型服务: 问题改写,优化检索词
大模型服务-->>FastAPI RAG服务: 返回优化后的检索query
FastAPI RAG服务->>向量化服务: 生成query向量
向量化服务-->>FastAPI RAG服务: 返回query向量
FastAPI RAG服务->>PostgreSQL向量库: 向量检索Top-K相关块
PostgreSQL向量库-->>FastAPI RAG服务: 返回初始检索结果
FastAPI RAG服务->>重排服务: 对检索结果进行重排
重排服务-->>FastAPI RAG服务: 返回重排后的Top-N相关块
FastAPI RAG服务->>FastAPI RAG服务: 构建Prompt,注入上下文
FastAPI RAG服务->>大模型服务: 流式调用大模型
大模型服务-->>FastAPI RAG服务: 流式返回生成内容
FastAPI RAG服务-->>Nest业务服务: SSE流式转发内容
Nest业务服务-->>前端: SSE流式转发内容
前端->>前端: 实时渲染生成内容
Note over FastAPI RAG服务,大模型服务: 对话结束后,记录对话日志与Token消耗
核心优化点:
◦ 问题改写:基于历史对话上下文,将用户的模糊问题、指代问题改写为精准的检索query,提升召回准确率
◦ 多路召回:向量语义检索 + 关键词全文检索,兼顾语义与精准匹配,提升召回率
◦ 重排优化:基于交叉编码器模型对召回结果进行重排,过滤低相关度内容,提升上下文精准度
◦ 流式响应:基于SSE实现Token级流式返回,最低延迟响应用户,提升对话体验
◦ 上下文管理:自动管理对话历史,控制上下文窗口大小,避免Token溢出
◦ 引用溯源:在Prompt中注入文档块ID,大模型生成内容时标注引用来源,前端可直接溯源
- 大模型管理服务
核心能力包括:
◦ 多模型统一封装:适配OpenAI、Anthropic、通义千问、文心一言、Llama 3、Qwen 2等主流大模型,提供统一的调用接口,支持模型无缝切换
◦ 失败重试与降级:实现指数退避重试机制,主模型调用失败自动切换到备用模型,保障服务可用性
◦ Token管理:精准计算输入输出Token,实时统计消耗,对接成本管控系统
◦ 缓存优化:实现Prompt语义缓存,相同/相似问题直接返回缓存结果,降低调用成本,提升响应速度
4.5 数据库核心表结构设计
核心业务表
-
用户表 sys_user:存储用户ID、账号、密码哈希、姓名、邮箱、手机号、状态、所属租户、创建时间等
-
角色表 sys_role:存储角色ID、角色名称、角色编码、描述、状态、创建时间等
-
权限表 sys_permission:存储权限ID、权限名称、权限标识、权限类型、所属模块、创建时间等
-
文档表 biz_document:存储文档ID、文件名、文件类型、文件大小、文件URL、所属用户、所属知识库、处理状态、分块数量、创建时间、更新时间等
-
文档分块表 biz_document_chunk:存储分块ID、所属文档ID、分块内容、分块序号、字符数、创建时间,配合pgvector存储向量数据
-
对话表 biz_chat:存储对话ID、对话名称、所属用户、所属知识库、模型配置、创建时间、更新时间等
-
消息表 biz_chat_message:存储消息ID、所属对话ID、角色(user/assistant)、消息内容、Token消耗、引用来源、创建时间等
-
模型配置表 sys_model_config:存储配置ID、模型厂商、模型名称、API地址、API Key、模型配置、优先级、状态、创建时间等
向量表设计
基于pgvector实现,核心向量表 document_embedding:
-- 启用pgvector扩展
CREATE EXTENSION IF NOT EXISTS vector;
-- 文档向量表
CREATE TABLE document_embedding (
id UUID PRIMARY KEY DEFAULT uuid_generate_v4(),
chunk_id UUID NOT NULL REFERENCES biz_document_chunk(id) ON DELETE CASCADE,
document_id UUID NOT NULL REFERENCES biz_document(id) ON DELETE CASCADE,
tenant_id UUID NOT NULL,
embedding vector(1536) NOT NULL, -- 1536维向量,适配OpenAI Embedding模型
created_at TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
-- 向量索引,提升检索速度
CONSTRAINT embedding_idx UNIQUE (chunk_id)
);
-- 创建HNSW向量索引,适配高维向量近邻检索
CREATE INDEX ON document_embedding USING hnsw (embedding vector_cosine_ops);
4.6 DevOps与部署架构
本项目支持Docker Compose单机一键部署,也支持Kubernetes集群高可用部署,满足不同企业的部署需求。
4.6.1 容器化设计
所有服务均提供Dockerfile,实现环境一致性,核心包括:
• 前端Next.js应用Dockerfile
• NestJS业务服务Dockerfile
• FastAPI AI服务Dockerfile
• APISIX网关配置
• PostgreSQL + pgvector 镜像
• Redis、MinIO、RabbitMQ、Elasticsearch 官方镜像
4.6.2 Docker Compose 单机部署
提供docker-compose.yml文件,一键启动所有服务,适合中小企业、私有化部署场景。
4.6.3 Kubernetes 集群部署
针对大型企业、高并发场景,提供K8s部署清单,核心包括:
• 命名空间隔离:生产、测试、开发环境隔离
• 工作负载:Deployment部署无状态服务,StatefulSet部署有状态服务(数据库、消息队列)
• 服务发现:ClusterIP + Service 实现内部服务通信
• 配置管理:ConfigMap + Secret 管理配置文件与敏感信息
• 存储管理:PersistentVolume 实现数据持久化
• 弹性扩缩容:HPA 基于CPU/内存使用率自动扩缩容Pod副本数
• ingress-nginx 实现流量入口与SSL终止
4.6.4 监控与可观测性
• 指标监控:Prometheus采集全系统指标,Grafana提供可视化看板,包括:接口请求量、延迟、错误率、大模型调用量、Token消耗、文档处理数量、服务器CPU/内存/磁盘使用率
• 日志管理:ELK Stack 采集所有服务的日志,支持日志检索、异常定位、审计回溯
• 链路追踪:Jaeger 实现全链路分布式追踪,定位接口瓶颈、异常节点
• 告警系统:基于Grafana Alerting 实现异常告警,支持邮件、钉钉、企业微信推送,及时响应系统故障
4.7 安全体系设计
-
网络安全:全站HTTPS加密,WAF防护,公网仅暴露网关443端口,所有内部服务部署在内网,不暴露公网
-
应用安全:全接口参数校验,SQL注入防护,XSS防护,CSRF防护,Prompt注入防护,大模型输出内容安全审核
-
数据安全:数据库加密存储,敏感信息脱敏,数据定时备份,传输全程加密,租户数据完全隔离
-
权限安全:RBAC权限模型,最小权限原则,操作日志全审计,多因素认证,会话超时自动登出
-
合规性:符合《生成式人工智能服务管理暂行办法》,支持数据留存、用户隐私保护、可审计、可追溯,满足企业等保2.0要求
五、AI全栈工程师成长路径
-
入门阶段(1-3个月):夯实前端/后端基础,掌握TypeScript、Next.js/NestJS、Python/FastAPI核心用法,完成简单的大模型API调用Demo,理解RAG基本原理
-
进阶阶段(3-6个月):系统学习前后端完整知识体系,掌握RAG全链路实现,独立完成AI对话系统的前后端开发与部署,理解微服务架构与容器化部署
-
资深阶段(6-12个月):深入AI工程化核心,掌握Agent编排、推理优化、高并发AI系统设计,能独立完成企业级AI产品的架构设计、全链路开发、性能优化、成本管控
-
专家阶段(1年以上):形成完整的AI全栈技术方法论,能主导大型AI平台的架构设计与技术选型,解决AI系统的高并发、高可用、低成本等核心难题,兼顾技术深度与业务广度
六、总结
AI全栈工程师的核心竞争力,从来不是「前后端技术的简单堆砌」,而是以用户需求为核心,以AI能力为驱动,打通从用户界面到AI推理的全链路技术闭环。
本文梳理的知识框架与项目架构,覆盖了AI全栈开发的核心知识点与落地实践,读者可以基于本文的架构设计,动手实现一个完整的RAG智能问答系统,在实战中巩固知识体系,完成从普通开发者到AI全栈工程师的转型。
本文配套的完整代码、Docker部署清单、架构设计文档,可关注作者GitHub获取。
需要我把这篇博客的配套Mermaid源码、核心模块完整代码、Docker Compose一键部署清单整理成可直接复制使用的文件包吗?