一、高级调度
1、Job
Job(batch/v1) 是用来跑一次性、跑完就退出的任务控制器,保证任务 Pod 成功完成,失败会自动重试Kubernetes。
典型场景:
- 数据库迁移,数据备份
- 批量计算,报表生成
- 初始化脚本,一次运维任务
Job的工作机制:
- 创建Job→启动pod
- pod正常退出(exit=0)→计数+1
- 达到Completions数→job状态为completed
- pod异常退出→job按backofflimit 重试
- 超过重试次数→job状态Failed
案例:
使用 mysql 镜像,等待 MySQL 服务就绪 → 自动导入测试数据
-
已有独立 MySQL Deployment + Service(业务数据库)
-
单独创建一个 Job (使用
mysql:8.0镜像) -
Job 内循环等待 MySQL 服务就绪,自动执行建库、建表、写入测试数据
-
一次性任务,跑完 Job 标记为 Completed,不常驻
准备configMap(my.cnf)文件
cat > my.cnf << EOF
[mysqld]
bind-address = 0.0.0.0
character_set_server = utf8mb4
collation-server = utf8mb4_unicode_ci
max_connections = 200
default-time_zone = '+8:00'
EOF创建configMap
[root@k8s-master01 job]# kubectl create configmap mysql-cfg --from-file=my.cnf -n tcloud
StatefulSet 靠 Headless Service 给每个 Pod 分配固定域名!
没有 Service → 没有固定域名 → 你的 Job 找不到 mysql-0、mysql-1、mysql-2 → 初始化失败!
# 准备service文件
[root@k8s-master01 job]# vim service.yaml
apiVersion: v1
kind: Service
metadata:
name: mysql-svc
namespace: tcloud
spec:
clusterIP: None
selector:
app: mysql
ports:
- port: 3306
# 准备statefulset文件
[root@k8s-master01 job]# vim statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
namespace: tcloud
spec:
serviceName: mysql-svc
replicas: 3
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: docker.io/library/mysql:8.0
env:
- name: MYSQL_ROOT_PASSWORD
value: "Test@123"
ports:
- containerPort: 3306
# 挂载 ConfigMap 到 MySQL 配置目录 ↓↓↓
volumeMounts:
- name: mysql-config
mountPath: /etc/mysql/conf.d
# 使用创建的 ConfigMap ↓↓↓
volumes:
- name: mysql-config
configMap:
name: mysql-cfg
# 准备job任务文件
[root@k8s-master01 job]# vim job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: mysql-init-job # Job任务名称
namespace: tcloud # 运行在tcloud命名空间
spec:
parallelism: 1 # 同时只启动1个Pod执行任务
completions: 1 # 需成功完成1次任务才算结束
backoffLimit: 10 # 任务失败最大重试次数
activeDeadlineSeconds: 300 # 任务最大运行超时时间,超时自动终止
template:
spec:
restartPolicy: OnFailure # 仅容器异常失败时才重启
containers:
- name: init-data
image: docker.io/library/mysql:8.0
command:
- /bin/sh
- -c
- |
# 变量
u=root
p=Test@123
# 等待 10 秒让 MySQL 完全启动(最稳妥)
sleep 10
# 插入 mysql-0
mysql -h mysql-0.mysql-svc -u$u -p$p -e "create database testdb; use testdb; create table t(id int); insert into t values(0);"
echo "mysql-0 插入数据成功"
# 插入 mysql-1
mysql -h mysql-1.mysql-svc -u$u -p$p -e "create database testdb; use testdb; create table t(id int); insert into t values(1);"
echo "mysql-1 插入数据成功"
# 插入 mysql-2
mysql -h mysql-2.mysql-svc -u$u -p$p -e "create database testdb; use testdb; create table t(id int); insert into t values(2);"
echo "mysql-2 插入数据成功"
# 创建资源
[root@k8s-master01 job]# kubectl apply -f statefulset.yaml
[root@k8s-master01 job]# kubectl apply -f service.yaml
# 验证创建的资源
[root@k8s-master01 job]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
mysql-0 1/1 Running 0 2m25s 10.244.58.236 k8s-node02 <none> <none>
mysql-1 1/1 Running 0 2m23s 10.244.135.172 k8s-node03 <none> <none>
mysql-2 1/1 Running 0 2m22s 10.244.85.230 k8s-node01 <none> <none>
[root@k8s-master01 job]# kubectl get endpoints -n tcloud
Warning: v1 Endpoints is deprecated in v1.33+; use discovery.k8s.io/v1 EndpointSlice
NAME ENDPOINTS AGE
mysql-svc 10.244.135.172:3306,10.244.58.236:3306,10.244.85.230:3306 96s
# 创建job来执行任务
[root@k8s-master01 job]# kubectl apply -f job.yaml
# 查看创建的job
[root@k8s-master01 job]# kubectl get pod -n tcloud
NAME READY STATUS RESTARTS AGE
mysql-0 1/1 Running 0 67s
mysql-1 1/1 Running 0 65s
mysql-2 1/1 Running 0 64s
mysql-init-job-m89sh 0/1 Completed 0 62s
状态是Completed说明已经执行完毕
# 查看日志
[root@k8s-master01 job]# kubectl logs -n tcloud mysql-init-job-m89sh
mysql: [Warning] Using a password on the command line interface can be insecure.
mysql-0 插入数据成功
mysql: [Warning] Using a password on the command line interface can be insecure.
mysql-1 插入数据成功
mysql: [Warning] Using a password on the command line interface can be insecure.
mysql-2 插入数据成功
# 进入pod查看数据
[root@k8s-master01 job]# kubectl exec -n tcloud mysql-0 -- mysql -uroot -pTest@123 -e "use testdb; select * from t;"
mysql: [Warning] Using a password on the command line interface can be insecure.
id
0
[root@k8s-master01 job]# kubectl exec -n tcloud mysql-1 -- mysql -uroot -pTest@123 -e "use testdb; select * from t;"
mysql: [Warning] Using a password on the command line interface can be insecure.
id
1
[root@k8s-master01 job]# kubectl exec -n tcloud mysql-2 -- mysql -uroot -pTest@123 -e "use testdb; select * from t;"
mysql: [Warning] Using a password on the command line interface can be insecure.
id
2
# 删除实验所用到的资源
[root@k8s-master01 job]# kubectl delete configmaps -n tcloud mysql-cfg
[root@k8s-master01 job]# kubectl delete -f service.yaml
[root@k8s-master01 job]# kubectl delete -f statefulset.yaml
[root@k8s-master01 job]# kubectl delete -f job.yaml 2、CronJob
CronJob控制器以Job控制器资源为其管控对象,并借助它管理pod资源对象,Job控制器定义的作业任务在其控制器资源创建之后便会立即执行,但CronJob可以以类似于Linux操作系统的周期性任务作业计划的方式控制其运行时间点及重复运行的方式。也就是说,CronJob可以在特定的时间点(反复的)去运行job任务。
使用场景:
- 数据库定时运维
- 日志与垃圾清理
- 业务定时任务
- 定时数据同步
案例:K8s 定时集群健康巡检
定时任务需要使用kubelet命令,需要自己制作镜像
# 在云服务器使用docker制作
[root@iZatn52hwp5l42Z ~]# mkdir -p /opt/self-kubectl-img
[root@iZatn52hwp5l42Z ~]# cd /opt/self-kubectl-img
[root@iZatn52hwp5l42Z self-kubectl-img]# wget https://dl.k8s.io/release/v1.28.2/bin/linux/amd64/kubectl
[root@iZatn52hwp5l42Z self-kubectl-img]# chmod +x kubectl
# 编写Dockerfile
[root@iZatn52hwp5l42Z self-kubectl-img]# cat > Dockerfile <<EOF
FROM busybox:1.36
COPY kubectl /usr/local/bin/
RUN chmod +x /usr/local/bin/kubectl
EOF
# 构建镜像
[root@iZatn52hwp5l42Z self-kubectl-img]# docker build -t local/busybox-kubectl:v1.28 .
# 打包镜像
[root@iZatn52hwp5l42Z self-kubectl-img]# docker save -o busybox-kubectl.tar local/busybox-kubectl:v1.28
# 把镜像包上传到每一台Kubernetes节点,导入
[root@k8s-master01 ~]# ctr -n k8s.io image import busybox-kubectl.tar
# 创建服务认证授权rabc权限
[root@k8s-master01 cronjob]# vim ServiceAccount.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: cluster-health-sa
namespace: tcloud
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cluster-health-role
rules:
- apiGroups: [""]
resources: ["nodes", "pods"]
verbs: ["get", "list"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: cluster-health-rb
subjects:
- kind: ServiceAccount
name: cluster-health-sa
namespace: tcloud
roleRef:
kind: ClusterRole
name: cluster-health-role
apiGroup: rbac.authorization.k8s.io
# 编写cronjob文件
[root@k8s-master01 cronjob]# vim crontab.ymal
apiVersion: batch/v1
kind: CronJob
metadata:
name: cluster-health-check
namespace: tcloud
spec:
# 每分钟执行一次
schedule: "*/1 * * * *"
# 禁止并发:上一个没跑完,跳过本次
concurrencyPolicy: Forbid
# 错过30秒不再补跑
startingDeadlineSeconds: 30
# 保留成功/失败历史各3个
successfulJobsHistoryLimit: 3
failedJobsHistoryLimit: 3
jobTemplate:
spec:
# 任务最长运行60秒,超时强制终止
activeDeadlineSeconds: 60
# 失败不重启Pod
backoffLimit: 0
template:
spec:
serviceAccountName: cluster-health-sa
restartPolicy: Never
containers:
- name: health-check
image: local/busybox-kubectl:v1.28
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- |
echo "====================================================="
echo " K8s 集群健康巡检报告"
echo "====================================================="
echo "执行时间: $(date '+%Y-%m-%d %H:%M:%S')"
echo "命名空间: tcloud"
echo "====================================================="
echo -e "\n===== 1. 集群节点列表 ====="
kubectl get nodes -o wide
echo -e "\n===== 2. 检测非就绪节点 ====="
UNREADY_NODE=$(kubectl get nodes --no-headers | grep -v Ready)
if [ -n "$UNREADY_NODE" ]; then
echo "❌ 检测到未就绪节点:"
echo "$UNREADY_NODE"
exit 1
else
echo "✅ 所有节点全部就绪"
fi
echo -e "\n===== 3. 检测异常Pod ====="
ERROR_POD=$(kubectl get pods -A --no-headers \
| grep -E "CrashLoopBackOff|Error|Pending|Evicted|ImagePullBackOff|ErrImagePull")
if [ -n "$ERROR_POD" ]; then
echo "❌ 检测到异常Pod:"
echo "$ERROR_POD"
exit 1
else
echo "✅ 全局所有Pod状态正常"
fi
echo -e "\n====================================================="
echo "✅ 本次集群巡检全部通过"
echo "====================================================="
# apply
[root@k8s-master01 cronjob]# kubectl apply -f ServiceAccount.yaml
[root@k8s-master01 cronjob]# kubectl apply -f crontab.ymal
# 查看cronjob
[root@k8s-master01 cronjob]# kubectl get cronjob -n tcloud
NAME SCHEDULE TIMEZONE SUSPEND ACTIVE LAST SCHEDULE AGE
cluster-health-check */1 * * * * <none> False 1 3s 69s
# 查看job
[root@k8s-master01 cronjob]# kubectl get job -n tcloud
NAME STATUS COMPLETIONS DURATION AGE
cluster-health-check-29625369 Complete 1/1 3s 87s
cluster-health-check-29625370 Complete 1/1 3s 27s
# 查看pod
[root@k8s-master01 cronjob]# kubectl get pod -n tcloud
NAME READY STATUS RESTARTS AGE
cluster-health-check-29625369-kg5pg 0/1 Completed 0 101s
cluster-health-check-29625370-646hl 0/1 Completed 0 41s
# 查看日志
[root@k8s-master01 cronjob]# kubectl logs -n tcloud cluster-health-check-29625369-kg5pg
=====================================================
K8s 集群健康巡检报告
=====================================================
执行时间: 2026-04-30 04:09:00
命名空间: tcloud
=====================================================
===== 1. 集群节点列表 =====
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-master01 Ready <none> 10d v1.34.1 192.168.1.10 <none> CentOS Linux 7 (Core) 5.4.226-1.el7.elrepo.x86_64 containerd://1.6.20
k8s-master02 Ready <none> 10d v1.34.1 192.168.1.11 <none> CentOS Linux 7 (Core) 5.4.226-1.el7.elrepo.x86_64 containerd://1.6.20
k8s-master03 Ready <none> 10d v1.34.1 192.168.1.12 <none> CentOS Linux 7 (Core) 5.4.226-1.el7.elrepo.x86_64 containerd://1.6.20
k8s-node01 Ready <none> 10d v1.34.1 192.168.1.13 <none> CentOS Linux 7 (Core) 5.4.226-1.el7.elrepo.x86_64 containerd://1.6.20
k8s-node02 Ready <none> 10d v1.34.1 192.168.1.14 <none> CentOS Linux 7 (Core) 5.4.226-1.el7.elrepo.x86_64 containerd://1.6.20
k8s-node03 Ready <none> 10d v1.34.1 192.168.1.15 <none> CentOS Linux 7 (Core) 5.4.226-1.el7.elrepo.x86_64 containerd://1.6.20
===== 2. 检测非就绪节点 =====
✅ 所有节点全部就绪
===== 3. 检测异常Pod =====
✅ 全局所有Pod状态正常
=====================================================
✅ 本次集群巡检全部通过
=====================================================
# 删除资源
[root@k8s-master01 cronjob]# kubectl delete -f ServiceAccount.yaml
[root@k8s-master01 cronjob]# kubectl delete -f crontab.ymal 3、初始化容器initContainer
初始化容器是在pod的主容器启动之前要运行的容器,主要是做一些主容器的前置工作,它具有两大特征:
- 初始化容器必须运行完成直至结束,若某初始化容器运行失败,那么kubernetes需要重启它直到成功完成
- 初始化容器必须按照定义的顺序执行,当且仅当前一个成功之后,后面的一个才能运行
初始化容器有很多的应用场景,下面列出的是最常见的几个:
-
创建业务所需目录
-
初始化配置文件
-
设置目录权限
-
预热完成再启动主业务容器
创建使用初始化容器的pod
[root@k8s-master01 init]# vim init-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: vue-login-app
namespace: tcloud
spec:
replicas: 1
selector:
matchLabels:
app: vue-login
template:
metadata:
labels:
app: vue-login
spec:
# ==============================================
# 初始化容器(串行执行)
# 1. 检测域名解析是否就绪
# 2. 节点预热:创建目录、权限、配置
# ==============================================
initContainers:
# -------------------
# Init 1: 域名解析检测
# -------------------
- name: check-dns
image: local/busybox-kubectl:v1.28
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- |
echo "===== 检测K8s域名解析是否就绪 ====="
until nslookup kubernetes.default.svc; do
echo "域名未就绪,等待3秒..."
sleep 3
done
echo "✅ 域名解析正常!"# ------------------- # Init 2: 节点预热 # ------------------- - name: node-preheat image: local/busybox-kubectl:v1.28 imagePullPolicy: IfNotPresent volumeMounts: - name: data-volume mountPath: /data command: - /bin/sh - -c - | echo "===== 开始节点预热 =====" mkdir -p /data/logs /data/nginx/cache chmod -R 755 /data echo "✅ 目录创建完成" echo "✅ 权限初始化完成" echo "✅ 节点预热完成!" # ============================================== # 主容器:你的 vue-login 业务镜像 # ============================================== containers: - name: vue-login image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0 imagePullPolicy: IfNotPresent ports: - containerPort: 80 volumeMounts: - name: data-volume mountPath: /data # 共享存储卷 volumes: - name: data-volume emptyDir: {}
其中emptyDir = 临时空目录
流程:
-
Init 容器(node-preheat)
- 挂载 emptyDir →
/data - 创建目录:
/data/logs、/data/nginx/cache - 设置权限
- 挂载 emptyDir →
-
emptyDir 保存这些目录和文件
-
主容器(vue-login)
-
挂载 同一个 emptyDir →
/data -
直接使用 Init 容器创建好的目录
-
可以读写日志、缓存
在另一个窗口查看pod的生命周期状态
[root@k8s-master01 ~]# kubectl get pod -n tcloud -w
apply
[root@k8s-master01 init]# kubectl apply -f init-deployment.yaml
pod的生命周期
[root@k8s-master01 ~]# kubectl get pod -n tcloud -w
NAME READY STATUS RESTARTS AGE
vue-login-app-5c64cbb49c-qbn6r 0/1 Pending 0 0s
vue-login-app-5c64cbb49c-qbn6r 0/1 Pending 0 0s
vue-login-app-5c64cbb49c-qbn6r 0/1 Init:0/2 0 0s
vue-login-app-5c64cbb49c-qbn6r 0/1 Init:1/2 0 1s
vue-login-app-5c64cbb49c-qbn6r 0/1 PodInitializing 0 2s
vue-login-app-5c64cbb49c-qbn6r 1/1 Running 0 3s
Init:0/2 → 刚开始运行 2 个初始化容器
Init:1/2 → 第 1 个 Init 容器完成(DNS 检测)
PodInitializing → 第 2 个 Init 容器完成(节点预热)
Running → 主容器 vue-login 启动成功!查看初始化的日志,这里需要-C指定初始化容器
[root@k8s-master01 init]# kubectl logs -n tcloud vue-login-app-5c64cbb49c-qbn6r -c check-dns
===== 检测K8s域名解析是否就绪 =====
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.localName: kubernetes.default.svc
Address 1: 10.96.0.1 kubernetes.default.svc.cluster.local
✅ 域名解析正常!
[root@k8s-master01 init]# kubectl logs -n tcloud vue-login-app-5c64cbb49c-qbn6r -c node-preheat
===== 开始节点预热 =====
✅ 目录创建完成
✅ 权限初始化完成
✅ 节点预热完成!进入pod查看目录是否创建
[root@k8s-master01 init]# kubectl exec -it -n tcloud vue-login-app-5c64cbb49c-qbn6r -- bash
Defaulted container "vue-login" out of: vue-login, check-dns (init), node-preheat (init)
root@vue-login-app-5c64cbb49c-qbn6r:/# ls -l /data/
total 0
drwxr-xr-x 2 root root 6 Apr 30 05:26 logs
drwxr-xr-x 3 root root 19 Apr 30 05:26 nginx
如果不使用emptydir 目录会跟随初始化容器的结束而删除
-
4、pod调度
1)定向调度
定向调度,指的是利用在pod上声明nodeName或者nodeSelector,以此将Pod调度到期望的node节点上。注意,这里的调度是强制的,这就意味着即使要调度的目标Node不存在,也会向上面进行调度,只不过pod运行失败而已。
NodeName
直接强制把 Pod 绑定到指定节点 ,绕过调度器,不经过预选、打分,强制落在你写的节点上。
规则:
-
写了 nodeName: 节点名,Pod 只会调度到该节点
-
该节点不存在 / 宕机 / 不可调度 → Pod 永远 Pending
-
不支持弹性、不自动漂移,纯手动写死
[root@k8s-master01 nodename]# vim vue-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: vue-login
namespace: tcloud
spec:
replicas: 2
selector:
matchLabels:
app: vue-login
template:
metadata:
labels:
app: vue-login
spec:
# 定向调度:写要固定的节点名
nodeName: k8s-node01containers: - name: vue-login image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0 imagePullPolicy: IfNotPresent ports: - containerPort: 80apply
[root@k8s-master01 nodename]# kubectl apply -f vue-deployment.yaml
查看pod的运行在那个节点上
[root@k8s-master01 nodename]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
vue-login-6fc46b59d5-bwqpl 1/1 Running 0 17s 10.244.85.235 k8s-node01
vue-login-6fc46b59d5-prp9n 1/1 Running 0 17s 10.244.85.236 k8s-node01删除其中一个pod
[root@k8s-master01 nodename]# kubectl delete pod -n tcloud vue-login-6fc46b59d5-bwqpl
查看pod的运行节点
[root@k8s-master01 nodename]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
vue-login-6fc46b59d5-prp9n 1/1 Running 0 80s 10.244.85.236 k8s-node01
vue-login-6fc46b59d5-swpkl 1/1 Running 0 2s 10.244.85.237 k8s-node01
还是node01删除资源
[root@k8s-master01 nodename]# kubectl delete -f vue-deployment.yaml
NodeSelector
给节点打标签 → Pod 根据标签选择节点 → 只调度到符合标签的机器上
# 给k8s-node01节点打赏标签
[root@k8s-master01 nodename]# kubectl label nodes k8s-node01 app=vue
# 查看节点的标签
[root@k8s-master01 nodename]# kubectl get nodes --show-labels
# 编辑deployment文件
[root@k8s-master01 nodeselector]# vim nodeselector.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: vue-login
namespace: tcloud
spec:
replicas: 1
selector:
matchLabels:
app: vue-login
template:
metadata:
labels:
app: vue-login
spec:
nodeSelector:
app: vue # 只调度到有 app=vue 标签的节点
containers:
- name: vue-login
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
# apply
[root@k8s-master01 nodeselector]# kubectl apply -f nodeselector.yaml
# 查看pod运行的节点
[root@k8s-master01 nodeselector]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
vue-login-658b98d7c5-2qt9h 1/1 Running 0 25s 10.244.85.238 k8s-node01 <none> <none>
# 删除pod重建
[root@k8s-master01 nodeselector]# kubectl delete pod -n tcloud vue-login-658b98d7c5-2qt9h
# 再次查看pod的运行节点
[root@k8s-master01 nodeselector]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
vue-login-658b98d7c5-6hnbg 1/1 Running 0 13s 10.244.85.239 k8s-node01 <none> <none>
# 删除资源
[root@k8s-master01 nodeselector]# kubectl delete -f nodeselector.yaml
# 删除标签
[root@k8s-master01 nodeselector]# kubectl label nodes k8s-node01 app-2)亲和性调度
两种定向调度的方式,使用起来非常方便,但是也有一定的问题,那就是如果没有满足条件的Node,那么Pod将不会被运行,即使在集群中还有可用Node列表也不行,这就限制了它的使用场景。
基于上面的问题,kubernetes还提供了一种亲和性调度(Affinity)。它在NodeSelector的基础之上的进行了扩展,可以通过配置的形式,实现优先选择满足条件的Node进行调度,如果没有,也可以调度到不满足条件的节点上,使调度更加灵活。
Affinity主要分为三类:
- nodeAffinity(node亲和性): 以node为目标,解决pod可以调度到哪些node的问题
- podAffinity(pod亲和性) : 以pod为目标,解决pod可以和哪些已存在的pod部署在同一个拓扑域中的问题
- podAntiAffinity(pod反亲和性) : 以pod为目标,解决pod不能和哪些已存在pod部署在同一个拓扑域中的问题
NodeAffinity(节点亲和性)
Pod,只想跑在「有某个标签」的节点上;可以设 必须在这(硬策略)、尽量在这(软策略)
硬策略
关键参数:requiredDuringSchedulingIgnoredDuringExecution
# 先给节点打标签
[root@k8s-master01 nodeselector]# kubectl label nodes k8s-node01 role=web
[root@k8s-master01 nodeselector]# kubectl label nodes k8s-node02 role=web
[root@k8s-master01 nodeselector]# kubectl label nodes k8s-node03 role=db
# 编写硬策略的yaml文件
[root@k8s-master01 nodeselector]# vim NodeAffinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: vue-nodeaffinity-hard
namespace: tcloud
spec:
replicas: 2
selector:
matchLabels:
app: vue-hard
template:
metadata:
labels:
app: vue-hard
spec:
containers:
- name: vue-login
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
imagePullPolicy: IfNotPresent
# ====================== 节点亲和性配置(硬亲和,必须满足)======================
affinity:
nodeAffinity:
# 硬亲和策略:调度时必须满足,不满足则Pod无法调度(运行时不生效)
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
# 节点必须包含标签 key=role
- key: role
# 操作符:节点标签的值必须在指定列表中
operator: In
# 允许的值:节点标签 role=web 才能调度
values:
- web
# apply
[root@k8s-master01 nodeselector]# kubectl apply -f NodeAffinity.yaml
# 查看pod的运行节点
[root@k8s-master01 nodeselector]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
vue-nodeaffinity-hard-6486578875-67wv9 1/1 Running 0 30s 10.244.58.208 k8s-node02 <none> <none>
vue-nodeaffinity-hard-6486578875-zp7tw 1/1 Running 0 30s 10.244.85.240 k8s-node01 <none> <none>
# 硬策略特点
强制匹配,不匹配就 Pending
效果比 nodeSelector 更强,支持多条件、复杂运算符
适合业务必须跑在指定业务节点
# 现在把node01的标签删除
[root@k8s-master01 nodeselector]# kubectl label nodes k8s-node01 role-
# 扩容副本改成5
[root@k8s-master01 nodeselector]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
vue-nodeaffinity-hard-6486578875-67wv9 1/1 Running 0 6m48s 10.244.58.208 k8s-node02 <none> <none>
vue-nodeaffinity-hard-6486578875-ctc6z 1/1 Running 0 11s 10.244.58.210 k8s-node02 <none> <none>
vue-nodeaffinity-hard-6486578875-n6vpz 1/1 Running 0 11s 10.244.58.209 k8s-node02 <none> <none>
vue-nodeaffinity-hard-6486578875-r7pb4 1/1 Running 0 11s 10.244.58.211 k8s-node02 <none> <none>
vue-nodeaffinity-hard-6486578875-zp7tw 1/1 Running 0 6m48s 10.244.85.240 k8s-node01 <none> <none>
已经运行的 Pod 不会被驱逐
新扩容 / 重建的 Pod 就不能调度到 node01 了
# 删除资源
[root@k8s-master01 nodeselector]# kubectl delete -f NodeAffinity.yaml
[root@k8s-master01 nodeselector]# kubectl label nodes k8s-node02 role-
[root@k8s-master01 nodeselector]# kubectl label nodes k8s-node03 role-软策略
pod尽量运行在符合的节点,没有也行
关键参数:preferredDuringSchedulingIgnoredDuringExecution
# 打标签
[root@k8s-master01 nodeselector]# kubectl label nodes k8s-node01 env=test
[root@k8s-master01 nodeselector]# kubectl label nodes k8s-node02 env=test
# 创建软策略的yaml文件
[root@k8s-master01 nodeselector]# vim NodeAffinity-vue.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: vue-nodeaffinity-soft
namespace: tcloud
spec:
replicas: 2
selector:
matchLabels:
app: vue-soft
template:
metadata:
labels:
app: vue-soft
spec:
containers:
- name: vue-login
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
imagePullPolicy: IfNotPresent
affinity:
nodeAffinity:
# 软亲和策略:调度时优先满足,不满足也可正常调度运行(运行时不生效)
preferredDuringSchedulingIgnoredDuringExecution:
# 权重值10,权重越高,优先调度的倾向越强
- weight: 10
preference:
matchExpressions:
# 匹配节点标签 key=env
- key: env
# 操作符:节点标签值在指定列表中
operator: In
# 优先调度到 标签env=test 的节点上
values:
- test
# apply
[root@k8s-master01 nodeselector]# kubectl apply -f NodeAffinity-vue.yaml
# 查看pod的运行节点
[root@k8s-master01 nodeselector]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
vue-nodeaffinity-soft-677465f496-pnpjj 1/1 Running 0 90s 10.244.58.213 k8s-node02 <none> <none>
vue-nodeaffinity-soft-677465f496-tnlxq 1/1 Running 0 90s 10.244.85.241 k8s-node01 <none> <none>
# 把node1和node2的标签删除
[root@k8s-master01 nodeselector]# kubectl label nodes k8s-node01 env-
node/k8s-node01 unlabeled
[root@k8s-master01 nodeselector]# kubectl label nodes k8s-node02 env-
node/k8s-node02 unlabeled
# 删除pod重建
[root@k8s-master01 nodeselector]# kubectl delete pod -n tcloud -l app=vue-soft
# 查看pod的运行节点
[root@k8s-master01 nodeselector]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
vue-nodeaffinity-soft-677465f496-mbszx 1/1 Running 0 4s 10.244.135.132 k8s-node03 <none> <none>
vue-nodeaffinity-soft-677465f496-xqh7r 1/1 Running 0 4s 10.244.195.50 k8s-master03 <none> <none>
不满足的也可以运行
# 删除资源
[root@k8s-master01 nodeselector]# kubectl delete -f NodeAffinity-vue.yaml PodAffinity(pod亲和性)
新 Pod 要跟 已存在的某类 Pod 调度在同一个拓扑域(同一节点 / 同可用区)
适用场景:
前端后端,业务和reids要就近部署,减少网络延迟
硬亲和
新的 Pod 必须 和 目标 Pod 部署在同一个拓扑域(同一节点)不满足 → 直接 Pending,绝不调度!
关键参数:requiredDuringSchedulingIgnoredDuringExecution
# 创建一个被依赖的pod
[root@k8s-master01 podAffinity]# vim podaffinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis
namespace: tcloud
spec:
replicas: 1
selector:
matchLabels:
app: redis
template:
metadata:
labels:
app: redis
spec:
containers:
- name: redis
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
imagePullPolicy: IfNotPresent
# apply查看跑在那个节点
[root@k8s-master01 podAffinity]# kubectl apply -f podaffinity.yaml
[root@k8s-master01 podAffinity]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
redis-7b6f9ff8cd-lt792 1/1 Running 0 12s 10.244.58.214 k8s-node02 <none> <none>
# 创建硬亲和的pod
[root@k8s-master01 podAffinity]# vim hard-podaffinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: pod-affinity-hard
namespace: tcloud
spec:
replicas: 2
selector:
matchLabels:
app: backend
template:
metadata:
labels:
app: backend
spec:
containers:
- name: vue-login
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
imagePullPolicy: IfNotPresent
# ==============================
# Pod 硬亲和(核心配置)
# ==============================
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- redis # 必须跟标签 app=redis 的 Pod 在一起
topologyKey: kubernetes.io/hostname # 同一节点才算同一个域topologyKey:拓扑域,主要针对宿主机,相当于对宿主机进行区域的划分。用label进行判断,不同的key和不同的value是属于不同的拓扑域
# apply查看运行在那个节点
[root@k8s-master01 podAffinity]# kubectl apply -f hard-podaffinity.yaml
[root@k8s-master01 podAffinity]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-affinity-hard-599cb76bd8-4c7x2 1/1 Running 0 2s 10.244.58.215 k8s-node02 <none> <none>
pod-affinity-hard-599cb76bd8-7vl4d 1/1 Running 0 2s 10.244.58.217 k8s-node02 <none> <none>
redis-7b6f9ff8cd-lt792 1/1 Running 0 3m6s 10.244.58.214 k8s-node02 <none> <none>
可以发现pod找到了我们设定的规则 也运行在node02上了
# 删除依赖pod
[root@k8s-master01 podAffinity]# kubectl delete -f podaffinity.yaml
# 再删除硬亲和的pod
[root@k8s-master01 podAffinity]# kubectl delete pod -n tcloud pod-affinity-hard-599cb76bd8-2d6nh
# 查看重建的pod跑到那个节点
[root@k8s-master01 podAffinity]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-affinity-hard-599cb76bd8-4s2wd 0/1 Pending 0 14s <none> <none> <none> <none>
pod-affinity-hard-599cb76bd8-75cch 1/1 Running 0 76s 10.244.58.219 k8s-node02 <none> <none>
状态是Pending,找不到对应的pod,所以直接Pending
# 删除资源
[root@k8s-master01 podAffinity]# kubectl delete -f hard-podaffinity.yaml 软亲和
尽量和目标 Pod 部署在同一拓扑域,有位置就凑一起,没位置也能调度到其他节点,不会 Pending
关键参数:preferredDuringSchedulingIgnoredDuringExecution
# 创建依赖pod
[root@k8s-master01 podAffinity]# kubectl apply -f podaffinity.yaml
# 创建软亲和的yaml文件
[root@k8s-master01 podAffinity]# vim soft-podaffinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: pod-affinity-soft
namespace: tcloud
spec:
replicas: 3
selector:
matchLabels:
app: backend-soft
template:
metadata:
labels:
app: backend-soft
spec:
containers:
- name: vue-login
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
imagePullPolicy: IfNotPresent
affinity:
podAffinity:
# 软亲和:尽量在一起
preferredDuringSchedulingIgnoredDuringExecution:
# 权重 1~100,数值越大优先程度越高
- weight: 100
podAffinityTerm:
# 找 app=redis 的 Pod
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- redis
# 按同一节点作为拓扑域
topologyKey: kubernetes.io/hostname
# apply
[root@k8s-master01 podAffinity]# kubectl apply -f soft-podaffinity.yaml
# 查看运行的节点,都是node02
[root@k8s-master01 podAffinity]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-affinity-soft-5cb99988f7-c4vfx 1/1 Running 0 14s 10.244.58.222 k8s-node02 <none> <none>
pod-affinity-soft-5cb99988f7-dklzw 1/1 Running 0 14s 10.244.58.221 k8s-node02 <none> <none>
pod-affinity-soft-5cb99988f7-g5mg2 1/1 Running 0 14s 10.244.58.223 k8s-node02 <none> <none>
redis-7b6f9ff8cd-58jsg 1/1 Running 0 2m45s 10.244.58.220 k8s-node02 <none> <none>
# 删除依赖pod,在删除软亲和的pod
[root@k8s-master01 podAffinity]# kubectl delete -f podaffinity.yaml
[root@k8s-master01 podAffinity]# kubectl delete pod -n tcloud pod-affinity-soft-5cb99988f7-c4vfx
# 查看重建的pod运行在那个节点
[root@k8s-master01 podAffinity]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-affinity-soft-5cb99988f7-dklzw 1/1 Running 0 86s 10.244.58.221 k8s-node02 <none> <none>
pod-affinity-soft-5cb99988f7-dxn47 1/1 Running 0 24s 10.244.135.133 k8s-node03 <none> <none>
pod-affinity-soft-5cb99988f7-g5mg2 1/1 Running 0 86s 10.244.58.223 k8s-node02 <none> <none>
重建的pod运行在了node03上
# 删除资源
[root@k8s-master01 podAffinity]# kubectl delete -f soft-podaffinity.yaml PodAntiAffinity(pod反亲和性)
PodAntiAffinity主要实现以运行的Pod为参照,让新创建的Pod跟参照pod不在一个区域中的功能。
多副本强制打散到不同节点,避免一台节点挂了,服务全挂,保障高可用。
硬反亲和
同一个拓扑域(同一节点)不能存在多个相同标签的 Pod必须打散,做不到就 Pending,绝不扎堆。生产用来做高可用:多副本强制分到不同节点,防止单节点挂掉服务全崩。
可以用来反本身的标签,也可以反别的pod的标签
关键参数:requiredDuringSchedulingIgnoredDuringExecution
[root@k8s-master01 podAntiAffinity]# vim hard-podAntiAffinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-antiaff-hard
namespace: tcloud
spec:
replicas: 6 # 副本数6
selector:
matchLabels:
app: web-antiaff-hard
template:
metadata:
labels:
app: web-antiaff-hard # Pod 标签,反亲和依据这个标签匹配
spec:
containers:
- name: vue-login
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
imagePullPolicy: IfNotPresent # 本地有镜像就不拉取,没有才拉取
# ====================== 硬反亲和配置 ======================
affinity:
# Pod 反亲和:不让相同的 Pod 调度到同一类节点
podAntiAffinity:
# 硬反亲和(必须满足,不满足则调度失败,Pod 处于 Pending)
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
# 选择带有以下标签的 Pod
matchExpressions:
- key: app # 标签 key
operator: In # 操作符:属于以下值列表
values:
# 根据自身的标签打散pod运行节点
- web-antiaff-hard # 标签 value,和当前 Pod 标签一致
# 拓扑域:以节点为单位(不同 node 视为不同域)
# kubernetes.io/hostname 表示:每个节点是一个独立域
topologyKey: kubernetes.io/hostname
# 我们这里是副本的是6,因为我们的集群共有6个节点,master上没有打污点所有master也可以运行
# apply
[root@k8s-master01 podAntiAffinity]# kubectl apply -f hard-podAntiAffinity.yaml
# 查看pod的运行节点
[root@k8s-master01 podAntiAffinity]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-antiaff-hard-7d6c64ff9c-cqm8p 1/1 Running 0 3m31s 10.244.135.134 k8s-node03 <none> <none>
web-antiaff-hard-7d6c64ff9c-fzszg 1/1 Running 0 3m31s 10.244.195.51 k8s-master03 <none> <none>
web-antiaff-hard-7d6c64ff9c-h7crk 1/1 Running 0 3m31s 10.244.58.224 k8s-node02 <none> <none>
web-antiaff-hard-7d6c64ff9c-hcxv7 1/1 Running 0 3m31s 10.244.32.166 k8s-master01 <none> <none>
web-antiaff-hard-7d6c64ff9c-qxpv9 1/1 Running 0 3m31s 10.244.85.243 k8s-node01 <none> <none>
web-antiaff-hard-7d6c64ff9c-x5csn 1/1 Running 0 3m31s 10.244.122.150 k8s-master02 <none> <none>
都是运行在不用的节点
# 现在扩容到7副本
# 查看pod运行节点
[root@k8s-master01 podAntiAffinity]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-antiaff-hard-7d6c64ff9c-cqm8p 1/1 Running 0 4m36s 10.244.135.134 k8s-node03 <none> <none>
web-antiaff-hard-7d6c64ff9c-fzszg 1/1 Running 0 4m36s 10.244.195.51 k8s-master03 <none> <none>
web-antiaff-hard-7d6c64ff9c-h7crk 1/1 Running 0 4m36s 10.244.58.224 k8s-node02 <none> <none>
web-antiaff-hard-7d6c64ff9c-hcxv7 1/1 Running 0 4m36s 10.244.32.166 k8s-master01 <none> <none>
web-antiaff-hard-7d6c64ff9c-qxpv9 1/1 Running 0 4m36s 10.244.85.243 k8s-node01 <none> <none>
web-antiaff-hard-7d6c64ff9c-rr48w 0/1 Pending 0 7s <none> <none> <none> <none>
web-antiaff-hard-7d6c64ff9c-x5csn 1/1 Running 0 4m36s 10.244.122.150 k8s-master02 <none> <none>
可以看到直接Pending了
# 删除资源
[root@k8s-master01 podAntiAffinity]# kubectl delete -f hard-podAntiAffinity.yaml 软反亲和
尽量把同服务副本分散、不挤在同一节点,节点资源紧张、不够分时,允许挤在同一节点,不会出现 Pending,容错性很强
关键参数:preferredDuringSchedulingIgnoredDuringExecution
# 创建软反亲和的pod
[root@k8s-master01 podAntiAffinity]# vim soft-podAntiAffinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-antiaff-soft # Deployment名称
namespace: tcloud # 命名空间
spec:
replicas: 6 # 副本数:6个Pod
selector:
matchLabels:
app: web-antiaff-soft # 标签选择器,管理带此标签的Pod
template:
metadata:
labels:
app: web-antiaff-soft # Pod自带标签,反亲和依据此标签匹配
spec:
containers:
- name: vue-login
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
imagePullPolicy: IfNotPresent # 本地有镜像则不拉取,提高启动速度
# ====================== Pod 软反亲和配置 ======================
affinity:
# Pod反亲和:尽量让相同Pod分散调度
podAntiAffinity:
# 软反亲和(重点)
# 规则:尽量满足,不满足也可以调度,不会导致Pod Pending
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100 # 权重:1-100,数值越高,优先级越强
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app # 匹配标签的key
operator: In # 操作符:包含在values列表中
values:
- web-antiaff-soft # 以自身的标签打散,比如集群中有一个app = mysql 的 不想和这个mysql服务跑在同一个节点,就更换为mysql就行
# 拓扑域:以节点为单位(每个节点是一个独立域)
# 作用:尽量不让带相同标签的Pod调度到同一个节点
topologyKey: kubernetes.io/hostname
# apply 查看pod运行节点
[root@k8s-master01 podAntiAffinity]# kubectl apply -f soft-podAntiAffinity.yaml
[root@k8s-master01 podAntiAffinity]# kubectl get pod -n tcloud -o wide
[root@k8s-master01 podAntiAffinity]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-antiaff-soft-9b5ff75c-5r7sm 1/1 Running 0 10s 10.244.32.167 k8s-master01 <none> <none>
web-antiaff-soft-9b5ff75c-6lg9j 1/1 Running 0 10s 10.244.122.151 k8s-master02 <none> <none>
web-antiaff-soft-9b5ff75c-dcqn8 1/1 Running 0 10s 10.244.58.225 k8s-node02 <none> <none>
web-antiaff-soft-9b5ff75c-fl6q7 1/1 Running 0 10s 10.244.85.244 k8s-node01 <none> <none>
web-antiaff-soft-9b5ff75c-kdmfz 1/1 Running 0 10s 10.244.195.52 k8s-master03 <none> <none>
web-antiaff-soft-9b5ff75c-vtk68 1/1 Running 0 10s 10.244.135.135 k8s-node03 <none> <none>
# 扩容副本为7
[root@k8s-master01 podAntiAffinity]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-antiaff-soft-9b5ff75c-5r7sm 1/1 Running 0 55s 10.244.32.167 k8s-master01 <none> <none>
web-antiaff-soft-9b5ff75c-6lg9j 1/1 Running 0 55s 10.244.122.151 k8s-master02 <none> <none>
web-antiaff-soft-9b5ff75c-dcqn8 1/1 Running 0 55s 10.244.58.225 k8s-node02 <none> <none>
web-antiaff-soft-9b5ff75c-fl6q7 1/1 Running 0 55s 10.244.85.244 k8s-node01 <none> <none>
web-antiaff-soft-9b5ff75c-kdmfz 1/1 Running 0 55s 10.244.195.52 k8s-master03 <none> <none>
web-antiaff-soft-9b5ff75c-vtk68 1/1 Running 0 55s 10.244.135.135 k8s-node03 <none> <none>
web-antiaff-soft-9b5ff75c-z5th8 1/1 Running 0 3s 10.244.58.226 k8s-node02 <none> <none>
新pod运行在node02上了,状态也是running
# 删除资源
[root@k8s-master01 podAntiAffinity]# kubectl delete -f soft-podAntiAffinity.yaml 3)污点和容忍
污点 Taint:打在节点上,相当于节点设门槛、拒接普通 Pod
容忍 Toleration:打在Pod上,相当于 Pod有通行证,能容忍节点污点、被调度上去
kubernetes有一些内置污点(触发自动打,无需手动操作)
| 污点 Key | 触发条件 | 默认 Effect |
|---|---|---|
node.kubernetes.io/not-ready |
节点未就绪 Ready=False | NoSchedule、NoExecute |
node.kubernetes.io/unreachable |
节点失联、kubelet 断连 Ready=Unknown | NoSchedule、NoExecute |
node.kubernetes.io/memory-pressure |
内存压力不足 | NoSchedule |
node.kubernetes.io/disk-pressure |
磁盘空间 / IO 压力大 | NoSchedule |
node.kubernetes.io/pid-pressure |
系统进程 PID 耗尽 | NoSchedule |
node.kubernetes.io/network-unavailable |
网络插件未就绪 | NoSchedule |
node.kubernetes.io/unschedulable |
手动执行 kubectl cordon 锁节点 | NoSchedule |
三种策略:
-
NoSchedule:绝不调度新 Pod 过来,已在上面的不驱逐
-
PreferNoSchedule:尽量不调度,实在没节点也能调度
-
NoExecute:绝不调度 + 已在节点上的 Pod 直接驱逐
给节点打污点
kubectl taint nodes 节点名 key=value:NoSchedule
查看节点污点
kubectl describe node 节点名 | grep Taints
删除污点(末尾加 -)
kubectl taint nodes 节点名 key=value:NoSchedule-
污点常用场景:
- master 节点默认有污点,普通 Pod 不上调度,保证控制平面独占
- 特殊机器隔离:日志节点、监控节点、数据库节点,只允许专属 Pod 部署
- 节点维护时打 NoExecute,驱逐 Pod 做迁移
- 区分业务环境:生产 / 测试节点隔离
容忍有5种标准写法
1、精确匹配(最常用)
tolerations:
- key: "app"
operator: "Equal"
value: "test"
effect: "NoSchedule"2、匹配同key所有Effect
不写 effect,匹配该 key 下所有污点效果
tolerations:
- key: "app"
operator: "Equal"
value: "test"3、Exists只匹配key(任意value)
只要节点有这个 key 就容忍,不用写 value
tolerations:
- key: "app"
operator: "Exists"4、万能容忍(匹配所有污点)
空 key+Exists,无视所有节点污点
tolerations:
- operator: "Exists"5、NoExecute延迟驱逐
设置 tolerationSeconds 延迟驱逐时间
tolerations:
- key: "node"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 300NoSchedule
绝不调度新 Pod 过来,已在上面的不驱逐
# 给k8s-node01打NoSchedule污点
[root@k8s-master01 ~]# kubectl taint node k8s-node01 node=lock:NoSchedule
# 查看节点污点
[root@k8s-master01 ~]# kubectl describe node k8s-node01 | grep Taints
Taints: node=lock:NoSchedule
# 查看node01上之前运行的pod
[root@k8s-master01 Taint]# kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
calico-kube-controllers-658896864b-4w6hn 1/1 Running 12 (130m ago) 8d 192.168.1.11 k8s-master02 <none> <none>
calico-node-8krq6 1/1 Running 14 (130m ago) 11d 192.168.1.13 k8s-node01 <none> <none>
calico-node-fs4zn 1/1 Running 14 (130m ago) 11d 192.168.1.10 k8s-master01 <none> <none>
calico-node-g6pr2 1/1 Running 14 (130m ago) 11d 192.168.1.11 k8s-master02 <none> <none>
calico-node-l9m8k 1/1 Running 14 (130m ago) 11d 192.168.1.15 k8s-node03 <none> <none>
calico-node-nj6jh 1/1 Running 14 (130m ago) 11d 192.168.1.14 k8s-node02 <none> <none>
calico-node-ps59q 1/1 Running 14 (130m ago) 11d 192.168.1.12 k8s-master03 <none> <none>
coredns-6659878fb9-5tvrj 1/1 Running 14 (130m ago) 11d 10.244.122.149 k8s-master02 <none> <none>
metrics-server-6f49b5d9d9-xd7wm 1/1 Running 25 (130m ago) 11d 10.244.85.242 k8s-node01 <none> <none>
也是没有被驱赶的
# 创建deployment
[root@k8s-master01 Taint]# vim taint-noschedule-no-tol.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: taint-no-tol
namespace: tcloud
spec:
replicas: 10
selector:
matchLabels:
app: taint-no-tol
template:
metadata:
labels:
app: taint-no-tol
spec:
containers:
- name: vue-login
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
imagePullPolicy: IfNotPresent
# apply查看pod运行的节点
[root@k8s-master01 Taint]# kubectl apply -f taint-noschedule-no-tol.yaml
[root@k8s-master01 Taint]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
taint-no-tol-9575648d8-7xm6p 1/1 Running 0 6s 10.244.135.137 k8s-node03 <none> <none>
taint-no-tol-9575648d8-9l97x 1/1 Running 0 6s 10.244.32.168 k8s-master01 <none> <none>
taint-no-tol-9575648d8-cmfs9 1/1 Running 0 6s 10.244.122.153 k8s-master02 <none> <none>
taint-no-tol-9575648d8-hn5wh 1/1 Running 0 6s 10.244.58.227 k8s-node02 <none> <none>
taint-no-tol-9575648d8-ldzw9 1/1 Running 0 6s 10.244.195.54 k8s-master03 <none> <none>
taint-no-tol-9575648d8-lrtrh 1/1 Running 0 6s 10.244.32.169 k8s-master01 <none> <none>
taint-no-tol-9575648d8-n2dtq 1/1 Running 0 6s 10.244.122.152 k8s-master02 <none> <none>
taint-no-tol-9575648d8-p559w 1/1 Running 0 6s 10.244.58.228 k8s-node02 <none> <none>
taint-no-tol-9575648d8-sbkth 1/1 Running 0 6s 10.244.135.136 k8s-node03 <none> <none>
taint-no-tol-9575648d8-w8v24 1/1 Running 0 6s 10.244.195.53 k8s-master03 <none> <none>
发现node01上没有pod运行
# 删除deployment
[root@k8s-master01 Taint]# kubectl delete deployments.apps -n tcloud taint-no-tol
# 修改deployment加上容忍
[root@k8s-master01 Taint]# vim taint-noschedule-no-tol.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: taint-has-tol
namespace: tcloud
spec:
replicas: 4
selector:
matchLabels:
app: taint-has-tol
template:
metadata:
labels:
app: taint-has-tol
spec:
containers:
- name: vue-login
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
imagePullPolicy: IfNotPresent
# 容忍匹配 node=lock:NoSchedule 污点
tolerations:
- key: "node"
operator: "Equal"
value: "lock"
effect: "NoSchedule"
# apply查看运行节点
[root@k8s-master01 Taint]# kubectl apply -f taint-noschedule-no-tol.yaml
[root@k8s-master01 Taint]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
taint-has-tol-db79db4c-mv5hz 1/1 Running 0 7s 10.244.135.139 k8s-node03 <none> <none>
taint-has-tol-db79db4c-pwzrk 1/1 Running 0 7s 10.244.58.230 k8s-node02 <none> <none>
taint-has-tol-db79db4c-r45qq 1/1 Running 0 7s 10.244.85.246 k8s-node01 <none> <none>
taint-has-tol-db79db4c-sfdj9 1/1 Running 0 7s 10.244.195.56 k8s-master03 <none> <none>
可以发现node01上有pod运行,说明他容忍了这个污点
# 清除污点
[root@k8s-master01 Taint]# kubectl taint nodes k8s-node01 node=lock:NoSchedule-
[root@k8s-master01 Taint]# kubectl delete -f taint-noschedule-no-tol.yaml PreferNoSchedule
尽量不把 Pod 调度到该污点节点
能迁就就迁就,没其他节点时也能调度上去
不会把 Pod 卡成 Pending,只是调度偏好
整体环境规划
3 台 master:打 NoSchedule 污点,禁止业务 Pod 调度进来(生产标准做法)
k8s-node01:打 PreferNoSchedule 软污点
k8s-node02、k8s-node03:无污点,正常业务节点
用 Pod 资源请求压满 node02/node03,观察多余 Pod只能被迫跑到 node01,不会跑到 master
# 给所有master节点打NoSchedule污点
[root@k8s-master01 Taint]# kubectl taint nodes k8s-master01 node-role.kubernetes.io/control-plane:NoSchedule
node/k8s-master01 tainted
[root@k8s-master01 Taint]# kubectl taint nodes k8s-master02 node-role.kubernetes.io/control-plane:NoSchedule
node/k8s-master02 tainted
[root@k8s-master01 Taint]# kubectl taint nodes k8s-master03 node-role.kubernetes.io/control-plane:NoSchedule
3 台 master:有 NoSchedule 污点 → 普通业务 Pod 进不来
3 台 node:纯业务调度节点
# 给node01打PreferNoSchedule 软污点
[root@k8s-master01 Taint]# kubectl taint nodes k8s-node01 app=soft:PreferNoSchedule
# 编写压力测试yaml
[root@k8s-master01 Taint]# vim pressure.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: prefer-pressure
namespace: tcloud
spec:
replicas: 3
selector:
matchLabels:
app: prefer-pressure
template:
metadata:
labels:
app: prefer-pressure
spec:
containers:
- name: vue-login
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
imagePullPolicy: IfNotPresent
# 资源请求:1核1500Mi,单node最多跑1个
resources:
requests:
cpu: "1000m"
memory: "1500Mi"
# apply
[root@k8s-master01 Taint]# kubectl apply -f pressure.yaml
# 查看pod运行节点
[root@k8s-master01 Taint]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
prefer-pressure-86dd98c4b5-dnqpf 1/1 Running 0 2m23s 10.244.85.247 k8s-node01 <none> <none>
prefer-pressure-86dd98c4b5-qxh9h 1/1 Running 0 2m23s 10.244.58.231 k8s-node02 <none> <none>
prefer-pressure-86dd98c4b5-tzwn9 1/1 Running 0 2m23s 10.244.135.140 k8s-node03 <none> <none>
可以看见node02和node03的资源被占满,多余的副本只能跑到打了软污点的node01上
# 清除污点
[root@k8s-master01 Taint]# kubectl taint nodes k8s-node01 app=soft:PreferNoSchedule-
[root@k8s-master01 Taint]# kubectl taint nodes k8s-master01 node-role.kubernetes.io/control-plane:NoSchedule-
[root@k8s-master01 Taint]# kubectl taint nodes k8s-master02 node-role.kubernetes.io/control-plane:NoSchedule-
[root@k8s-master01 Taint]# kubectl taint nodes k8s-master03 node-role.kubernetes.io/control-plane:NoSchedule-
# 删除deployment
[root@k8s-master01 Taint]# kubectl delete -f pressure.yaml NoExecute
禁止新 Pod 调度到该节点(和 NoSchedule 一样)
立刻驱逐已经在节点上运行的旧 Pod
没有对应容忍的 Pod,直接被踢走
# 查看集群的所有pod运行节点
[root@k8s-master01 Taint]# kubectl get pod -A -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
ingress-nginx ingress-nginx-controller-5zbcx 1/1 Running 8 (154m ago) 5d17h 192.168.1.10 k8s-master01 <none> <none>
kube-system calico-kube-controllers-658896864b-4w6hn 1/1 Running 12 (154m ago) 8d 192.168.1.11 k8s-master02 <none> <none>
kube-system calico-node-8krq6 1/1 Running 14 (154m ago) 11d 192.168.1.13 k8s-node01 <none> <none>
kube-system calico-node-fs4zn 1/1 Running 14 (154m ago) 11d 192.168.1.10 k8s-master01 <none> <none>
kube-system calico-node-g6pr2 1/1 Running 14 (154m ago) 11d 192.168.1.11 k8s-master02 <none> <none>
kube-system calico-node-l9m8k 1/1 Running 14 (154m ago) 11d 192.168.1.15 k8s-node03 <none> <none>
kube-system calico-node-nj6jh 1/1 Running 14 (154m ago) 11d 192.168.1.14 k8s-node02 <none> <none>
kube-system calico-node-ps59q 1/1 Running 14 (154m ago) 11d 192.168.1.12 k8s-master03 <none> <none>
kube-system coredns-6659878fb9-5tvrj 1/1 Running 14 (154m ago) 11d 10.244.122.149 k8s-master02 <none> <none>
kube-system metrics-server-6f49b5d9d9-xd7wm 1/1 Running 25 (154m ago) 11d 10.244.85.242 k8s-node01 <none> <none>
node01上运行的pod有:
ingress-nginx-controller-5zbcx
calico-node-8krq6
metrics-server-6f49b5d9d9-xd7wm
# 给node01上打NoExecute污点
[root@k8s-master01 Taint]# kubectl taint nodes k8s-node01 test=evict:NoExecute
# 查看pod的运行节点变化
[root@k8s-master01 Taint]# kubectl get pod -A -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
ingress-nginx ingress-nginx-controller-l59g4 1/1 Running 0 36m 192.168.1.10 k8s-master01 <none> <none>
kube-system calico-kube-controllers-658896864b-4w6hn 1/1 Running 12 (3h18m ago) 9d 192.168.1.11 k8s-master02 <none> <none>
kube-system calico-node-8krq6 1/1 Running 14 (3h18m ago) 11d 192.168.1.13 k8s-node01 <none> <none>
kube-system calico-node-fs4zn 1/1 Running 14 (3h18m ago) 11d 192.168.1.10 k8s-master01 <none> <none>
kube-system calico-node-g6pr2 1/1 Running 14 (3h18m ago) 11d 192.168.1.11 k8s-master02 <none> <none>
kube-system calico-node-l9m8k 1/1 Running 14 (3h18m ago) 11d 192.168.1.15 k8s-node03 <none> <none>
kube-system calico-node-nj6jh 1/1 Running 14 (3h18m ago) 11d 192.168.1.14 k8s-node02 <none> <none>
kube-system calico-node-ps59q 1/1 Running 14 (3h18m ago) 11d 192.168.1.12 k8s-master03 <none> <none>
kube-system coredns-6659878fb9-5tvrj 1/1 Running 14 (3h18m ago) 11d 10.244.122.149 k8s-master02 <none> <none>
kube-system metrics-server-6f49b5d9d9-45qx9 1/1 Running 0 69s 10.244.58.232 k8s-node02 <none> <none>
发现只有metrics-server被驱逐到node02上了,calico没有被驱逐,是因为calico的容忍是万能容忍
kubectl describe daemonset -n kube-system calico-node | grep NoExecute
:NoExecute op=Exists
# 编写无容忍的pod强制调度到node01
[root@k8s-master01 Taint]# vim deploy-evict.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: taint-no-tol
namespace: tcloud
spec:
replicas: 1
selector:
matchLabels:
app: taint-no-tol
template:
metadata:
labels:
app: taint-no-tol
spec:
# 强制运行在 node01
nodeName: k8s-node01
containers:
- name: vue-login
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
imagePullPolicy: IfNotPresent
# apply 查看pod运行情况
[root@k8s-master01 Taint]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
taint-no-tol-7859cdbf4d-29mhf 0/1 Terminating 0 17s <none> k8s-node01 <none> <none>
taint-no-tol-7859cdbf4d-2q4z4 0/1 Terminating 0 2s <none> k8s-node01 <none> <none>
taint-no-tol-7859cdbf4d-45hkj 0/1 Terminating 0 16s <none> k8s-node01 <none> <none>
taint-no-tol-7859cdbf4d-4kfgd 0/1 Terminating 0 17s <none> k8s-node01 <none> <none>
taint-no-tol-7859cdbf4d-4w5ld 0/1 Terminating 0 5s <none> k8s-node01 <none> <none>
taint-no-tol-7859cdbf4d-55mrc 0/1 Terminating 0 12s <none> k8s-node01 <none> <none>
taint-no-tol-7859cdbf4d-5gfm2 0/1 Terminating 0 1s <none> k8s-node01 <none> <none>
taint-no-tol-7859cdbf4d-5jt6x 0/1 Pending 0 0s <none> k8s-node01 <none>
...
可以看到状态一致在删除,重建,因为强制让pod运行在node01上
# 删除deployment
[root@k8s-master01 Taint]# kubectl delete -f deploy-evict.yaml
# 编辑yaml文件添加容忍NoExecte
[root@k8s-master01 Taint]# vim deploy-evict.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: taint-no-tol
namespace: tcloud
spec:
replicas: 1
selector:
matchLabels:
app: taint-no-tol
template:
metadata:
labels:
app: taint-no-tol
spec:
# 强制运行在 node01
nodeName: k8s-node01
containers:
- name: vue-login
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
imagePullPolicy: IfNotPresent
# 容忍 NoExecute 污点(必须和污点一致)
tolerations:
- key: "test"
operator: "Equal"
value: "evict"
effect: "NoExecute"
# apply 查看pod运行情况
[root@k8s-master01 Taint]# kubectl get pod -n tcloud -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
taint-no-tol-56ffb7b844-6v8xz 1/1 Running 0 34s 10.244.85.248 k8s-node01 <none> <none>
加了容忍就可以运行在node01上了
# 清除环境
[root@k8s-master01 Taint]# kubectl delete -f deploy-evict.yaml
# 清除污点
[root@k8s-master01 Taint]# kubectl taint nodes k8s-node01 test=evict:NoExecute-二、资源管控
1、ResourceQuota
ResourceQuota 是生产集群的「资源保险丝」,防止业务 "裸奔",避免一个应用拖垮整个集群。
它是 Kubernetes 的内置准入控制资源,作用于整个 Namespace,用来限制该命名空间下所有资源的总使用量
它可以限制:
- 计算资源:requests.cpu / requests.memory / limits.cpu / limits.memory
- 存储资源:PVC 数量、总存储容量
- 资源对象数量:Pod、Deployment、Service、ConfigMap 等的最大数量
1)为什么生产一定要使用ResourceQuota
1、防止【资源泄漏】导致节点被打满
如果没有 ResourceQuota:
- 某个应用出现 Bug,不断创建新 Pod 或占用大量内存 / CPU
- 它会耗尽节点资源,导致同节点的其他业务被挤掉、节点宕机
- 严重时会引发集群雪崩
有了 ResourceQuota:
- 命名空间的总资源被锁死,应用再怎么泄漏,也不会超出配额
- 其他业务、节点、集群整体稳定性不受影响
2、强制用户资源声明资源,避免"裸奔"pod
很多用户部署应用时,会忘记写 requests/limits:
- 没 requests:调度器无法知道该 Pod 实际需要多少资源,可能调度到资源不足的节点,导致 Pod 运行缓慢甚至崩溃
- 没 limits:Pod 可以无限制占用节点资源,直接拖垮宿主机
配合 LimitRange + ResourceQuota:
- LimitRange 给没写资源的 Pod 注入默认值
- ResourceQuota 限制总使用量,避免用户 "裸奔"
3、多租户环境的资源隔离与公平分配
在多团队共用的集群里,每个团队一个 Namespace:
- 没有 ResourceQuota:资源抢用、互相影响,谁的应用能占资源谁就赢
- 有 ResourceQuota:
- 每个团队的资源配额是固定的,比如 dev 命名空间 4 核 8G,prod 命名空间 16 核 32G
- 避免开发环境业务占用生产环境资源,保障核心业务的资源优先级
4、控制成本,避免资源浪费
- 云环境下,CPU / 内存 / 存储都是按用量计费的
- 没有 ResourceQuota,用户可能随意创建大量高规格 Pod,导致账单飙升
- 有了 ResourceQuota,配额上限 = 成本上限,预算可控
5、防止恶意攻击或误操作
- 误操作:比如 kubectl scale deployment app --replicas=1000,瞬间创建上千个 Pod
- 恶意行为:攻击者利用集群漏洞,创建大量资源耗尽集群
2)资源配额
ResourceQuota 三大核心层级:metadata /spec/status
1. metadata
包含 ResourceQuota 的名称、所属命名空间、标签、注解等标准元数据。特点:资源配额仅对当前所在 namespace 生效。
2. spec
只包含核心配置项 hard(硬限制),超出直接拒绝创建资源。常用限制项:
requests.cpu:命名空间内所有 Pod CPU 请求总量上限
limits.cpu:命名空间内所有 Pod CPU 限制总量上限
requests.memory:命名空间内所有 Pod 内存请求总量上限
limits.memory:命名空间内所有 Pod 内存限制总量上限
persistentvolumeclaims:允许创建 PVC 的总数量
pods:允许运行 Pod 最大总数
还可限制:configmaps、secrets、services 等对象个数
3. status
系统自动维护,无需手动配置:
展示各类资源当前已使用量
展示各类资源配额硬上限
直观看到 已用 / 总量 占用情况
# 创建ResourceQuota
[root@k8s-master01 ResourceQuota]# vim ResourceQuota.yaml
apiVersion: v1
kind: ResourceQuota # 资源类型:资源配额
metadata:
name: tcloud-quota # 配额名称
namespace: tcloud # 只对 tcloud 这个命名空间生效
spec:
hard: # hard = 硬限制,绝对不能超过
# ========== 1. 计算资源限制(最重要) ==========
requests.cpu: "4" # 所有Pod的CPU请求总和 ≤ 4核
requests.memory: "8Gi" # 所有Pod的内存请求总和 ≤ 8G
limits.cpu: "8" # 所有Pod的CPU限制总和 ≤ 8核
limits.memory: "16Gi" # 所有Pod的内存限制总和 ≤ 16G
# ========== 2. Pod数量限制 ==========
pods: "5" # 这个命名空间最多跑 5 个Pod
# ========== 3. 存储资源限制 ==========
persistentvolumeclaims: 5 # 最多创建5个PVC
requests.storage: "50Gi" # 所有存储请求总和 ≤ 50G
# ========== 4. K8s对象数量限制(可选) ==========
services: "2" # 最多2个Service
configmaps: "10" # 最多10个ConfigMap
secrets: "10" # 最多10个Secret
# apply
[root@k8s-master01 ResourceQuota]# kubectl apply -f ResourceQuota.yaml
# 查看配额是否生效
[root@k8s-master01 ResourceQuota]# kubectl get quota -n tcloud
NAME REQUEST LIMIT AGE
tcloud-quota configmaps: 1/10, persistentvolumeclaims: 0/5, pods: 0/5, requests.cpu: 0/4, requests.memory: 0/8Gi, requests.storage: 0/50Gi, secrets: 1/10, services: 0/2 limits.cpu: 0/8, limits.memory: 0/16Gi 48m
# 创建deployment
[root@k8s-master01 ResourceQuota]# vim deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-pod-quota
namespace: tcloud
spec:
replicas: 6
selector:
matchLabels:
app: test
template:
metadata:
labels:
app: test
spec:
containers:
- name: vue-login
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
# 必须加这个!否则被 ResourceQuota 拦截
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 500m
memory: 512Mi
# apply查看pod数量
[root@k8s-master01 ResourceQuota]# kubectl get pod -n tcloud
NAME READY STATUS RESTARTS AGE
test-pod-quota-7dbc8f55b4-45w77 1/1 Running 0 <invalid>
test-pod-quota-7dbc8f55b4-82h8c 1/1 Running 0 <invalid>
test-pod-quota-7dbc8f55b4-9qkzp 1/1 Running 0 <invalid>
test-pod-quota-7dbc8f55b4-cfkht 1/1 Running 0 <invalid>
test-pod-quota-7dbc8f55b4-fdxts 1/1 Running 0 <invalid>
只能创建5个第6个被拦截
# 查看配额使用情况
[root@k8s-master01 ResourceQuota]# kubectl describe quota tcloud-quota -n tcloud
Name: tcloud-quota
Namespace: tcloud
Resource Used Hard
-------- ---- ----
configmaps 1 10
limits.cpu 2500m 8
limits.memory 2560Mi 16Gi
persistentvolumeclaims 0 5
pods 5 5
requests.cpu 500m 4
requests.memory 640Mi 8Gi
requests.storage 0 50Gi
secrets 1 10
services 0 2
# 删除资源和ResourceQuato
[root@k8s-master01 ResourceQuota]# kubectl delete -f deployment.yaml
[root@k8s-master01 ResourceQuota]# kubectl delete -f ResourceQuota.yaml 2、LimitRange
1)什么是LimitRange
只有ResoueceQuota是不够的
LimitRange 是 Kubernetes 中的一种资源对象,用于限制命名空间内单个容器或 Pod 的资源使用量。它通过定义资源的最小值、最大值和默认值,确保资源分配的合理性和公平性。
- 资源限制:限制单个容器或 Pod 的 CPU、内存等资源的使用量。
- 默认值设置:为未指定资源请求或限制的容器提供默认值。
- 避免资源浪费:防止过度分配资源,提高集群资源利用率。
ResourceQuota(总量限制) + LimitRange(自动补资源)
没有 LimitRange → 有配额也创建不了 Pod
有了 LimitRange → 自动补资源,
核心字段
| 层级 | 字段 | 作用说明 |
|---|---|---|
| metadata | name | LimitRange 资源名称 |
| metadata | namespace | 作用于当前指定命名空间,隔离生效 |
| spec.limits | type | 限制类型,常用 Container 代表针对容器生效 |
| spec.limits | default | 容器未定义 limits 时,自动补充CPU / 内存最大限制 |
| spec.limits | defaultRequest | 容器未定义 requests 时,自动补充CPU / 内存申请值 |
| spec.limits | max | 单个容器允许的 CPU、内存资源上限,超了直接拒绝创建 |
| spec.limits | min | 单个容器允许的 CPU、内存资源下限,低于下限拒绝创建 |
2)限制类型
容器、整 Pod、存储 PVC都是可以限制的
| 限制类型 type | 限制对象 | 管控内容 | 作用场景 |
|---|---|---|---|
| Container | 单个容器 | 单个容器 CPU / 内存 的默认值、最大值、最小值 | 规范每个容器资源,防止单容器资源超标 |
| Pod | 整个 Pod(所有容器总和) | Pod 内所有容器合计 CPU / 内存 最大、最小值 | 限制一个 Pod 整体资源占用,避免 Pod 过大拖垮节点 |
| PersistentVolumeClaim | PVC 持久卷声明 | 单个 PVC 存储容量的默认值、最大值、最小值 | 管控单 PVC 存储空间,防止乱申请超大存储 |
apiVersion: v1
kind: LimitRange
metadata:
name: tcloud-lr # LimitRange 规则名称
namespace: tcloud # 仅对 tcloud 命名空间生效
spec:
limits:
# 1、Container:限制【单个容器】资源规范
- type: Container
default: # 容器未配置limits时,自动填充默认资源上限
cpu: 500m
memory: 512Mi
defaultRequest: # 容器未配置requests时,自动填充默认资源申请值
cpu: 100m
memory: 128Mi
max: # 单个容器允许的CPU/内存最大上限,超出拒绝创建
cpu: 2
memory: 2Gi
min: # 单个容器允许的CPU/内存最小下限,低于拒绝创建
cpu: 50m
memory: 64Mi
# 2、Pod:限制【整个Pod所有容器总和】资源
- type: Pod
max: # 单个Pod所有容器合计资源最大上限
cpu: 4
memory: 4Gi
min: # 单个Pod所有容器合计资源最小下限
cpu: 100m
memory: 256Mi
# 3、PersistentVolumeClaim:限制【PVC存储】容量
- type: PersistentVolumeClaim
max: # 单个PVC允许申请的存储最大容量
storage: 100Gi
min: # 单个PVC允许申请的存储最小容量
storage: 1Gi
default: # PVC未指定存储大小时,自动填充默认容量
storage: 10Gi3)配置默认资源限制
# 创建LimitRange
[root@k8s-master01 limitrange]# vim limitrange.yaml
apiVersion: v1
kind: LimitRange
metadata:
name: tcloud-lr # 规则名字叫 tcloud-lr
namespace: tcloud # 只管 tcloud 这个命名空间
spec:
limits:
- type: Container # 【容器】
# --------------- 规矩 1:自动补默认值 ----------------
default: # 如果容器没写 limits
cpu: 500m # 自动给 0.5核上限
memory: 512Mi # 自动给 512M上限
defaultRequest: # 如果容器没写 requests
cpu: 100m # 自动给 0.1核申请
memory: 128Mi # 自动给 128M申请
# --------------- 规矩 2:最大能配多少 ----------------
max: # 单个容器【最大】不能超过
cpu: 2 # 2核
memory: 2Gi # 2G内存
# --------------- 规矩 3:最小能配多少 ----------------
min: # 单个容器【最小】不能低于
cpu: 50m # 0.05核
memory: 64Mi # 64M
# apply
[root@k8s-master01 limitrange]# kubectl apply -f limitrange.yaml
# 查看LimitRange
[root@k8s-master01 limitrange]# kubectl get limitrange -n tcloud
NAME CREATED AT
tcloud-lr 2026-05-01T08:03:04Z
[root@k8s-master01 limitrange]# kubectl describe limitrange tcloud-lr -n tcloud
Name: tcloud-lr
Namespace: tcloud
Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio
---- -------- --- --- --------------- ------------- -----------------------
Container cpu 50m 2 100m 500m -
Container memory 64Mi 2Gi 128Mi 512Mi -
# 创建不写资源配置的deployment
[root@k8s-master01 limitrange]# vim deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-lr-deploy
namespace: tcloud
spec:
replicas: 3
selector:
matchLabels:
app: vue
template:
metadata:
labels:
app: vue
spec:
containers:
- name: vue-login
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
# apply查看pod
[root@k8s-master01 limitrange]# kubectl get pod -n tcloud
NAME READY STATUS RESTARTS AGE
test-lr-deploy-547c68ccfd-brpf7 1/1 Running 0 43s
test-lr-deploy-547c68ccfd-gf4z4 1/1 Running 0 43s
test-lr-deploy-547c68ccfd-j9wfl 1/1 Running 0 43s
# 查看是否注入了Resources
[root@k8s-master01 limitrange]# kubectl get pod -n tcloud test-lr-deploy-547c68ccfd-brpf7 -o yaml | grep -A 10 resources
resources:
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 100m
memory: 128Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
--
resources:
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 100m
memory: 128Mi
restartCount: 0
started: true
state:
running:
Pod 自动拥有了 requests 和 limits!
# 删除deployment
[root@k8s-master01 limitrange]# kubectl delete -f deployment.yaml
# 创建超出资源的deployment
[root@k8s-master01 limitrange]# vim deploy-over-limit.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-over-limit
namespace: tcloud
spec:
replicas: 1
selector:
matchLabels:
app: over
template:
metadata:
labels:
app: over
spec:
containers:
- name: vue-login
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
resources:
limits:
cpu: 3 # 超过 max: 2
memory: 3Gi # 超过 max: 2Gi
# apply 查看pod
[root@k8s-master01 limitrange]# kubectl apply -f deploy-over-limit.yaml
[root@k8s-master01 limitrange]# kubectl get pod -n tcloud
No resources found in tcloud namespace.
发现没有pod,直接被准入控制拒绝,创建失败!
# 查看拒绝日志
[root@k8s-master01 limitrange]# kubectl get events -n tcloud --sort-by=.metadata.creationTimestamp
...
is 3, maximum memory usage per Container is 2Gi, but limit is 3Gi]
3m21s Normal ScalingReplicaSet deployment/deploy-over-limit Scaled up replica set deploy-over-limit-6b499c4df7 from 0 to 1
3m21s Warning FailedCreate replicaset/deploy-over-limit-6b499c4df7 Error creating: pods "deploy-over-limit-6b499c4df7-tjbv6" is forbidden: [maximum cpu usage per Container is 2, but limit is 3, maximum memory usage per Container is 2Gi, but limit is 3Gi]
3m21s Warning FailedCreate replicaset/deploy-over-limit-6b499c4df7 Error creating: pods "deploy-over-limit-6b499c4df7-bftgs" is forbidden: [maximum cpu usage per Container is 2, but limit is 3, maximum memory usage per Container is 2Gi, but limit is 3Gi]
3m21s Warning FailedCreate replicaset/deploy-over-limit-6b499c4df7 Error creating: pods "deploy-over-limit-6b499c4df7-9fkrv" is forbidden: [maximum cpu usage per Container is 2, but limit is 3, maximum memory usage per Container is 2Gi, but limit is 3Gi]
3m21s Warning FailedCreate replicaset/deploy-over-limit-6b499c4df7 Error creating: pods "deploy-over-limit-6b499c4df7-svbld" is forbidden: [maximum cpu usage per Container is 2, but limit is 3, maximum memory usage per Container is 2Gi, but limit is 3Gi]
3m21s Warning FailedCreate replicaset/deploy-over-limit-6b499c4df7 Error creating: pods "deploy-over-limit-6b499c4df7-x7htx" is forbidden: [maximum cpu usage per Container is 2, but limit is 3, maximum memory usage per Container is 2Gi, but limit is 3Gi]
3m20s Warning FailedCreate replicaset/deploy-over-limit-6b499c4df7 Error creating: pods "deploy-over-limit-6b499c4df7-59kh5" is forbidden: [maximum cpu usage per Container is 2, but limit is 3, maximum memory usage per Container is 2Gi, but limit is 3Gi]
3m20s Warning FailedCreate replicaset/deploy-over-limit-6b499c4df7 Error creating: pods "deploy-over-limit-6b499c4df7-v95xk" is forbidden: [maximum cpu usage per Container is 2, but limit is 3, maximum memory usage per Container is 2Gi, but limit is 3Gi]
3m19s Warning FailedCreate replicaset/deploy-over-limit-6b499c4df7 Error creating: pods "deploy-over-limit-6b499c4df7-dnjf7" is forbidden: [maximum cpu usage per Container is 2, but limit is 3, maximum memory usage per Container is 2Gi, but limit is 3Gi]
37s Warning FailedCreate replicaset/deploy-over-limit-6b499c4df7 (combined from similar events): Error creating: pods "deploy-over-limit-6b499c4df7-fb6vl" is forbidden: [maximum cpu usage per Container is 2, but limit is 3, maximum memory usage per Container is 2Gi, but limit is 3Gi]
说明:
创建失败:Pod 被禁止创建
原因:
1. 单个容器最大允许 CPU 是 2核,却申请了 3核
2. 单个容器最大允许内存是 2Gi,却申请了 3Gi
# 也可以看RS的详细信息,就是创建的deployment管理的RS信息
[root@k8s-master01 limitrange]# kubectl describe replicaset -n tcloud deploy-over-limit-6b499c4df7
......
Warning FailedCreate <invalid> replicaset-controller Error creating: pods "deploy-over-limit-6b499c4df7-dnjf7" is forbidden: [maximum cpu usage per Container is 2, but limit is 3, maximum memory usage per Container is 2Gi, but limit is 3Gi]
Warning FailedCreate <invalid> (x8 over <invalid>) replicaset-controller (combined from similar events): Error creating: pods "deploy-over-limit-6b499c4df7-brmmv" is forbidden: [maximum cpu usage per Container is 2, but limit is 3, maximum memory usage per Container is 2Gi, but limit is 3Gi]
# 清除资源
[root@k8s-master01 limitrange]# kubectl delete -f limitrange.yaml
[root@k8s-master01 limitrange]# kubectl delete -f deploy-over-limit.yaml 3、Quality of Service(服务质量)
1)什么是Qos
K8s 自动根据 Pod 里容器的 requests /limits 配置,把 Pod 划分成三种服务质量等级。
作用:
- 节点资源紧张时,决定先驱逐谁、后驱逐谁
- 决定 OOM 谁先被杀死
- 保障核心业务优先占用资源,不被普通业务抢占
- 生产用来做可用性保障、服务分级
Qos一共分为3种:
- Guaranteed 保证型(最高优先级)
- Burstable 突发型(中等优先级)
- BestEffort 尽力型(最低优先级)
驱逐顺序(资源不够时)
BestEffort → Burstable → Guaranteed
先杀最低的,保留核心服务
# Guaranteed 保证型
# 所有容器 requests = limits(CPU、内存都相等)2)Qos详细规则
Guaranteed 保证型
满足条件
- Pod 里所有容器都必须同时配置 requests 和 limits
- CPU、内存 每项:requests = limits
特点:
- 资源完全独占、不被抢占
- 节点资源不足最后被驱逐
- 稳定性最高
生产适用
数据库、订单、支付、核心中间件、不能挂的核心服务。
[root@k8s-master01 qos]# vim qos-guaranteed.yaml
apiVersion: v1
kind: Pod
metadata:
name: qos-guaranteed
namespace: tcloud
spec:
containers:
- name: app
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
resources:
requests:
cpu: 500m
memory: 512Mi
limits:
cpu: 500m
memory: 512Mi
# 创建并查看qos
[root@k8s-master01 qos]# kubectl apply -f qos-guaranteed.yaml
[root@k8s-master01 qos]# kubectl get pod qos-guaranteed -n tcloud -o yaml | grep qosClass
qosClass: GuaranteedBurstable 突发型
满足条件
- 不满足 Guaranteed
- Pod 内至少有一个容器配置了 requests
- 常见配置:requests < limits
特点:
- 有保底资源,允许临时突发用更高资源
- 优先级中等
- 资源紧张时,比 BestEffort 晚被清理
生产适用
绝大多数普通业务、微服务、后端应用。
[root@k8s-master01 qos]# vim qos-burstable.yaml
apiVersion: v1
kind: Pod
metadata:
name: qos-burstable
namespace: tcloud
spec:
containers:
- name: app
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 500m
memory: 512Mi
# 创建并查看
[root@k8s-master01 qos]# kubectl apply -f qos-burstable.yaml
[root@k8s-master01 qos]# kubectl get pod qos-burstable -n tcloud -o yaml | grep qosClass
qosClass: BurstableBestEffort 尽力型
满足条件
- Pod 内所有容器都不写 requests、limits 任何资源配置
特点
- 无任何资源保障,只吃节点剩余空闲资源
- 资源紧张第一个被驱逐、最先被杀
生产适用
-
仅测试、开发环境、临时 Pod、离线任务;生产业务禁止使用。
[root@k8s-master01 qos]# vim qos-besteffort.yaml
apiVersion: v1
kind: Pod
metadata:
name: qos-besteffort
namespace: tcloud
spec:
containers:
- name: app
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0创建并查看
[root@k8s-master01 qos]# kubectl apply -f qos-besteffort.yaml
[root@k8s-master01 qos]# kubectl get pod qos-besteffort -n tcloud -o yaml | grep qosClass
qosClass: BestEffort
三、安全认证
1、访问控制概述
Kubernetes作为一个分布式集群的管理工具,保证集群的安全性是其一个重要的任务。所谓的安全性其实就是保证对Kubernetes的各种客户端进行认证和鉴权操作。
客户端
在Kubernetes集群中,客户端通常有两类:
- User Account:一般是独立于kubernetes之外的其他服务管理的用户账号。
- Service Account:kubernetes管理的账号,用于为Pod中的服务进程在访问Kubernetes时提供身份标识。
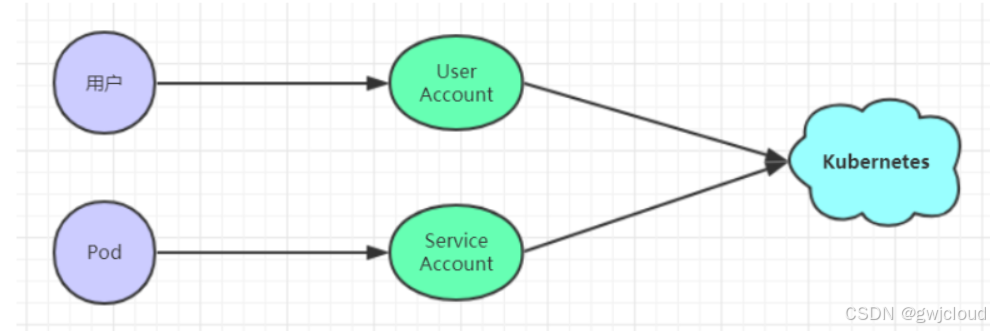
认证、授权与准入控制
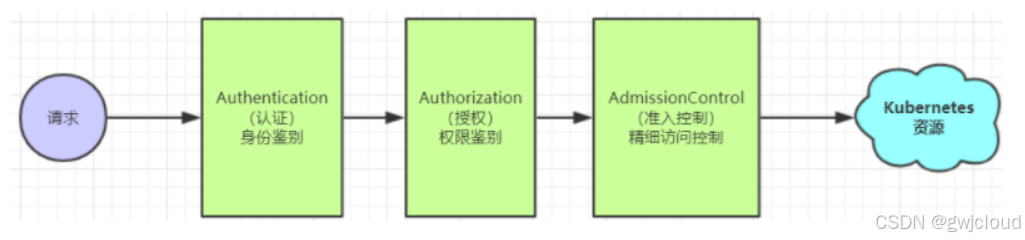
ApiServer是访问及管理资源对象的唯一入口。任何一个请求访问ApiServer,都要经过下面三个流程:
- Authentication(认证):身份鉴别,只有正确的账号才能够通过认证
- Authorization(授权): 判断用户是否有权限对访问的资源执行特定的动作
- Admission Control(准入控制):用于补充授权机制以实现更加精细的访问控制功能。
2、认证管理
在Kubernetes(简称K8s)集群中,客户端访问者主要分为两大类------普通用户与服务用户,二者的访问场景、安全需求截然不同,对应的认证方式也各有侧重。Kubernetes的客户端身份认证,从宏观通信模式上可分为HTTP Base、HTTP Token、HTTPS证书三种核心大类,从具体实现机制上可细分为7种细分方式,下文将结合「普通用户」「服务用户」的使用场景,逐一解析各类认证方式,兼顾入门正统性与生产实用性。
核心区分:普通用户指运维人员、开发人员等手动操作集群的人员;服务用户指集群内Pod、kubelet、controller-manager等自动访问API Server的组件/应用,二者认证方式的选择,核心围绕「易用性」「安全性」「自动化」三大需求。
User Account(运维/开发人员)
普通用户的核心需求是「便捷操作+适度安全」,主要通过手动方式(如kubectl命令、API调用)访问集群,适配的认证方式以宏观三大类为主
HTTP Base基础认证
采用用户名 + 密码方式,将 用户:密码 做 Base64 编码放在 HTTP 请求头中发给 APIServer,服务端解码校验身份。特点:配置简单,安全性弱,只适合测试环境,不用于生产。
HTTP Token认证
HTTP Token 认证通过一串唯一且难以伪造的 Token 字符串识别合法用户。每个 Token 对应绑定一个集群用户,客户端发起 API 请求时,在请求头中携带 Token 信息;API Server 收到请求后,将传入 Token 与服务端留存的令牌列表进行比对校验,以此确认普通用户身份合法性。相比 Base 认证安全性有所提升,配置轻量化,但令牌固定、灵活性差,仍只适用于测试和小型非生产场景。
HTTPS证书认证
HTTPS 证书认证基于 CA 根证书签名实现双向数字证书认证,是三种方式中安全性最高的一种。通信双方通过 CA 机构申请并颁发证书,客户端与 API Server 之间完成双向证书校验,确认彼此身份可信;协商加密密钥后全程密文通信,有效防止身份伪造与数据窃听。配置流程相对繁琐,但安全等级最高,是生产环境普通用户访问集群的首选认证方式。
在部署集群的时候采用的就是HTTPS的证书方式认证的
# 查看 apiserver 启动参数
systemctl cat kube-apiserver
说明:
--basic-auth-file=xxx.csv # 有这个参数 → 开启了 HTTP Base 认证
--token-auth-file=xxx.csv # 有这个参数 → 开启了 HTTP Token 认证
--client-ca-file=/etc/kubernetes/pki/ca.pem # 集群默认用 HTTPS 证书认证Service Account(服务账号)
不同于普通用户,服务用户(如集群组件、业务 Pod)无人工操作场景,其核心需求是「自动化、无需人工干预、长期安全可靠」,无法依赖手动配置的账号密码或客户端证书,因此 Kubernetes 专门设计了 ServiceAccount(服务账号) 来解决这类程序身份认证问题。
ServiceAccount 是 Kubernetes 集群内置的资源对象,专门为 Pod 和后台组件提供身份标识,是服务用户访问 API Server 的标准方式。它的核心特点是:
- 自动化身份管理:Kubernetes 会为每个 ServiceAccount 自动生成并签发 JWT 令牌,Pod 启动时默认将令牌挂载到容器内固定路径 /var/run/secrets/kubernetes.io/serviceaccount/,应用无需手动配置即可读取并使用该令牌发起 API 请求。
- 与 RBAC 深度结合:可以通过 RBAC 规则,为不同 ServiceAccount 配置精细的资源访问权限,实现最小权限原则,避免程序越权访问集群资源。
- 全生命周期托管:ServiceAccount 的创建、令牌的签发与轮换、资源的清理,均由集群控制器自动完成,无需人工干预,保障身份的安全性与一致性。
支撑 ServiceAccount(服务账号)全自动化 的核心角色,它们分工明确,共同完成「服务账号的创建、令牌的管理、Pod 挂载令牌」这一整套流程。
- ServiceAccount Admission Controller
- Token Controller
- ServiceAccount Controller
ServiceAccount Admission Controller
它是 API Server 的内置准入控制器,在 Pod 创建请求被 API Server 处理前介入,完成两项关键工作:
-
自动绑定服务账号:如果 Pod 配置中未显式指定 spec.serviceAccountName,控制器会自动为 Pod 绑定当前命名空间下的 default 服务账号,确保每个 Pod 都有合法身份标识。
-
自动挂载令牌配置:为 Pod 注入一个特殊 Volume,将服务账号对应的 JWT 令牌 Secret 挂载到容器内固定路径 /var/run/secrets/kubernetes.io/serviceaccount/,让应用无需手动配置即可读取令牌,向 API Server 发起认证请求。
查看kube-apiserver配置
[root@k8s-master01 ~]# cat /usr/lib/systemd/system/kube-apiserver.service | grep enable-admission-plugins
--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction,ResourceQuota \可以看到有ServiceAccount,说明控制器已经启用
创建deployment
[root@k8s-master01 serviceAccount]# vim deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: serviceaccount-pod
namespace: tcloud
spec:
replicas: 1
selector:
matchLabels:
app: test
template:
metadata:
labels:
app: test
spec:
containers:
- name: vue-login
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0apply
[root@k8s-master01 serviceAccount]# kubectl apply -f deployment.yaml
查看 Pod 的服务账号配置
[root@k8s-master01 serviceAccount]# kubectl get pod -n tcloud serviceaccount-pod-86b9487458-t7xnz -o yaml | grep serviceAccount
serviceAccount: default
serviceAccountName: default
- serviceAccountToken:
控制器已自动为 Pod 绑定default服务账号进入pod查看挂载令牌
[root@k8s-master01 serviceAccount]# kubectl exec -it serviceaccount-pod-86b9487458-t7xnz -n tcloud -- ls /var/run/secrets/kubernetes.io/serviceaccount/
ca.crt namespace token
控制器已将服务账号的令牌、CA 证书等文件自动挂载到容器内,应用可直接读取使用。
ServiceAccount Admission Controller 是服务账号自动化的第一道环节,它确保了所有 Pod 默认具备合法身份并自动获取认证凭证,无需人工干预配置。该控制器配合 Token Controller、ServiceAccount Controller,共同实现了服务账号从创建、令牌签发到 Pod 挂载的全流程自动化,为集群内服务用户提供了安全、便捷的认证方式。
Token Controller
Token Controller 运行在 kube-controller-manager 中,专门负责为 ServiceAccount 生成、维护和回收 JWT 令牌,是服务账号认证的 "令牌管理员"。
核心作用
1、自动创建令牌
当一个 ServiceAccount 被创建时,Token Controller 会自动为其生成对应的 Secret 资源,并签发包含服务账号身份信息的 JWT 令牌,存入该 Secret 中。(1.24+版本不生成Secret资源 )
2、令牌有效性维护
持续监控令牌状态,当令牌过期、失效或被篡改时,会自动更新并重新签发,确保服务账号的认证凭证始终有效。
3、资源生命周期同步
当 ServiceAccount 被删除时,Token Controller 会自动清理其关联的所有令牌 Secret,避免无效身份凭证残留,保障集群安全。
# 查看 controller-manager 进程参数(systemd 部署)
[root@k8s-master01 serviceAccount]# ps aux | grep kube-controller-manager
root 1033 0.1 3.1 1297344 62392 ? Ssl 09:05 0:07 /usr/local/bin/kube-controller-manager --v=2 --bind-address=127.0.0.1 --root-ca-file=/etc/kubernetes/pki/ca.pem --cluster-signing-cert-file=/etc/kubernetes/pki/ca.pem --cluster-signing-key-file=/etc/kubernetes/pki/ca-key.pem --service-account-private-key-file=/etc/kubernetes/pki/sa.key --kubeconfig=/etc/kubernetes/controller-manager.kubeconfig --leader-elect=true --use-service-account-credentials=true --node-monitor-grace-period=40s --node-monitor-period=5s --node-eviction-rate=0.1 --controllers=*,bootstrapsigner,tokencleaner --allocate-node-cidrs=true --cluster-cidr=10.244.0.0/16 --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.pem --node-cidr-mask-size=24
正常运行即代表 Token Controller 已启用。
# 创建自定义的服务账号
[root@k8s-master01 ~]# kubectl create sa test-sa -n tcloud
# 创建deployment使用创建的ServiceAccount
[root@k8s-master01 serviceAccount]# vim deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: serviceaccount-pod
namespace: tcloud
spec:
replicas: 1
selector:
matchLabels:
app: test
template:
metadata:
labels:
app: test
spec:
serviceAccountName: test-sa
containers:
- name: vue-login
image: registry.cn-hangzhou.aliyuncs.com/gwjcloud/vue-login:v1.0
# apply
[root@k8s-master01 serviceAccount]# kubectl apply -f deployment.yaml
# 查看容器内动态生成的令牌
[root@k8s-master01 serviceAccount]# kubectl exec -it serviceaccount-pod-578f9d45b6-k59s8 -n tcloud -- cat /var/run/secrets/kubernetes.io/serviceaccount/token
eyJhbGciOiJSUzI1NiIsImtpZCI6ImNpVjg4Rmd6VjBEbGZwXzE4RVl0OGhNWTBjWV94a1hhR2V3QmhQR1d4aTAifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxODA5MjI2NDUxLCJpYXQiOjE3Nzc2OTA0NTEsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwianRpIjoiNWRiNjExNWItYmFkOC00NjU3LWFiNDgtYjVmNTVjYTNkYTc4Iiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJ0Y2xvdWQiLCJub2RlIjp7Im5hbWUiOiJrOHMtbm9kZTAzIiwidWlkIjoiYjA2YjRjMGMtNTc0Ny00MTgxLWI5MDMtYWZjMjVmNTg2NmE5In0sInBvZCI6eyJuYW1lIjoic2VydmljZWFjY291bnQtcG9kLTU3OGY5ZDQ1YjYtazU5czgiLCJ1aWQiOiJmODg5M2NjZS1lZDc0LTRmYjctODMxYi1hODc1YTZjNDlkNDIifSwic2VydmljZWFjY291bnQiOnsibmFtZSI6InRlc3Qtc2EiLCJ1aWQiOiIwNmFhM2IxMy0yYjU5LTQwZWItYWMyYi04OGE5ZTBhZGM2NWQifSwid2FybmFmdGVyIjoxNzc3Njk0MDU4fSwibmJmIjoxNzc3NjkwNDUxLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6dGNsb3VkOnRlc3Qtc2EifQ.FG_oBmRR7m_UMWm1WsfMkmUmWtaZZCUz6lSZSt31kND_NiOq6w2d89omXmQel-6yg7Pho4Ady9LSkRiLNZNOxX1ZCmc6NDnFvyjZcvSU-tGFwS-QN3Tix3lscAiZ02m02UeRhScWz1jEXUw00MD0k3Zt9oz3iWVYpJlwVrH5ylJLau5BiOm3ppq1nvV8MS8mp08uy5eL0jM7FHk1Lm9vHmSD-h--sjY2NWwFPcbVbX4hu_hNbvW-hvWIEm5Vi0Jc-V8gQn-SYYOUa8SiHRglbz4mu9k3my9kPH2Umo8yFFFhtwBAD6mmIivk5D6mj1rDcmlXpqKux_XzusTPjcSS1g
输出一长串 JWT 令牌,由 Token Controller 动态签发。
# 验证令牌可访问集群API
[root@k8s-master01 serviceAccount]# kubectl exec -it serviceaccount-pod-578f9d45b6-k59s8 -n tcloud -- bash
root@serviceaccount-pod-578f9d45b6-k59s8:/# TOKEN=$(cat /var/run/secrets/kubernetes.io/serviceaccount/token)
root@serviceaccount-pod-578f9d45b6-k59s8:/# curl -H "Authorization: Bearer $TOKEN" https://kubernetes.default.svc/api/v1/namespaces/tcloud/pods -k
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {},
"status": "Failure",
"message": "pods is forbidden: User \"system:serviceaccount:tcloud:test-sa\" cannot list resource \"pods\" in API group \"\" in the namespace \"tcloud\"",
"reason": "Forbidden",
"details": {
"kind": "pods"
},
"code": 403
说明:
认证成功 ✅ 权限不足 ❌
认证成功
令牌正确、Token Controller 正常工作、ServiceAccount 认证通过API Server 认识这个用户:system:serviceaccount:tcloud:test-sa
权限不足
Kubernetes 默认安全机制:服务账号默认没有任何操作权限必须通过 RBAC 授权后才能操作资源ServiceAccount Controller
同样运行在 kube-controller-manager 中,负责服务账号生命周期管理。
-
新命名空间创建后,自动为其生成default默认服务账号;
-
维护命名空间与服务账号的关联关系,保障资源匹配;
-
删除服务账号或命名空间时,自动联动清理关联资源,避免无效身份凭证残留;
-
为整个服务账号体系提供基础资源支撑。
查看命名空间自动生成的默认服务账号
[root@k8s-master01 ~]# kubectl get sa -n tcloud
NAME SECRETS AGE
default 0 10d
test-sa 0 15m
可以看到命名空间自带 default 服务账号,由 ServiceAccount Controller 自动创建。查看当前自定义服务账号
[root@k8s-master01 ~]# kubectl get sa test-sa -n tcloud
NAME SECRETS AGE
test-sa 0 15m删除正在被 Pod 使用的服务账号
[root@k8s-master01 ~]# kubectl delete sa test-sa -n tcloud
进入原有 Pod 再次测试 API 访问
[root@k8s-master01 ~]# kubectl exec -it serviceaccount-pod-578f9d45b6-k59s8 -n tcloud -- bash
root@serviceaccount-pod-578f9d45b6-k59s8:/# TOKEN=(cat /var/run/secrets/kubernetes.io/serviceaccount/token) root@serviceaccount-pod-578f9d45b6-k59s8:/# curl -H "Authorization: Bearer TOKEN" https://kubernetes.default.svc/api/v1/namespaces/tcloud/pods -k
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {},
"status": "Failure",
"message": "Unauthorized",
"reason": "Unauthorized",
"code": 401
说明:
ServiceAccount Controller 工作完全正常
服务账号删除后,令牌立刻失效
Pod 失去合法身份权限
401 就是证明:服务账号已被系统回收,身份不合法了!
3、授权管理
认证只解决 "你是谁" 的身份识别问题,但识别身份后,并不能默认拥有集群所有资源操作权限;想要控制用户能做什么、不能做什么,就需要引入授权管理。
授权管理的核心作用,是在用户或服务账号完成身份认证之后,进一步校验该主体是否具备对某类资源执行增删改查等操作的权限,实现身份认证与权限授权分离,遵循最小权限安全原则。
API Server目前支持以下几种授权策略:
- AlwaysDeny:表示拒绝所有请求,一般用于测试
- AlwaysAllow:允许接收所有请求,相当于集群不需要授权流程(Kubernetes默认的策略)
- ABAC:基于属性的访问控制,表示使用用户配置的授权规则对用户请求进行匹配和控制
- Webhook:通过调用外部REST服务对用户进行授权
- Node:是一种专用模式,用于对kubelet发出的请求进行访问控制
- RBAC:基于角色的访问控制
RBAC(Role-Based Access Control) 基于角色的访问控制,主要是在描述一件事情:给哪些对象授予了哪些权限
其中涉及到了下面几个概念:
- 对象:User、Groups、ServiceAccount
- 角色:代表着一组定义在资源上的可操作动作(权限)的集合
- 绑定:将定义好的角色跟用户绑定在一起
1、什么是RBAC
RBAC:基于角色的访问控制
核心逻辑: 不给用户直接赋权限,先把权限打包成角色,在给用户绑定角色
- 先把一堆权限(看 Pod、删 Service、改配置)打包,起个名字叫角色;
- 有普通用户、服务账号、用户组这些主体;
- 直接把角色分给人,人就拥有角色里所有权限;
- 换人、改权限只需要改角色绑定,不用一个个改权限,好管理、符合最小权限原则。
RBAC引入了4个顶级资源对象:
| 资源 | 级别 | 作用 | 适用场景 |
|---|---|---|---|
| Role | 命名空间 | 定义命名空间内权限 | 项目权限、团队权限 |
| ClusterRole | 集群 | 定义全局权限 | 集群管理员、节点管理 |
| RoleBinding | 命名空间 | 绑定命名空间角色 | 给用户分配某个 ns 权限 |
| ClusterRoleBinding | 集群 | 绑定集群角色 | 集群管理员、全局只读账号 |
2、RBAC配置解析
所有的RBAC配置都遵循这个逻辑
apiVersion: rbac.authorization.k8s.io/v1
kind: 角色类型
metadata:
name: 名称
namespace: 命名空间(只有集群级不需要)
rules: 权限规则(角色才有)
subjects: 被授权的人/账号(绑定才有)
roleRef: 关联哪个角色(绑定才有)Role(命名空间级角色)
作用:定义某个命名空间下的权限。
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: pod-reader # 角色名
namespace: tcloud # 只在 tcloud 生效
rules:
- apiGroups: [""] # 核心组(空字符串 = core 组,如 pod、service)
resources: ["pods"] # 要控制的资源
verbs: ["get", "list", "watch"] # 允许的操作apiGroups:API 组,空 = 核心资源(pod、svc、node),apps = deployment、statefulset
resources:资源类型(pods、services、deployments 等)
verbs:权限动作
get 查看单个
list 列表查看
watch 监听变化
create 创建
update 更新
patch 部分更新
delete 删除
deletecollection 批量删除
* 所有权限ClusterRole(集群级角色)
作用:定义整个集群、所有命名空间的权限。
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cluster-pod-reader # 全局唯一名称
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list", "watch"]没有 namespace 字段
作用于整个集群
可用于集群级资源:nodes、namespaces、persistentvolumes
RoleBinding(命名空间级绑定)
作用:把 Role 绑定给 用户 / ServiceAccount / 用户组,让它获得权限。
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: pod-reader-binding
namespace: default
subjects:
- kind: User
name: tom # 用户名
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: pod-reader # 绑定的角色名
apiGroup: rbac.authorization.k8s.io- subjects :被授权的对象
- User:普通用户
- Group:用户组
- ServiceAccount:服务账号(Pod 用)
- roleRef:关联的角色(必须写全,不能省略)
ClusterRoleBinding(集群级绑定)
作用:把 ClusterRole 绑定给对象,全局生效。
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: cluster-pod-reader-binding
subjects:
- kind: User
name: tom
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: cluster-pod-reader
apiGroup: rbac.authorization.k8s.io3、RBAC实践
命名空间级Role和RoleBinding
案例:创建服务账号,创建权限,绑定权限到SA,适用于只有查看权限的人员场景,核心目标是实现"业务资源隔离、最小权限管控",避免开发人员误操作其他命名空间资源或删除、修改核心业务组件。
# 创建服务账号和role角色绑定权限
[root@k8s-master01 role]# vim rbac.yaml
# 1. 创建服务账号
apiVersion: v1
kind: ServiceAccount
metadata:
name: tcloud-dev-sa
namespace: tcloud
---
# 2. 命名空间角色:定义权限
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: tcloud-dev-role
namespace: tcloud # 关键:限定只在tcloud生效
rules:
# 核心资源权限
- apiGroups: [""]
resources: ["pods", "services", "configmaps"]
verbs: ["get", "list", "watch"]
# apps组资源权限
- apiGroups: ["apps"]
resources: ["deployments", "statefulsets"]
verbs: ["get", "list", "watch"]
---
# 3. 角色绑定:把权限赋给SA
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: tcloud-dev-bind
namespace: tcloud
subjects: # 被授权主体
- kind: ServiceAccount
name: tcloud-dev-sa
namespace: tcloud
roleRef: # 关联哪个角色
kind: Role
name: tcloud-dev-role
apiGroup: rbac.authorization.k8s.io
ServiceAccount 解析
作用:给业务 Pod / 程序使用的内置账号,代替集群超级管理员账号
必须指定 namespace: tcloud,归属当前命名空间
Role 关键字段解析
kind: Role:命名空间级角色,不能跨命名空间
apiGroups:资源分组
"" 空组:核心原生资源(pod、svc、cm)
apps:工作负载资源(deployment、statefulset)
resources:要管控的资源类型
verbs:动作权限
get/List/watch:只读
不配置 create/update/delete:禁止增删改
RoleBinding 解析
subjects:填被授权对象,这里是 tcloud 下的 SA
roleRef:固定关联本命名空间的 Role
生效范围:只在 tcloud 内有效
# apply
[root@k8s-master01 role]# kubectl apply -f rbac.yaml
# kubectl auth 是用来检查与管理 K8s 权限(RBAC)、确认当前用户身份的命令组,核心就是回答两个问题:我是谁?我能干什么?
# 1. tcloud命名空间:允许查pod
[root@k8s-master01 role]# kubectl auth can-i get pods -n tcloud --as=system:serviceaccount:tcloud:tcloud-dev-sa
yes
# 2. tcloud命名空间:禁止删pod
[root@k8s-master01 role]# kubectl auth can-i delete pods -n tcloud --as=system:serviceaccount:tcloud:tcloud-dev-sa
no
# 3. 跳到default命名空间:完全无权限
[root@k8s-master01 role]# kubectl auth can-i get pods -n default --as=system:serviceaccount:tcloud:tcloud-dev-sa
no
# 4.查deployment:有权限
[root@k8s-master01 role]# kubectl auth can-i list deployments -n tcloud --as=system:serviceaccount:tcloud:tcloud-dev-sa
yes
# 使用服务账号(ServiceAccount)来验证
[root@k8s-master01 role]# vim pod-rbac.yaml
apiVersion: v1
kind: Pod
metadata:
name: rbac-test-pod
namespace: tcloud
spec:
serviceAccountName: tcloud-dev-sa # 挂载 RBAC 账号
containers:
- name: kubectl-box
image: docker.io/local/busybox-kubectl:v1.28
command: ["sleep", "36000"]
# apply
[root@k8s-master01 role]# kubectl apply -f pod-rbac.yaml
# 进入pod测试权限
[root@k8s-master01 role]# kubectl exec -it -n tcloud rbac-test-pod -- sh
/ # kubectl get pods -n tcloud
NAME READY STATUS RESTARTS AGE
rbac-test-pod 1/1 Running 0 67s
serviceaccount-pod-86b9487458-rdjf5 1/1 Running 0 3m13s
/ # kubectl get deploy -n tcloud
NAME READY UP-TO-DATE AVAILABLE AGE
serviceaccount-pod 1/1 1 1 3m16s
/ # kubectl delete pod rbac-test-pod -n tcloud
Error from server (Forbidden): pods "rbac-test-pod" is forbidden: User "system:serviceaccount:tcloud:tcloud-dev-sa" cannot delete resource "pods" in API group "" in the namespace "tcloud"
# 也可以模拟SA的账号是验证
[root@k8s-master01 role]# kubectl get pods -n tcloud --as=system:serviceaccount:tcloud:tcloud-dev-sa
NAME READY STATUS RESTARTS AGE
rbac-test-pod 1/1 Running 0 3m15s
serviceaccount-pod-86b9487458-rdjf5 1/1 Running 0 5m21s
# 查看当前我是谁
[root@k8s-master01 role]# kubectl auth whoami
ATTRIBUTE VALUE
Username admin
Groups [system:masters system:authenticated]
Extra: authentication.kubernetes.io/credential-id [X509SHA256=977025f007c274df33e14080ec4bd70969aa6be2f94d857cdcd0733f8e100cb2]
# 模拟SA查看身份
[root@k8s-master01 role]# kubectl auth whoami --as=system:serviceaccount:tcloud:tcloud-dev-sa
ATTRIBUTE VALUE
Username system:serviceaccount:tcloud:tcloud-dev-sa
Groups [system:serviceaccounts system:serviceaccounts:tcloud system:authenticated]当然我们这里只是验证,而不是去真正使用,真实使用是去把 tcloud-dev-sa 生成可给开发直接用的 kubeconfig
作用:开发拿到这份 kubeconfig,本地 kubectl 只能操作 tcloud 命名空间、只读,跨 NS / 删改都无权限
# 创建生成kubeconfig的脚本
[root@k8s-master01 role]# vim gen-dev-kubeconfig.sh
#!/bin/bash
SA_NAME="tcloud-dev-sa"
NS_NAME="tcloud"
KUBECONFIG="./tcloud-dev-kubeconfig"
# 1.24+ 官方生成短期token(1小时有效期)
TOKEN=$(kubectl create token $SA_NAME -n $NS_NAME)
# APISERVER地址
APISERVER=$(kubectl config view --raw -o jsonpath='{.clusters[0].cluster.server}')
# CA证书base64
CA_DATA=$(kubectl config view --raw -o jsonpath='{.clusters[0].cluster.certificate-authority-data}')
# 生成独立kubeconfig,不覆盖本机~/.kube/config
cat > $KUBECONFIG <<EOF
apiVersion: v1
kind: Config
clusters:
- name: k8s
cluster:
server: ${APISERVER}
certificate-authority-data: ${CA_DATA}
contexts:
- name: tcloud-dev
context:
cluster: k8s
namespace: tcloud
user: dev-user
current-context: tcloud-dev
users:
- name: dev-user
user:
token: ${TOKEN}
EOF
echo "生成成功:$KUBECONFIG"
# 执行脚本
[root@k8s-master01 role]# chmod +x gen-dev-kubeconfig.sh
[root@k8s-master01 role]# ./gen-dev-kubeconfig.sh
生成成功:./tcloud-dev-kubeconfig
# 这样把这个kubeconfig文件给到开发
# 模拟使用tcloud-dev-kubeconfig文件来操作集群
[root@k8s-master01 role]# export KUBECONFIG=./tcloud-dev-kubeconfig
[root@k8s-master01 role]# kubectl get pods
NAME READY STATUS RESTARTS AGE
rbac-test-pod 1/1 Running 0 16m
serviceaccount-pod-86b9487458-rdjf5 1/1 Running 0 18m
[root@k8s-master01 role]# kubectl get pod -A
Error from server (Forbidden): pods is forbidden: User "system:serviceaccount:tcloud:tcloud-dev-sa" cannot list resource "pods" in API group "" at the cluster scope
可以看到我们定义了什么权限,就有什么权限
# 恢复环境
[root@k8s-master01 role]# unset KUBECONFIG
[root@k8s-master01 role]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
ingress-nginx ingress-nginx-controller-l59g4 1/1 Running 0 25h
kube-system calico-kube-controllers-658896864b-4w6hn 1/1 Running 13 (3h57m ago) 10d
kube-system calico-node-8krq6 1/1 Running 15 (3h57m ago) 12d
kube-system calico-node-fs4zn 1/1 Running 14 (28h ago) 12d
kube-system calico-node-g6pr2 1/1 Running 15 (3h57m ago) 12d
kube-system calico-node-l9m8k 1/1 Running 15 (3h57m ago) 12d
kube-system calico-node-nj6jh 1/1 Running 15 (3h57m ago) 12d
kube-system calico-node-ps59q 1/1 Running 15 (3h57m ago) 12d
kube-system coredns-6659878fb9-5tvrj 1/1 Running 15 (3h57m ago) 12d
kube-system metrics-server-6f49b5d9d9-45qx9 1/1 Running 1 (3h57m ago) 25h
tcloud rbac-test-pod 1/1 Running 0 19m
tcloud serviceaccount-pod-86b9487458-rdjf5 1/1 Running 0 21m
# 清除环境
[root@k8s-master01 role]# kubectl delete -f rbac.yaml
[root@k8s-master01 role]# kubectl delete -f pod-rbac.yaml
[root@k8s-master01 role]# kubectl delete -f deployment.yaml 当然这里可以使用集群级别的,让开发去操作整个集群
集群级ClusterRole和ClusterRolebinding
案例:适用于运维人员全局查看集群、监控、问题排查场景,实现全集群只读、禁止高危操作。
生产正式运维人员使用,基于 K8s x509 客户端证书认证,不靠 SA、不靠 Token。
原理
- 给运维签发客户端证书,设置 CN=ops-user;
- 创建 ClusterRole 定义全局只读权限;
- 创建 ClusterRoleBinding,直接绑定 User: ops-user;
- 运维用带证书的 kubeconfig 连接集群,K8s 读取证书 CN 匹配用户名,自动授权;
- 无任何 ServiceAccount,纯证书 + User 绑定模式,企业标准生产用法。
权限原理:
-
后续给运维签发客户端证书,指定 CN=ops-user;
-
定义 ClusterRole 全局只读规则;
-
通过 ClusterRoleBinding 直接绑定 User: ops-user;
-
运维携带证书连接集群,K8s 自动读取证书 CN 匹配身份,授予对应权限。
[root@k8s-master01 clusterrole]# vim rbac-cluster.yaml
1. 集群角色:定义全局只读权限
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cluster-ops-read
rules:集群核心资源 + 普通资源只读
- apiGroups: [""]
resources:- nodes
- namespaces
- persistentvolumes
- pods
- services
- configmaps
- endpoints
verbs: - get
- list
- watch
应用工作负载资源只读
- apiGroups: ["apps"]
resources:- deployments
- statefulsets
- replicasets
- daemonsets
verbs: - get
- list
- watch
2. 集群角色绑定:绑定证书用户名 ops-user(不使用SA)
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: cluster-ops-read-binding
subjects:绑定类型:User 用户名,对应客户端证书里的 CN=ops-user
- kind: User
name: ops-user
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: cluster-ops-read
apiGroup: rbac.authorization.k8s.io
apply
[root@k8s-master01 clusterrole]# kubectl apply -f rbac-cluster.yaml
查看资源
[root@k8s-master01 clusterrole]# kubectl get clusterrole | grep cluster-ops-read
cluster-ops-read 2026-05-02T06:08:06Z
[root@k8s-master01 clusterrole]# kubectl get clusterrolebinding | grep cluster-ops-read
cluster-ops-read-binding ClusterRole/cluster-ops-readauth验证权限
有权限:查看集群节点
kubectl auth can-i get nodes --as=ops-user
有权限:查看所有命名空间Pod
kubectl auth can-i get pods -A --as=ops-user
无权限:删除集群节点
kubectl auth can-i delete nodes --as=ops-user
无权限:创建命名空间
kubectl auth can-i create namespaces --as=ops-user
给运维人员创建 ops-user 证书 + kubeconfig
创建目录(存放证书)
[root@k8s-master01 ~]# mkdir -p /opt/ops-user && cd /opt/ops-user
生成私钥
[root@k8s-master01 ops-user]# openssl genrsa -out ops-user.key 2048
生成CSR
[root@k8s-master01 ops-user]# openssl req -new -key ops-user.key -out ops-user.csr -subj "/CN=ops-user"
签发证书
[root@k8s-master01 ops-user]# openssl x509 -req -in ops-user.csr -CA /etc/kubernetes/pki/ca.pem -CAkey /etc/kubernetes/pki/ca-key.pem -CAcreateserial -out ops-user.crt -days 3650
现在目录就有
ops-user.key
ops-user.csr
ops-user.crt ← 运维用户证书(已签发)生成kubeconfig
[root@k8s-master01 ops-user]# APISERVER=(kubectl config view --raw -o jsonpath='{.clusters[0].cluster.server}') [root@k8s-master01 ops-user]# CA_DATA=(base64 -w 0 /etc/kubernetes/pki/ca.pem)
[root@k8s-master01 ops-user]# CLIENT_CERT=(base64 -w 0 ops-user.crt) [root@k8s-master01 ops-user]# CLIENT_KEY=(base64 -w 0 ops-user.key)
[root@k8s-master01 ops-user]# cat > ./ops-kubeconfig << EOF
apiVersion: v1
kind: Config
clusters:- cluster:
certificate-authority-data: CA_DATA server: APISERVER
name: k8s
contexts: - context:
cluster: k8s
user: ops-user
name: ops-context
current-context: ops-context
users: - name: ops-user
user:
client-certificate-data: CLIENT_CERT client-key-data: CLIENT_KEY
EOF
当前目录会生成ops-kubeconfig文件
临时使用这个配置,只当前终端生效
[root@k8s-master01 ops-user]# export KUBECONFIG=./ops-kubeconfig
看下当前使用的那个用户(ops-user)
[root@k8s-master01 ops-user]# kubectl auth whoami
ATTRIBUTE VALUE
Username ops-user
Groups [system:authenticated]
Extra: authentication.kubernetes.io/credential-id [X509SHA256=ca323c0ce7bdebd6989c112fe4af8ac0524e2bac1d115753e207625a290a5f18]验证只读操作
[root@k8s-master01 ops-user]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready13d v1.34.1
k8s-master02 Ready13d v1.34.1
k8s-master03 Ready13d v1.34.1
k8s-node01 Ready13d v1.34.1
k8s-node02 Ready13d v1.34.1
k8s-node03 Ready13d v1.34.1
[root@k8s-master01 ops-user]# kubectl get ns
NAME STATUS AGE
default Active 13d
ingress-nginx Active 6d22h
kube-node-lease Active 13d
kube-public Active 13d
kube-system Active 13d
tcloud Active 10d
[root@k8s-master01 ops-user]# kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
ingress-nginx ingress-nginx-controller-l59g4 1/1 Running 1 (5h28m ago) 27h
kube-system calico-kube-controllers-658896864b-4w6hn 1/1 Running 13 (5h28m ago) 10d
kube-system calico-node-8krq6 1/1 Running 15 (5h28m ago) 12d
kube-system calico-node-fs4zn 1/1 Running 15 (5h28m ago) 12d
kube-system calico-node-g6pr2 1/1 Running 15 (5h28m ago) 12d
kube-system calico-node-l9m8k 1/1 Running 15 (5h28m ago) 12d
kube-system calico-node-nj6jh 1/1 Running 15 (5h28m ago) 12d
kube-system calico-node-ps59q 1/1 Running 15 (5h28m ago) 12d
kube-system coredns-6659878fb9-5tvrj 1/1 Running 15 (5h28m ago) 12d
kube-system metrics-server-6f49b5d9d9-45qx9 1/1 Running 1 (5h28m ago) 26h
[root@k8s-master01 ops-user]# kubectl get svc -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.96.0.1443/TCP 13d
ingress-nginx ingress-nginx-controller ClusterIP 10.96.26.24880/TCP,443/TCP 6d22h
kube-system kube-dns ClusterIP 10.96.0.1053/UDP,53/TCP,9153/TCP 12d
kube-system metrics-server ClusterIP 10.96.41.20443/TCP 12d
[root@k8s-master01 ops-user]# kubectl get deploy -A
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
kube-system calico-kube-controllers 1/1 1 1 12d
kube-system coredns 1/1 1 1 12d
kube-system metrics-server 1/1 1 1 12d验证禁止写操作(会报错 Forbidden)
创建命名空间
[root@k8s-master01 ops-user]# kubectl create ns test-demo
Error from server (Forbidden): namespaces is forbidden: User "ops-user" cannot create resource "namespaces" in API group "" at the cluster scope删除节点
[root@k8s-master01 ops-user]# kubectl delete node k8s-master01
Error from server (Forbidden): nodes "k8s-master01" is forbidden: User "ops-user" cannot delete resource "nodes" in API group "" at the cluster scope删除Pod
[root@k8s-master01 ops-user]# kubectl delete pod -n kube-system xxx
Error from server (Forbidden): pods "xxx" is forbidden: User "ops-user" cannot delete resource "pods" in API group "" in the namespace "kube-system"恢复权限
[root@k8s-master01 ops-user]# unset KUBECONFIG
- apiGroups: [""]
这套流程就是Kubenetes标准的多租户RBAC隔离方案
多租户(套 K8s 集群,分给多个不同用户 / 团队使用,每个人权限隔离、互不干扰,只能看自己被授权的资源。)