文章目录
- 前言
- 一、测试题目及解析
-
- [(一)Flink 生态集成(第1题)](#(一)Flink 生态集成(第1题))
- [二、Flink 运行时架构与组件](#二、Flink 运行时架构与组件)
-
- [(一)YARN 会话模式命令参数(第 2 题)](#(一)YARN 会话模式命令参数(第 2 题))
-
- 1.解析
- [2.总结:Flink YARN 会话模式常用参数](#2.总结:Flink YARN 会话模式常用参数)
- [(二)部署模式(第 3、14 题)](#(二)部署模式(第 3、14 题))
- [(三) History Server(第 4 题)](#(三) History Server(第 4 题))
-
- 1.解析
- [2.总结(Flink History Server 的核心作用)](#2.总结(Flink History Server 的核心作用))
- [(四) 核心组件职责(对应第 12、13 题)](#(四) 核心组件职责(对应第 12、13 题))
- [三、Flink API 与算子优化](#三、Flink API 与算子优化)
- [四、Flink 资源调度与并行度](#四、Flink 资源调度与并行度)
-
- [(一) TaskManager 数量计算(第 6 题)](#(一) TaskManager 数量计算(第 6 题))
- [(二)Slot 核心规则(第 7、8 题)](#(二)Slot 核心规则(第 7、8 题))
- [(三)核心概念定义(对应第 11 题)](#(三)核心概念定义(对应第 11 题))
- [五、Flink 基础概念与设计理念](#五、Flink 基础概念与设计理念)
-
- [(一) 核心设计理念(第 17 题)](#(一) 核心设计理念(第 17 题))
-
- 1.解析
- [2.总结:**Flink vs Spark Streaming 核心差异**](#2.总结:Flink vs Spark Streaming 核心差异)
- [(二)Flink 主要特点(第 18 题)](#(二)Flink 主要特点(第 18 题))
-
- 1.解析
- [2.总结:Flink 状态一致性语义](#2.总结:Flink 状态一致性语义)
- [(三)起源与发展(第 19 题)](#(三)起源与发展(第 19 题))
-
- 1.解析
- [2.总结:Flink 的发展历程](#2.总结:Flink 的发展历程)
- [(四)有界流 vs 无界流(第 20 题)](#(四)有界流 vs 无界流(第 20 题))
-
- 1.解析
- [2.总结:有界流 vs 无界流 核心对比](#2.总结:有界流 vs 无界流 核心对比)
- 总结
前言
本文是 Flink 学习笔记系列中的一篇专题总结,聚焦于 Flink 核心知识点的测试题目与详细解析。内容覆盖了 Flink 生态集成、运行时架构与组件、部署模式、History Server、核心组件职责、API 演进与分层设计、算子链优化、资源调度与并行度计算、Slot 核心规则、Flink 与 Spark Streaming 的设计理念对比,以及有界流与无界流的基础概念等。
一、测试题目及解析
(一)Flink 生态集成(第1题)
正确答案:D(与常用生态系统的良好集成)

1.解析
- 选项 A(高吞吐低延迟):这是 Flink 流处理引擎的核心性能优势,由其流水线执行、异步 Checkpoint 等机制实现,和连接外部系统的特性无关。
- 选项 B(结果的准确性):该优势来自 Flink 的事件时间、窗口机制,能对乱序数据做精准计算,和外部系统连接能力无关。
- 选项 C(精确一次的状态一致性):这是 Flink 通过 Checkpoint、两阶段提交等机制实现的状态容错能力,保障数据不丢不重,和生态集成无关。
- 选项 D(与常用生态系统的良好集成):Flink 提供了丰富的连接器(Connectors),原生支持 Kafka、Hive、HDFS 等大数据生态中主流的消息队列、存储系统,这一特性直接体现了其与常用生态系统的良好集成能力,符合题意。
2.总结:flink的核心优势
- Flink 的核心优势 之一:与常用大数据生态系统的良好集成
- 支持的连接器:
消息队列:Kafka、Pulsar、RabbitMQ
存储系统:HDFS、S3、HBase、Elasticsearch
数据仓库:Hive、Doris
数据库:MySQL、PostgreSQL(JDBC / 专用连接器)
二、Flink 运行时架构与组件
(一)YARN 会话模式命令参数(第 2 题)
正确答案:B(指定任务在 YARN UI 上显示的名称)

1.解析
- 选项 A(指定 JobManager 内存):对应参数为
-jm/--jobManagerMemory,和 -nm 无关。 - 选项 B(指定任务在 YARN UI 上显示的名称):
-nm是--name的缩写,作用是为 YARN 上的 Flink 应用设置自定义名称,该名称会直接显示在 YARN 的 Web UI 中,方便运维识别和管理,符合题意。 - 选项 C(指定分离模式运行):对应参数为
-d/--detached,用于让 Session 在后台独立运行,和-nm无关。 - 选项 D(指定 YARN 队列名):对应参数为
-qu/--queue,用于指定任务提交到的 YARN 队列,和 -nm 无关。
2.总结:Flink YARN 会话模式常用参数
- Flink YARN 会话模式常用参数速查表
| 参数 | 全称 | 作用 |
|---|---|---|
| -nm | --name | 自定义 YARN 应用名称,显示在 YARN UI |
| -jm | --jobManagerMemory | 指定 JobManager 的内存大小(单位 MB) |
| -tm | --taskManagerMemory | 指定每个 TaskManager 的内存大小(单位 MB) |
| -d | --detached | 分离模式运行,客户端退出后集群仍在后台运行 |
| -qu | --queue | 指定 YARN 队列名称 |
| -n | --container | 指定 TaskManager 的数量 |
| -s | --slots | 指定每个 TaskManager 的 Slot 数量 |
(二)部署模式(第 3、14 题)
1.第3题解析
正确答案:C(应用模式 (Application Mode))

- 选项 A(会话模式 Session Mode):main 方法在客户端执行,客户端负责生成 JobGraph 并提交给 JobManager,会占用客户端资源,不符合题意。
- 选项 B(单作业模式 Per-Job Mode):main 方法同样在客户端执行,客户端提交作业后 YARN 才启动集群,客户端资源消耗高,不符合题意。
- 选项 C(应用模式 Application Mode):这是 Flink 专为解决客户端资源消耗问题设计的模式,应用的main方法直接在 JobManager(ApplicationMaster)上执行,客户端仅负责提交作业包,提交后即可断开连接,完全避免了客户端的资源占用,符合题意。
- 选项 D(独立模式 Standalone Mode):这是 Flink 的集群部署架构,不是作业提交模式,且main方法仍在客户端执行,不符合题意。
2.第14题解析
正确答案:B (单作业模式 Per-Job Mode)

- A、会话模式 (Session Mode):先启动一个长期运行的共享 YARN 集群,所有提交的作业都复用这个集群,不会为每个作业单独启动集群,资源隔离性差,不符合题意。
- B、单作业模式 (Per-Job Mode):Flink on YARN 的经典生产首选模式,为每一个提交的作业单独启动一个专属的 Flink 集群,作业运行结束后集群自动销毁,资源隔离性强、稳定性高,是实际生产环境的首选,完全符合题意。
- C、应用模式 (Application Mode):虽也为每个应用启动集群,但核心优化是将main方法放到 JobManager 执行,解决客户端资源消耗问题,并非传统意义上 "为每个作业启动集群" 的首选模式。
- D、独立模式 (Standalone Mode):不属于 YARN 运行模式,是独立部署的 Flink 集群架构,不符合题意。
3.总结:Flink部署模式
(1)按作业提交模式分类
- Flink 三种核心部署模式对比
| 部署模式 | main方法执行位置 | 资源隔离 | 适用场景 |
|---|---|---|---|
| 会话模式(Session mode) | 客户端 | 弱(多作业共享集群) | 短任务、频繁提交的作业 |
| 单作业模式(Per-job mode) | 客户端 | 强(单作业独享集群) | 长流式作业、高隔离需求,经典实际生产环境的首选 |
| 应用模式(Application mode) | JobManager(集群内) | 强(单应用独享集群) | 大作业、客户端资源受限场景 |
(2)按集群部署方式分类
YARN 模式:最主流的部署方式,支持上述三种提交模式
Standalone 模式:独立部署的 Flink 集群架构,不依赖外部资源调度器
K8s 模式:云原生部署,支持动态扩缩容
(三) History Server(第 4 题)
正确答案:C(History Server)

1.解析
- 选项 A(JobManager):是 Flink 集群的主节点,负责作业调度、状态管理,但仅在集群运行时提供作业监控,集群关闭后服务终止,无法查询历史作业信息。
- 选项 B(TaskManager):是 Flink 的工作节点,负责执行具体的任务算子,不存储历史作业统计信息,集群关闭后服务也会停止。
- 选项 C(History Server):Flink 专门设计的历史服务器,用于独立存储和展示已完成作业的运行日志、统计指标、执行计划等信息。即使 Flink 集群(JobManager/TaskManager)关闭,只要 History Server 正常运行,就可以通过其 Web UI 查询历史作业数据,完全符合题意。
- 选项 D(ResourceManager):是 YARN 等资源调度框架的核心组件,负责集群资源管理,不负责 Flink 作业历史信息的存储与查询
2.总结(Flink History Server 的核心作用)
- 1.持久化历史作业数据: 将已完成作业的统计信息、执行图、日志等归档存储,避免集群销毁后数据丢失。
- 2.独立运维查询:提供独立的 Web UI,支持跨集群、跨时间的历史作业回溯,用于问题排查、性能优化。
- 3.配置依赖 :需要在
flink-conf.yaml中开启jobmanager.archive.fs.dir(归档目录)和·historyserver.archive.fs.dir(历史服务器读取目录),并启动bin/historyserver.sh start
(四) 核心组件职责(对应第 12、13 题)
表格
| 组件 | 层级 | 核心职责 |
|---|---|---|
| Client | 客户端 | 提交作业、生成 JobGraph,不执行计算 |
| JobManager(含 Dispatcher、JobMaster) | 集群 / 作业级 | - Dispatcher:接收作业、路由、Web UI 服务 - JobMaster:单个作业的中央调度核心,负责任务调度、状态管理 |
| TaskManager | 工作节点(Worker) | 真正执行数据计算的 "干活的人",承载子任务 |
| ResourceManager | 集群级 | 全局 Slot 资源分配、集群资源管理 |
三、Flink API 与算子优化
(一) API 演进(第 5、15 题)
1.第5题解析
正确答案:D(使用 DataSet API 进行转换操作

- 选项 A(使用 StreamExecutionEnvironment 创建执行环境):StreamExecutionEnvironment是 Flink 流处理专属的执行环境,批处理使用ExecutionEnvironment,属于流处理特有操作。
- 选项 B(分组操作调用 keyBy 方法):keyBy是流处理中对无界数据流进行按键分组的核心方法,批处理分组使用groupBy,属于流处理特有操作。
- 选项 C(需要调用 env.execute () 方法启动任务):流处理是无限流,必须显式调用execute()触发任务提交;批处理部分场景可隐式触发,属于流处理特有操作。
- 选项 D(使用 DataSet API 进行转换操作):DataSet API是 Flink批处理专属的 API,流处理使用DataStream API,因此该操作不是流处理特有,符合题意。
学完第五章datastream api 回头再看针对各关键字句函数,会更加理解透彻
2.第15题解析
正确答案:C(Flink 1.12)

- A、Flink 0.9.0:早期版本,DataSet API 是批处理的核心 API,远未到流批统一阶段,错误。
- B、Flink 1.9.0:虽开始推进流批统一,但未正式弃用 DataSet API,也未推荐用 DataStream API 做批处理,错误。
- C、Flink 1.12:从该版本开始,Flink 基于 FLIP-131/FLIP-134 正式推进流批统一,官方明确推荐使用 DataStream API,通过设置BATCH执行模式来处理批数据,同时将 DataSet API 标记为过时(deprecated),完全符合题意,正确。
- D、Flink 1.17.0:该版本进一步完善了 DataStream API 的批处理能力,但并非 DataSet API 过时的起始版本,错误。
3.总结:流处理和批处理的区别
| 特性 | 流处理(DataStream API) | 批处理(DataSet API) |
|---|---|---|
| 执行环境 | StreamExecutionEnvironment | ExecutionEnvironment |
| 数据模型 | 无界数据流(DataStream) | 有界数据集(DataSet) |
| 分组操作 | keyBy | groupBy |
| 任务启动 | 必须显式调用env.execute() | 可隐式触发 |
| 时间语义 | 支持事件时间、处理时间、摄入时间 | 仅处理时间 |
- 流批统一:从 Flink 1.12 开始 ,官方推荐使用
DataStream API,通过设置BATCH执行模式处理批数据,DataSet API 标记为过时
WordCount 示例差异: - 流处理 :
StreamExecutionEnvironment创建环境,keyBy分组,需显式调用env.execute()启动任务 - 批处理:旧版使用DataSet API,新版使用DataStream API + BATCH模式
(二)分层 API(第 16 题)
正确答案:D(SQL)

1.解析
Flink 的分层 API 从底层到顶层、从具体到抽象的层级顺序为:
- 1.底层 API(有状态流处理):最贴近运行时,可直接操作状态、时间等底层机制,抽象度最低,对应选项 A。
- 2.核心 API(DataStream / DataSet API):流批处理的核心编程接口,抽象度中等,对应选项 B。
- 3.Table API:基于关系型表的声明式 API,抽象度更高,对应选项 C。
- 4.SQL:最顶层、最抽象的 API,完全符合 ANSI SQL 标准,用户只需编写 SQL 语句,无需关心底层执行细节,抽象度最高,对应选项 D,符合题意。
2.总结
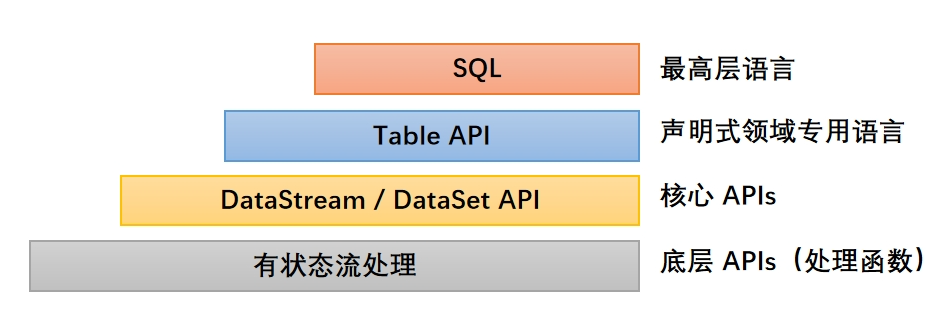
从底层到顶层、从具体到抽象的层级:
- 越顶层越抽象,表达含义越简明,使用越方便
- 越底层越具体,表达能力越丰富,使用越灵活
| API 层级 | 抽象度 | 适用场景 | 特点 |
|---|---|---|---|
| 有状态流处理(底层 API) | 最低 | 复杂状态逻辑、自定义算子 | 灵活度最高,开发成本高 |
| DataStream/DataSet API | 中等 | 通用流批处理业务 | 平衡灵活度与开发效率 |
| Table API | 较高 | 结构化数据处理 | 声明式编程,流批统一 |
| SQL | 最高 | 即席查询、报表分析 | 零代码、低门槛,生态兼容性最好 |
(三) 算子链优化(第 9 题)
正确答案:B(disableChaining())

1.解析
- A、
setParallelism():用于设置算子的并行度,和算子链合并优化无关。 - B、
disableChaining():Flink 专门提供的方法,作用是禁用当前算子的算子链合并优化,让该算子单独作为一个任务执行,不与前后算子合并,完全符合题意。 - C、
startNewChain():作用是从当前算子开始,开启一条新的算子链,仅断开与前序算子的链合并,不会完全禁用当前算子的链合并(仍可与后续算子合并),不符合题意。 - D、
slotSharingGroup():用于设置算子的 slot 共享组,控制算子的 slot 分配,和算子链优化无关。
2.总结
(1)算子链定义
- 算子链(Operator Chain)是 Flink 的核心优化机制:
- 将满足条件(同并行度、同分区、无 shuffle)的连续算子合并为一个任务,减少线程间数据交换开销,提升性能。
(2)控制方法
- disableChaining():完全禁用当前算子的链合并,单独执行
- startNewChain():从当前算子开启新链,仅断开与前序算子的连接
- 全局禁用:配置pipeline.operator-chaining: false
四、Flink 资源调度与并行度
(一) TaskManager 数量计算(第 6 题)
正确答案:B(4 个,10/3 向上取整)

1.解析
- Flink 的 TaskManager 与 slot 的核心逻辑:
- slot 是 TaskManager 的并行执行单元:每个 TaskManager 的 slot 数量固定,1 个 slot 可执行 1 个并行子任务。
- 并行度与 slot 的关系:作业总并行度 = 所需总 slot 数,Flink 会按「总并行度 ÷ 单个 TaskManager 的 slot 数」向上取整,计算需要申请的 TaskManager 数量。
2.总结
(1)公式
所需TaskManager数量 = ⌈ 作业并行度 单个TaskManager的Slot数 ⌉ \text{所需TaskManager数量} = \left\lceil \frac{\text{作业并行度}}{\text{单个TaskManager的Slot数}} \right\rceil 所需TaskManager数量=⌈单个TaskManager的Slot数作业并行度⌉
- 示例:并行度 10,每个 TaskManager 3 个 Slot → 10/3≈3.33,向上取整为 4 个 TaskManager
(2)Flink on YARN 资源分配核心规则
- 1.所需 TaskManager 数量 = ⌈并行度 / 单个TaskManager slot数⌉(向上取整)
- 2.总 slot 数 ≥ 作业并行度,才能满足任务执行需求
- 3.剩余 slot 可用于后续作业调度,提升集群资源利用率
(二)Slot 核心规则(第 7、8 题)
1.第7题解析
正确答案:C(9 个)

- 1.slot 是并行执行的最小单元:1 个 slot 对应 1 个并行子任务的执行槽位。
- 2.作业最大并行度 = 该作业最多占用的 slot 数:即使开启了 slot 共享(算子共享 slot),slot 共享仅允许同一个作业的多个算子在同一个 slot 中串行执行,不会减少作业需要的总 slot 数。
- 3.集群总 slot 数 = TaskManager 数量 × 单个 TaskManager 的 slot 数:本题中集群总 slot 数 = 3 × 3 = 9,刚好匹配作业的最大并行度 9。
2.第8题解析
正确答案:D(默认情况下,不同作业的任务不能共享同一个 Slot)

- A 选项:错误。开启 Slot 共享后,同一个作业的多个算子子任务可以在同一个 Slot 中运行,并非一个 Slot 只能运行一个子任务。
- B 选项:错误。Slot 不是 CPU 资源隔离的最小单位,Flink 的 Slot 主要做内存隔离,CPU 资源默认不做硬隔离(可通过 YARN 等外部框架实现)。
- C 选项:描述不准确。Slot 的核心作用是资源调度与隔离,内存隔离是其核心特性之一,但 "主要作用是内存划分" 的表述片面,Slot 同时承担了作业并行度调度、资源隔离的核心功能,且该选项不是最优正确项。
- D 选项:正确。Flink 的 Slot 共享机制仅允许同一个作业的不同算子子任务共享 Slot,默认情况下,不同作业的任务绝对不能共享同一个 Slot,这是 Flink 资源隔离的核心设计原则。
3.总结:Flink Task Slot 核心特性
| 特性 | 说明 |
|---|---|
| 共享规则 | 仅同作业可共享,不同作业绝对隔离 |
| 资源隔离 | 核心是内存隔离,CPU 默认共享 |
| 并行度对应 | 作业最大并行度 = 所需 Slot 数(不超过集群总 Slot 数) |
| 核心作用 | 资源调度、并行度控制、多作业资源隔离 |
(三)核心概念定义(对应第 11 题)
正确答案:B(并行度 Parallelism)

1.解析
- A、任务槽(Task Slot):是 TaskManager 上的资源执行单元,用于承载子任务,不是子任务的数量定义,错误。
- B、并行度(Parallelism):Flink 中并行度的定义就是单个算子被切分的子任务(subtask)的数量,直接决定了算子的并行执行能力,符合题意,正确。
- C、算子链(Operator Chain):是 Flink 将连续算子合并为一个任务的优化机制,和子任务数量无关,错误。
- D、分区(Partition):是数据流的分片概念,用于数据分发,不是子任务数量的定义,错误。
2.总结:并行度相关概念
- 并行度(Parallelism):单个算子被切分的子任务(subtask)数量,决定算子的并行执行能力
- Task Slot:TaskManager 上的资源执行单元,用于承载子任务,是 Flink 的核心资源隔离单位(核心是内存隔离)
- 核心规则:
算子并行度 = 该算子的子任务数量,1 个子任务对应 1 个 slot 。
作业最大并行度 = 作业所有算子中最大的并行度,决定了作业最多占用的 slot 数。
并行度可全局配置、作业级配置、算子级配置,优先级:算子级 > 作业级 > 全局。
五、Flink 基础概念与设计理念
(一) 核心设计理念(第 17 题)
··正确答案:B(以流处理为根本,批处理是流处理的特例)
``

1.解析
- A 选项:这是Spark Streaming的设计理念,以批处理为核心,将流数据切分为微批次(Micro-Batch)模拟流处理,不是 Flink 的理念,错误。
- B 选项:这是 Flink 的根本设计理念。Flink 从诞生起就是原生流处理引擎,认为批数据本质是有界的数据流,因此批处理只是流处理的一个特例,完美实现流批统一,符合题意,正确。
- C 选项:Flink 1.12 之后已实现流批统一,仅用 DataStream 一套 API 即可处理流批数据,不再是两套独立 API,错误。
- D 选项:两者架构完全不同,Spark 是微批次架构,Flink 是原生流处理架构,错误。
2.总结:Flink vs Spark Streaming 核心差异
| 特性 | Flink | Spark Streaming(含 Structured Streaming) |
|---|---|---|
| 核心设计 | 原生流处理,批是流的特例 | 批处理为根,流是微批次模拟 |
| 延迟特性 | 真正毫秒级低延迟 | 秒级延迟(受批次大小限制) |
| 时间语义 | 原生支持事件时间、乱序处理 | 早期仅处理时间,Structured Streaming 逐步支持 |
| 流批统一 | 一套 API 统一流批处理 | 流、批、结构化流三套 API(逐步统一) |
| 状态管理 | 原生轻量级状态,Exactly-Once 语义 | 基于 Checkpoint 的状态管理,开销更高 |
- Flink 根本设计:以流处理为根本,批处理是流处理的特例。批数据本质是有界流,因此 Flink 实现了流批统一,一套 API 可同时处理流和批数据。
- 对比 Spark Streaming:Spark Streaming 是以批处理为根本,将流处理模拟为微批次,延迟受批次大小限制;Flink 是原生流处理引擎,支持真正的低延迟。
(二)Flink 主要特点(第 18 题)
正确答案:B(仅提供至少一次(at-least-once)的状态一致性保证)

1.解析
- A 选项:高吞吐、低延迟是 Flink 的核心优势,属于主要特点,不符合题意。
- B 选项:Flink不仅支持 at-least-once(至少一次),还原生支持 exactly-once(精确一次)状态一致性保证,这是 Flink 的核心特性之一,因此 "仅提供至少一次" 的描述错误,不是 Flink 的主要特点,符合题意。
- C 选项:Flink 原生支持事件时间、处理时间、摄入时间三种时间语义,是其核心特性,属于主要特点,不符合题意。
- D 选项:Flink 具备高可用能力,可与 YARN、K8s 等资源调度系统紧密集成,是其核心特性,属于主要特点,不符合题意。
2.总结:Flink 状态一致性语义
Flink 支持三种一致性语义,可灵活配置:
- at-most-once(最多一次):数据不保证处理,仅保证不重复,适用于对数据准确性要求低的场景。
- at-least-once(至少一次):保证数据不丢失,但可能重复,适用于对延迟敏感、可接受重复计算的场景。
- exactly-once(精确一次):Flink 的核心优势,通过 Checkpoint、两阶段提交等机制,保证数据仅被处理一次,状态完全一致,是生产环境的首选。
✅ 高吞吐 + 低延迟:流水线执行机制实现毫秒级延迟
✅ 支持三种时间语义:事件时间、处理时间、摄入时间
✅ 支持三种状态一致性:at-most-once、at-least-once、exactly-once(核心优势)
✅ 高可用:与 YARN、K8s 等资源调度系统紧密集成
(三)起源与发展(第 19 题)
正确答案:C(Stratosphere)

1.解析
- A、Hadoop:是 Apache 基金会的大数据生态项目,不是 Flink 的起源项目,错误。
- B、Spark:是另一个独立的大数据处理引擎,与 Flink 是竞争关系,错误。
- C、Stratosphere:Flink 的前身是德国柏林工业大学等机构主导的Stratosphere研究项目,2014 年该项目捐献给 Apache 基金会后,更名为 Flink 并成为顶级项目,完全符合题意,正确。
- D、Storm:是早期的流处理引擎,与 Flink 无起源关系,错误。
2.总结:Flink 的发展历程
- 1.起源(2010-2014):Stratosphere 研究项目,核心目标是打造一个统一的大数据处理引擎,支持流、批、图、机器学习等多种计算场景。
- 2.Apache 孵化(2014):Stratosphere 更名为 Flink,进入 Apache 孵化器。
- 3.顶级项目(2014 年底):Flink 成为 Apache 顶级项目,正式进入开源社区视野。
- 4.流批统一(2020+):Flink 1.12 + 版本完成流批统一,成为大数据领域的核心实时计算引擎。
(四)有界流 vs 无界流(第 20 题)
正确答案:C(无界流的数据必须等全部到达后才能开始处理)

1.解析
- A 选项:无界流的定义就是有开始、无结束的持续数据流,需要实时持续处理,描述正确。
- B 选项:有界流有明确的起止边界,本质是有界数据集,可被视为批处理,描述正确。
- C 选项:无界流是持续产生的数据流,不需要等全部数据到达,而是来一条处理一条,实时计算,这是流处理的核心特性,因此该描述错误,符合题意。
- D 选项:有界流数据完整,可在处理前进行全局排序,无需按顺序摄取,描述正确。
2.总结:有界流 vs 无界流 核心对比
| 特性 | 无界流 | 有界流 |
|---|---|---|
| 边界 | 有开始,无结束 | 有明确的开始和结束 |
| 处理方式 | 实时、流式、持续处理 | 批量、一次性处理 |
| 数据特性 | 持续产生、无限 | 固定大小、有限 |
| 典型场景 | 实时日志、监控、推荐 | 离线报表、数据仓库 |
| Flink 对应模式 | STREAMING 模式 | BATCH 模式 |
总结
通过对上述 20 道题目的解析,可以梳理出以下 Flink 核心要点:
-
Flink 的核心优势 不仅是高吞吐、低延迟和精确一次的状态一致性,还体现在与 Kafka、HDFS、Hive 等常用大数据生态系统的无缝集成上。
-
YARN 部署模式中:
-nm参数用于在 YARN UI 上自定义应用名称;- 单作业模式(Per-Job Mode)是生产环境的首选,资源隔离性强;
- 应用模式(Application Mode)将 main 方法移至 JobManager 执行,彻底避免客户端资源占用。
-
History Server 是 Flink 查询历史作业信息的关键组件,即使集群关闭也能独立运行。
-
流批统一从 Flink 1.12 版本开始正式推进,DataSet API 被标记为过时,官方推荐使用 DataStream API 并配合 BATCH 模式处理批数据。
-
分层 API 的抽象度从低到高为:有状态流处理底层 API → DataStream/DataSet API → Table API → SQL,越上层使用越简便,越下层表达越灵活。
-
算子链 是 Flink 的核心优化机制,
disableChaining()可完全禁用当前算子的链合并,startNewChain()可开启新链。 -
TaskManager 数量计算公式 为
⌈并行度 / 单个 TaskManager 的 Slot 数⌉。Slot 是并行执行的最小单元,不同作业的 Slot 绝对隔离,同一作业的不同算子可以共享 Slot。 -
Flink 的根本设计理念是 "以流处理为根本,批处理是流处理的特例",这与 Spark Streaming 的微批次架构形成本质区别。
-
Flink 支持三种状态一致性:最多一次、至少一次、精确一次(核心优势),并非"仅支持至少一次"。
-
有界流与无界流的核心区别在于是否有明确的边界:无界流需实时持续处理,有界流可批量一次性处理。
通过系统掌握上述知识点,可以更深入地理解 Flink 的运行时架构、API 设计哲学以及生产环境中的资源调度策略,为实际项目中的实时计算选型与调优打下扎实基础。