一、基础认知
1. 核心概念定义
1.1 进程保活
指通过技术手段持续监控大模型运行进程,确保模型服务不意外退出、不被系统杀死、不静默挂起,核心目标是维持模型服务的持续在线状态,是大模型提供稳定推理、训练服务的基础前提。
- 覆盖场景:进程崩溃、系统OOM终止进程、程序异常退出、依赖服务中断导致进程挂死
- 核心能力:进程存活检测、自动拉起、状态上报

1.2 故障自愈
指大模型服务发生异常时,无需人工干预,系统自动识别故障、定位原因、执行修复策略,让服务恢复正常运行的闭环能力,是无人运维的核心。
- 覆盖场景:显存泄漏、OOM内存溢出崩溃、推理超时、服务无响应、端口占用
- 核心能力:故障检测、原因判定、自动修复、自愈日志、告警通知
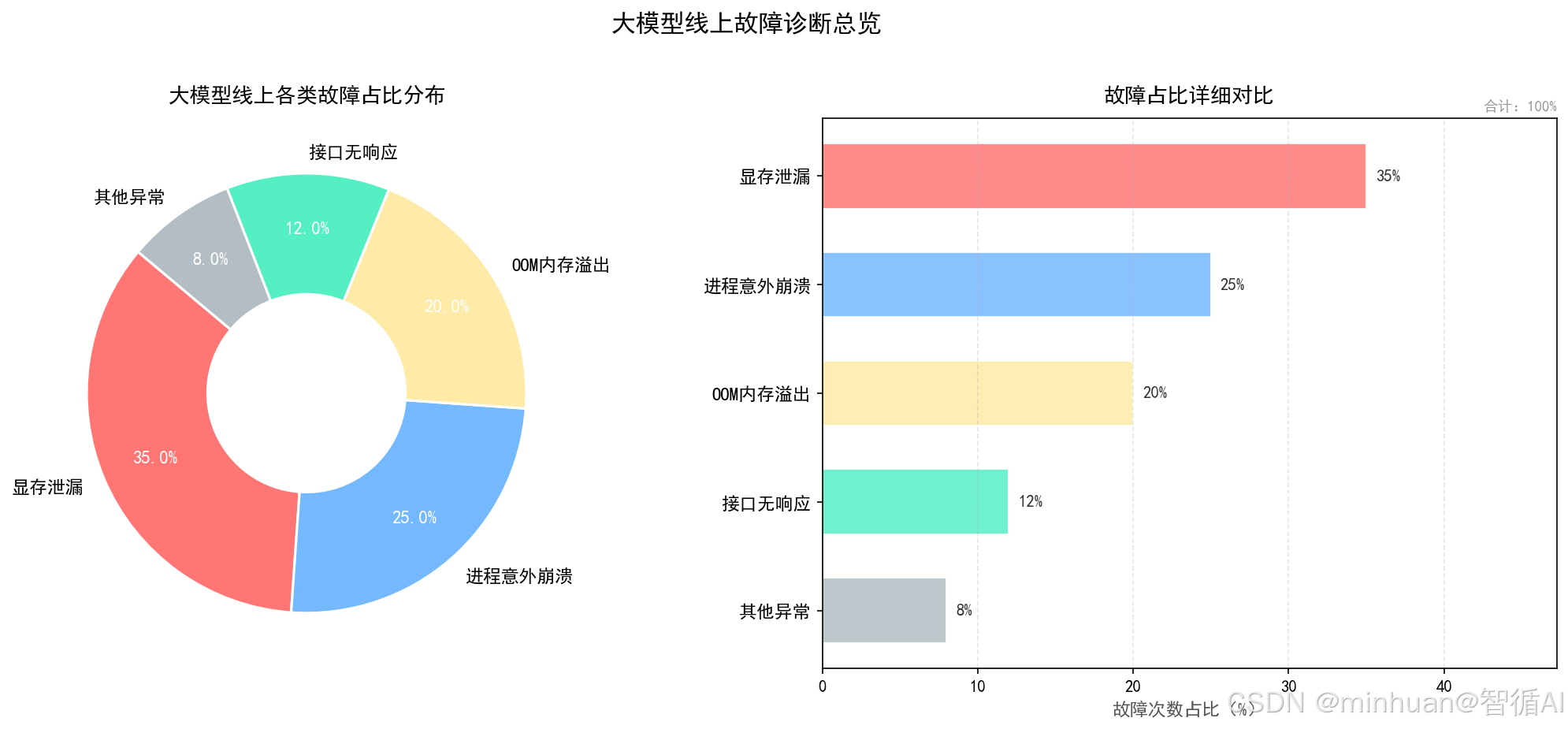
1.3 显存泄漏
大模型运行过程中,申请的显存未被正常释放,随着运行时间增加,显存占用持续升高,最终导致显存耗尽、服务崩溃,是大模型最常见的慢性故障。
- 典型特征:显存占用线性增长、重启后显存恢复、长时间运行必触发OOM内存溢出
- 危害:直接导致模型推理失败、服务中断、硬件资源浪费
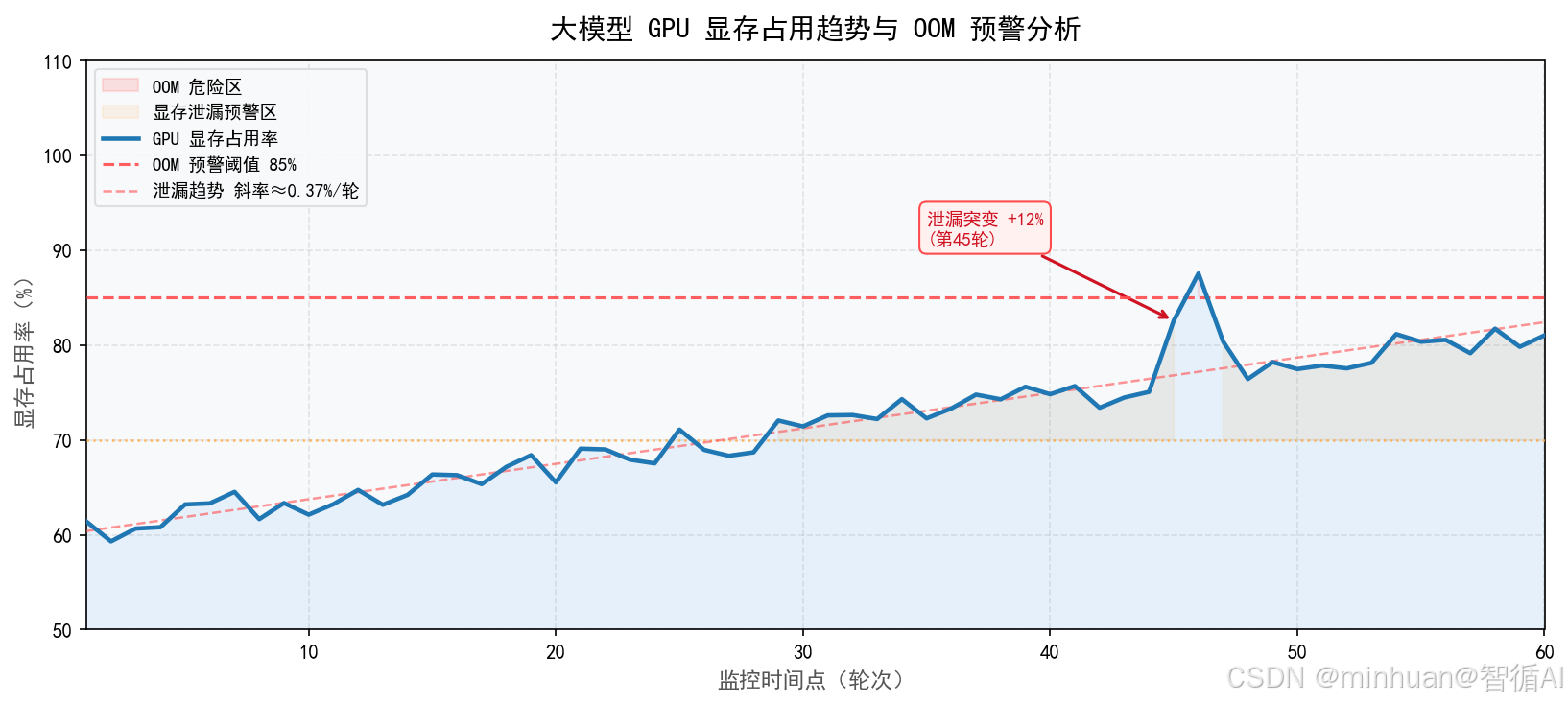
1.4 OOM 预警
OOM,Out Of Memory,内存耗尽是大模型服务的致命故障,预警指在显存或内存占用达到阈值前,提前发出告警,并执行预定义的降载、清理策略,避免故障发生。
- 预警维度:GPU显存占用、系统内存占用、交换区使用率
- 核心价值:从被动修复变为主动预防
1.5 定时巡检
按照固定时间周期,对大模型服务的进程状态、硬件资源、接口可用性、显存占用等核心指标进行全面检测,生成巡检报告,提前发现隐性故障。
- 巡检频率:
- 分钟级(进程):每分钟实时检测核心进程存活状态,确保服务进程在线,秒级发现异常。
- 小时级(资源):每小时深度采集硬件资源数据,分析显存与算力负载,预警性能瓶颈。
- 天级(全量):每日执行全链路深度巡检,覆盖接口可用性及日志,生成综合健康报告。
- 核心价值:消除隐性故障,保障服务长期稳定
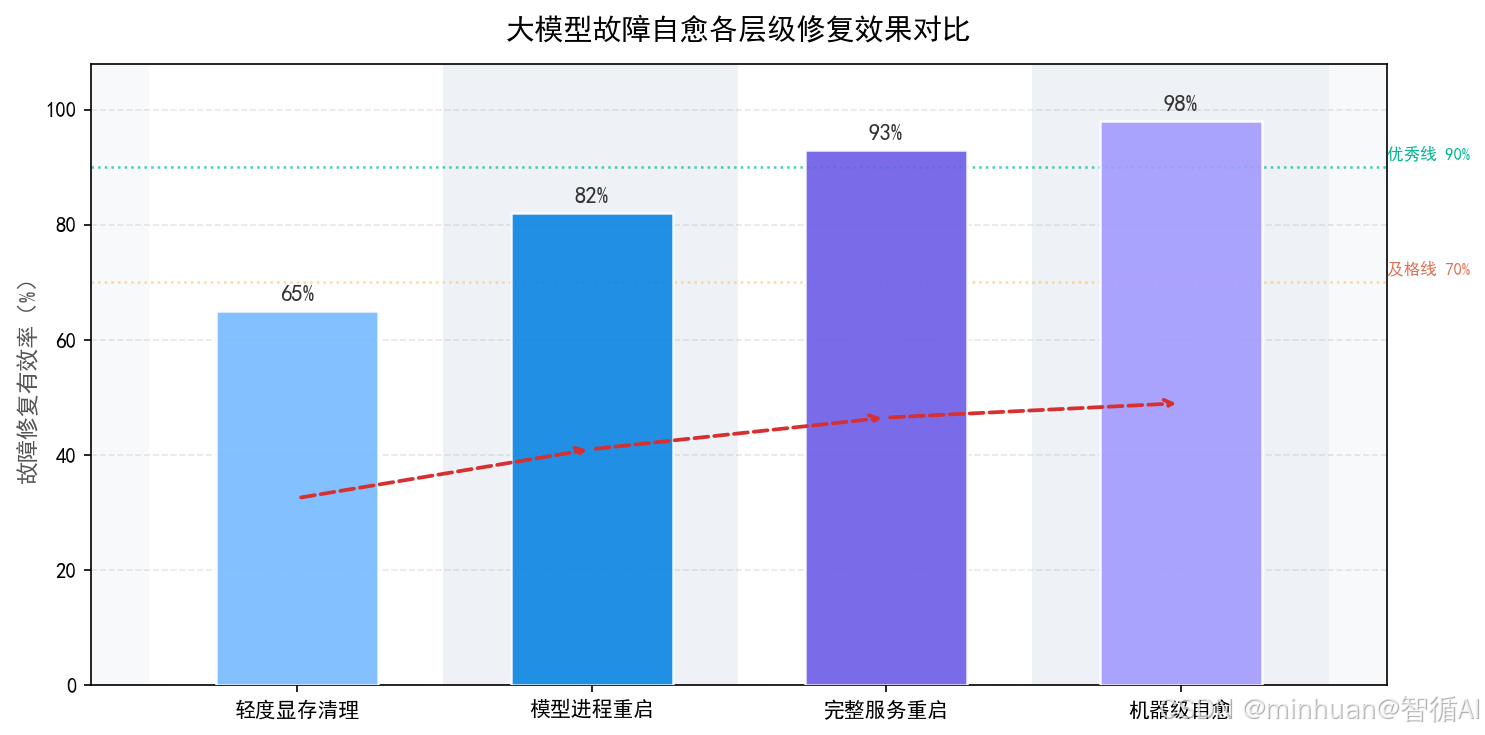
1.6 无人运维自愈
结合进程保活、故障自愈、OOM预警、定时巡检,构建全自动化运维体系,无需人工登录服务器、无需手动重启、无需排查日志,系统自主完成所有运维操作。
- 核心目标:7×24小时稳定运行、零人工干预、故障零感知
2. 运维基础必备
2.1 Linux 进程基础
2.1.1 进程状态查看
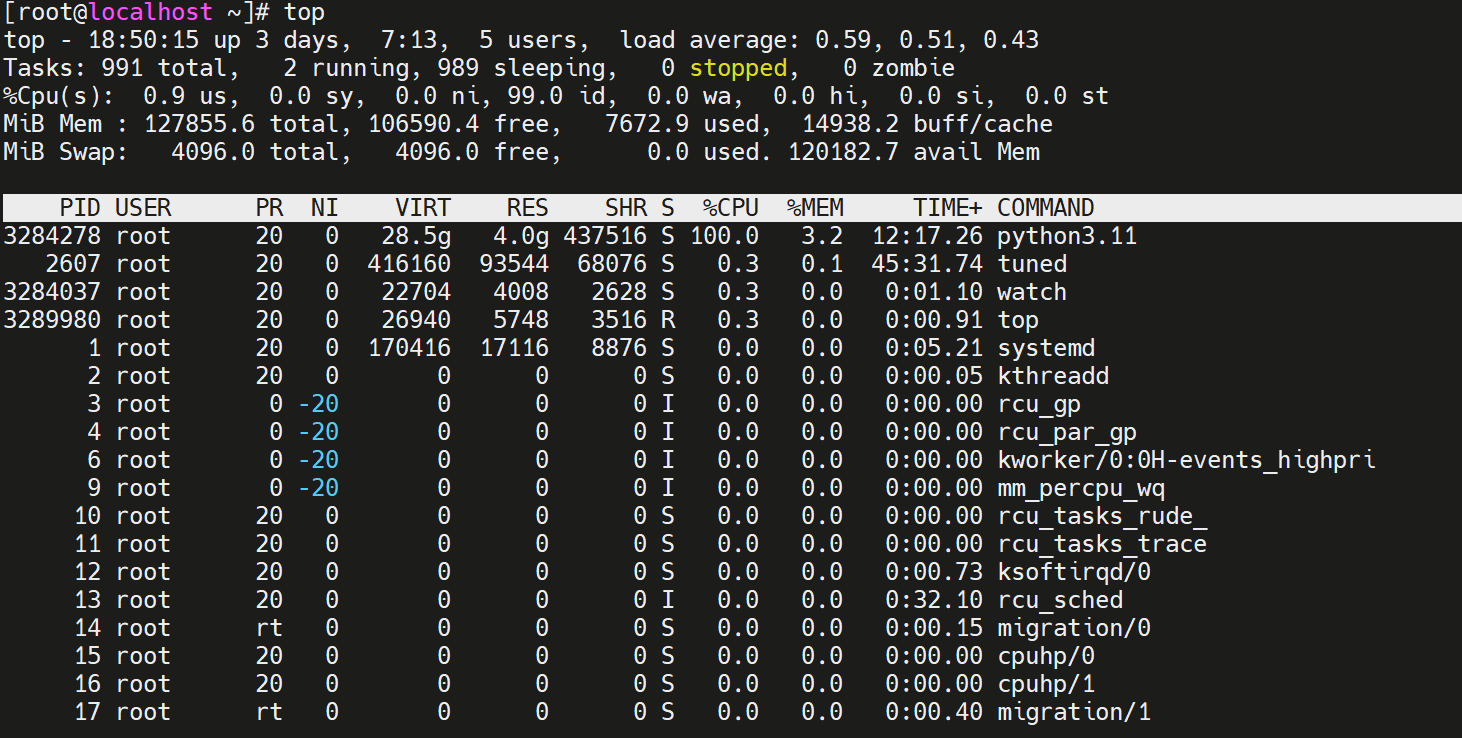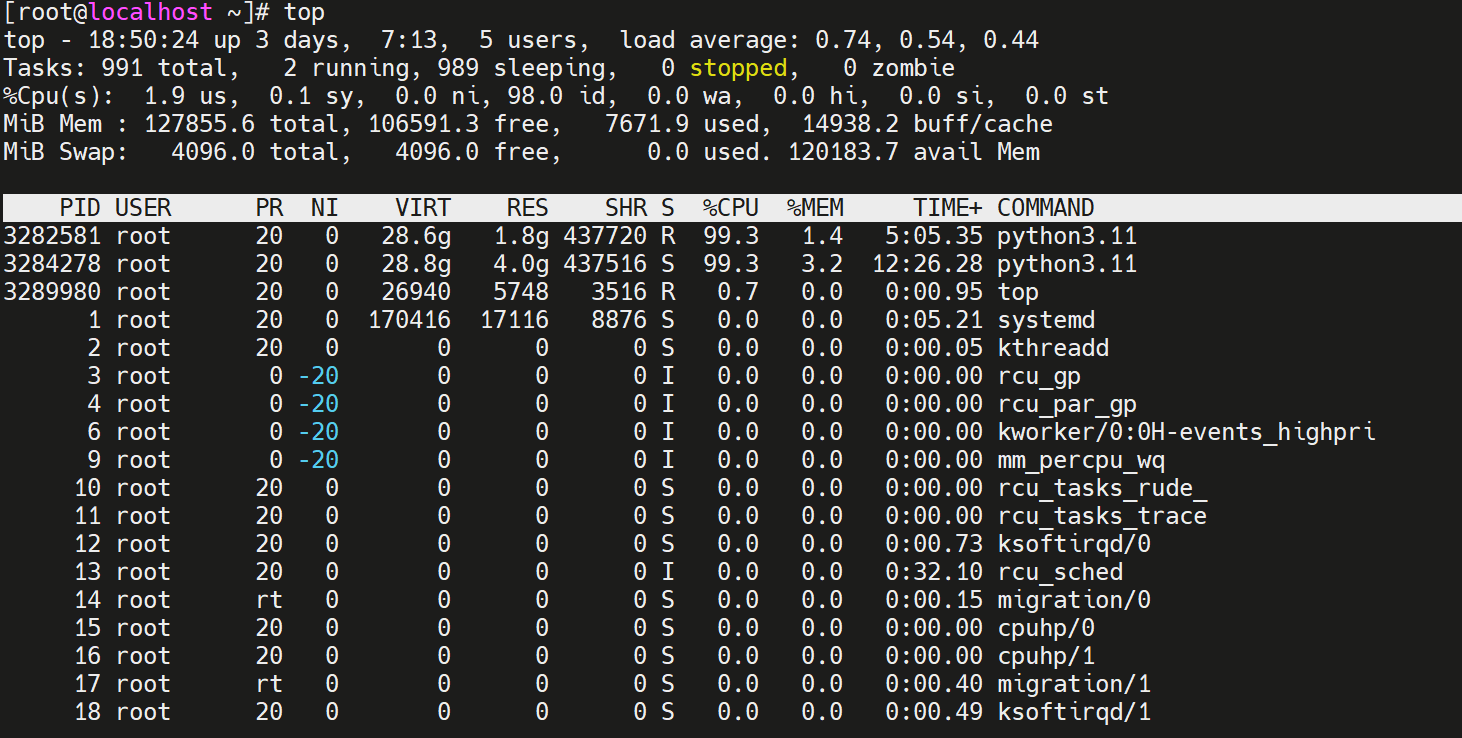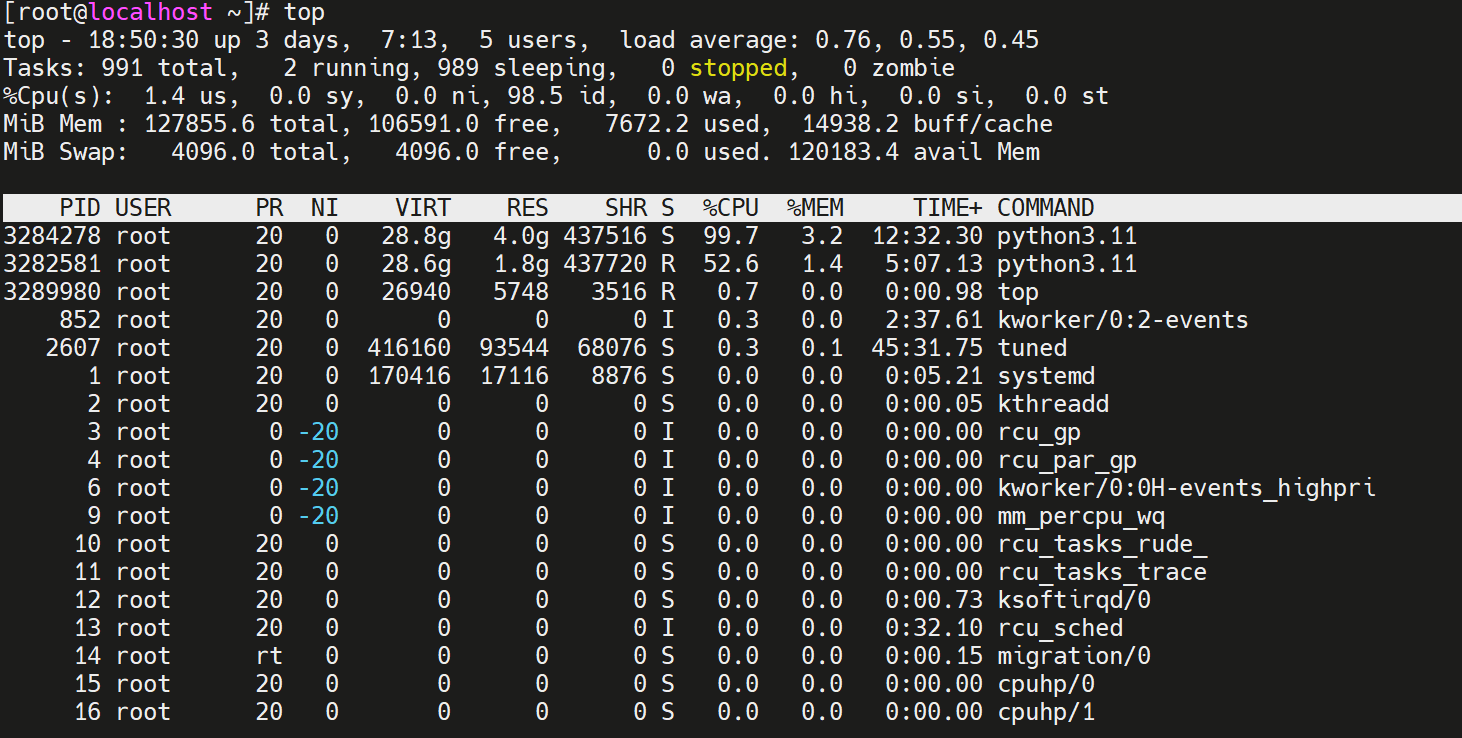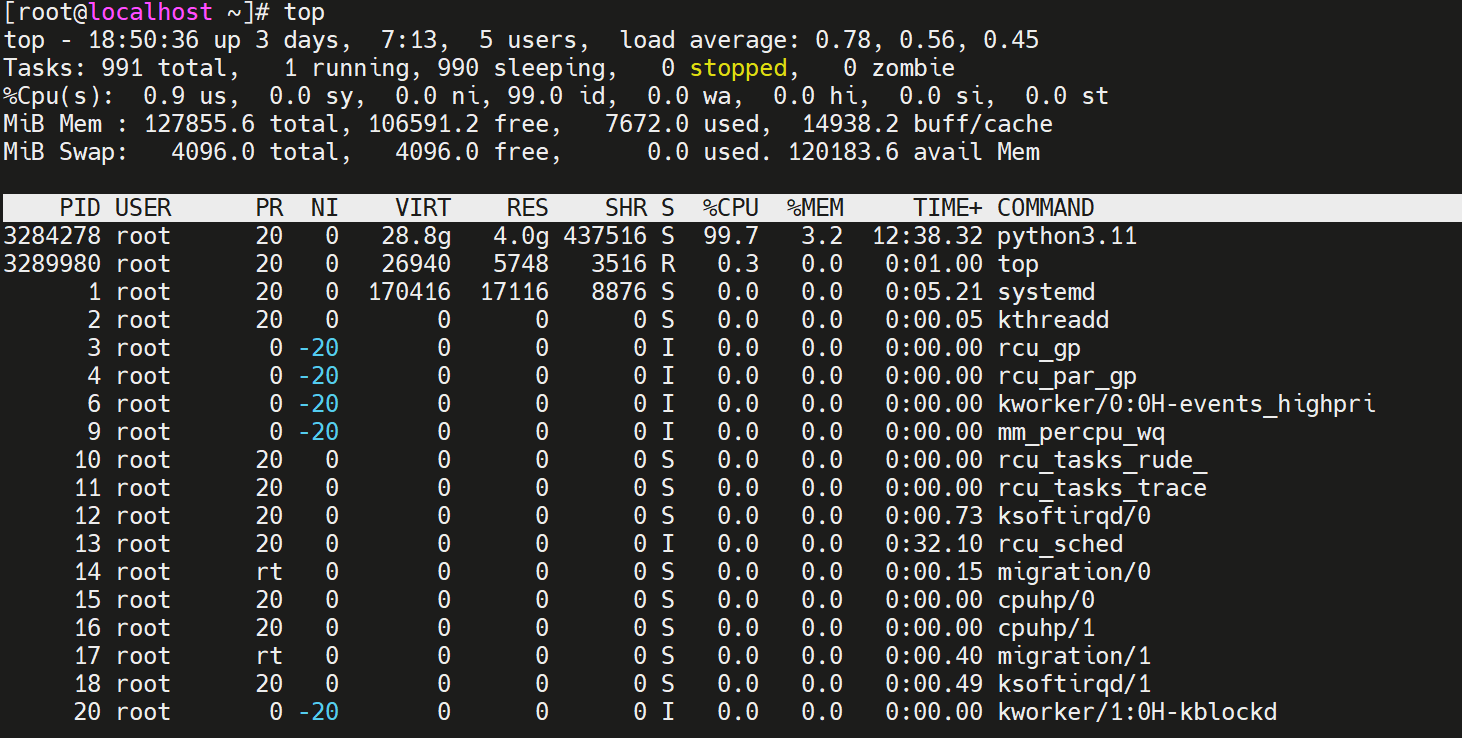
- 使用"ps aux"或"ps -ef"查看所有进程的详细信息。
- 使用"top"或"htop"命令实时动态查看系统进程和资源占用情况。
- 使用"pgrep -f <进程名>"根据名称查找进程的PID。
2.1.2 进程状态理解
- 理解ps命令输出中STAT列的含义,如S:睡眠, R:运行, Z:僵尸进程, T:停止。
- 重点识别僵尸进程Z,它表示子进程已结束但父进程未回收其资源。
2.1.3 进程杀死与重启
- 使用"kill <PID>"发送IGTERM信号,请求进程优雅地终止。
- 使用"kill -9 <PID>"发送SIGKILL信号,强制杀死进程。
- 使用"killall <进程名>"根据名称杀死所有同名进程。
2.1.4 systemd服务管理
- 使用"systemctl status <服务名>"查看服务运行状态。
- 使用"systemctl start|stop|restart <服务名>"启动、停止、重启服务。
- 使用"journalctl -u <服务名> -f"实时查看服务的日志输出。
2.2 GPU 硬件知识
2.2.1 nvidia-smi 命令
- 直接运行"nvidia-smi"查看GPU的概览信息,包括型号、显存、温度、功耗等。
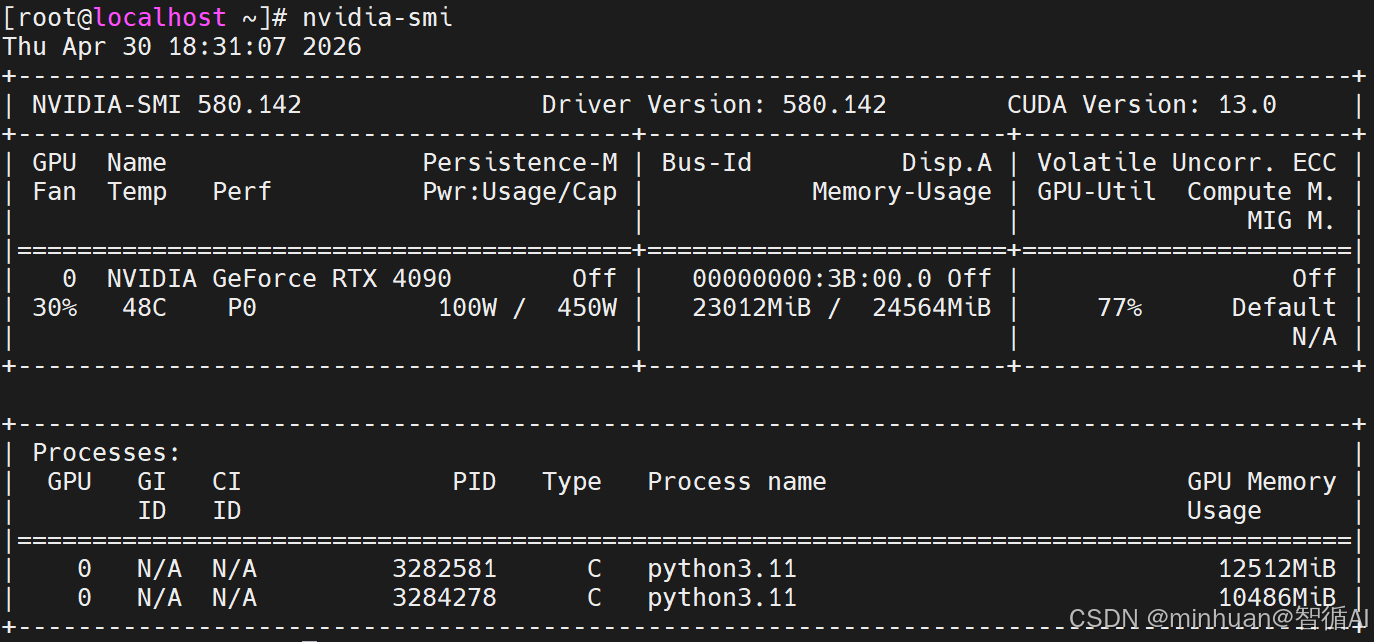
- 使用"watch -n 1 nvidia-smi"每秒刷新一次,实现实时监控。
2.2.2 显存占用查看
- 在nvidia-smi的输出中,关注Memory-Usage栏,了解已用/总显存。
- 使用"nvidia-smi --query-compute-apps=pid,process_name,used_memory,gpu_name --format=csv"查看每个进程占用的显存。
- 完整字段列表:
- timestamp:查询时间,按照标准时间格式输出。
- gpu_name:GPU 设备的官方名称。
- gpu_bus_id:设备的 PCI 总线 ID。
- gpu_serial:设备的序列号。
- gpu_uuid:设备的唯一识别 ID
- pid:进程的 ID。
- process_name或name:进程的名称。
- used_memory 或used_gpu_memory:进程占用的GPU显存。

2.2.3 GPU利用率监控
- 在nvidia-smi的输出中,关注Volatile GPU-Util栏,了解GPU计算核心的利用率。
- 理想情况下,大模型推理/训练时,GPU利用率应保持在较高水平,如>90%。
2.2.4 进程信息查询
- 使用"nvidia-smi pmon"监控GPU进程,查看是哪个进程PID在使用GPU。
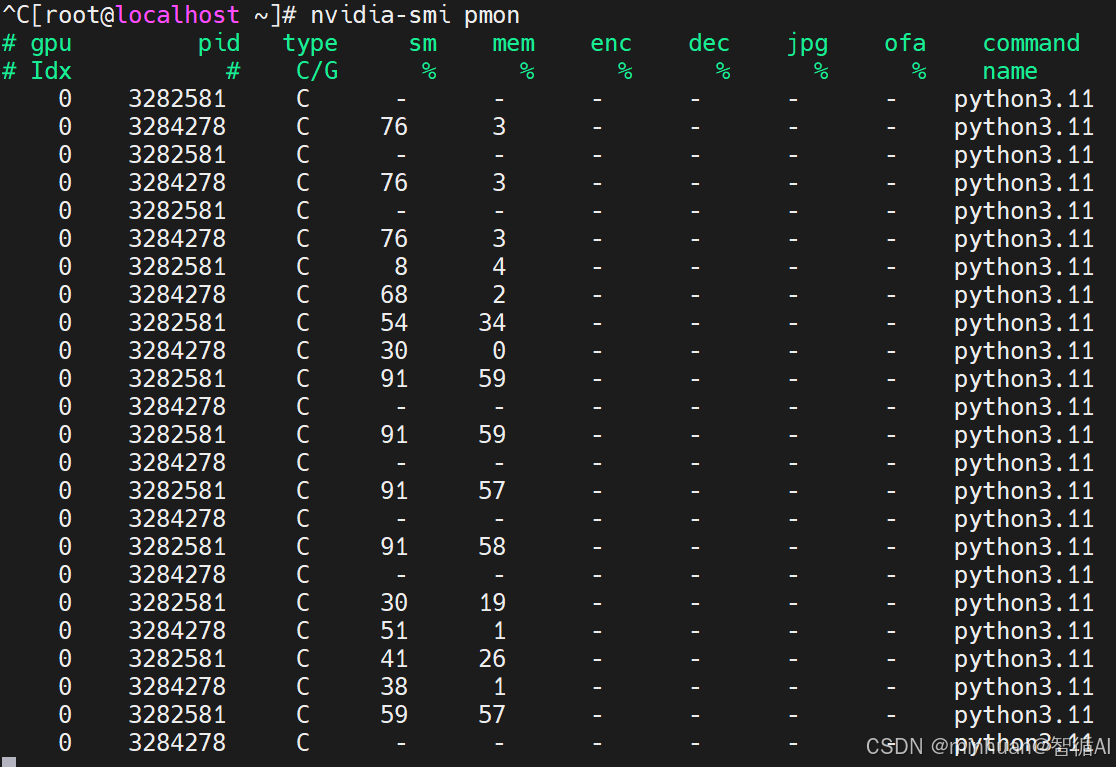
2.3 Python 进程管理
2.3.1 subprocess 库
- 使用"subprocess.run()"执行系统命令,如启动一个模型推理脚本。
- 使用"subprocess.Popen()"创建子进程,并可以非阻塞地与其交互,例如读取其标准输出。
2.3.2 psutil 库
- 使用"psutil.process_iter()"遍历所有进程,查找特定名称的进程。
- 使用"process.is_running()"判断一个进程对象是否仍在运行。
- 使用"process.memory_info().rss"获取进程的内存占用。
- 使用"psutil.cpu_percent(interval=1)"获取CPU使用率。
2.3.3 进程创建、监控、终止逻辑
- 创建:通过subprocess.Popen("python", "inference.py")启动一个Python脚本。
- 监控:在一个循环中,定期检查Popen对象的poll()方法返回值,判断进程是否结束。
- 终止:调用Popen对象的terminate()方法发送SIGTERM或kill()方法发送SIGKILL。
2.4 异常处理机制
2.4.1 Python 异常捕获
- 使用 try...except...else...finally 结构来捕获和处理代码执行中可能出现的异常。
- 例如,捕获 subprocess.TimeoutExpired 异常来处理命令执行超时。
- 捕获 psutil.NoSuchProcess 异常来处理进程在检查时已不存在的情况。
2.4.2 日志记录
- 使用Python内置的logging模块,将巡检过程中的关键信息、警告和错误记录到日志文件中。
- 配置日志级别DEBUG, INFO, WARNING, ERROR, CRITICAL和格式,便于问题排查。
2.4.3 服务状态判断逻辑
- 通过检查进程的退出码returncode来判断其是否正常退出。
- 结合psutil检查进程状态,判断其是否处于预期的运行状态。
- 通过调用服务的健康检查接口来判断服务是否可用,如HTTP GET/health。
2.5 阈值与策略
2.5.1 自定义显存/内存预警阈值
- 设定显存占用百分比阈值,例如当显存使用率>95%时触发预警。
- 设定系统内存RAM使用率阈值,例如当内存使用率>85% 时触发预警。
2.5.2 自愈触发条件
- 进程连续几次无响应或崩溃。
- 显存占用持续多少分钟超过预警阈值,且无下降趋势。
- 服务健康检查接口连续多次返回非200状态码。
2.5.2 重启策略
- 立即重启:对于核心服务,一旦检测到异常,立即尝试重启。
- 延迟重启:在重启前等待一段时间,避免因瞬时波动导致频繁重启。
- 指数退避:如果重启后再次失败,则逐渐增加下一次重启的等待时间,防止重启风暴。
- 最大重试次数:设定一个最大重启次数,超过该次数后停止自动操作并发送高级别告警,通知人工介入。
3. 对大模型的意义
- 保障服务连续性:大模型作为核心AI服务,崩溃会直接导致对话、推理、训练业务中断,保活 + 自愈可实现秒级恢复
- 降低运维成本:无需专人全天值守,减少人工排查、重启、修复的时间成本
- 提升硬件利用率:显存泄漏治理、OOM预警可避免硬件资源无效占用,提升GPU使用效率
- 支撑工业级部署:商业化大模型必须具备高可用能力,自愈方案是生产环境部署的必备条件
- 延长服务寿命:定时巡检 + 主动清理,避免慢性故障累积,让大模型服务持续稳定运行数月甚至数年
二、核心原理
1. 整体架构原理
大模型进程保活与故障自愈采用"监控 - 检测 - 决策 - 执行 - 反馈:闭环架构,5大模块协同工作:
- 监控模块:实时采集进程状态、GPU显存、系统内存、服务接口状态
- 检测模块:对比采集数据与预设阈值,判断是否存在异常:崩溃、泄漏、OOM
- 决策模块:根据异常类型,匹配对应的自愈策略:重启、清理、降载、告警
- 执行模块:自动执行自愈操作,无需人工介入
- 反馈模块:记录自愈日志、更新服务状态、完成故障闭环
2. 分模块基础原理
2.1 进程崩溃自动重启原理
- 核心逻辑:持续轮询检测进程PID是否存在
- 执行流程:获取目标进程PID → 判断PID是否存活 → 存活则继续监控 → 死亡则执行重启命令 → 验证重启是否成功
- 技术关键:精准匹配进程名称或端口,避免误杀、误重启其他服务
2.2 显存泄漏治理原理
- 核心逻辑:识别显存未释放的代码、操作 → 定时清理显存 → 限制显存峰值
- 治理手段:
-
- 主动释放:Python中调用 torch.cuda.empty_cache() 清理缓存
-
- 重启释放:显存超过阈值自动重启服务,彻底释放显存
-
- 代码修复:禁止循环内重复加载模型、及时删除无用张量
-
- 技术关键:区分"正常显存占用"和"泄漏显存",避免误清理
2.3 OOM预警原理
- 核心逻辑:实时采集GPU显存使用率 → 对比预警阈值 → 触发预警、降载策略
- 预警分级:
-
- 一级预警(70%):记录日志,轻度清理显存
-
- 二级预警(85%):发送告警,强制清理缓存
-
- 三级预警(95%):立即重启服务,避免OOM崩溃
-
- 技术关键:高精度采集GPU数据,低延迟触发预警
2.4 定时巡检原理
- 核心逻辑:基于时间触发器,周期性执行全维度检测
- 巡检维度:
-
- 进程巡检:是否存在、CPU占用、线程数
-
- 硬件巡检:GPU显存、温度、利用率;系统内存、磁盘
-
- 服务巡检:推理接口是否响应、响应时间、错误率
-
- 技术关键:轻量化巡检,不占用大模型推理资源
2.5 无人运维自愈原理
- 核心逻辑:所有模块联动,形成全自动闭环
- 联动流程:巡检发现异常 → 检测判定故障类型 → 决策匹配自愈策略 → 执行自动修复 → 反馈验证修复结果 → 持续监控
- 技术关键:策略可配置、故障可追溯、操作可记录
三、完整执行流程
1. 标准执行流程
-
- 初始化配置:设置进程名称、预警阈值、巡检频率、自愈策略
-
- 启动监控服务:后台运行保活自愈程序,不影响大模型服务
-
- 实时数据采集:每秒或每5秒采集一次核心指标
-
- 异常判定:
- 进程不存在 → 触发崩溃重启
- 显存持续增长无释放 → 判定显存泄漏
- 显存或内存超阈值 → 触发OOM预警
-
- 策略执行:根据异常类型执行对应自愈操作
-
- 结果验证:检查服务是否恢复正常
-
- 日志记录:保存故障时间、类型、自愈操作、执行结果
-
- 持续循环:回到监控环节,7×24小时运行
2. 异常处理流程
2.1 大模型进程突然崩溃
-
- 监控模块检测到目标进程 PID 消失
-
- 立即记录崩溃时间、日志
-
- 执行进程重启命令,加载模型
-
- 等待模型加载完成,验证进程是否存活
-
- 存活则自愈成功,失败则重试重启,注意最多3次
-
- 重试失败则发送告警通知
2.2 显存泄漏导致占用持续升高
-
- 巡检模块对比历史显存数据,发现线性增长
-
- 执行一级清理:调用显存清理函数
-
- 清理后仍升高 → 执行二级清理:重启模型推理进程
-
- 重启后显存恢复正常,记录泄漏治理日志
-
- 持续监控,防止再次泄漏
2.3 OOM预警触发
-
- 显存占用达到85%二级预警阈值
-
- 系统自动暂停非核心推理请求,释放显存
-
- 执行强制缓存清理
-
- 显存下降至安全值 → 恢复正常服务
-
- 显存持续升高 → 立即重启服务,避免OOM
2.4 定时巡检执行
-
- 到达预设巡检时间,如每小时
-
- 依次检测进程、GPU、内存、服务接口
-
- 所有指标正常 → 生成正常巡检报告
-
- 发现隐性异常 → 触发对应自愈策略
-
- 保存巡检报告,便于后续追溯
四、应用实践
以下是一个大模型服务进程保活与故障自愈监控脚本,定时检测、异常崩溃重启,并将结果记录到图表中,具体说明:
- 进程保活:定时检测模型进程是否存活,崩溃后自动重启,最多重试3次
- OOM预警:GPU显存超85%阈值时自动清理缓存,清理无效则重启服务
- 显存泄漏治理:显存超70%时执行轻度清理,预防泄漏累积
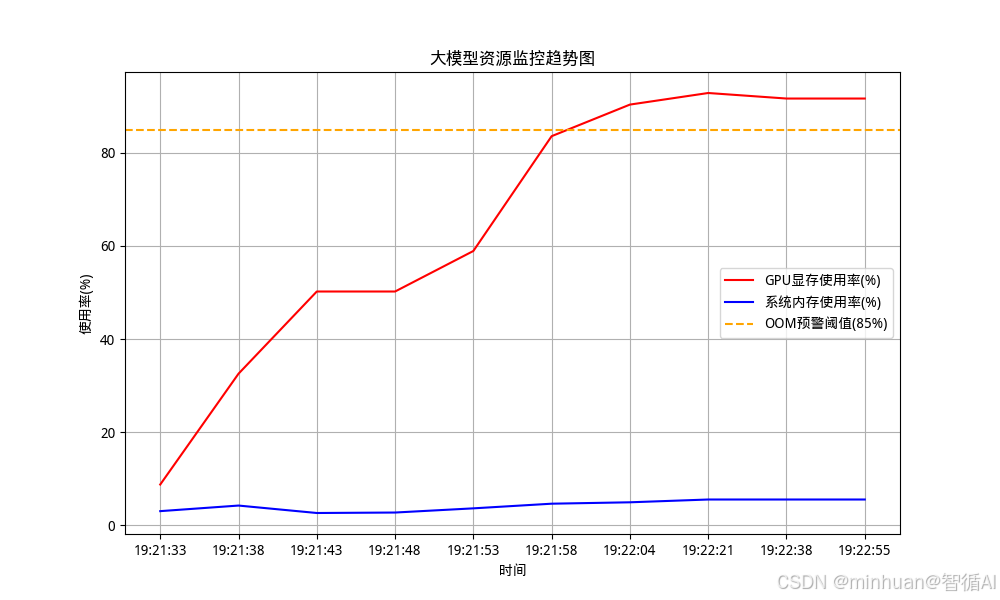
- 资源监控可视化:实时采集GPU、系统内存数据,定时生成趋势图表
python
import os
import time
import psutil
import subprocess
import torch
import matplotlib.pyplot as plt
import matplotlib
from datetime import datetime
import sys
# ===================== 中文字体适配(Linux/Windows/macOS) =====================
def _setup_chinese_font():
"""自动选择系统中可用的中文字体"""
import matplotlib.font_manager as fm
# 按优先级尝试的字体列表
font_candidates = [
'WenQuanYi Micro Hei', # Linux 常用
'WenQuanYi Zen Hei',
'Noto Sans CJK SC',
'Noto Sans SC',
'SimHei', # Windows
'Microsoft YaHei',
'PingFang SC', # macOS
'Heiti SC',
'sans-serif'
]
available_fonts = {f.name for f in fm.fontManager.ttflist}
for font in font_candidates:
if font in available_fonts:
plt.rcParams['font.sans-serif'] = [font]
plt.rcParams['axes.unicode_minus'] = False
print(f"[字体] 已加载中文字体:{font}")
return
# 都没找到:用系统默认 + 警告
print("[字体] 未找到中文字体,图表中文可能显示为方块,请安装:apt install fonts-wqy-microhei")
plt.rcParams['font.sans-serif'] = ['sans-serif']
plt.rcParams['axes.unicode_minus'] = False
_setup_chinese_font()
# ==============================================================================
# ===================== 配置项 =====================
MODEL_PROCESS_NAME = "python3.11" # 大模型进程名称
GPU_ID = 0 # 使用的GPU编号
OOM_WARN_THRESHOLD = 85 # OOM预警阈值(%)
MEMORY_LEAK_THRESHOLD = 70 # 显存泄漏预警阈值(%)
CHECK_INTERVAL = 5 # 监控间隔(秒)
RETRY_COUNT = 3 # 重启重试次数
# =================================================
# 存储监控数据,用于生成图表
monitor_data = {
"timestamp": [],
"gpu_memory": [],
"system_memory": []
}
def get_gpu_memory_usage(gpu_id=0):
"""获取GPU显存使用率"""
try:
result = subprocess.check_output(
f"nvidia-smi --query-gpu=memory.used,memory.total --format=csv,noheader,nounits -i {gpu_id}",
shell=True
)
used, total = map(int, result.decode().strip().split(","))
return round((used / total) * 100, 2)
except:
return 0.0
def is_model_running(process_name):
"""检测大模型进程是否存活"""
for proc in psutil.process_iter(['pid', 'name']):
if process_name in proc.info['name']:
return True, proc.info['pid']
return False, None
def clear_gpu_memory():
"""清理GPU显存缓存"""
if torch.cuda.is_available():
torch.cuda.empty_cache()
print(f"[{datetime.now()}] 已执行GPU显存清理")
def restart_model_process():
"""重启大模型进程(替换为你的启动命令)"""
print(f"[{datetime.now()}] 开始重启大模型进程")
# 示例启动命令:根据你的模型实际启动命令修改
startup_cmd = "nohup python your_model_server.py > model.log 2>&1 &"
os.system(startup_cmd)
time.sleep(10) # 等待模型加载
success, pid = is_model_running(MODEL_PROCESS_NAME)
if success:
print(f"[{datetime.now()}] 重启成功,进程PID:{pid}")
return True
else:
print(f"[{datetime.now()}] 重启失败")
return False
def save_monitor_chart():
"""生成监控图表(可视化显存/内存趋势)"""
plt.figure(figsize=(10, 6))
plt.plot(monitor_data["timestamp"], monitor_data["gpu_memory"], label="GPU显存使用率(%)", color="red")
plt.plot(monitor_data["timestamp"], monitor_data["system_memory"], label="系统内存使用率(%)", color="blue")
plt.axhline(y=OOM_WARN_THRESHOLD, color="orange", linestyle="--", label=f"OOM预警阈值({OOM_WARN_THRESHOLD}%)")
plt.xlabel("时间")
plt.ylabel("使用率(%)")
plt.title("大模型资源监控趋势图")
plt.legend()
plt.grid(True)
plt.savefig("model_monitor.png")
plt.close()
print("[{datetime.now()}] 监控图表已保存:model_monitor.png")
def main():
print("===== 大模型进程保活与故障自愈服务启动 =====")
retry = 0
while True:
now = datetime.now().strftime("%H:%M:%S")
# 1. 获取核心指标
gpu_mem = get_gpu_memory_usage(GPU_ID)
sys_mem = psutil.virtual_memory().percent
proc_running, pid = is_model_running(MODEL_PROCESS_NAME)
# 记录监控数据
monitor_data["timestamp"].append(now)
monitor_data["gpu_memory"].append(gpu_mem)
monitor_data["system_memory"].append(sys_mem)
# 每100次采样保存一次图表
if len(monitor_data["timestamp"]) % 10 == 0:
save_monitor_chart()
# 2. 进程崩溃检测
if not proc_running:
print(f"[{now}] 大模型进程已崩溃,尝试重启...")
restart_success = restart_model_process()
if restart_success:
retry = 0
else:
retry += 1
if retry >= RETRY_COUNT:
print(f"[{now}] 重启重试次数耗尽,需人工检查")
retry = 0
time.sleep(CHECK_INTERVAL)
continue
# 3. OOM预警与显存泄漏治理
if gpu_mem >= OOM_WARN_THRESHOLD:
print(f"[{now}] 警告:GPU显存占用{gpu_mem}%,触发OOM预警!")
clear_gpu_memory()
time.sleep(2)
# 清理后仍超标,重启服务
if get_gpu_memory_usage(GPU_ID) >= OOM_WARN_THRESHOLD:
restart_model_process()
# 4. 显存泄漏轻度治理
elif gpu_mem >= MEMORY_LEAK_THRESHOLD and gpu_mem < OOM_WARN_THRESHOLD:
print(f"[{now}] 提示:GPU显存占用{gpu_mem}%,执行轻度清理")
clear_gpu_memory()
# 5. 正常状态输出
else:
print(f"[{now}] 运行正常 | 进程PID:{pid} | GPU显存:{gpu_mem}% | 系统内存:{sys_mem}%")
time.sleep(CHECK_INTERVAL)
if __name__ == "__main__":
main()输出结果:
===== 大模型进程保活与故障自愈服务启动 =====
19:21:33 运行正常 | 进程PID:3296490 | GPU显存:8.72% | 系统内存:3.0%
19:21:38 运行正常 | 进程PID:3296490 | GPU显存:32.54% | 系统内存:4.2%
19:21:43 运行正常 | 进程PID:3296490 | GPU显存:50.21% | 系统内存:2.6%
19:21:48 运行正常 | 进程PID:3296490 | GPU显存:50.21% | 系统内存:2.7%
19:21:53 运行正常 | 进程PID:3296490 | GPU显存:58.92% | 系统内存:3.6%
19:21:58 提示:GPU显存占用83.6%,执行轻度清理
2026-04-30 19:21:59.061133 已执行GPU显存清理
19:22:04 警告:GPU显存占用90.39%,触发OOM预警!
2026-04-30 19:22:04.113335 已执行GPU显存清理
........
输出结果图示:
大模型资源监控趋势图:
五、总结
大模型进程保活与故障自愈方案是大模型落地生产环境必不可少的运维核心能力。我们在实际应用中,应该都遇到过大模型部署后进程莫名崩溃、显存悄悄泄漏、突发OOM宕机,都是极其头疼的问题,这些问题如果靠人工盯着排查、手动重启,既费时又容易错过故障处理时机,根本没法支撑长期稳定运行。系统性的进程监控、显存治理、OOM预警、定时巡检、自动自愈是运维环节必不可少、极其重要的部分,从个人感悟来说,大模型不只是把模型跑起来就够了,高可用、无人值守自愈才是工业级部署的关键,很多时候业务故障不是模型本身不行,而是进程和资源没管好。
这里起到一个抛砖引玉的作用,大家上手时建议先吃透进程监控、GPU显存查看这些基础知识点,再动手跑通示例代码,亲自测试崩溃重启、显存预警的效果;后续可以在此基础上扩展告警通知、日志持久化功能,慢慢把这套方案改成适配自己项目的定制化版本,真正做到适合自己的大模型服务免人工值守、全自动稳定运行。