目录
[二、安装 Ollama 客户端](#二、安装 Ollama 客户端)
[四、基于 Qwen2.5 实现零样本情感文本分类实战](#四、基于 Qwen2.5 实现零样本情感文本分类实战)
[1. 库导入](#1. 库导入)
[2. 模型路径配置](#2. 模型路径配置)
[3. 模型与分词器加载](#3. 模型与分词器加载)
[4. Prompt 模板设计](#4. Prompt 模板设计)
[5. 输入文本预处理](#5. 输入文本预处理)
[6. 文本编码](#6. 文本编码)
[7. 模型推理](#7. 模型推理)
[8. 结果解码与提取](#8. 结果解码与提取)
Ollama 是一款能让你在本地电脑上一键部署、运行各种大模型的工具。它把模型下载、依赖配置、运行环境全部封装好了,只需要几条命令,就能在你的 Windows 电脑上跑通 Qwen、Llama、Mistral 等热门模型,不用再折腾复杂的 Python 环境。
下面我以 Windows 系统为例,带你从零安装并运行你的第一个本地大模型。
一、准备工作
-
系统要求:Windows 10 / 11(推荐 Windows 11)
-
硬件建议:
◦ 运行 qwen2.5:1.5b 这类 1.5B 小模型:8G 内存就足够
◦ 想要更流畅:16G 内存 + 独立显卡(NVIDIA 显卡优先)
- 网络:全程需要联网下载模型文件
二、安装 Ollama 客户端
- 下载安装包
1.打开 Ollama 官网:https://ollama.com/
2.点击 Download for Windows,下载 Windows 安装包
3.双击下载好的 .exe 文件,一路默认安装即可。安装完成后,Ollama 会自动在后台启动服务。
- 验证安装是否成功
按 Win + R,输入 cmd 打开命令提示符,输入:
bash
ollama --version如果能输出版本号,就说明安装成功了。
三、一键运行你的第一个大模型
我们以 Qwen2.5-1.5B 为例(就是你截图里用的模型),它体积小、速度快,非常适合新手入门。
- 拉取并运行模型
在命令提示符里输入:
bash
ollama run qwen2.5:1.5b执行后,Ollama 会自动拉取模型文件(大约 1GB 左右),下载完成后,你就能直接和模型对话了
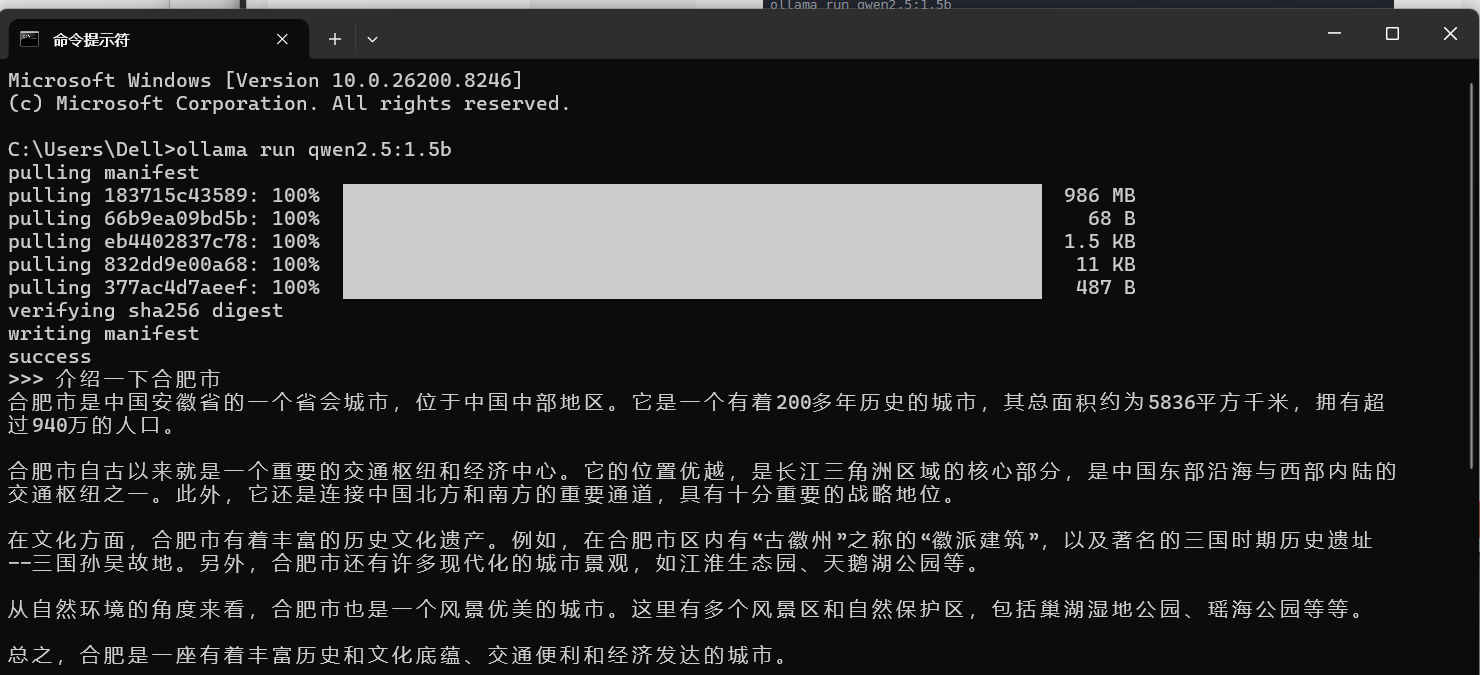
四、基于 Qwen2.5 实现零样本情感文本分类实战
在自然语言处理(NLP)领域,文本情感分类是最经典的应用场景之一。传统的文本分类方案需要标注数据集、模型训练与调参,门槛较高。而随着开源大模型的普及,我们可以通过Prompt 提示词工程实现零样本分类,无需训练、无需数据,直接调用本地轻量模型完成任务。
本文将使用阿里开源的Qwen2.5-1.5B-Instruct轻量级大模型,手把手教你实现本地部署的文本情感分类,代码极简、易上手,普通电脑即可运行。
加载本地的 Qwen2.5 大模型,通过自定义提示词(Prompt)告诉模型执行文本情感分类任务,输入一段评论文本,让模型自动判断其情感倾向(正面 / 负面 / 中立),全程本地运行,无需联网。环境准备
首先安装核心依赖库,transformers是 Hugging Face 官方提供的大模型调用库,torch是模型运行的基础框架:
python
pip install transformers torch完整代码实现
1. 库导入
导入大模型加载、分词、张量计算的核心工具,是运行大模型的基础。
python
from transformers import AutoModelForCausalLM, AutoTokenizer#先要安装一个第三方库transformers2. 模型路径配置
指定本地已下载好的 Qwen2.5-1.5B 模型文件夹路径,实现本地离线运行。
python
#大模型 的 网络 结构 就 自 注意力 机制、
# 假设Qwen是一个生成式模型,并且我们有它的权重和分词器
model_name = r"D:\software\Pycharm\Qwen2.5-1.5B-Instruct" #只需要写文件路径即可3. 模型与分词器加载
AutoModelForCausalLM:专门加载生成式大模型,适配 Qwen 系列模型;AutoTokenizer:分词工具,完成自然语言与数字编码的相互转换。
python
model = AutoModelForCausalLM.from_pretrained(model_name) #加载模型。
tokenizer = AutoTokenizer.from_pretrained(model_name)#对文本进行分词,创建一4. Prompt 模板设计
这是零样本分类的核心,清晰告诉模型任务目标、待处理文本和可选分类,引导模型输出正确结果。
python
# 定义一个Prompt模板
prompt_template = "请判断以下文本属于哪个类别:{text}。可选类别有:正面、负面、中立。"5. 输入文本预处理
将自定义的评论文本填入 Prompt 模板,构造完整的模型输入指令。
python
# 预处理输入文本
input_text = ""这部电影真是太差劲,我非常不喜欢!"" #领域:识别你是否具有抑郁症。
prompt_input = prompt_template.format(text=input_text)6. 文本编码
分词器将文本转换为模型可识别的input_ids(数字索引)和attention_mask(有效内容掩码)。
python
inputs = tokenizer(prompt_input, return_tensors="pt")# 对Prompt进行编码,inputs返回的结果中包含了input_ids和attention_mask7. 模型推理
调用大模型的生成函数,基于输入指令生成情感分类结果。
python
# input_ids:是将输入文本(prompt_input)按照分词器对应的词汇表进行编码后得到的结果,表现为一个张量(torch.Tensor 类型,因为设置了 return_tensors="pt" 表示返回 PyTorch 格式的张量)。这个张量里的每个元素对应词汇表中的一个词(准确说是词对应的索引)
# attention_mask:是用于指示模型在处理输入时应该关注哪些部分的掩码张量,其元素的值通常是 0 或者 1,1 表示对应位置的 input_ids 是有效输入,需要模型去关注和处理;0 表示对应位置是填充部分(比如在批量处理文本且文本长度不一致时进行填充后的那些位置),模型在进行注意力计算等操作时可以忽略这些位置。
# 使用模型进行推理(生成文本)
output_sequences = model.generate(inputs.input_ids, max_new_tokens=512, # 生成文本的最大长度
attention_mask=inputs.attention_mask)8. 结果解码与提取
将模型输出的数字还原为文字,并剔除输入指令,仅保留分类答案。代码中保留了结果解析的注释,取消注释即可直接输出分类结果。
python
# 解码生成的文本
generated_text = tokenizer.decode(output_sequences[0], skip_special_tokens=True)
print(generated_text)
text = generated_text[len(prompt_input):]#大模型需要保存记忆
# # 解析生成的文本以获取分类结果
# # 这里我们假设生成的文本会包含"正面"、"负面"或"中立"中的一个
classification = None
text = generated_text[len(prompt_input):]
if "正面" in text:
classification = "正面"
elif "负面" in text:
classification = "负面"
elif "中立" in text:
classification = "中立"
# 输出分类结果
print(f"分类结果:{classification}")完整代码:
python
from transformers import AutoModelForCausalLM, AutoTokenizer#先要安装一个第三方库transformers
#安装transformers,大模型的开发库
#大模型 的 网络 结构 就 自 注意力 机制、
# 假设Qwen是一个生成式模型,并且我们有它的权重和分词器
model_name = r"D:\software\Pycharm\Qwen2.5-1.5B-Instruct" #只需要写文件路径即可
model = AutoModelForCausalLM.from_pretrained(model_name) #加载模型。
tokenizer = AutoTokenizer.from_pretrained(model_name)#对文本进行分词,创建一
# 定义一个Prompt模板
prompt_template = "请判断以下文本属于哪个类别:{text}。可选类别有:正面、负面、中立。"
# 预处理输入文本
input_text = ""这部电影真是太差劲,我非常不喜欢!"" #领域:识别你是否具有抑郁症。
prompt_input = prompt_template.format(text=input_text)
inputs = tokenizer(prompt_input, return_tensors="pt")# 对Prompt进行编码,inputs返回的结果中包含了input_ids和attention_mask
# input_ids:是将输入文本(prompt_input)按照分词器对应的词汇表进行编码后得到的结果,表现为一个张量(torch.Tensor 类型,因为设置了 return_tensors="pt" 表示返回 PyTorch 格式的张量)。这个张量里的每个元素对应词汇表中的一个词(准确说是词对应的索引)
# attention_mask:是用于指示模型在处理输入时应该关注哪些部分的掩码张量,其元素的值通常是 0 或者 1,1 表示对应位置的 input_ids 是有效输入,需要模型去关注和处理;0 表示对应位置是填充部分(比如在批量处理文本且文本长度不一致时进行填充后的那些位置),模型在进行注意力计算等操作时可以忽略这些位置。
# 使用模型进行推理(生成文本)
output_sequences = model.generate(inputs.input_ids, max_new_tokens=512, # 生成文本的最大长度
attention_mask=inputs.attention_mask)
# 解码生成的文本
generated_text = tokenizer.decode(output_sequences[0], skip_special_tokens=True)
print(generated_text)
text = generated_text[len(prompt_input):]#大模型需要保存记忆
# # 解析生成的文本以获取分类结果
# # 这里我们假设生成的文本会包含"正面"、"负面"或"中立"中的一个
classification = None
text = generated_text[len(prompt_input):]
if "正面" in text:
classification = "正面"
elif "负面" in text:
classification = "负面"
elif "中立" in text:
classification = "中立"
# 输出分类结果
print(f"分类结果:{classification}")执行代码后,控制台会输出模型的完整回复,示例如下:
bash
C:\Users\Dell\AppData\Local\Programs\Python\Python39\python.exe D:\software\Pycharm\大模型\代码\1、Qwen文本分类.py
请判断以下文本属于哪个类别:"这部电影真是太差劲,我非常不喜欢!"。可选类别有:正面、负面、中立。 这段文本属于"负面"类别。
原因如下:
1. "这部电影真是太差劲",这句话直接表达了对电影的不满和失望。
2. "我非常不喜欢!"进一步强调了作者对于该电影的强烈负面情感。
3. 文本中的所有措辞都是消极的评价,没有任何积极或中性的元素。
因此,这段文本明确表达了一种负面的情感反应,符合"负面"类别的定义。
分类结果:负面
进程已结束,退出代码0