从零实现Transformer:第 4 部分 - 残差连接、层归一化与前馈网络(Add & Norm, Feed-Forward)
flyfish
本部分的完整代码在文末
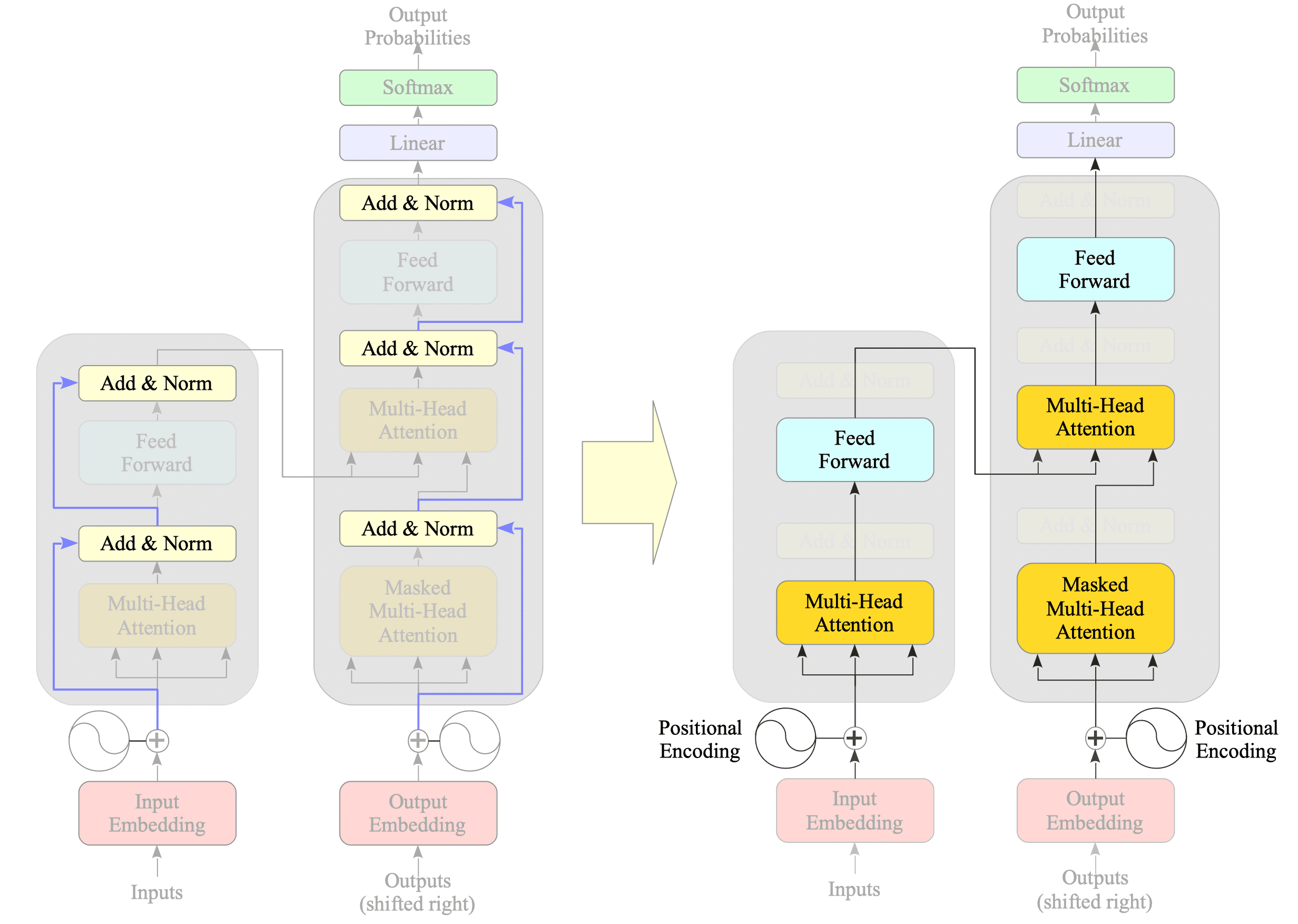
完整的图
主要用于和其他的图做参考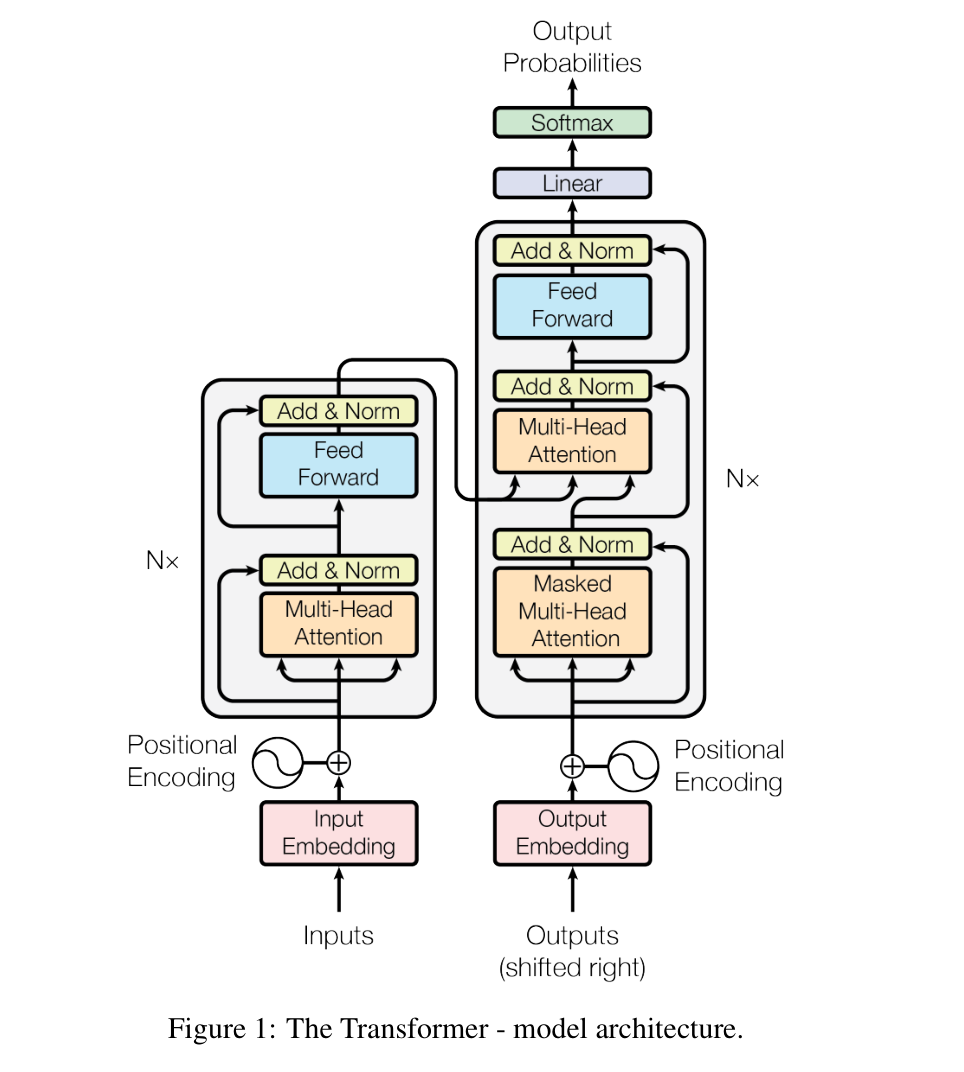
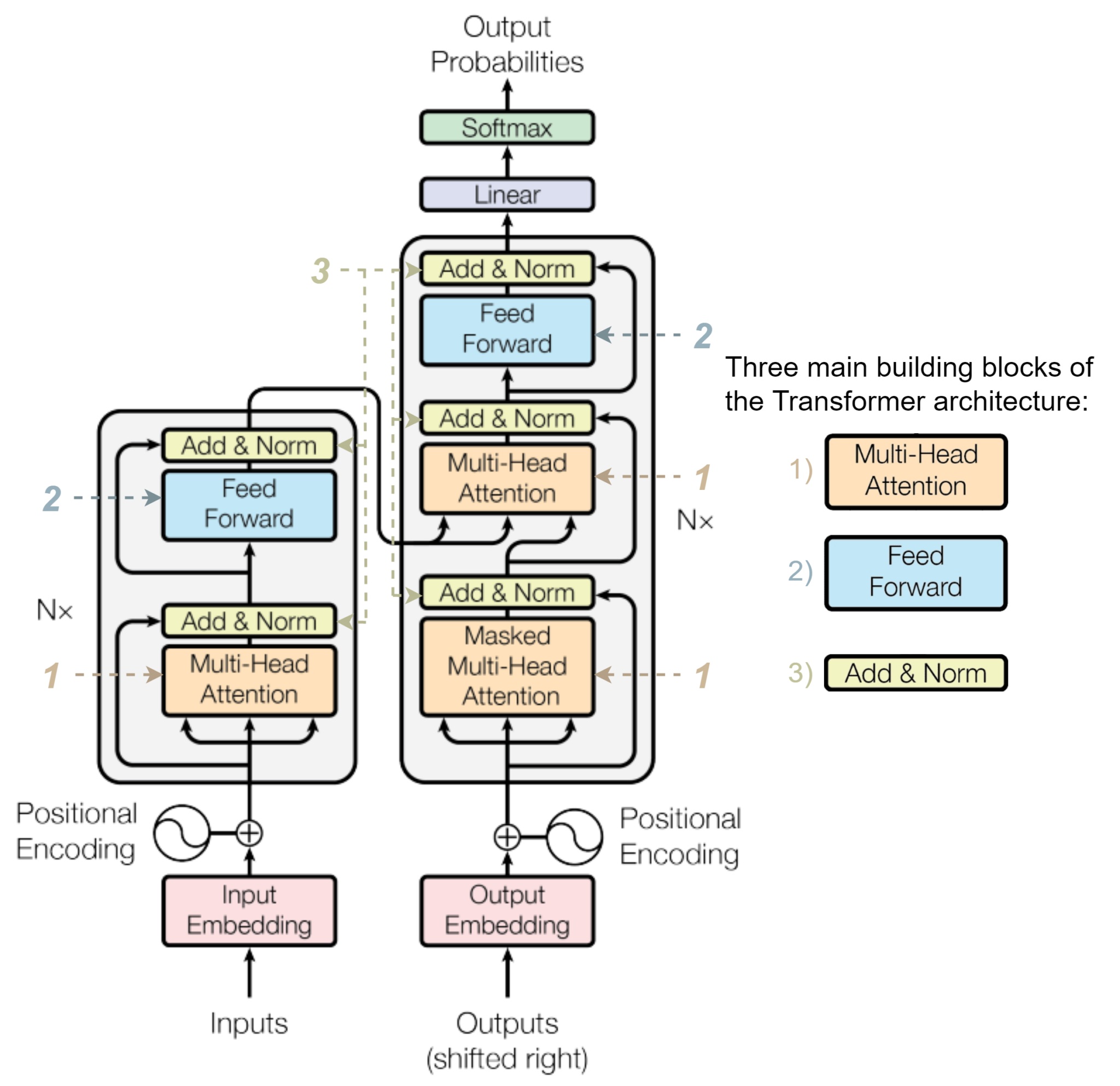
还有两个组件要实现
多头注意力机制(Multi-Head Attention)已经实现了还有Add & Norm和 Feed-forward networ,这里的norm是Layer normalization.
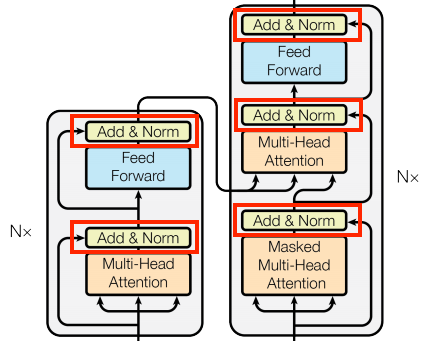
Add & Norm 部分
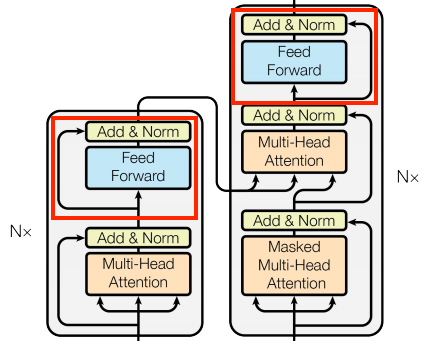
Feed-Forward 部分
组件一:层归一化(Layer Normalization)即Norm
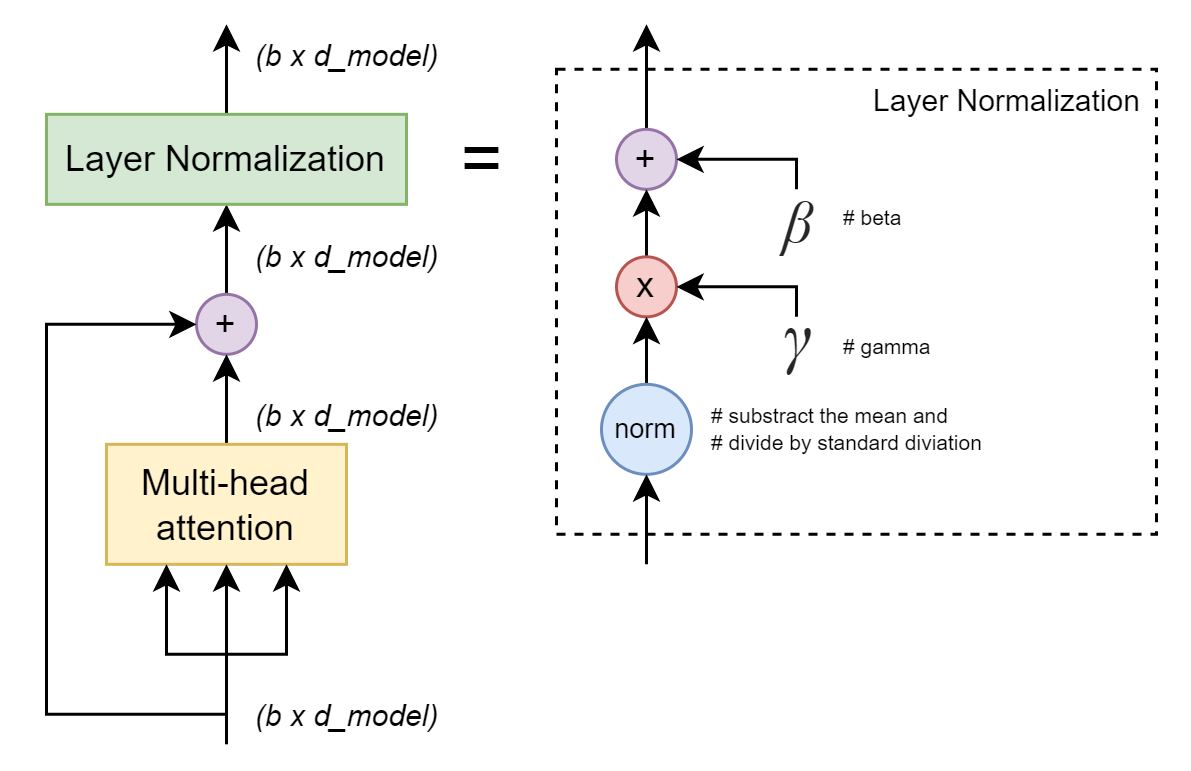
公式
对于输入向量 x ∈ R d m o d e l x \in \mathbb{R}^{d_{model}} x∈Rdmodel:
μ = 1 d ∑ i = 1 d x i (均值) σ 2 = 1 d ∑ i = 1 d ( x i − μ ) 2 (方差) x ^ = x − μ σ 2 + ϵ (标准化) y = γ ⋅ x ^ + β (可学习缩放平移) \begin{aligned} \mu &= \frac{1}{d}\sum_{i=1}^{d} x_i \quad &\text{(均值)}\\ \sigma^2 &= \frac{1}{d}\sum_{i=1}^{d} (x_i - \mu)^2 \quad &\text{(方差)}\\ \hat{x} &= \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} \quad &\text{(标准化)}\\ y &= \gamma \cdot \hat{x} + \beta \quad &\text{(可学习缩放平移)} \end{aligned} μσ2x^y=d1i=1∑dxi=d1i=1∑d(xi−μ)2=σ2+ϵ x−μ=γ⋅x^+β(均值)(方差)(标准化)(可学习缩放平移)
ϵ \epsilon ϵ:数值稳定项(通常 1e-6)
γ , β \gamma, \beta γ,β:可学习参数,初始化为 1 和 0
PyTorch 实现
python
import torch
import torch.nn as nn
class LayerNormalization(nn.Module):
"""层归一化实现"""
def __init__(self, features: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
# 可学习的缩放和平移参数
self.gamma = nn.Parameter(torch.ones(features)) # γ
self.beta = nn.Parameter(torch.zeros(features)) # β
def forward(self, x: torch.Tensor):
"""
Args:
x: [batch_size, seq_len, features]
Returns:
normalized: [batch_size, seq_len, features]
"""
# 沿特征维度计算均值和标准差
mean = x.mean(dim=-1, keepdim=True) # [batch, seq, 1]
std = x.std(dim=-1, keepdim=True) # [batch, seq, 1]
# 标准化 + 可学习变换
x_norm = (x - mean) / torch.sqrt(std**2 + self.eps)
return self.gamma * x_norm + self.beta细节
| 要点 | 说明 |
|---|---|
dim=-1 |
对最后一个维度(特征维)计算统计量 |
keepdim=True |
保持维度便于广播计算 |
eps |
防止除零,保证数值稳定 |
nn.Parameter |
使 γ/β 成为可训练参数 |
组件二:位置前馈网络(Position-wise Feed-Forward Network)
FFN (前馈神经网络 Feedforward Neural Network)是最大的概念,只要数据单向传播即属于 FFN;
MLP(Multi-Layer Perceptron) 是 FFN 的子集,限定为全连接层组成的网络;
Transformer 的 FFN 模块是 MLP 的特例,结构固定为 "升维→激活→降维"
FFN是数据流向层面的概念;
MLP强调全连接层的堆叠;
Transformer 的 FFN是 MLP 在 Transformer 中的标准化实现
《Attention Is All You Need》论文原文
用论文里的字母表示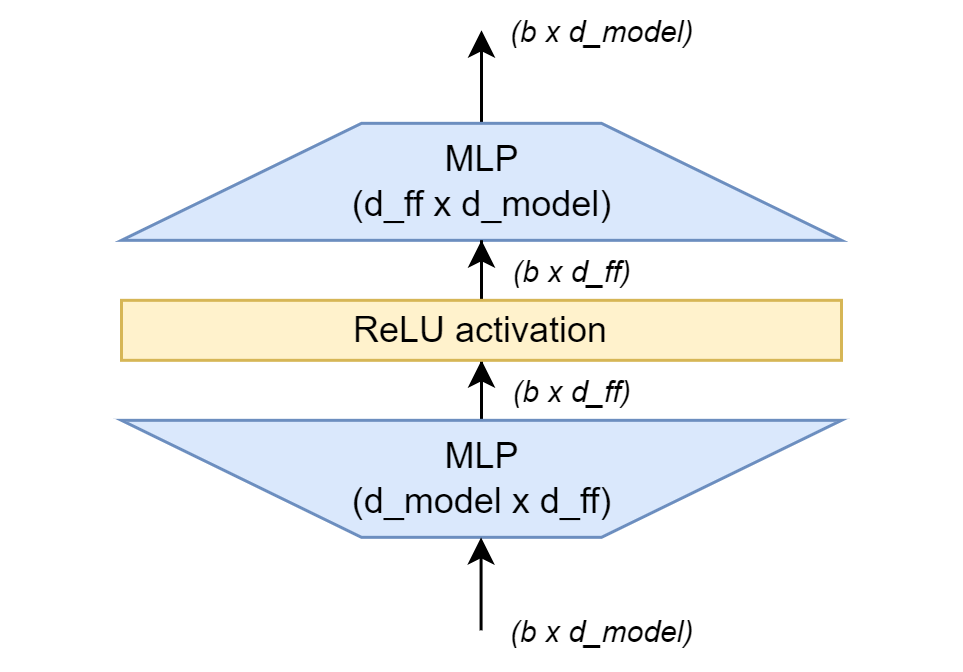
结构
输入: [batch, seq_len, d_model]
│
▼
┌─────────────────┐
│ Linear: d_model → d_ff │ (d_ff = 4×d_model)
└─────────────────┘
│
▼
┌─────────────────┐
│ ReLU │
└─────────────────┘
│
▼
┌─────────────────┐
│ Dropout(p) │
└─────────────────┘
│
▼
┌─────────────────┐
│ Linear: d_ff → d_model │
└─────────────────┘
│
▼
输出: [batch, seq_len, d_model] ✓PyTorch 实现
python
import torch
import torch.nn as nn
class PositionwiseFeedForward(nn.Module):
"""位置前馈网络实现"""
def __init__(self, d_model: int, d_ff: int, dropout: float):
super().__init__()
self.linear_1 = nn.Linear(d_model, d_ff) # 升维
self.activation = nn.ReLU() # 激活函数
self.dropout = nn.Dropout(dropout) # 正则化
self.linear_2 = nn.Linear(d_ff, d_model) # 降维
def forward(self, x: torch.Tensor):
"""
Args:
x: [batch_size, seq_len, d_model]
Returns:
output: [batch_size, seq_len, d_model]
"""
x = self.linear_1(x) # [batch, seq, d_ff]
x = self.activation(x) # ReLU
x = self.dropout(x) # Dropout
x = self.linear_2(x) # [batch, seq, d_model]
return x组件三:Add & Norm结构
Add 在这里就是残差连接
残差连接(Residual Connection)配合层归一化形成标准子层结构:
输出 = LayerNorm( 输入 + Dropout(子层(输入)) )Transformer这里的点子来自这里
Deep Residual Learning for Image Recognition
这几人的大作 Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
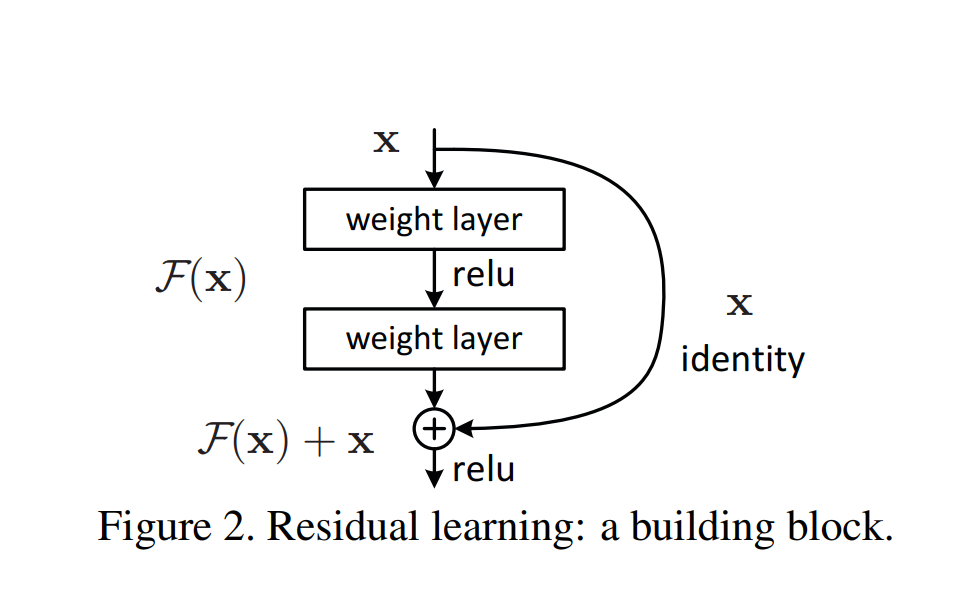
(左)有 残差连接,(右)无残差连接。
数据流向
输入 x
│
├─────────────────┐
│ │
▼ │
[子层: MHA 或 FFN] │
│ │
▼ │
[Dropout] │
│ │
▼ │
[+ 残差相加] ◄──────┘
│
▼
[LayerNorm]
│
▼
输出 (形状与输入相同)PyTorch 实现
python
import torch
import torch.nn as nn
# LayerNormalization 已定义
class ResidualConnection(nn.Module):
"""残差连接 + 层归一化封装"""
def __init__(self, features: int, dropout: float):
super().__init__()
self.dropout = nn.Dropout(dropout)
self.norm = LayerNormalization(features)
def forward(self, x: torch.Tensor, sublayer: nn.Module):
"""
Args:
x: 输入张量 [batch, seq_len, features]
sublayer: 子层模块(如 MultiHeadAttention 或 PositionwiseFeedForward)
Returns:
output: [batch, seq_len, features]
"""
# 标准流程: LayerNorm(x + Dropout(sublayer(x)))
sublayer_out = sublayer(x) # 子层计算
return self.norm(x + self.dropout(sublayer_out)) # 残差 + 归一化使用示例
python
# 在 Encoder 块中使用
mha = MultiHeadAttention(d_model=512, num_heads=8, dropout=0.1)
residual_mha = ResidualConnection(features=512, dropout=0.1)
# 前向传播
x = residual_mha(x, sublayer=mha) # x 形状保持不变测试代码
python
import torch
import torch.nn as nn
## LayerNormalization
## PositionwiseFeedForward
## ResidualConnection
print("\n--- 测试支撑组件 ---")
# 参数设置
batch_size, seq_len, d_model = 4, 10, 512
d_ff, dropout = 2048, 0.1
dummy_input = torch.randn(batch_size, seq_len, d_model)
# 测试 LayerNormalization
ln = LayerNormalization(d_model)
ln_out = ln(dummy_input)
assert ln_out.shape == dummy_input.shape
print("LayerNormalization 形状验证通过")
# 测试 PositionwiseFeedForward
ffn = PositionwiseFeedForward(d_model, d_ff, dropout)
ffn_out = ffn(dummy_input)
assert ffn_out.shape == dummy_input.shape
print("PositionwiseFeedForward 形状验证通过")
# 测试 ResidualConnection(用 Linear 模拟子层)
dummy_sublayer = nn.Linear(d_model, d_model)
residual = ResidualConnection(d_model, dropout)
res_out = residual(dummy_input, dummy_sublayer)
assert res_out.shape == dummy_input.shape
print("ResidualConnection 形状验证通过")
print("\n所有支撑组件测试通过!")组件组合预览:Encoder 块结构
输入
│
▼
┌─────────────────────┐
│ Multi-Head Attention │
│ (Part 3) │
└─────────────────────┘
│
▼
┌─────────────────────┐
│ Add & Norm │ ← ResidualConnection
│ (x + Dropout(MHA)) │
│ → LayerNorm │
└─────────────────────┘
│
▼
┌─────────────────────┐
│ Position-wise FFN │ ← PositionwiseFeedForward
│ (Linear→ReLU→Linear)│
└─────────────────────┘
│
▼
┌─────────────────────┐
│ Add & Norm │ ← ResidualConnection
│ (x + Dropout(FFN)) │
│ → LayerNorm │
└─────────────────────┘
│
▼
输出 → 下一个 Encoder 块每个子层都遵循:子层 → Dropout → 残差相加 → LayerNorm 的统一模式
完整代码
cpp
import torch
import torch.nn as nn
import torch
import torch.nn as nn
class PositionwiseFeedForward(nn.Module):
"""位置前馈网络实现"""
def __init__(self, d_model: int, d_ff: int, dropout: float):
super().__init__()
self.linear_1 = nn.Linear(d_model, d_ff) # 升维
self.activation = nn.ReLU() # 激活函数
self.dropout = nn.Dropout(dropout) # 正则化
self.linear_2 = nn.Linear(d_ff, d_model) # 降维
def forward(self, x: torch.Tensor):
"""
Args:
x: [batch_size, seq_len, d_model]
Returns:
output: [batch_size, seq_len, d_model]
"""
x = self.linear_1(x) # [batch, seq, d_ff]
x = self.activation(x) # ReLU
x = self.dropout(x) # Dropout
x = self.linear_2(x) # [batch, seq, d_model]
return x
class LayerNormalization(nn.Module):
"""层归一化实现"""
def __init__(self, features: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
# 可学习的缩放和平移参数
self.gamma = nn.Parameter(torch.ones(features)) # γ
self.beta = nn.Parameter(torch.zeros(features)) # β
def forward(self, x: torch.Tensor):
"""
Args:
x: [batch_size, seq_len, features]
Returns:
normalized: [batch_size, seq_len, features]
"""
# 沿特征维度计算均值和标准差
mean = x.mean(dim=-1, keepdim=True) # [batch, seq, 1]
std = x.std(dim=-1, keepdim=True) # [batch, seq, 1]
# 标准化 + 可学习变换
x_norm = (x - mean) / torch.sqrt(std**2 + self.eps)
return self.gamma * x_norm + self.beta
class ResidualConnection(nn.Module):
"""残差连接 + 层归一化封装"""
def __init__(self, features: int, dropout: float):
super().__init__()
self.dropout = nn.Dropout(dropout)
self.norm = LayerNormalization(features)
def forward(self, x: torch.Tensor, sublayer: nn.Module):
"""
Args:
x: 输入张量 [batch, seq_len, features]
sublayer: 子层模块(如 MultiHeadAttention 或 PositionwiseFeedForward)
Returns:
output: [batch, seq_len, features]
"""
# 标准流程: LayerNorm(x + Dropout(sublayer(x)))
sublayer_out = sublayer(x) # 子层计算
return self.norm(x + self.dropout(sublayer_out)) # 残差 + 归一化
print("\n--- 测试支撑组件 ---")
# 参数设置
batch_size, seq_len, d_model = 4, 10, 512
d_ff, dropout = 2048, 0.1
dummy_input = torch.randn(batch_size, seq_len, d_model)
# 测试 LayerNormalization
ln = LayerNormalization(d_model)
ln_out = ln(dummy_input)
assert ln_out.shape == dummy_input.shape
print("LayerNormalization 形状验证通过")
# 测试 PositionwiseFeedForward
ffn = PositionwiseFeedForward(d_model, d_ff, dropout)
ffn_out = ffn(dummy_input)
assert ffn_out.shape == dummy_input.shape
print("PositionwiseFeedForward 形状验证通过")
# 测试 ResidualConnection(用 Linear 模拟子层)
dummy_sublayer = nn.Linear(d_model, d_model)
residual = ResidualConnection(d_model, dropout)
res_out = residual(dummy_input, dummy_sublayer)
assert res_out.shape == dummy_input.shape
print("ResidualConnection 形状验证通过")
print("\n所有支撑组件测试通过!")输出
cpp
--- 测试支撑组件 ---
LayerNormalization 形状验证通过
PositionwiseFeedForward 形状验证通过
ResidualConnection 形状验证通过
所有支撑组件测试通过!下一步预告
从零实现Transformer:第 5 部分 - 构建编码器(The Encoder)
将把本部分的三个组件与多头注意力组装成完整的 Encoder Block,并堆叠多个块形成 Transformer 编码器!
python
# 伪代码预览
class EncoderBlock(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
self.mha = MultiHeadAttention(d_model, num_heads, dropout)
self.ffn = PositionwiseFeedForward(d_model, d_ff, dropout)
self.residual1 = ResidualConnection(d_model, dropout)
self.residual2 = ResidualConnection(d_model, dropout)
def forward(self, x, mask):
x = self.residual1(x, lambda t: self.mha(t, t, t, mask))
x = self.residual2(x, self.ffn)
return x已经准备好组装第一个 Transformer 模块了