摘要:在接入 OpenAI、Anthropic、Gemini 等多种大模型协议时,token 统计经常会遇到协议格式不同、usage 字段不稳定、流式响应难统计、业务侧还要兜底估算等问题。本文介绍一个 Go 语言库
tokencalc:它专注把不同协议下的 token 统计能力统一起来,支持本地估算、上游 usage 归一化、流式响应聚合、自定义协议扩展和批量统计。

一、为什么需要 tokencalc
做大模型网关、AI 应用后台或者内部调用审计时,token 统计通常不是一个"顺手 len() 一下"的问题。
真实业务里常见的情况是:
- OpenAI Chat、OpenAI Responses、Anthropic Messages、Gemini Contents 的请求和响应结构都不一样。
- 有些上游会返回完整
usage,有些只返回部分字段,有些干脆不返回。 - 流式响应是一段段 chunk 回来的,不能等同于普通 JSON 响应。
- 图片、音频、文件等非文本内容也需要有一个可控的占位估算策略。
- 业务系统希望最终拿到统一结构:
prompt_tokens、completion_tokens、total_tokens。
tokencalc 的目标就是把这些差异收敛到一个统一 API 里。它不负责网关转发、扣费、落库或鉴权,而是专注做一件事:把不同协议下的 token 统计能力统一起来。
项目安装方式:
bash
go get github.com/xy200303/tokencalc二、当前支持能力
目前 tokencalc 支持的协议包括:
openai_chatopenai_responsesanthropic_messagesgemini_contents
核心能力包括:
- 根据模型名解析 tokenizer encoding。
- 从请求体或响应体自动识别模型。
- 优先读取上游返回的 usage。
- usage 不完整时自动与本地估算合并。
- 无 usage 时从 prompt 和 completion 文本做本地估算。
- 支持流式响应 chunk 聚合与增量统计。
- 支持自定义 estimator 和 stream collector。
- 支持批量文本统计与批量请求估算。
三、整体估算流程
tokencalc 的主流程可以概括为四步:
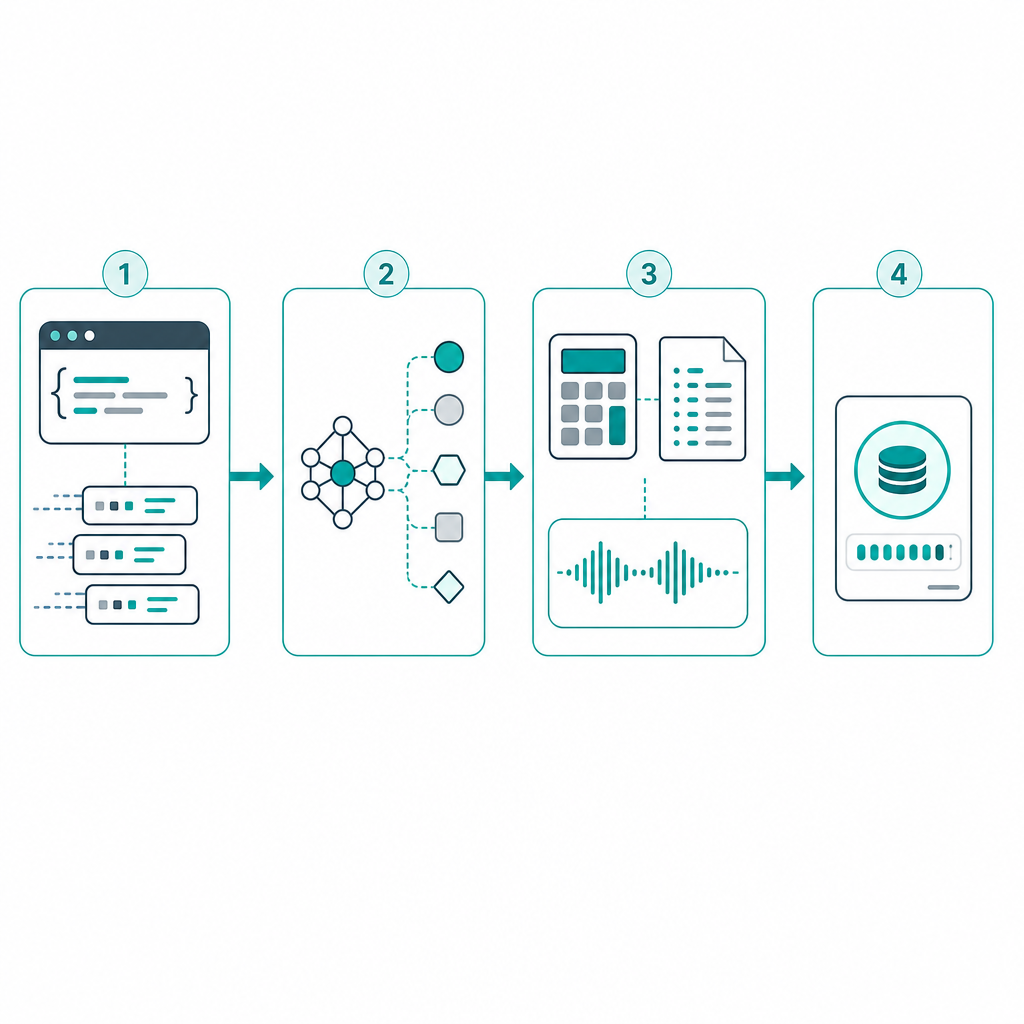
- 协议输入:调用方传入协议类型、请求体、响应体、模型信息或上游 usage。
- 模型解析 :优先使用
UpstreamModel,其次是RequestModel,再从请求体和响应体中提取模型字段。 - usage 归一化或本地估算:如果上游 usage 完整,直接使用;如果 usage 不完整,则结合本地估算补齐。
- 输出统一结果 :最终得到统一的
Usage、估算来源、模型、encoding 和说明信息。
关键类型非常简单:
go
type EstimateRequest struct {
Protocol Protocol
RequestModel string
UpstreamModel string
IsStream bool
RequestBody []byte
ResponseBody []byte
ReportedUsage *Usage
}
type EstimateResult struct {
Usage Usage
ResolvedModel string
Source EstimateSource
Encoding string
Supported bool
Note string
PromptTextLen int
CompletionTextLen int
}
type Usage struct {
PromptTokens int
CompletionTokens int
TotalTokens int
}其中 EstimateResult.Source 表示这次统计结果的来源:
reported_usage:直接使用上游或调用方传入的 usage。local_estimate:本地从文本估算。merged:上游 usage 不完整,和本地估算合并。unsupported:当前协议或载荷无法处理。
这个字段在业务里很有用:它能告诉你当前 token 结果到底是"上游精确返回",还是"本地兜底估算"。
四、快速开始:估算一次 OpenAI Chat 调用
最常见的使用方式是创建一个 service,然后调用 Estimate:
go
package main
import (
"fmt"
"log"
"github.com/xy200303/tokencalc"
)
func main() {
service := tokencalc.New()
result, err := service.Estimate(tokencalc.EstimateRequest{
Protocol: tokencalc.ProtocolOpenAIChat,
RequestBody: []byte(`{
"model":"gpt-4o-mini",
"messages":[
{"role":"system","content":"You are helpful."},
{"role":"user","content":"Count to three."}
]
}`),
ResponseBody: []byte(`{
"choices":[
{"message":{"role":"assistant","content":"One, two, three."}}
]
}`),
})
if err != nil {
log.Fatal(err)
}
fmt.Printf("usage=%+v\n", result.Usage)
fmt.Printf("source=%s model=%s encoding=%s\n",
result.Source,
result.ResolvedModel,
result.Encoding,
)
fmt.Printf("note=%s\n", result.Note)
}如果响应体里没有 usage,库会尝试从请求和响应里提取文本,再用对应 encoding 做本地估算。
如果响应体里已经有完整 usage:
json
{
"usage": {
"prompt_tokens": 111,
"completion_tokens": 222,
"total_tokens": 333
}
}那么结果会直接走 reported_usage,避免重复解析和估算。
五、usage 不完整时的合并策略
很多代理层或模型服务只会返回一部分 usage,比如只有 prompt_tokens。这时如果业务侧希望得到完整结构,就可以交给 tokencalc 合并:
go
result, err := service.Estimate(tokencalc.EstimateRequest{
Protocol: tokencalc.ProtocolOpenAIResponses,
RequestModel: "gpt-4.1-mini",
RequestBody: []byte(`{
"input":[
{
"role":"user",
"content":[{"type":"input_text","text":"Explain gravity in one sentence."}]
}
]
}`),
ResponseBody: []byte(`{
"output":[
{
"content":[{"type":"output_text","text":"Gravity pulls objects together."}]
}
]
}`),
ReportedUsage: &tokencalc.Usage{
PromptTokens: 50,
},
})
fmt.Println(result.Source) // merged
fmt.Printf("%+v\n", result.Usage)这里的设计思路是:上游已经明确返回的字段优先,本地只补足缺失部分。这样既尽量尊重上游计量结果,又能在字段缺失时保证业务结构完整。
六、流式响应:边接收边统计
流式响应是 token 统计里比较容易踩坑的部分。因为业务收到的是一段段 SSE chunk,而不是完整 JSON。
tokencalc 提供了 StreamingCounter,可以一边添加 chunk,一边拿到当前累计结果和相对上一次的增量:

go
counter, err := tokencalc.NewStreamingCounter(tokencalc.EstimateRequest{
Protocol: tokencalc.ProtocolOpenAIChat,
RequestModel: "gpt-4o-mini",
RequestBody: []byte(`{
"messages":[{"role":"user","content":"Count to three."}]
}`),
})
if err != nil {
log.Fatal(err)
}
chunks := [][]byte{
[]byte("data: {\"choices\":[{\"delta\":{\"content\":\"One\"}}]}\n\n"),
[]byte("data: {\"choices\":[{\"delta\":{\"content\":\"two\"}}]}\n\n"),
[]byte("data: [DONE]\n\n"),
}
for _, chunk := range chunks {
update, err := counter.AddChunk(chunk)
if err != nil {
log.Fatal(err)
}
if !update.Updated {
continue
}
fmt.Printf("累计 usage=%+v\n", update.Result.Usage)
fmt.Printf("本次增量 delta=%+v\n", update.Delta)
}
final, err := counter.FinalResult()
if err != nil {
log.Fatal(err)
}
fmt.Printf("最终 usage=%+v\n", final.Result.Usage)它的行为是:
AddChunk接收原始 chunk。- 如果当前 chunk 还不足以组成完整事件,会先缓存,返回
Updated=false。 - 一旦形成新的有效流式结果,就返回最新累计 usage。
Delta表示相对上一次成功统计的增量。FinalResult()用于在流结束时做最终校验。Clear()和Reset()支持复用同一个 counter,适合连续多轮对话。
如果某些模型是在最后一个 chunk 才返回总 usage,tokencalc 也会自动同步:中间先走本地估算,等上游 usage 出现后切到 reported_usage 或 merged。
七、扩展自定义协议
如果你的业务协议不是内置的四类,也可以注册自己的 estimator:
go
type myEstimator struct{}
func (myEstimator) ExtractPrompt(body []byte) (tokencalc.ExtractResult, error) {
return tokencalc.ExtractResult{
Text: "ping",
Supported: true,
}, nil
}
func (myEstimator) ExtractCompletion(body []byte, isStream bool) (tokencalc.ExtractResult, error) {
return tokencalc.ExtractResult{
Text: "pong",
Supported: true,
}, nil
}
func (myEstimator) ExtractReportedUsage(body []byte, isStream bool) (tokencalc.ReportedUsageResult, error) {
return tokencalc.ReportedUsageResult{}, nil
}
service := tokencalc.New(
tokencalc.WithEstimator("custom_echo", myEstimator{}),
)
result, err := service.Estimate(tokencalc.EstimateRequest{
Protocol: "custom_echo",
UpstreamModel: "gpt-4o-mini",
})
if err != nil {
log.Fatal(err)
}
fmt.Printf("%+v\n", result.Usage)这让 tokencalc 不只是一个固定协议工具,也可以作为业务内部协议的 token 统计底座。
八、非文本内容的占位估算
对于图片、音频、文件等非文本内容,项目采用可配置的占位估算策略。
默认值:
- 图片:
256token - 音频:
128token - 文件:
64token
如果你的业务对多模态输入有更激进或更保守的估算规则,可以这样覆盖:
go
service := tokencalc.New(
tokencalc.WithPlaceholderPolicy(tokencalc.PlaceholderPolicy{
ImageTokenCost: 512,
AudioTokenCost: 256,
FileTokenCost: 128,
}),
)九、批量统计与便捷函数
如果只是统计纯文本 token,可以直接调用:
go
count, encoding, err := tokencalc.CountText("gpt-4o-mini", "你好,帮我总结一下这段内容。")
if err != nil {
log.Fatal(err)
}
fmt.Println("count:", count)
fmt.Println("encoding:", encoding)如果需要批量统计:
go
service := tokencalc.New()
results := service.CountTexts([]tokencalc.CountTextRequest{
{Model: "gpt-4o-mini", Text: "hello"},
{Model: "claude-3-5-sonnet", Text: "world"},
{Model: "gemini-2.0-flash", Text: "batch example"},
})
for _, item := range results {
if item.Error != nil {
log.Fatal(item.Error)
}
fmt.Printf("count=%d encoding=%s\n", item.Count, item.Encoding)
}批量接口适合在同一个 service 上复用配置、协议实现和内部缓存,减少重复初始化成本。
十、性能表现
项目里提供了 benchmark:
bash
go test -run '^$' -bench . -benchmem .根据项目 README 中记录的一组 Windows/amd64 环境结果,可以看到几个趋势:
- 已带完整 usage 的响应路径最快,因为无需完整本地估算。
- 只统计请求 token 比完整请求加响应估算更轻。
- 单个完整流式 chunk 的直接估算很轻量,适合做增量统计。
- 流式场景会多一层事件聚合开销。
- Anthropic 和 Gemini 的本地估算分配更高,主要因为协议结构和占位符处理更复杂。
实际业务里的性能会受到 Go 版本、CPU、请求体大小和 payload 结构影响,建议在自己的场景里复测。
十一、我比较喜欢的几个设计点
第一,tokencalc 没有把自己做成"大模型网关全家桶",而是只解决 token 统计这个边界清晰的问题。这让它更容易被嵌入到已有系统里。
第二,reported_usage、local_estimate、merged 这几个来源状态很实用。业务侧不仅能拿到数字,还能知道数字的可信来源。
第三,流式统计没有强行要求调用方一次性拼完整响应,而是提供 StreamingCounter 帮你处理 chunk 缓存、累计值和增量值,这对网关场景非常友好。
第四,自定义 estimator 和 stream collector 给扩展留了口子。公司内部协议、代理层协议、实验性模型协议都可以接进去。
十二、总结
tokencalc 适合放在这些位置:
- 大模型网关的 token 统计层。
- AI 应用后台的调用成本估算模块。
- 请求审计、日志分析、成本看板。
- 多模型、多协议统一接入时的 usage 归一化层。
- 流式响应的实时 token 计数场景。
如果你的系统正在同时接入 OpenAI、Anthropic、Gemini 或其他兼容协议,并且希望统一统计 token,那么把这类逻辑沉淀成独立库会比散落在业务代码里更稳。
项目地址:
text
https://github.com/xy200303/tokencalc一句话概括:tokencalc 不做网关,不做计费,不做鉴权,只把 token 统计这件事做清楚。