一、案例
抓取电影天堂里面的电影信息
二、准备工作
在浏览器中输入 dy2018.com 我们需要抓取的内容就是下图中2026必看热片栏及下面的所有电影名和下载的地址
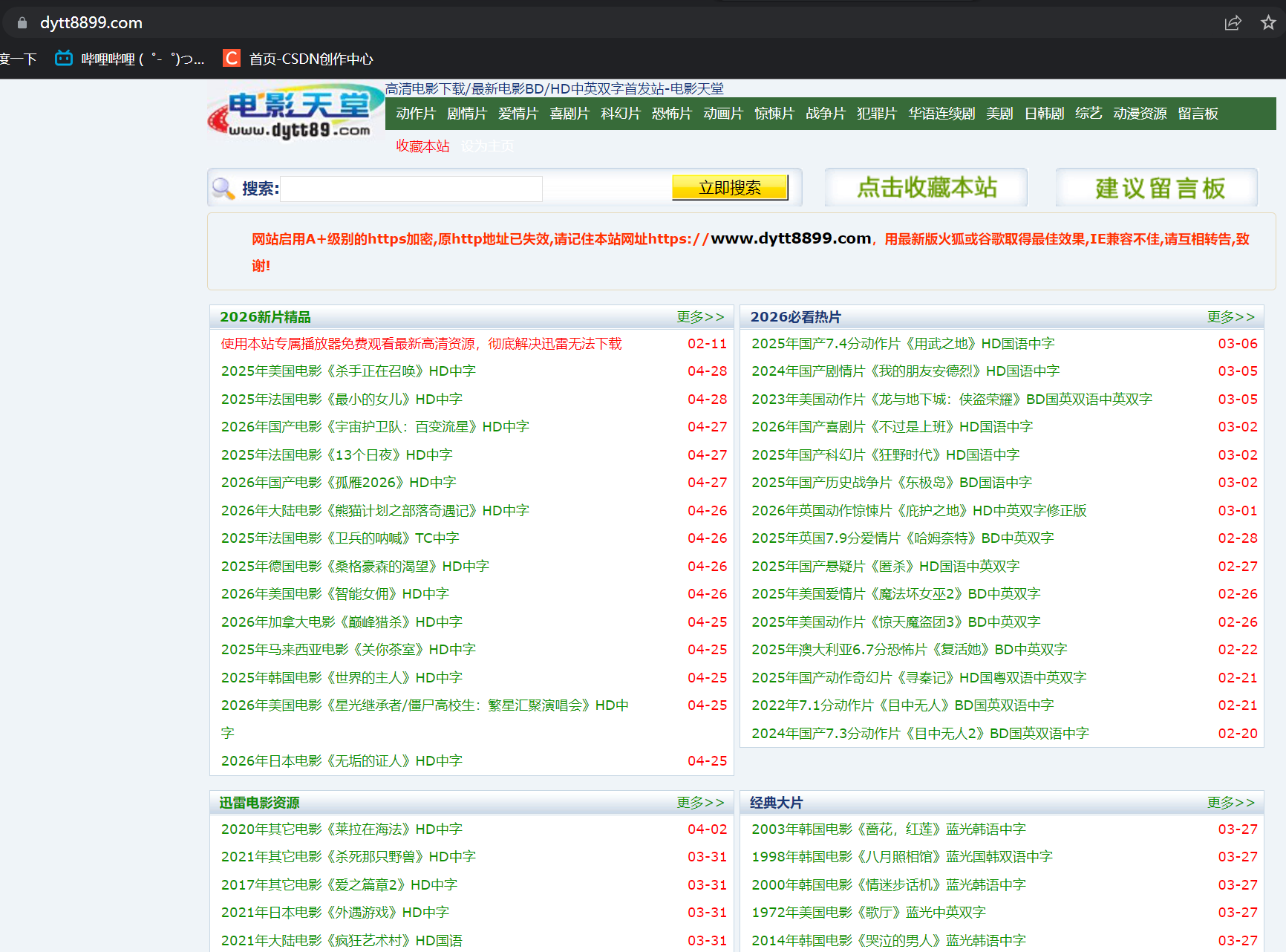
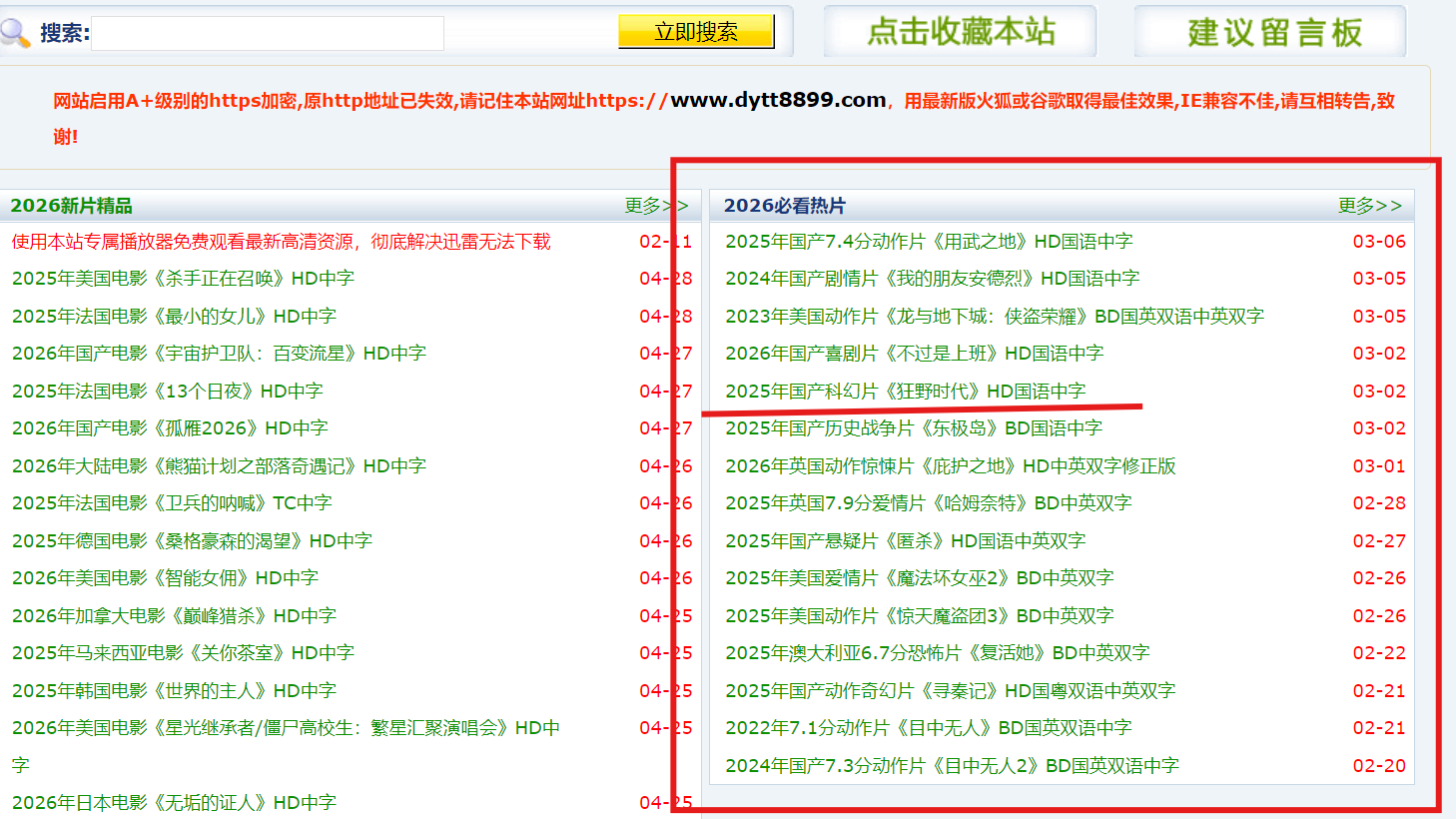
在下图红色框内随机选择一个电影点击进去(这里我选择的是画横线的电影)---- 这里建议找2021年以前的热片,2026年的你点进去可能最后面没有给下载地址。
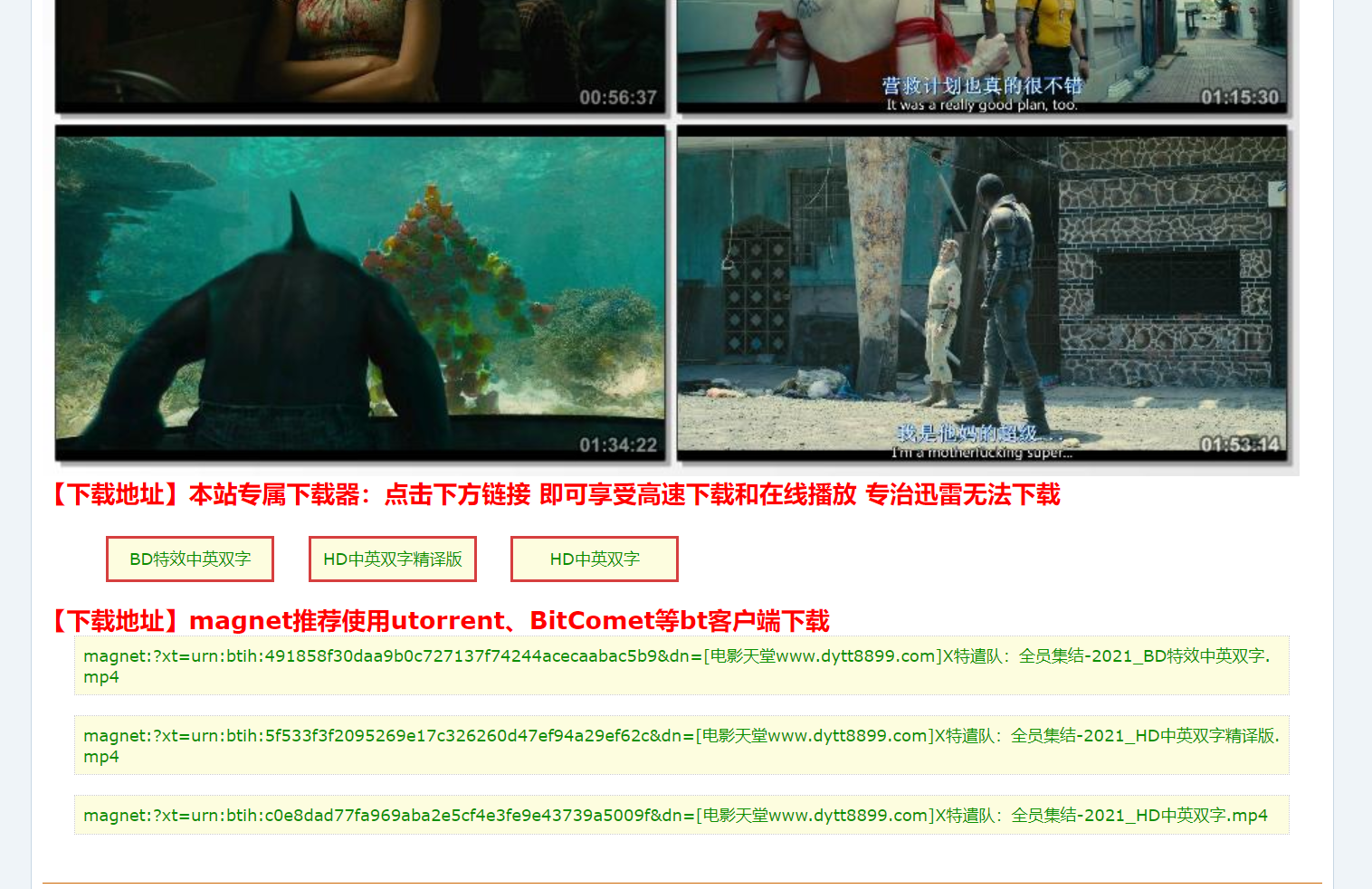
进入后网下拉网页,可以查看该电影的很多信心

网页的最底部----- 是该电影的下载地址
三、明确需求
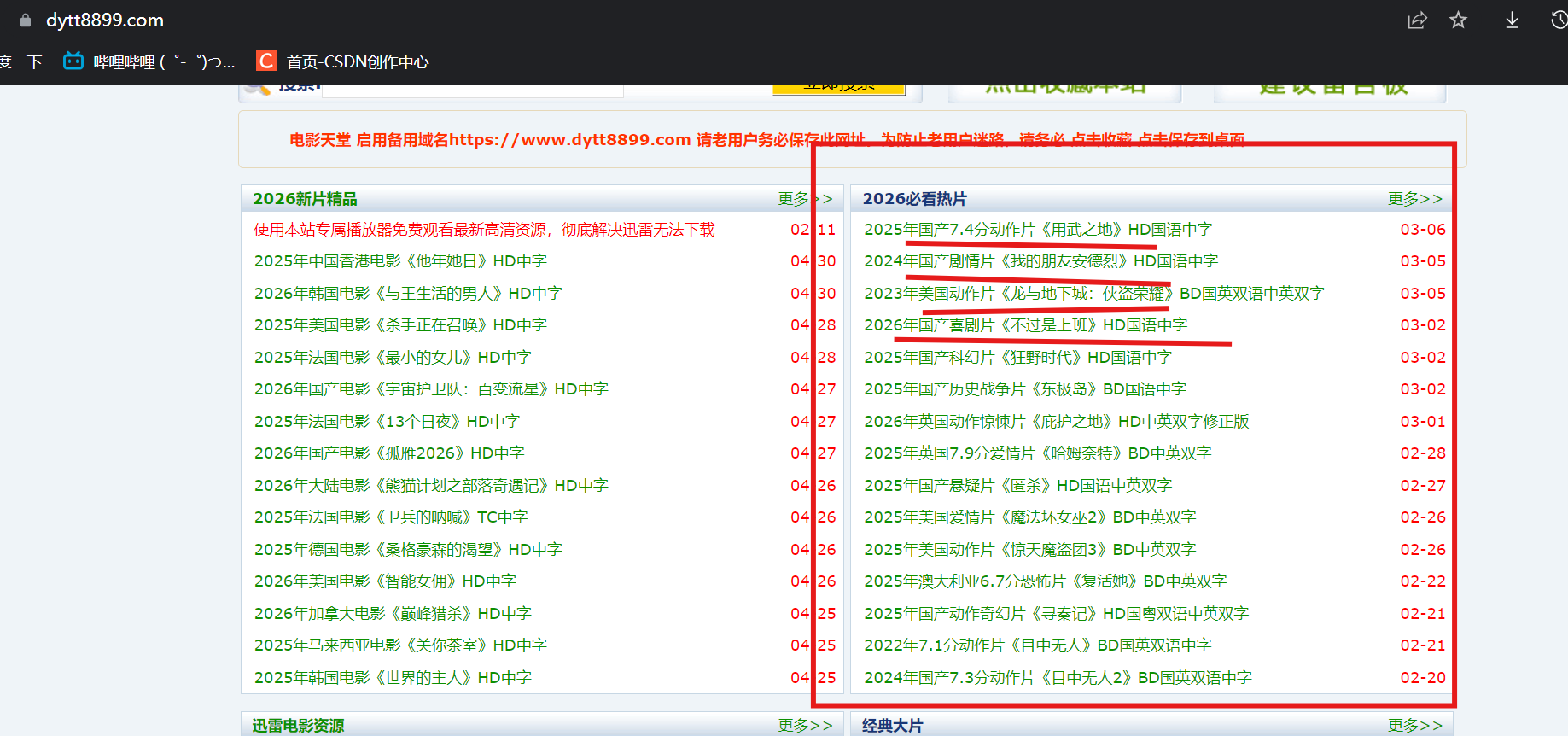
3.1提取到主页面中的每一个电影的背后的那个url地址
3.2访问子页面,提取到电影的名称以及下载的地址
四、找寻url地址
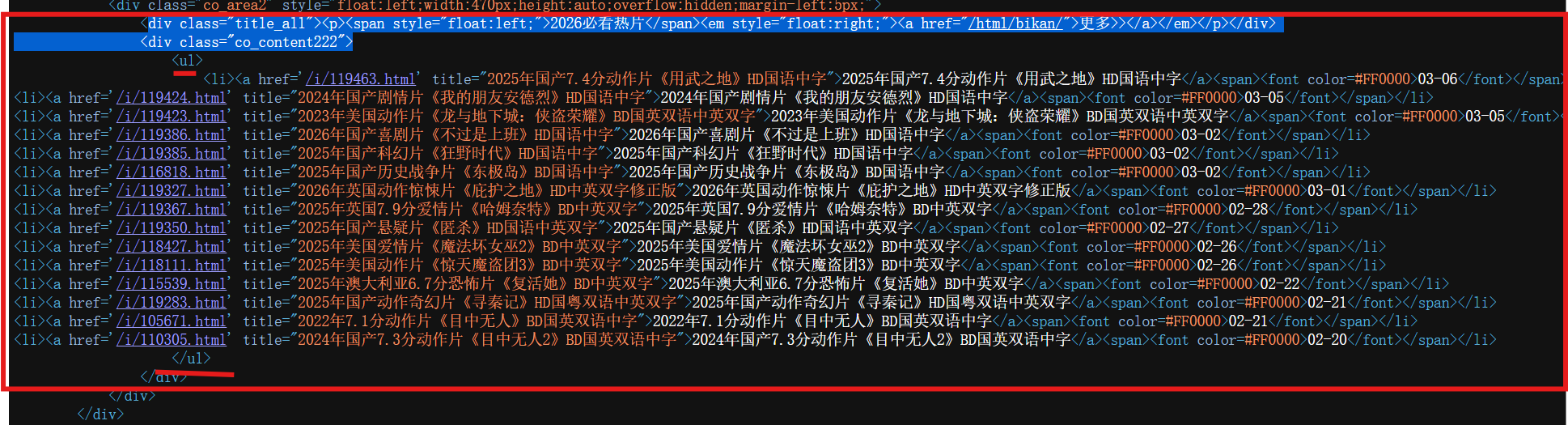
从上图可知:
1.a标签中属性href的值就是我们需要的真正url地址 ---(这个知识点是web前端的基础知识)
2.也可以知道想获取的如下图勾画出的数据,在<a>......</a> (省略号代表的就是我们需要的网页中的数据)
五、问题所在及解决方法
5.1问题所在:
这里不能直接就开始对着<ul>进行正则运算,你会发现前面后面都有很多个
5.2解决思路:
我们先在整个页面源代码中先去获取到如下图红色框起来的一部分内容,在去提取横线所勾出来的内容
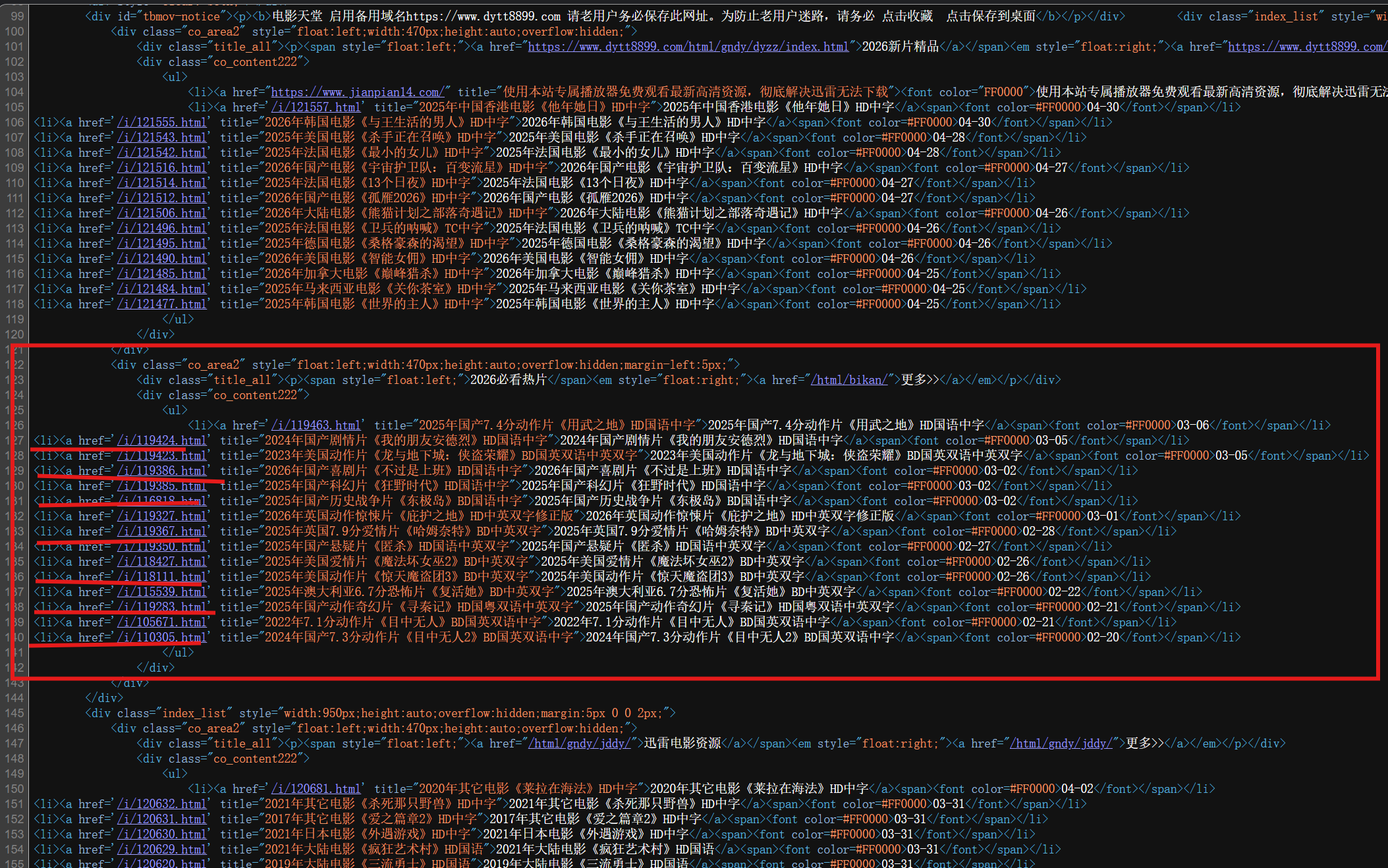
六、步骤
6.1提取到主页面中的每一个电影的背后的那个url地址
1.先拿到"2026必看热片"这块的HTML代码
2.然后从拿到的HTML代码中提取到href的值
6.2访问子页面,提取到电影的名称以及下载的地址
1.拿到子页面的页面源代码
2.数据提取
七、代码展示
7.1提取到主页面中的每一个电影的背后的那个url地址
import requests # 这里的地址来自网页栏的地址 url = "https://www.dytt8899.com/" req = requests.get(url) # print(req.text) #如果直接打印,里面的结果没有中文展示 打印中开头的有个代码中出现charset=gb2312 # 解决方法 ---- 修改字符集 req.encoding = "gbk" #这里就说明不是万能遇事就直接用 utf-8 字符集 ,如果不会判断,则上次提及的最笨的方法gbk和utf-8俩都试试看 print(req.text) #打印结果如下图:
1.提取2021必看热片部分的HTML代码
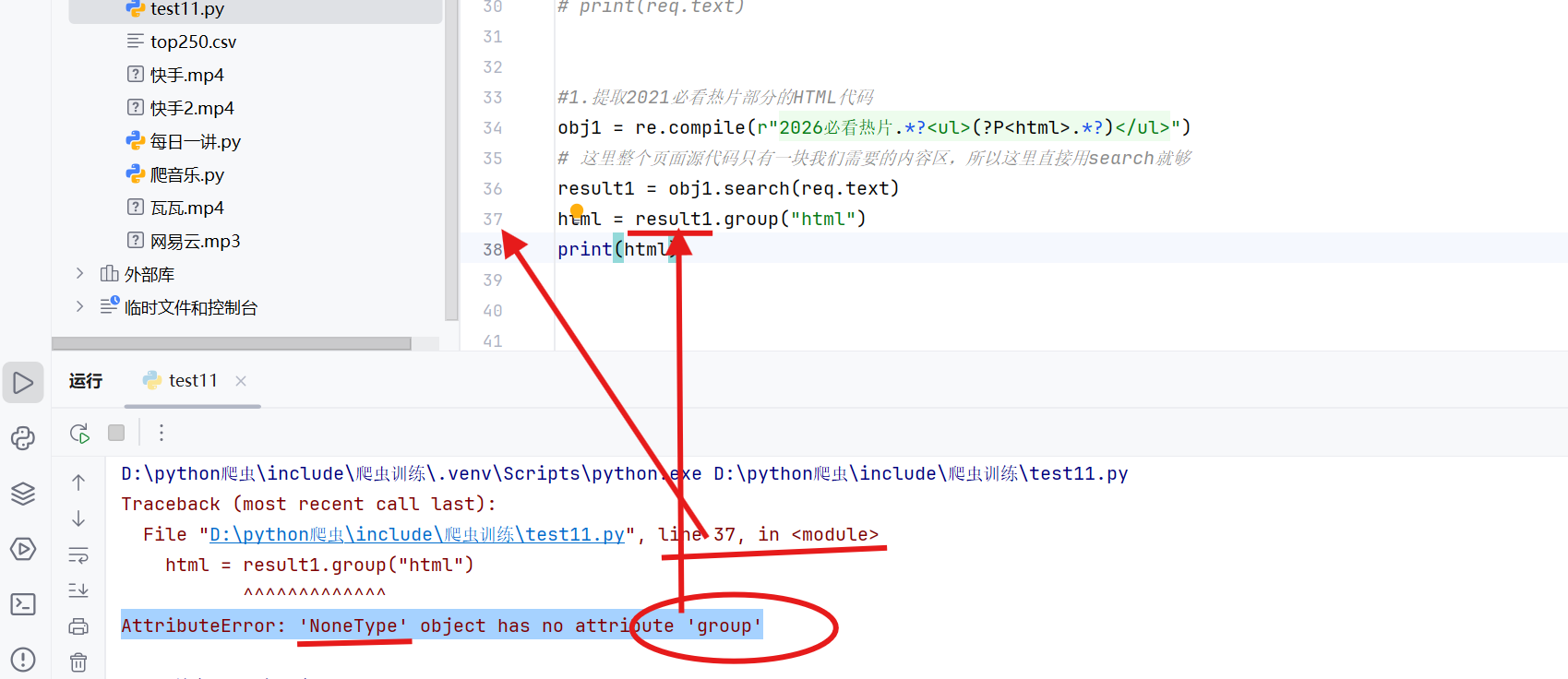
obj1 = re.compile(r"2026必看热片.*?<ul>(?P<html>.*?)</ul>") # 这里整个页面源代码只有一块我们需要的内容区,所以这里直接用search就够 result1 = obj1.search(req.text) html = result1.group("html") print(html) #这里打印时需要将之前的print(req.text)这个代码注释掉好一些;这里的结果会报错,报错形式如下图所示#AttributeError: 'NoneType' object has no attribute 'group'
#这个报错结果表明的意义是:result1是空的
#这里反推即可知道在34行代码中result1 = obj1.search(req.text)时search没有寻找到东西
#这里的原因是在网页源代码中我们去排除蓝色字体背景的代码中用到了换行,我们却没有去进行处理
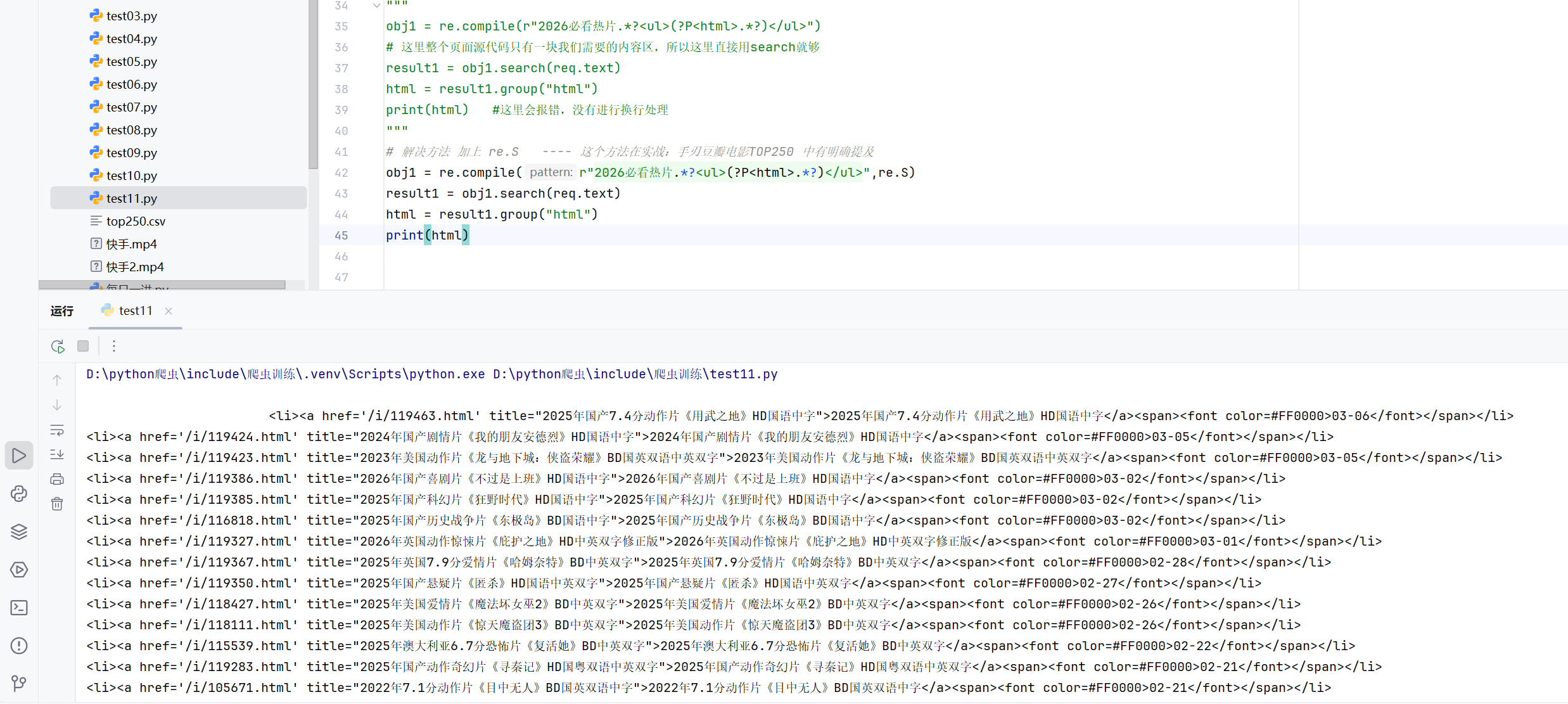
解决方法 ---> 加上 re.S ---- 这个方法在实战:手刃豆瓣电影TOP250 中有明确提及
obj1 = re.compile(r"2026必看热片.*?<ul>(?P<html>.*?)</ul>",re.S)
result1 = obj1.search(req.text)
html = result1.group("html")
print(html)
#这时打印的结果就是那一部分需要的内容区域
2.提取a标签中的hrefde值
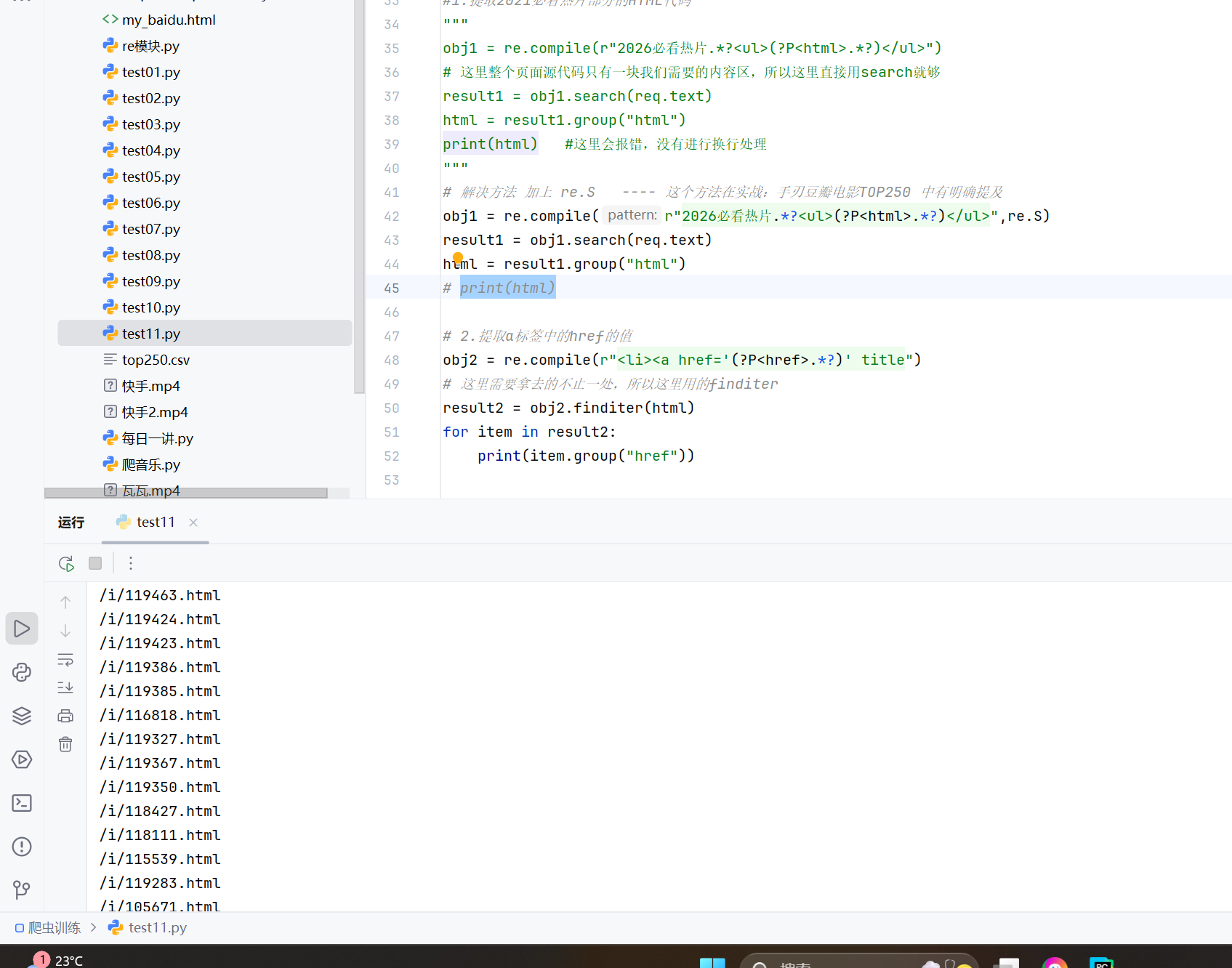
obj2 = re.compile(r"<li><a href='(?P<href>.*?)' title") # 这里需要拿去的不止一处,所以这里用的finditer result2 = obj2.finditer(html) for item in result2: print(item.group("href"))#这里使用循环打印出的结果,如下图可知已经获取到了链接(href的值)
3.注意:
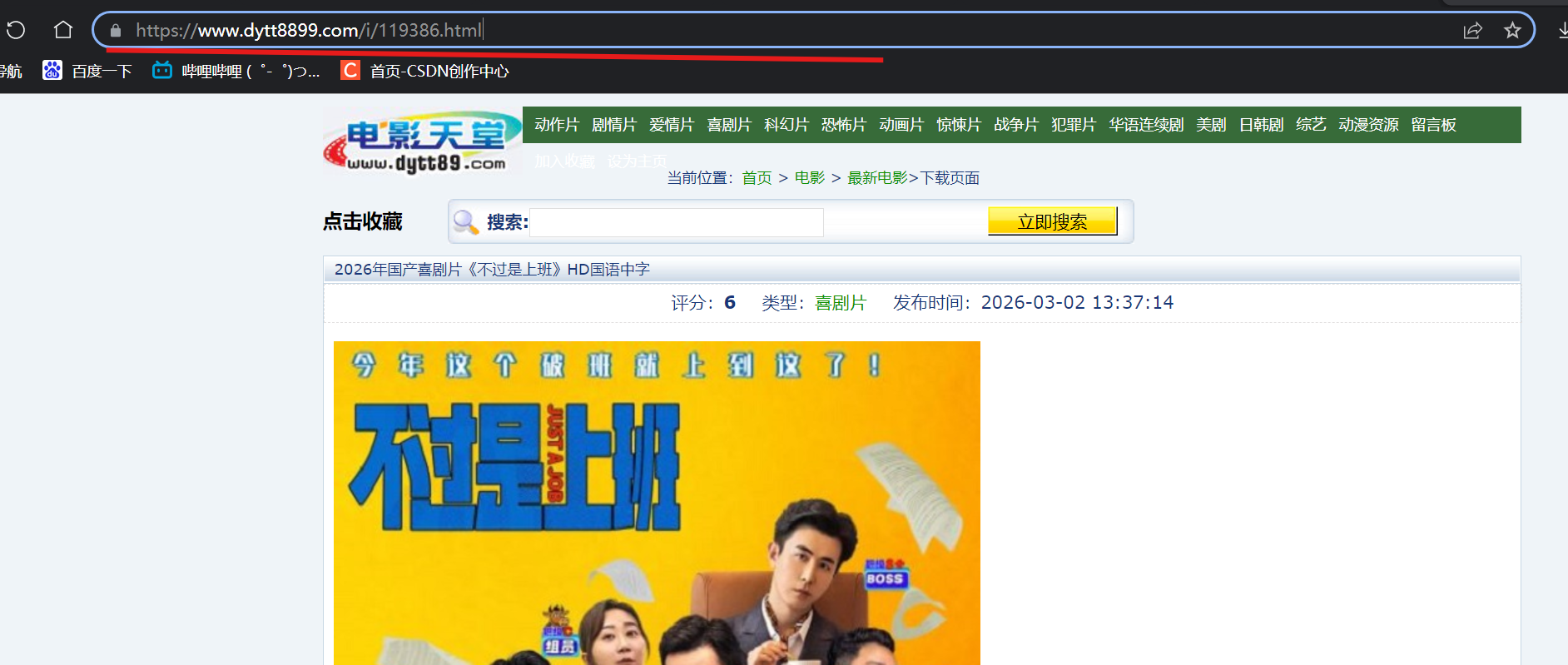
这里拿到的链接/i/119386.html,不能直接在服务器里直接进行搜索
原因 --- 这个链接之前少了一个域名(https://www.dytt8899.com/),得将其拼进去
加上域名之后则说明拿到的链接没有问题

7.2访问子页面,提取到电影的名称以及下载的地址
---- 提取下图中画横线的数据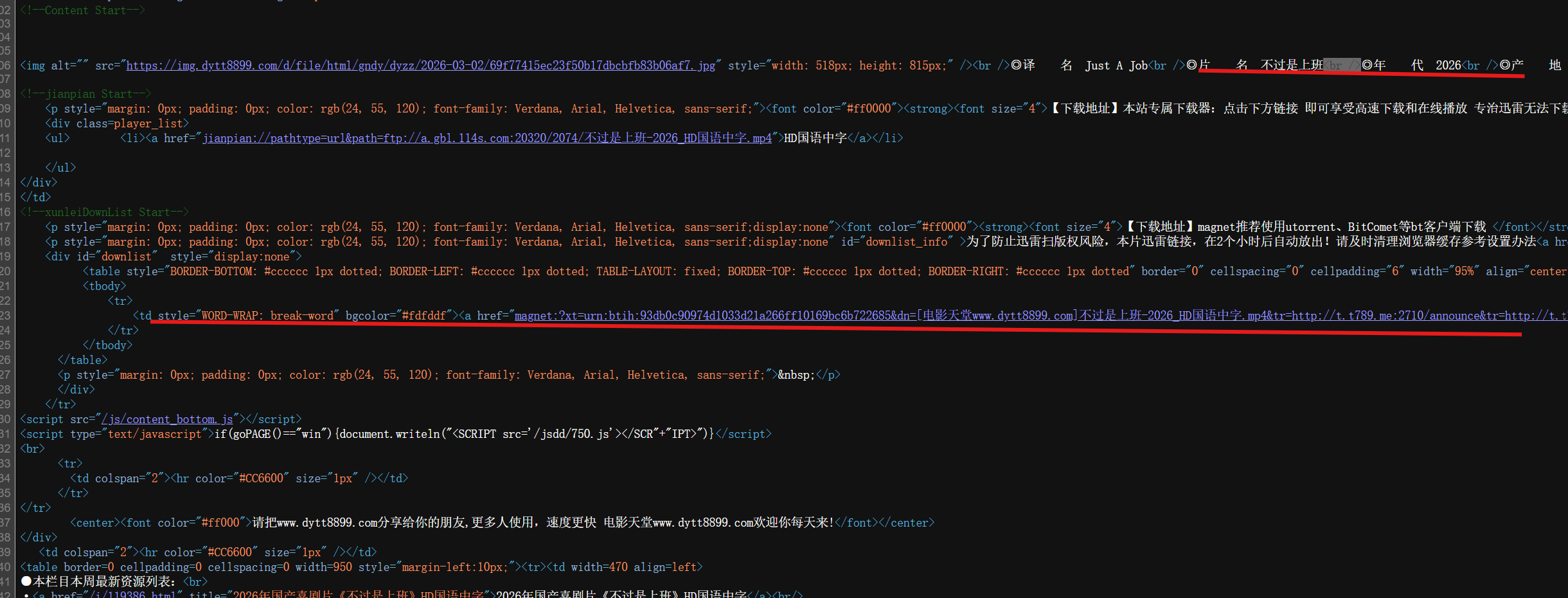
result2 = obj2.finditer(html) for item in result2: # print(item.group("href")) # strip去掉最后一个/ 原因如果不去掉拼出来的是 https://www.dytt8899.com//i/119386.html(com后面多了一个/) # 拼接出子页面的url child_url = url.strip("/") + item.group("href") child_req = requests.get(child_url) # 这里依旧需要设置字符集 否则结果会有乱码 child_req.encoding = "gbk" print(child_req.text)
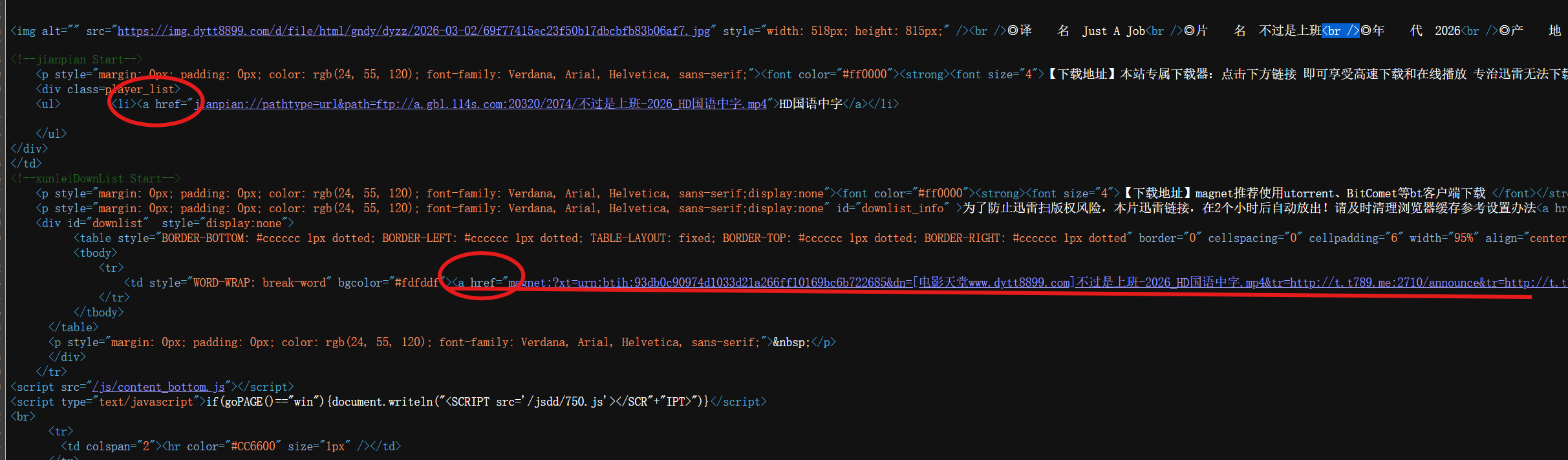
有上图可知:在获取电影下载地址的时候,不能直接提取a标签(有俩处a标签,导致有风险)
解决方法: 将a标签前面的标签带上
<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a hre
# 在这里可以直接用"片 名"来确定位置,这里比较特殊只有这一处才有 # 正常的普通的网页里面(往往都是重复的) ---> 找id --- 对于我们爬虫者来说一定要对id敏感 --- id的值一般情况下是整个网页里面唯一的一个值 # obj3 = re.compile(r"片 名")
obj3 = re.compile(r'<div id="Zoom">.*?片 名(?P<movie>.*?)<br />.*?' r'<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<download>.*?)">',re.S) headrs = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36" } for item in result2: child_url = url.strip("/") + item.group("href") child_req = requests.get(child_url,headers=headrs) # 这里依旧需要设置字符集 否则结果会有乱码 child_req.encoding = "gbk" result3 = obj3.search(child_req.text) move = result3.group("movie") download = result3.group("download") print(move,download)#打印结果
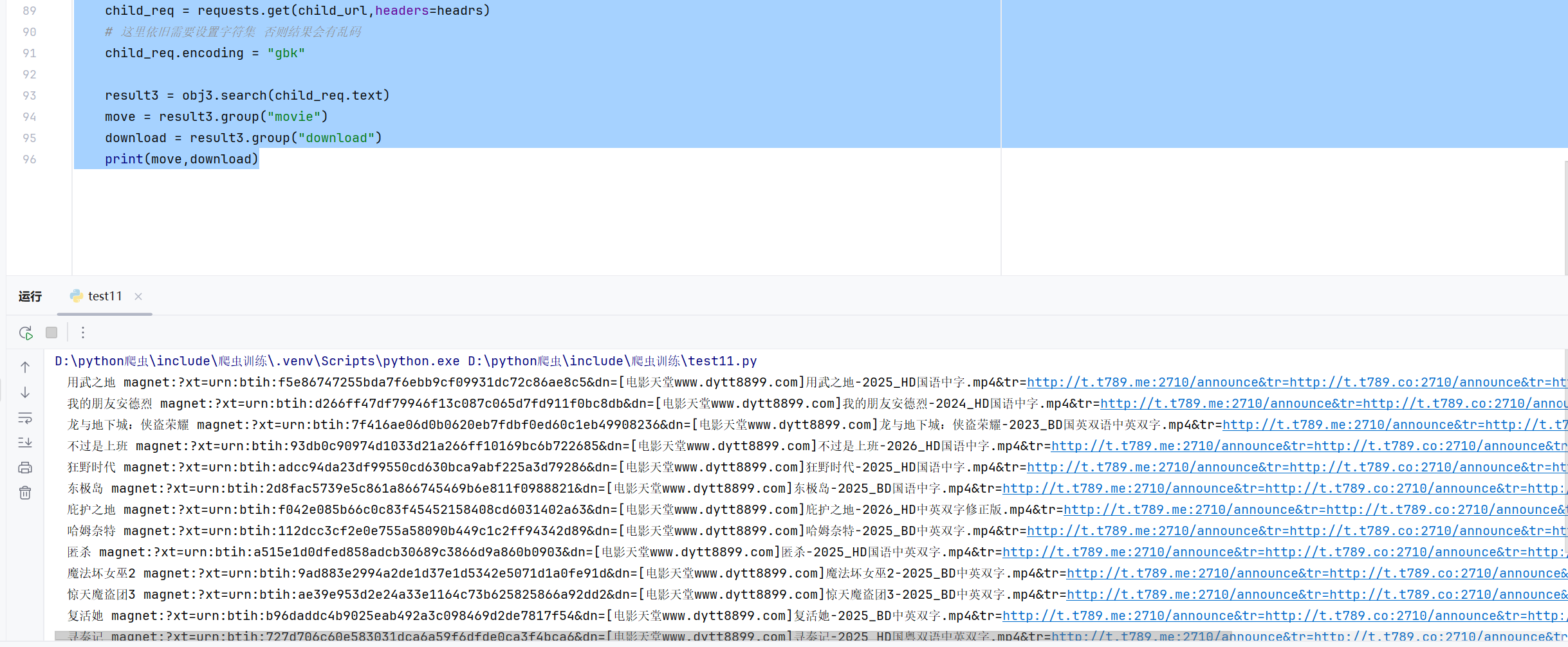
八、总体代码
------- 去掉了注释,和一些前面要用的代码,但是后续更换了的代码
import requests import re url = "https://www.dytt8899.com/" req = requests.get(url) req.encoding = "gbk" obj1 = re.compile(r"2026必看热片.*?<ul>(?P<html>.*?)</ul>",re.S) result1 = obj1.search(req.text) html = result1.group("html") # 2.提取a标签中的href的值 obj2 = re.compile(r"<li><a href='(?P<href>.*?)' title") result2 = obj2.finditer(html) obj3 = re.compile(r'<div id="Zoom">.*?片 名(?P<movie>.*?)<br />.*?' r'<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<download>.*?)">',re.S) headrs = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36" } for item in result2: child_url = url.strip("/") + item.group("href") child_req = requests.get(child_url,headers=headrs) child_req.encoding = "gbk" result3 = obj3.search(child_req.text) move = result3.group("movie") download = result3.group("download") print(move,download)