核心概念
排序 (ORDER BY) 决定了数据的物理存储顺序和索引结构。
分区 (PARTITION BY) 是逻辑管理单元,用于高效删除或维护数据。
稀疏索引 基于排序键和颗粒(8192行)实现快速定位,避免了全表扫描。
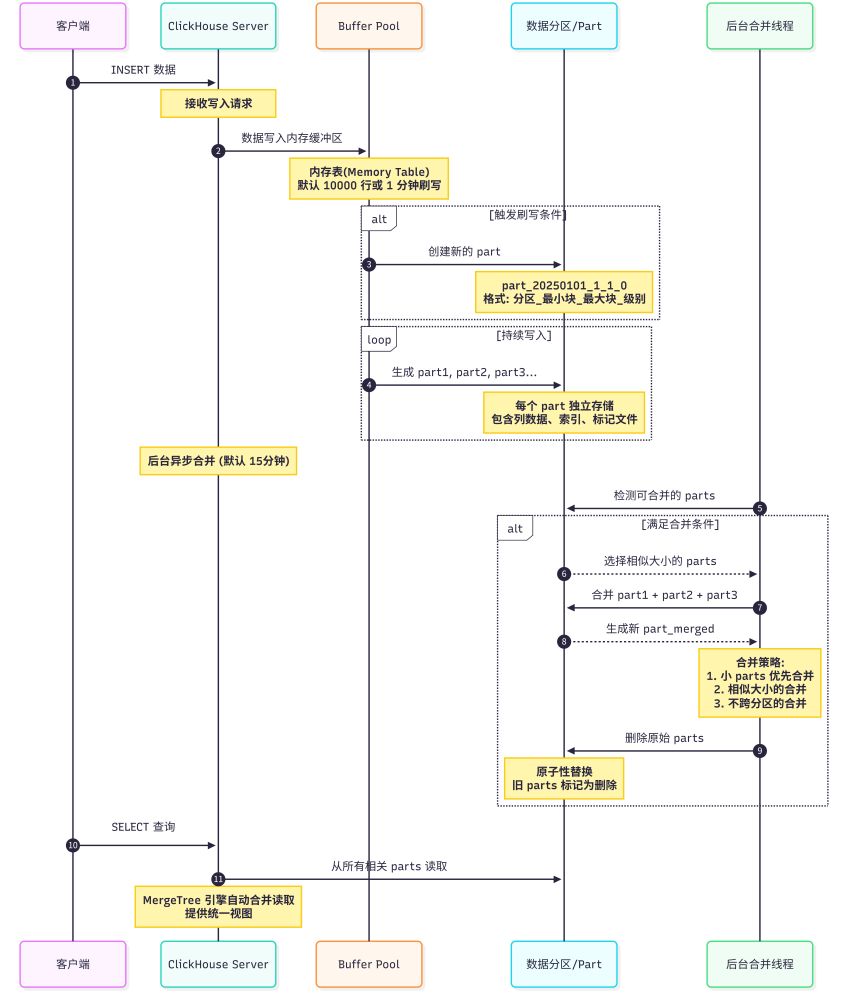
MergeTree 引擎 通过后台合并小 parts 来优化查询性能,支持海量数据的高效写入与读取。
MergeTree 采用的是稀疏索引
order by
在 ClickHouse 的 MergeTree引擎中,ORDER BY是必须的,原因在于它是整个存储和查询机制的基石。没有它,ClickHouse 就无法正常工作。
以下是必须设置 ORDER BY的几个核心原因:
- 它是数据存储的物理顺序(物理排序键)
ClickHouse 不像传统数据库(如 MySQL)那样使用 B+ 树做随机读写,而是采用列式存储 + 顺序读取。
要求:数据在磁盘上必须是有序的。ORDER BY定义了这一顺序。
后果:如果没有 ORDER BY,数据写入磁盘时是混乱的,无法利用顺序读的高性能优势,也无法构建后续的索引。
- 它是稀疏索引(主键)的基础
机制:ClickHouse 的"主键"(Primary Key)实际上是基于 ORDER BY列生成的稀疏索引(跳表)。
过程:系统会按照 ORDER BY的顺序,每隔 8192 行(index_granularity)记录一个索引标记(Mark)。
后果:如果没有 ORDER BY,就没有排序依据,也就无法生成这些索引标记。查询时引擎不知道如何快速跳过无关数据,只能全表扫描,性能极差。
- 它是数据合并(Merge)的依据
机制:MergeTree 的后台线程会将小的数据块(parts)合并成大的块。合并过程中,必须知道数据是按照什么顺序组织的,才能正确地进行归并排序和去重(如 ReplacingMergeTree)。
后果:如果没有 ORDER BY,后台合并无法进行,数据会一直以无序的小块存在,导致查询效率低下。
- 它是数据分片(Partition)后排序的依据
如果你还使用了 PARTITION BY,那么每个分区内部的数据依然必须按照 ORDER BY排序。
后果:没有 ORDER BY,分区内的数据也是乱序的,分区优势丧失。
总结
你可以把 ORDER BY理解为 ClickHouse 表结构的"地基":
没有它:数据物理无序 -> 无法建索引 -> 查询只能全扫 -> 后台无法合并 -> 性能崩溃。
有了它:数据物理有序 -> 可以建稀疏索引 -> 查询能快速定位 -> 后台能高效合并 -> 发挥极速性能。
因此,在设计 MergeTree表时,必须指定 ORDER BY,通常选择经常用于查询过滤、排序或聚合的列。
与mysql的对比
在 MySQL 等 OLTP 数据库中,ORDER BY通常是一个运行时的排序操作(Using filesort),确实只在查询时生效。但在 ClickHouse 的 MergeTree 引擎中,ORDER BY是一个建表时的物理存储定义。
它决定了数据在磁盘上"长什么样",而不是查询时"怎么排"。
它更像是一个"物理存储顺序 + 联合索引"的混合体

核心差异:
MySQL:索引是书的目录,书页(数据)本身可以是乱的。
ClickHouse:ORDER BY是书的页码顺序,书页(数据)本身就是按页码排好的。它的"索引"只是每隔几页贴一个便利贴(稀疏索引),告诉你"第100页的内容是XXX"。
物理布局,没有回表
ClickHouse 的 ORDER BY比 MySQL 的联合索引更"霸道",因为它直接决定了数据的物理布局:
数据局部性(Data Locality):由于数据在磁盘上按 ORDER BY物理排序,当你查询最近一天的数据时,ClickHouse 读取的是磁盘上连续的物理块,IO 效率极高。MySQL 即使走索引,也可能面临随机 IO。
无需回表:ClickHouse 是列存,ORDER BY的列通常会被单独存储,查询时直接读取对应的列文件,没有 MySQL 那种"回表"的概念。
合并的基础:后台的 Merge 过程本质是一个多路归并排序,它必须依赖 ORDER BY这个排序键来操作。
流程图
设计原则
是 (tenant_id, timestamp)还是 (timestamp, tenant_id)?
