背景介绍
这里记录一次迁移HDFS数据的过程
需求 :从A私有云hadoop2.10.2集群将所有数据迁移到B私有云HDFS集群hadoop 3.3.6
限制 :网络限制,只能申请开通A集群的一个端口14000供B集群访问
方案 :在目的集群B上 使用 dictcp 命令 A集群启动 HttpFS 服务作为代理,使用 WebHDFS 协议请求数据,每次迁移一级目录中的一个目录。
完成情况:整个集群有2T的数据,迁移总耗时8天,这个速度还能提升,因为一直有个连接超时导致任务卡顿的问题没有解决。
迁移步骤
1. 修改源集群A的httpfs配置文件
1.1 $HADOOP_HOME/etc/hadoop/httpfs-site.xml 文件增加如下内容
xml
<property>
<name>httpfs.http.hostname</name>
<value>0.0.0.0</value>
</property>
<property>
<name>httpfs.http.port</name>
<value>14000</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.http.authentication.type</name>
<value>simple</value>
</property>
<property>
<name>hadoop.http.authentication.simple.anonymous.allowed</name>
<value>true</value>
</property>1.2 修改 httpfs tomcat 配置文件
主要解决一直超时断开导致后续任务终止的问题
bash
$HADOOP_HOME/share/hadoop/httpfs/tomcat/conf/server.xml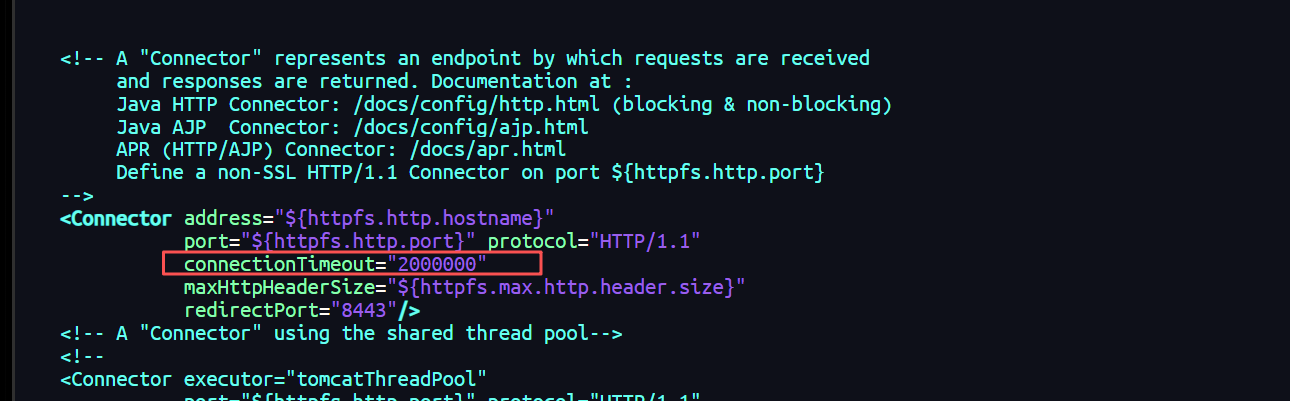
设置超时时间
bash
connectionTimeout="2000000"2. 启动源集群A的httpfs服务
bash
$HADOOP_HOME/sbin/httpfs.sh start3. 目的集群B执行 distcp 命令传输文件
切换至hadoop用户
bash
su - hadoop执行命令
bash
nohup hadoop distcp \
-Dmapreduce.task.timeout=0 \
-Dmapreduce.task.stuck.timeout-ms=0 \
-Ddfs.webhdfs.socket.connect-timeout=300000 \
-Ddfs.webhdfs.socket.read-timeout=600000 \
-Dipc.client.connect.timeout=300000 \
-Dipc.client.connect.max.retries=10 \
-Dipc.client.connect.retry.interval=10000 \
-Ddfs.http.client.retry.policy.enabled=true \
-Ddfs.http.client.retry.policy.spec=2000,5,10000,5 \
-skipcrccheck \
-update \
-m 5 \
-bandwidth 50 \
-numListstatusThreads 10 \
-i \
-strategy dynamic \
webhdfs://46.11.22.33:14000/1HGP6THTM \
hdfs://192.168.1.2:8020/1HGP6THTM > /data/great/logs/1HGP6THTM.out 2>&1 &1HGP6THTM 是其中一个目录
4. 迁移过程中实时监控状态
切换至hadoop用户
bash
su - hadoop查看distcp进程是否存在
bash
ps aux | grep distcp检查日志
bash
tail -f /data/great/logs/1HGP6THTM.out检查文件数量和大小
bash
hdfs dfs -count '/1HGP6THTM' | awk '
{
bytes=$3
if (bytes >= 1099511627776) {
size=sprintf("%.2f T", bytes/1099511627776)
} else if (bytes >= 1073741824) {
size=sprintf("%.2f G", bytes/1073741824)
} else if (bytes >= 1048576) {
size=sprintf("%.2f M", bytes/1048576)
} else if (bytes >= 1024) {
size=sprintf("%.2f K", bytes/1024)
} else {
size=sprintf("%d B", bytes)
}
printf "目录名: %-35s \t 子目录数: %5s \t 文件数: %10s \t 总大小: %12s\n", $4, $1, $2, size
}'迁移完成
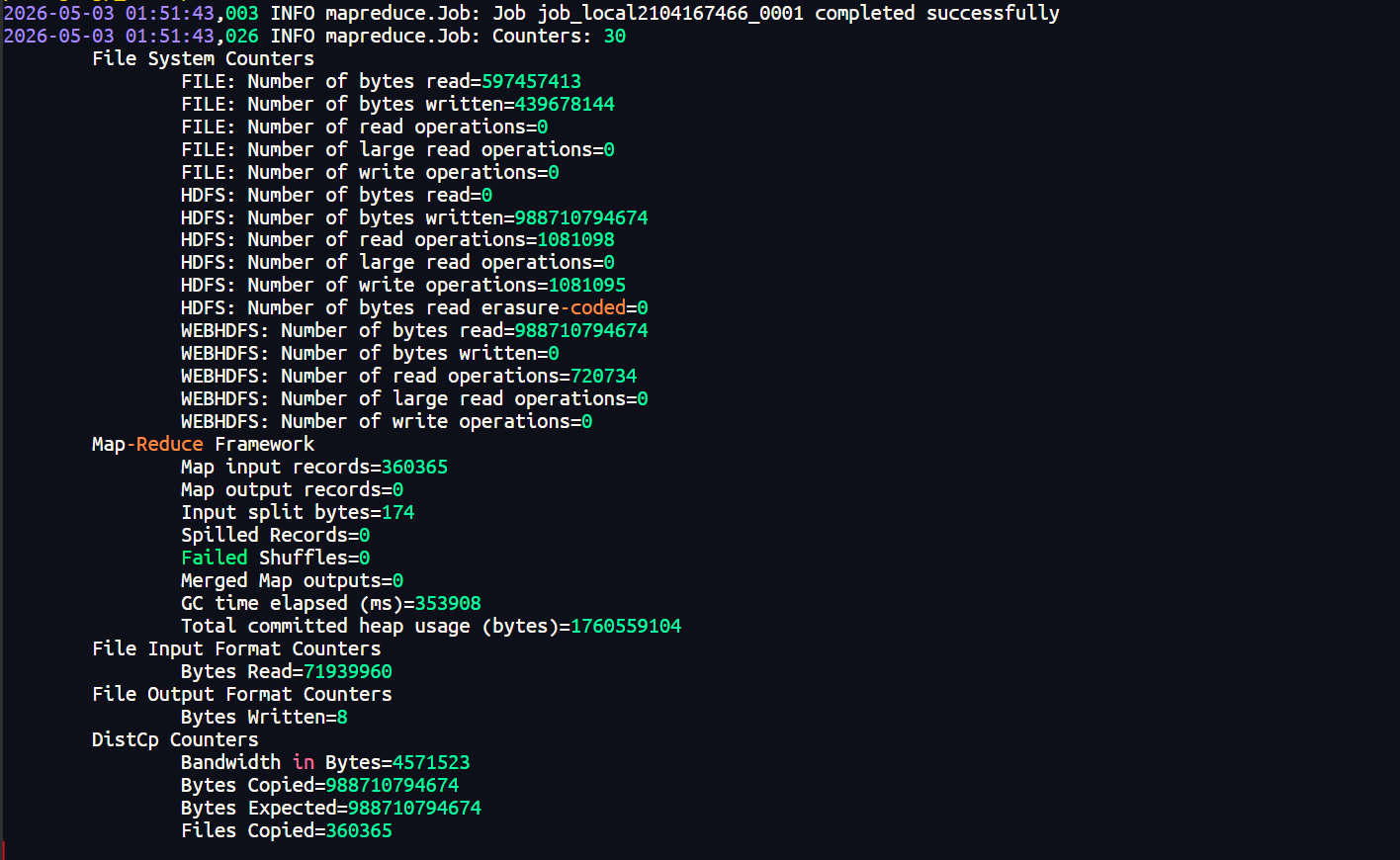
5 迁移完成后数据统计
切换至hadoop用户
bash
su - hadoop统计集群占用总空间
bash
hdfs dfs -du -s -h /统计第一层子目录占用空间情况
bash
hdfs dfs -count '/*' | awk '
{
bytes=$3
if (bytes >= 1099511627776) {
size=sprintf("%.2f T", bytes/1099511627776)
} else if (bytes >= 1073741824) {
size=sprintf("%.2f G", bytes/1073741824)
} else if (bytes >= 1048576) {
size=sprintf("%.2f M", bytes/1048576)
} else if (bytes >= 1024) {
size=sprintf("%.2f K", bytes/1024)
} else {
size=sprintf("%d B", bytes)
}
printf "目录名: %-35s \t 子目录数: %5s \t 文件数: %10s \t 总大小: %12s\n", $4, $1, $2, size
}'