随着直播业务持续扩张,很多问题就会慢慢暴露出来:内容越来越多,直播间越来越杂,但系统真正能用来做决策的信息却没有同步变多。
运营同学当然知道什么样的主播更容易拿到好反馈,什么样的直播间画面更稳定、形象更统一、转化更有把握。问题是,这些判断长期都停留在人工经验里。人能看出来,系统看不出来;人知道该怎么分,推荐和治理链路却接不上。
这次我们做的事情,本质上就是把这部分"人工一眼能看懂"的内容,尽量变成系统也能消费的结构化数据。
先看几组结果:
-
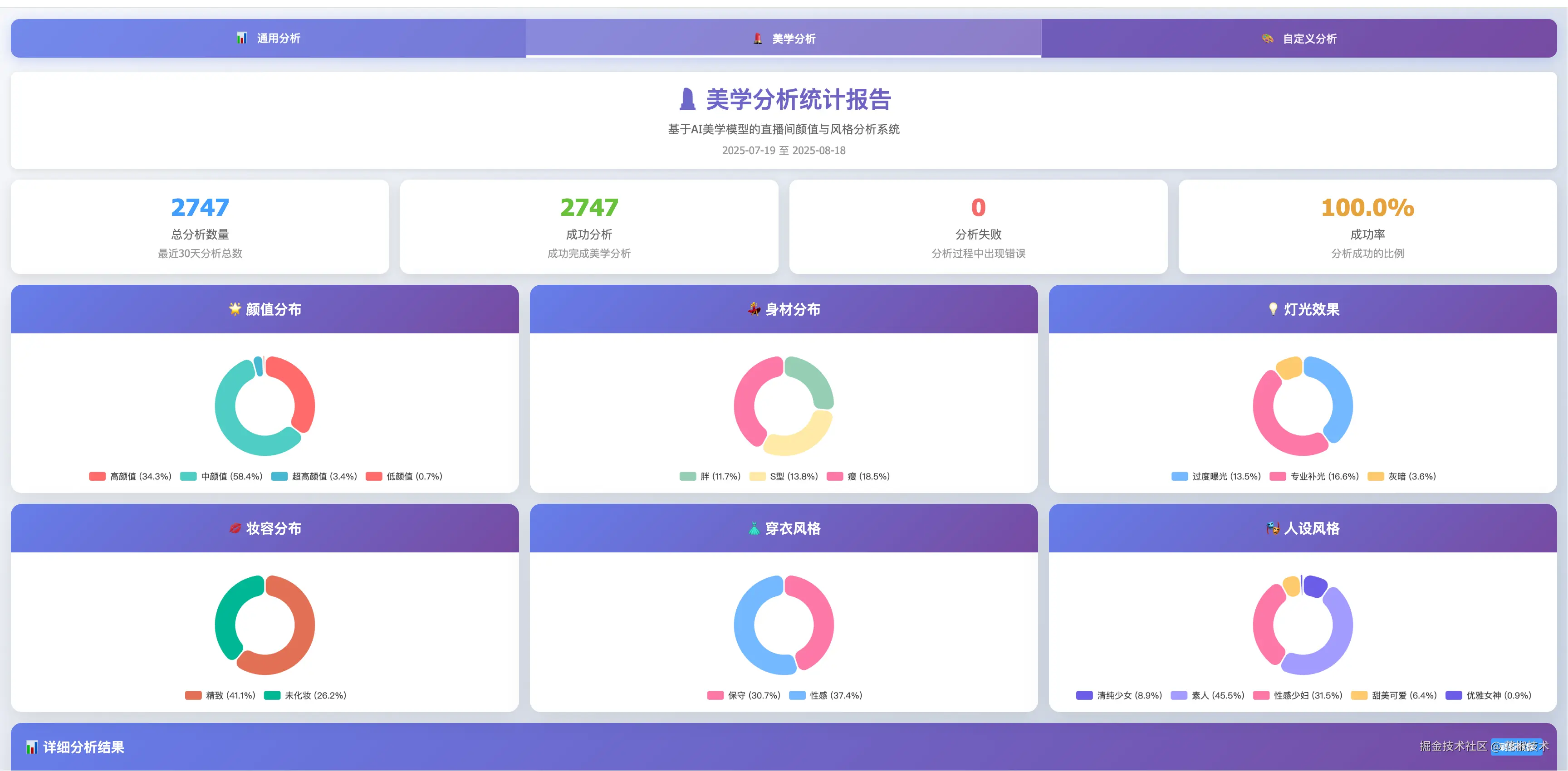
主播高等级画像识别结果,与运营人工高等级达人判断的重合度约 75%
-
对低质量直播做实时识别、推送复核和自动处理后,人工审核运营效率提升 50%+
-
数据分析发现,约 60% 的中低画像主播,占用了平台约 22% 的曝光流量
这几个数字放在一起,已经说明一件事:直播内容理解不是"模型演示能力",而是可以真正进入推荐、治理和运营链路的基础能力。
一、问题并不只是"人工效率低"
最早的直播内容管理,本质上是一套人工体系。
运营同学看直播、打分、评级,再把这些结果反馈到平台策略里。这套方式并不是不能用,它的问题在于,随着内容规模扩大,它会越来越不适合做细颗粒度治理。
原因主要有三层。
第一层是处理速度跟不上。人工打分和达人评级本身就有成本,更新频率也不够高,很难覆盖快速变化的直播内容。
第二层是状态变化接不住。主播不是静态对象,妆容、灯光、出镜状态、画质甚至是否换人,都会在直播过程中变化。人工标签通常是一次性判断,但直播内容是连续变化的。
第三层是平台缺少真正可计算的人物画像。已有标签更多偏业务属性,对主播外观、风格、人设、画面质量这类会直接影响分发效果的信息,系统感知并不充分。
所以,这次要解决的问题,不只是"帮运营省点时间",而是让平台第一次真正拥有一套能进入系统决策的人物与画面理解能力。
二、我们先做的,不是大模型炫技,而是把内容拆成字段
这类事情最容易走偏的一点,是一开始就把目标设成"让模型看懂直播间"。
但如果模型看懂了,结果却只是吐出一段自然语言描述,那对推荐和治理其实帮助有限。系统真正需要的,不是一段漂亮总结,而是一组可以落库、可以打标签、可以被下游消费的结构化结果。
所以我们一开始就没有把重点放在"模型自由发挥"上,而是先反过来定义:业务到底想要哪些字段。
当前重点识别的维度包括:
-
颜值等级
-
身材特征
-
灯光效果
-
妆容状态
-
穿衣风格
-
人设风格
在此基础上,再让模型补一段简短的人物描述文案,用于辅助展示和内容理解。
这个顺序很重要。先定义字段,再设计识别逻辑,最后才是模型输出方式。这样做的结果是,这套能力从一开始就不是"看图说话",而是在为后面的业务接入预留接口。
三、技术方案真正难的地方,在整条链路能不能跑通
从工程角度看,这件事难点并不只在模型。
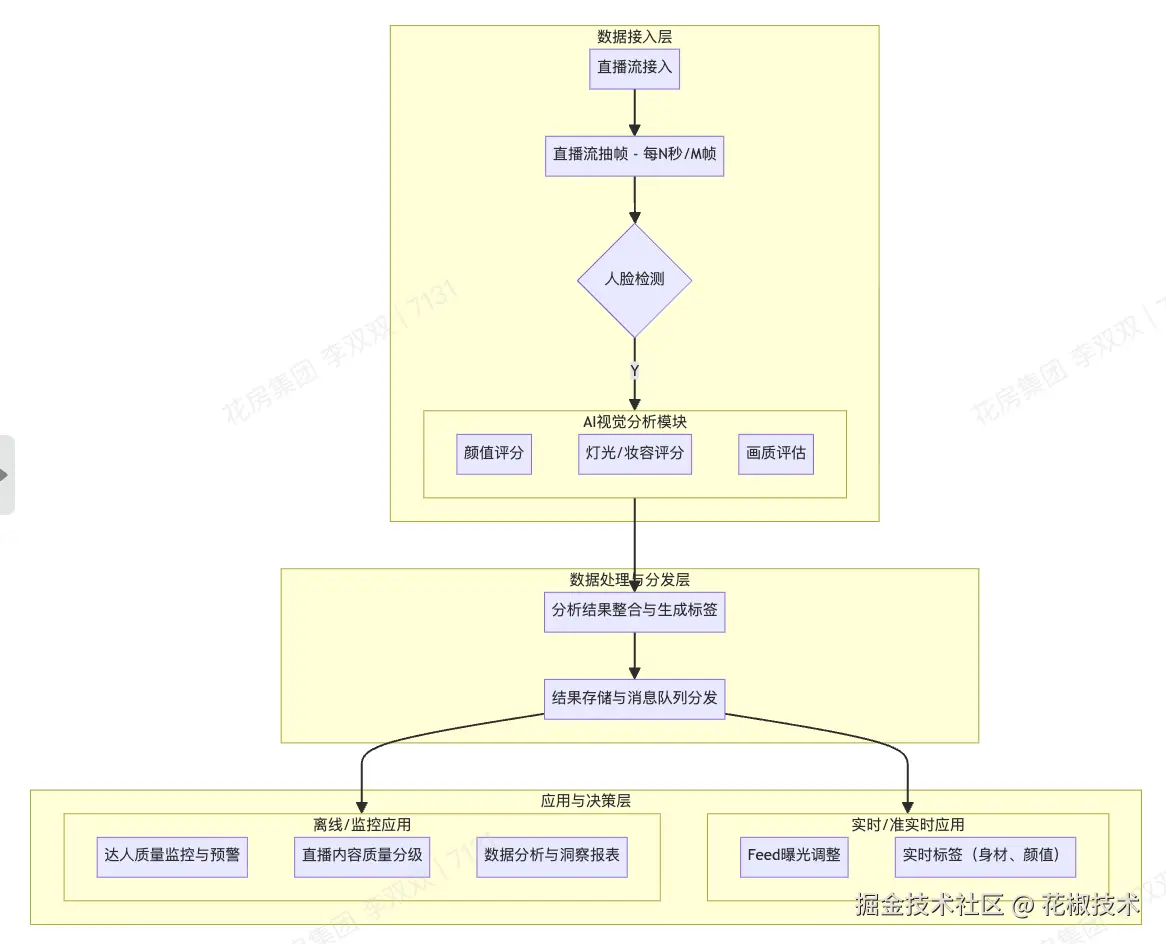
真正要落地,至少要把下面这条链路跑顺:
-
从直播流中抽帧
-
筛掉无效帧
-
保留适合识别的人脸与画面
-
送入模型做多维分析
-
把结果整合成统一标签
-
写入存储,再接到推荐、运营和监控链路
-
整体方案示意
这次选用的基础模型是 豆包 1.5 lite。但更关键的不是模型名称,而是我们在输入和输出两端都做了约束。
在输入侧,我们通过抽帧、人脸检测和图像处理,尽量保证进入模型的是有效内容,而不是噪声很大的随机截图。
在输出侧,我们尽量把结果限定成 JSON 结构,要求模型返回稳定字段,而不是一段不可控的自然语言长描述。因为下游系统真正能用的是"标签",不是一次性的模型回答。
也正因为这样,这套方案的核心价值并不在某一版 prompt,而在于它把直播内容理解变成了一条可持续生产结构化数据的链路。
四、先验证一件事:系统判断和人工经验能不能对上
这类能力如果要往业务里接,第一步不能只看"模型有没有输出",而要先看它和人工经验是不是基本对齐。
在这次验证里,我们重点看了两件事:
-
识别结果和运营经验能否大体一致
-
这些结果是否足够稳定,可以进入实际业务动作
当前结果是:
| 指标 | 数据表现 |
|---|---|
| 高等级画像识别一致性 | 超高/高画像结果与运营人工高等级达人判断重合度约 75% |
| 运营效率 | 通过实时识别低质量直播并推送复核,运营效率提升 50%+ |
| 流量盘面洞察 | 约 60% 的中低画像主播占用了约 22% 的曝光流量 |
| 标签可用性 | 妆容、灯光、人设等标签与运营经验基本一致 |
这里最有价值的,不是某一个字段有多高精度,而是整套结果已经足够支撑业务判断。
换句话说,它不再只是"模型觉得这个主播看起来怎么样",而是平台开始能把这类判断接到流量和运营动作里。
五、业务价值真正出来,是因为它接进了决策链路
如果这套能力只停留在可视化页面上,它的价值会比较有限。
真正让它有业务意义的,是它开始进入两个方向。
第一个方向是推荐分发。 在音乐、舞蹈、颜值等类目中,画像结果可以作为排序和权重调整的辅助输入,让系统在做曝光决策时,不再只依赖已有的行为数据和人工标签。
第二个方向是运营治理。 比如优质达人质量监控、热门冷启动策略、精选频道推荐等场景,都开始有机会基于更实时的内容理解结果做辅助判断,而不是等人工巡检之后再慢慢修正。
也就是说,内容理解这件事一旦落地,它不会只服务一个业务点,而会逐步变成推荐、治理、运营共用的一套底层输入。
六、这次先把一件具体的事做成了
如果只看名字,这个项目像是在做"主播画像识别"。
但从落地角度看,我们这次真正做成的,是把原来依赖人工经验的一部分判断,先稳定地接进系统里。不是一下子把直播间所有内容都理解完,而是先把几个业务最在意、最容易落地的维度跑通。
比如现在已经能稳定产出的这些结果:
-
主播画像相关标签
-
与运营判断基本对得上的高低质量识别结果
-
可直接进入推荐和运营动作的结构化字段
这样一来,后面的扩展才有基础。
原文里提到的几个方向,其实都可以沿着这条链路继续往下做:
-
颜值衰减和画面状态变化提醒
-
才艺识别,比如舞蹈、乐器
-
话题识别,比如美妆、旅游、游戏、健身、音乐
-
场景检测,比如户外、室内、景区、餐厅、健身房
-
弹幕互动分析
-
非真人识别,比如虚拟人场景
这几项不一定要一起做,也没必要一次铺太大。更现实的做法,还是先看哪些字段最容易进业务、哪些结果最容易被验证,再一项一项往外扩。
结尾总结
这次内容理解落地,先解决的不是"模型能不能把直播间描述得很像回事",而是"平台能不能拿到一批真的能用的数据"。
从结果看,这件事已经往前走了一步:运营能更快处理低质量直播,推荐侧也开始有机会拿到更细的人物画像输入。
后面还有很多东西可以继续做,但至少这次证明了一点:直播间内容理解这件事,不只是展示能力,确实能往业务里接。
以上是本期分享。如果你想和我们进一步交流技术问题、获取独家干货,欢迎扫码加入花椒技术交流群。
