文章目录
- [用 PyTorch 跑通 SDGT:短期电力负荷预测复现、工程实现与图表分析](#用 PyTorch 跑通 SDGT:短期电力负荷预测复现、工程实现与图表分析)
-
- 这篇文章适合谁看
- [1. 问题背景:为什么要做短期电力负荷预测](#1. 问题背景:为什么要做短期电力负荷预测)
- [2. 项目整体介绍](#2. 项目整体介绍)
- [3. 数据集与预处理](#3. 数据集与预处理)
-
- [3.1 当前使用的数据](#3.1 当前使用的数据)
- [3.2 多变量时间序列表示](#3.2 多变量时间序列表示)
- [3.3 缺失值、异常值与标准化](#3.3 缺失值、异常值与标准化)
- [3.4 滑动窗口构造](#3.4 滑动窗口构造)
- [3.5 数据分布与周期性检查](#3.5 数据分布与周期性检查)
- [4. SDGT 模型原理详解](#4. SDGT 模型原理详解)
-
- [4.1 动态时空相关图 STCG](#4.1 动态时空相关图 STCG)
- [4.2 MixHop 图卷积聚合](#4.2 MixHop 图卷积聚合)
- [4.3 周期检测与多尺度 patch](#4.3 周期检测与多尺度 patch)
- [4.4 Transformer 注意力](#4.4 Transformer 注意力)
- [4.5 多尺度融合与输出层](#4.5 多尺度融合与输出层)
- [5. 损失函数与评价指标](#5. 损失函数与评价指标)
- [6. 工程实现细节](#6. 工程实现细节)
-
- [6.1 配置管理](#6.1 配置管理)
- [6.2 路径鲁棒性修复](#6.2 路径鲁棒性修复)
- [6.3 CSV 列检查与错误信息](#6.3 CSV 列检查与错误信息)
- [6.4 模拟数据生成](#6.4 模拟数据生成)
- [6.5 训练循环](#6.5 训练循环)
- [6.6 可视化输出](#6.6 可视化输出)
- [7. 实验结果与图表分析](#7. 实验结果与图表分析)
-
- [7.1 训练过程](#7.1 训练过程)
- [7.2 测试集整体指标](#7.2 测试集整体指标)
- [7.3 预测曲线分析](#7.3 预测曲线分析)
- [7.4 从图表反推模型效果](#7.4 从图表反推模型效果)
- [7.5 数据图与结果图的联动解释](#7.5 数据图与结果图的联动解释)
- [8. 项目踩坑记录](#8. 项目踩坑记录)
-
- [8.1 FileNotFoundError:相对路径不等于项目路径](#8.1 FileNotFoundError:相对路径不等于项目路径)
- [8.2 字段名不一致](#8.2 字段名不一致)
- [8.3 时间列解析失败](#8.3 时间列解析失败)
- [8.4 周期检测依赖问题](#8.4 周期检测依赖问题)
- [8.5 训练指标和测试指标口径不同](#8.5 训练指标和测试指标口径不同)
- [9. 当前实现的局限](#9. 当前实现的局限)
- [10. 后续改进方向](#10. 后续改进方向)
- [11. 运行命令与输出文件](#11. 运行命令与输出文件)
- [12. 总结](#12. 总结)
-
- [3 条实战经验](#3 条实战经验)
用 PyTorch 跑通 SDGT:短期电力负荷预测复现、工程实现与图表分析
本文基于我当前完成的
sdgt_reproduction项目整理,重点记录一次从数据生成、预处理、动态时空图构建、多尺度 Transformer 训练,到预测结果可视化分析的完整 SDGT 复现过程。项目使用 PyTorch 实现,当前主线数据集为 Australian 风格半小时级电力负荷数据,最终在测试集上得到MAE=67.92、RMSE=84.45、MAPE=2.50%、R2=0.865、Accuracy=97.50%。
这篇文章适合谁看
这篇文章比较适合三类读者:
- 想入门短期电力负荷预测,但不想只看理论公式的人;
- 正在做时序预测、图神经网络、Transformer 复现项目的同学;
- 需要把一个深度学习复现项目整理成竞赛报告、课程设计、技术博客或科研笔记的人。
如果你已经熟悉 LSTM、Transformer 和基本回归指标,可以重点看 SDGT 模型实现、动态图构建、周期检测和实验图表分析;如果你刚开始做时序预测,可以从数据预处理和滑动窗口构造部分开始读。
1. 问题背景:为什么要做短期电力负荷预测
短期电力负荷预测的目标,是根据历史负荷、天气、电价、时间属性等信息,预测未来一段时间内的电力需求。它看起来像一个普通回归问题,但实际难点并不少:
- 负荷有明显的日周期和周周期;
- 温度、湿度、电价等外生变量会影响负荷;
- 峰谷变化比平稳区间更难预测;
- 多步预测中,预测步长越远,误差越容易累积;
- 不同变量之间的关系不是固定的,可能随时间动态变化。
传统统计模型如 ARIMA、指数平滑,对平稳序列和短期趋势比较友好,但对复杂非线性关系和多变量耦合能力有限。LSTM、GRU 等循环网络能建模时间依赖,但对长窗口、多尺度周期和变量间结构关系的刻画仍然不够直接。普通 Transformer 擅长长序列建模,却容易把多变量时间序列当成一串 token,忽略变量之间的动态相关图。
SDGT(Spatial-Temporal Dynamic Graph Transformer)的核心想法正好切中这个问题:一边用动态时空相关图 STCG 捕捉变量之间的关系,一边用多尺度 Transformer 捕捉不同周期尺度下的时间模式。我的项目不是论文官方源码,而是基于论文公开思路做的一版工程复现,因此文中涉及 STCG 细节、周期检测降级策略、轻量 PatchTST 基线等地方,都会明确标注为"工程实现层面的复现表达"。
2. 项目整体介绍
当前项目目录如下:
text
sdgt_reproduction/
├── configs/
│ ├── australian.yaml
│ ├── morocco.yaml
│ └── model.yaml
├── data/
│ ├── raw/
│ └── processed/
├── datasets/
│ ├── preprocessing.py
│ └── sliding_window.py
├── models/
│ ├── stcg.py
│ ├── graph_conv.py
│ ├── multi_scale_transformer.py
│ ├── period_detector.py
│ ├── layers.py
│ └── sdgt.py
├── trainers/
│ ├── train.py
│ ├── evaluate.py
│ └── inference.py
├── baselines/
├── utils/
├── scripts/
└── outputs/
├── checkpoints/
├── figures/
├── logs/
└── tables/主入口是 main.py,可以通过命令行选择训练、测试、基线对比和消融实验:
bash
python main.py --dataset australian --mode train --config configs/australian.yaml --run_mode quick
python main.py --dataset australian --mode test --checkpoint outputs/checkpoints/australian_sdgt_best.pt
python main.py --dataset australian --mode compare
python main.py --dataset australian --mode ablation --run_mode quick本项目最终完成的功能包括:
- Australian 风格模拟数据生成;
- CSV 读取、列检查、时间列解析、缺失值处理、异常值裁剪;
- 仅用训练集拟合 StandardScaler,避免数据泄漏;
- 按时间顺序构造 train / val / test;
- 336 步 lookback 到 96 步 horizon 的多步负荷预测;
- STCG 动态邻接矩阵构建;
- MixHop 图卷积;
- VMD+FFT 周期检测,并支持 FFT / ACF 降级;
- 多尺度 patch Transformer;
- gated fusion 融合图特征和时间特征;
- MAE、RMSE、MAPE、R2、Accuracy 指标计算;
- 训练曲线、预测曲线、残差分布、horizon 误差、邻接矩阵等完整图表输出。
整体执行流程可以概括为:
text
原始 CSV / 模拟 CSV
-> 数据清洗与标准化
-> 滑动窗口构造
-> 周期检测得到 patch sizes
-> STCG 动态构图
-> MixHop 图聚合
-> 多尺度 Transformer 时间建模
-> 门控融合
-> 96 步负荷预测
-> 指标计算与可视化分析3. 数据集与预处理
3.1 当前使用的数据
当前主线运行的是 Australian 风格半小时级模拟数据,文件位于:
text
data/raw/australian.csv数据共有 4000 行,时间范围为 2022-01-01 00:00:00 到 2022-03-25 07:30:00,采样间隔为 30min。字段如下:
| 字段 | 含义 | 是否作为特征 |
|---|---|---|
timestamp |
时间戳 | 否,作为排序和切分依据 |
load |
电力负荷,预测目标 | 是,第 0 个通道 |
price |
电价 | 是 |
temperature |
温度 | 是 |
humidity |
湿度 | 是 |
is_weekend |
是否周末 | 是 |
模拟数据不是纯随机噪声,而是显式加入了日周期、周周期、趋势项、天气敏感项、周末效应和随机扰动。项目里也保留了真实 Australian 数据接入的配置口径,只是当前复现使用本地生成数据保证快速跑通。
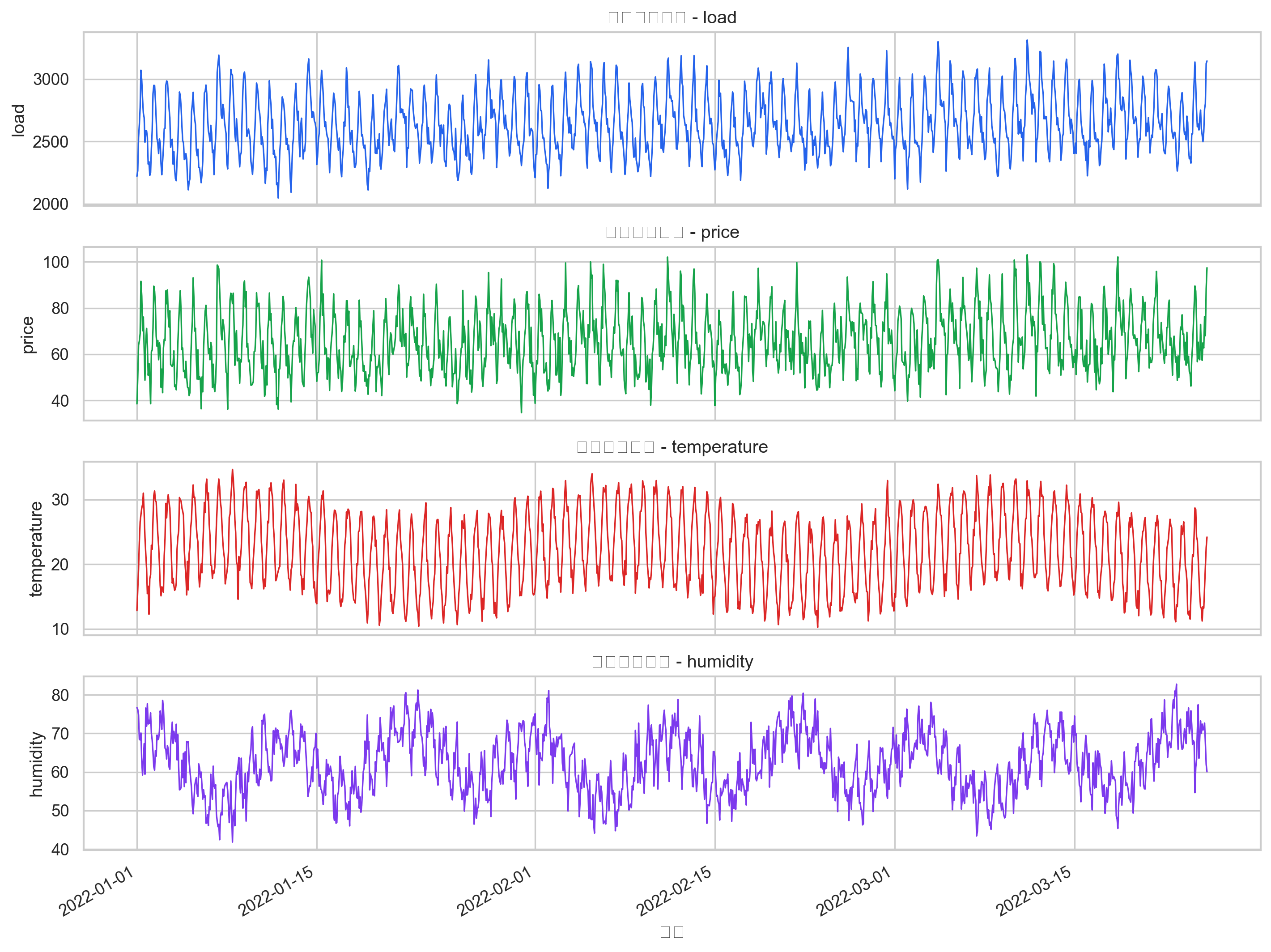
这张图展示了模拟数据中 load、price、temperature、humidity 的时间变化。可以看到负荷与电价具有较同步的起伏,温湿度则形成另一组天气相关波动,这为后续多变量建模提供了合理的外生变量基础。
3.2 多变量时间序列表示
将清洗后的多变量序列记为:
X = x 1 , x 2 , ... , x T ⊤ ∈ R T × C \mathbf{X} = \\mathbf{x}_1,\\mathbf{x}_2,\\ldots,\\mathbf{x}_T^\top \in \mathbb{R}^{T \times C} X=x1,x2,...,xT⊤∈RT×C
其中, T T T 是时间步数量,当前为 4000 4000 4000; C C C 是变量数,当前为 5 5 5;第 t t t 个时间步的特征向量为:
x t = x t ( l o a d ) , x t ( p r i c e ) , x t ( t e m p e r a t u r e ) , x t ( h u m i d i t y ) , x t ( i s _ w e e k e n d ) \mathbf{x}_t = x_t\^{(load)}, x_t\^{(price)}, x_t\^{(temperature)}, x_t\^{(humidity)}, x_t\^{(is\\_weekend)} xt=xt(load),xt(price),xt(temperature),xt(humidity),xt(is_weekend)
预测目标是未来 H H H 个时间步的负荷:
y t = x t ( l o a d ) , x t + 1 ( l o a d ) , ... , x t + H − 1 ( l o a d ) ∈ R H \mathbf{y}_t = x_t\^{(load)}, x_{t+1}\^{(load)}, \\ldots, x_{t+H-1}\^{(load)} \in \mathbb{R}^{H} yt=xt(load),xt+1(load),...,xt+H−1(load)∈RH
当前配置中:
L = 336 , H = 96 L=336,\quad H=96 L=336,H=96
由于数据是半小时级采样, L = 336 L=336 L=336 表示使用过去 7 天历史窗口, H = 96 H=96 H=96 表示预测未来 48 小时。
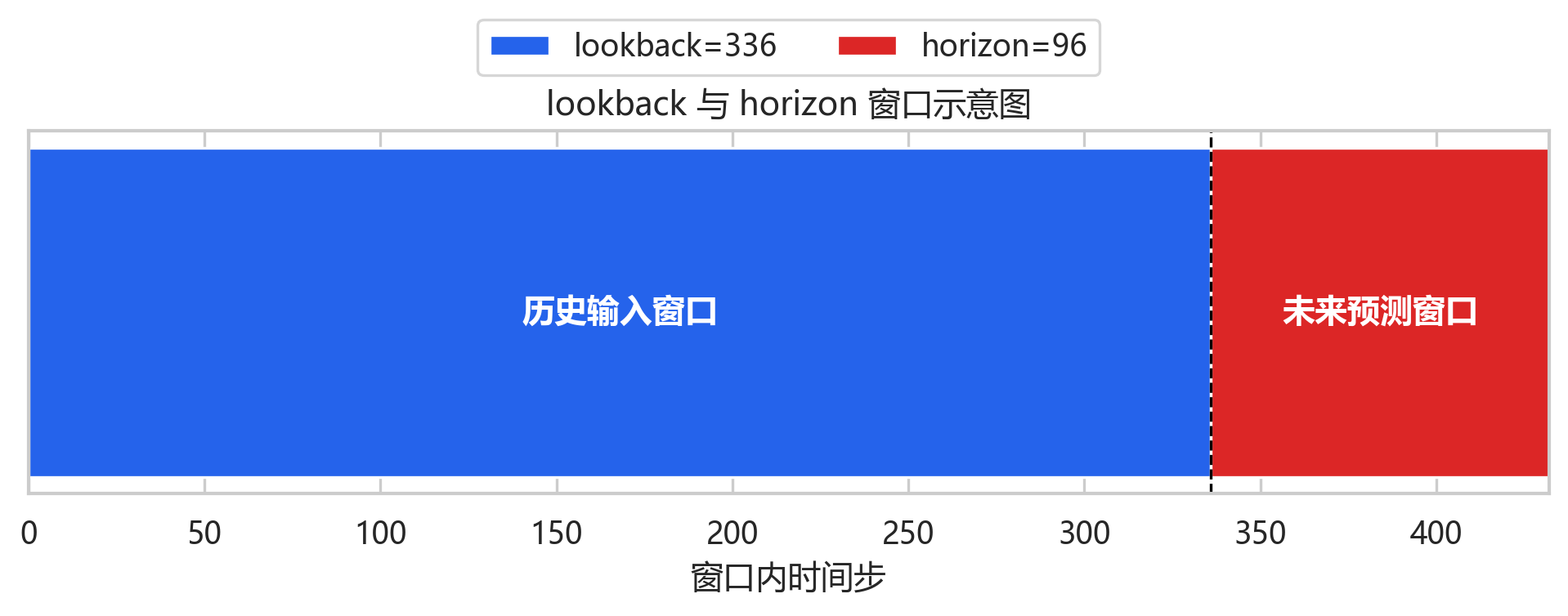
这张图很适合放在复现项目里,因为它把抽象的输入输出长度变成了直观的窗口关系。短期负荷预测并不是"拿一个点预测一个点",而是用一段历史曲线预测未来一整段曲线。
3.3 缺失值、异常值与标准化
预处理阶段会先检查必要列是否存在,然后解析时间列、按时间排序、删除重复时间戳。数值列缺失值使用:
text
ffill -> bfill -> median也就是先前向填充,再后向填充,最后用中位数兜底。当前数据缺失值为 0:

异常值处理采用分位数裁剪,当前配置为:
yaml
outlier_clip:
enabled: true
lower_quantile: 0.01
upper_quantile: 0.99工程上可以写成:
x ~ t ( j ) = min ( max ( x t ( j ) , Q 0.01 ( j ) ) , Q 0.99 ( j ) ) \tilde{x}^{(j)}t = \min\left( \max\left(x^{(j)}t, Q{0.01}^{(j)}\right), Q{0.99}^{(j)} \right) x~t(j)=min(max(xt(j),Q0.01(j)),Q0.99(j))
其中, Q 0.01 ( j ) Q_{0.01}^{(j)} Q0.01(j) 和 Q 0.99 ( j ) Q_{0.99}^{(j)} Q0.99(j) 分别表示第 j j j 个变量在 1% 和 99% 分位处的值。这个处理不会"修复"所有异常,但能避免极端值把 StandardScaler 和 MSE 损失带偏。
当前启用的是 StandardScaler,并且只在训练集上拟合:
z t ( j ) = x t ( j ) − μ t r a i n ( j ) σ t r a i n ( j ) + ϵ z_t^{(j)} = \frac{x_t^{(j)}-\mu_{train}^{(j)}}{\sigma_{train}^{(j)}+\epsilon} zt(j)=σtrain(j)+ϵxt(j)−μtrain(j)
这里 μ t r a i n ( j ) \mu_{train}^{(j)} μtrain(j) 和 σ t r a i n ( j ) \sigma_{train}^{(j)} σtrain(j) 只由训练区间统计得到,验证集和测试集只做 transform,不参与 scaler 拟合。这一点很关键,否则时间序列预测会出现隐性数据泄漏。
3.4 滑动窗口构造
滑动窗口样本可以表示为:
X i = x i − L , x i − L + 1 , ... , x i − 1 ∈ R L × C \mathbf{X}_i = \\mathbf{x}_{i-L}, \\mathbf{x}_{i-L+1}, \\ldots, \\mathbf{x}_{i-1} \in \mathbb{R}^{L \times C} Xi=xi−L,xi−L+1,...,xi−1∈RL×C
y i = x i ( l o a d ) , x i + 1 ( l o a d ) , ... , x i + H − 1 ( l o a d ) ∈ R H \mathbf{y}_i = x_i\^{(load)}, x_{i+1}\^{(load)}, \\ldots, x_{i+H-1}\^{(load)} \in \mathbb{R}^{H} yi=xi(load),xi+1(load),...,xi+H−1(load)∈RH
其中 i i i 是预测窗口起点。对应到代码中,就是 SlidingWindowDataset.__getitem__:
python
def __getitem__(self, idx):
i = self.indices[idx]
x = self.values[i - self.lookback : i]
y = self.values[i : i + self.horizon, self.target_index]
return torch.from_numpy(x), torch.from_numpy(y)当前时间划分为:
| 数据段 | 原始行数 | 时间顺序范围 |
|---|---|---|
| Train | 2800 | 0 到 2799 |
| Val | 399 | 2800 到 3198 |
| Test | 801 | 3199 到 3999 |
构造滑窗后,样本数量为:
| 数据集 | 滑窗样本数 |
|---|---|
| Train | 2369 |
| Val | 640 |
| Test | 1042 |
验证集和测试集的 start 会向前回看 lookback,保证输入窗口有足够历史;但标签起点仍落在各自区间内,不会把验证或测试标签泄漏到训练阶段。
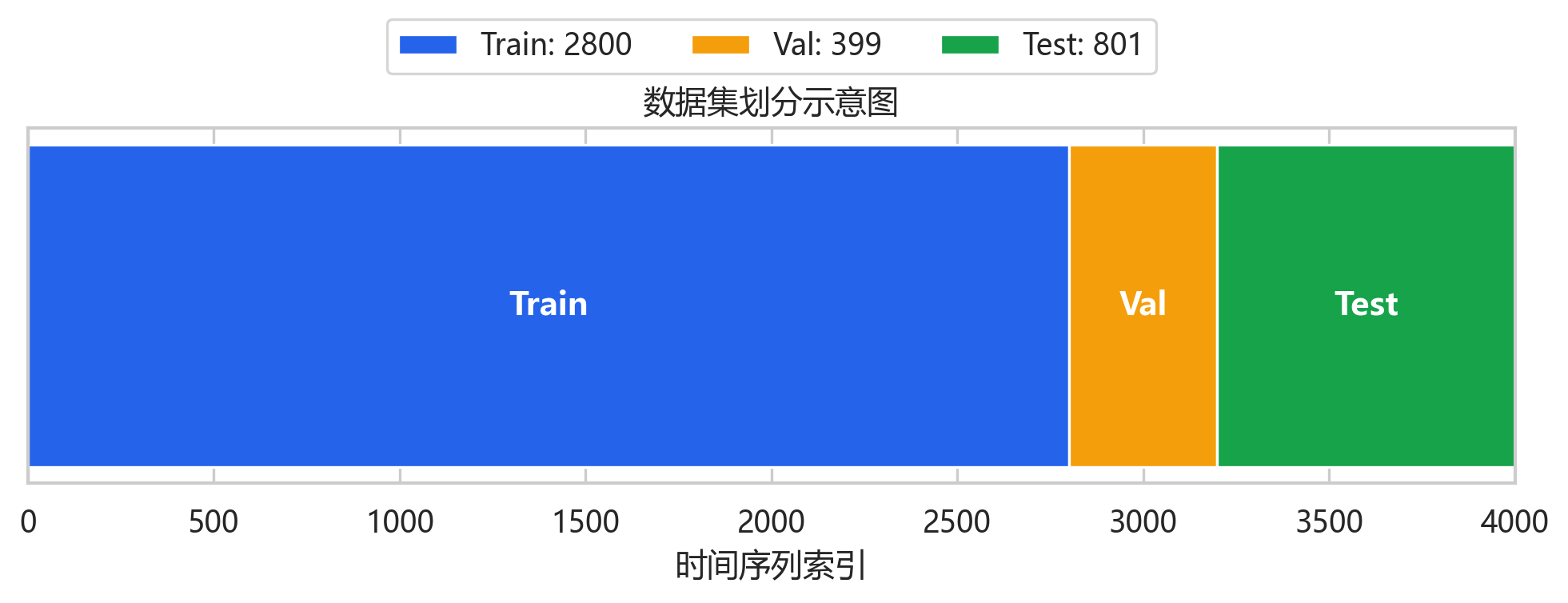
这张图说明项目采用的是时间顺序切分,而不是随机划分。对时序预测而言,随机划分会让模型在训练阶段见到未来分布,指标看起来漂亮但没有实际意义。
3.5 数据分布与周期性检查
预处理阶段自动输出了一组数据诊断图。先看原始负荷序列:
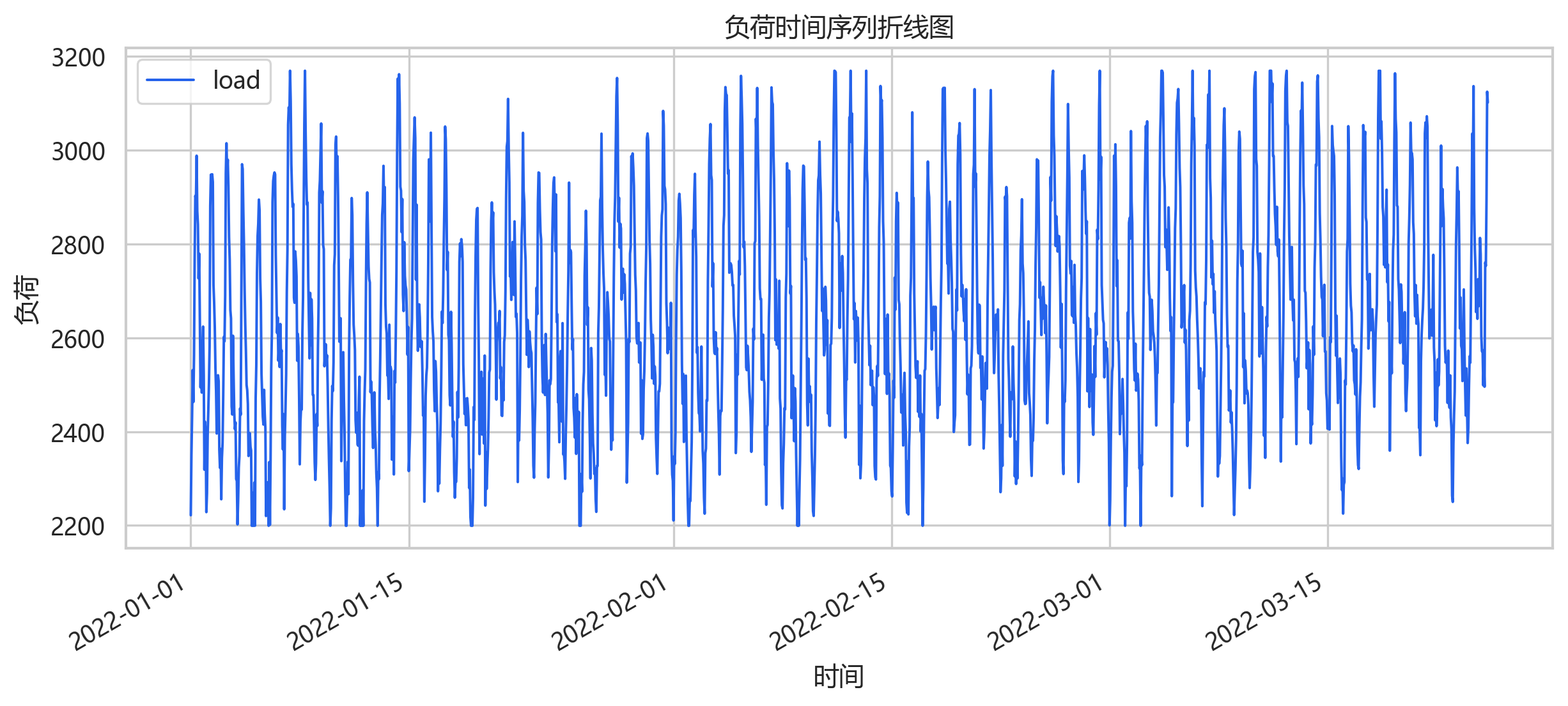
负荷序列呈现明显的周期起伏,同时带有缓慢趋势和局部波动。对于短期负荷预测,这种图至少能回答两个问题:序列有没有断点,周期结构是否足够明显。当前数据整体连续,没有明显缺失断层。
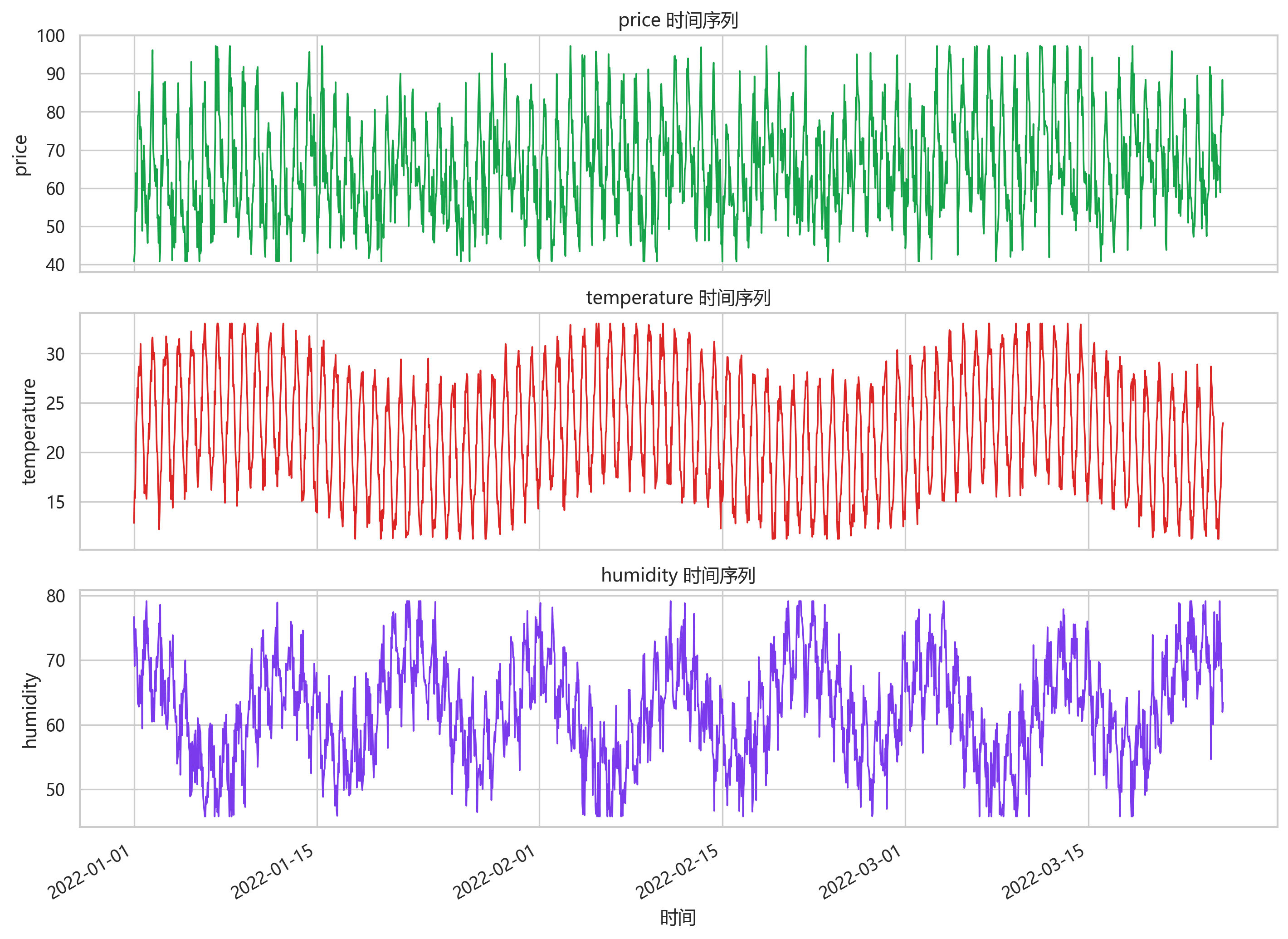
外生变量的时间变化与负荷不是完全同步,但存在可解释关系。例如温度变化会影响制冷或采暖需求,湿度也可能改变体感负荷,电价则与需求强相关。
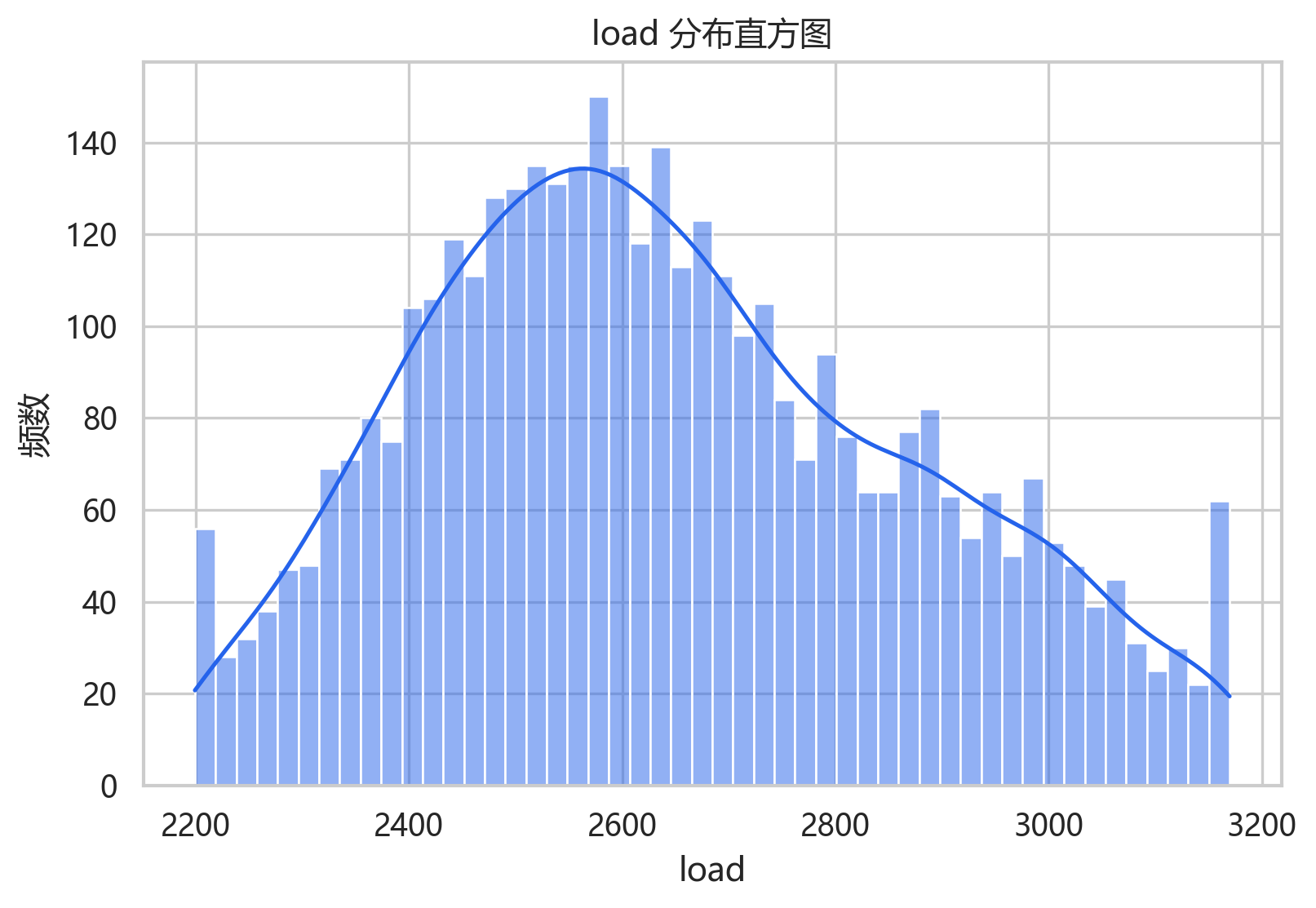
直方图显示负荷主要集中在 2400 到 2900 附近,分布不是严格正态,但没有极端长尾。这个分布形态也解释了为什么 MAPE 在反标准化后比较稳定。
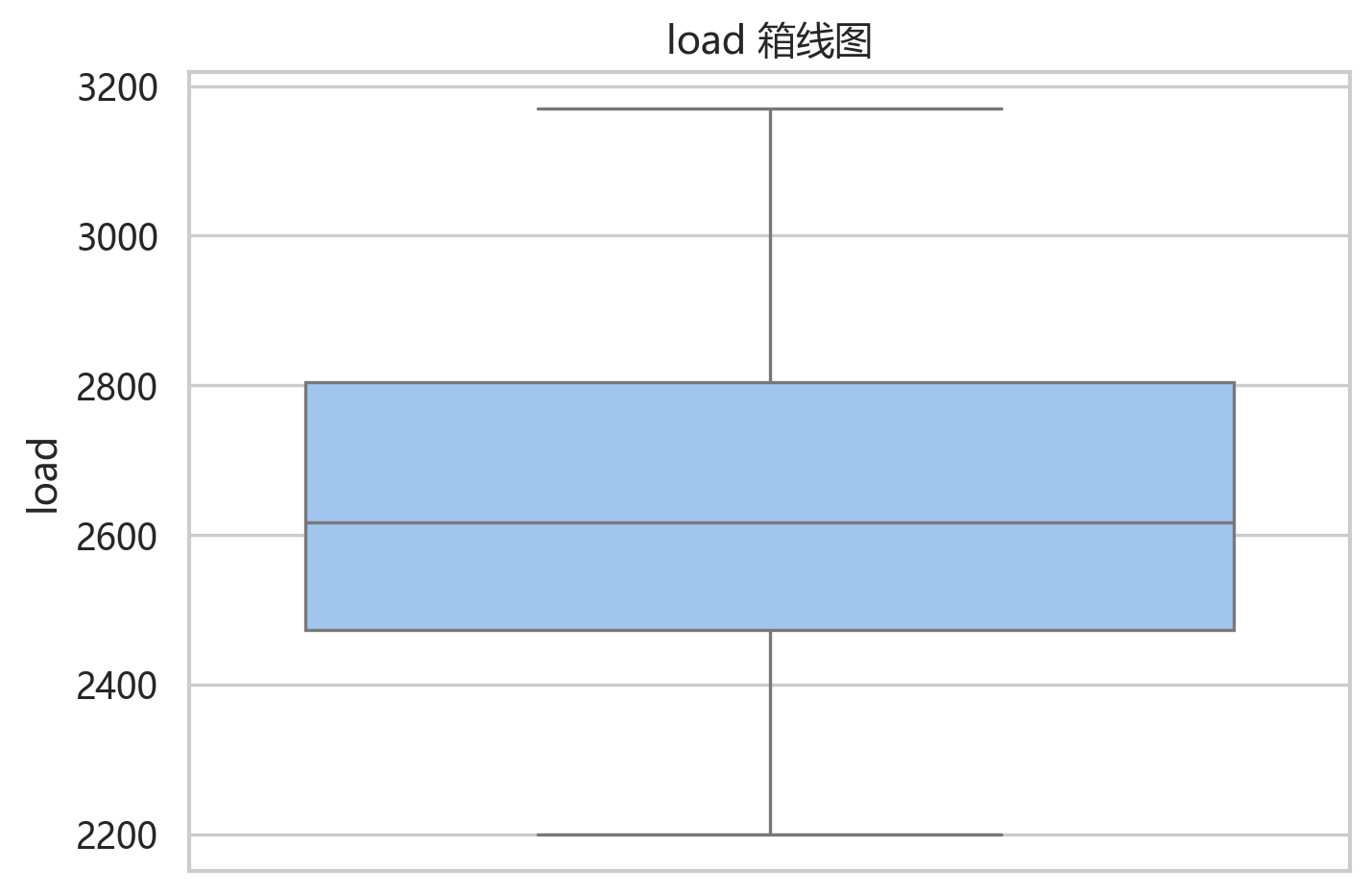
箱线图中的离群点并不夸张,说明分位数裁剪更多是工程保险,而不是对数据做大幅改造。
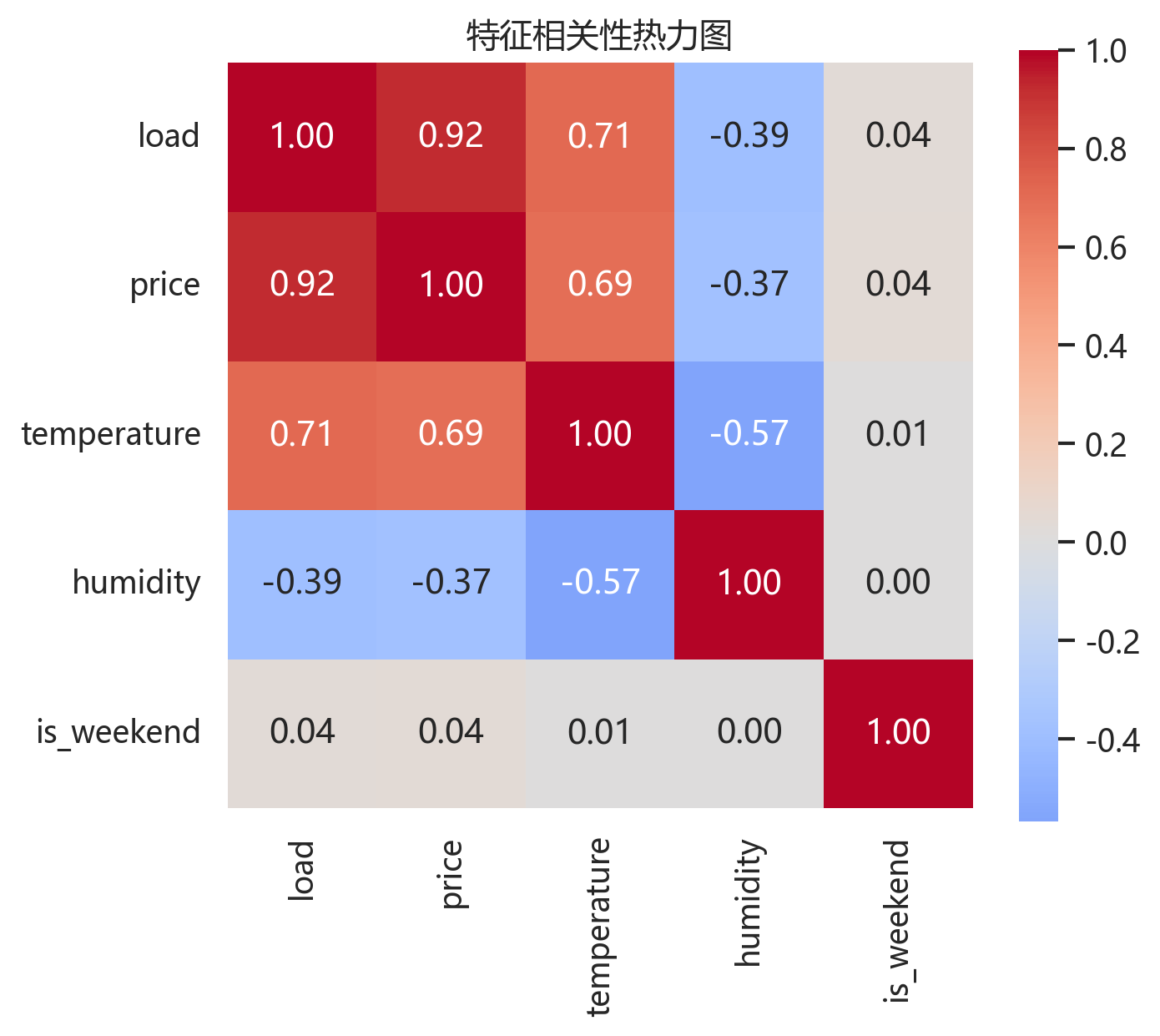
从相关性统计看,load 与 price 的相关系数约为 0.921,与 temperature 约为 0.704,与 humidity 约为 -0.392。这说明外生变量确实携带了负荷预测信息,而不是随便拼进模型的噪声列。
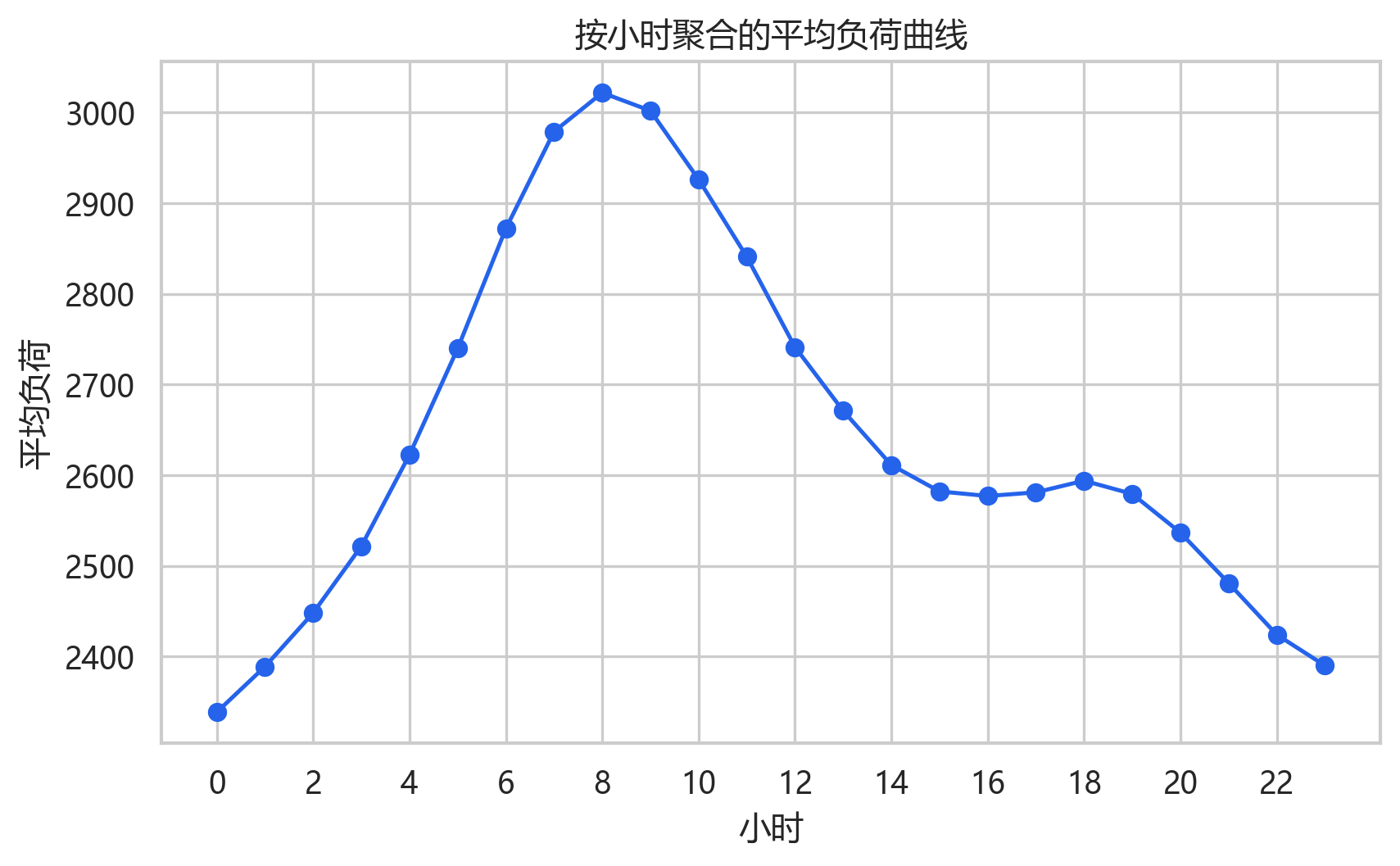
小时均值图揭示了日内负荷形态。半小时数据中一天有 48 个点,而图中按小时聚合后仍能看到明显的日周期,这也支持后面周期检测得到 48 附近的 patch size。
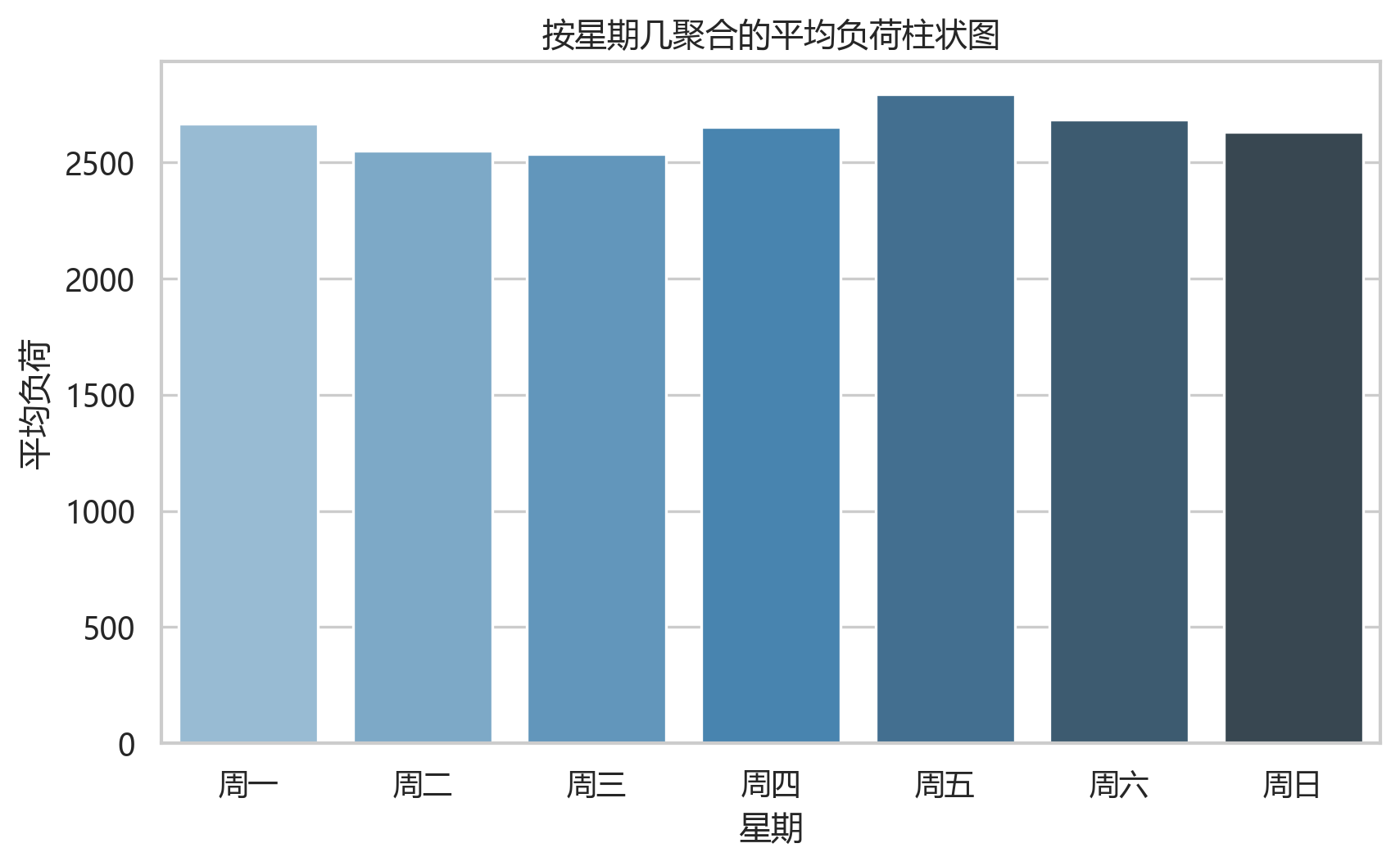
星期维度的平均负荷用于观察工作日和周末差异。虽然当前模拟数据中的 is_weekend 与负荷整体相关性不高,但生成逻辑里保留了周末效应,模型仍可以把它作为辅助变量。
4. SDGT 模型原理详解
当前 SDGT 主体由五个部分组成:
- STCG 动态时空相关图;
- MixHop 图卷积聚合;
- 周期检测与多尺度 patch 构造;
- 多尺度 Transformer 编码;
- gated fusion 与多步预测头。
4.1 动态时空相关图 STCG
在多变量负荷预测中,每个变量可以看成一个节点:
V = { v 1 , v 2 , ... , v C } \mathcal{V}=\{v_1,v_2,\ldots,v_C\} V={v1,v2,...,vC}
当前 C = 5 C=5 C=5,节点分别对应 load、price、temperature、humidity、is_weekend。STCG 的目标是为每个输入窗口动态构建邻接矩阵:
A t ∈ R C × C \mathbf{A}_t \in \mathbb{R}^{C \times C} At∈RC×C
本项目采用的工程复现公式是:
A t = α S t s h a p e + β S s e m a n t i c \mathbf{A}_t=\alpha\mathbf{S}_t^{shape}+\beta\mathbf{S}^{semantic} At=αStshape+βSsemantic
其中, S t s h a p e \mathbf{S}_t^{shape} Stshape 表示窗口内变量形状相似性, S s e m a n t i c \mathbf{S}^{semantic} Ssemantic 表示可学习语义相关性,当前配置为:
α = 0.6 , β = 0.4 \alpha=0.6,\quad \beta=0.4 α=0.6,β=0.4
形状相似性来自历史窗口内不同变量序列的余弦相似度。对变量 i i i 和变量 j j j,先取它们在窗口内的序列:
x t − L : t − 1 ( i ) , x t − L : t − 1 ( j ) \mathbf{x}{t-L:t-1}^{(i)},\quad \mathbf{x}{t-L:t-1}^{(j)} xt−L:t−1(i),xt−L:t−1(j)
去均值并归一化后计算:
s i j s h a p e = 1 2 ( ( x ( i ) − x ˉ ( i ) ) ⊤ ( x ( j ) − x ˉ ( j ) ) ∥ x ( i ) − x ˉ ( i ) ∥ 2 ∥ x ( j ) − x ˉ ( j ) ∥ 2 + ϵ + 1 ) s_{ij}^{shape}=\frac{1}{2}\left(\frac{(\mathbf{x}^{(i)}-\bar{x}^{(i)})^\top(\mathbf{x}^{(j)}-\bar{x}^{(j)})}{\|\mathbf{x}^{(i)}-\bar{x}^{(i)}\|_2\|\mathbf{x}^{(j)}-\bar{x}^{(j)}\|_2+\epsilon}+1\right) sijshape=21(∥x(i)−xˉ(i)∥2∥x(j)−xˉ(j)∥2+ϵ(x(i)−xˉ(i))⊤(x(j)−xˉ(j))+1)
这里加 1 再除以 2,是为了把余弦相似度从 − 1 , 1 -1,1 −1,1 映射到 0 , 1 0,1 0,1。
语义相关性由可学习节点嵌入得到:
e i s r c , e j d s t ∈ R d s \mathbf{e}_i^{src}, \mathbf{e}_j^{dst} \in \mathbb{R}^{d_s} eisrc,ejdst∈Rds
s i j s e m a n t i c = σ ( ( e i s r c ) ⊤ e j d s t d s ) s_{ij}^{semantic}=\sigma\left(\frac{(\mathbf{e}_i^{src})^\top\mathbf{e}_j^{dst}}{\sqrt{d_s}}\right) sijsemantic=σ(ds (eisrc)⊤ejdst)
这里使用源节点嵌入和目标节点嵌入,因此可以表达有向关系。对应代码来自 models/stcg.py:
python
def _shape_similarity(self, x):
xn = x.transpose(1, 2)
xn = xn - xn.mean(dim=-1, keepdim=True)
xn = F.normalize(xn, p=2, dim=-1, eps=self.eps)
sim = torch.matmul(xn, xn.transpose(-1, -2))
return (sim + 1.0) / 2.0
def _semantic_similarity(self, batch_size, device):
idx = torch.arange(self.num_nodes, device=device)
src = self.node_embedding_src(idx)
dst = self.node_embedding_dst(idx)
scores = torch.matmul(src, dst.t()) / (src.size(-1) ** 0.5)
sem = torch.sigmoid(scores)
return sem.unsqueeze(0).expand(batch_size, -1, -1)构图后还要做稀疏化。当前 sparsity_factor=0.3,节点数为 5 时,每个节点保留大约 2 条强连接,并强制保留自环:
A ~ i j = { A i j , j ∈ T o p K ( A i , : ) or i = j 0 , o t h e r w i s e \tilde{A}{ij} = \begin{cases} A{ij}, & j \in TopK(A_{i,:}) \ \text{or}\ i=j \\ 0, & otherwise \end{cases} A~ij={Aij,0,j∈TopK(Ai,:) or i=jotherwise
最后进行行归一化:
A ^ i j = A ~ i j ∑ k = 1 C A ~ i k + ϵ \hat{A}{ij} = \frac{\tilde{A}{ij}}{\sum_{k=1}^{C}\tilde{A}_{ik}+\epsilon} A^ij=∑k=1CA~ik+ϵA~ij
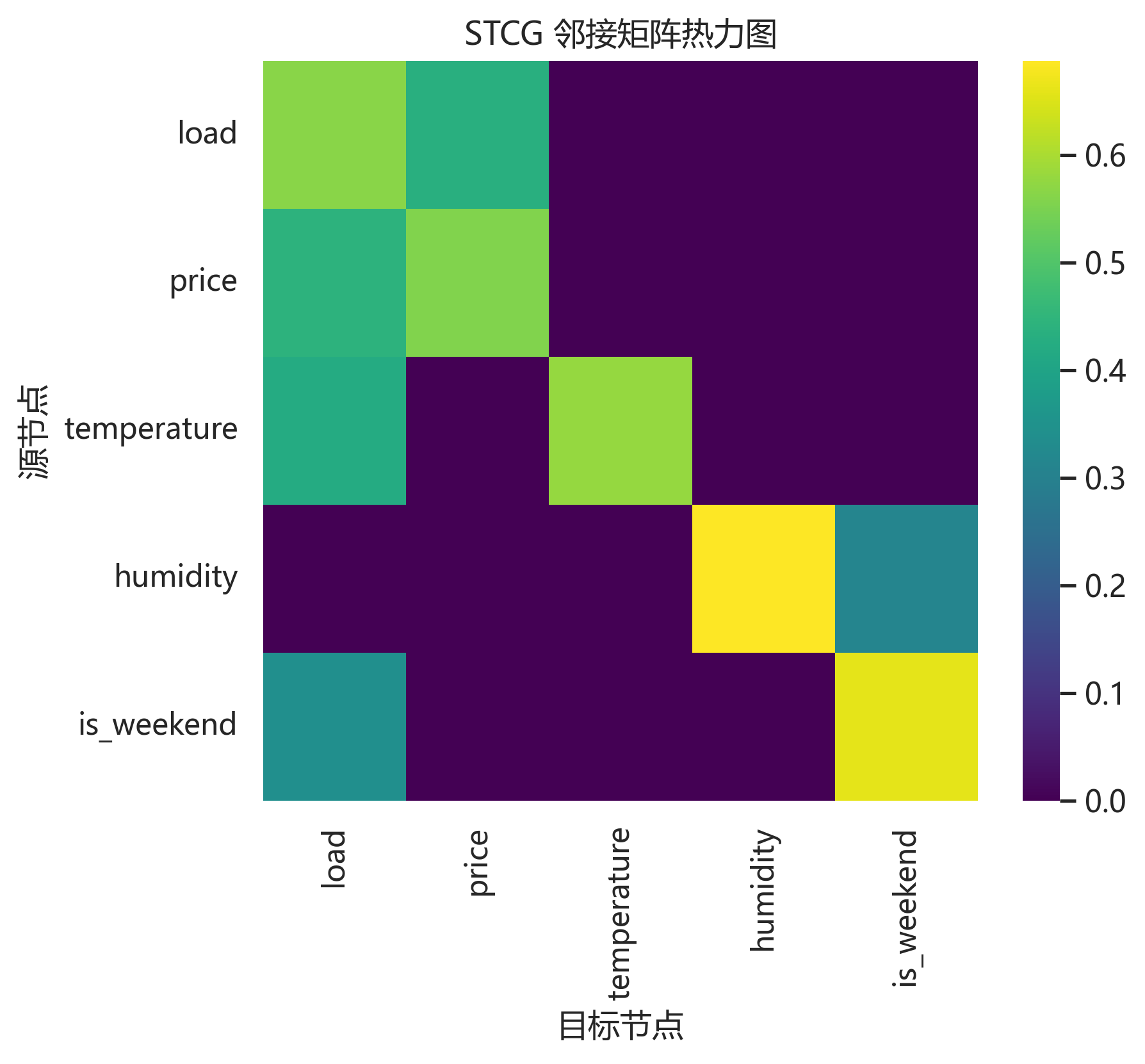
这张邻接矩阵图展示了模型在当前测试批次中学习到的变量连接强度。它不是静态相关系数表,而是结合窗口形状和可学习语义得到的动态图快照。对负荷预测而言,这类图可以帮助我们观察模型是否把 load、price、天气变量之间的关系纳入了建模。
4.2 MixHop 图卷积聚合
构建邻接矩阵后,需要把节点信息沿图传播。当前项目没有直接对每个时间步做图卷积,而是先为每个变量提取窗口统计摘要:
h i ( 0 ) = L i n e a r ( m e a n ( x ( i ) ) , s t d ( x ( i ) ) , l a s t ( x ( i ) ) ) \mathbf{h}_i^{(0)}=Linear\left(mean(\\mathbf{x}\^{(i)}),std(\\mathbf{x}\^{(i)}),last(\\mathbf{x}\^{(i)})\right) hi(0)=Linear(mean(x(i)),std(x(i)),last(x(i)))
也就是用均值、标准差和最后一个观测值描述变量在窗口中的水平、波动和最近状态。
MixHop 的核心是多跳聚合:
H ( k ) = A ^ H ( k − 1 ) , k = 1 , 2 , ... , K \mathbf{H}^{(k)} = \hat{\mathbf{A}}\mathbf{H}^{(k-1)}, \quad k=1,2,\ldots,K H(k)=A^H(k−1),k=1,2,...,K
然后拼接 0 0 0 到 K K K 跳表示:
Z = H ( 0 ) ∥ H ( 1 ) ∥ ⋯ ∥ H ( K ) \mathbf{Z}=\\mathbf{H}\^{(0)}\\\|\\mathbf{H}\^{(1)}\\\|\\cdots\\\|\\mathbf{H}\^{(K)} Z=H(0)∥H(1)∥⋯∥H(K)
再经过线性映射、激活、dropout 和残差归一化:
H o u t = L a y e r N o r m ( H ( 0 ) + D r o p o u t ( G E L U ( Z W ) ) ) \mathbf{H}_{out}=LayerNorm\left(\mathbf{H}^{(0)}+Dropout(GELU(\mathbf{Z}\mathbf{W}))\right) Hout=LayerNorm(H(0)+Dropout(GELU(ZW)))
对应代码来自 models/graph_conv.py:
python
outs = [h]
cur = h
for _ in range(self.depth):
cur = torch.bmm(adj, cur)
outs.append(cur)
z = torch.cat(outs, dim=-1)
z = self.dropout(self.act(self.proj(z)))
return self.norm(h + z)当前配置中 mix_hop_layers=2,aggregation_depth=3,也就是图模块会堆叠两层,每层聚合到 3 跳邻居。
4.3 周期检测与多尺度 patch
SDGT 的另一个关键点是多尺度时间建模。电力负荷往往同时有日周期、半日周期、局部峰谷等不同尺度,如果只用固定 patch size,可能会偏向某一种周期。
当前项目使用 PeriodDetector 检测主周期,配置为:
yaml
period:
method: vmd_fft
fallback: fft
vmd_k: 5
vmd_alpha: 2000
max_periods: 4检测结果保存到 outputs/tables/australian_periods.csv:
| rank | period | method |
|---|---|---|
| 1 | 48 | vmd_fft |
| 2 | 47 | vmd_fft |
| 3 | 24 | vmd_fft |
| 4 | 6 | vmd_fft |
这里的 48 很合理,因为半小时级数据一天有 48 个点;24 对应半天尺度;6 则更像局部短时波动。47 接近 48,说明在噪声和趋势影响下,主周期估计不是绝对整数理想值。
多尺度 patch 构造可以写成:
P m , r = x r s m , x r s m + 1 , ... , x r s m + p m − 1 \mathbf{P}_{m,r}=\\mathbf{x}_{rs_m},\\mathbf{x}_{rs_m+1},\\ldots,\\mathbf{x}_{rs_m+p_m-1} Pm,r=xrsm,xrsm+1,...,xrsm+pm−1
其中 p m p_m pm 是第 m m m 个 patch size, s m s_m sm 是 stride。当前项目支持 overlapping patch:
s m = max ( 1 , r o u n d ( p m ⋅ ρ ) ) s_m = \max(1, round(p_m \cdot \rho)) sm=max(1,round(pm⋅ρ))
当前 stride_ratio=0.5,所以窗口之间有 50% 重叠。
对应代码来自 models/multi_scale_transformer.py:
python
stride = int(round(self.patch_size * stride_ratio)) if overlapping else self.patch_size
self.stride = max(1, stride)
patches = x.unfold(dimension=1, size=self.patch_size, step=self.stride)如果启用 channel-independent,每个变量会单独 patchify,再共享 Transformer 编码器:
E m , r ( c ) = L i n e a r ( P m , r ( c ) ) ∈ R d \mathbf{E}{m,r}^{(c)}=Linear(\mathbf{P}{m,r}^{(c)})\in\mathbb{R}^d Em,r(c)=Linear(Pm,r(c))∈Rd
这样做的好处是不同变量先独立学习时间模式,最后再聚合通道表示,减少变量混合带来的噪声。
4.4 Transformer 注意力
每个尺度分支内部使用 Transformer Encoder。给定 patch embedding 序列:
E m ∈ R P m × d \mathbf{E}_m \in \mathbb{R}^{P_m \times d} Em∈RPm×d
注意力中的 Query、Key、Value 为:
Q = E m W Q , K = E m W K , V = E m W V \mathbf{Q}=\mathbf{E}_m\mathbf{W}_Q,\quad \mathbf{K}=\mathbf{E}_m\mathbf{W}_K,\quad \mathbf{V}=\mathbf{E}_m\mathbf{W}_V Q=EmWQ,K=EmWK,V=EmWV
Scaled Dot-Product Attention 为:
A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q K ⊤ d k ) V Attention(\mathbf{Q},\mathbf{K},\mathbf{V})=Softmax\left(\frac{\mathbf{Q}\mathbf{K}^\top}{\sqrt{d_k}}\right)\mathbf{V} Attention(Q,K,V)=Softmax(dk QK⊤)V
多头注意力则是:
h e a d i = A t t e n t i o n ( Q i , K i , V i ) head_i = Attention(\mathbf{Q}_i,\mathbf{K}_i,\mathbf{V}_i) headi=Attention(Qi,Ki,Vi)
M H A ( E m ) = h e a d 1 ∥ h e a d 2 ∥ ⋯ ∥ h e a d h W O MHA(\mathbf{E}_m)=head_1\\\|head_2\\\|\\cdots\\\|head_h\mathbf{W}_O MHA(Em)=head1∥head2∥⋯∥headhWO
当前配置中 heads=4,encoder_layers=2,ffn_dim=1024,hidden_dim=512。项目里直接使用 PyTorch 的 nn.TransformerEncoderLayer:
python
enc_layer = nn.TransformerEncoderLayer(
d_model=hidden_dim,
nhead=heads,
dim_feedforward=ffn_dim,
dropout=dropout,
activation="gelu",
batch_first=True,
norm_first=True,
)
self.encoder = nn.TransformerEncoder(enc_layer, num_layers=layers)为了让模型获得额外的全局上下文,当前实现还引入了可学习 global tokens:
X ′ = G ∥ X \mathbf{X}' = \\mathbf{G} \\Vert \\mathbf{X} X′=G∥X
其中 G ∈ R g × C \mathbf{G}\in \mathbb{R}^{g \times C} G∈Rg×C,当前 global_token_len=3。
4.5 多尺度融合与输出层
不同 patch size 得到不同尺度的时间表示:
z 1 , z 2 , ... , z M \mathbf{z}_1,\mathbf{z}_2,\ldots,\mathbf{z}_M z1,z2,...,zM
当前多尺度聚合方式是 attention:
a m = exp ( w ⊤ z m ) ∑ r = 1 M exp ( w ⊤ z r ) a_m = \frac{\exp(\mathbf{w}^\top \mathbf{z}m)} {\sum{r=1}^{M}\exp(\mathbf{w}^\top \mathbf{z}_r)} am=∑r=1Mexp(w⊤zr)exp(w⊤zm)
z t i m e = ∑ m = 1 M a m z m \mathbf{z}{time}=\sum{m=1}^Ma_m\mathbf{z}_m ztime=m=1∑Mamzm
图模块输出 z g r a p h \mathbf{z}{graph} zgraph,时间模块输出 z t i m e \mathbf{z}{time} ztime,最终通过 gated fusion 融合:
g = σ ( M L P ( z g r a p h ∥ z t i m e ) ) \mathbf{g}=\sigma\left(MLP(\\mathbf{z}_{graph}\\\|\\mathbf{z}_{time})\right) g=σ(MLP(zgraph∥ztime))
z t i m e = ∑ m = 1 M a m z m \mathbf{z}{time}=\sum{m=1}^Ma_m\mathbf{z}_m ztime=m=1∑Mamzm
对应代码来自 models/layers.py:
python
z = torch.cat([graph_feat, temporal_feat], dim=-1)
gate = self.gate(z)
mixed = gate * graph_feat + (1.0 - gate) * temporal_feat
return mixed + self.out(z)最终预测头输出未来 96 步:
y ^ = F o r e c a s t H e a d ( z m i x ) ∈ R H \hat{\mathbf{y}}=ForecastHead(\mathbf{z}_{mix})\in\mathbb{R}^H y^=ForecastHead(zmix)∈RH
代码中的 SDGT.forward 很清楚地串起了整个流程:
python
if self.use_graph:
adj = self.stcg(x, dynamic=self.dynamic_graph)
self.last_adj = adj.detach()
graph_feat = self.graph_conv(x, adj)
if self.use_temporal:
temporal_feat = self.temporal(x)
if graph_feat is not None and temporal_feat is not None:
z = self.fusion(graph_feat, temporal_feat)
return self.head(z)5. 损失函数与评价指标
训练损失使用 MSE:
L M S E = 1 N H ∑ n = 1 N ∑ h = 1 H ( y ^ n , h − y n , h ) 2 \mathcal{L}{MSE}=\frac{1}{NH}\sum{n=1}^N\sum_{h=1}^H(\hat{y}{n,h}-y{n,h})^2 LMSE=NH1n=1∑Nh=1∑H(y^n,h−yn,h)2
评估阶段在反标准化后的真实量纲上计算指标。MAE 为:
M A E = 1 N H ∑ n = 1 N ∑ h = 1 H ∣ y ^ n , h − y n , h ∣ MAE=\frac{1}{NH}\sum_{n=1}^N\sum_{h=1}^H|\hat{y}{n,h}-y{n,h}| MAE=NH1n=1∑Nh=1∑H∣y^n,h−yn,h∣
RMSE 为:
R M S E = 1 N H ∑ n = 1 N ∑ h = 1 H ( y ^ n , h − y n , h ) 2 RMSE=\sqrt{\frac{1}{NH}\sum_{n=1}^N\sum_{h=1}^H(\hat{y}{n,h}-y{n,h})^2} RMSE=NH1n=1∑Nh=1∑H(y^n,h−yn,h)2
MAPE 为:
M A P E = 100 N H ∑ n = 1 N ∑ h = 1 H ∣ y ^ n , h − y n , h y n , h + ϵ ∣ MAPE=\frac{100}{NH}\sum_{n=1}^N\sum_{h=1}^H\left|\frac{\hat{y}{n,h}-y{n,h}}{y_{n,h}+\epsilon}\right| MAPE=NH100n=1∑Nh=1∑H yn,h+ϵy^n,h−yn,h
R2 为:
R 2 = 1 − ∑ ( y ^ − y ) 2 ∑ ( y − y ˉ ) 2 + ϵ R^2=1-\frac{\sum(\hat{y}-y)^2}{\sum(y-\bar{y})^2+\epsilon} R2=1−∑(y−yˉ)2+ϵ∑(y^−y)2
项目里还实现了一个工程口径的 Accuracy:
A c c u r a c y = max ( 0 , 100 − M A P E ) Accuracy = \max(0, 100 - MAPE) Accuracy=max(0,100−MAPE)
指标计算代码来自 utils/metrics.py:
python
def compute_metrics(y_true, y_pred):
y_true = np.asarray(y_true).reshape(-1)
y_pred = np.asarray(y_pred).reshape(-1)
return {
"MAE": mae(y_true, y_pred),
"RMSE": rmse(y_true, y_pred),
"MAPE": mape(y_true, y_pred),
"R2": r2_score_np(y_true, y_pred),
"Accuracy": accuracy_paper(y_true, y_pred),
}6. 工程实现细节
6.1 配置管理
项目将数据配置和模型配置拆成两个 YAML 文件,然后在 utils/io_utils.py 中合并:
python
def load_config(dataset_config, model_config="configs/model.yaml"):
model = load_yaml(model_config)
dataset = load_yaml(dataset_config)
cfg = deep_update(model, dataset)
normalize_config_paths(cfg)
return cfgconfigs/australian.yaml 负责数据路径、字段名、窗口长度和训练参数,configs/model.yaml 负责 SDGT 模型结构。这样做的好处是换数据集时不需要改模型代码,调模型时也不容易误改数据字段。
当前关键配置如下:
yaml
dataset:
name: australian
raw_path: data/raw/australian.csv
time_col: timestamp
target_col: load
feature_cols: [load, price, temperature, humidity, is_weekend]
sampling_interval: "30min"
lookback: 336
horizon: 96
train_ratio: 0.7
val_ratio: 0.1
test_ratio: 0.2
normalize: true
scaler: standard
training:
quick_epochs: 10
full_epochs: 50
batch_size: 32
lr: 0.0005
weight_decay: 0.0001
scheduler: cosine6.2 路径鲁棒性修复
复现项目最常见的问题之一,是从不同工作目录运行脚本时找不到数据文件。这个项目专门实现了项目根目录推断和相对路径解析:
python
def resolve_project_path(path_like, project_root=None):
if path_like is None or str(path_like).strip() == "":
raise ValueError("配置项 raw_path 为空,请在配置文件中填写原始数据路径。")
raw = Path(str(path_like)).expanduser()
if raw.is_absolute():
return raw.resolve()
root = project_root or find_project_root()
return (root / raw).resolve()也就是说,data/raw/australian.csv 永远会被解析到项目根目录下,而不是依赖当前 shell 的 os.getcwd()。这对 Windows 环境尤其有用。
6.3 CSV 列检查与错误信息
预处理阶段不是直接读完就训练,而是先检查时间列、目标列和特征列:
python
def check_required_columns(df, time_col, target_col, feature_cols):
expected = [time_col, target_col, *feature_cols]
expected = list(dict.fromkeys(expected))
actual = list(df.columns)
missing = [c for c in expected if c not in actual]
if missing:
raise ValueError(
f"期望列: {expected}\n实际列: {actual}\n缺失列: {missing}"
)这个小细节能省很多排错时间。负荷数据来自不同平台时,字段名经常是 SETTLEMENTDATE、TOTALDEMAND、PowerConsumption_Zone1 之类,如果没有列检查,错误会延迟到模型输入阶段才爆出来。
6.4 模拟数据生成
为了保证项目开箱可跑,scripts/make_mock_australian.py 生成了 4000 行半小时级数据。核心逻辑是把负荷拆成多个可解释部分:
python
morning_peak = 220 * np.exp(-0.5 * ((hour - 8.0) / 2.0) ** 2)
evening_peak = 340 * np.exp(-0.5 * ((hour - 19.0) / 2.8) ** 2)
daily_cycle = 260 * np.sin(day_phase - 0.7)
weekly_cycle = 180 * np.cos(week_phase - 0.5)
weekend_effect = -180 * is_weekend
temp_effect = 18 * np.maximum(temperature - 24, 0)
load = 2450 + morning_peak + evening_peak + daily_cycle + weekly_cycle + weekend_effect + temp_effect + noise这段生成逻辑的好处是,模型不是在拟合一条毫无结构的随机曲线,而是在学习一个接近负荷预测任务的合成系统。
6.5 训练循环
训练阶段使用 AdamW、MSELoss、梯度裁剪和 cosine 学习率调度:
python
for x, y in train_loader:
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
pred = model(x)
loss = criterion(pred, y)
loss.backward()
if grad_clip:
torch.nn.utils.clip_grad_norm_(model.parameters(), grad_clip)
optimizer.step()每个 epoch 后在验证集上计算 loss 和指标,若验证 loss 改善则保存 best checkpoint。当前 quick 模式训练 10 个 epoch。
6.6 可视化输出
项目的可视化集中在 utils/plots.py。训练结束后会自动输出:
- 训练 / 验证 loss;
- 学习率曲线;
- epoch 指标曲线;
- 真实值 vs 预测值;
- 局部放大预测图;
- pred vs true 散点图;
- 残差分布和残差序列;
- horizon 误差曲线;
- STCG 邻接矩阵热力图。
这样做的价值很大:只看一个 RMSE,很难判断模型到底是峰值预测差、远期预测差,还是整体偏差;图表能把误差结构暴露出来。
7. 实验结果与图表分析
7.1 训练过程
训练日志中检测到的 patch sizes 为:
text
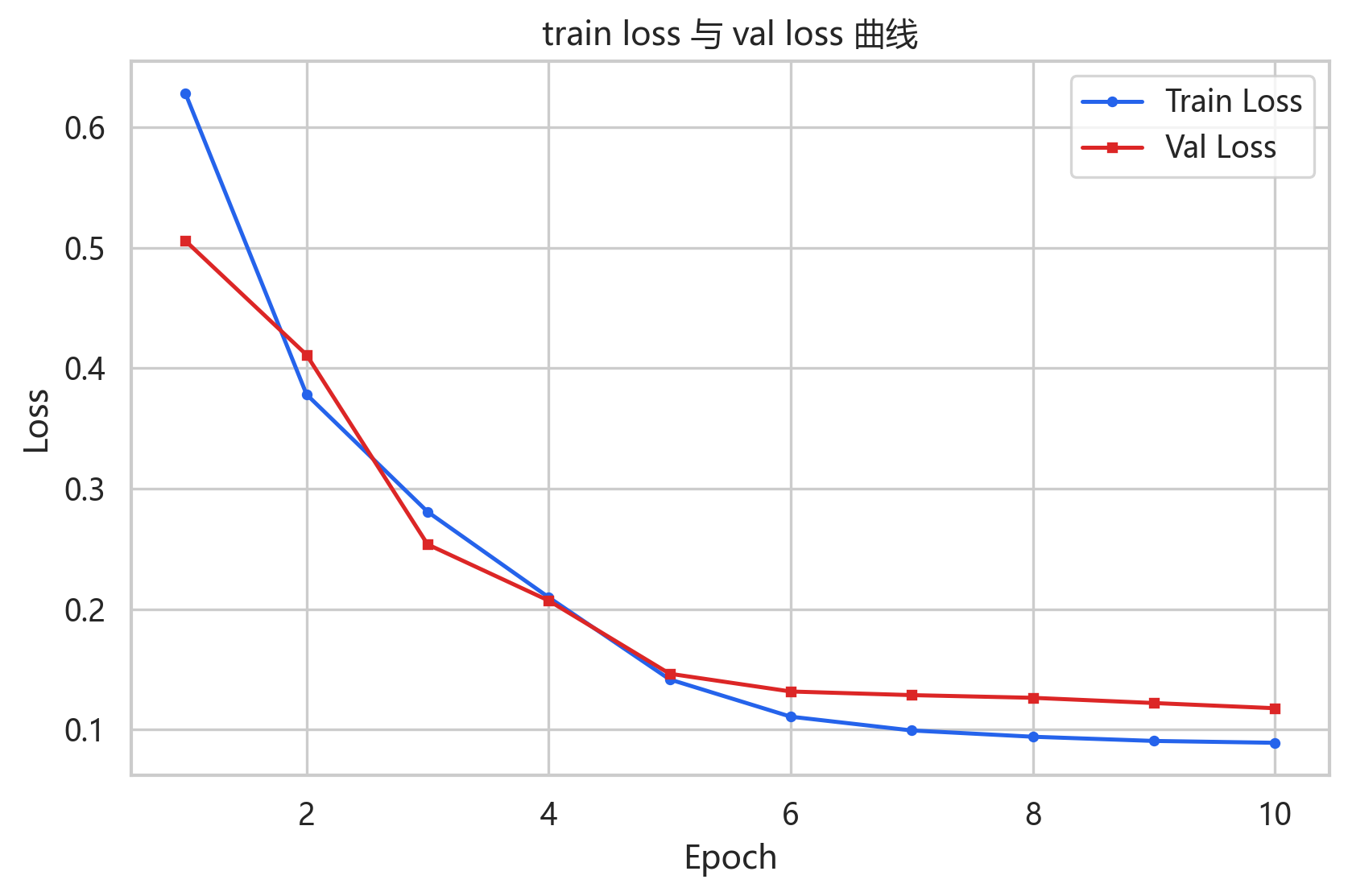
[48, 47, 24, 6]quick 模式训练 10 个 epoch,验证 loss 从 0.5057 下降到 0.1178,验证 RMSE 从 0.7111 下降到 0.3433。注意这里是标准化空间上的验证指标,最终测试指标是在反标准化后计算的。
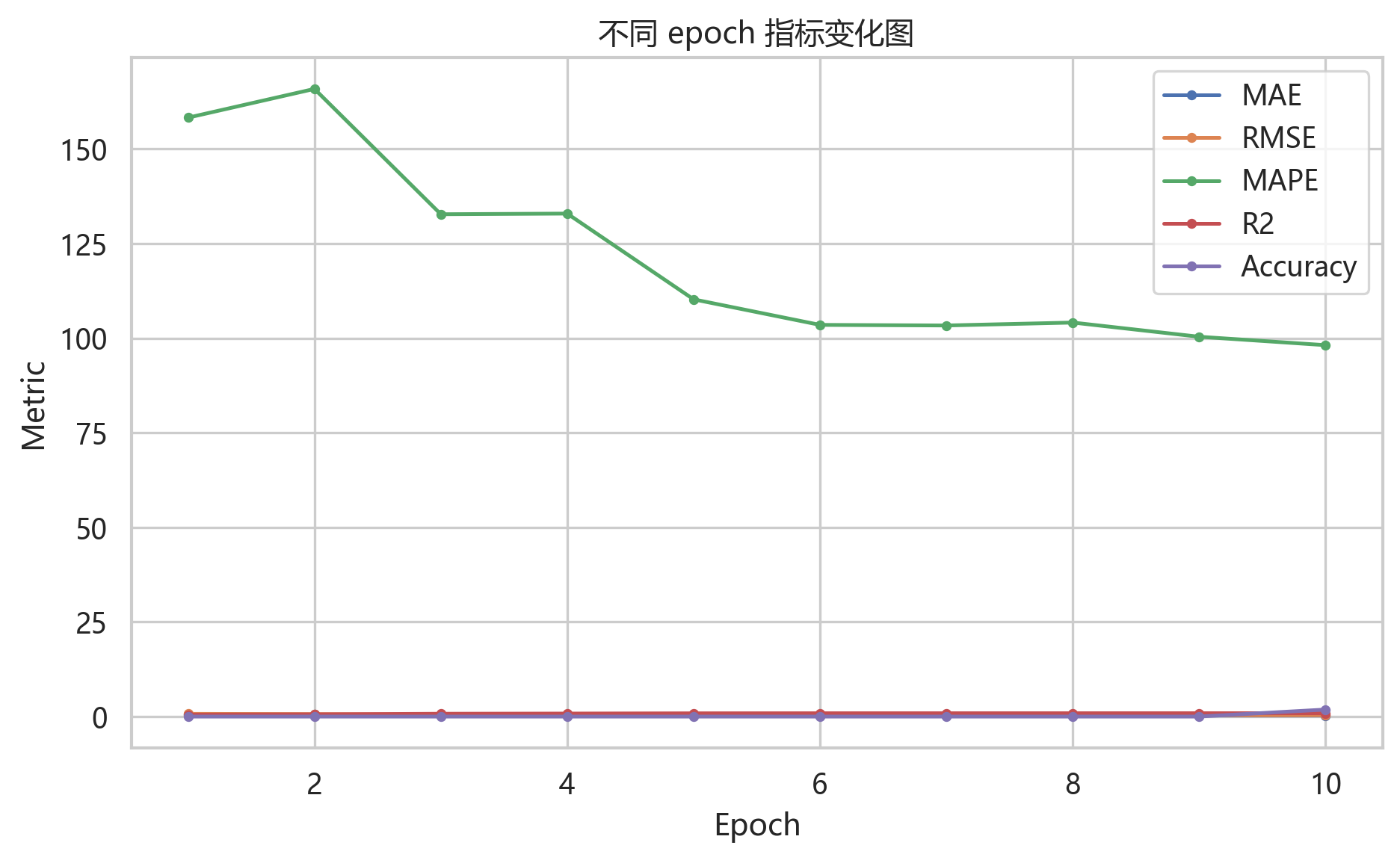
loss 曲线整体下降,训练集和验证集之间没有出现明显背离。第 5 个 epoch 后下降速度放缓,说明模型已经学到主要周期和变量关系,后面更多是在微调。
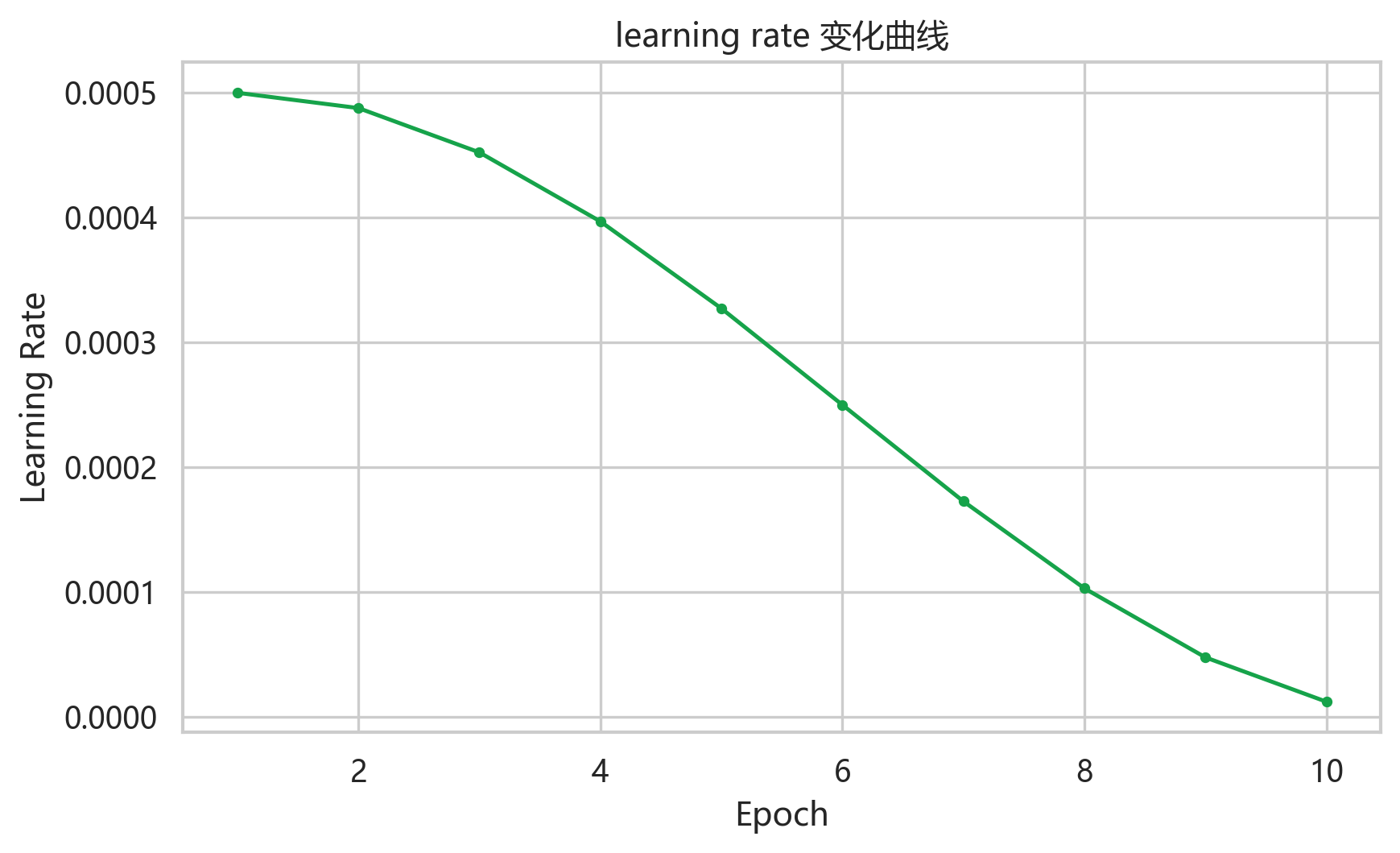
学习率曲线符合 cosine 调度预期,从 5e-4 平滑降到接近 1.22e-5。这种调度在 quick 训练里比较稳,不会在最后几个 epoch 继续大步更新。
指标曲线中 MAE、RMSE 持续下降,R2 持续上升,说明模型学习过程是有效的。这里的 MAPE 和 Accuracy 是标准化空间验证阶段计算出来的,不适合作为最终业务指标解读;最终测试指标以反标准化后的结果为准。
7.2 测试集整体指标
测试集最终指标如下:
| Model | MAE | RMSE | MAPE | R2 | Accuracy |
|---|---|---|---|---|---|
| SDGT | 67.92 | 84.45 | 2.50% | 0.8648 | 97.50 |
从量纲上看,测试集真实负荷均值约为 2697,标准差约为 230,RMSE 为 84.45,约占负荷均值的 3.13%。对于当前模拟数据,这个结果说明模型已经较好捕捉了主周期和外生变量影响。
7.3 预测曲线分析
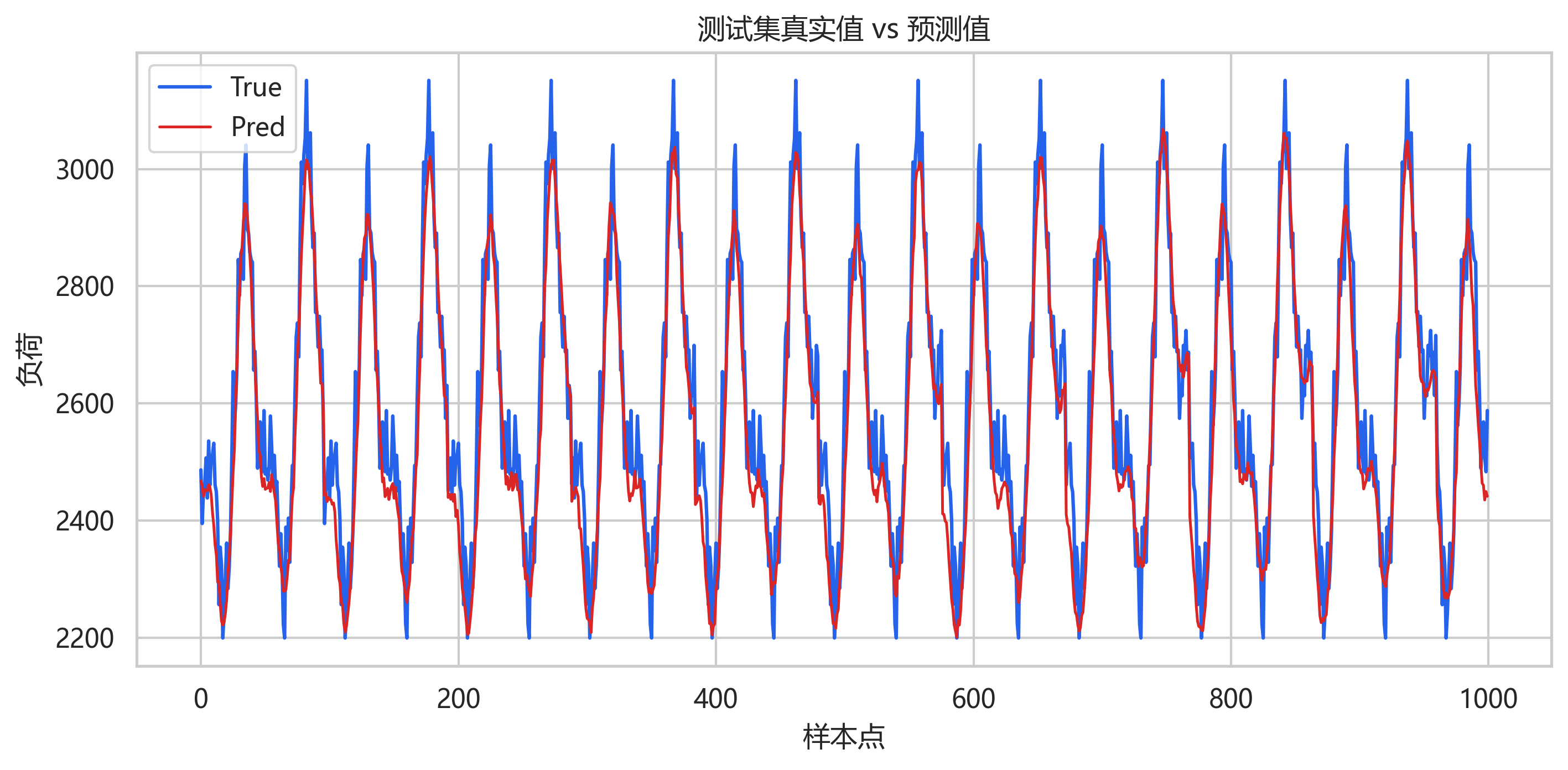
整体预测曲线与真实曲线贴合较好,主要峰谷位置能够跟随。由于这是把所有测试窗口的 96 步预测展平后绘制,曲线中会包含大量重叠窗口的连续预测结果,因此更适合观察整体拟合趋势。
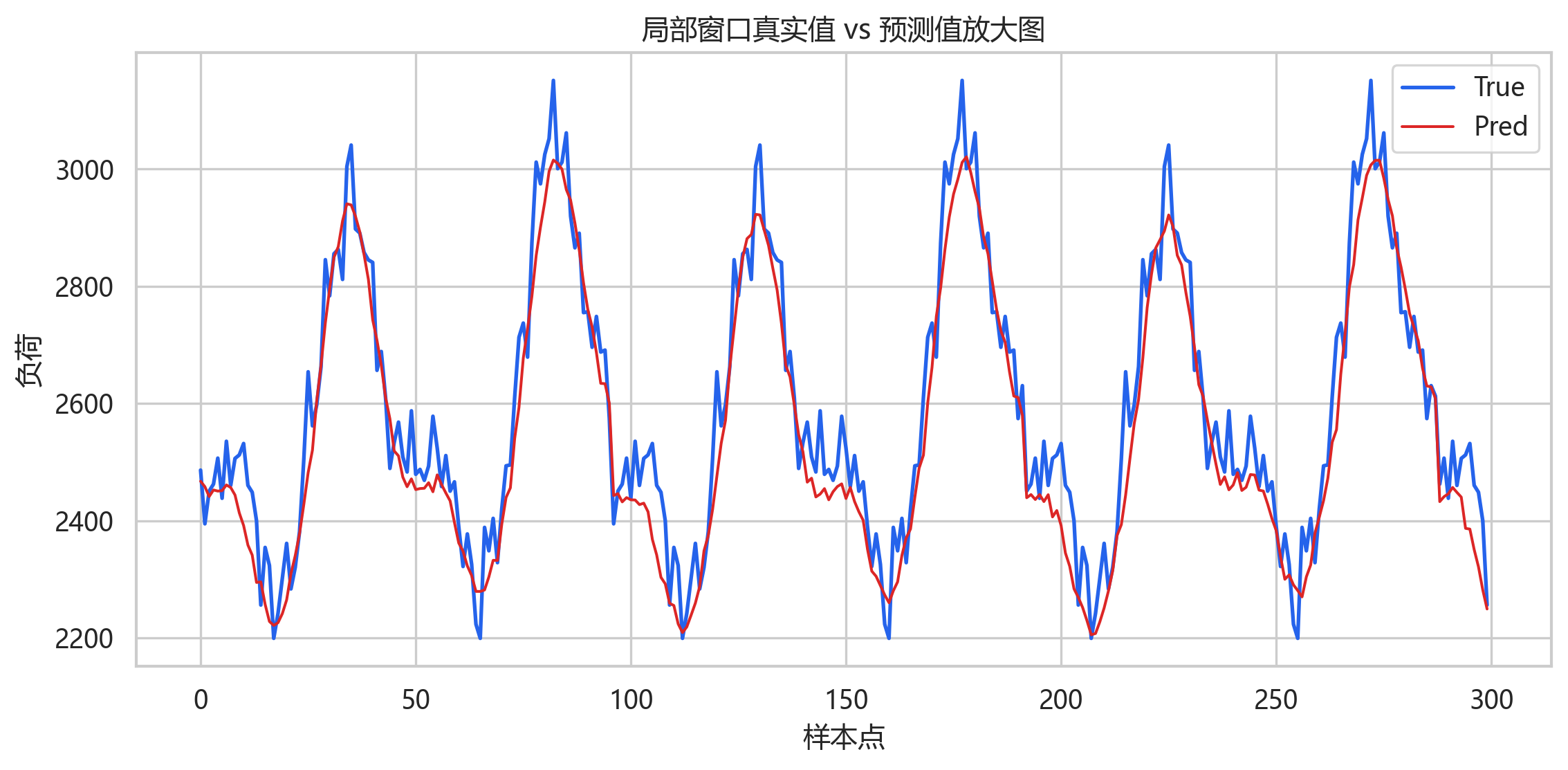
局部放大图能看到更细的误差:模型对负荷上升和下降趋势反应较快,但在部分峰值附近略有低估。这类现象在负荷预测中很常见,因为 MSE 倾向于学习均值附近的稳定模式,极端峰值样本相对较少。
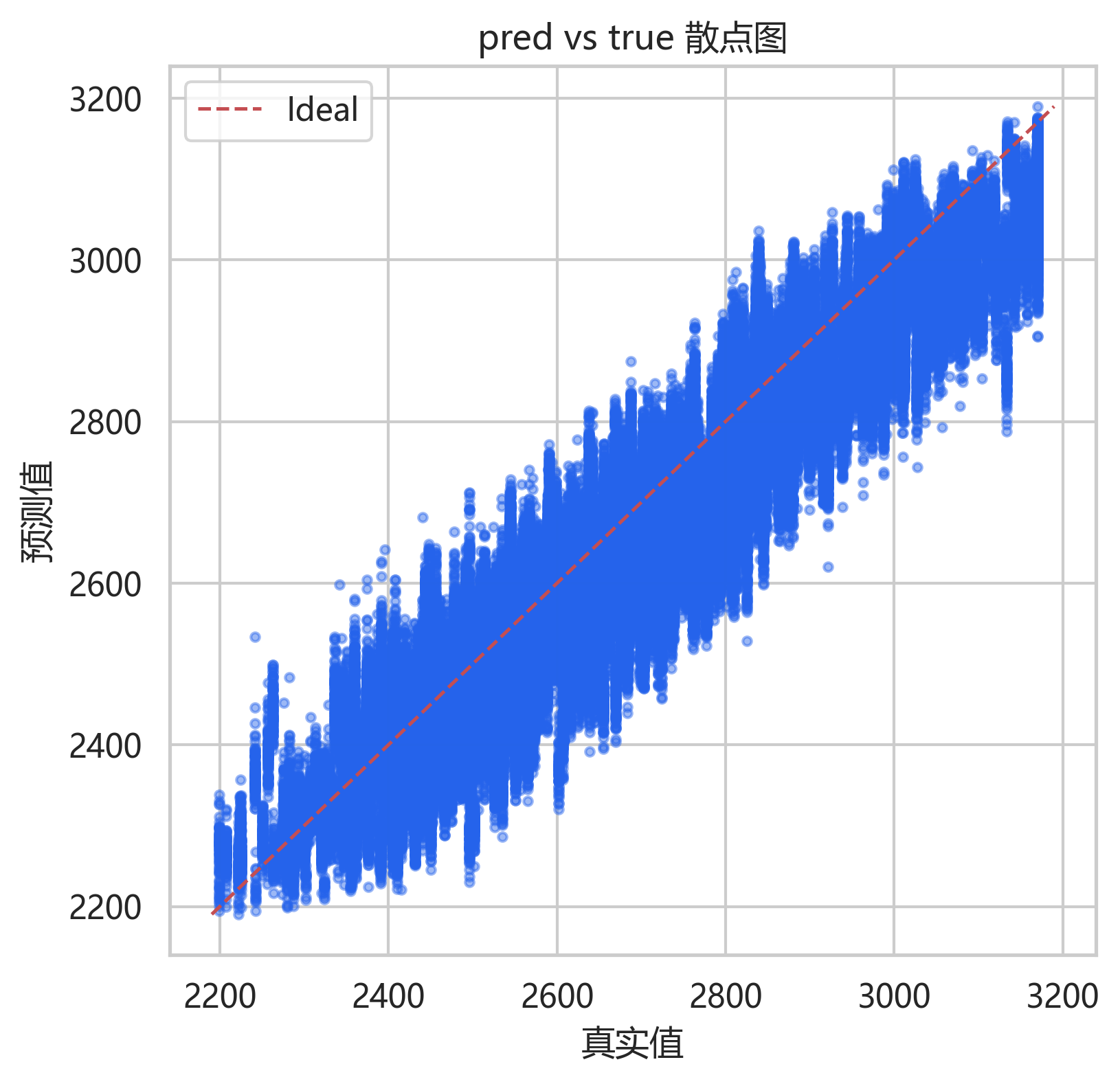
散点大多分布在对角线附近,展平后的预测值与真实值相关系数约为 0.949。高负荷区的点略有分散,说明峰值区间仍是误差主要来源之一。
7.4 从图表反推模型效果
如果只看 MAPE=2.50%,很容易得出"模型很好"的结论,但图表能告诉我们更多细节。
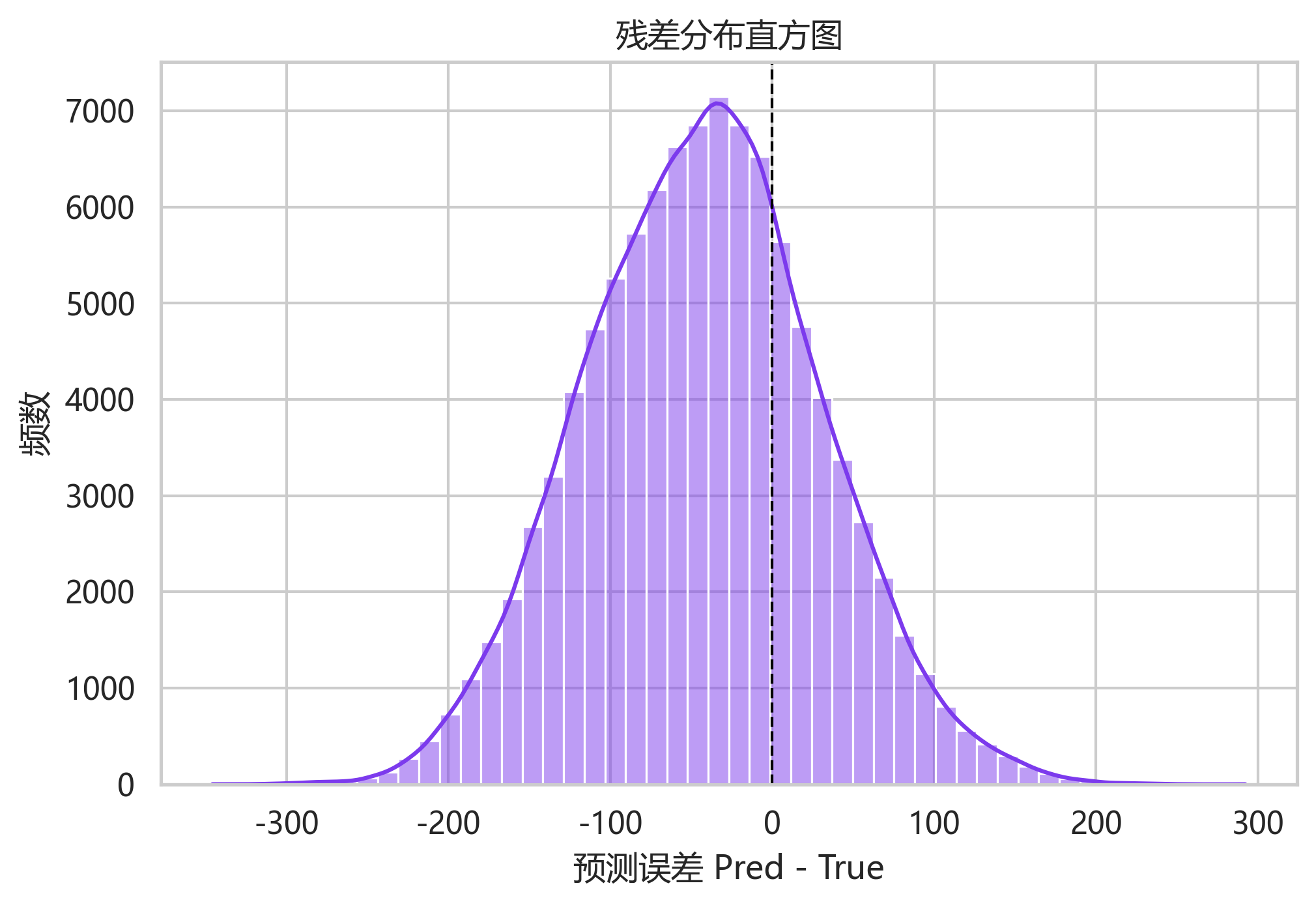
残差均值约为 -43.10,标准差约为 72.62,中位数约为 -42.40。这说明模型整体存在一定低估倾向,而不是完全围绕 0 对称波动。换句话说,模型学到了曲线形状,但输出水平略偏保守。
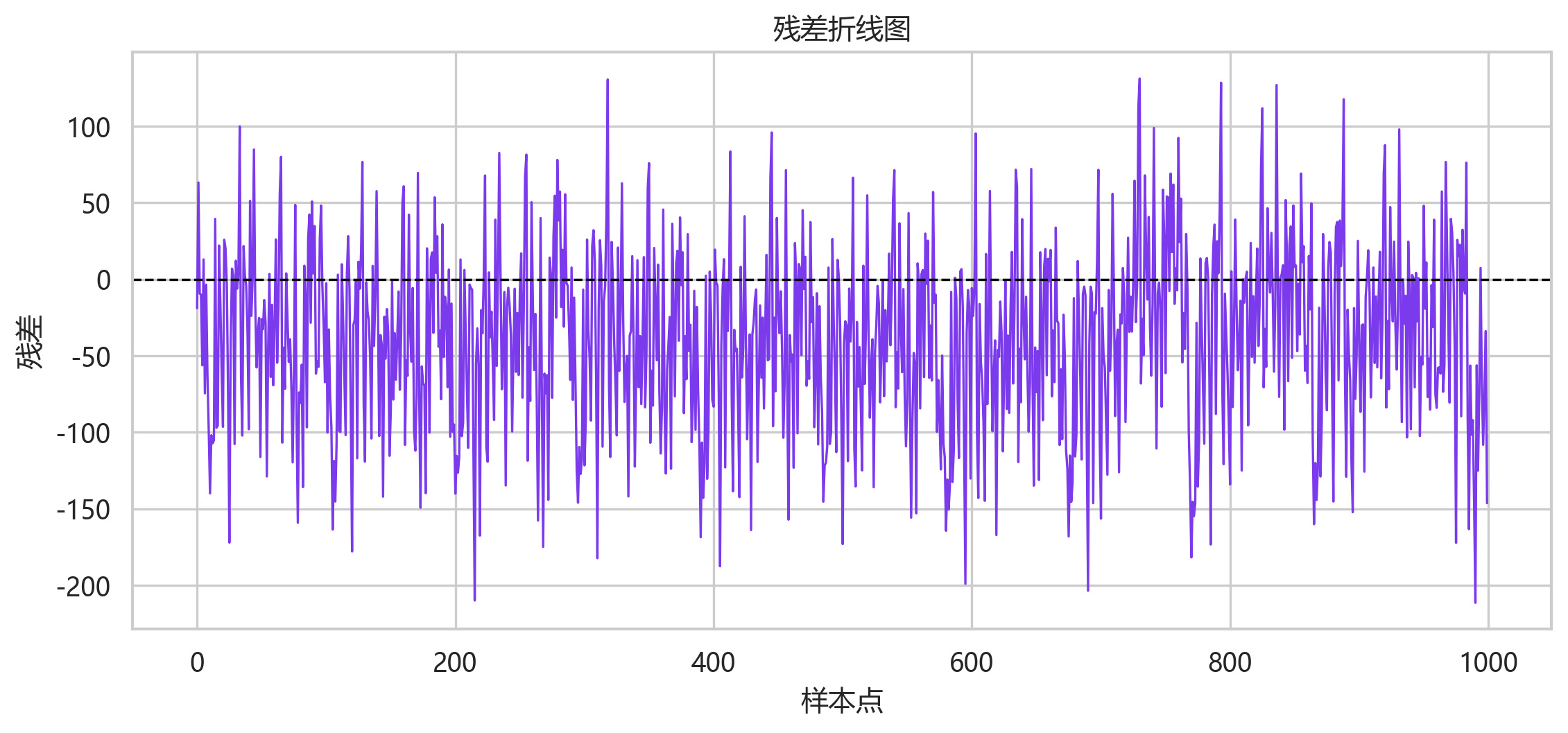
残差序列大多在较有限范围内波动,没有出现长期单边漂移,但局部区间仍有连续偏负误差。这可能对应峰值或趋势变化较快的时间段。
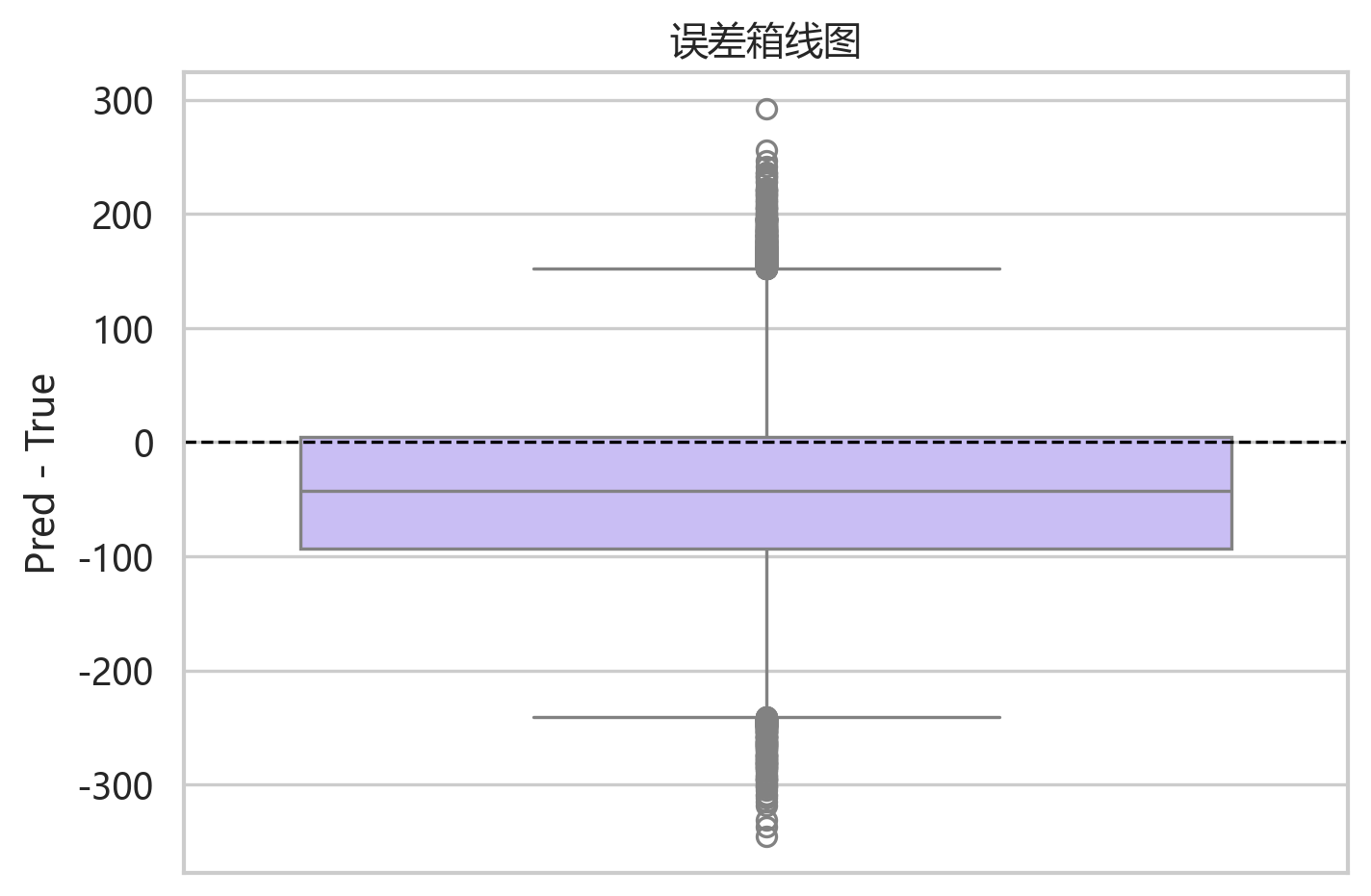
箱线图进一步确认了残差分布的偏移。误差中存在少量离群点,最大低估约为 -345.70,最大高估约为 292.15。在实际负荷预测中,这类极端误差往往比平均误差更值得关注,因为它们会影响调度和备用容量决策。
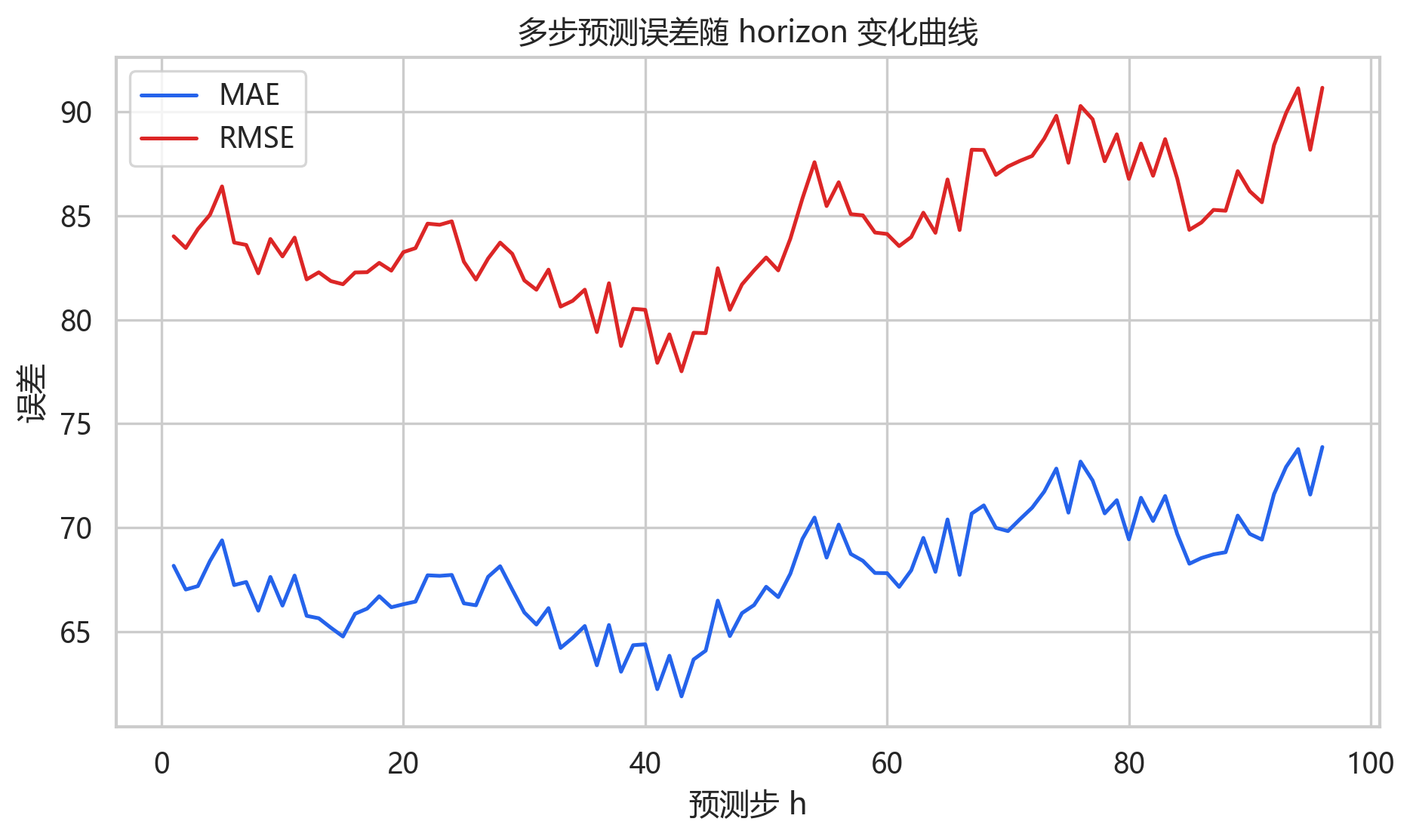
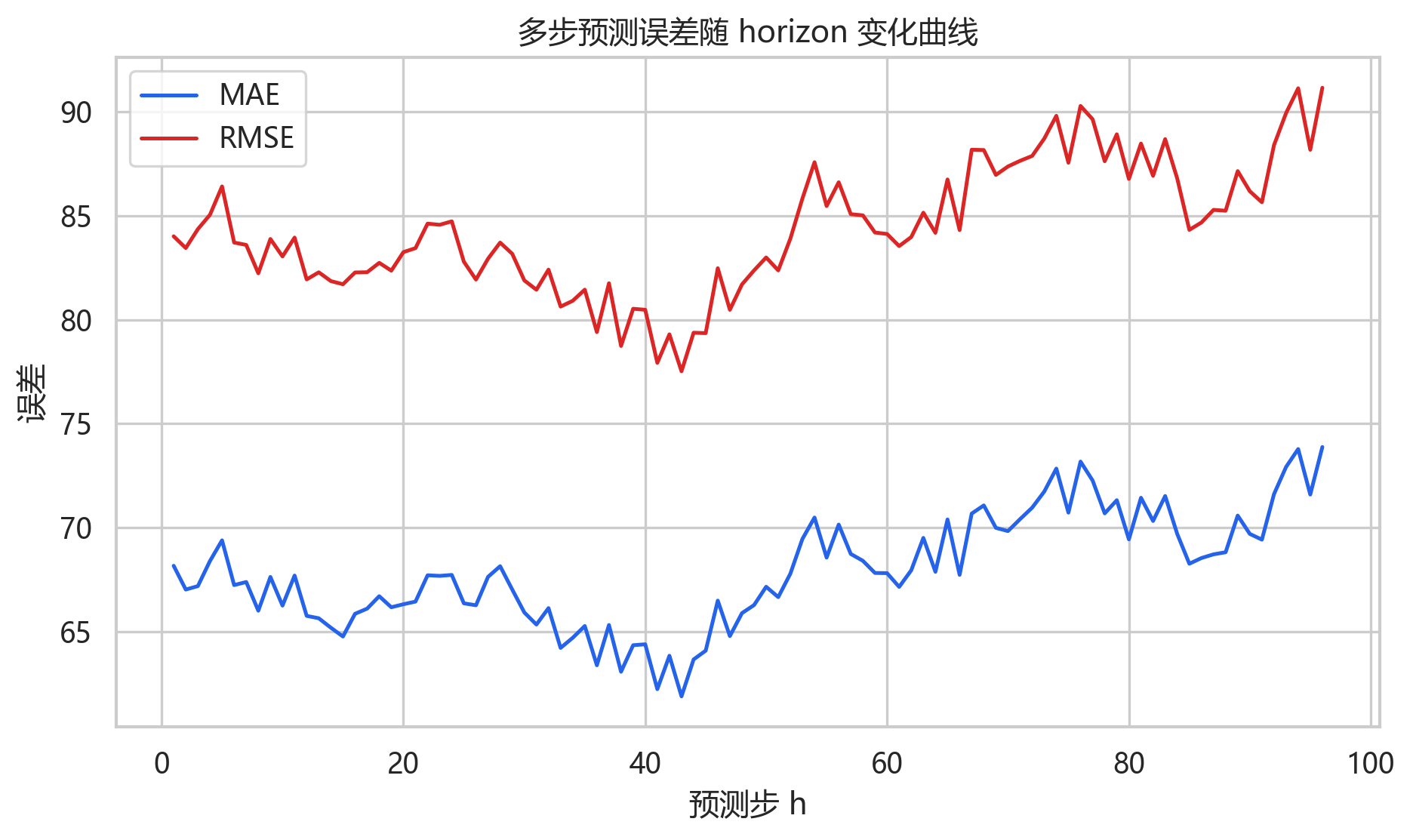
horizon 误差曲线显示,越靠后的预测步误差略有上升。第 1 步 MAE 约为 68.16,第 48 步约为 66.27,第 96 步约为 73.88,最大误差出现在第 96 步。这个结果符合多步预测的一般规律:预测越远,不确定性越高。
7.5 数据图与结果图的联动解释
回到前面的数据图,可以发现几个现象能解释模型效果:
- 负荷有稳定日周期,因此周期检测得到
48后,多尺度 Transformer 能较好捕捉日内模式; price与load强相关,STCG 和多变量输入都能利用这部分信息;temperature与负荷正相关,天气变量为峰谷变化提供了额外解释;- 残差存在轻微负偏,说明模型可能对高负荷峰值仍然偏保守。
这也是我比较喜欢保留全套图表的原因:训练曲线告诉你"模型有没有学",预测曲线告诉你"拟合像不像",残差图告诉你"错在哪里",horizon 曲线告诉你"远期退化有多明显"。
8. 项目踩坑记录
8.1 FileNotFoundError:相对路径不等于项目路径
最容易踩的坑是:
text
FileNotFoundError: data/raw/australian.csv原因通常不是文件真的不存在,而是命令从别的目录启动,导致相对路径被解析到错误位置。项目里的修复方式是用 find_project_root() 自动寻找包含 main.py 和 configs/ 的目录,然后把相对路径解析到项目根目录。
更进一步,validate_raw_file() 会把配置路径、解析后绝对路径、当前工作目录、推断项目根目录、建议放置位置都打印出来。这个错误信息对复现者非常友好。
8.2 字段名不一致
公开负荷数据常常字段名不同。例如 README 中提到真实 Australian 数据可能使用:
text
SETTLEMENTDATE
TOTALDEMAND而当前模拟数据使用:
text
timestamp
load所以项目把字段写进配置文件,而不是硬编码在预处理脚本中。遇到列缺失时,错误信息会列出期望列、实际列和缺失列,定位很快。
8.3 时间列解析失败
时间列如果不是标准格式,pd.to_datetime(..., errors="coerce") 可能会产生空值。项目在所有时间值都无法解析时直接报错,并展示前 5 个原始时间值,方便检查 CSV 导出格式。
8.4 周期检测依赖问题
论文思路中使用 VMD+FFT,但 VMD 依赖 vmdpy。项目里做了降级策略:
text
vmd_fft 失败 -> fallback 到 fft 或 acf这样即使某些环境安装不了 vmdpy,训练流程也不会完全中断。降级方法会写入周期表,保证实验记录可追踪。
8.5 训练指标和测试指标口径不同
训练过程中的验证指标是在标准化空间上算的,最终测试指标是在反标准化后算的。写博客或报告时必须说明这一点,否则读者会发现验证 MAPE 很大、测试 MAPE 很小,看起来像矛盾。实际上二者口径不同。
9. 当前实现的局限
这次复现已经跑通了完整流程,但仍有几个限制需要诚实说明:
- 当前博客中的结果来自 Australian 风格模拟数据,不代表真实电网数据上的最终表现;
- STCG 的公式细节是根据论文思路做的工程实现,不是论文官方源码逐行复刻;
- 当前只做单目标负荷预测,虽然输入是多变量,但输出只有
load; - quick 模式只训练 10 个 epoch,适合验证流程,不代表充分调参后的最优结果;
- 当前结果表只保留了 SDGT 主线,基线对比和消融接口存在,但本次主线结果没有展开多模型对比表;
- 残差存在整体低估倾向,后续可以针对峰值负荷加权训练或做分段误差优化。
10. 后续改进方向
后续如果继续完善这个项目,我会优先做几件事:
- 接入真实 Australian 或 Morocco 数据,保留模拟数据作为 quick demo;
- 增加多随机种子实验,输出均值和标准差;
- 完整跑通 LSTM、CNN-LSTM、PatchTST、XGBoost 基线对比;
- 做消融实验:去动态图、静态图、单尺度 patch、不同稀疏率;
- 引入峰值加权损失,缓解当前预测偏保守的问题;
- 将周期检测结果保存进 checkpoint,推理阶段直接复用训练期 periods;
- 增加 attention / adjacency 的时间变化可视化,而不只是保存一个 batch 快照。
11. 运行命令与输出文件
生成模拟数据:
bash
python scripts/make_mock_australian.pyquick 模式训练:
bash
python main.py --dataset australian --mode train --config configs/australian.yaml --run_mode quick测试 checkpoint:
bash
python main.py --dataset australian --mode test --checkpoint outputs/checkpoints/australian_sdgt_best.pt主要输出文件包括:
text
outputs/checkpoints/australian_sdgt_best.pt
outputs/logs/australian_sdgt.log
outputs/tables/australian_sdgt_metrics.csv
outputs/tables/australian_sdgt_history.json
outputs/tables/australian_periods.csv
outputs/tables/australian_sdgt_true.npy
outputs/tables/australian_sdgt_pred.npy
outputs/figures/*.png参考论文入口:
12. 总结
这次 SDGT 复现对我最大的价值,不只是跑出了一个还不错的指标,而是把"短期负荷预测项目应该具备的工程闭环"补齐了:数据诊断、滑动窗口、多步预测、动态图建模、多尺度周期建模、训练记录、预测分析和残差解释。
从结果看,当前 SDGT 在 Australian 风格半小时级数据上能较好跟随负荷曲线,测试集 MAPE=2.50%,整体拟合效果不错;从误差结构看,模型仍有轻微低估倾向,远期 horizon 误差也会逐步增加。这些问题并不奇怪,反而说明图表分析比单个指标更有价值。
3 条实战经验
- 做时序预测不要随机划分数据集,时间顺序切分是底线。
- 不要只看 RMSE,预测曲线、残差分布和 horizon 误差能暴露更多问题。
- 复现论文时要区分"论文原文确定实现"和"工程复现假设",这样结果才可解释、可维护。
想要源代码的,请再博客下面留言;制作不易,请各位看官老爷点个赞和收藏!!!!