你有没有过这样的体验------
月底一看 Cursor 的用量统计,发现额度已经见底,而距离重置还有一周。回想一下,好像也没干多少活啊,怎么就用完了?
如果你也有这种感觉,那么问题大概率不出在「用得太多」,而出在「用得不对」。
我用了 Cursor 一年多,从最初的月抛选手到现在的精打细算,踩了不少坑。这篇文章把我积累的实战技巧全部分享出来,没有废话,只有可操作的策略。
一、上下文控制 --- 省 Token 最大的杠杆
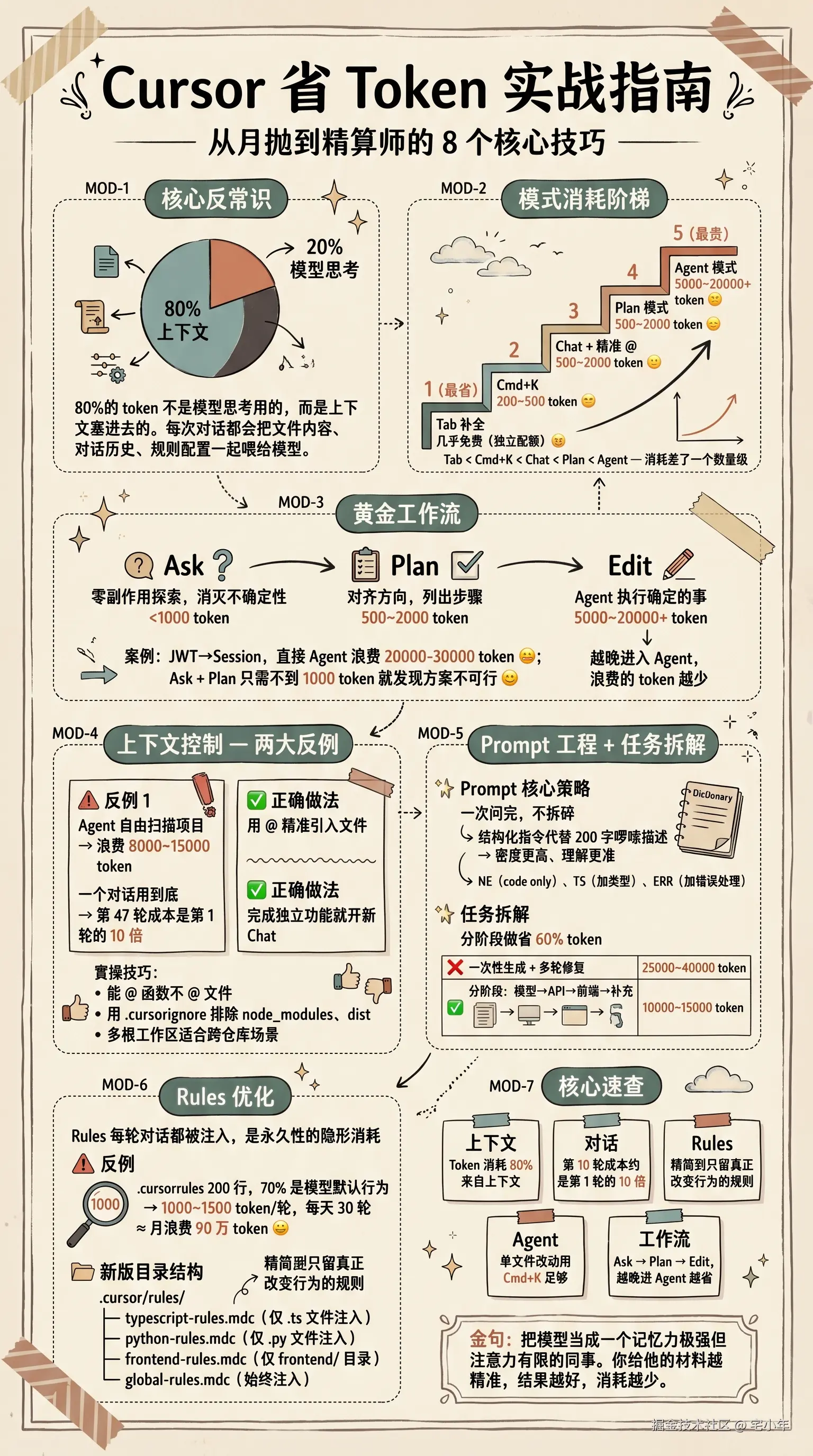
说一个反常识的事实:你消耗的 token 里,80% 不是模型思考用的,而是上下文塞进去的。
什么意思?每次你跟 Cursor 对话,它都会把当前上下文里所有的文件内容、对话历史、规则配置一起喂给模型。这些是你真正的成本大头。
❌ 反例:让 Agent 自由扫描项目
见过最多的场景:打开 Agent,不提具体文件,只说「帮我改一下用户注册表单的邮箱验证」。
Agent 开始自动分析项目结构------翻遍路由、控制器、模型、组件、样式文件,甚至在 dist/ 和 node_modules 里兜了一圈。为了改一个邮箱验证规则,读了几十个无关文件。
💸 浪费:8000~15000 token,而且无关文件会稀释模型的注意力,输出质量反而下降。
正确做法: 用 @ 精准引入表单组件文件,或者把要改的函数直接贴进对话。Agent 就不会漫无目的地扫全项目了。
@file 的正确姿势
@ 的本质是让你的上下文尽可能精简。几个实操经验:
- 能
@函数不@文件 :选中代码后用Cmd+K,上下文天然就是选中部分 - 能
@文件不依赖自动扫描:一个文件能说清楚的事,不要让 Agent 满项目乱翻 - 非要让 Agent 了解项目整体时 :先用
.cursorignore把node_modules、dist、*.lock、测试快照等大文件排除掉,减少自动扫描的噪音
简单来说,你给模型的材料越精准,它的注意力就越集中,结果越好,消耗越少。
❌ 反例:一个对话用到底
这个太常见了------一个 Chat 从周一开到周五,经历了创建项目结构(5 轮)、写用户模型(8 轮)、实现 API(12 轮)、写前端页面(15 轮)、修 bug(7 轮)......
到第 47 轮,你只是想加一个简单的排序功能。但对话上下文已经塞了几万 token 的历史,包含早已解决的问题、废弃的代码、不再适用的讨论。
💸 浪费:第 47 轮一个简单问题,光历史上下文就多消耗 30005000 token。开新对话只需 300500 token 描述背景。
Cursor 每轮都携带完整历史,第 10 轮的成本约是第 1 轮的 10 倍。而且上下文太长,模型反而记不住关键细节。
正确做法: 每完成一个独立功能,果断开新 Chat。关键结论(接口定义、核心逻辑)粘进去作为简短背景就行,比拖着几十轮历史便宜 10 倍。
多根工作区 --- 2026 年的新解法
Cursor 在 2026 年 4 月上线了多根工作区,单个 Agent 会话可以跨多个文件夹工作。如果你经常在前后端仓库之间切换,这个功能能省掉大量「每次重新指定目标文件」的重复上下文开销。
不过这个功能更适合跨仓库协同的场景,单仓库开发没必要用。
二、Prompt 工程 --- 一次问对,减少来回
每多一次来回,就多一轮完整的上下文传递。所以 prompt 的核心策略只有一个:一次问完,不拆碎。
❌ 反例:200 字自然语言啰嗦描述
「请你帮我在用户管理页面中增加一个搜索功能,这个搜索功能要能支持按照用户名、邮箱、手机号、注册时间范围来搜索用户,搜索结果要分页显示,每页 20 条......」
200 字自然语言里大量冗余,模型还要从段落里自己提取需求。
用结构化描述替代段落:
diff
用户列表搜索
- 搜索字段:用户名、邮箱、手机号、注册时间范围
- 分页:20条/页
- 排序:注册时间 ↓、用户名 ↑
- UI:搜索框 + 搜索按钮 + 重置按钮
- 状态:loading / 空结果 / 错误
NE(no explanation,只给代码)结构化指令密度更高,模型理解更准,输出也不带废话。
几个实战技巧
技巧一:建立个人缩写词典
在 .cursorrules 里定义缩写,之后 prompt 里直接用:
ini
- "NE" = no explanation, code only
- "TS" = add TypeScript types
- "ERR" = add error handling之后直接输入:「重构这个函数 NE + ERR + TS」
技巧二:指定输出范围
不加限制时,模型给你输出问题分析(200 token)+ 备选方案对比(300 token)+ 推荐理由(150 token)+ 完整代码(800 token)+ 测试建议(200 token)------60% 是你不想要的。
在 prompt 末尾加一句「只输出需要修改的行,不要解释」就能省掉这些。
💡 小提示: 用 Cmd+K 时直接在代码注释里写需求,比在 Chat 里描述省去大量历史上下文。比如选中函数后在代码里写 // TODO: 把这个 forEach 改成并发 Promise.all,加超时 5s,然后按 Cmd+K。
技巧三:用 @Docs 替代粘贴文档
需要引用库文档时,用 @Docs 让 Cursor 按需检索,而不是把整段文档粘进 Chat。模型只会读取相关的部分,省 token 效果明显。
三、模式选择 --- 按任务匹配成本
Cursor 有几种不同的交互模式,消耗差异非常大。很多人亏就亏在全程用一种模式干所有事。
从省到贵排个序:
Tab < Cmd+K < Chat < Plan < Agent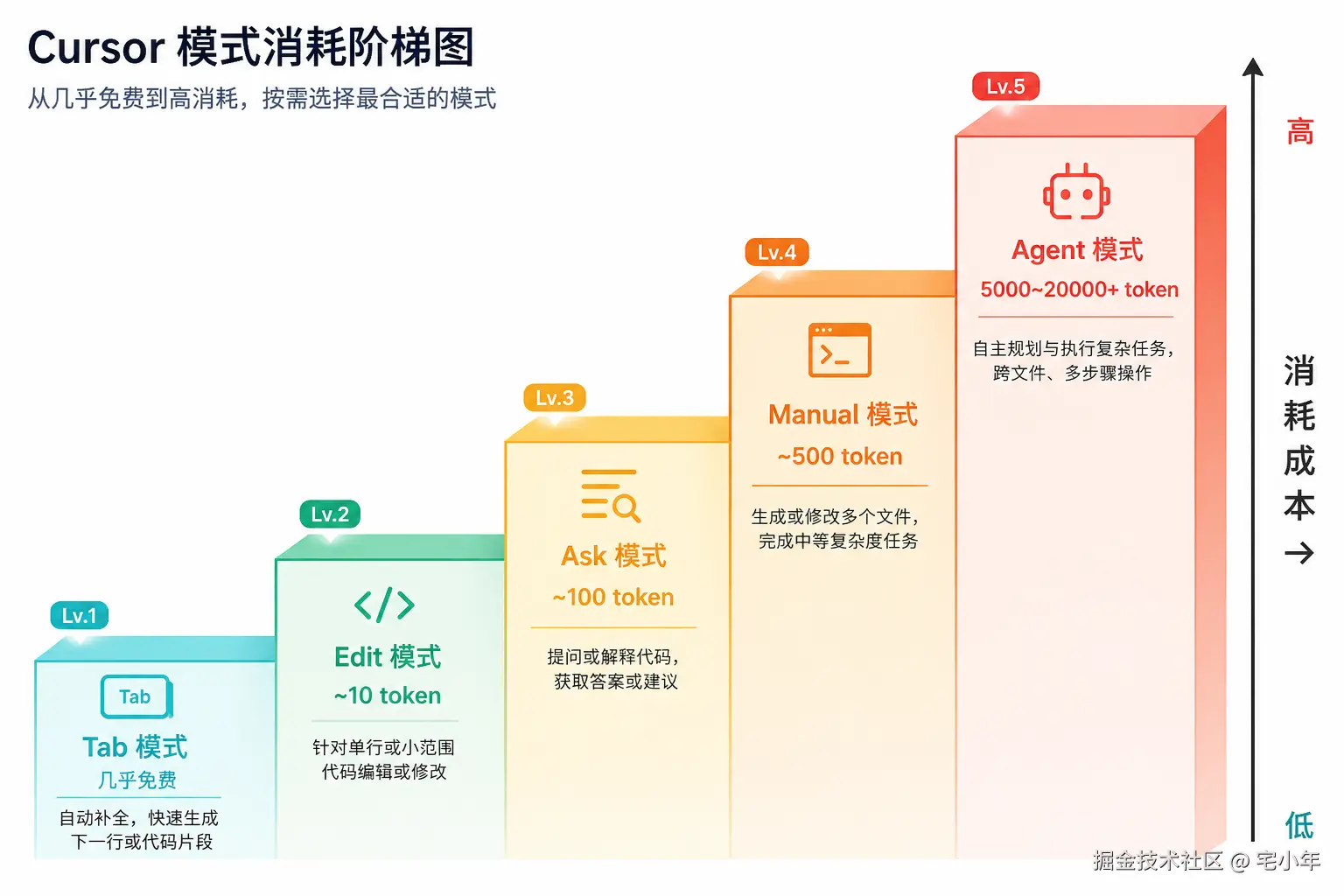
各模式消耗差了一个数量级。关键是要按任务匹配合适的模式。
| 任务类型 | 推荐模式 | 预估消耗 |
|---|---|---|
| 改变量名、格式化、加注释 | Tab 补全 / Cmd+K | 极低 |
| 单文件逻辑修改 | Chat + 精准 @ | 低 |
| 架构讨论、方案调研 | Plan(不写代码) | 低~中 |
| 跨文件复杂功能 | Agent | 高 |
❌ 反例:改个变量名也要开 Agent
改名、加注释、格式化这类简单任务,Agent 模式起步就是 20004000 token。Tab 补全几乎免费(走独立配额),Cmd+K 也只要 200500 token。为了省手指,多花十几倍 token,怎么看都不划算。
各模式详解
Tab 补全 --- 走独立配额,跟 Chat/Agent 的额度不互通。能用 Tab 解决的小改动------变量重命名、补全函数参数、快速导入------就不要去开 Chat 窗口。
Cmd+K --- 选中代码后直接修改,上下文天然就是选中部分,零额外开销。单函数修改的首选。
Chat --- 对话式交互,适合理解代码、讨论方案、单文件修改。配合精准 @ 引用,是日常最均衡的模式。
Plan --- 规划模式,只出方案不写代码。适合探索架构、评估影响范围、确认改动步骤。消耗极低,是 Agent 的前置安全网。
Agent --- 自主执行模式,能自动读文件、改代码、跑命令。能力最强但消耗最高,留到复杂的跨文件任务再用。
用统计数据说话
定期去 Cursor 的 Settings → Usage 看看,找出哪类任务消耗最高。很多时候你凭感觉觉得「Agent 用得多」,但看到具体数字才知道多到什么程度。数据会告诉你该在哪个环节优化。
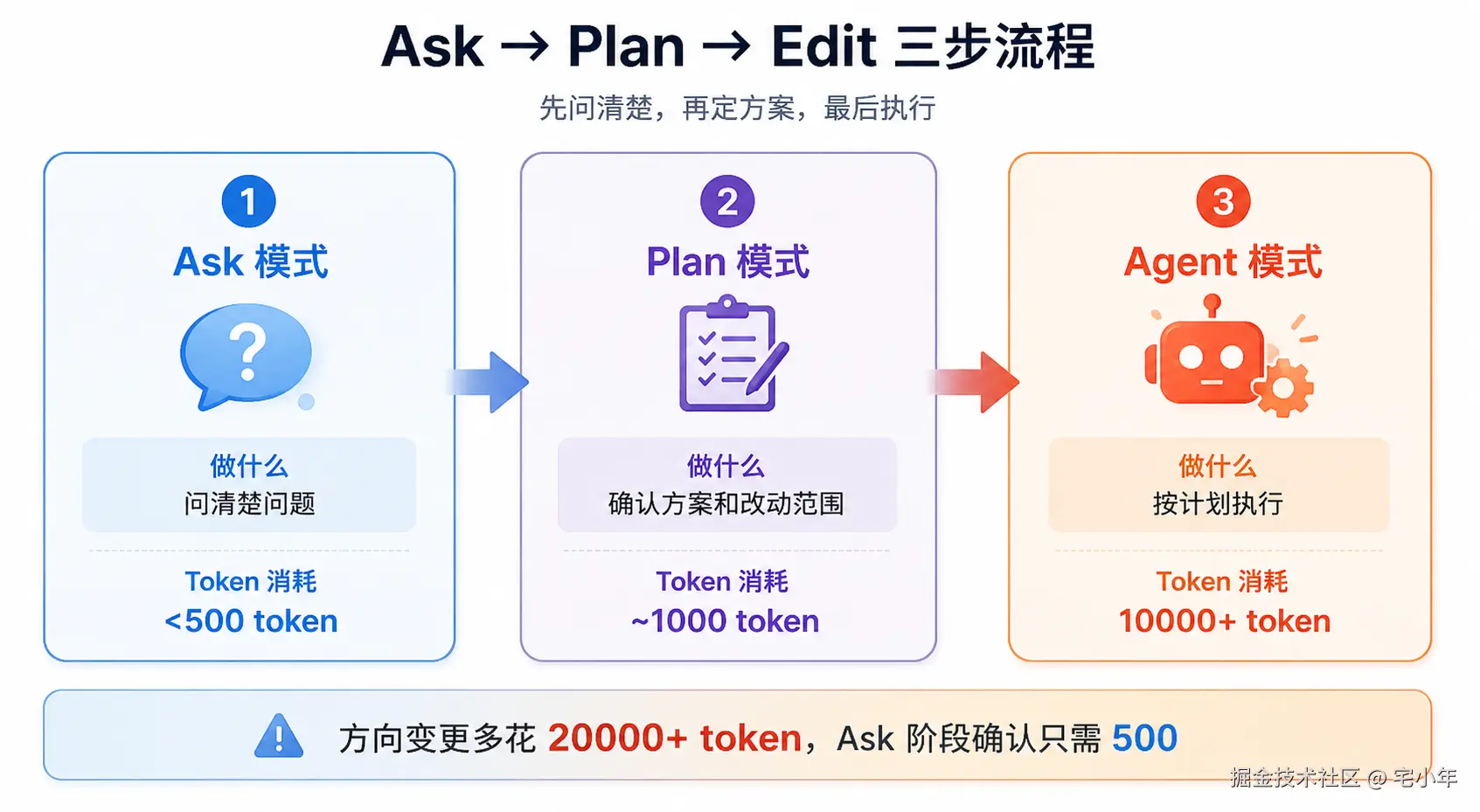
四、黄金工作流 --- Ask → Plan → Edit
这是整篇文章里最值钱的一个框架。记住一句话:
用 Ask 对齐理解,用 Plan 对齐方向,用 Agent 执行确定的事。越晚进入 Agent,浪费的 token 越少。
❌ 反例:还没想清楚就开干
说实话,这个坑我踩得最惨。
我想把用户认证从 JWT 换成 Session,直接在 Agent 里输入需求。Agent 开始读代码→查方案→改数据库模型→改中间件→改登录接口→改前端存储......
做到一半我突然发现,Session 方案需要 Redis,项目环境不支持。
回滚,重来。
💸 直接浪费 20000~30000 token,时间成本 2 小时变 4 小时。
正确姿势
vbnet
Step 1 --- Ask:「当前 JWT 改成 Session 有哪几种方式?需要什么基础设施?」
→ 发现需要 Redis,环境和条件不满足
→ 直接毙掉方案,零 token 浪费
Step 2 --- Ask:「不换 Session,JWT 有什么改良方案?」
→ 得到答案:加 Refresh Token + 黑名单机制
Step 3 --- Plan:列出需要改的文件和步骤 → 审查确认
Step 4 --- Agent:按计划执行修改Ask + Plan 阶段用了不到 1000 token,避免了 20000+ token 的错误执行。
Ask 的隐藏价值
Ask 不只是「问问题」,它本质上是零副作用的上下文探索:
- 不确定改哪个文件 → 先 Ask
- 看不懂某段逻辑 → 先 Ask
- 想知道影响范围 → 先 Ask
- 觉得有 bug 但不确定在哪 → 先 Ask
把所有「不确定」消灭在 Ask 阶段,进入 Edit 时你和模型都已经对齐,一次成功的概率大幅提升。
YOLO 模式:省 token 的激进选项
Agent 每做一步都停下来问「可以创建这个文件吗?」「可以安装依赖吗?」------每次确认都是一轮完整的上下文传递。
有些操作其实风险很低。开启 YOLO 模式后,Agent 自动执行终端命令,省去确认轮次。在 Cursor Settings → Features → Agent 里找到 YOLO mode 开关,打开即可。或者在 Agent 面板输入框旁边的设置齿轮里也能找到。
💡 我的建议: 对可信项目可以开 YOLO,但保留对高风险操作(删表、发生产请求等)的手动确认。能省一半 token。
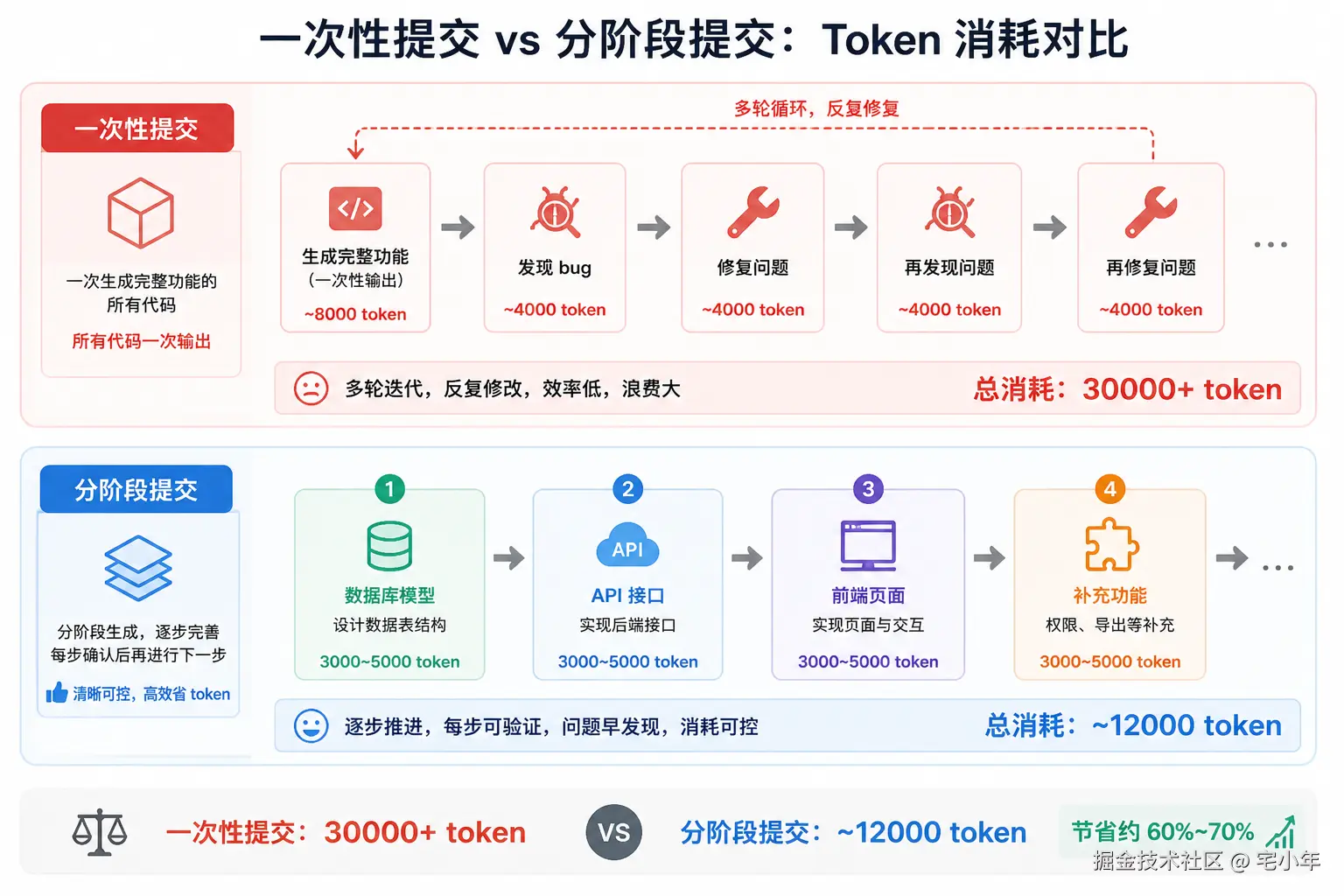
五、任务拆解策略
❌ 反例:一次让模型写完整功能
「帮我实现完整的用户通知系统,包括数据库模型、API 接口、前端页面、WebSocket 实时推送、邮件通知......」
Agent 一次性输出上千行代码。但数据库模型有字段遗漏,前端样式不对,WebSocket 有 bug。开始逐项修复------每修一个问题都要重新载入完整上下文。
💸 初始生成 + 多轮修复,总消耗 2500040000 token。分阶段做只需 1000015000 token。
三段式工作流
把大任务拆成三~四个阶段,每个阶段聚焦一个层次:
yaml
第一轮:生成数据库模型 → 审查 → 确认 ← 5000 token
第二轮:生成 API 接口(基于已确认的模型) ← 4000 token
第三轮:生成前端页面(基于已确认的 API) ← 4000 token
第四轮:WebSocket + 邮件通知补充 ← 3000 token每一轮上下文都聚焦,模型不容易出错,出错了也容易修。
先问方案,再问实现
markdown
第一轮:「文件上传功能有哪几种方案?我们的场景是内网使用、文件不大」
→ 确认方案后
第二轮:「用方案二(MinIO)实现」避免模型一上来就写你不想要的实现。方向调整的 token 浪费最冤枉------之前的代码全白写了。
/multitask 并行子 Agent
2026 年 4 月在 Cursor 3.2 中推出。用法很简单,在 Agent 对话框里直接输入 /multitask 跟上你的请求就行。
有两种工作方式:
方式一:队列积压时并行处理 Agent 窗口里已经排了好几条消息,输入 /multitask,Cursor 会启动多个子 Agent 并行处理,不用一个个排队等。
方式二:大任务自动拆分 提交一个大型任务,系统自动拆成子任务,分配给多个子 Agent 同时干。
适合什么场景:子任务之间相互独立的时候。比如同时改三个不相关的模块、给多个文件加注释、批量重构独立的工具函数。
不适合什么场景:任务之间有先后依赖关系(A 改完才能改 B),并行执行会乱套。
六、Rules 与系统提示优化
Rules 每轮对话都会被注入。写得不好就是永久性的隐形消耗。
❌ 反例:.cursorrules 写了 200 行
见过把团队所有开发规范全写进 Rules 的项目------从「缩进用 2 个空格」到「API 必须用 /api/v1/ 前缀」到「注释要双语」到「组件必须用 Composition API」......200 行。
问题是其中 70% 的规则(比如缩进风格)模型已经默认遵守了。真正改变模型行为的核心规则可能只有 20~30 条。
💸 200 行 ≈ 1000~1500 token 每轮对话。假设每天 30 轮,一个月浪费约 90 万 token。
新版 .cursor/rules/ 目录结构
旧版是单个 .cursorrules 文件,每次对话全部注入。新版支持 .cursor/rules/*.mdc 目录,可以按文件扩展名或目录精准匹配:
bash
.cursor/rules/
├── typescript-rules.mdc # 只在编辑 .ts 文件时注入
├── python-rules.mdc # 只在编辑 .py 文件时注入
├── frontend-rules.mdc # 只在编辑 frontend/ 目录时注入
└── global-rules.mdc # 始终注入(真正需要全局生效的规则)这样做的好处很明显:前端项目不会注入后端规则,Python 文件不会带上 TypeScript 约束。每轮对话只带当前文件需要的规则。
如果你还在用 .cursorrules,建议补充 .cursor/rules/ 目录来做精细化控制,.cursorrules 保留作为全局兜底即可。两者可以共存,不冲突。
建立个人指令缩写词典
把高频的指令模式提炼成缩写,放在 Rules 里。每次写 prompt 就能用两个字母替代一句话,既省 token 又减少拼写偏差。
ini
NE = no explanation, code only
TS = add TypeScript types
ERR = add error handling
SC = single class/file output only七、复用与缓存
❌ 反例:相同的 CRUD 需求反复描述
每次写新的 CRUD 模块都在 Chat 里重新描述一遍需求------「帮我生成 CRUD,字段有 xxx,要分页、搜索、排序」。每次描述方式不一样,模型理解有偏差,输出不一致。
正确做法: 让模型第一次就生成一个「CRUD 代码生成模板」,后续只需 @ 这个模板 + 参数,模型就知道要输出什么格式。
一次投入,永久受益。后续每次生成节省 2000~4000 token。
错误修复时只贴报错
arduino
❌ 差:把整个 600 行文件 @ 进去问为什么报错
✅ 好:
报错:TypeError: Cannot read property 'id' of undefined
位置:src/api/user.ts line 87
相关代码:
const userId = user.id ← 第87行
user 来自:listUsers() 的返回值精准的报错信息 + 关键代码行,让模型直接定位问题,而不是先理解几百行无关代码。
八、核心心智模型
说了这么多技巧,最后总结成几句话,建议你贴在脑子里:
Token 消耗全景速查
| 操作 | 典型消耗 | 一句话原则 |
|---|---|---|
| Tab 补全 | 几乎免费(独立配额) | 小改动用 Tab |
| Cmd+K 选中修改 | 200~500 token | 单函数修改用它 |
| Chat + 精准 @ | 500~2000 token | 单文件逻辑用 Chat |
| Plan 模式 | 500~2000 token | 先计划再执行 |
| Agent 模式 | 5000~20000+ token | 复杂的、确定的再用 |
一句话原则集合
- 上下文是最大变量 :Token 消耗 80% 来自上下文。Agent 自动扫描虽方便,但可能引入大量无关代码。用
@精准指定文件,比靠 Agent 自己猜省很多 - 对话长度复利递增:每轮携带完整历史,第 10 轮成本约是第 1 轮的 10 倍,及时开新 Chat
- Rules 是隐形消耗:每次对话都被注入,精简到只留真正改变行为的规则
- Agent 是最后的手段:单文件改动用 Cmd+K 足够,Agent 留给多文件协同
- Ask → Plan → Edit:越晚进 Agent,浪费越少
把模型当成一个记忆力极强但注意力有限的同事。 你给他的材料越精准,他的注意力越集中,结果越好,消耗越少。堆砌上下文不等于给更多帮助,往往适得其反。
九、Cursor 3 / Composer 2 时代的新变化
2026 年 Cursor 的变化很快,这些新东西值得你关注:
Cursor 3 统一工作区
Cursor 从编辑器变成了「借助智能体构建软件的统一工作区」。Canvas、多根工作区、Worktree(工作树)集成,实质上是在减少你管理上下文的成本。
Composer 2 --- 2026 年的模型升级
2026 年 3 月,Cursor 发布了 Composer 2,这是一个底层模型的大版本升级,不是一种新的交互模式。
几个关键信息:
- 训练方式:首次做了 Continued Pretraining,再用强化学习(RL)在长任务上训练,能处理需要数百步操作的高难度编程任务
- 性能提升:CursorBench 从 44.2(1.5 版)提升到 61.3,SWE-bench Multilingual 从 65.9 提升到 73.7
- 定价 :Standard 版 0.50/M输入、2.50/M 输出;Fast 版 1.50/M输入、7.50/M 输出(智力相同,速度更快,默认使用)
- 用量:个人方案走独立用量池
对你省钱的影响:Composer 2 本身不改变你选哪种模式(Chat/Agent),但它作为底层模型效率更高了,同样的模式消耗可能比以前少。
Cloud Agents
云端持久化运行 Agent,使用独立配额。适合长时间后台任务------比如你睡觉时让 Agent 跑一个大的重构,第二天起来验收。
定价策略
现行方案供参考:Hobby(免费)→ Pro( 20/月)→Pro+(60/月,3 倍配额)→ Ultra($200/月,20 倍配额)。如果你的用量大,Pro+ 的性价比比 Pro 高很多。
如果这篇对你有帮助,欢迎转发给也被 token 困扰的朋友。有踩过其他坑的,欢迎交流补充。