决策树
决策树简介
学习目标
1.理解决策树算法的基本思想
2.知道构建决策树的步骤
【理解】决策树例子
决策树算法是一种监督学习算法,英文是Decision tree。
决策树思想的来源非常朴素,试想每个人的大脑都有类似于if-else这样的逻辑判断,这其中的if表示的是条件,if之后的else就是一种选择或决策。程序设计中的条件分支结构就是if-else结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法。
【知道】决策树简介
决策树是什么?
决策树是一种树形结构,树中每个内部节点表示一个特征上的判断,每个分支代表一个判断结果的输出,每个叶子节点代表一种分类结果
决策树的建立过程:
1.特征选择:选取有较强分类能力的特征。
2.决策树生成:根据选择的特征生成决策树。
3.决策树也易过拟合,采用剪枝的方法缓解过拟合。
ID3决策树
学习目标:
1.理解信息熵的意义
2.理解信息增益的作用
3.知道ID3树的构建流程
【理解】信息熵
ID3 树是基于信息增益构建的决策树.
定义
- 熵在信息论中代表随机变量不确定度的度量。
- 熵越大,数据的不确定性度越高
- 熵越小,数据的不确定性越低
公式:
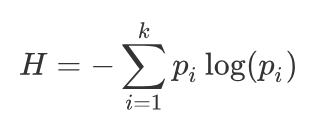
例子1:假如有三个类别,分别占比为:{1/3,1/3,1/3},信息熵计算结果为:
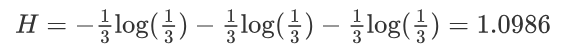
例子2:假如有三个类别,分别占比为:{1/10,2/10,7/10},信息熵计算结果为:
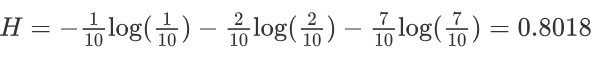
熵越大,表示整个系统不确定性越大,越随机,反之确定性越强。
例子3:假如有三个类别,分别占比为:{1,0,0},信息熵计算结果为:
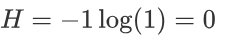
【理解】信息增益
在机器学习中,信息增益(Information Gain, IG) 是决策树算法(特别是 ID3 算法)用于特征选择的核心指标。简单来说,它的核心思想是:"在知道某个特征的信息后,数据的不确定性减少了多少?" 减少得越多,说明这个特征对分类越重要,信息增益也就越大。
定义:信息增益就是"划分前的熵"减去"划分后的熵"。
g(D,A)=H(D)−H(D∣A) \large g(D,A)=H(D)-H(D|A) g(D,A)=H(D)−H(D∣A)
H(D) :原始数据集的熵(分之前的混乱度)。
H(D∣A) :特征 A 的条件熵(分之后的加权平均混乱度)。
g(D,A) :特征 A 带来的信息增益。
举个具体的计算例子
假设我们要预测 "是否去打篮球",现在有一个数据集,共14条记录:
- 9条是 "去" (Yes)
- 5条是 "不去" (No)
我们想计算特征 "天气" 的信息增益
第一步:计算划分前的总熵 H(D)
数据集总共有14个样本
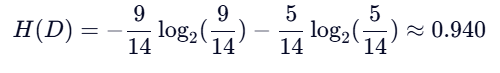
(此时数据比较混乱,熵接近1)
第2步:计算划分后的条件熵H(D|A)
假设"天气"有三个取值:晴、阴、雨

计算加权平均熵(条件熵):
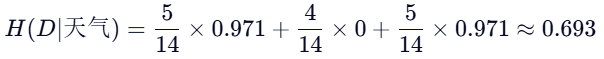
第3步:计算信息增益

**结论:**如果我们知道了"天气"这个信息,分类的不确定性就减少了 0.247。如果另一个特征(比如"湿度")算出来的增益是 0.15,那么我们会优先选择"天气"作为树的根节点,因为它让数据变得更"纯"了。
优缺点与改进 (ID3 vs C4.5)
虽然信息增益很好用,但它有一个著名的缺陷:
| 算法 | 指标 | 缺点/特点 |
|---|---|---|
| ID3 | 信息增益 | 偏好取值多的特征。例如"用户ID"这种特征,每个样本都不一样,分完后纯度极高(熵为0),信息增益最大,但对分类毫无意义(过拟合) |
| C4.5 | 信息增益 | 修正了上述缺点。引入了"分裂信息"作为惩罚项。特征取值越多,惩罚越大。公式为:GainRatio = IG / IV(A) |
总结:
- 信息增益衡量的是确定性的提升。
- 它是 ID3 决策树构建的核心,通过递归选择增益最大的特征来切分数据。
- 在实际应用中(如 Python 的 Scikit-Learn),虽然默认使用的是基尼指(CART 算法,计算更快且效果接近),但理解信息增益对于理解决策树的"分而治之"思想至关重要。
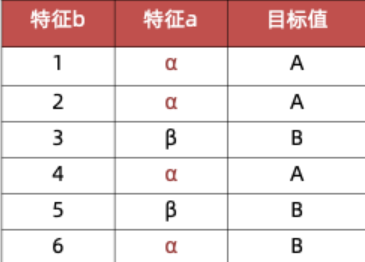
例子:已知6个样本,根据特征a:
| 特征a | 目标值 |
|---|---|
| α | A |
| α | A |
| β | B |
| α | A |
| β | B |
| α | B |
α 部分对应的目标值为: AAAB
β 部分对应的目标值为:BB
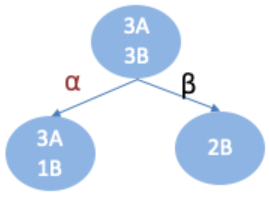
熵 = 数据混乱程度,数据越混乱,熵越大
= -标签列 A分类占比 * log2(A分类占比) + - 标签列 B分类占比 * log2(B分类占比)...
条件熵 = 特征列中A分类占比 * 条件熵 + 特征列中B分类占比 * 条件B的熵...
信息熵 = 熵 - 条件熵
信息增益率 = 信息增益 / 特征熵
特征熵 = -特征列A分类占比 * log2(A分类占比) + -标签列B分类占比 * log2(B分类占比)...
需求:求特征a、b的信息增益率 α β
计算 特征α 的信息增益率:
1.计算 特征α 的信息增益 信息增益 = 熵 - 条件熵
= -3/6 * log2(3/6) * 2 - (4/6 * (-3/4 * log2(3/4) + -1/4 * log2(1/4)) + 2/6 * (-2/2 * log2(2/2)) )
= 1 - 0.54
= 0.46
2.计算 特征α的 特征熵
= -4/6 * log2(4/6) + -2/6 * log2(2/6)
= 0.92
3.计算 信息增益率
信息增益率 = 信息增益 / 特征熵 = 0.46 / 0.92 = 0.5
计算 特征β 的信息增益率:
1.计算 特征β 的信息增益 信息增益 = 熵 - 条件熵
= -3/6 * log2(3/6) * 2 - (1/6 * (-1/1 * log2(1/1))) * 6
= 1
2.计算 特征β的 特征熵
= -1/6 * log2(1/6) * 6
= 2.58
3.计算 信息增益率
信息增益率 = 信息增益 / 特征熵 = 1 / 2.58 = 0.39
结论:特征α的信息增益率大于特征β的信息增益率,根据信息增益,应该选择特征α为分裂特征
【知道】ID3树构建流程
构建流程:
- 计算每个特征的信息增益
- 使用信息增益最大的特征将数据集 S 拆分为子集
- 使用该特征(信息增益最大的特征)作为决策树的一个节点
- 使用剩余特征对子集重复上述(1,2,3)过程
案例:
已知:某一个论坛客户流失率数据
需求:考察性别、活跃度特征哪一个特征对流失率的影响更大
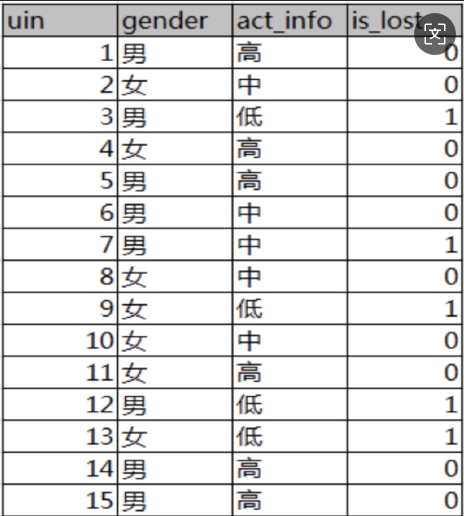
分析:
15条样本:5正样本、10个负样本
- 计算熵
- 计算性别信息增益
- 计算活跃度信息增益
- 比较两个特征的信息增益
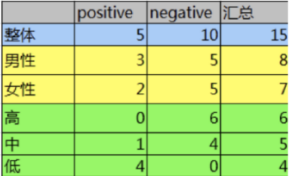
1.计算熵
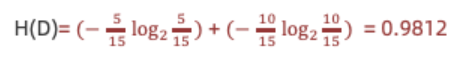
2.计算性别条件熵(a="性别"):
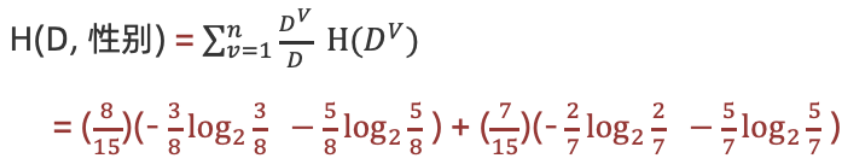
计算性别信息增益(a="性别")
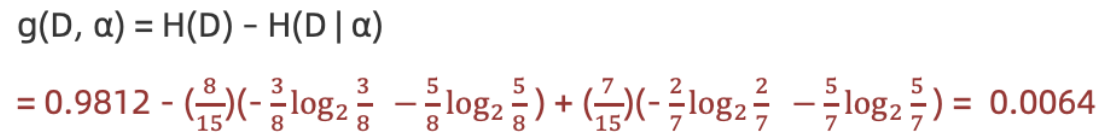
3.计算活跃度条件熵(a="活跃度")
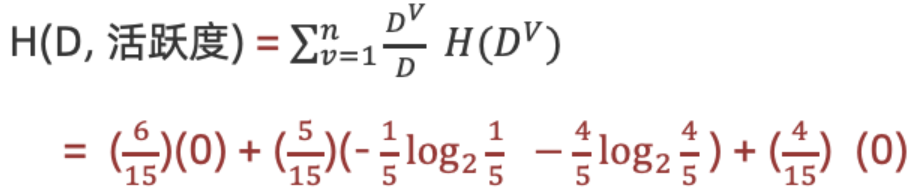
计算活跃度信息增益(a=活跃度")
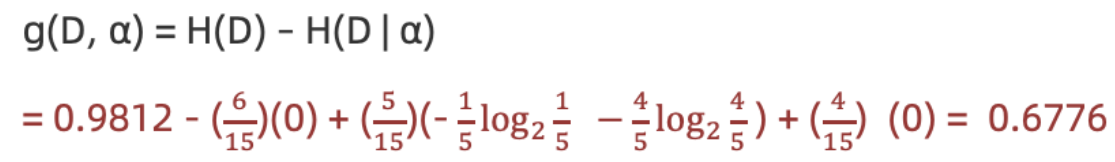
结论 :活跃度的信息增益比性别的信息增益大,对用户流失的影响比性别大。


C4.5决策树
学习目标:
1.理解信息增益率的意义
2.知道C4.5树的构建方法
【理解】信息增益率
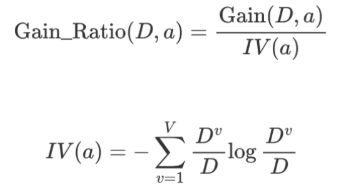
1.Gain_Ratio 表示信息增益率:信息增益 / 特征熵
特征熵 = -特征列 A 分类占比 * log2(A分类占比) + -特征列 B 分类占比 * log2(B分类占比)...
2.IV 表示分裂信息、内在信息
3.特征的信息增益 ➗ 内在信息
-
如果某个特征的特征值种类较多,则其内在信息值就越大。即:特征值种类越多,除以的系数就越大。
-
如果某个特征的特征值种类较小,则其内在信息值就越小。即:特征值种类越小,除以的系数就越小。
信息增益比本质: 是在信息增益的基础之上乘上一个惩罚参数。特征个数较多时,惩罚参数较小;特征个数较少时,惩罚参数较大。惩罚参数:数据集D以特征A作为随机变量的熵的倒数。
【知道】C4.5树构建说明


CART决策树
学习目标:
1.理解基尼指数的作用
2.知道cart构建的特征选择方法
【知道】Cart树简介
Cart模型是一种决策树模型,它即可以用于分类,也可以用于回归。
与ID3、C4.5等算法不同,CART在分类任务中使用基尼指数 (Gini Index) 来选择最优特征,在回归任务中则使用最小化均方误差(MSE)。
【理解】基尼指数计算方法
对于一个包含 K 个类别的节点,其基尼指数计算公式为:
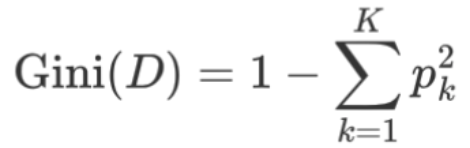
其中,p_k 是第 k 类样本在数据集 D 中的比例。
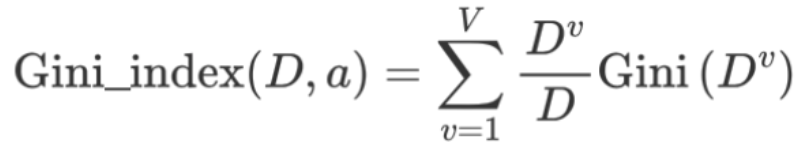
- 信息增益(ID3)、信息增益率值越大(C4.5),则说明优先选择该特征。
- 基尼指数值越小(cart),则说明优先选择该特征。算法会计算每个特征在每个可能切分点分裂后的加权基尼指数,并选择值最小的那个特征和切分点作为最优分裂方案。
CART回归树
回归树的目标是预测一个连续的数值。它使用均方误差(MSE)作为选择最优分裂的标准。
- 均方误差 (MSE)
算法寻找一个切分点,使得分裂后两个子节点的MSE之和最小。MSE衡量的是节点内样本的真实值与该节点预测值(通常是节点内样本的均值)的差异。 - 预测值
回归树的每个叶子节点不再是一个类别,而是该节点内所有样本目标值的平均值。
【理解】基尼指数计算举例
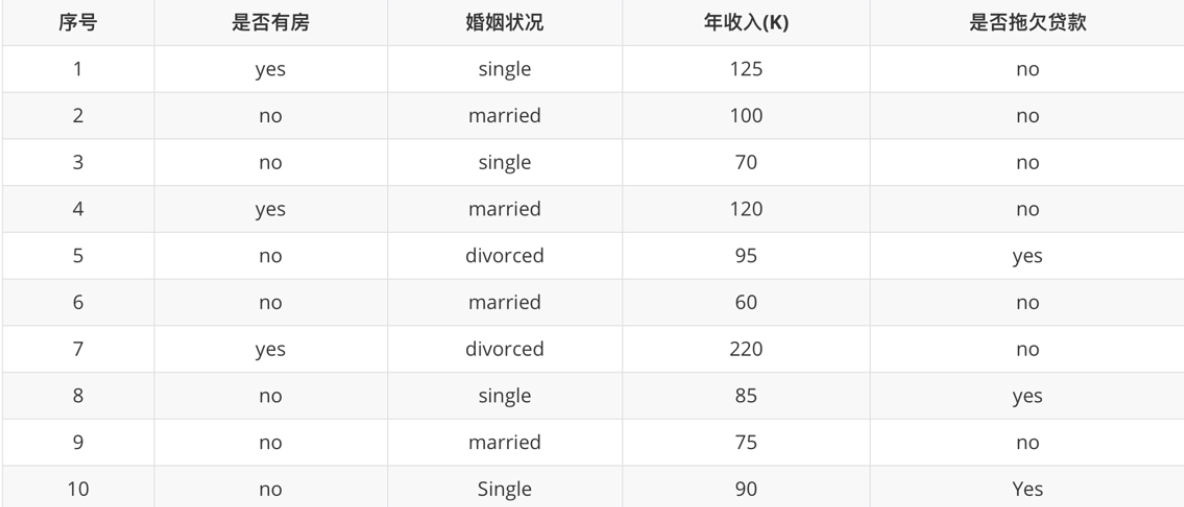
是否有房
计算过程如下:根据是否有房将目标值划分为两部分:
- 计算有房子的基尼值: 有房子有 1、4、7 共计三个样本,对应:3个no、0个yes
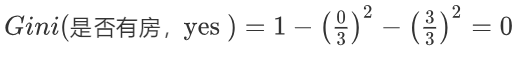
- 计算无房子的基尼值:无房子有 2、3、5、6、8、9、10 共七个样本,对应:4个no、3个yes
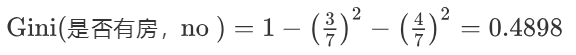
- 计算基尼指数:第一部分样本数量占了总样本的 3/10、第二部分样本数量占了总样本的 7/10:
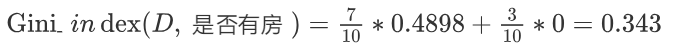
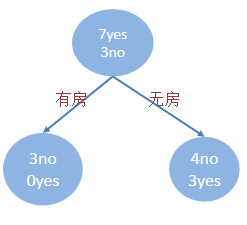
婚姻状况
1.计算 是否有房 的基尼值
有房子的基尼值 = 1 - (0/3)² - (3/3)² = 0
无房子的基尼值 = 1- (3/7)² - (4/7)² = 0.4898
2.计算 是否有房(特征列) 的基尼指数
基尼指数 = 3/10 * 0 + 7/10 * 0.4898 = 0.343
基尼系数(指数) = 分类占比 * 基尼值 累加和
3.计算婚姻状况 的 基尼值 和 基尼指数
因为婚姻状况有 married, single, divorce 三个值,我们对其分类,分别计算:
场景1:{married} 和 {single, divorced}
计算 married 的基尼值 = 1 - (4/4)² = 0
计算{single, divorced} 的基尼值 = 1 - (3/6)² - (3/6)² = 0.5
最终,基尼值 = married占比 * married的基尼值 + 非married占比 * 非married的基尼值 = 4/10 * 0 + 6 / 10 * 0.5 = 0.3
场景2:{single} 和 {married, divorced} = 0.367
场景3:{divorced} 和 {married, single} = 0.4
最终:该特征的基尼值为0.3,并且预选分裂点为:{married} 和 {single, divorced}
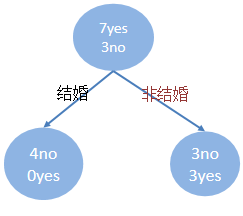
4.计算 年收入特征列 的基尼指数
(1) 先将数值型属性升序排列,以相邻中间值作为待确定分裂点
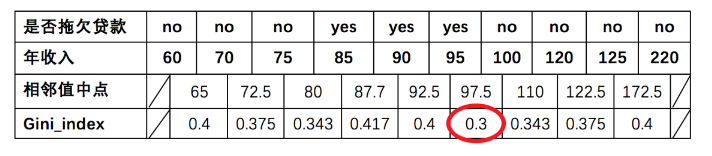
待确定的分裂点为:65,72.5,80,87.7,92.5,97.5,110,122.5,172.5
(2) 以年收入 65 将样本分为两部分,计算基尼指数,节点65时:
{年收入} = 1/10 * 0 + 9/10 * 1-(6/9)² - (3/9)² = 0.4
(3) 以此类推计算所有分割点的基尼指数,最小的基尼指数为0.3
第一轮结果:
以是否有房作为分裂点的基尼指数为:0.343
以婚姻状况为分裂特征、以married作为分裂点的基尼指数为:0.3
以年收入作为分裂特征、以97.5作为分裂点的基尼指数为:0.3
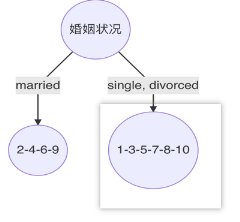
根据奥卡姆剃刀原则以婚姻状况作为根节点,开始构建决策树。
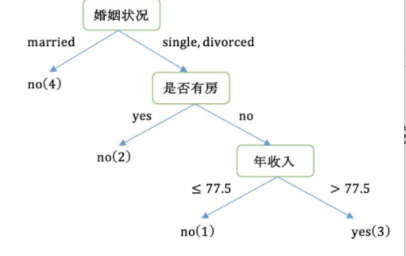
第二轮结果:
1.样本2、4、6、9样本的类别都是no,已经达到最大纯度,所以该节点不需要再继续分裂
2.样本1、3、5、7、8、10样本中仍然包含4个no,2个yes,该节点并未达到要求的纯度,需要继续划分
3.右子树的数据集变为:1、3、5、7、8、10,在该数据集中计算不同特征的基尼指数,选择基尼指数最小的特征继续分裂
重复上述过程,直到构建完成整个决策树
| 名称 | 提出时间 | 分支方式 | 特点 |
|---|---|---|---|
| ID3 | 1975 | 信息增益 | 1.ID3只能对离散属性的数据集构成决策树 2.倾向于选择取值较多的属性 |
| C4.5 | 1993 | 信息增益率 | 1.缓解了ID3分支过程中总喜欢偏向选择值较多的属性 2.可处理连续数值型属性,也增加了对缺失值的处理方法 3.只适合于能够驻留于内存的数据集,大数据集无能为力 |
| CART | 1984 | 基尼指数 | 1.可以进行分类和回归,可处理离散属性,也可以处理连续属性 2.采用基尼指数,计算量减小 3.一定是二叉树 |
【实践】泰坦尼克号生存案例
数据集:泰坦尼克号 --> 阿里天池
案例背景
泰坦尼克号沉没是历史上最著名的沉船事件。1912年4月15日,在她的处女航中,泰坦尼克号在与冰山相撞后沉没,在2224名乘客和船员中造成1502人死亡。这场耸人听闻的悲剧震惊了国际社会,并为船舶制定了更好的安全规定。 造成海难失事的原因之一是乘客和船员没有足够的救生艇。尽管幸存下来有一些运气因素,但有些人比其他人更容易生存,例如妇女,儿童和社会地位较高的人群。 在这个案例中,我们要求您完成对哪些人可能存活的分析。
数据集中的特征包括票的类别,是否存活,乘坐班次,姓名,年龄,上船港口,房间,性别等。

API介绍
class sklearn.tree.DecisionTreeClassifier(criterion='gini', max_depth=None,random_state=None)
- criterion
- 特征选择标准
- "gini"或者"entropy",前者代表基尼系数,后者代表信息增益。一默认"gini",即CART算法。
- min_samples_split
- 内部节点再划分所需最小样本数
- 这个值限制了子树继续划分的条件,如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分。 默认是2.如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。我之前的一个项目例子,有大概10万样本,建立决策树时,我选择了min_samples_split=10。可以作为参考。
- min_samples_leaf
- 叶子节点最少样本数
- 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 默认是1,可以输入最少的样本数的整数,或者最少样本数占样本总数的百分比。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。之前的10万样本项目使用min_samples_leaf的值为5,仅供参考。
- max_depth
- 决策树最大深度
- 决策树的最大深度,默认可以不输入,如果不输入的话,决策树在建立子树的时候不会限制子树的深度。一般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间
- random_state
- 随机数种子
案例实现
相比其他学习模型,决策树在模型描述上有巨大的优势,决策树的逻辑推断非常直观,具有清晰的可解释性,也有很方便的模型的可视化。在决策树的使用中,无需考虑对数据量化和标准化,就能达到比较好的识别率。
回归决策树
学习目标:
1.了解回归决策树的构建原理
2.能利用回归决策树API解决问题
【了解】回归决策树构建原理
CART 回归树和 CART 分类树的不同之处在于:
- CART 分类树预测输出的是一个离散值,CART 回归树预测输出的是一个连续值。
- CART 分类树使用基尼指数作为划分、构建树的依据,CART 回归树使用平方损失。
- 分类树使用叶子节点里出现更多次数的类别作为预测类别,回归树则采用叶子节点里均值作为预测输出
CART 回归树构建:
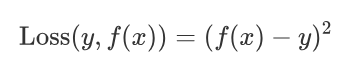
例子:
假设:数据集只有 1 个特征 x, 目标值值为 y,如下图所示:
| x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| y | 5.56 | 5.7 | 5.91 | 6.4 | 6.8 | 7.05 | 8.9 | 8.7 | 9 | 9.05 |
分析 :因只有1个特征,所以只需选择该特征的最优划分点,并不需要计算其他特征
1.先将特征x的值排序,并取相邻元素均值作为待划分点,如下图所示:

2 计算每一个划分点的平方损失,例如:划分点1.5的平方损失计算过程为:
(1) R1为小于1.5的样本个数,样本数量为1,其输出值为:5.56
R1 = 5.56
(2) R2为大于1.5的样本个数,样本数量为9,其输出值为:
R2 = (5.7 + 5.91 + 6.4 + 6.8 + 7.05 + 8.9 + 8.7 + 9 + 9.05) / 9 = 7.50
(3) 该划分点的平方损失:
L(1.5) = (5.56 - 5.56)² + (5.7 - 7.5)² + (5.91 - 7.5)² + ... + (9.05 - 7.5)² = 0 + 15.72 = 15.72
3.以此方式计算2.5、3.5...等划分点的平方损失,结果如下所示:
| s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 | 9.5 |
|---|---|---|---|---|---|---|---|---|---|
| m(s) | 15.72 | 12.07 | 8.36 | 5.78 | 3.91 | 1.93 | 8.01 | 11.73 | 15.74 |
4.当划分点s = 6.5时,m(s)最小。因此,第一个划分变量:特征为x,切分点为6.5,即:j = x, s = 6.5
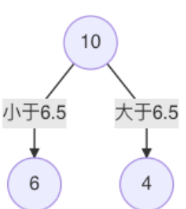
5.对左子树的6个结点计算每个划分点的平方式损失,找出最优划分点:
| x | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| y | 5.56 | 5.7 | 5.91 | 6.4 | 6.8 | 7.05 |
| s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 |
|---|---|---|---|---|---|
| c1 | 5.56 | 5.63 | 5.72 | 5.89 | 6.07 |
| c2 | 6.37 | 6.54 | 6.75 | 6.93 | 7.05 |
| s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 |
|---|---|---|---|---|---|
| m(s) | 1.3087 | 0.754 | 0.2771 | 0.4368 | 1.0644 |
6.s = 3.5时,m(s)最小,所以左子树继续以3.5进行分裂:
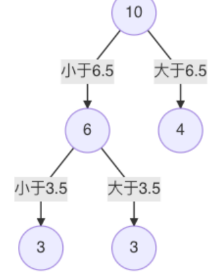
7.假设在生成3个区域之后停止划分,以上就是回归树。每一个叶子节点的输出为:挂在该节点上的所有样本均值。
| x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| y | 5.56 | 5.7 | 5.91 | 6.4 | 6.8 | 7.05 | 8.9 | 8.7 | 9 |
1号样本真实值 5.56 预测结果:5.72
2号样本真实值是 5.7 预测结果:5.72
3 号样本真实值是 5.91 预测结果 5.72
CART 回归树构建过程如下:
1.选择第一个特征,将该特征的值进行排序,取相邻点计算均值作为待划分点
2.根据所有划分点,将数据集分成两部分:R1、R2
3.R1 和 R2 两部分的平方损失相加作为该切分点平方损失
4.取最小的平方损失的划分点,作为当前特征的划分点
5.以此计算其他特征的最优划分点、以及该划分点对应的损失值
6.在所有的特征的划分点中,选择出最小平方损失的划分点,作为当前树的分裂点
【实践】回归决策树实践
已知数据:
| x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| y | 5.56 | 5.7 | 5.91 | 6.4 | 6.8 | 7.05 | 8.9 | 8.7 | 9 | 9.05 |
分别训练线性回归、回归决策树模型,并预测对比
训练模型,并使用1000个0.0, 10之间的数据,让模型预测,画出预测值图线
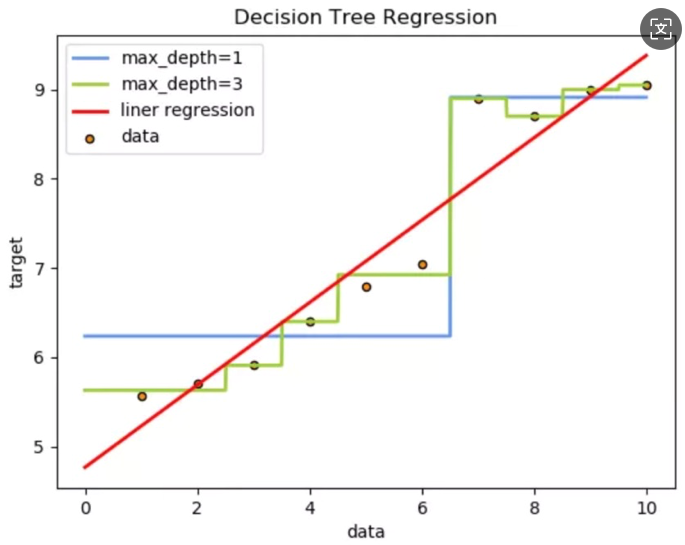
从预测效果来看:
1、线性回归是一条直线
2、决策树是曲线
3、树的拟合能力是很强的,易过拟合
决策树剪枝
学习目标:
1.知道什么是剪枝
2.理解剪枝的作用
3.知道常用剪枝方法
4.了解不同剪枝方法的优缺点
【知道】什么是剪枝?
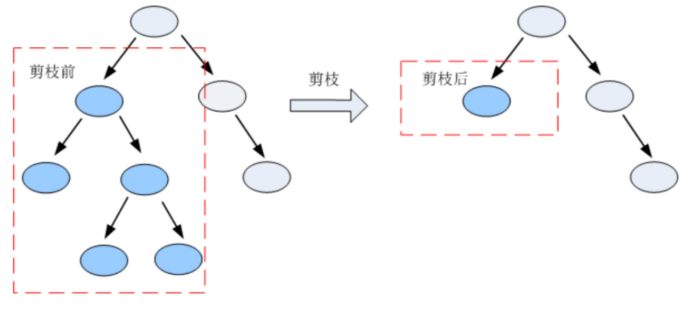
剪枝 (pruning)是决策树学习算法对付 过拟合 的主要手段。
在决策树学习中,为了尽可能正确分类训练样本,结点划分过程将不断重复,有时会造成决策树
分支过多,这时就可能因训练样本学得"太好"了,以致于把训练集自身的一些特点当作所有数据
都具有的一般性质而导致过拟合。因此,可通过主动去掉一些分支来降低过拟合的风险。剪枝是指将一颗子树的子节点全部删掉,利用叶子节点替换子树(实质上是后剪枝技术),也可以(假定当前对以root为根的子树进行剪枝)只保留根节点本身而删除所有的叶子,以下图为例:
【知道】常见减枝方法汇总
决策树剪枝的基本策略有"预剪枝" (pre-pruning)和"后剪枝"(post- pruning) 。
1.预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点;
2.后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
【理解】例子
在构建树时, 为了能够实现剪枝, 可预留一部分数据用作 "验证集" 以进行性能评估。我们的训练集如下:
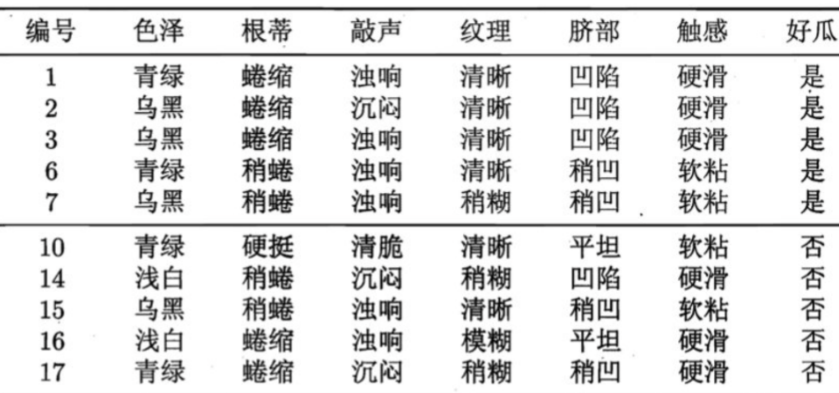
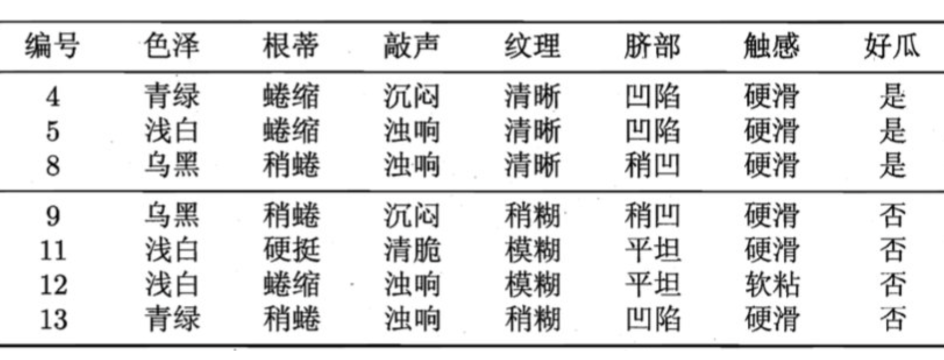
验证集如下:
预剪枝
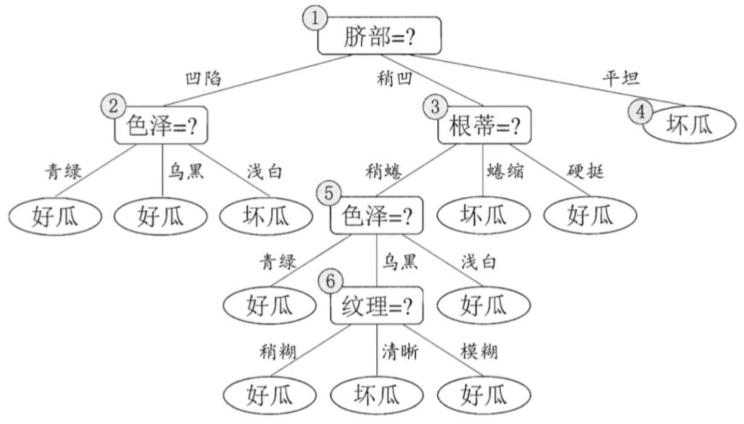
1.假设: 当前树只有一个结点, 即编号为1的结点. 此时, 所有的样本预测类别为: 其类别标记为训练样例数最多的类别,假设我们将这个叶结点标记为 "好瓜"。此时, 在验证集上所有的样本都会被预测为 "好瓜", 此时的准确率为: 3/7
2.如果进行此次分裂, 则树的深度为 2, 有三个分支. 在用属性"脐部"划分之后,上图中的结点2、3、4分别包含编号为 {1,2,3, 14}、 {6,7, 15, 17}、 {10, 16} 的训练样例,因此这 3 个结点分别被标记为叶结点"好瓜"、 "好瓜"、 "坏瓜"。此时, 在验证集上 4、5、8、11、12 样本预测正确,准确率为: 5/7。很显然, 通过此次分裂准确率有所提升, 值得分裂.
3.接下来,对结点2进行划分,基于信息增益准则将挑选出划分属性"色泽"。然而,在使用"色泽"划分后,编号为 {5} 的验证集样本分类结果会由正确转为错误,使得验证集精度下降为 57.1%。于是,预剪枝策略将禁止结点2被划分。
4.对结点3,最优划分属性为"根蒂",划分后验证集精度仍为 5/7. 这个 划分不能提升验证集精度,于是,预剪枝策略禁止结点3被划分。
5.对结点4,其所含训练样例己属于同一类,不再进行划分.
于是,基于预剪枝策略从上表数据所生成的决策树如下图所示,其验证集精度为 71.4%. 这是一棵仅有一层划分的决策树。
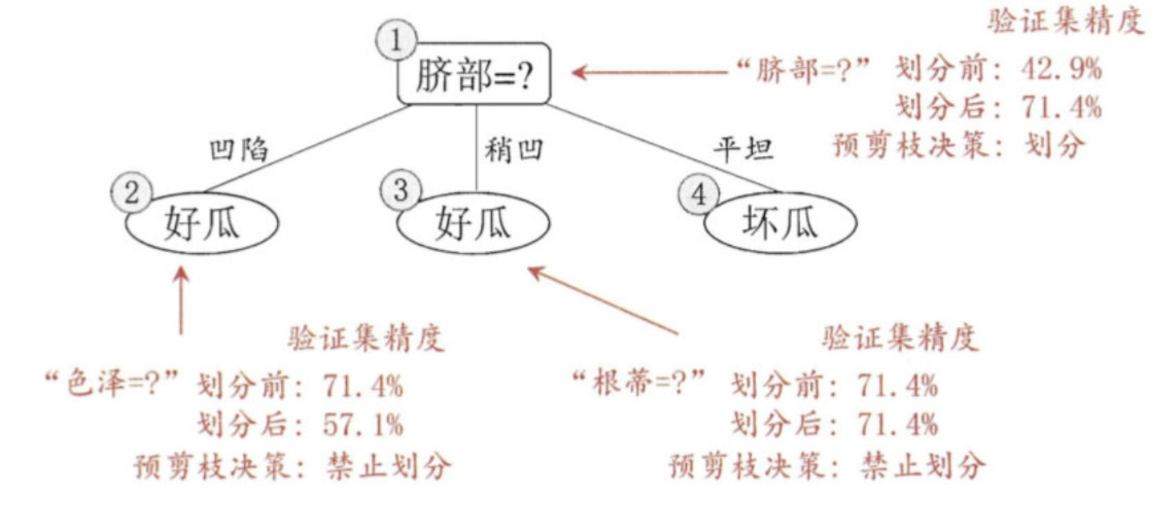
后剪枝
后剪枝先从训练集生成一棵完整决策树,继续使用上面的案例,从前面计算,我们知前面构造的决策树的验证集精度为42.9%。
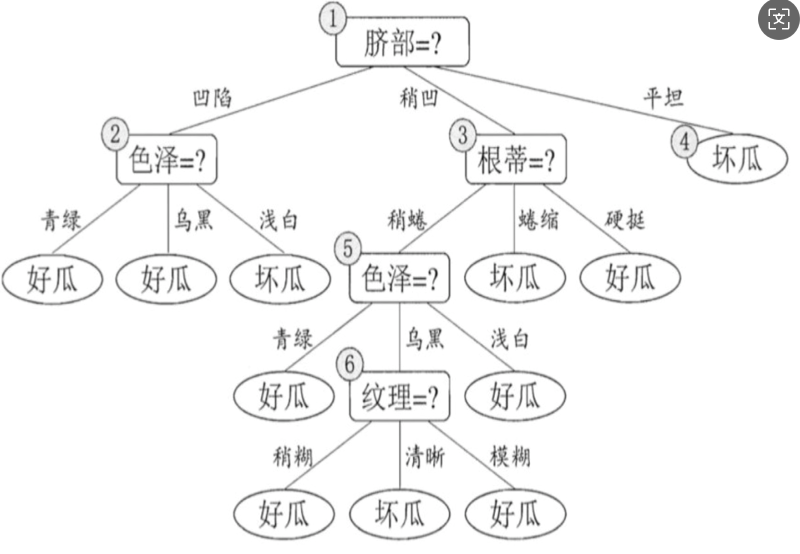
1.首先考察结点6,若将其领衔的分支剪除则相当于把6替换为叶结点。替换后的叶结点包含编号为 {7, 15} 的训练样本,于是该叶结点的类别标记为"好瓜", 此时决策树的验证集精度提高至 57.1%。
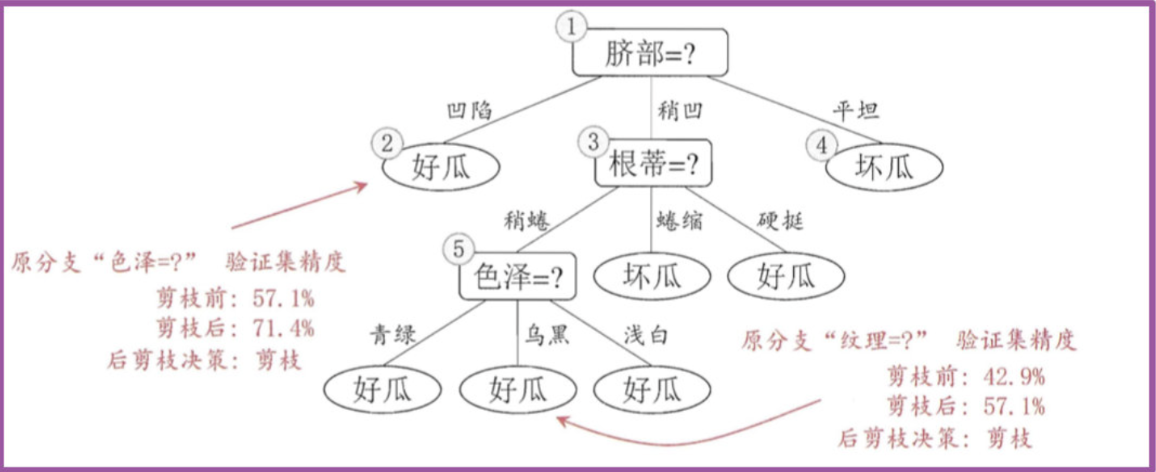
2.然后考察结点5,若将其领衔的子树替换为叶结点,则替换后的叶结点包含编号为 {6,7,15}的训练样例,叶结点类别标记为"好瓜';此时决策树验证集精度仍为 57.1%. 于是,可以不进行剪枝.
3.对结点2,若将其领衔的子树替换为叶结点,则替换后的叶结点包含编号 为 {1, 2, 3, 14} 的训练样例,叶结点标记为"好瓜"此时决策树的验证集精度提高至 71.4%. 于是,后剪枝策略决定剪枝.
4.对结点3和1,若将其领衔的子树替换为叶结点,则所得决策树的验证集 精度分别为 71.4% 与 42.9%,均未得到提高,于是它们被保留。
5.最终, 基于后剪枝策略生成的决策树如上图所示, 其验证集精度为 71.4%。
【了解】剪枝方法对比
预剪枝优点:
- 预剪枝使决策树的很多分支没有展开,不单降低了过拟合风险,还显著减少了决策树的训练、测试时间开销
预剪枝缺点:
- 有些分支的当前划分虽不能提升泛化性能,甚至会导致泛化性能降低,但在其基础上进行的后续划分却有可能导致性能的显著提高
- 预剪枝决策树也带来了欠拟合的风险
后剪枝优点:
- 比预剪枝保留了更多的分支。一般情况下,后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝
后剪枝缺点:
- 但后剪枝过程是在生成完全决策树之后进行的,并且要自底向上地对树中所有非叶子节点进行逐一考察,因此在训练时间开销比未剪枝的决策树和预剪枝的决策树都要大得多。
作业
1.下面以常用的贷款申请样本数据表为样本集,计算信息增益计算过程,并构建ID3决策树。
| ID | 年龄 | 有工作 | 有房子 | 信贷情况 | 类别 |
|---|---|---|---|---|---|
| 1 | 青年 | 否 | 否 | 一般 | 拒绝 |
| 2 | 青年 | 否 | 否 | 好 | 拒绝 |
| 3 | 青年 | 是 | 否 | 好 | 同意 |
| 4 | 青年 | 是 | 是 | 一般 | 同意 |
| 5 | 青年 | 否 | 否 | 一般 | 拒绝 |
| 6 | 中年 | 否 | 否 | 一般 | 拒绝 |
| 7 | 中年 | 否 | 否 | 好 | 拒绝 |
| 8 | 中年 | 是 | 是 | 好 | 同意 |
| 9 | 中年 | 否 | 是 | 非常好 | 同意 |
| 10 | 中年 | 否 | 是 | 非常好 | 同意 |
| 11 | 老年 | 否 | 是 | 非常好 | 同意 |
| 12 | 老年 | 否 | 是 | 好 | 同意 |
| 13 | 老年 | 是 | 否 | 好 | 同意 |
| 14 | 老年 | 是 | 否 | 非常好 | 同意 |
| 15 | 老年 | 否 | 否 | 一般 | 拒绝 |
2.说明CART分类树和回归树的特点,并说明构建过程
3.说明决策树剪枝的方法有哪些?及各自的特点是什么?