冯诺依曼体系结构
我们常⻅的计算机,如笔记本。我们不常⻅的计算机,如服务器,⼤部分都遵守冯诺依曼体系。
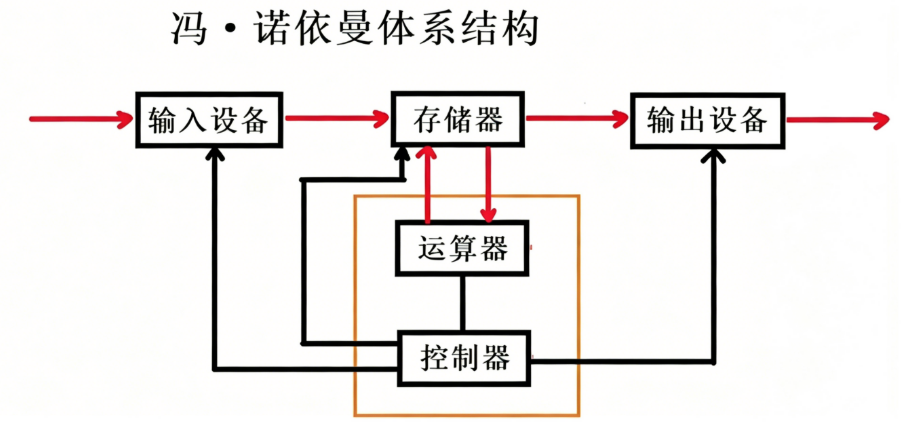 截⾄⽬前,我们所认识的计算机,都是由⼀个个的硬件组件组成
截⾄⽬前,我们所认识的计算机,都是由⼀个个的硬件组件组成
• 输⼊单元:包括键盘,⿏标,扫描仪,写板等
• 中央处理器(CPU):含有运算器(ALU)和控制器(CU)等
• 输出单元:显⽰器,打印机等
• 存储器:内存(RAM)
关于冯诺依曼,必须强调⼏点:
• 这⾥的存储器指的是内存
• 不考虑缓存情况,这⾥的CPU能且只能对内存进⾏读写,不能访问外设(输⼊或输出设备)(数据层⾯)
• 外设(输⼊或输出设备)要输⼊或者输出数据,也只能写⼊内存或者从内存中读取。
• ⼀句话,所有设备都只能直接和内存打交道
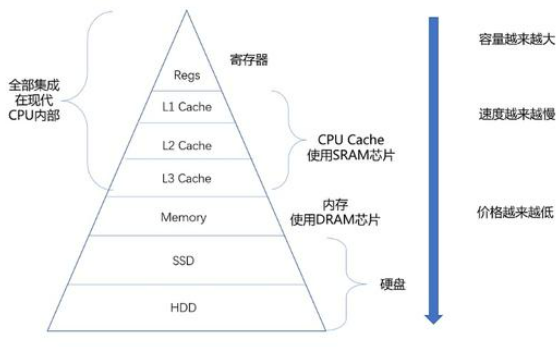
木桶效应
大家应该都听过经典的木桶原理:一只木桶能装多少水,不取决于最长的那块木板,而取决于最短的那一块。
其实这个道理,放在计算机体系里,体现得淋漓尽致。

在计算机五大核心组成中:运算器、控制器、存储器、输入设备、输出设备。其中运算器、控制器(CPU) 运算速度极快,是整台电脑里性能最强、效率最高的硬件,相当于木桶里最长的木板。
但反观存储器、输入、输出设备,读写速度、响应速度远远跟不上 CPU 的处理节奏,成了整个系统里的「短板」。
这就是计算机世界里的木桶效应:
✅ 计算机整体运行性能,不会被高性能的 CPU 拉高上限;
❌ 反而会被速度慢的内存、硬盘、外设死死限制,拖慢整体效率。
哪怕你的处理器再强悍、运算处理能力再强,一旦内存不足、机械硬盘读写缓慢,或是外设响应迟钝,CPU 就只能被迫等待,大量性能被白白闲置,整机照样卡顿、运行缓慢。
计算机系统的综合性能,由最慢的部件决定,强弱硬件无法互补,短板才是真正的性能天花板。
操作系统(OperatorSystem)
概念
任何计算机系统都包含⼀个基本的程序集合,称为操作系统(OS)。
笼统的理解,操作系统包括:
•内核(进程管理,内存管理,⽂件管理,驱动管理)
• 其他程序(例如函数库,shell程序等等)
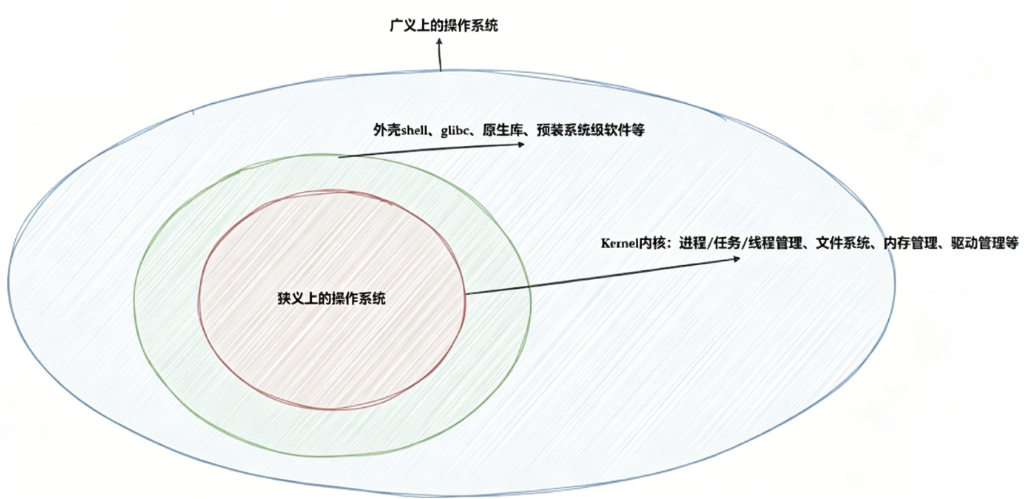
设计OS的⽬的
操作系统旨在统一管理计算机软硬件资源 ,屏蔽硬件细节,为用户和应用程序提供便捷、高效、安全的运行与服务环境。
• 对下,与硬件交互,管理所有的软硬件资源
• 对上,为⽤⼾程序(应⽤程序)提供⼀个良好的执⾏环境
操作系统结构图
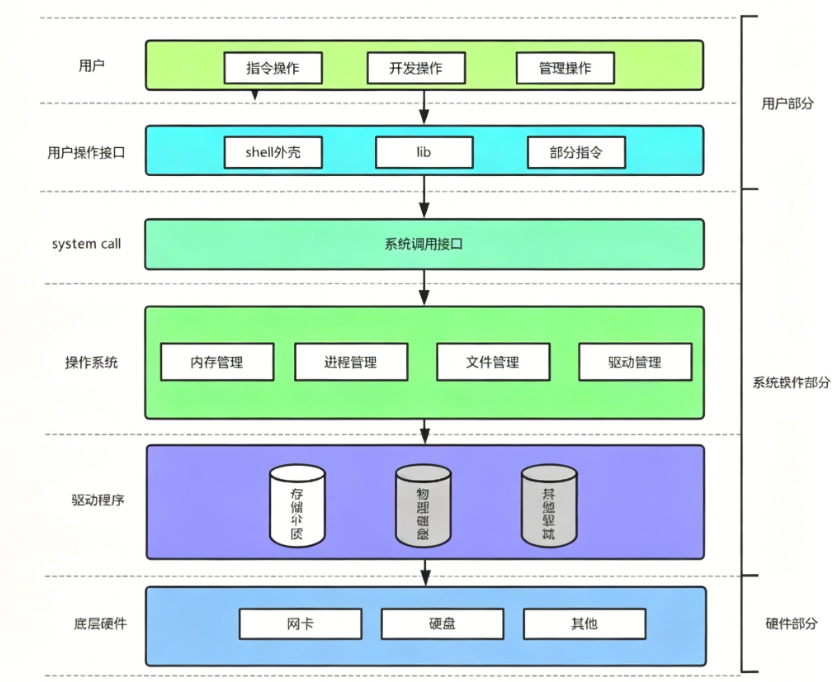
理解操作系统
在整个计算机软硬件架构中,操作系统的定位是:⼀款纯正的搞"管理"的软件。
如何理解"管理"
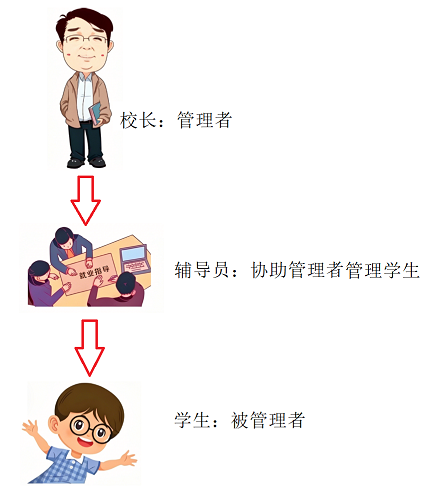
我们用一个比喻:用户(程序员)、操作系统、硬件
- 用户 / 程序员 = 校长
- 操作系统 = 辅导员
- 底层硬件(CPU、内存、硬盘) = 学生
管理的过程:
-
要管理,管理者和被管理者,可以不需要见面你(用户 / 程序员)写代码、敲命令,根本不用直接和硬盘、CPU 这些硬件打交道。你只需要告诉操作系统 "我要读写文件、运行程序" 就行。
-
**管理者和被管理者,怎么管理呢?根据 "数据" 进行管理!**你想存文件,操作系统就帮你把数据存到硬盘上;你想运行程序,操作系统就帮你分配内存、调度 CPU。你不用知道硬盘的磁头怎么转、CPU 怎么调度,只需要关心你得到的结果。
-
**不需要见面,如何得到数据?由中间层获取!**操作系统就是那个 "中间层":
- 你要读文件 → 操作系统帮你去硬盘取数据,再给你
- 你要运行程序 → 操作系统帮你调度 CPU 和内存,再告诉你结果
再来看这个比喻:
校长(你)要管理学生(硬件),但学生太多、太底层,校长管不过来,也没必要管细节。于是有了辅导员(操作系统):
- 辅导员帮校长管学生的出勤、成绩、纪律
- 校长只需要告诉辅导员 "统计成绩、安排课程",不用直接管每个学生
- 学生只听辅导员的指令,不会直接被校长指挥
在计算机里:
- 校长(用户 / 程序员):你,只负责提需求
- 辅导员(操作系统):帮你管 CPU、内存、硬盘,把你的需求翻译成硬件能懂的指令
- 学生(底层硬件):CPU、内存、硬盘,只听操作系统的调度
所以你看:操作系统就是那个帮你管硬件的 "辅导员",让你不用直接面对复杂的硬件细节,只需要关心自己的业务逻辑就行。
校长(程序员 ),通过传递消息(系统调用接口 ),要求辅导员(操作系统 )获取学生(硬件)的数据
然而一个学生身上会有很多的属性:名字,性别,学号,出生日期......
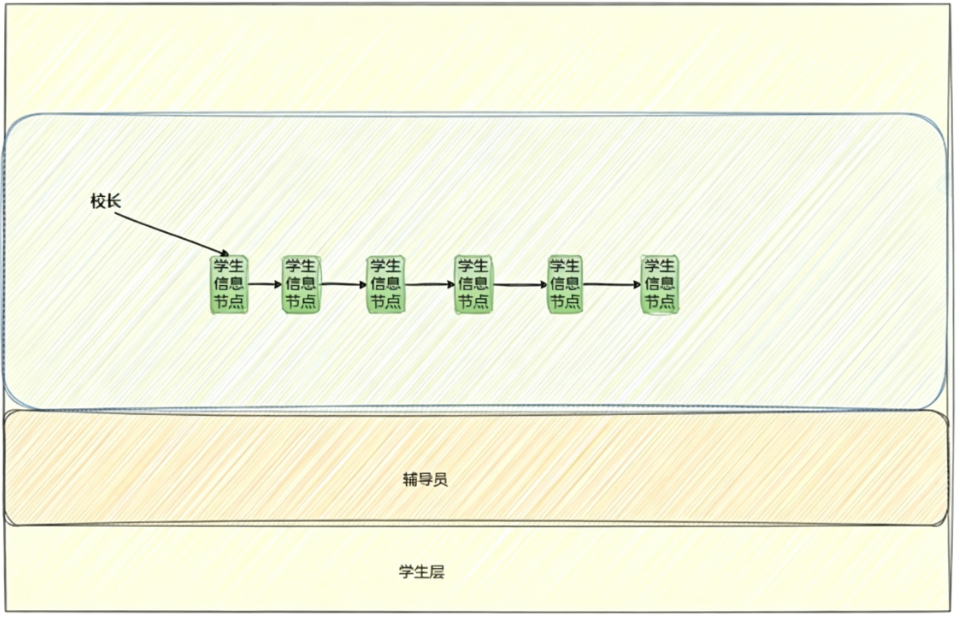
每个学生都具有这些属性,因此学校可以统一管理这些属性,就可以利用结构体:
cpp
struct student
{
string name;//名字
int sex;//性别
string date;//出生日期
string code;//学号
.......
}这就是->先描述,再组织(贯穿整个操作系统);
通过特定的数据结构描述来一个对象的属性,然后组织在一起进行管理;
校长就将对学生的管理,转换到了对数据结构的管理和对数据结构的增删查改;
对应到操作系统中,一切皆文件,所有的硬件都有其属性。以此有了一个个的数据结构,操作系统就从对硬件的管理转移到了对数据结构的管理。
系统调⽤和库函数概念
1. 系统调用(System Call)
就像你直接给辅导员发指令,是你(用户)和操作系统内核之间的「直接对话」。
- 本质:用户态进入内核态的接口,是操作系统内核提供给用户程序的「原生服务」
- 特点 :
- 由操作系统内核直接实现,最底层、最直接
- 开销大:每次调用都要从用户态切换到内核态,有性能成本
- 例子 :
open()、read()、write()、fork()等,都是直接向操作系统内核发起请求。
2. 库函数(Library Function)
就像你通过班干部转达给辅导员,是对系统调用的「封装和包装」,让你用起来更方便。
- 本质:运行在用户态的一段代码,很多库函数内部会封装调用系统调用
- 特点 :
- 对系统调用做了简化、增强或组合,提供更友好的接口
- 不一定每次都陷入内核,性能开销更小(比如字符串处理函数
strlen()完全在用户态完成)
- 例子 :C 标准库的
fopen()、fread()、printf(),内部会调用open()、read()、write()等系统调用,但给你做了缓存、格式化等额外处理。
两者关系一句话总结
**库函数是 "包装好的便利工具",系统调用是 "内核提供的原生服务"。**大部分库函数都是对系统调用的封装,但也有库函数完全不依赖系统调用,系统调用不可移植,而库函数是可移植的。
进程
进程的基本概念
- 课本概念:程序的一个执行实例,正在执行的程序等
- 内核观点:担当分配系统资源(CPU时间,内存)的实体。
进程=内核数据结构(PCB)+自己的程序代码和数据
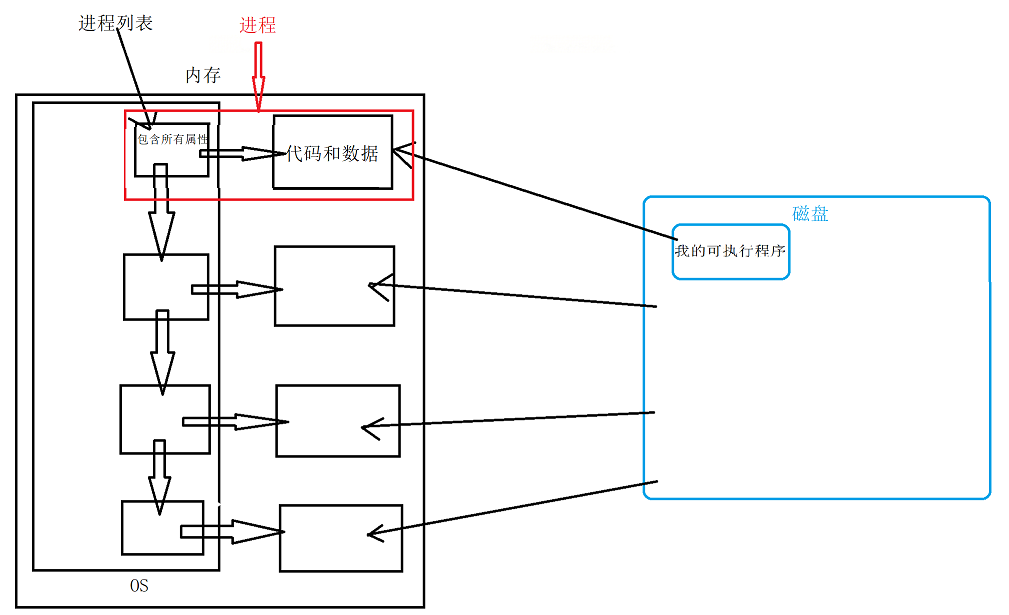
• 系统中有成百上千个进程,操作系统必须将这些进程管理起来,管理方式为:先描述,再组织;
• 操作系统管理你进程,只需要管理对应的数据结构即可;因此这样的数据结构就是PCB;
• 管理并不是管理你的数据,是管理当前进程的task_struct结构体。
描述进程-PCB
基本概念
• 进程信息被放在⼀个叫做进程控制块的数据结构中,可以理解为进程属性的集合。
• 课本上称之为PCB(processcontrolblock), Linux 操作系统下的 PCB 是:task_struct
task_struct-PCB的一种
• 在 Linux 中描述进程的结构体叫做 task_struct 。
• task_struct 是 Linux内核的⼀种数据结构类型,它会被装载到RAM(内存)⾥并且包含着进程的信息。
一个进程的属性
• 标⽰符:描述本进程的唯⼀标⽰符,⽤来区别其他进程。
• 状态:任务状态,退出代码,退出信号等。
• 优先级:相对于其他进程的优先级。
• 程序计数器:程序中即将被执⾏的下⼀条指令的地址。
• 内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
• 上下⽂数据:进程执⾏时处理器的寄存器中的数据休学例⼦,要加图CPU,寄存器。
• I∕O状态信息:包括显⽰的I/O请求,分配给进程的I∕O设备和被进程使⽤的⽂件列表。
• 记账信息:可能包括处理器时间总和,使⽤的时钟数总和,时间限制,记账号等。
• 其他信息......
查看进程
- 进程的信息可以通过 如 /proc 系统⽂件夹查看
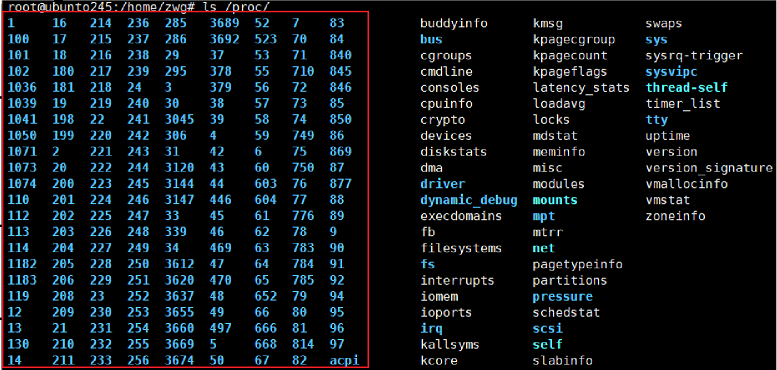
- ⼤多数进程信息同样可以使⽤top和ps这些⽤⼾级⼯具来获取
cpp
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
while(1)
{
sleep(1);
}
return 0;
}
进程的ID
每个进程都有其ID,这个就是PID,其父进程的ID是PPID。
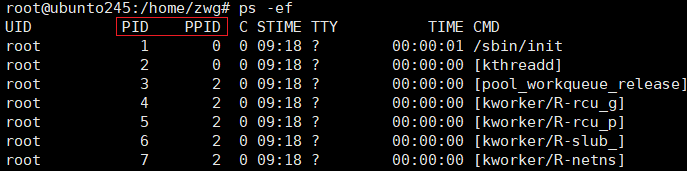
ps命令
ps 是 process status 的缩写,它就像给当前系统的进程状态拍一张 "静态照片",展示某一瞬间的进程信息。
语法:ps 选项
| 选项 | 作用说明 |
|---|---|
-a |
显示所有终端下的进程 |
-u |
显示进程所属用户、CPU / 内存占用等详细信息 |
-x |
显示无终端的后台进程、守护进程 |
-e |
显示系统全部进程(等价 -A) |
-f |
完整格式显示,展示父进程 ID (PPID)、完整命令 |
-aux |
最常用,查看全量进程 + 详细资源占用 |
-ef |
查看所有进程 + 父子进程关系 |
-r |
只显示正在运行的进程 |
-T |
查看线程信息 |
常用组合:ps aux
这是最通用的查看所有进程的命令,信息最全:
bash
ps auxa:显示所有用户的进程u:显示进程的归属用户及详细信息x:显示没有控制终端的进程(比如后台服务)
通过系统调⽤创建进程
创造子进程fork
fork是Linux中的一个系统调用,可以创建子进程。
我们通过man fork来了解:
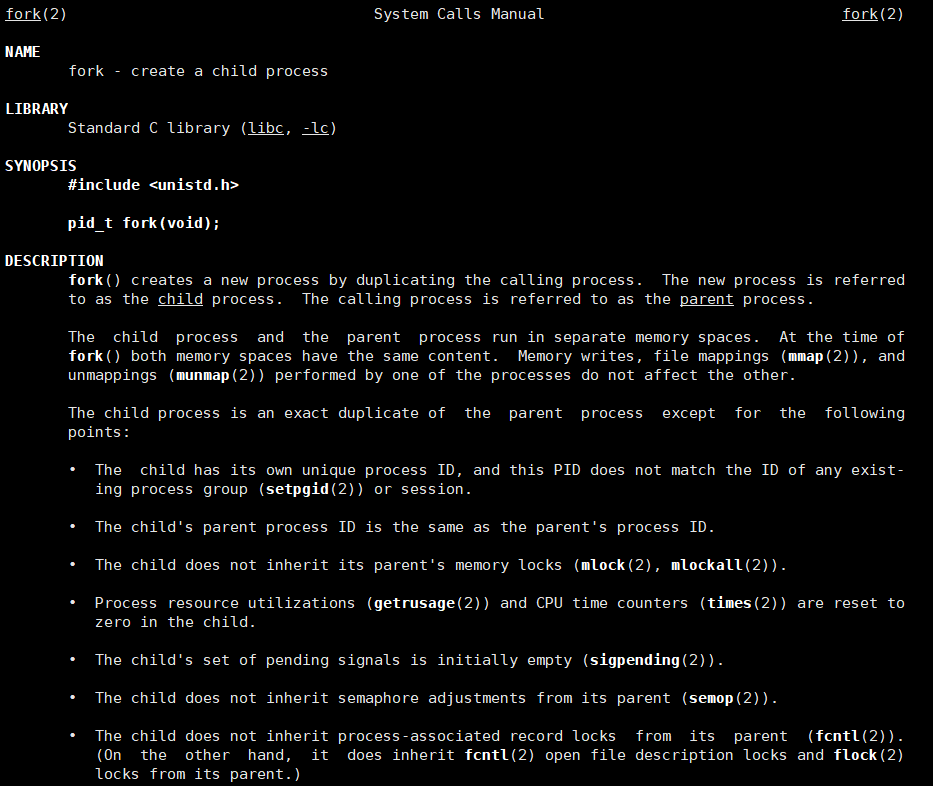
fork有两个返回值
子进程拿到的返回值是0 ,父进程拿到的返回值是子进程的ID,下面用代码来验证:
cpp
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
int pid = fork();
if(pid < 0)
{
perror("fork");
return 1;
}
else if(pid == 0)
printf("I am child\n");
else
printf("I am father\n");
sleep(1);
return 0;
}结果:

通过系统调⽤获取PID和PPID
• 进程id(PID):getpid()
• ⽗进程id(PPID):getppid()
cpp
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
pid_t pid = fork();
if(pid < 0)
{
perror("fork");
}
if(pid == 0)
printf("I am child,pid:%d,ppid:%d\n",getpid(),getppid());
else
printf("I am father,pid:%d,ppid:%d\n",getpid(),getppid());
}
父进程的pid是子进程的ppid,说通过fork创建了一个子进程。
为什么 fork() 函数会返回两次?
在 C 语言的进程编程里,fork() 是最让人困惑也最迷人的函数之一。
很多新手第一次用它都会懵:明明只写了一次 pid = fork();,代码里却会同时进入 if(pid == 0) 和 else 两个分支。这背后,藏着 Linux 进程创建的核心逻辑。
一、先搞懂:fork() 到底干了什么?
一句话总结:fork() 会复制出一个和父进程几乎一模一样的子进程,然后两个进程一起往下执行。
就像图里画的:父进程调用 fork() 时,内核会复制父进程的全部信息,包括代码、数据、寄存器状态,还有最重要的 PCB(进程控制块)。复制完成后,系统里就有了两个进程:
- 原来的进程:父进程
- 新复制出来的进程:子进程
而且这两个进程,会在 fork() 函数的同一个位置,一起往下执行代码。
二、为什么会 "返回两次"?
因为 fork() 函数在两个进程里,分别执行了一次 return:
- 对子进程来说 :它是被复制出来的新进程,
fork()给它返回0,代表 "我是子进程"。 - 对父进程来说 :它是原来的进程,
fork()给它返回子进程的 PID,代表 "我创建的子进程 ID 是 xxx"。
所以,你写的代码里,fork() 表面上被调用了一次,实际上在两个进程里,各自执行了一次返回,看起来就像 "返回了两次"。
三、一句话总结
fork() 不是魔法,它只是复制出了一个新进程,然后两个进程在同一个代码位置继续执行 。fork() 的两次返回,本质是两个进程各自拿到了属于自己的返回值,而进程的独立性,全靠每个进程独有的 PCB 来保证。