文章目录
- 一、先搞懂:什么样的SQL才算「慢SQL」?
-
- [1.1 生产慢SQL判定标准(通用标准)](#1.1 生产慢SQL判定标准(通用标准))
- 二、慢SQL第一步:永远先定位,再优化(别瞎改SQL)
-
- [2.1 必用神器:explain 执行计划](#2.1 必用神器:explain 执行计划)
- [2.2 explain 只要看3个核心字段(新手够用)](#2.2 explain 只要看3个核心字段(新手够用))
-
- [① type 字段(最关键)](#① type 字段(最关键))
- [② key 字段](#② key 字段)
- [③ rows 字段](#③ rows 字段)
- 三、核心根源:99%慢SQL就这几大原因
- 四、索引优化:优化慢SQL最见效、提升最快
-
- [4.1 哪些字段必须建索引?](#4.1 哪些字段必须建索引?)
- [4.2 索引最左匹配原则(必记)](#4.2 索引最左匹配原则(必记))
- [4.3 索引失效十大坑(日常开发最容易踩)](#4.3 索引失效十大坑(日常开发最容易踩))
- 五、SQL写法规范优化(改完立马提速)
-
- [5.1 永远禁止 select *](#5.1 永远禁止 select *)
- [5.2 小表驱动大表,join别乱连](#5.2 小表驱动大表,join别乱连)
- [5.3 尽量避免子查询,改成join](#5.3 尽量避免子查询,改成join)
- [5.4 limit 深度分页一定要优化](#5.4 limit 深度分页一定要优化)
- 六、业务层面优化(最高级、最有效)
-
- [6.1 大查询、统计、报表别查主库](#6.1 大查询、统计、报表别查主库)
- [6.2 热点数据、高频查询全部放Redis](#6.2 热点数据、高频查询全部放Redis)
- [6.3 大表一定要分库分表](#6.3 大表一定要分库分表)
- 七、生产慢SQL优化标准流程(照着这个步骤排查)
- 八、最终总结一句话
一、先搞懂:什么样的SQL才算「慢SQL」?
不是报错的SQL才叫有问题,执行时间长、扫描行数多、返回数据少,就是慢SQL。
1.1 生产慢SQL判定标准(通用标准)
-
单条SQL执行时间 超过1秒:算轻微慢查询;
-
单条SQL执行时间 超过3秒:线上必须优化;
-
扫描行数几十万、上百万,结果只返回几十条:典型烂SQL,必优化。
核心本质:扫描的数据太多,真正用到的数据太少,全是无效IO、无效计算。
二、慢SQL第一步:永远先定位,再优化(别瞎改SQL)
优化慢SQL,千万别上来就改代码。不改explain的优化,都是瞎优化。
2.1 必用神器:explain 执行计划
任何慢SQL,前面加个 explain,一眼看出问题在哪。
sql
explain SELECT * FROM user WHERE name = '张三';2.2 explain 只要看3个核心字段(新手够用)
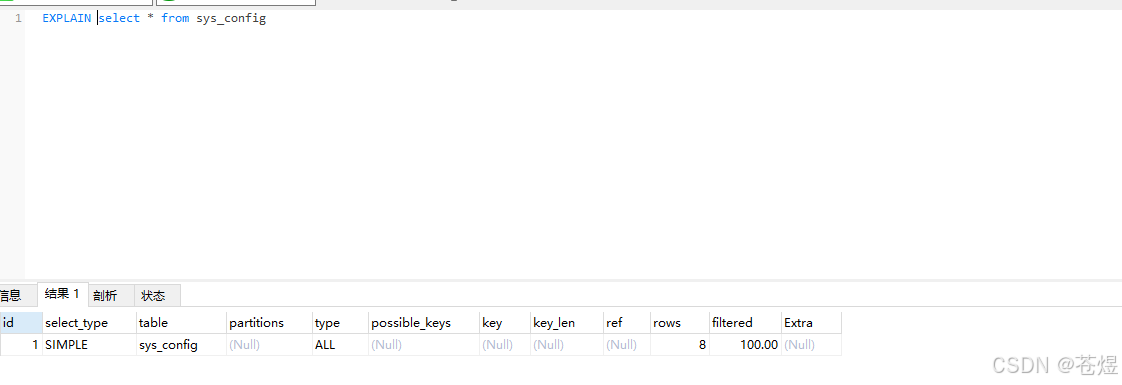
① type 字段(最关键)
查询类型,好坏级别:system > const > eq_ref > ref > range > index > ALL
生产红线:绝对不能出现 ALL,ALL就是全表扫描,数据一多必慢。
② key 字段
真正用到的索引。key为null = 没走索引,直接全表扫描。
③ rows 字段
扫描了多少行。扫描行数越大,SQL越慢。
优化核心目标:type别为ALL,key要有索引,rows尽量小。
三、核心根源:99%慢SQL就这几大原因
-
没加索引:查询字段、条件字段没建索引,全表扫描;
-
索引失效:建了索引,写法不对,索引作废;
-
select * 乱查:查一堆用不着的字段,不走覆盖索引,大量回表;
-
join、子查询乱用:大表连大表,笛卡尔积爆炸;
-
分页深度过大:limit 100000,10 经典大坑;
-
业务逻辑不合理:数据库干了不该干的事,排序统计全压给SQL。
四、索引优化:优化慢SQL最见效、提升最快
4.1 哪些字段必须建索引?
一句话:WHERE、JOIN、ORDER BY、GROUP BY 后面的字段,必须建索引。
4.2 索引最左匹配原则(必记)
联合索引 \(a,b,c\)
-
查 where a=? 走索引;
-
查 where a=? and b=? 走索引;
-
只查 b=? 或 c=? 索引直接失效。
索引带头大哥不能丢,丢了就不走索引。
4.3 索引失效十大坑(日常开发最容易踩)
只要踩中,索引直接作废,全表扫描:
-
select * 不用覆盖索引;
-
索引字段做运算、函数:
where age\+1=20; -
隐式类型转换:字符串字段用数字查询;
-
like %xxx 左模糊查询;
-
or 两边字段不同时加索引;
-
not in、not exists 反查逻辑;
-
order by 字段没在索引最后;
-
数据量太少、mysql觉得走索引不如全表快;
-
隔离级别、锁冲突导致索引优化失效;
-
长时间长事务不提交,索引缓存异常。
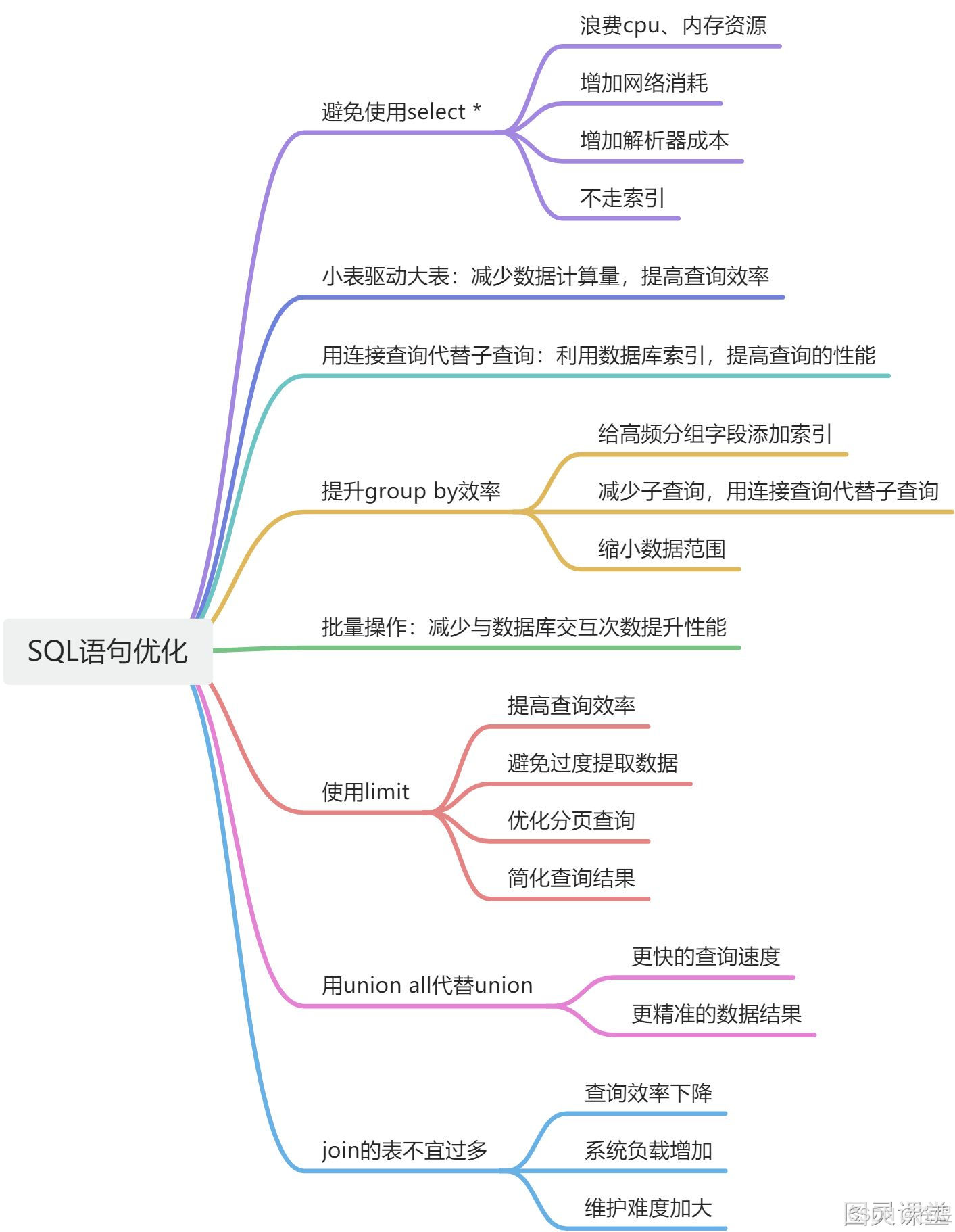
五、SQL写法规范优化(改完立马提速)
5.1 永远禁止 select *
只查需要的字段,能走覆盖索引就不用回表查询数据,性能直接差十倍起步。
很多人习惯随手写 SELECT *,看似省事,实则把没必要的大字段(备注、文本、创建时间等)全部查出来,不仅增加磁盘IO、网络传输,还直接导致索引覆盖失效,必须回表捞数据,越查越慢。
sql
-- 烂写法:查所有字段,不走覆盖索引,必然回表,性能极差
SELECT * FROM `order` WHERE user_id = 1001;
-- 优化写法:只查业务需要字段,命中覆盖索引,无需回表,速度飞快
SELECT id, order_no, pay_price, create_time FROM `order` WHERE user_id = 1001;
sql
-- 垃圾
SELECT * FROM order WHERE user_id = 1001;
-- 推荐
SELECT id,order_no,price FROM order WHERE user_id = 1001;5.2 小表驱动大表,join别乱连
join 两张表:小表放左边,大表放右边,减少循环匹配次数。
禁止大表连大表,禁止三张以上表join,关联越多,匹配逻辑越复杂,临时表开销越大。
核心原则:数据量小的小表当驱动表,先循环小表;数据量大的大表当被驱动表,只做精准匹配,减少整体循环匹配次数,JOIN性能直接翻倍。
sql
-- 烂写法:大表驱动小表,循环次数多,匹配效率低
SELECT * FROM big_order_table b LEFT JOIN small_user_table s ON b.user_id = s.id;
-- 优化写法:小表驱动大表,精准匹配,减少循环扫描
SELECT o.id, o.order_no, s.username FROM small_user_table s
LEFT JOIN big_order_table o ON s.id = o.user_id
WHERE s.id = 1001;5.3 尽量避免子查询,改成join
子查询运行时会自动生成临时表,临时表没有索引,查询匹配全靠遍历,数据量大了巨慢。生产实战里,能用JOIN关联查询,一律不用子查询。
sql
-- 烂写法:使用子查询,生成无索引临时表,查询低效
SELECT * FROM `order` WHERE user_id IN (SELECT id FROM `user` WHERE level = 1);
-- 优化写法:改成JOIN关联查询,直接走已有索引,无临时表开销
SELECT o.id, o.order_no FROM `order` o
INNER JOIN `user` u ON o.user_id = u.id
WHERE u.level = 1;5.4 limit 深度分页一定要优化
limit 100000,10 数据库要先扫10万行,再丢弃,巨慢。
优化核心方案:先靠主键索引做快速分页定位,再关联查询其他字段,避免扫描大量无效数据,深度分页性能提升几十倍。
sql
-- 烂写法:深度分页,先扫10万行再丢弃,超级慢
SELECT * FROM `order` ORDER BY id LIMIT 100000, 10;
-- 优化写法:主键索引快速定位,再关联查询,无需扫描无效数据
SELECT o.id, o.order_no, o.pay_price FROM `order` o
INNER JOIN (SELECT id FROM `order` ORDER BY id LIMIT 100000, 10) temp
ON o.id = temp.id ORDER BY o.id;六、业务层面优化(最高级、最有效)
很多慢SQL,SQL本身没问题,业务设计有问题。
6.1 大查询、统计、报表别查主库
主库只负责日常业务新增、修改、删除核心读写操作,压力必须稳住;统计报表、后台数据导出、历史大数据分析这类慢查询、大扫描SQL,全部迁移到从库执行,绝不碰主库,避免拖垮核心业务。
sql
-- 烂写法:主库执行统计报表大SQL,扫描海量数据,压垮主库
SELECT id, COUNT(*) AS order_count, SUM(pay_price) AS total_money
FROM `order` GROUP BY user_id;优化操作:同样的统计SQL,代码里直接配置连接从库数据源执行,SQL不变,压力隔离,主库零影响。
6.2 热点数据、高频查询全部放Redis
首页数据、个人信息、配置参数、秒杀库存,不要每次查数据库。
高频访问、变动少的热点数据,提前缓存到Redis,接口查询优先读缓存,压根不执行SQL,从根源杜绝慢查询。
sql
-- 烂写法:每次接口请求都查数据库,高频并发下数据库压力巨大
SELECT id, username, phone, avatar FROM `user` WHERE id = 1001;优化操作:用户信息首次查询后存入Redis,后续请求直接读Redis,不再执行这条查询SQL,定时异步更新缓存数据即可。
6.3 大表一定要分库分表
单表数据量达到千万级别以上,不管怎么优化索引、改SQL写法,查询性能都会有物理瓶颈,读写压力天生扛不住,必须做分库分表,拆分大表为多个小表,从架构上解决慢查询问题。
sql
-- 烂写法:上亿数据单表查询,再怎么加索引,范围查询、统计依旧慢
SELECT * FROM big_order_data WHERE create_time BETWEEN '2026-01-01' AND '2026-05-01';优化操作:按时间或用户ID做分片分表,查询只路由到对应小分片表,扫描数据量骤减,SQL无需复杂优化自然变快。
七、生产慢SQL优化标准流程(照着这个步骤排查)
-
拿到慢SQL日志,找到执行时间最长、扫描行数最多的SQL;
-
explain 分析执行计划,看是不是全表扫描;
-
检查是否缺索引,或者索引失效;
-
修改SQL写法,避免索引失效语法;
-
优化select字段、join、分页逻辑;
-
大查询迁移从库,热点数据加缓存;
-
超大表考虑分库分表。
八、最终总结一句话
慢SQL优化核心就三件事:别走全表扫描、索引别失效、数据库只干核心读写,别让它干统计和查询杂活。