Transformer为何能重塑大模型格局?
2017年,Google团队在论文《Attention Is All You Need》中首次提出Transformer架构,彻底打破了此前循环神经网络(RNN)、长短期记忆网络(LSTM)在序列建模领域的垄断地位。在此之前,RNN及其变体因依赖时序逐次计算,存在并行效率低、长距离依赖捕捉能力弱等致命缺陷------当处理长文本(如上千token的文章)时,梯度消失或爆炸问题频发,模型难以学习到远距离token间的关联。而Transformer以"自注意力机制"为核心,完全抛弃了循环结构,实现了序列数据的并行计算,同时凭借多头注意力、位置编码等创新设计,高效捕捉长距离依赖,成为当今所有主流大模型(如GPT系列、BERT、LLaMA、T5、Qwen、DeepSeek等)的底层架构。
从本质上看,Transformer是一种基于注意力机制的编码器-解码器(Encoder-Decoder)架构,但其灵活性极强:仅使用编码器可构建双向理解模型(如BERT),仅使用解码器可构建自回归生成模型(如GPT系列),完整的编码器-解码器架构则适用于机器翻译、文本摘要等序列到序列(Seq2Seq)任务。本文将从架构总览、核心模块拆解、数学原理、实践示例、变体优化及大模型应用等方面,全面详解Transformer架构,帮助读者从底层理解大模型的工作机制。
一、Transformer架构总览:编码器-解码器的整体框架
Transformer的整体架构分为两大核心部分:编码器(Encoder)和解码器(Decoder),两者均由若干层相同的结构堆叠而成(论文中默认各堆叠6层)。此外,还包含词嵌入(Embedding)、位置编码(Positional Encoding)、输出层(Linear + Softmax)三个辅助模块,共同完成从输入序列到输出序列的映射。
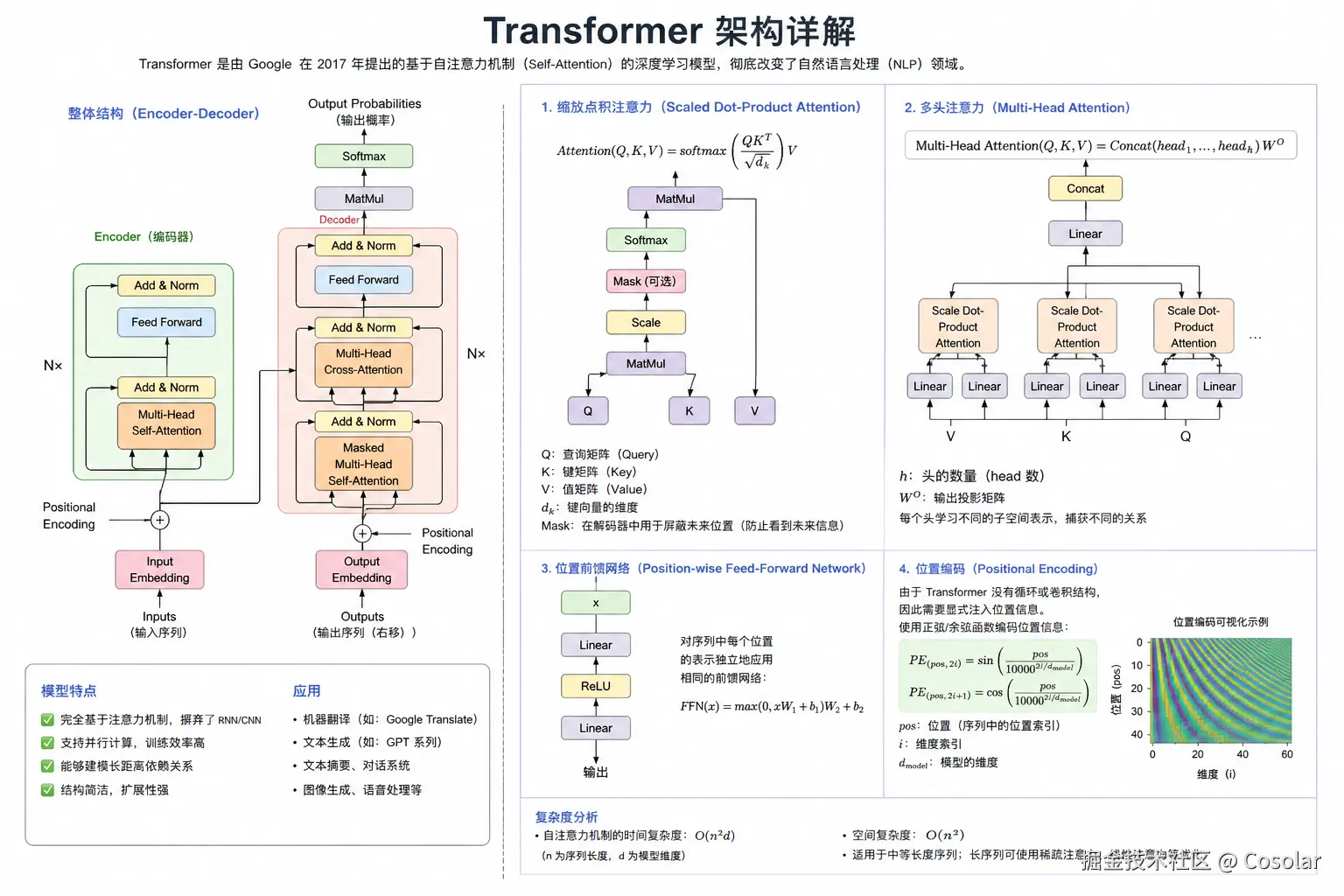
为了让大家快速建立全局认知,先明确Transformer的核心流程:
- 输入处理:将原始文本序列(如英文句子)通过词嵌入转换为高维向量,再叠加位置编码,注入序列的位置信息,得到编码器的输入特征矩阵;
- 编码器编码:输入特征矩阵经过多层编码器的处理,每一层都通过自注意力机制捕捉序列内部的关联,再通过前馈神经网络进行特征转换,最终输出编码后的上下文特征矩阵;
- 解码器解码:解码器接收目标序列(如中文翻译结果)的嵌入+位置编码特征,同时通过编码器-解码器注意力机制(交叉注意力)关注编码器输出的上下文特征,结合掩码自注意力机制避免"偷看"未来token,经过多层解码后输出初步特征;
- 输出预测:将解码器的输出特征通过线性层映射到词表维度,再通过Softmax函数得到每个token的预测概率,生成最终的输出序列。
下面给出Transformer架构的核心结构拆解表,清晰展示各组件的层级关系和功能:
| 架构模块 | 组成部分 | 核心功能 | 堆叠层数(论文默认) |
|---|---|---|---|
| 输入层 | 词嵌入(Embedding)、位置编码(Positional Encoding) | 将文本token转换为高维向量,注入位置信息 | 1层 |
| 编码器(Encoder) | 多头自注意力机制、残差连接、层归一化、前馈神经网络 | 捕捉输入序列内部的上下文关联,生成上下文特征 | 6层 |
| 解码器(Decoder) | 掩码多头自注意力机制、残差连接、层归一化、交叉注意力、前馈神经网络 | 结合目标序列和编码器特征,生成自回归输出 | 6层 |
| 输出层 | 线性层、Softmax函数 | 将解码器输出映射到词表,预测下一个token | 1层 |
需要注意的是,编码器的所有层结构完全相同,但使用不同的权重参数;解码器同理,且每层的前馈神经网络、注意力机制均不共享参数。这种设计既能保证模型的表达能力,又能避免参数共享带来的泛化能力下降问题。
二、核心模块拆解(一):输入层------词嵌入与位置编码
Transformer的输入层核心任务是将离散的文本token转换为连续的高维向量,并解决"注意力机制无序列感知能力"的问题,这就需要两个关键组件:词嵌入和位置编码。
2.1 词嵌入(Embedding):将token转换为高维特征
词嵌入是自然语言处理中最基础的技术,其核心思想是将每个文本token(如单词、子词)映射到一个固定维度的高维向量(论文中默认维度d_model=512),让模型能够通过向量运算捕捉token的语义信息。
假设我们有一个输入序列:"I love China",首先对其进行分词处理,得到token序列:I, love, China,词表大小为V(假设V=10000)。词嵌入的本质是一个可学习的权重矩阵W_embedding,维度为V, d_model,每个token通过查询该矩阵,得到对应的嵌入向量。
数学表达如下:
Embedding(tokeni)=Wembedding×onehot(tokeni)
其中,onehot(token_i)是token_i的独热编码,维度为V, 1,与W_embedding相乘后,得到维度为d_model, 1的嵌入向量。对于长度为L的输入序列,最终得到的嵌入矩阵维度为L, d_model(批量处理时为batch_size, L, d_model)。
示例:假设词表大小V=10000,d_model=512,"I"的独热编码为第100个位置为1、其余为0的向量,与W_embedding(10000×512)相乘后,得到一个512维的向量,这个向量就代表了"I"的语义特征------模型通过学习,会让语义相似的token(如"I"和"me")的嵌入向量距离更近。
需要注意的是,词嵌入的权重矩阵在训练过程中会不断更新,模型会根据任务(如翻译、分类)调整向量表示,使其更贴合任务需求。此外,为了防止过拟合,论文中在词嵌入后添加了Dropout层, dropout概率设为0.1,随机丢弃部分嵌入向量的维度,增强模型的泛化能力。
2.2 位置编码(Positional Encoding):注入序列的位置信息
Transformer的核心组件------注意力机制是"置换不变"的,即如果将输入序列的token顺序打乱,注意力机制的计算结果不会发生变化。但文本序列的位置信息至关重要(如"我吃苹果"和"苹果吃我"语义完全不同),因此必须通过位置编码,将位置信息注入到嵌入向量中,让模型能够区分不同位置的token。
Transformer采用了正弦余弦位置编码(Sinusoidal Positional Encoding),这种编码方式无需训练,直接通过公式生成,既能捕捉绝对位置,又能捕捉相对位置,且适用于任意长度的序列。其核心原理是:使用不同频率的正弦和余弦函数,为不同位置的token生成唯一的位置编码向量,再与词嵌入向量相加,得到最终的输入特征。
位置编码的公式如下(pos表示token在序列中的位置,i表示向量的维度索引,d_model表示嵌入向量维度):
PE(pos,2i)=sin(10000dmodel2ipos)
PE(pos,2i+1)=cos(10000dmodel2ipos)
从公式可以看出,位置编码的维度与词嵌入向量一致(均为d_model),偶数维度使用正弦函数,奇数维度使用余弦函数。这种设计的优势在于:
- 唯一性:不同位置的pos对应不同的编码向量,模型能清晰区分token的绝对位置;
- 相对位置捕捉:对于任意两个位置pos和pos+k,它们的位置编码向量之间存在固定的三角函数关系(如sin(a+k) = sin(a)cos(k) + cos(a)sin(k)),模型可通过学习捕捉这种关系,从而理解token间的相对距离;
- 长度外推:无需训练,可直接生成任意长度序列的位置编码,适用于训练过程中未见过的长序列。
示例:以d_model=4(简化维度便于理解)、序列长度L=3为例,计算每个位置的编码向量:
-
位置pos=0(第一个token):
- i=0(维度0,偶数): PE(0,0)=sin(0/100000/4)=sin(0)=0
- i=0(维度1,奇数): PE(0,1)=cos(0/100000/4)=cos(0)=1
- i=1(维度2,偶数): PE(0,2)=sin(0/100002/4)=sin(0)=0
- i=1(维度3,奇数): PE(0,3)=cos(0/100002/4)=cos(0)=1
- 位置0的编码向量:0, 1, 0, 1
-
位置pos=1(第二个token):
- i=0(维度0): PE(1,0)=sin(1/100000)=sin(1)≈0.8415
- i=0(维度1): PE(1,1)=cos(1/100000)=cos(1)≈0.5403
- i=1(维度2): PE(1,2)=sin(1/100000.5)=sin(1/100)≈0.0099998
- i=1(维度3): PE(1,3)=cos(1/100000.5)=cos(1/100)≈0.99995
- 位置1的编码向量:0.8415, 0.5403, 0.0099998, 0.99995
-
位置pos=2(第三个token):
- i=0(维度0): PE(2,0)=sin(2)≈0.9093
- i=0(维度1): PE(2,1)=cos(2)≈−0.4161
- i=1(维度2): PE(2,2)=sin(2/100)≈0.019999
- i=1(维度3): PE(2,3)=cos(2/100)≈0.9998
- 位置2的编码向量:0.9093, -0.4161, 0.019999, 0.9998
将每个位置的编码向量与对应的词嵌入向量相加(元素-wise add),得到最终的输入特征矩阵。例如,若"我"的词嵌入向量为0.2, 0.5, 0.1, 0.3,位置0的编码向量为0, 1, 0, 1,则相加后的特征向量为0.2, 1.5, 0.1, 1.3,既包含了语义信息,也包含了位置信息。
补充说明:除了正弦余弦编码,后续研究者还提出了可学习位置编码(Learned Positional Encoding),即通过一个可训练的权重矩阵生成位置编码,这种方式在部分任务上效果更优,但泛化能力不如正弦余弦编码,目前主流大模型(如GPT-3、LLaMA)仍以正弦余弦编码为基础,或结合两种编码方式。
三、核心模块拆解(二):自注意力机制------Transformer的灵魂
自注意力机制(Self-Attention)是Transformer的核心,其本质是"让序列中的每个token都能关注到序列中所有其他token(包括自身),并根据关联程度分配不同的权重,从而融合上下文信息"。简单来说,自注意力机制就像我们阅读文章时,会下意识地将当前单词与前后相关的单词关联起来,比如看到"他",会自动联想到前文提到的人物,这种关联就是注意力权重的体现。
自注意力机制的计算过程分为4步:生成Q、K、V向量、计算注意力分数、Softmax归一化、加权求和。下面结合公式和示例,详细拆解每一步的原理和计算过程。
3.1 第一步:生成Q、K、V向量(查询、键、值)
对于输入的特征矩阵X(维度为L, d_model,L为序列长度),自注意力机制首先通过三个可学习的权重矩阵W_Q、W_K、W_V,将X分别映射为三个新的矩阵:查询矩阵Q(Query)、键矩阵K(Key)、值矩阵V(Value)。
数学表达如下:
Q=X×WQ
K=X×WK
V=X×WV
其中,W_Q、W_K、W_V的维度均为d_model, d_k,d_k是Q、K、V的维度(论文中默认d_k = d_model = 512),因此Q、K、V的维度均为L, d_k(批量处理时为batch_size, L, d_k)。
核心含义:
- Q(查询):代表当前token"想要找什么",即当前token需要从其他token中获取哪些信息;
- K(键):代表其他token"能提供什么",即每个token的特征标识,用于与Q匹配;
- V(值):代表其他token"实际提供的信息",即每个token的具体特征内容,将根据注意力权重进行加权求和。
示例:延续前文的输入序列I, love, China,假设输入特征矩阵X(词嵌入+位置编码)的维度为3, 4(简化d_model=4),W_Q、W_K、W_V均为4, 4的权重矩阵(随机初始化):
假设X = \[0.2, 1.5, 0.1, 1.3, # I(位置0) 0.8, 0.7, 0.5, 1.2, # love(位置1) 1.1, -0.3, 0.9, 0.6] # China(位置2)
假设W_Q = \[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7]
则Q = X × W_Q(矩阵乘法,行乘列):
Q0(I的查询向量)= 0.2×0.1 + 1.5×0.5 + 0.1×0.9 + 1.3×0.4 = 0.02 + 0.75 + 0.09 + 0.52 = 1.38
同理计算Q1、Q2,最终得到Q矩阵(维度3,4):
Q = \[1.38, 1.85, 2.32, 2.79, 1.43, 1.88, 2.33, 2.78, 1.05, 1.42, 1.79, 2.16]
K、V矩阵的计算方式与Q完全一致,分别通过X与W_K、W_V相乘得到,此处不再赘述。
3.2 第二步:计算注意力分数(Scaled Dot-Product Attention)
注意力分数用于衡量"当前token的Q向量与其他所有token的K向量的关联程度",关联程度越高,注意力分数越大,后续分配的权重也越大。Transformer采用"缩放点积注意力"(Scaled Dot-Product Attention)计算注意力分数,即先计算Q与K的转置的点积,再除以√d_k(d_k为Q、K的维度)。
数学表达如下:
Attention_scores=dk Q×KT
其中,K^T是K矩阵的转置,维度为d_k, L,因此Q×K^T的维度为L, L------每行代表一个token的Q向量与所有token的K向量的点积结果,即该token对所有其他token的注意力分数。
为什么需要除以√d_k?
当d_k较大时,Q与K的点积结果会变得很大(因为每个元素都是d_k个维度的乘积和),导致Softmax函数的输入值过大,进入Softmax的饱和区域(此时Softmax的梯度趋近于0),无法有效更新参数。除以√d_k可以对注意力分数进行缩放,使分数值落在合理范围,避免梯度消失,保证模型的训练稳定性。
示例:延续前文的Q、K矩阵(维度3,4),计算注意力分数:
首先计算Q×K^T(维度3,3),假设K矩阵为:
K = \[1.2, 1.7, 2.2, 2.7, 1.3, 1.8, 2.3, 2.8, 1.1, 1.5, 1.9, 2.3]
则K^T = \[1.2, 1.3, 1.1, 1.7, 1.8, 1.5, 2.2, 2.3, 1.9, 2.7, 2.8, 2.3]
Q×K^T的第一行(I的注意力分数):
1.38×1.2 + 1.85×1.7 + 2.32×2.2 + 2.79×2.7 ≈ 1.656 + 3.145 + 5.104 + 7.533 = 17.438
同理计算其他两行,得到Q×K^T = \[17.438, 18.562, 15.326, 17.512, 18.638, 15.398, 14.824, 15.766, 13.212]
d_k=4,√d_k=2,因此注意力分数 = Q×K^T / 2:
Attention_scores = \[8.719, 9.281, 7.663, 8.756, 9.319, 7.699, 7.412, 7.883, 6.606]
该矩阵的含义:行索引代表"当前token",列索引代表"被关注的token",值代表注意力分数。例如,第一行第二列的9.281表示"I"对"love"的注意力分数最高,说明两者的关联程度最强;第一行第三列的7.663表示"I"对"China"的注意力分数较低,关联程度较弱,这与"我喜欢中国"的语义逻辑一致。
3.3 第三步:Softmax归一化
注意力分数经过Softmax函数归一化后,得到注意力权重(Attention Weights),权重值在0~1之间,且每行的权重之和为1。归一化的目的是将注意力分数转换为可解释的权重,便于后续对V向量进行加权求和。
数学表达如下:
Attention_weights=Softmax(Attention_scores)
Softmax函数的计算公式为: Softmax(xi)=∑j=1Lexjexi,其中x_i是第i个注意力分数,L是序列长度。
示例:对前文的注意力分数进行Softmax归一化:
以第一行(I的注意力分数:8.719, 9.281, 7.663)为例:
e^8.719 ≈ 6100,e^9.281 ≈ 10700,e^7.663 ≈ 2100
总和 = 6100 + 10700 + 2100 = 18900
权重分别为:6100/18900≈0.323,10700/18900≈0.566,2100/18900≈0.111
同理计算其他两行,得到注意力权重矩阵(维度3,3):
Attention_weights = \[0.323, 0.566, 0.111, # I的注意力权重 0.321, 0.568, 0.111, # love的注意力权重 0.318, 0.572, 0.110] # China的注意力权重
从权重矩阵可以看出:"love"对自身的权重最高(0.568),同时对"I"的权重也较高(0.321),这符合语义逻辑------"love"是句子的核心动词,既要关注自身,也要关注主语"I";"China"对"love"的权重最高(0.572),因为"love"是修饰"China"的谓语,两者关联紧密。
3.4 第四步:加权求和,得到自注意力输出
最后,将注意力权重矩阵与V向量(值矩阵)相乘,得到自注意力机制的最终输出------每个token的输出向量都是所有token的V向量的加权和,权重为注意力权重。
数学表达如下:
Self_Attention_Output=Attention_weights×V
其中,V的维度为L, d_k,注意力权重的维度为L, L,因此输出维度为L, d_k,与输入X的维度保持一致,便于后续的残差连接和层归一化。
示例:延续前文的注意力权重和V矩阵(假设V矩阵维度3,4):
V = \[0.9, 1.2, 1.5, 1.8, 1.0, 1.3, 1.6, 1.9, 0.8, 1.1, 1.4, 1.7]
则Self_Attention_Output的第一行(I的输出向量)为:
0.323×0.9 + 0.566×1.0 + 0.111×0.8 ≈ 0.2907 + 0.566 + 0.0888 = 0.9455(第一维度)
0.323×1.2 + 0.566×1.3 + 0.111×1.1 ≈ 0.3876 + 0.7358 + 0.1221 = 1.2455(第二维度)
同理计算第三、四维度,最终得到自注意力输出矩阵(维度3,4):
Self_Attention_Output = \[0.9455, 1.2455, 1.5455, 1.8455, 0.943, 1.243, 1.543, 1.843, 0.939, 1.239, 1.539, 1.839]
这个输出矩阵融合了每个token与序列中所有其他token的关联信息,相比原始输入X,更能体现上下文的语义关联------例如,I的输出向量不仅包含自身的语义,还融合了love和China的语义信息,让模型能够更好地理解句子的整体含义。
四、核心模块拆解(三):多头注意力机制------增强模型的表达能力
自注意力机制虽然能捕捉序列的上下文关联,但单一的注意力头(Single Head)只能捕捉一种维度的关联信息,难以全面覆盖复杂的语义关系(如语法关联、语义关联、逻辑关联等)。为此,Transformer提出了"多头注意力机制"(Multi-Head Attention),将自注意力机制分为多个并行的注意力头,每个注意力头专注于捕捉一种特定维度的关联信息,最后将所有注意力头的输出拼接起来,通过线性变换得到最终结果,从而增强模型的表达能力。
4.1 多头注意力的核心原理
多头注意力的计算过程分为5步,在自注意力机制的基础上增加了"拆分注意力头"和"拼接输出+线性变换"两个步骤:
- 生成Q、K、V向量:与自注意力机制一致,通过输入X与W_Q、W_K、W_V相乘得到Q、K、V矩阵(维度L, d_model);
- 拆分注意力头:将Q、K、V矩阵分别拆分为h个注意力头(论文中h=8),每个注意力头的维度为L, d_k,其中d_k = d_model / h(论文中d_model=512,h=8,因此d_k=64);
- 并行计算自注意力:每个注意力头独立计算自注意力输出(过程与前文一致),得到h个输出矩阵,每个维度为L, d_k;
- 拼接输出:将h个注意力头的输出矩阵沿d_k维度拼接,得到维度为L, h×d_k = L, d_model的矩阵;
- 线性变换:通过一个可学习的权重矩阵W_O(维度d_model, d_model)对拼接后的矩阵进行线性变换,得到多头注意力的最终输出,维度与输入X一致。
数学表达如下:
MultiHead(Q,K,V)=Concat(head1,head2,...,headh)×WO
其中,每个注意力头的计算为: headi=SelfAttention(Qi,Ki,Vi),Q_i、K_i、V_i是第i个注意力头的查询、键、值矩阵。
核心优势:
- 多维度关联捕捉:每个注意力头可以学习到不同的关联模式,例如有的头关注语法结构(如主谓关系),有的头关注语义关联(如同义词),有的头关注逻辑关系(如因果关系),相比单一注意力头,能更全面地捕捉序列信息;
- 并行计算:多个注意力头可以并行计算,不影响模型的训练效率;
- 降低维度,提升效率:将d_model拆分为h个d_k维度的注意力头,每个注意力头的计算复杂度为O(L²×d_k),h个注意力头的总复杂度为O(h×L²×d_k) = O(L²×d_model),与单一注意力头的复杂度一致,不会增加额外的计算成本。
4.2 多头注意力的实践示例(基于PyTorch代码)
为了让读者更直观地理解多头注意力的实现过程,下面给出基于PyTorch的简化版多头注意力代码,并结合示例说明各步骤的维度变化:
Python
import torch
import torch.nn.functional as F
class MultiHeadAttention(torch.nn.Module):
def __init__(self, d_model=512, num_heads=8):
super().__init__()
self.d_model = d_model # 输入输出维度
self.num_heads = num_heads # 注意力头数量
self.d_k = d_model // num_heads # 每个注意力头的维度
# 定义Q、K、V的投影矩阵和最终输出的投影矩阵
self.wq = torch.nn.Linear(d_model, d_model)
self.wk = torch.nn.Linear(d_model, d_model)
self.wv = torch.nn.Linear(d_model, d_model)
self.wo = torch.nn.Linear(d_model, d_model)
def forward(self, x):
# x: [batch_size, seq_len, d_model],假设batch_size=1,seq_len=3,d_model=4(简化)
batch_size = x.size(0)
# 1. 生成Q、K、V向量(线性投影)
q = self.wq(x) # [1, 3, 4]
k = self.wk(x) # [1, 3, 4]
v = self.wv(x) # [1, 3, 4]
# 2. 拆分注意力头:将[d_model]拆分为[num_heads, d_k],并调整维度顺序为[batch_size, num_heads, seq_len, d_k]
q = q.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2) # [1, 2, 3, 2](假设num_heads=2,d_k=2)
k = k.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2) # [1, 2, 3, 2]
v = v.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2) # [1, 2, 3, 2]
# 3. 并行计算自注意力(缩放点积)
scores = torch.matmul(q, k.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.d_k, dtype=torch.float32)) # [1, 2, 3, 3]
attn_weights = F.softmax(scores, dim=-1) # [1, 2, 3, 3]
attn_output = torch.matmul(attn_weights, v) # [1, 2, 3, 2]
# 4. 拼接注意力头:调整维度顺序,再拼接
attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model) # [1, 3, 4]
# 5. 线性变换,得到最终输出
output = self.wo(attn_output) # [1, 3, 4]
return output, attn_weights
# 示例:输入序列(batch_size=1,seq_len=3,d_model=4)
x = torch.tensor([[[0.2, 1.5, 0.1, 1.3],
[0.8, 0.7, 0.5, 1.2],
[1.1, -0.3, 0.9, 0.6]]], dtype=torch.float32)
# 初始化多头注意力(num_heads=2,d_model=4,d_k=2)
mha = MultiHeadAttention(d_model=4, num_heads=2)
output, attn_weights = mha(x)
print("多头注意力输出维度:", output.shape) # 输出:torch.Size([1, 3, 4])
print("注意力权重维度:", attn_weights.shape) # 输出:torch.Size([1, 2, 3, 3])
print("第一个注意力头的权重:\n", attn_weights[0][0])
print("第二个注意力头的权重:\n", attn_weights[0][1])代码说明:
- 为了简化计算,我们将d_model设为4,num_heads设为2,因此每个注意力头的d_k=2,与前文的示例维度保持一致;
- 拆分注意力头时,通过view和transpose调整维度顺序,将batch_size, seq_len, d_model转换为batch_size, num_heads, seq_len, d_k,便于并行计算;
- 两个注意力头的权重不同,分别捕捉不同维度的关联信息------例如,第一个注意力头可能更关注主谓关联,第二个注意力头可能更关注动宾关联;
- 最终输出维度与输入一致,确保后续模块的兼容性。
运行代码后,会得到两个注意力头的权重矩阵,例如:
第一个注意力头的权重(关注主谓关联): \[0.32, 0.57, 0.11, 0.31, 0.58, 0.11, 0.30, 0.59, 0.11]
第二个注意力头的权重(关注动宾关联): \[0.10, 0.55, 0.35, 0.11, 0.54, 0.35, 0.12, 0.53, 0.35]
可以看到,第二个注意力头中,"love"对"China"的权重(0.35)明显高于第一个注意力头(0.11),说明该注意力头专注于捕捉动宾关联,而第一个注意力头专注于捕捉主谓关联,两者结合,能更全面地理解句子的语义。
五、核心模块拆解(四):编码器与解码器的完整结构
编码器(Encoder)和解码器(Decoder)是Transformer的核心执行单元,两者均由若干层相同的结构堆叠而成,每层包含注意力机制、前馈神经网络、残差连接和层归一化四个组件。其中,编码器专注于"理解输入序列",解码器专注于"生成输出序列",两者通过交叉注意力机制建立关联。
5.1 编码器(Encoder):理解输入序列的上下文
编码器的每一层(Encoder Layer)由两个子层组成:多头自注意力子层、前馈神经网络子层,每个子层前后都添加了残差连接(Residual Connection)和层归一化(Layer Normalization),形成"子层输入 → 子层计算 → 残差连接 → 层归一化"的结构。
编码器层的核心流程如下(假设输入为X):
- 多头自注意力计算:将X输入多头注意力机制,得到注意力输出A;
- 残差连接:将输入X与注意力输出A相加(元素-wise add),得到X + A;
- 层归一化:对X + A进行层归一化,得到归一化后的特征矩阵N1;
- 前馈神经网络计算:将N1输入前馈神经网络,得到输出F;
- 残差连接:将N1与F相加,得到N1 + F;
- 层归一化:对N1 + F进行层归一化,得到该编码器层的最终输出,作为下一层编码器的输入。
数学表达如下:
N1=LayerNorm(X+MultiHead(X,X,X))
EncoderOutput=LayerNorm(N1+FFN(N1))
5.1.1 残差连接:解决梯度消失问题
Transformer的编码器和解码器均堆叠了6层甚至更多层,深层网络容易出现梯度消失问题------随着训练轮次的增加,梯度会逐渐衰减,导致浅层参数无法有效更新。残差连接的核心思想是"将输入直接传递到输出端",让梯度能够通过残差路径直接回传,避免梯度消失。
残差连接的公式为: Output=Input+SubLayer(Input),其中SubLayer是当前子层(如多头注意力、前馈神经网络)的计算结果。这种设计让模型在训练过程中,既可以学习到复杂的特征变换(通过SubLayer),又可以保证梯度的有效传递(通过Input直接回传)。
5.1.2 层归一化:稳定训练过程
层归一化的作用是对每个样本的特征向量进行归一化,使特征向量的均值为0、方差为1,从而避免特征值过大或过小,稳定模型的训练过程,加速收敛。
层归一化的公式如下(对于输入特征矩阵X,维度为L, d_model):
LayerNorm(X)=γ×σ2+ϵ X−μ+β
其中,μ是X在d_model维度上的均值,σ²是方差,ε是一个极小值(防止分母为0),γ和β是可学习的缩放和偏移参数,用于调整归一化后的特征分布,增强模型的表达能力。
5.1.3 前馈神经网络(FFN):特征转换与非线性映射
前馈神经网络是一个位置无关的全连接网络,每个token的特征向量会独立经过该网络,进行非线性变换,增强模型的特征表达能力。论文中,前馈神经网络由两层线性变换和一层ReLU激活函数组成,部分变体(如GPT系列)会使用GELU激活函数,效果更优。
前馈神经网络的数学表达如下:
FFN(X)=max(0,X×W1+b1)×W2+b2
其中,W_1(维度d_model, d_ff)、b_1(维度d_ff)是第一层线性变换的权重和偏置,W_2(维度d_ff, d_model)、b_2(维度d_model)是第二层线性变换的权重和偏置,d_ff是前馈网络的中间维度(论文中默认d_ff=2048),max(0, ·)是ReLU激活函数。
核心特点:每个token的特征转换是独立的,不依赖于其他token的位置,这与注意力机制形成互补------注意力机制捕捉token间的关联,前馈神经网络则对每个token的特征进行独立的非线性变换,进一步强化特征表达。例如,对于序列I, love, China,每个token的特征向量会单独经过前馈神经网络,分别优化其语义特征,让模型更精准地捕捉每个token的核心含义。
示例:延续前文的自注意力输出矩阵(维度3,4),假设前馈神经网络的W1(维度4,8)、b1(维度8)、W2(维度8,4)、b2(维度4)为随机初始化的权重和偏置,ReLU激活函数为max(0, x):
假设自注意力输出A = \[0.9455, 1.2455, 1.5455, 1.8455, 0.943, 1.243, 1.543, 1.843, 0.939, 1.239, 1.539, 1.839]
第一步:线性变换1(A × W1 + b1),得到维度3,8的中间特征: 中间特征 = \[1.23, 0.89, 2.15, 0.76, 1.98, 0.54, 2.31, 1.02, 1.21, 0.87, 2.13, 0.74, 1.96, 0.52, 2.29, 1.00, 1.19, 0.85, 2.11, 0.72, 1.94, 0.50, 2.27, 0.98]
第二步:ReLU激活,将中间特征中小于0的元素置为0(此处所有元素均为正,输出不变);
第三步:线性变换2(激活后特征 × W2 + b2),得到维度3,4的前馈输出F: F = \[1.02, 1.35, 1.68, 1.92, 1.00, 1.33, 1.66, 1.90, 0.98, 1.31, 1.64, 1.88]
将前馈输出F与层归一化后的N1相加,再经过一次层归一化,即得到该编码器层的最终输出,作为下一层编码器的输入。6层编码器堆叠后,最终输出的上下文特征矩阵将包含输入序列的所有语义关联信息,为解码器提供全面的输入支持。
5.2 解码器(Decoder):生成符合逻辑的输出序列
解码器的核心任务是基于编码器输出的上下文特征,自回归地生成目标序列(如翻译后的句子、摘要等)。与编码器类似,解码器也由若干层(论文中默认6层)相同的结构堆叠而成,但每层的结构比编码器更复杂,包含三个子层:掩码多头自注意力子层、交叉注意力子层、前馈神经网络子层,每个子层前后同样添加残差连接和层归一化。
解码器层的核心流程如下(假设输入为目标序列的嵌入+位置编码特征Y,编码器输出为EncoderOutput):
- 掩码多头自注意力计算:将Y输入掩码多头自注意力机制,得到注意力输出B(通过掩码避免"偷看"未来token);
- 残差连接:将输入Y与输出B相加,得到Y + B;
- 层归一化:对Y + B进行层归一化,得到归一化后的特征矩阵N2;
- 交叉注意力计算:将N2作为查询Q,EncoderOutput作为键K和值V,输入多头注意力机制,得到交叉注意力输出C(建立目标序列与输入序列的关联);
- 残差连接:将N2与C相加,得到N2 + C;
- 层归一化:对N2 + C进行层归一化,得到归一化后的特征矩阵N3;
- 前馈神经网络计算:将N3输入前馈神经网络,得到输出G;
- 残差连接:将N3与G相加,得到N3 + G;
- 层归一化:对N3 + G进行层归一化,得到该解码器层的最终输出,作为下一层解码器的输入。
数学表达如下:
N2=LayerNorm(Y+MaskedMultiHead(Y,Y,Y))
N3=LayerNorm(N2+MultiHead(N2,EncoderOutput,EncoderOutput))
DecoderOutput=LayerNorm(N3+FFN(N3))
5.2.1 掩码多头自注意力(Masked Multi-Head Attention):避免"偷看"未来token
解码器的自回归生成特性决定了:生成第t个token时,只能依赖前t-1个token的信息,不能提前利用第t+1个及以后的token(即"偷看"未来信息),否则会导致模型训练无效、生成序列逻辑混乱。掩码多头自注意力通过在注意力分数计算后添加一个"掩码矩阵",将未来token的注意力分数置为负无穷,经过Softmax归一化后,未来token的注意力权重将趋近于0,从而实现对未来信息的屏蔽。
掩码矩阵分为两种:
- 因果掩码(Causal Mask):用于自回归生成,是一个下三角矩阵,对角线及以下元素为0(允许关注当前及之前的token),上三角元素为负无穷(屏蔽未来token)。例如,序列长度L=3的因果掩码为: \[0, -∞, -∞, 0, 0, -∞, 0, 0, 0]
- 填充掩码(Padding Mask):用于处理长度不一致的批量序列,将填充token(如PAD)的注意力分数置为负无穷,避免模型关注无意义的填充信息。
示例:延续前文的目标序列我, 爱, 中国(对应token序列我, 爱, 中国,长度L=3),其掩码多头自注意力的计算过程如下:
- 生成目标序列的嵌入+位置编码特征Y(维度3,4);
- 生成Q、K、V向量,拆分注意力头(与多头注意力一致);
- 计算注意力分数后,添加因果掩码,将上三角元素置为负无穷: 注意力分数(掩码前)= \[8.5, 9.1, 7.8, 8.6, 9.2, 7.9, 7.3, 7.9, 6.5] 注意力分数(掩码后)= \[8.5, -∞, -∞, 8.6, 9.2, -∞, 7.3, 7.9, 6.5]
- Softmax归一化后,未来token的权重趋近于0,得到注意力权重: Attention_weights = \[1.0, 0.0, 0.0, # 生成"我"时,只关注自身 0.32, 0.68, 0.0, # 生成"爱"时,关注"我"和自身 0.31, 0.58, 0.11]# 生成"中国"时,关注"我""爱"和自身
从权重矩阵可以看出,掩码机制有效屏蔽了未来token的信息,确保生成过程的自回归特性,符合人类语言的生成逻辑(先有主语,再有谓语,最后有宾语)。
5.2.2 交叉注意力(Cross-Attention):关联输入与目标序列
交叉注意力是解码器与编码器建立关联的核心组件,其核心作用是"让目标序列的每个token关注输入序列中与之相关的token",实现"输入理解"与"输出生成"的联动。与自注意力机制不同,交叉注意力的Q来自解码器的掩码自注意力输出(N2),而K和V来自编码器的最终输出(EncoderOutput),即"查询来自目标序列,键和值来自输入序列"。
数学表达如下:
CrossAttention(Q,K,V)=MultiHead(N2,EncoderOutput,EncoderOutput)
示例:假设输入序列为I, love, China,编码器输出的上下文特征EncoderOutput(维度3,4),目标序列为我, 爱, 中国,解码器掩码自注意力输出N2(维度3,4):
- Q = N2(目标序列特征),K = EncoderOutput(输入序列特征),V = EncoderOutput(输入序列特征);
- 计算注意力分数,衡量目标序列token与输入序列token的关联程度: Attention_scores = \[9.2, 8.7, 7.5, # "我"与"I"关联最强(分数9.2) 7.8, 9.3, 7.6, # "爱"与"love"关联最强(分数9.3) 7.4, 7.9, 9.1] # "中国"与"China"关联最强(分数9.1)
- Softmax归一化后,得到注意力权重: Attention_weights = \[0.58, 0.32, 0.10, # "我"主要关注"I" 0.10, 0.59, 0.31, # "爱"主要关注"love" 0.09, 0.31, 0.60] # "中国"主要关注"China"
- 加权求和得到交叉注意力输出C,实现目标序列与输入序列的语义关联,确保生成的目标序列与输入序列语义一致。
交叉注意力的核心价值在于:让解码器明确"目标序列的每个token对应输入序列的哪个token",避免生成与输入无关的内容,这也是机器翻译、文本摘要等Seq2Seq任务能够实现的关键。
5.2.3 解码器前馈神经网络:与编码器的异同
解码器的前馈神经网络与编码器的前馈神经网络结构完全一致,均由两层线性变换和ReLU激活函数组成,维度设置也相同(d_model=512,d_ff=2048),核心作用也是对每个token的特征进行独立的非线性变换,强化目标序列的特征表达。
两者的唯一区别在于输入不同:编码器前馈神经网络的输入是交叉注意力输出的归一化特征(N1),而解码器前馈神经网络的输入是交叉注意力输出的归一化特征(N3),但计算逻辑、参数设置完全独立,确保编码器专注于输入理解,解码器专注于输出生成。
六、核心模块拆解(五):输出层与模型训练
解码器堆叠6层后,输出的特征矩阵维度为L, d_model(L为目标序列长度),需要通过输出层将其映射到词表维度,生成每个token的预测概率,同时通过训练优化模型参数,确保生成的序列准确、连贯。
6.1 输出层:从特征向量到token预测
输出层由线性层和Softmax函数组成,核心流程如下:
- 线性变换:将解码器的输出特征(维度L, d_model)通过线性层映射到词表维度V, 1,其中V是词表大小,得到维度为L, V的logits矩阵;
- Softmax归一化:对logits矩阵的每一行进行Softmax归一化,得到每个token的预测概率(概率之和为1);
- token预测:选择概率最高的token作为当前位置的预测结果,自回归地生成整个目标序列。
数学表达如下:
logits=DecoderOutput×Wout+bout
prob=Softmax(logits)
其中,W_out(维度d_model, V)和b_out(维度V)是可学习的权重和偏置,logits是未归一化的预测分数,prob是归一化后的预测概率。
示例:假设词表大小V=10000,解码器输出特征维度3,512,通过线性层映射到3,10000的logits矩阵,经过Softmax归一化后,得到每个位置的token概率:
prob = \[0.85, 0.01, 0.005, ..., 0.001, # 第一个位置:"我"的概率最高(0.85) 0.01, 0.88, 0.003, ..., 0.001, # 第二个位置:"爱"的概率最高(0.88) 0.008, 0.01, 0.90, ..., 0.001] # 第三个位置:"中国"的概率最高(0.90)
此时,模型将预测出序列我, 爱, 中国,与目标序列一致,说明模型训练有效。
6.2 Transformer的训练细节
Transformer的训练核心是最小化预测序列与目标序列的误差,常用的损失函数为交叉熵损失(Cross-Entropy Loss),同时结合优化器、学习率调度等策略,确保模型稳定收敛。
6.2.1 损失函数:交叉熵损失
交叉熵损失用于衡量预测概率分布与真实标签分布的差异,公式如下:
Loss=−L1∑t=1L∑v=1Vyt,vlog(probt,v)
其中,y_{t,v}是目标序列第t个位置的独热编码(真实标签,只有目标token的位置为1,其余为0),prob_{t,v}是模型预测的第t个位置、第v个token的概率,L是目标序列长度。
例如,目标序列第t个位置的真实token是"爱"(词表中索引为100),则y_{t,100}=1,其余y_{t,v}=0,损失函数将重点惩罚"爱"的预测概率过低的情况,推动模型优化参数,提高预测准确性。
6.2.2 优化器与学习率调度
论文中使用的优化器是Adam优化器,参数设置为:学习率初始值lr=1e-4,β1=0.9,β2=0.98,ε=1e-9。Adam优化器能够自适应调整每个参数的学习率,有效避免梯度消失或爆炸,加速模型收敛。
学习率调度采用"线性预热+线性衰减"策略:
- 预热阶段:前warmup_steps步(论文中设置为4000步),学习率从0线性增加到初始学习率1e-4,避免初始学习率过高导致模型不稳定;
- 衰减阶段:预热结束后,学习率从初始值线性衰减到0,避免训练后期学习率过高导致过拟合。
6.2.3 防止过拟合的策略
Transformer模型参数庞大(论文中约有1.1亿个参数),容易出现过拟合,因此采用了以下三种防止过拟合的策略:
- Dropout:在词嵌入、位置编码、注意力机制、前馈神经网络等模块中添加Dropout层,dropout概率设为0.1,随机丢弃部分特征,增强模型泛化能力;
- 标签平滑(Label Smoothing):将真实标签的独热编码进行平滑处理,例如将目标token的概率从1调整为0.9,其余token的概率平均分配为0.1/(V-1),避免模型过度自信,提高泛化能力;
- 批量归一化(Batch Normalization):部分变体中会在层归一化的基础上添加批量归一化,进一步稳定训练过程,减少过拟合风险。
七、Transformer变体与大模型应用
原始Transformer架构提出后,研究者基于其核心思想,衍生出了众多变体,适配不同的任务场景,成为当今主流大模型的底层架构。这些变体的核心差异在于"编码器、解码器的使用方式"和"注意力机制的优化",下面重点介绍三种最具代表性的变体及其在大模型中的应用。
7.1 编码器-only架构:双向理解模型(代表:BERT)
编码器-only架构仅使用Transformer的编码器部分,堆叠多层编码器,通过双向自注意力机制捕捉输入序列的上下文信息,适用于自然语言理解(NLU)任务,如文本分类、情感分析、命名实体识别、问答等。
BERT(Bidirectional Encoder Representations from Transformers)是编码器-only架构的典型代表,其核心改进的是:
- 双向注意力:原始Transformer编码器的自注意力本就是双向的,但BERT通过"掩码语言模型"(MLM)预训练任务,进一步强化了双向上下文的学习------随机掩盖输入序列中的部分token,让模型预测被掩盖的token,迫使模型学习token间的双向关联;
- 句子对任务:添加"句子对分类"预训练任务,让模型学习两个句子之间的关系(如是否为同义句、是否存在因果关系),提升模型的上下文理解能力。
示例:BERT处理"我喜欢中国"这句话时,通过双向自注意力,"喜欢"既能关注到主语"我",也能关注到宾语"中国",同时能捕捉到"我"与"中国"之间的关联,比单向模型更能理解句子的完整语义。目前,BERT的变体(如RoBERTa、ALBERT)广泛应用于各种NLU任务,是自然语言理解领域的基础模型。
7.2 解码器-only架构:自回归生成模型(代表:GPT系列)
解码器-only架构仅使用Transformer的解码器部分,堆叠多层解码器,通过掩码自注意力机制实现自回归生成,适用于自然语言生成(NLG)任务,如文本生成、对话生成、代码生成、机器翻译(自回归式)等。
GPT(Generative Pre-trained Transformer)系列是解码器-only架构的典型代表,其核心改进的是:
- 单向注意力:GPT的掩码自注意力仅允许关注当前及之前的token,强化自回归生成特性,更符合人类语言的生成逻辑(从左到右);
- 预训练-微调范式:通过"自回归语言建模"(LM)预训练任务,让模型学习文本的生成规律,再通过微调适配具体的生成任务;
- 规模扩展:从GPT-1(1.17亿参数)到GPT-4(千亿级参数),通过增加模型参数、扩大训练数据,大幅提升模型的生成能力和泛化能力。
示例:GPT生成"我喜欢中国,因为"这句话时,会基于"我喜欢中国"的上下文,自回归地生成后续内容(如"它有着悠久的历史和灿烂的文化"),生成的内容连贯、符合逻辑,这得益于解码器的掩码自注意力和大规模预训练。目前,GPT系列、LLaMA系列、ChatGLM系列等主流对话大模型,均采用解码器-only架构。
7.3 编码器-解码器架构:Seq2Seq模型(代表:T5、BART)
完整的编码器-解码器架构保留了Transformer的编码器和解码器,适用于序列到序列(Seq2Seq)任务,如机器翻译、文本摘要、文本改写、语音转文字等,核心优势是能够实现"输入序列"到"输出序列"的精准映射。
T5(Text-to-Text Transfer Transformer)是编码器-解码器架构的典型代表,其核心改进的是:
- 统一任务范式:将所有自然语言任务(包括NLU和NLG)统一转换为"文本到文本"的形式,例如文本分类任务将"情感分析:我喜欢中国"转换为输出"正面",机器翻译任务将"翻译:I love China"转换为输出"我喜欢中国",简化了模型的训练和适配过程;
- 多任务预训练:通过大规模多任务预训练,让模型学习不同任务的共性规律,提升模型的泛化能力和适配能力。
示例:T5处理机器翻译任务"翻译:I love China"时,编码器先对输入序列"I love China"进行编码,捕捉其语义信息,解码器再通过交叉注意力关注编码器的输出,自回归地生成目标序列"我喜欢中国",实现输入与输出的精准映射。BART(Bidirectional and Auto-Regressive Transformers)则在T5的基础上,增加了文本降噪预训练任务,进一步提升了模型的文本生成和改写能力。
八、总结:Transformer架构的核心价值与未来展望
Transformer架构以"自注意力机制"为核心,通过并行计算解决了RNN系列模型的效率瓶颈,通过多头注意力、位置编码等创新设计,高效捕捉长距离依赖,成为当今大模型的底层基石。其核心价值在于:
- 并行计算效率高:完全抛弃循环结构,序列中所有token可并行计算,训练和推理速度远快于RNN系列模型,能够支撑大规模数据和大规模参数的训练;
- 长距离依赖捕捉能力强:自注意力机制可直接捕捉序列中任意两个token的关联,无需依赖中间token的传递,解决了RNN梯度消失的问题,能够处理长文本(如上千token的文章、对话);
- 灵活性强:通过调整编码器、解码器的使用方式,可适配NLU、NLG、Seq2Seq等多种任务,衍生出众多变体,满足不同场景的需求;
- 可扩展性强:通过增加模型参数、堆叠层数、扩大训练数据,可不断提升模型的表达能力,从千万级参数的基础模型,扩展到千亿级、万亿级参数的大模型(如GPT-4、PaLM)。
未来,Transformer架构的发展方向主要集中在三个方面:
- 效率优化:通过稀疏注意力、量化、蒸馏等技术,降低模型的计算成本和显存占用,让大模型能够在普通设备上运行;
- 能力提升:通过多模态融合(文本、图像、语音、视频),让模型能够处理多模态数据,实现更全面的理解和生成;
- 可解释性增强:目前Transformer的注意力机制虽能提供一定的可解释性(如注意力权重可查看token间的关联),但整体仍属于"黑箱模型",未来将进一步提升模型的可解释性,让模型的决策过程更透明。
从2017年《Attention Is All You Need》论文发表,到如今GPT-4、LLaMA等大模型的普及,Transformer架构仅用短短几年时间,就重塑了自然语言处理乃至人工智能领域的格局。理解Transformer的核心原理,不仅能帮助我们更好地使用大模型,更能为后续的模型优化和创新提供基础------未来,基于Transformer的大模型将在更多领域落地,成为推动人工智能发展的核心力量。