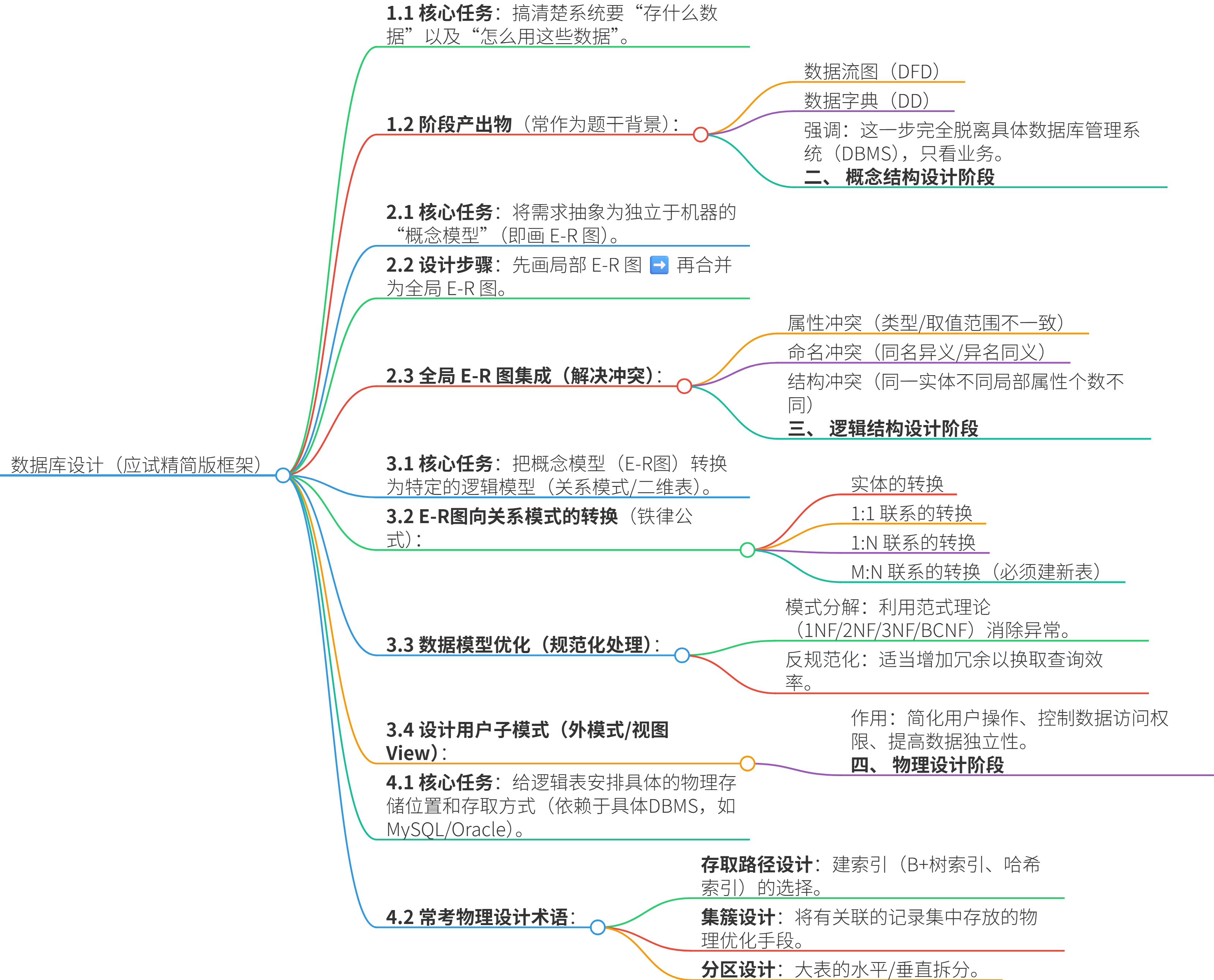
数据库设计
参考资料:
深入理解数据库物理设计:索引、存储结构与聚簇,B+树与Hash索引的存取
数据库系统概论(二)数据库设计--数据库物理设计--存取结构、索引、聚簇、存储结构 - 幽灵化石 - 博客园
目录
[一、 需求分析阶段](#一、 需求分析阶段)
[二、 概念结构设计阶段](#二、 概念结构设计阶段)
[三、 逻辑结构设计阶段](#三、 逻辑结构设计阶段)
[1. 模式优化的宏观博弈(反规范化)](#1. 模式优化的宏观博弈(反规范化))
[2. 外模式设计(用户子模式 / 视图 View)](#2. 外模式设计(用户子模式 / 视图 View))
[四、 物理设计阶段](#四、 物理设计阶段)
一、 需求分析阶段
核心定位
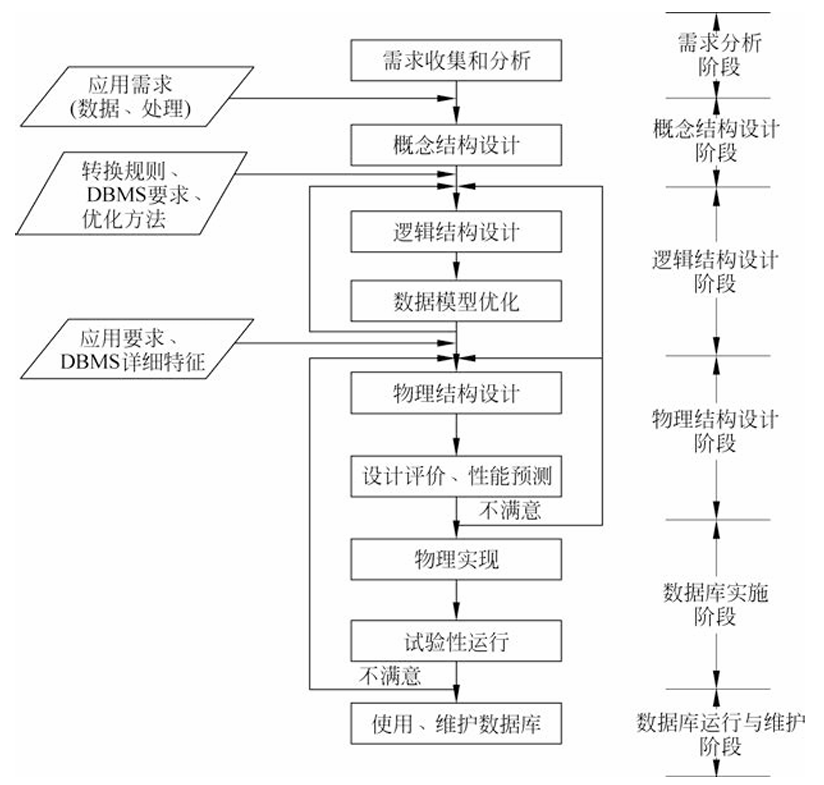
这是整个数据库设计的"原料采购期"。
在这个阶段,完全不需要考虑数据库(比如MySQL、Oracle)长什么样。
阶段产出物
就是在前面学过的 数据流图(DFD) 和 数据字典(DD)。
它们是下一步画E-R图的唯一依据。
二、 概念结构设计阶段
核心动作
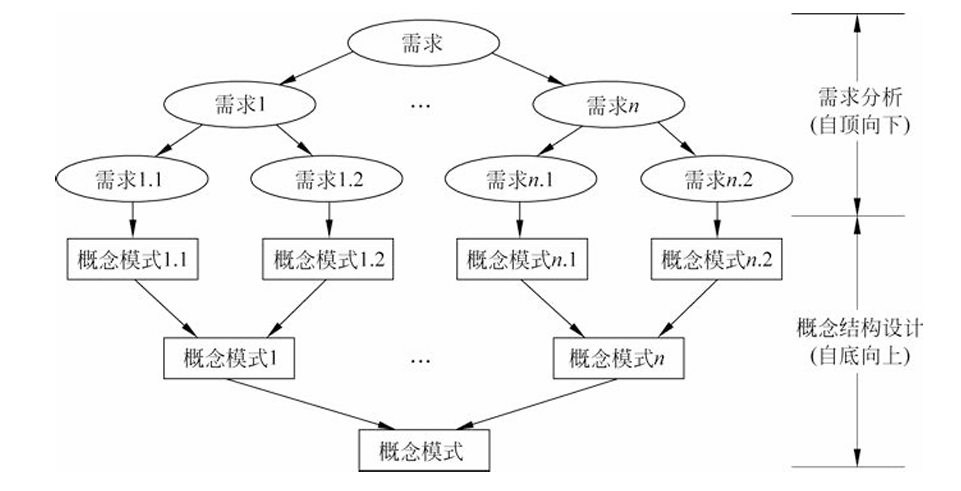
把需求抽象为E-R图。
在实际开发中,通常是不同业务员各自画自己的"局部E-R图",最后要拼成一张"全局E-R图"。
属性冲突(底层格式打架)
表现:同一个东西,规定的类型或长度不一样。比如A部门说"工号"是数字型,B部门说"工号"是字符型;或者A叫"出生日期",B叫"生日"。
解决:开个会,统一标准。
命名冲突(名字打架)
同名异义:名字一样,意思不同。比如财务子系统的"单位"指"元/角/分",人事子系统的"单位"指"部门"。(解决:改成"货币单位"和"所属部门")。
异名同义:意思一样,名字不同。比如"顾客"和"客户"、"产品"和"商品"。(解决:统一成一个名字)。
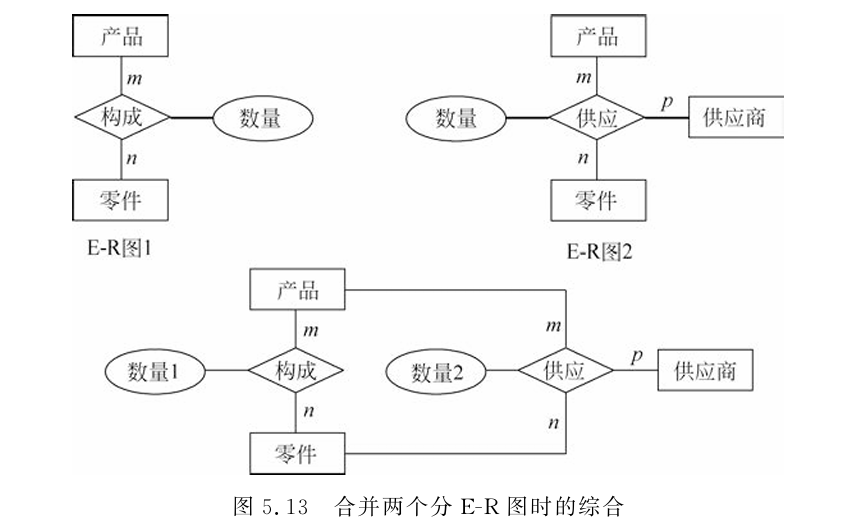
结构冲突(结构打架)
表现:同一个实体,在不同局部E-R图里包含的属性个数不一样;或者同一个联系,在A图里是1:N,在B图里被拆成了M:N。
解决:取属性的并集;或者对联系进行重新构思和合并。
三、 逻辑结构设计阶段
逻辑设计部分:数据设计 - 软考备战(五十)-CSDN博客

1. 模式优化的宏观博弈(反规范化)
为了提高查询效率,减少多表连接操作。
这是典型的"空间换时间"。
2. 外模式设计(用户子模式 / 视图 View)
本质
视图是一张"虚拟表",它不存真实数据,只是存了一段查询SQL语句。
为什么要有视图?
简化用户操作
把复杂的3表联合查询打包成一个视图,用户直接 SELECT * FROM 视图 就行,当傻子一样用。
提高数据安全性(控制权限)
员工表有工资字段,创建一个不含工资的视图给普通员工查,实现列级保密。
提高逻辑独立性
如果底层的"基表"结构改了(比如把一个表拆成了两个表),只需要修改一下视图里的SQL定义,外面的应用程序一行代码都不用改!
四、 物理设计阶段
核心定位
给逻辑表安排具体的硬盘存储方式和加速策略。
存取路径设计(建索引)
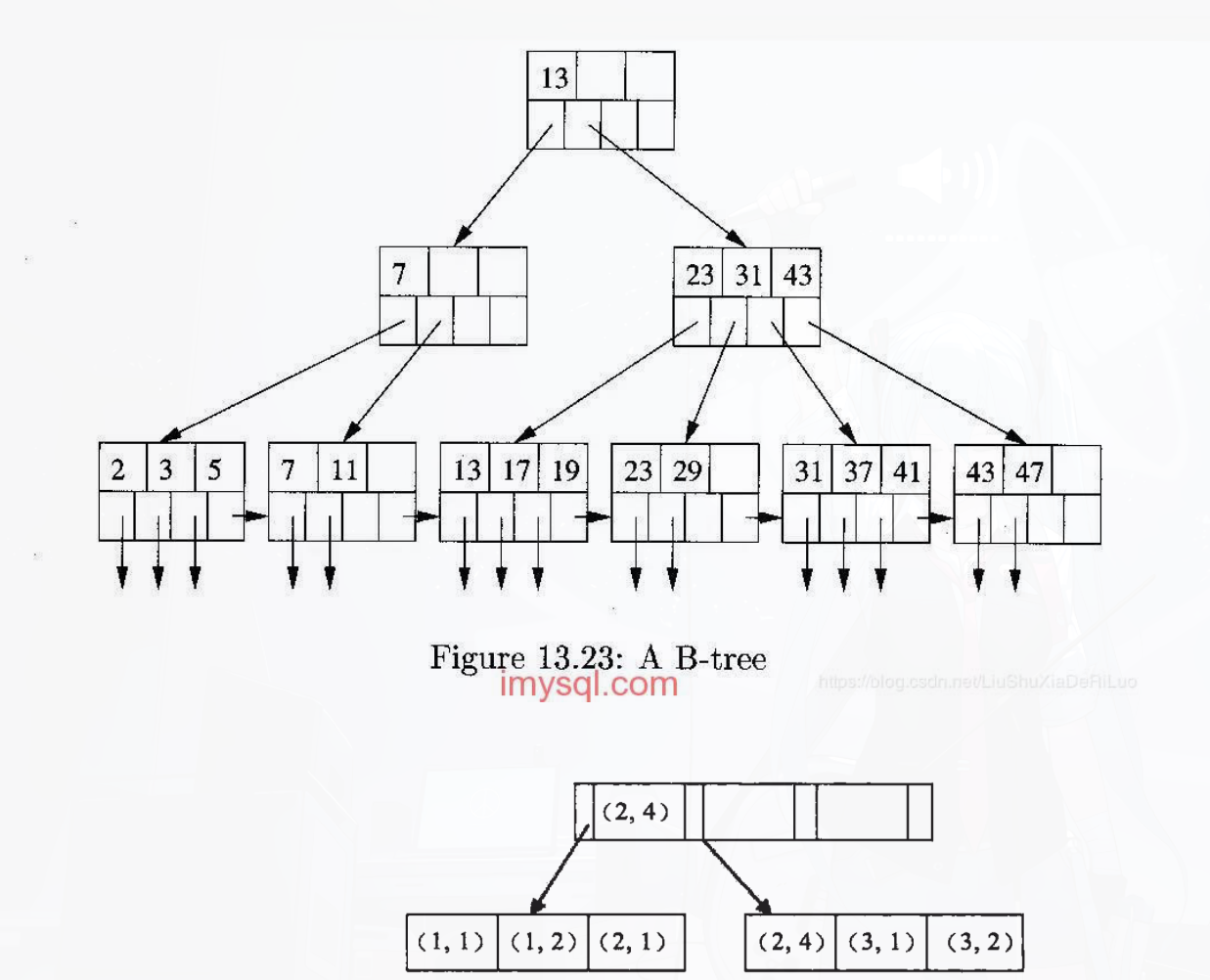
B+树索引
最常用的索引。
不仅适合等值查询(id = 10),还特别适合范围查询(age BETWEEN 20 AND 30)和排序。
哈希索引
只适合精确的等值查询(id = 10),绝对不能用于范围查询或排序,但速度极快。
集簇设计
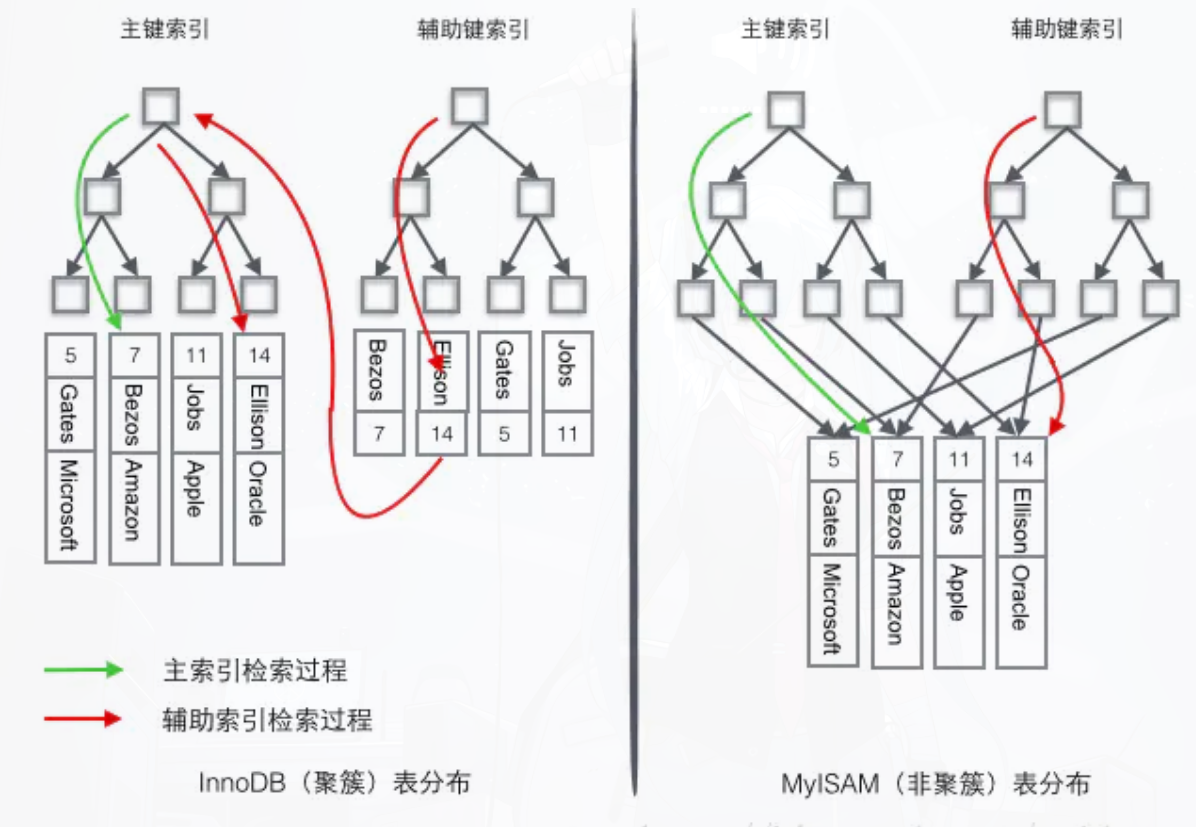
概念
把经常一起查询的记录,在物理磁盘上尽量放在相邻的簇块里。
比如查员工时经常要查他的简历,就把员工记录和简历记录物理上绑在一起。
代价
因为物理绑死了,所以如果只查员工不查简历,反而会浪费I/O;且修改关联关系时代价极大。
分区设计
概念
当一张表大到千万级以上,按某种规则拆分存储。
水平分区
按行拆。比如按月份把订单表拆成12个小表。
垂直分区
按列拆。把一张宽表(有100个字段)拆成两张表,把不常用的字段(如大文本备注)单独拎出去。