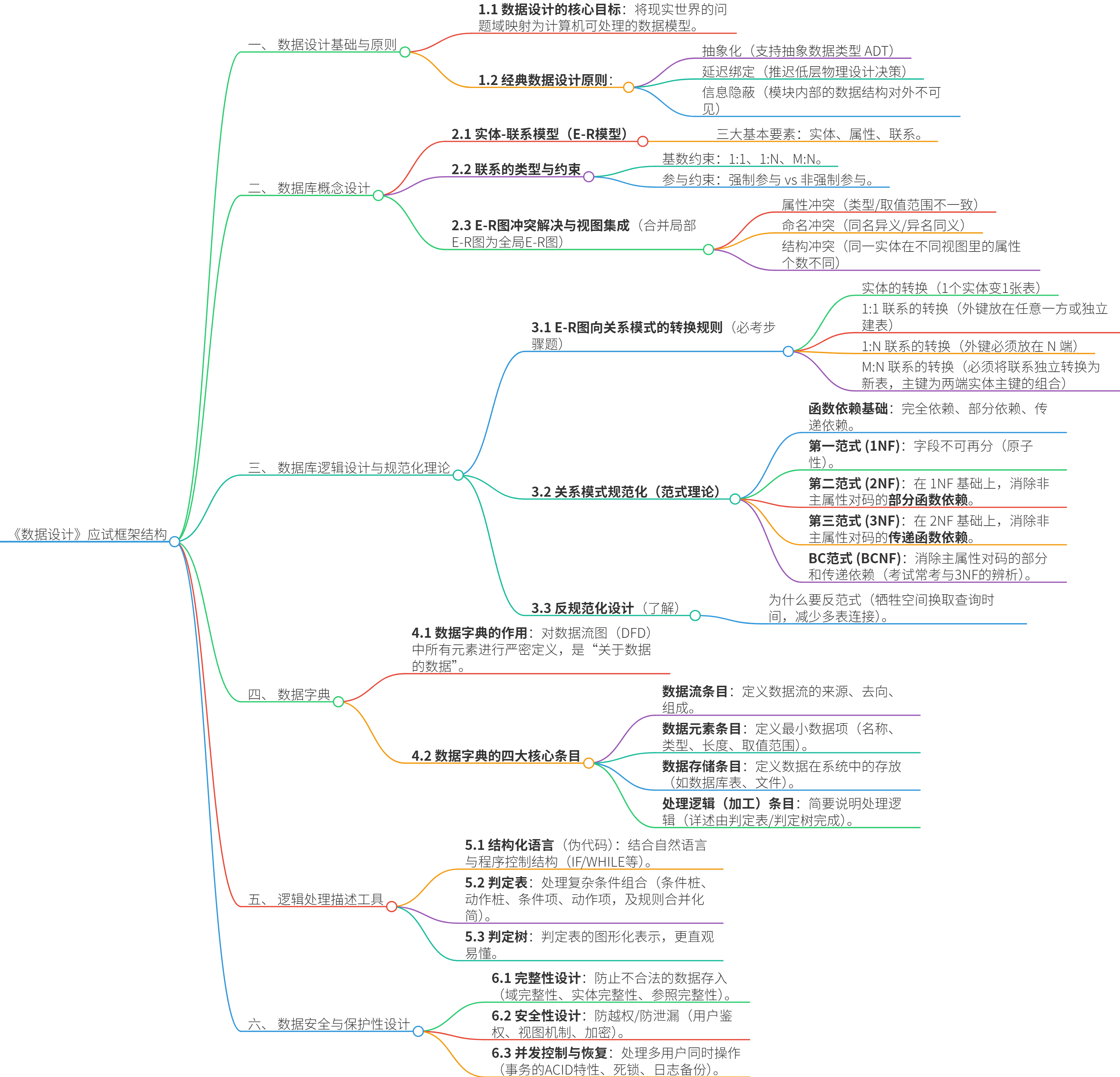
数据设计
目录
[一、 数据设计基础与原则](#一、 数据设计基础与原则)
[1.1 数据设计的核心目标(理解宏观全貌)](#1.1 数据设计的核心目标(理解宏观全貌))
[1.2 数据设计的"三大核心原则"](#1.2 数据设计的“三大核心原则”)
[1. 抽象化原则 ------抽象数据类型(ADT)](#1. 抽象化原则 ——抽象数据类型(ADT))
[2. 信息隐蔽原则 ------ 模块内部数据私有化](#2. 信息隐蔽原则 —— 模块内部数据私有化)
[3. 延迟绑定(推迟决策)原则 ------ 先逻辑,后物理](#3. 延迟绑定(推迟决策)原则 —— 先逻辑,后物理)
[二、 数据库概念设计](#二、 数据库概念设计)
[2.1 三大基本要素:找准"词性"](#2.1 三大基本要素:找准“词性”)
[2.2 联系的类型与约束](#2.2 联系的类型与约束)
[1. 基数约束(1:1、1:N、M:N)](#1. 基数约束(1:1、1:N、M:N))
[2. 参与约束](#2. 参与约束)
[2.3 E-R图冲突解决与视图集成](#2.3 E-R图冲突解决与视图集成)
[三、 数据库逻辑设计与规范化理论](#三、 数据库逻辑设计与规范化理论)
[3.1 E-R图向关系模式的转换规则](#3.1 E-R图向关系模式的转换规则)
[1. 实体的转换(最简单)](#1. 实体的转换(最简单))
[2. 1:1(一对一)联系的转换](#2. 1:1(一对一)联系的转换)
[3. 1:N(一对多)联系的转换](#3. 1:N(一对多)联系的转换)
[4. M:N(多对多)联系的转换](#4. M:N(多对多)联系的转换)
[3.2 关系模式规范化](#3.2 关系模式规范化)
[第一范式 (1NF):不可再分(原子性)](#第一范式 (1NF):不可再分(原子性))
[第二范式 (2NF):消除"部分依赖"](#第二范式 (2NF):消除“部分依赖”)
[第三范式 (3NF):消除"传递依赖"](#第三范式 (3NF):消除“传递依赖”)
[(附加) BCNF范式:了解即可](#(附加) BCNF范式:了解即可)
[3.3 反规范化设计](#3.3 反规范化设计)
[四、 数据字典](#四、 数据字典)
[4.1 数据字典的四大核心条目](#4.1 数据字典的四大核心条目)
[4.2 数据字典的符号](#4.2 数据字典的符号)
[五、 逻辑处理描述工具](#五、 逻辑处理描述工具)
[5.1 结构化语言(伪代码)](#5.1 结构化语言(伪代码))
[5.2 判定表](#5.2 判定表)
[5.3 判定树](#5.3 判定树)
一、 数据设计基础与原则
1.1 数据设计的核心目标(理解宏观全貌)
数据设计的本质,就是做一个"翻译官",把现实世界中乱七八糟的业务数据,翻译成计算机能存、能算的结构。
数据模型的层次具体内容链接:数据模型与关系理论 - 软考备战(三十)-CSDN博客
这个过程在软件工程中分为经典的"三步走":
概念设计
脱离任何具体数据库软件,用"E-R图"画出业务实体和关系(面向现实世界)。
逻辑设计
把E-R图转换成"关系模式"(也就是一张张二维表),并进行"范式优化"(面向关系模型)。
物理设计
决定表里字段用什么数据类型(int/varchar)、建什么索引、存哪个磁盘(面向具体DBMS,如MySQL/Oracle)。
1.2 数据设计的"三大核心原则"
1. 抽象化原则 ------抽象数据类型(ADT)
数据设计不能一上来就定死用 int 还是 char,而是要先把它抽象成一个"抽象数据类型"。
ADT的本质:数据结构 + 操作的封装体。它只定义"能存什么数据、能对这些数据做什么操作",绝不规定底层怎么实现。
2. 信息隐蔽原则 ------ 模块内部数据私有化
一个模块内部的数据结构细节,必须对其他模块隐藏起来。
其他模块不能直接改这个模块的数据,只能通过这个模块提供的"公开接口(方法)"来访问。
目的:一旦底层数据结构改了(比如把数组换成链表),只要接口不变,别的模块一行代码都不用改(完美契合"高内聚低耦合")。
3. 延迟绑定(推迟决策)原则 ------ 先逻辑,后物理
概念:在做逻辑设计时,严禁过早介入物理细节。
你先只管把"用户表、订单表"的逻辑关系理顺,不要在这个阶段去纠结"这个字段加不加索引""用不用分表"。
这些物理层面的决策,必须推迟到"物理设计"阶段再根据实际性能需求决定。
在需求阶段就确定了具体的数据库存储格式,这就是违背了延迟绑定原则。
二、 数据库概念设计
2.1 三大基本要素:找准"词性"
画E-R图的第一步,不是拿笔就画,而是拿笔在题干上圈词。
记住这个"找词法则":
实体
独立存在的名词。
特征:它不仅能存在,而且通常有一个唯一的编号(主键)。
做题识别:题干里的"员工"、"客户"、"商品"、"病房"。(注意:"性别"、"颜色"这种不能独立存在的词,绝对不是实体)。
图形:矩形。
属性
依附于实体的修饰词。
特征:它不能脱离实体单独存在,通常用来描述实体的特征。
做题识别:员工的"姓名"、商品的"价格"、订单的"日期"。
图形:椭圆。
联系(关系)
连接两个实体的动词。
特征:描述实体之间发生了什么事。
做题识别:员工"属于"部门、客户"下"订单、学生"选"课程。
图形:菱形。
2.2 联系的类型与约束
找到菱形(联系)后,还要在菱形旁边标上数字(1, m, n)。
必须学会翻译题干里的"限制性形容词"。
1. 基数约束(1:1、1:N、M:N)
1:1(一对一)
题干暗示词 ------ "唯一"、"仅对应"。
例:一个班级只有一个班主任,一个班主任只带一个班级。
1:N(一对多)
题干暗示词 ------ "多个"、"若干"、"最多"。
例:一个部门有若干员工,一个员工只能属于一个部门。(记住:谁是"多个",谁就是 N)。
M:N(多对多)
题干暗示词 ------ "多个...多个..."、"不同...不同..."。
例:一个学生可以选多门课程,一门课程可以被多个学生选修。
2. 参与约束
这决定了实体和联系之间的连线是实线还是虚线(有些题目用单线/双线表示):
强制参与(全参与)
题干暗示词 ------ "必须"、"至少一个"、"每个"。
例:"每个员工必须属于一个部门"。说明没有"流浪员工",连线画实线/双线。
非强制参与(部分参与)
题干暗示词 ------ "可以"、"可能"、"或"。
例:员工"可以"拥有笔记本电脑。说明有的员工没电脑,连线画虚线/单线。
2.3 E-R图冲突解决与视图集成
在实际大型系统开发中,不同业务员各自画局部的E-R图,最后要拼成一张总图,这时候就会"打架"。
属性冲突(最底层)
同一个东西,规定不一样。
比如:A图里"学号"是字符串,B图里"学号"是整数;或者A叫"出生年月",B叫"生日"。
解决:统一标准。
命名冲突(同义/异义)
名字一样但意思不同,或者意思一样但名字不同。
比如:A图的"单位"指长度(米),B图的"单位"指部门。
解决:改名区分。
结构冲突(最难搞)
同一个实体,在两张图里的结构不一样。
比如:"学生"在A图里只有"姓名"属性,在B图里被拆成了"本科生"和"研究生"两个实体。(解决:取并集或重构)。
三、 数据库逻辑设计与规范化理论
参考资料:数据库设计.pdf
3.1 E-R图向关系模式的转换规则
把画好的E-R图变成实际的数据库表(关系模式),有且仅有以下4条铁律。
记住口诀:实体直接变,联系看连边。
具体内容链接:数据库设计学习文档_数据库设计文档-CSDN博客
1. 实体的转换(最简单)
一个实体直接转换成一张表(关系模式)。
实体的属性就是表的列(字段),实体的标识符就是表的主键。
矩形员工(属性:工号、姓名、部门) ➡️ 表:员工(工号, 姓名, 部门),主键是:工号。
2. 1:1(一对一)联系的转换
规则:将外键放在任意一方的表中,或者单独建一张表。
做题策略:考试时,如果题目没特殊要求,优先把外键加在"弱实体"或"从属实体"那一方。
例:员工与工位(1:1)。
转换后:员工(工号, 姓名, 工位号) 或者 工位(工位号, 位置, 员工工号)
只要在一个表里加上对方的主键作为外键即可。

3. 1:N(一对多)联系的转换
规则:将外键必须放在 N 端(也就是"多"的那一方) 的表中。
例:部门与员工(1:N)。一个部门多个员工。
部门表:部门(部门号, 部门名) ------ 主键:部门号。
员工表:员工(工号, 姓名, 所属部门号) ------ 主键:工号,外键:所属部门号。
注意:绝对不能在"部门表"里加一个"员工工号"字段,因为部门不可能只有一个员工!

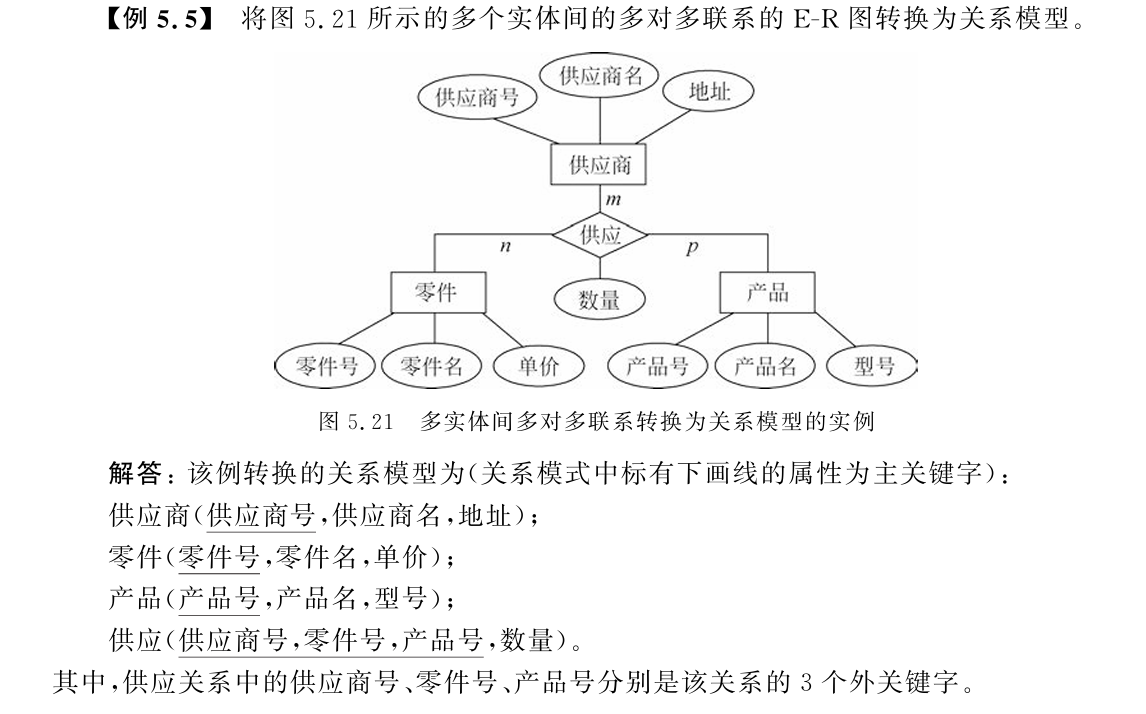
4. M:N(多对多)联系的转换
规则:必须将联系单独转换成一张新表(交叉表)!这张新表的主键,是原来两端实体主键的组合。
例:学生与课程(M:N)。
学生表:学生(学号, 姓名) ------ 主键:学号。
课程表:课程(课程号, 课程名) ------ 主键:课程号。
选课表(新建):选课(学号, 课程号, 成绩) ------ 主键:(学号, 课程号),外键分别是学号、课程号。
注意:
千万不要试图在"学生表"里加"课程号"字段,因为一个学生选多门课,字段根本存不下!
新表里的"成绩"就是联系自带的属性,别忘了写。
3.2 关系模式规范化
具体内容链接:数据模型与关系理论 - 软考备战(三十)-CSDN博客
范式就是"防呆标准"。
等级越高,数据冗余越少,但查数据可能越麻烦(要拼表)。
前置常识:两个角色
码(候选键/主键)
能唯一标识一行数据的字段(比如:学号,或者 (学号, 课程号) 组合)。
非主属性
除了"码"之外的其他所有字段(比如:姓名、成绩、系主任)。
第一范式 (1NF):不可再分(原子性)
表里的每一个格子,只能填一个值,不能填一堆值。
违规样例:员工(工号, 姓名, 联系电话),如果联系电话格子里填了 13800000000, 021-12345678(两个号码),就违背了1NF。
怎么改:把电话拆成两行,或者拆成两张表。
第二范式 (2NF):消除"部分依赖"
在组合主键的情况下,所有的"非主属性"必须完整地依赖整个组合主键,不能只依赖组合主键里的"某一部分"。
致命前提:如果表只有一个字段做主键,它天生就满足2NF!(因为没法被"部分"依赖)。
违规样例:选课(学号, 课程号, 姓名, 成绩)。
主键是:(学号, 课程号)。
"成绩"依赖整个主键(只有学了这门课才有这门课的成绩)------ 合法。
"姓名"只依赖"学号",跟"课程号"半毛钱关系都没有 ------ 部分依赖,违背2NF!
怎么改(拆表):把部分依赖的剥出去。
拆成:学生(学号, 姓名) 和 选课(学号, 课程号, 成绩)。
第三范式 (3NF):消除"传递依赖"
非主属性不能"接力"。
也就是:A决定B,B决定C,那A就传递决定了C。
这不行!非主属性必须直接依赖主键。
违规样例:学生(学号, 姓名, 系名, 系主任)。
主键是:学号。
学号 → 姓名(直接依赖,合法)
学号 → 系名(直接依赖,合法)
系名 → 系主任(学号决定了系名,系名又决定了系主任,传递依赖,违背3NF!)
怎么改(拆表):把传递依赖的链条斩断,单独建表。
拆成:学生(学号, 姓名, 系名) 和 系(系名, 系主任)。
(附加) BCNF范式:了解即可
比3NF更严格。
3NF只管"非主属性"不传递依赖,BCNF连"主属性"也不许传递依赖。 "消除了主属性的传递依赖"------BCNF。
3.3 反规范化设计
概念
故意打破范式,把拆开的表重新合并,或者增加冗余字段。
为什么这么干
因为范式级别越高,表拆得越碎,查询的时候就需要大量 JOIN(连接) 操作,导致查询速度极慢。
本质
用"空间(多存点冗余数据)"换"时间(提高查询速度)"。
比如在订单表里冗余存一个"商品名称",这样查订单时就不用去连商品表了。
四、 数据字典
数据字典(Data Dictionary,简称DD)是数据流图(DFD)的"配词表"。
具体内容链接:主要软件开发方法 - 软考备战(二十四)-CSDN博客
DFD只画了框和箭头,框里存什么、箭头传什么,全靠DD来解释。 它本质上是"关于数据的数据"(元数据)。
4.1 数据字典的四大核心条目
数据流条目
解释DFD上的箭头。
内容:数据流的名称、来源、去向、组成(由哪些数据元素构成)。
例:订货单 = 订单号 + 客户名 + {商品名 + 数量}
数据元素条目
解释最小不可分割的数据项。
内容:名称、类型、长度、取值范围。
例:订单号:字符型,长度10,由字母和数字组成。
数据存储条目
解释DFD上的双横线(数据库/文件)。
内容:存储的名称、编号、流入/流出的数据流、数据结构描述、主键。
例:D1 订单表:存储所有历史订单,主键为订单号。
数据加工(处理逻辑)条目
解释DFD上的圆角矩形或圆形。
内容:加工的编号、激发条件、输入/输出、处理逻辑的简要说明(详细说明由判定表/树完成)。
4.2 数据字典的符号
DD里描述数据组成时,有一套严密的符号系统,看到符号要能翻译成中文:
= :等价于,定义为(由...组成)。
- :与,表示顺序连接(比如 A + B 就是既有A又有B)。
... 或 | :或,表示从多个选项中选一个(比如 男\|女)。
{...} :重复,表示大括号里的内容可以出现多次(比如 {商品名+数量} 表示可以买多件商品)。
(...) :可选,表示括号里的内容可以有也可以没有。
五、 逻辑处理描述工具
详细描述数据加工过程,当DFD里的某个加工逻辑比较复杂时,就用它们来细化。
5.1 结构化语言(伪代码)
外层用自然语言,内层用极其严格的程序控制结构(IF-ELSE、WHILE、CASE)。
适用场景:包含顺序执行和简单判断的逻辑。
做题特征:看到一大段带缩进的"如果...否则..."、"当...时...",那就是结构化语言。
5.2 判定表
判定表具体内容链接:测试用例设计 - 软考备战(四十八)-CSDN博客
当条件太多、且条件之间互相组合时,用IF-ELSE会写出几百行,这时候必须上判定表。
四象限结构
左上(条件桩):列出所有条件(如:会员?金额>100?)。
右上(条件项):针对每条规则,打出 Y(是)或 N(否)。
左下(动作桩):列出所有可能执行的动作(如:打8折、送积分)。
右下(动作项):打 X 表示该规则下要执行这个动作。
判定表的化简(合并规则)
无关条件:如果某个条件无论取Y还是N,都不影响最终的动作,那么这个条件位就可以画横杠 -,表示"无所谓"。
合并规则:如果两列(两条规则)除了一个是Y一个是N,其他全一样,且动作也完全一样,这两列就可以合并成一列(变成 -)。这是软考最常见的考法:给你一个满的判定表,让你选化简后的正确版本。
5.3 判定树
本质:判定表的"图形化翻译"。
长得像一棵倒挂的树,左边是树根(条件),中间是树枝(判断分支),右边是树叶(最终动作)。
适用场景:给非技术人员(比如业务员、客户)看,最直观。但不适合做复杂条件的化简(树太大会乱)。
三者选择口诀
简单顺序 ➡️ 结构化语言
条件复杂且需化简/严谨 ➡️ 判定表
给客户看/要直观 ➡️ 判定树