背景
最近在项目中使用 docker-compose 部署 Kafka 时,遇到一个问题:执行 docker-compose down && docker-compose up -d 后,之前创建的所有 Topic 和消息全部丢失。
在此前部署的基础上(相关记录:1、2),继续探索,解决这个数据持久化的问题。经过这次系统性的排查和多次实验,我终于找到了一套完整、可靠的解决方案。本文完整记录整个排错过程、原因分析以及最终的 docker-compose 配置。
一、问题现象
-
数据丢失 :使用
wurstmeister/kafka镜像,默认配置下执行docker-compose down && docker-compose up -d后,Kafka 就像"全新安装"一样,之前创建的主题和消息全部消失。尝试挂载目录。 -
挂载目录异常 :按照常规思路将 Kafka 的数据目录挂载到宿主机(例如
./kafka-data:/kafka),但每次重启后容器内会出现kafka-logs-{随机值}这样的目录,且每次重启该随机数都不同,导致消息并没有真正写入预期的持久化路径。 -
消费者报错 :经过过载目录调整后,Kafdrop 工具能看到 Topic 和消息,但原本正常的消费者却开始报错:
json{"error": "kafka server: Request was for a consumer group that is not coordinated by this broker.", "trace_id": ""}执行
kafka-consumer-groups.sh --bootstrap-server kafka:9093 --group <组名> --describe时出现:CoordinatorNotAvailableException: The coordinator is not available
二、根本原因分析
2.1 数据丢失 & 目录随机变化 → broker.id 未固定
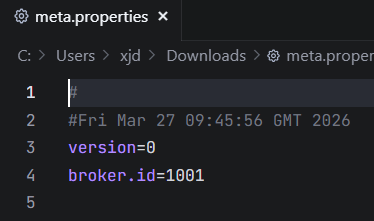
Kafka Broker 启动时需要在 ZooKeeper 中注册一个全局唯一的 broker.id。如果未在环境变量中显式设置 KAFKA_BROKER_ID,wurstmeister/kafka 镜像会自动生成一个新的 ID(通常是一个较大的随机数,如 1017、1018)。
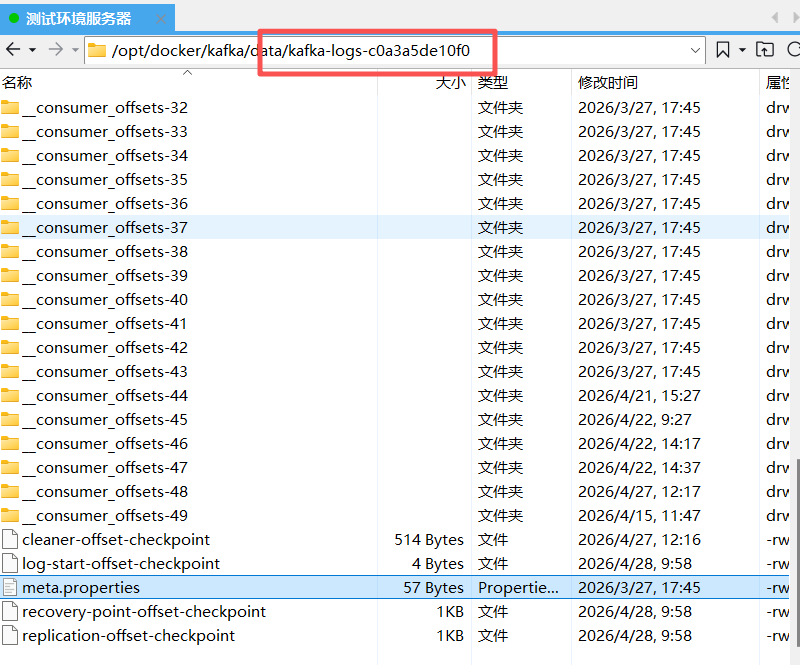
- Kafka 的每个数据目录中都包含
meta.properties文件,其中记录了该目录所属的broker.id。 - 当重启后
broker.id发生变化时,新的 Broker 会认为自己是全新节点,于是创建一个新的数据目录(如kafka-logs-<新随机值>),而旧的数据目录被完全忽略。 - 这就解释了为什么挂载卷中会出现非预期的子目录,以及消息为什么会"丢失"(数据其实还在,只是未被加载)。
比如,测试环境服务器部署时的情况:
2.2 消费者组协调失败 → broker.id 变化导致元数据错乱
Kafka 的消费者组协调器(Group Coordinator)是根据 group.id 的哈希值与集群中存活的 broker.id 列表通过一致性哈希确定的。当 broker.id 频繁变化时:
- ZooKeeper 中记录的消费者组信息和偏移量仍然指向旧的
broker.id,但新的 Broker 无法认领这些组。 - 客户端在查找协调器时,得到的是已经失效的 Broker 地址或根本不存在的 Broker,因此抛
not coordinated by this broker和CoordinatorNotAvailableException。
2.3 一个小疑惑:集群部署时如何动态分配?
在排查过程中,我有一个疑问:如果手动固定 broker.id,那么多节点集群部署时,难道要由运维人员逐一规划 ID 吗?动态扩容怎么办?
查阅官方文档和社区实践后,我明白了:
broker.id本质上是集群中每个 Broker 的"身份证号",必须全局唯一且长期稳定。集群部署时,通常会提前规划好 ID 范围(例如从 0 到 N-1),并在配置文件中固定下来。- 自动生成机制(
broker.id.generation.enable=true)更多用于临时测试环境或快速拉起集群的场景。但它生成的 ID 虽然唯一,却不保证重启后不变------ZooKeeper 会分配一个新的 ID,而不是重用旧的。 - 即使是大规模动态扩容,也推荐通过自动化工具(如 Ansible、Terraform)为每个新节点分配一个固定的、不冲突的 ID,而不是完全依赖自动生成。
结论 :无论是单节点还是集群部署,都应该显式固定 KAFKA_BROKER_ID,这是保证持久化和消费者组正常工作的基石。
三、解决方案
3.1 核心改动
-
固定 Broker ID
在 Kafka 服务环境变量中添加:
KAFKA_BROKER_ID: 1(值为任意非负整数,但必须在集群内唯一) -
显式指定数据目录
添加:
KAFKA_LOG_DIRS: /kafka/data并挂载卷:
- ./kafka-data:/kafka/data -
为 ZooKeeper 添加持久化卷
ZooKeeper 存储了 Kafka 集群的元数据。如果不持久化,重启后元数据丢失,同样会导致各种诡异问题。注意
wurstmeister/zookeeper镜像的数据目录为/data和/datalog,必须挂载这两个目录。 -
正确配置 listeners
确保
KAFKA_ADVERTISED_LISTENERS中对外公布的地址是客户端真正能够访问的地址(本例如172.16.14.213为宿主机内网 IP,请根据自身环境修改)。
3.2 最终 docker-compose.yml
yaml
version: '2'
# 自定义网络:所有服务加入同一网络,通过服务名直接通信
networks:
kafka-network:
driver: bridge
services:
# Zookeeper:Kafka 的协调服务
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181" # 映射 Zookeeper 客户端端口到宿主机
networks:
- kafka-network
restart: always # 容器退出时自动重启
# 关键修改 1:为 Zookeeper 添加持久化卷
volumes:
- ./zookeeper/data:/opt/zookeeper-3.4.13/data
# Kafka Broker:消息队列核心
kafka:
image: wurstmeister/kafka:latest
ports:
- "9092:9092" # 映射容器内 PLAINTEXT_HOST 监听器端口(9092)到宿主机,供外部客户端使用
environment:
# 监听器定义:Kafka 在容器内监听的地址和端口
# PLAINTEXT 监听器(内部通信)绑定到 9093 端口,PLAINTEXT_HOST 监听器(外部访问)绑定到 9092 端口
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9093,PLAINTEXT_HOST://0.0.0.0:9092
# 公布地址:Kafka 注册到 Zookeeper 并向客户端公布的连接信息
# 内部客户端(如同网络的 Kafdrop)应使用 PLAINTEXT://kafka:9093
# 外部客户端(宿主机)应使用 PLAINTEXT_HOST://localhost:9092
# 使用了内网穿透工具,外部客户端需要使用穿透后的地址
#KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9093,PLAINTEXT_HOST://域名
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9093,PLAINTEXT_HOST://{{你的ip}}:9092
# 监听器名称到安全协议的映射,这里均使用 PLAINTEXT(无加密)
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
# 指定 broker 之间内部通信使用的监听器,这里使用 PLAINTEXT(即 9093 端口)
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
# Zookeeper 连接地址,使用服务名
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
# Topic 默认配置:副本因子 1(单副本),分区数 3
KAFKA_DEFAULT_REPLICATION_FACTOR: 1
KAFKA_NUM_PARTITIONS: 3
KAFKA_BROKER_ID: 1
# 新增:指定数据目录
KAFKA_LOG_DIRS: /kafka/data
networks:
- kafka-network
depends_on:
- zookeeper # 确保 Zookeeper 先启动
restart: always
# 新增:挂载数据卷
volumes:
- ./kafka-data:/kafka/data
# Kafdrop:Kafka Web UI 管理工具
kafdrop:
image: obsidiandynamics/kafdrop
ports:
- "9000:9000" # 映射 Web 端口到宿主机,访问 http://localhost:9000
environment:
# 连接 Kafka 的 broker 地址:必须使用内部公布的 PLAINTEXT 地址(kafka:9093)
KAFKA_BROKERCONNECT: kafka:9093
SERVER_SERVLET_CONTEXTPATH: "/"
networks:
- kafka-network
depends_on:
- kafka # 确保 Kafka 先启动
restart: always注意 :如果你使用的 ZooKeeper 镜像不是
wurstmeister/zookeeper(例如bitnami/zookeeper),请确认其数据目录的实际路径并相应修改volumes。
3.3 清理旧数据,全新启动
执行以下命令彻底清理旧环境(会清除所有历史数据,确保一次全新验证):
bash
docker-compose down -v
rm -rf ./kafka-data ./zookeeper
docker-compose up -d四、验证方法
-
检查数据持久化
创建测试主题并发送几条消息:
bashdocker exec -it $(docker ps -qf name=kafka) kafka-topics.sh --create --topic test --bootstrap-server localhost:9092 --partitions 3 --replication-factor 1 docker exec -it $(docker ps -qf name=kafka) kafka-console-producer.sh --topic test --bootstrap-server localhost:9092 # 输入几条消息,Ctrl+C 退出 -
重启容器
bashdocker-compose down docker-compose up -d -
验证消息是否还在
bashdocker exec -it $(docker ps -qf name=kafka) kafka-console-consumer.sh --topic test --bootstrap-server localhost:9092 --from-beginning如果能消费到之前的消息,说明持久化成功。
-
验证消费者组
启动一个消费者(指定 group.id),然后查看组状态:
bashkafka-consumer-groups.sh --bootstrap-server localhost:9092 --group my-group --describe不应出现
CoordinatorNotAvailableException。 -
通过 Kafdrop 观察
打开
http://localhost:9000,查看 Topic 和消费者组信息是否正常。
五、延伸讨论:集群部署与动态分配
对于生产环境的多节点集群,建议遵循以下实践:
- 规划 ID 范围 :根据机器数量,固定分配
1..N,并在每个 Broker 的docker-compose或环境变量中设置不同的KAFKA_BROKER_ID。 - 使用自动化工具 :通过 Ansible、Terraform 等工具为每个节点生成独立的配置文件,确保
broker.id唯一且不冲突。 - 考虑 KRaft 模式 :Kafka 3.x 及以上版本已逐步支持 KRaft(Kafka Raft),可完全移除 ZooKeeper,元数据由 Kafka 内部管理。但 KRaft 模式下仍需为每个节点设置唯一的
node.id(类似broker.id),且同样建议固定。
另外,在解决本问题的过程中,我还遇到了另一个经典错误:InconsistentClusterIdException(集群 ID 不一致)。详细的解决过程记录在另一篇文章中,有兴趣的读者可以参考:《Kafka集群ID不一致异常(InconsistentClusterIdException)的解决》。
六、总结
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 数据丢失、目录随机变化 | broker.id 未固定 |
设置 KAFKA_BROKER_ID: 1 |
| 消费者组协调失败 | broker.id 变化导致元数据错乱 |
固定 broker.id + 持久化 ZooKeeper |
| 根因 | 自动生成的 broker.id 每次重启都会改变 |
手动指定固定值 |
最终,本文的目标圆满达成:执行 docker-compose down && docker-compose up -d 后,Kafka 的历史数据不会丢失,消费者组也能正常工作。
希望这份方案能帮助到同样被这些奇怪现象困扰的开发者。如果你在实践过程中遇到其他问题,欢迎在评论区留言讨论。
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。