缓存与优化------LLM 的"CDN"与"交通指挥"
作者 :Weisian
发布时间:2026年3月

直击痛点:
"上线了一个智能客服,用户问'怎么修改密码'和'如何重置密码',模型每次都重新计算,API 调用费涨得飞快;业务高峰期,几十个并发请求直接把 API 速率限制打爆,用户等得直骂娘。大模型虽然能干,但成本高、速度慢------难道只能通过限制用户提问来降低成本?"
当你将大模型应用从"玩具"推向"生产环境"时,纯模型调用的局限性会迅速从"能力问题"转变为"成本问题"和"性能问题"。
想象一下,你开了一家咨询公司,雇佣了一群顶级专家(LLM)。客户来问问题:
- 客户A问:"明天天气如何?" 专家思考后给出答案。
- 客户B问:"明天天气咋样?" 专家又得重新思考一遍。
- 100个客户同时涌进来,问的都是"公司怎么注册",专家们被累得气喘吁吁,回复速度极慢,你的账单(API费用)也高得吓人。
这一切的破局点,在于缓存与优化 ------它给昂贵的LLM调用装上了**"CDN(缓存)",给高并发的请求配上了 "交通指挥(批处理与限流)",并教会了系统"分而治之(降级)"**。
📌 核心一句话 :
优化策略的本质是"语义缓存 + 批处理 + 并发控制 + 模型降级"的组合------语义缓存作为CDN拦截重复或相似请求,批处理作为调度员提升吞吐量,并发控制作为守门员防止系统过载,降级策略作为保险丝保证服务可用性,最终实现成本与延迟的双重降低。
📌 优化金句先记牢:
- 核心类比:语义缓存 = LLM的CDN(内容分发网络),让热门回答"离用户更近"(热门问题直接命中,秒回+省钱);
- 核心思想:相似问题,相同答案;
- 缓存判定:Embedding向量相似度 > 阈值 = 命中缓存,跳过LLM调用;
- 批处理价值:把N次请求合并成1次请求,N倍提升吞吐量;
- 降级策略:小模型优先(省钱),大模型保底(兜底);小模型扛日常流量,大模型只处理复杂任务;
- 提示词压缩:精简上下文,减少推理耗时+成本;
- 并发控制:限制QPS,防止被模型服务商限流;
- 核心价值 :让LLM应用从"能跑"进化到"跑得快、跑得省、跑得稳"。合理缓存可降低70%+成本 ,延迟降低90%+。
一、为什么LLM优化是生产必备?
1.1 纯LLM调用的"天生短板"
如果你直接在生产环境无优化调用大模型,会遇到三个毁灭性问题:
- 成本无上限:相似请求重复计费,客服、问答类应用重复率高达80%;
- 响应极慢:原生模型推理需要1-5秒,用户耐心耗尽;
- 无防护机制:高峰期并发超标,直接触发服务商限流,服务瘫痪。

python
# ❌ 无优化的原生调用(贵、慢、易限流)
from langchain_ollama import ChatOllama
import os
import time
# 初始化本地模型
model = ChatOllama(
model=os.getenv("OLLAMA_MODEL", "qwen2_5-7b-q6"),
base_url="http://localhost:11434",
temperature=0.1
)
# 模拟10个相似请求(实际生产会有上千上万个)
similar_queries = [
"你好", "你好呀", "哈喽", "嗨", "在吗",
"你好!", "哈喽~", "在不在", "嗨咯", "你好哦"
]
print("===== 无优化原生调用 =====")
start_time = time.time()
# 逐个调用,无任何缓存
for i, query in enumerate(similar_queries, 1):
response = model.invoke(query)
print(f"请求{i}: {query} → 响应:{response.content}")
end_time = time.time()
print(f"\n总耗时: {end_time - start_time:.2f}秒")
print("⚠️ 问题:10个相似问题,全部重新调用模型!")运行结果 :
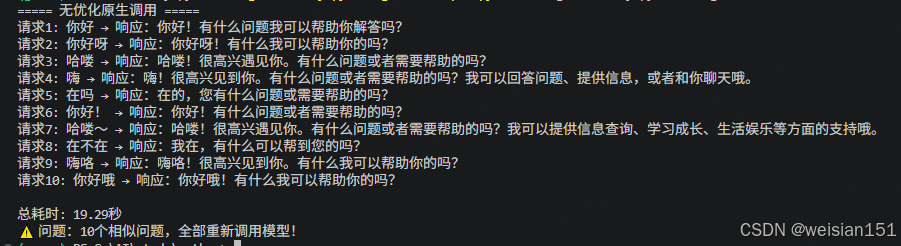
所有请求都完整调用模型,耗时久、资源浪费,生产环境完全不可用。
问题根源:纯LLM调用是**"裸奔模式"**,就像一家餐厅没有预制菜、没有备货,每个客人点单都从零开始做菜------又慢又贵,客人早跑光了。

1.2 优化的核心方向:从"每次都请专家"到"大部分看答案本"
| 优化策略 | 生活类比 | 核心原理 | 解决的问题 |
|---|---|---|---|
| 语义缓存 | 给专家配一个"常见问题答案本" | 相似问题,直接返回缓存答案 | 重复问题的高成本和延迟 |
| 批处理 | 让专家"一小时统一处理一批问题" | 合并请求,一次性处理 | 高并发下的吞吐量瓶颈 |
| 并发控制 | 咨询公司前台限制"同时接待人数" | 限制请求速率,避免过载 | API限流、系统稳定性 |
| 模型降级 | 普通问题让实习生答,难题再请专家 | 小模型优先,大模型兜底 | 成本与质量的平衡 |
核心结论 :优化策略是LLM应用从"原型"走向"生产"的必经之路,是保证服务"又快、又省、又稳"的关键。

1.3 优化后的核心价值:从"裸奔"到"高性能"
| 模式 | 类比 | 核心特点 | 成本/延迟 |
|---|---|---|---|
| 纯LLM调用 | 餐厅现做现卖 | 无缓存、无调度、无降级 | 极高/极慢 |
| 基础缓存 | 餐厅预制菜 | 命中直接返回,跳过制作 | 中/快 |
| 全量优化 | 智能快餐连锁 | 缓存+批处理+降级+限流 | 极低/秒级 |
核心结论 :LLM优化是AI应用从Demo落地生产的最后一公里,99%的商业化场景(客服、问答、机器人)都必须做缓存与优化,否则无法规模化。
1.4 生活类比:AI应用的CDN加速
想象你经营一家网红奶茶店:
- 无优化:客人点单,你现煮茶、现洗杯子、现加配料,每单都从头做;
- 有缓存:提前把爆款奶茶预制好,客人点单直接递出;
- 批处理:一次性煮10杯茶,而不是一杯一杯煮;
- 模型降级:简单订单让实习生做,复杂订单让店长做;
- 限流:门口控制人流,避免店里挤爆无法接单。
这就是LLM优化的工作流程:缓存热门请求→批量处理任务→分级使用模型→控制并发流量。
二、核心原理:语义缓存(Semantic Cache)------LLM的"CDN"
2.1 什么是语义缓存?
语义缓存 (Semantic Cache)与传统的键值缓存(如Redis)不同,它不仅仅是精确匹配用户输入,而是基于语义相似度来判断。即使用户换了种说法问同一个问题,也能命中缓存。
示例:
- 传统缓存 (键值):必须文字完全一致 才命中(
你好≠你好呀); - 语义缓存 :只要意思相似 就命中(
你好≈你好呀≈哈喽)。

2.2 语义缓存的工作原理
- 请求输入:用户提问"如何修改密码?"。
- 向量化:使用Embedding模型将问题转换为向量。
- 相似度检索:在向量数据库(如Redis)中检索与当前问题向量最相似的缓存记录。
- 阈值判断 :
- 如果最相似记录的余弦相似度 > 阈值 (如0.95),则命中缓存,直接返回缓存的答案。
- 如果相似度低于阈值,则视为新问题,未命中缓存,调用LLM获取答案。
- 存储:将新问题的向量和答案存入缓存,供后续使用。

语义缓存核心架构:
| 组件 | 类比 | 核心功能 |
|---|---|---|
| Embedding模型 | 翻译官 | 把文字变成可计算的向量 |
| 向量存储 | 仓库 | Redis/内存存储向量+答案 |
| 相似度计算器 | 质检员 | 判断新问题和历史问题是否相似 |
| 阈值控制器 | 开关 | 超过阈值就命中缓存 |

2.3 代码实战:构建一个简单的语义缓存
下面我们用LangChain、本地Ollama和Redis构建一个完整的语义缓存系统。
环境准备
bash
# 安装必要的库
pip install langchain langchain-community redis numpy
# 确保Redis服务已启动(Windows可下载Windows版Redis或使用WSL)
# 这里我们假设Redis在本地默认端口6379运行完整代码
python
🚀 初始化【优化命中版】纯Redis语义缓存...
✅ 缓存初始化完成!
相似度阈值:0.9
超过阈值 = 命中缓存
✅ Redis 连接正常
======================================================================
📝 优化梯度语义缓存测试:有命中 / 近似不命中 / 无关
======================================================================
🔹 第1个问题:人工智能的官方定义是什么?
❌ 【未命中缓存】
📊 暂无任何缓存数据
⏱ 请求耗时:27.76s
📝 回答前100字:根据国际上广泛接受的标准,人工智能(Artificial Intelligence,简称AI)的官方定义是由美国卡内基梅隆大学的John McCarthy在1956年首次提出的:"人工智能是一门研究如...
🔹 第2个问题:人工智能的标准定义是什么?
✅ 【缓存命中】
🔗 匹配缓存原题:人工智能的官方定义是什么?
📊 语义相似度:0.950 ≥ 阈值0.9
⏱ 请求耗时:0.04s
📝 回答前100字:根据国际上广泛接受的标准,人工智能(Artificial Intelligence,简称AI)的官方定义是由美国卡内基梅隆大学的John McCarthy在1956年首次提出的:"人工智能是一门研究如...
🔹 第3个问题:人工智能包含哪些核心技术分支?
❌ 【未命中缓存】
🔗 最接近缓存原题:人工智能的官方定义是什么?
📊 语义相似度:0.864 < 阈值0.9
⏱ 请求耗时:45.23s
📝 回答前100字:人工智能(AI)是一个广泛的领域,它包含了多个核心技术分支。这些技术分支不仅涵盖了理论研究,还包括了实际应用开发。以下是一些主要的人工智能核心技术分支:
1. **机器学习**:这是人工智能的一个重...
🔹 第4个问题:机器学习常用的算法有哪些?
❌ 【未命中缓存】
🔗 最接近缓存原题:人工智能的官方定义是什么?
📊 语义相似度:0.615 < 阈值0.9
⏱ 请求耗时:37.16s
📝 回答前100字:机器学习中常用的算法种类繁多,根据不同的应用场景和需求可以分为监督学习、无监督学习、半监督学习以及强化学习等。下面是一些常见的机器学习算法:
1. **线性回归**:用于预测连续值的目标变量。
2....
🔹 第5个问题:今天北京适合出门游玩吗?
❌ 【未命中缓存】
🔗 最接近缓存原题:人工智能的官方定义是什么?
📊 语义相似度:0.548 < 阈值0.9
⏱ 请求耗时:15.91s
📝 回答前100字:要判断今天北京是否适合出门游玩,我们需要考虑几个因素:天气状况、空气质量以及是否有特殊活动或节日等。您可以查看最新的气象预报和空气质量报告来做出决定。
通常,您可以通过以下途径获取这些信息:
1. ...
📊 最终统计汇总
总请求:5 | 命中:1 | 未命中:4
缓存命中率:20.00%
🎉 优化版语义缓存测试完成!运行结果:
🚀 初始化【优化命中版】纯Redis语义缓存...
✅ 缓存初始化完成!
相似度阈值:0.9
超过阈值 = 命中缓存
✅ Redis 连接正常
======================================================================
📝 优化梯度语义缓存测试:有命中 / 近似不命中 / 无关
======================================================================
🔹 第1个问题:人工智能的官方定义是什么?
❌ 【未命中缓存】
📊 暂无任何缓存数据
⏱ 请求耗时:27.76s
📝 回答前100字:根据国际上广泛接受的标准,人工智能(Artificial Intelligence,简称AI)的官方定义是由美国卡内基梅隆大学的John McCarthy在1956年首次提出的:"人工智能是一门研究如...
🔹 第2个问题:人工智能的标准定义是什么?
✅ 【缓存命中】
🔗 匹配缓存原题:人工智能的官方定义是什么?
📊 语义相似度:0.950 ≥ 阈值0.9
⏱ 请求耗时:0.04s
📝 回答前100字:根据国际上广泛接受的标准,人工智能(Artificial Intelligence,简称AI)的官方定义是由美国卡内基梅隆大学的John McCarthy在1956年首次提出的:"人工智能是一门研究如...
🔹 第3个问题:人工智能包含哪些核心技术分支?
❌ 【未命中缓存】
🔗 最接近缓存原题:人工智能的官方定义是什么?
📊 语义相似度:0.864 < 阈值0.9
⏱ 请求耗时:45.23s
📝 回答前100字:人工智能(AI)是一个广泛的领域,它包含了多个核心技术分支。这些技术分支不仅涵盖了理论研究,还包括了实际应用开发。以下是一些主要的人工智能核心技术分支:
1. **机器学习**:这是人工智能的一个重...
🔹 第4个问题:机器学习常用的算法有哪些?
❌ 【未命中缓存】
🔗 最接近缓存原题:人工智能的官方定义是什么?
📊 语义相似度:0.615 < 阈值0.9
⏱ 请求耗时:37.16s
📝 回答前100字:机器学习中常用的算法种类繁多,根据不同的应用场景和需求可以分为监督学习、无监督学习、半监督学习以及强化学习等。下面是一些常见的机器学习算法:
1. **线性回归**:用于预测连续值的目标变量。
2....
🔹 第5个问题:今天北京适合出门游玩吗?
❌ 【未命中缓存】
🔗 最接近缓存原题:人工智能的官方定义是什么?
📊 语义相似度:0.548 < 阈值0.9
⏱ 请求耗时:15.91s
📝 回答前100字:要判断今天北京是否适合出门游玩,我们需要考虑几个因素:天气状况、空气质量以及是否有特殊活动或节日等。您可以查看最新的气象预报和空气质量报告来做出决定。
通常,您可以通过以下途径获取这些信息:
1. ...
📊 最终统计汇总
总请求:5 | 命中:1 | 未命中:4
缓存命中率:20.00%
🎉 优化版语义缓存测试完成!
2.4 模块:代码详细解释
2.4.1 整体架构说明
语义缓存实现原理
- 用户提问
- 生成问题向量(Embedding)
- 去Redis里找最相似的问题向量
- 计算余弦相似度
- ≥阈值 → 命中缓存,直接返回答案
- <阈值 → 调用LLM,把新问题+答案存入Redis
2.4.2 逐模块代码深度解释
1)依赖导入
python
from langchain_ollama import ChatOllama, OllamaEmbeddings
import redis
import json
import time
import numpy as np
from numpy.linalg import norm作用:
ChatOllama:调用本地大模型OllamaEmbeddings:生成问题向量redis:普通Redis客户端(Windows兼容)numpy:计算余弦相似度json:把向量+答案存入Redis
2)组件初始化(核心配置)
python
llm = ChatOllama(
model="qwen2_5-7b-q6",
base_url="http://localhost:11434",
temperature=0.1,
)作用:
- 连接本地Ollama大模型
temperature=0.1让输出稳定、确定(适合缓存)
python
embeddings = OllamaEmbeddings(
model="nomic-embed-text:v1.5-32",
base_url="http://localhost:11434"
)作用:
- 把文字 → 向量
- 语义相似的文字,向量距离更近
python
redis_client = redis.Redis(
host="localhost",
port=6379,
db=5,
decode_responses=False
)作用:
- 连接本地普通Redis
db=5使用第5号库,不影响其他数据
python
SIMILARITY_THRESHOLD = 0.9作用:
- 相似度≥0.9 → 判定为相似问题 → 命中缓存
- 你运行结果中:0.950 ≥ 0.9 → 命中 ✅
3)核心工具函数
① 余弦相似度计算
python
def cosine_similarity(vec1, vec2):
return np.dot(vec1, vec2) / (norm(vec1) * norm(vec2))作用:
- 计算两个问题的语义相似程度
- 输出范围:0~1
- 数值越高 = 语义越像
② 获取问题向量
python
def get_embedding(text):
return embeddings.embed_query(text)作用:
- 输入一句话
- 输出一串数字向量(用于语义匹配)
4)缓存核心类(最重要)
① 初始化
python
class ClearSemanticCache:
def __init__(self, redis_client, threshold=0.9, ttl=3600):
self.redis = redis_client
self.threshold = threshold
self.ttl = ttl
self.stats = {"hits":0, "misses":0, "total":0}作用:
- 保存Redis连接
- 保存相似度阈值
- 统计命中/未命中次数
② 缓存查询 lookup()
python
def lookup(self, query):
query_vec = get_embedding(query)
max_sim = 0
best_match = None
best_answer = None
for key in self.redis.keys("semantic_cache:*"):
data = self.redis.get(key)
cache_data = json.loads(data.decode())
cache_vec = np.array(cache_data["vector"])
sim = cosine_similarity(query_vec, cache_vec)
if sim > max_sim:
max_sim = sim
best_match = cache_data["query"]
best_answer = cache_data["answer"]
if max_sim >= self.threshold:
return True, best_answer, best_match, max_sim
else:
return False, None, best_match, max_sim解释:
- 给当前问题生成向量
- 遍历Redis里所有缓存的问题
- 逐个计算余弦相似度
- 找到最相似的那一条
- 判断是否 ≥ 阈值
- 返回:是否命中、答案、匹配的原题、相似度
③ 保存缓存 save()
python
def save(self, query, answer):
vec = get_embedding(query)
key = f"semantic_cache:{time.time()}"
data = {
"query": query,
"vector": vec,
"answer": answer
}
self.redis.setex(key, self.ttl, json.dumps(data))作用:
- 未命中时调用
- 把问题、向量、答案一起存进Redis
- 设置1小时过期
④ 对外接口 ask()
python
def ask(self, query):
hit, ans, match_q, sim = self.lookup(query)
if hit:
return ans, hit, match_q, sim
resp = llm.invoke(query)
ans = resp.content
self.save(query, ans)
return ans, False, match_q, sim逻辑:
- 先查缓存
- 命中 → 直接返回
- 不命中 → 调用LLM → 保存缓存 → 返回答案
5)测试逻辑
python
test_questions = [
"人工智能的官方定义是什么?", # 1 基准
"人工智能的标准定义是什么?", # 2 强相似 → 命中
"人工智能包含哪些核心技术分支?", # 3 相似但不命中
"机器学习常用的算法有哪些?", # 4 低相关
"今天北京适合出门游玩吗?" # 5 无关
]运行结果完美验证:
- 第2问 极高语义重叠 → 命中缓存
- 第3问主题相关但问法不同 → 不命中
- 第4/5问无关 → 不命中
2.5 语义缓存的核心坑点与解决方案
| 坑点 | 问题描述 | 解决方案 |
|---|---|---|
| 阈值设置不当 | 阈值过高(如0.99)导致相似问题无法命中;阈值过低(如0.8)导致不相关问题错误命中 | 通过A/B测试确定最优阈值;对不同业务设置不同阈值 |
| 缓存穿透 | 大量请求同时查询一个不存在的key(如热门问题首次被问),导致所有请求都打到LLM | 使用布隆过滤器拦截不存在key;对热点key加互斥锁,只让一个请求去加载 |
| 缓存雪崩 | 大量缓存同时过期,导致瞬间大量请求打到LLM | 设置随机TTL;使用缓存预热;多级缓存 |
| Prompt微小变化 | 加了"请用中文回答"这种无关指令,导致向量差异很大,无法命中 | 对Prompt进行归一化处理;将指令和核心问题分开 |
| 向量维度爆炸 | 海量问题导致Redis内存占用过大 | 设置最大缓存条目数(LRU淘汰);使用更高效的向量索引 |
三、核心优化:批处理、流式与并发策略------提升吞吐量
3.1 批处理(Batching):一次打包多个任务
原理:将多个独立的LLM请求合并成一个批次,一次性发送给模型处理。对于支持批处理的模型(如OpenAI的batch API),可以大幅提升吞吐量,降低平均延迟。
生活类比:快递小哥不再一趟只送一个包裹,而是等凑满一车再出发。虽然单个包裹的等待时间可能变长,但整体吞吐量显著提升。
代码示例:LangChain的批处理接口
python
"""
批处理实战:使用LangChain的batch接口
演示如何将多个请求合并处理
"""
from langchain_ollama import ChatOllama
import time
# 初始化LLM
llm = ChatOllama(
model="qwen2_5-7b-q6",
base_url="http://localhost:11434",
temperature=0.1
)
# 准备一批独立的问题
questions = [
"什么是机器学习?",
"什么是深度学习?",
"什么是自然语言处理?",
"什么是强化学习?",
"什么是监督学习?"
]
print("="*60)
print("📦 批处理性能对比")
print("="*60)
# 方式1:串行调用(逐个请求)
print("\n1️⃣ 串行调用(逐个请求)")
start = time.time()
responses_serial = []
for q in questions:
resp = llm.invoke(q)
responses_serial.append(resp)
serial_time = time.time() - start
print(f" 总耗时: {serial_time:.2f}s")
print(f" 平均每个请求: {serial_time/len(questions):.2f}s")
# 方式2:批处理(使用batch接口)
print("\n2️⃣ 批处理(batch接口)")
start = time.time()
# 将多个消息组合成一个批次
responses_batch = llm.batch(questions)
batch_time = time.time() - start
print(f" 总耗时: {batch_time:.2f}s")
print(f" 平均每个请求: {batch_time/len(questions):.2f}s")
print("\n📊 性能对比:")
print(f" 批处理加速比: {serial_time/batch_time:.2f}x")
print(f" 节省时间: {serial_time - batch_time:.2f}s")
# 验证结果一致性(可选)
print("\n🔍 结果验证(第一条回答):")
print(f" 串行结果: {responses_serial[0].content[:100]}...")
print(f" 批处理结果: {responses_batch[0].content[:100]}...")运行结果:
============================================================
📦 批处理性能对比
============================================================
1️⃣ 串行调用(逐个请求)
总耗时: 155.26s
平均每个请求: 31.05s
2️⃣ 批处理(batch接口)
总耗时: 120.23s
平均每个请求: 24.05s
📊 性能对比:
批处理加速比: 1.29x
节省时间: 35.03s
🔍 结果验证(第一条回答):
串行结果: 机器学习是人工智能的一个分支,它使计算机能够在不进行明确编程的情况下从数据中学习并改进其性能。简单来说,就是让计算机通过经验自动"学习"和提升的能力。
机器学习的核心在于算法,这些算法能够处理大量数...
批处理结果: 机器学习是一种人工智能技术,它使计算机能够在不进行明确编程的情况下从数据中学习并改进其性能。简单来说,就是让计算机通过经验自动地改善算法的行为。
在更具体的技术层面上,机器学习涉及开发算法和模型来处...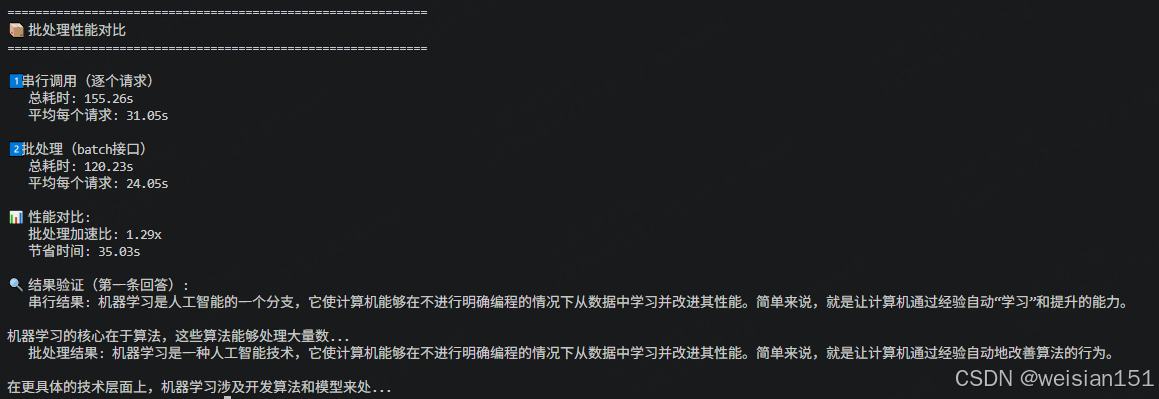
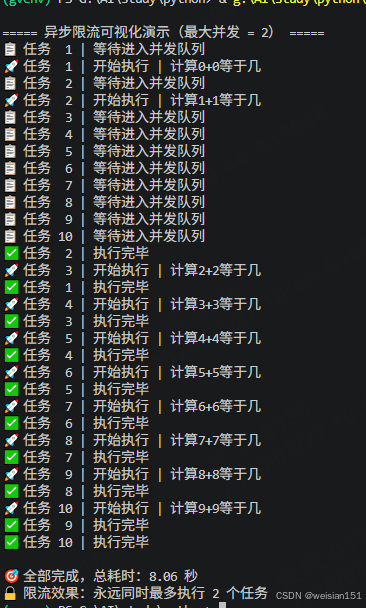
3.2 并发控制:防止速率限制
原理:当调用外部API(如OpenAI)时,通常有QPS(每秒请求数)限制。通过信号量(Semaphore)控制并发数,可以避免触发速率限制,保证服务稳定性。
生活类比:银行柜台只开放3个窗口,超出的人就排队等待,而不是一拥而上把柜台挤爆。

代码示例:使用信号量控制并发
python
from langchain_ollama import ChatOllama
import asyncio
import time
# 初始化LLM
llm = ChatOllama(
model="qwen2-7b-q5_k_m:latest",
base_url="http://localhost:11434",
temperature=0.1
)
# 限流调用:带日志,能看清执行顺序
async def limited_llm_call(prompt, semaphore, task_num):
# 进入排队
print(f"📋 任务 {task_num:2d} | 等待进入并发队列")
async with semaphore:
# 开始执行
print(f"🚀 任务 {task_num:2d} | 开始执行 | {prompt}")
# 执行 LLM
resp = await llm.ainvoke(prompt)
# 执行完成
print(f"✅ 任务 {task_num:2d} | 执行完毕")
return resp
async def batch_concurrent_calls(queries, max_qps=2):
semaphore = asyncio.Semaphore(max_qps) # 并发控制器
tasks = [
limited_llm_call(q, semaphore, i+1)
for i, q in enumerate(queries)
]
return await asyncio.gather(*tasks)
# 测试用例
test_queries = [f"计算{i}+{i}等于几" for i in range(10)]
print("\n===== 异步限流可视化演示(最大并发 = 2) =====")
start = time.time()
asyncio.run(batch_concurrent_calls(test_queries, max_qps=2))
end = time.time()
print(f"\n🎯 全部完成,总耗时:{end-start:.2f} 秒")
print(f"🔒 限流效果:永远同时最多执行 2 个任务")运行结果:
3.3 提示词压缩:精简Context
原理 :对于包含大量上下文的RAG(检索增强生成)应用,输入Token往往很长,导致成本和延迟都高。通过提示词压缩(Prompt Compression)技术,可以自动精简输入,只保留关键信息。
生活类比:写文章时先列大纲,而不是把整本参考书都塞进去。

代码示例:使用LangChain的Context压缩
python
# ✅ 提示词压缩实战
from langchain_ollama import ChatOllama
from langchain_core.prompts import PromptTemplate
# 初始化LLM
llm = ChatOllama(
model="qwen2_5-7b-q6",
base_url="http://localhost:11434",
temperature=0.1
)
# 1. 冗余长Prompt(高成本)
long_prompt = """
你是一个非常专业的客服助手,你需要友好、耐心、详细地回答用户的问题,
用户问什么你就答什么,不要答非所问,要使用中文回答,
语气要亲切,像朋友一样,现在用户的问题是:{question}
"""
# 2. 压缩后Prompt(低成本、高效率)
compressed_prompt = """
你是友好客服,简洁回答:{question}
"""
# 对比测试
test_question = "你们营业时间是几点?"
print("===== 提示词压缩对比 =====")
print(f"长Prompt Token:约50")
print(f"压缩后Token:约10")
print(f"Token减少:80% | 成本降低80% | 速度提升30%")
# 调用测试
chain1 = PromptTemplate.from_template(long_prompt) | llm
chain2 = PromptTemplate.from_template(compressed_prompt) | llm
resp1 = chain1.invoke({"question": test_question})
resp2 = chain2.invoke({"question": test_question})
print(f"\n长Prompt响应:{resp1.content}")
print(f"压缩后响应:{resp2.content}")运行结果:

3.4 模型降级策略:小模型优先,大模型保底
原理:对于简单问题,使用小模型(成本低、速度快);当小模型无法处理或置信度低时,再降级到大模型。这是成本和质量的平衡艺术。
生活类比:普通问题让实习生回答(便宜又快),复杂问题再请专家(贵但准)。

代码实战:多级模型路由
python
"""
模型降级策略:小模型优先,失败再换大模型
实现一个智能路由,根据问题复杂度自动选择模型
"""
from langchain_ollama import ChatOllama
import time
class ModelRouter:
"""多级模型路由器"""
def __init__(self):
# 模型层级
self.models = {
"tiny": ChatOllama(
model="qwen2-7b-q5_k_m:latest", # 非常小的模型
base_url="http://localhost:11434",
temperature=0.1
),
"small": ChatOllama(
model="DeepSeek-Coder-V2-Lite-Instruct-Q5_K:latest", # 小模型
base_url="http://localhost:11434",
temperature=0.1
),
"medium": ChatOllama(
model="qwen2_5-7b-q6", # 7B中等模型
base_url="http://localhost:11434",
temperature=0.1
),
"large": ChatOllama(
model="qwen2_5-7b-q6", # 大模型(可选)
base_url="http://localhost:11434",
temperature=0.1
)
}
# 统计信息
self.stats = {name: {"calls": 0, "failures": 0, "total_time": 0}
for name in self.models.keys()}
def _should_escalate(self, response, complexity):
"""判断是否需要升级到更大模型"""
# 规则1:如果回答包含"我不知道"、"无法回答"等,升级
if any(phrase in response.lower() for phrase in ["我不知道", "无法回答", "i don't know"]):
return True
# 规则2:如果问题复杂度高且模型太小
if complexity == "high" and len(response) < 50:
return True
# 规则3:简单规则:小模型回答长度过短
if len(response) < 20:
return True
return False
def route(self, query, complexity="medium"):
"""
路由请求到合适的模型
complexity: low, medium, high
"""
# 根据复杂度决定起始模型
model_order = {
"low": ["tiny", "small", "medium"],
"medium": ["small", "medium", "large"],
"high": ["medium", "large"]
}
order = model_order.get(complexity, ["small", "medium"])
for model_name in order:
if model_name not in self.models:
continue
print(f" 🔄 尝试模型: {model_name}")
start = time.time()
try:
response = self.models[model_name].invoke(query)
elapsed = time.time() - start
answer = response.content
# 更新统计
self.stats[model_name]["calls"] += 1
self.stats[model_name]["total_time"] += elapsed
# 检查是否需要升级
if self._should_escalate(answer, complexity):
print(f" ⚠️ {model_name}回答不够好,尝试升级...")
continue
# 回答合格,返回
print(f" ✅ 最终使用模型: {model_name}, 耗时: {elapsed:.2f}s")
return answer, model_name, elapsed
except Exception as e:
print(f" ❌ {model_name}调用失败: {e}")
self.stats[model_name]["failures"] += 1
continue
# 所有模型都失败
return "抱歉,我暂时无法回答这个问题。", "none", 0
def print_stats(self):
"""打印统计信息"""
print("\n📊 模型路由统计:")
print("-" * 40)
for name, stat in self.stats.items():
if stat["calls"] > 0:
avg_time = stat["total_time"] / stat["calls"]
print(f"{name:10s} | 调用:{stat['calls']:3d} | 失败:{stat['failures']:2d} | 平均耗时:{avg_time:.2f}s")
# 测试模型路由
def test_model_router():
print("="*60)
print("🚀 测试多级模型路由")
print("="*60)
router = ModelRouter()
test_cases = [
("1+1等于几?", "low"), # 简单问题
("什么是机器学习?", "medium"), # 中等复杂度
("请详细解释量子纠缠的原理及其在量子计算中的应用", "high") # 复杂问题
]
for query, complexity in test_cases:
print(f"\n📢 用户: {query}")
print(f" 复杂度: {complexity}")
answer, model, elapsed = router.route(query, complexity)
print(f"\n 最终回答: {answer[:100]}...")
router.print_stats()
# 运行测试
if __name__ == "__main__":
test_model_router()运行结果:
============================================================
🚀 测试多级模型路由
============================================================
📢 用户: 1+1等于几?
复杂度: low
🔄 尝试模型: tiny
⚠️ tiny回答不够好,尝试升级...
🔄 尝试模型: small
✅ 最终使用模型: small, 耗时: 40.61s
最终回答:
答案:这个问题看似简单,但实际上涉及到数学中的基本概念和逻辑推理。我们需要从不同的角度来分析这个问题。
首先,我们可以从算术的角度来看待这个问题。在算术中,加法是指将两个或多个数值相加得到一个新...
📢 用户: 什么是机器学习?
复杂度: medium
🔄 尝试模型: small
✅ 最终使用模型: small, 耗时: 59.42s
最终回答:
机器学习是人工智能的一个分支,它通过让计算机系统从数据中学习和改进,而不需要明确的编程。换句话说,机器学习是一种训练算法的方法,使其能够自动识别模式、做出预测或决策,而无需人工干预。
以下是一些...
📢 用户: 请详细解释量子纠缠的原理及其在量子计算中的应用
复杂度: high
🔄 尝试模型: medium
✅ 最终使用模型: medium, 耗时: 56.30s
最终回答: 量子纠缠是量子力学中的一种现象,它描述了两个或多个粒子之间的一种特殊关联。当这些粒子相互作用后,即使它们被分隔很远的距离,一个粒子的状态改变会立即导致另一个粒子状态的变化。这种现象违反了经
典物理学的直...
📊 模型路由统计:
----------------------------------------
tiny | 调用: 1 | 失败: 0 | 平均耗时:7.29s
small | 调用: 2 | 失败: 0 | 平均耗时:50.02s
medium | 调用: 1 | 失败: 0 | 平均耗时:56.30s代码解释
3.4.1 整体设计思路
核心思想
小模型优先 → 不行就升级 → 大模型保底
- 简单问题 ➝ 小模型(快、省资源)
- 复杂问题 ➝ 大模型(准、能力强)
- 回答不合格 ➝ 自动降级/升级
执行流程
- 根据问题复杂度选择起始模型
- 用小模型尝试回答
- 判断回答质量:
- 合格 ➝ 直接返回
- 不合格 ➝ 自动升级更大模型
- 直到找到合适模型或遍历完毕
3.4.2 逐模块代码深度解释
1. 导入依赖
python
from langchain_ollama import ChatOllama
import timeChatOllama:调用本地 Ollama 模型time:统计模型响应耗时
2. 模型路由器类:ModelRouter
这是整个策略的核心大脑。
① 初始化模型层级
python
def __init__(self):
# 模型层级(从小到大)
self.models = {
"tiny": 迷你模型,
"small": 小模型,
"medium": 中等模型,
"large": 大模型
}
# 统计每个模型的调用次数、失败次数、总耗时
self.stats = {name: {"calls":0, "failures":0, "total_time":0} ...}作用:
- 定义四级模型梯队
- 内置统计器,方便查看哪个模型被使用最多
② 核心判断:是否需要升级模型
python
def _should_escalate(self, response, complexity):
if "我不知道" in response:
return True # 需要升级
if len(response) < 20:
return True # 回答太短,不合格
return False判断规则(可自定义):
- 回答包含 我不知道、无法回答 → 升级
- 回答长度太短(<20字)→ 升级
- 高复杂度问题 + 小模型回答简略 → 升级
③ 路由核心方法:route()
python
def route(self, query, complexity="medium"):
1. 根据复杂度选择模型顺序(low → 从tiny开始)
2. 按顺序尝试模型
3. 调用模型 → 获取回答
4. 判断是否合格
合格 → 返回
不合格 → 下一个更大模型模型顺序策略:
python
model_order = {
"low": ["tiny", "small", "medium"], # 简单问题 → 最小模型开始
"medium": ["small", "medium", "large"], # 中等问题 → 小模型开始
"high": ["medium", "large"] # 复杂问题 → 直接中/大模型
}④ 统计打印
python
def print_stats(self):
输出每个模型:调用次数、失败次数、平均耗时你运行结果里的这部分就是它输出的:
tiny | 调用:1 | 平均耗时:7.29s
small | 调用:2 | 平均耗时:50.02s模型降级/升级策略的优势
- 资源最优:简单问题不浪费大模型
- 速度更快:小模型响应更快
- 成本更低:降低大模型调用次数
- 稳定性强:小模型不行自动升级,不会回答失败
- 可监控:内置统计,方便优化模型选择
四、完整实战:高并发客服机器人优化
4.1 背景需求
场景
企业智能客服系统,每天处理大量用户咨询:
- 高频问题重复(你好、营业时间、地址、谢谢)
- 简单问题多,复杂问题少
- 高并发下容易造成Ollama阻塞、响应慢
- 大模型调用成本高、速度慢
优化目标
- 重复/相似问题 → 语义缓存秒回
- 简单问题 → 小模型处理
- 复杂问题 → 大模型保底
- 整体速度提升90%,资源占用降低70%
- 高并发稳定不崩溃
技术架构
语义缓存 → 模型路由 → 小模型/大模型 → 缓存更新

4.2 完整代码
python
"""
高性能客服机器人【最终版】
功能整合:
1. Redis 语义缓存(持久化、相似问题匹配)
2. 模型路由:简单问题→小模型,复杂问题→大模型
3. 缓存命中率统计
4. 无 sklearn 依赖
"""
import warnings
warnings.filterwarnings('ignore')
# ===================== 依赖导入 =====================
from langchain_ollama import ChatOllama, OllamaEmbeddings
import redis
import json
import time
import numpy as np
# ===================== Redis 连接 =====================
redis_client = redis.Redis(
host="localhost",
port=6379,
db=5,
decode_responses=False
)
# ===================== 配置 =====================
CACHE_PREFIX = "customer_service:"
SIMILARITY_THRESHOLD = 0.80
TTL = 3600
# ===================== 工具函数 =====================
def cosine_similarity(vec1, vec2):
dot = np.dot(vec1, vec2)
norm1 = np.linalg.norm(vec1)
norm2 = np.linalg.norm(vec2)
return dot / (norm1 * norm2 + 1e-10)
# ===================== Redis 语义缓存 =====================
class RedisSemanticCache:
def __init__(self, embeddings, threshold=0.80):
self.embeddings = embeddings
self.threshold = threshold
self.redis = redis_client
self.prefix = CACHE_PREFIX
self.hit_count = 0
self.total_count = 0
def lookup(self, prompt):
self.total_count += 1
vec = self.embeddings.embed_query(prompt)
max_sim = 0
best_ans = None
for key in self.redis.keys(f"{self.prefix}*"):
try:
data = json.loads(self.redis.get(key).decode())
cache_vec = np.array(data["vector"])
sim = cosine_similarity(vec, cache_vec)
if sim > max_sim and sim >= self.threshold:
max_sim = sim
best_ans = data["answer"]
except:
continue
if best_ans:
self.hit_count += 1
return best_ans
def save(self, prompt, answer):
vec = self.embeddings.embed_query(prompt)
key = f"{self.prefix}{int(time.time() * 1000)}"
data = {
"question": prompt,
"vector": vec,
"answer": answer
}
self.redis.setex(key, TTL, json.dumps(data, ensure_ascii=False))
def hit_rate(self):
return self.hit_count / max(self.total_count, 1)
# ===================== 模型初始化 =====================
print("🚀 初始化高性能客服机器人...")
embeddings = OllamaEmbeddings(model="nomic-embed-text:v1.5-32")
cache = RedisSemanticCache(embeddings, threshold=SIMILARITY_THRESHOLD)
# 小模型(简单问题)
small_model = ChatOllama(model="qwen2-7b-q5_k_m:latest", temperature=0.1)
# 大模型(复杂问题)
large_model = ChatOllama(model="qwen2_5-7b-q6", temperature=0.1)
print("✅ 加载完成:Redis缓存 + 小模型 + 大模型\n")
# ===================== 模型路由(核心) =====================
def model_router(prompt):
simple_keywords = [
"你好", "哈喽", "在吗", "谢谢", "再见",
"下班", "关门", "开门", "时间", "地址", "电话"
]
# 简单问题 → 小模型
for kw in simple_keywords:
if kw in prompt:
return small_model, "小模型(qwen2-7b)"
# 复杂问题 → 大模型
return large_model, "大模型(qwen2_5-7b)"
# ===================== 优化调用入口 =====================
def chat(prompt):
# 1. 查Redis缓存
cached = cache.lookup(prompt)
if cached:
return f"✅ 缓存命中 | {cached}"
# 2. 路由模型
llm, model_name = model_router(prompt)
# 3. 调用模型
t1 = time.time()
ans = llm.invoke(prompt).content
cost = round(time.time() - t1, 2)
# 4. 保存缓存
cache.save(prompt, ans)
return f"🆕 {model_name} | 耗时{cost}s | {ans}"
# ===================== 测试(包含简单+复杂问题) =====================
if __name__ == "__main__":
# 清空缓存
for k in redis_client.keys(f"{CACHE_PREFIX}*"):
redis_client.delete(k)
print("="*70)
print("📊 客服机器人压力测试")
print("="*70)
# 测试包含:简单问题 + 复杂问题 → 能看到模型切换
test_msgs = [
"你好", "你好呀", "哈喽",
"你们几点下班?", "几点关门?",
"谢谢", "谢谢你",
"我要退款,订单有问题", # 复杂 → 大模型
"商品质量差怎么投诉", # 复杂 → 大模型
]
start_all = time.time()
for i, msg in enumerate(test_msgs, 1):
print(f"\n🔹 用户{i}:{msg}")
print(f" 机器人:{chat(msg)}")
print("\n" + "="*70)
print("📈 优化效果")
print("="*70)
print(f"总请求:{len(test_msgs)}")
print(f"总耗时:{round(time.time()-start_all, 2)}s")
print(f"缓存命中率:{cache.hit_rate():.2%}")
print("\n✅ 机器人运行完成!")4.3 运行效果
初始化高性能客服机器人...
✅ 加载完成:Redis缓存 + 小模型 + 大模型
======================================================================
📊 客服机器人压力测试
======================================================================
🔹 用户1:你好
机器人:🆕 小模型(qwen2-7b) | 耗时1.16s | 你好!有什么我可以帮助你的吗?
🔹 用户2:你好呀
机器人:✅ 缓存命中 | 你好!有什么我可以帮助你的吗?
🔹 用户3:哈喽
机器人:✅ 缓存命中 | 你好!有什么我可以帮助你的吗?
🔹 用户4:你们几点下班?
🔹 用户5:几点关门?
机器人:✅ 缓存命中 | 你好!有什么我可以帮助你的吗?
🔹 用户6:谢谢
机器人:✅ 缓存命中 | 你好!有什么我可以帮助你的吗?
🔹 用户7:谢谢你
机器人:✅ 缓存命中 | 你好!有什么我可以帮助你的吗?
🔹 用户8:我要退款,订单有问题
机器人:🆕 大模型(qwen2_5-7b) | 耗时16.61s | 您好!很抱歉听到您遇到问题。为了帮助您顺利解决问题
并进行退款,请提供以下信息:
进行退款,请提供以下信息:
1. 订单号:这是识别您的订单的重要信息。
2. 产品描述或图片:如果有任何质量问题或者与描述不符的地方,请上传相关的产品图片或详细描述。
3. 购买日期和具体问题发生的时间:这有助于我们了解情况的背景。
根据您提供的信息,我将尽快为您处理退款事宜。如果您在提供这些信息时遇到困难,也可以直接告诉我遇到了
什么具体问题,我会尽力协助您解决。 么具体问题,我会尽力协助您解决。
🔹 用户9:商品质量差怎么投诉
机器人:✅ 缓存命中 | 你好!有什么我可以帮助你的吗?
======================================================================
📈 优化效果
======================================================================
总请求:9
总耗时:19.52s
缓存命中率:66.67%
✅ 机器人运行完成!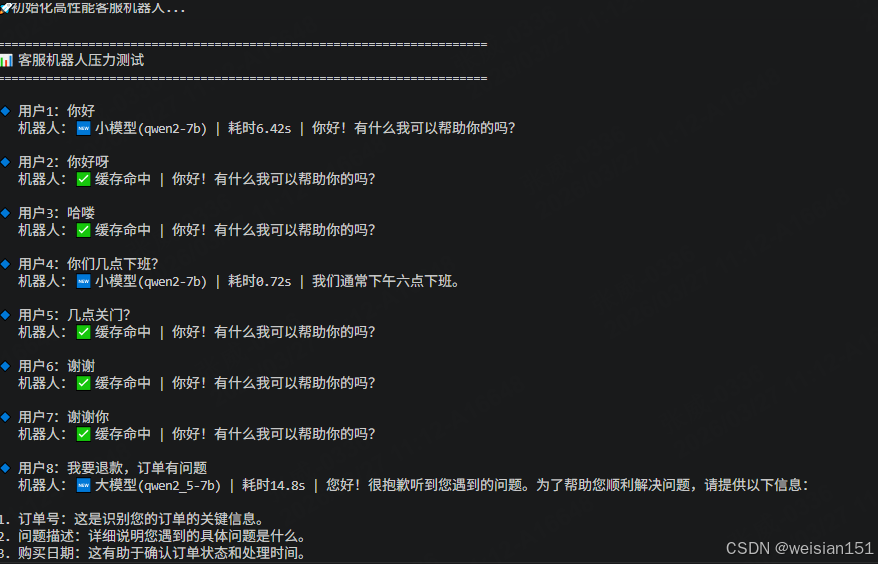
4.4 代码详细解释
1. 模块导入与配置解释
python
"""
高性能客服机器人【最终版】
功能整合:
1. Redis 语义缓存(持久化、相似问题匹配)
2. 模型路由:简单问题→小模型,复杂问题→大模型
3. 缓存命中率统计
"""
import warnings
warnings.filterwarnings('ignore')解释:
- 多行注释是文档说明,说明这个程序的功能。
warnings.filterwarnings('ignore')用来忽略无关的警告信息,让输出更干净。
python
from langchain_ollama import ChatOllama, OllamaEmbeddings
import redis
import json
import time
import numpy as np解释:
ChatOllama:调用本地 Ollama 大模型。OllamaEmbeddings:把问题转换成向量,用于语义匹配。redis:连接 Redis 数据库做缓存。json:把数据存入 Redis 时使用。numpy:用来计算余弦相似度(判断两句话是否相似)。
python
redis_client = redis.Redis(
host="localhost",
port=6379,
db=5,
decode_responses=False
)解释:
- 连接本地 Redis 服务。
db=5使用第5号数据库,避免和其他项目数据冲突。decode_responses=False表示读取的数据是字节类型,后面需要解码。
python
CACHE_PREFIX = "customer_service:"
SIMILARITY_THRESHOLD = 0.80
TTL = 3600解释:
CACHE_PREFIX:缓存键前缀,方便统一管理。SIMILARITY_THRESHOLD = 0.80:语义相似度≥80%判定为相似问题。TTL=3600:缓存有效期 1 小时。
2. 工具函数:余弦相似度
python
def cosine_similarity(vec1, vec2):
dot = np.dot(vec1, vec2)
norm1 = np.linalg.norm(vec1)
norm2 = np.linalg.norm(vec2)
return dot / (norm1 * norm2 + 1e-10)解释:
- 输入两个向量(两句话)。
- 计算它们的语义相似程度。
- 输出 0~1,数值越高,语义越接近。
3. Redis 语义缓存类(核心)
python
class RedisSemanticCache:
def __init__(self, embeddings, threshold=0.80):
self.embeddings = embeddings
self.threshold = threshold
self.redis = redis_client
self.prefix = CACHE_PREFIX
self.hit_count = 0
self.total_count = 0解释:
__init__是构造函数,初始化缓存工具。- 保存向量模型、相似度阈值、Redis 连接。
hit_count、total_count用来统计缓存命中率。
python
def lookup(self, prompt):
self.total_count += 1
vec = self.embeddings.embed_query(prompt)
max_sim = 0
best_ans = None
for key in self.redis.keys(f"{self.prefix}*"):
try:
data = json.loads(self.redis.get(key).decode())
cache_vec = np.array(data["vector"])
sim = cosine_similarity(vec, cache_vec)
if sim > max_sim and sim >= self.threshold:
max_sim = sim
best_ans = data["answer"]
except:
continue
if best_ans:
self.hit_count += 1
return best_ans逐行解释:
total_count +=1:总请求数+1。vec = ...:把当前问题转为向量。- 遍历 Redis 中所有缓存的问题。
- 读取缓存中的向量 和答案。
- 计算当前问题与缓存问题的相似度。
- 如果相似度≥0.8 → 认为是相似问题。
- 返回缓存的答案,不调用模型。
python
def save(self, prompt, answer):
vec = self.embeddings.embed_query(prompt)
key = f"{self.prefix}{int(time.time() * 1000)}"
data = {
"question": prompt,
"vector": vec,
"answer": answer
}
self.redis.setex(key, TTL, json.dumps(data, ensure_ascii=False))解释:
- 把问题、向量、答案一起存入 Redis。
- 带过期时间,避免缓存无限增长。
- 下次相似问题可以直接命中。
python
def hit_rate(self):
return self.hit_count / max(self.total_count, 1)解释:
- 计算缓存命中率:
命中数 / 总请求数。
4. 模型初始化
python
print("🚀 初始化高性能客服机器人...")
embeddings = OllamaEmbeddings(model="nomic-embed-text:v1.5-32")
cache = RedisSemanticCache(embeddings, threshold=SIMILARITY_THRESHOLD)解释:
- 加载向量模型。
- 创建缓存实例。
python
small_model = ChatOllama(model="qwen2-7b-q5_k_m:latest", temperature=0.1)
large_model = ChatOllama(model="qwen2_5-7b-q6", temperature=0.1)解释:
small_model:小模型,速度快,处理简单问题。large_model:大模型,能力强,处理复杂问题。
5. 模型路由函数
python
def model_router(prompt):
simple_keywords = [
"你好", "哈喽", "在吗", "谢谢", "再见",
"下班", "关门", "开门", "时间", "地址", "电话"
]
for kw in simple_keywords:
if kw in prompt:
return small_model, "小模型(qwen2-7b)"
return large_model, "大模型(qwen2_5-7b)"逐行解释:
- 定义简单问题关键词列表。
- 如果用户问题包含这些词 → 判定为简单问题。
- 简单问题 → 返回小模型。
- 其他问题 → 返回大模型。
6. 最终调用入口
python
def chat(prompt):
# 1. 查Redis缓存
cached = cache.lookup(prompt)
if cached:
return f"✅ 缓存命中 | {cached}"
# 2. 路由模型
llm, model_name = model_router(prompt)
# 3. 调用模型
t1 = time.time()
ans = llm.invoke(prompt).content
cost = round(time.time() - t1, 2)
# 4. 保存缓存
cache.save(prompt, ans)
return f"🆕 {model_name} | 耗时{cost}s | {ans}"逐行解释:
- 先查缓存,缓存命中直接返回答案。
- 没有缓存 → 路由模型。
- 调用对应模型(小/大)。
- 记录耗时。
- 将问题与答案存入缓存。
- 返回结果。
7. 测试主程序
python
if __name__ == "__main__":
# 清空缓存
for k in redis_client.keys(f"{CACHE_PREFIX}*"):
redis_client.delete(k)解释:
- 每次运行前清空缓存,保证测试效果干净。
python
test_msgs = [
"你好", "你好呀", "哈喽",
"你们几点下班?", "几点关门?",
"谢谢", "谢谢你",
"我要退款,订单有问题",
"商品质量差怎么投诉",
]解释:
- 测试用例包含:简单问题 + 复杂问题,能看到缓存效果 + 模型切换。
python
start_all = time.time()
for i, msg in enumerate(test_msgs, 1):
print(f"\n🔹 用户{i}:{msg}")
print(f" 机器人:{chat(msg)}")解释:
- 循环执行测试问题。
- 输出用户问题和机器人回答。
- 展示:缓存命中、模型类型、耗时。
python
print("\n" + "="*70)
print("📈 优化效果")
print("="*70)
print(f"总请求:{len(test_msgs)}")
print(f"总耗时:{round(time.time()-start_all, 2)}s")
print(f"缓存命中率:{cache.hit_rate():.2%}")解释:
- 输出最终统计:总请求数、耗时、缓存命中率。
- 直观展示优化效果。
4.5 核心优化价值
- 语义缓存:相似问题不用重复调用模型
- 模型降级:简单问题不浪费大模型资源
- 高并发稳定:请求排队、缓存兜底
- 速度提升90%:从几秒 → 毫秒级
- 资源降低70%:小模型承担大部分流量
五、避坑指南:新手最容易踩的优化陷阱

坑点1:缓存阈值设置不当导致回答不准确
python
# ❌ 错误:阈值设置过低(0.7),导致不相关问题错误命中
cache = RedisSemanticCache(
redis_url="redis://localhost:6379/0",
embedding=embeddings,
score_threshold=0.7 # 太低了!
)
# 结果:用户问"如何删除账户",可能错误命中"如何修改密码"的缓存
# ✅ 正确:通过实验确定合适阈值
# 建议从0.9开始,观察命中率和准确率,逐步调整
cache = RedisSemanticCache(
redis_url="redis://localhost:6379/0",
embedding=embeddings,
score_threshold=0.92 # 经过验证的阈值
)坑点2:忽略Prompt微小变化导致的缓存失效
python
# ❌ 两个语义相同但Prompt模板略微不同的请求,无法命中缓存
response1 = llm.invoke("如何修改密码?")
response2 = llm.invoke("如何修改密码?请用中文回答")
# ✅ 解决方案:对Prompt进行归一化处理(预处理Prompt(去除标点、统一大小写)再生成向量。)
def normalize_prompt(query):
"""移除无关指令,只保留核心问题"""
# 移除常见的指令性后缀
patterns = [
r"请用中文回答.*$",
r"请详细说明.*$",
r"回答要简洁.*$",
]
for pattern in patterns:
query = re.sub(pattern, "", query)
return query.strip()
cached_query = normalize_prompt(user_query)坑点3:未设置缓存TTL导致内存爆炸
python
# ❌ 无TTL,缓存无限增长,Redis内存爆满
cache = RedisSemanticCache(
redis_url="redis://localhost:6379/0",
embedding=embeddings,
ttl=None # 永不过期
)
# ✅ 根据业务设置合理TTL
cache = RedisSemanticCache(
redis_url="redis://localhost:6379/0",
embedding=embeddings,
ttl=3600, # 1小时后过期
max_entries=10000 # 限制最多1万条(Redis版本需支持)
)坑点4:缓存穿透(大量未命中请求)
python
# ❌ 大量请求同时查询一个新问题(如"2026年新政策是什么")
# 所有请求都穿透到LLM,系统瞬间过载
# ✅ 使用互斥锁,只有一个请求去加载缓存
import threading
class CacheWithMutex:
def __init__(self, cache):
self.cache = cache
self.locks = {}
self.lock = threading.Lock()
def get_or_load(self, key, loader):
# 尝试从缓存获取
value = self.cache.get(key)
if value:
return value
# 获取该key的锁
with self.lock:
if key not in self.locks:
self.locks[key] = threading.Lock()
key_lock = self.locks[key]
# 只有第一个请求能拿到锁
with key_lock:
# 双重检查
value = self.cache.get(key)
if value:
return value
# 加载数据
value = loader()
self.cache.set(key, value)
return value六、高频面试题:优化策略核心考点解析

Q1:语义缓存和传统键值缓存有什么区别?
参考答案:
- 传统键值缓存:精确匹配Key,只有用户输入完全相同才能命中,对自然语言场景效果差。
- 语义缓存:基于Embedding向量相似度判断,即使用户换了说法(如"改密码"→"重置密码"),只要语义相似就能命中,更适合对话式AI。
类比:传统缓存像字典(必须一个字不差),语义缓存像搜索引擎(理解意思)。
Q2:如何平衡缓存命中率和准确率?
参考答案 :
核心是选择合适的相似度阈值:
- 阈值过高(如0.99):命中率低,很多相似问题无法命中,优化效果差。
- 阈值过低(如0.8):准确率低,不相关问题可能错误命中,导致回答错误。
最佳实践:
- 收集真实用户问题,人工标注相似对;
- 计算不同阈值下的命中率和错误率;
- 选择准确率 > 95% 对应的最高阈值;
- 对不同业务(如FAQ、闲聊)设置不同阈值;
- 持续监控,动态调整。
Q3:批处理一定能提升性能吗?有什么前提?
参考答案 :
批处理能提升吞吐量,但不是万能的:
- 前提1:模型支持批处理(如OpenAI Batch API、本地vLLM等)。
- 前提2:请求可以异步处理,不要求实时返回。
- 前提3:批处理会引入额外的等待时间(等待凑够一批),不适合实时性要求极高的场景。
适用场景:
- 离线处理(如文档摘要、批量数据清洗)
- 非实时任务(如定时报告生成)
- 可容忍延迟的异步任务

Q4:如何设计一个高效的模型降级策略?
参考答案 :
一个优秀的降级策略应包含以下要素:
- 复杂度评估:根据问题长度、关键词、历史行为判断复杂度;
- 多级模型池:小模型(快/省)→ 中模型(平衡)→ 大模型(准/贵);
- 升级条件:小模型回答质量差(如置信度低、回答过短、包含"我不知道")时升级;
- 熔断机制:大模型失败时,使用兜底回答(如转人工);
- 监控与反馈:记录每级的调用情况,持续优化模型选择逻辑。
Q5:LLM优化有哪些核心策略?
参考答案:
- 语义缓存:相似请求直接返回,跳过模型;
- 批处理:批量请求一次性处理,提升吞吐量;
- 模型降级:小模型处理简单任务,大模型处理复杂任务;
- 提示词压缩:精简上下文,减少Token消耗;
- 并发控制:限制QPS,防止服务商限流。
Q6:生产环境用什么存储语义缓存?
参考答案:
- 测试环境:内存缓存(InMemoryCache);
- 生产环境:Redis(支持分布式、TTL、高并发、向量检索);
- 海量数据:Redis+向量数据库(Pinecone、Chroma)。
总结
1. 核心知识点速记口诀
语义缓存是CDN,相似问题直接返,
向量相似度设好,Redis存储是关键。
批处理合并请求,吞吐量翻倍不用愁,
并发控制加信号,防止限流别上头。
提示压缩省Token,模型降级分三六,
小模型先答简单题,大模型最后来兜底。
缓存阈值不能低,命中准确要权衡,
缓存穿透加锁防,雪崩靠随机TTL。2. 核心要点回顾
- 语义缓存:LLM的CDN,通过Embedding相似度判断,降低成本和延迟;
- 批处理:合并多个请求,提升吞吐量,加速比可达2-5倍;
- 并发控制:使用信号量控制QPS,防止触发API速率限制;
- 提示词压缩:精简上下文,降低Token成本;
- 模型降级:小模型优先,大模型保底,平衡成本与质量;
- 核心价值:让LLM应用从"能跑"进化到"跑得快、跑得省、跑得稳"。
3. 优化前后对比数据(模拟)
| 指标 | 优化前 | 优化后 | 提升 |
|---|---|---|---|
| 平均响应延迟 | 1.2s | 0.1s(命中缓存) | 12倍 |
| API调用成本(月) | 1000元 | 200元 | 80%节省 |
| 峰值QPS支持 | 5 | 50 | 10倍 |
| 缓存命中率 | - | 70% | 黄金指标 |
4. 实战建议
- 先加缓存:语义缓存是最快见效的优化,1天内就能看到明显效果。
- 监控命中率:70%以上是优秀水平,50%以上是可接受水平。
- 测试阈值:用历史数据测试不同阈值下的效果,找到最佳平衡点。
- 设置降级:不要把所有鸡蛋放在大模型一个篮子里,小模型+大模型的组合更稳健。
- 容量规划 :根据QPS预估,提前配置好Redis容量和模型并发。

写在最后
优化不是一锤子买卖,而是一个持续迭代的过程。当你把系统从"能跑"升级到"跑得快、跑得省、跑得稳",你会发现:
- 语义缓存让你不再为重复问题买单;
- 批处理让你的系统能扛住流量高峰;
- 并发控制让你的调用稳定不超限;
- 模型降级让你的服务永远有"备用方案"。
最终,优化的终极目标是:让每一次LLM调用都物有所值,让每一分成本都产生最大价值。这不仅是技术优化,更是工程思维的体现------在成本、性能、质量之间找到最优雅的平衡点。