目录
[1. 定义 Pydantic 模型(定格式)](#1. 定义 Pydantic 模型(定格式))
[2. 创建解析器(绑定模型)](#2. 创建解析器(绑定模型))
[3. 注入提示模板(教模型怎么输出)](#3. 注入提示模板(教模型怎么输出))
[4. 链式调用(一键结构化)](#4. 链式调用(一键结构化))
[1. 代码样例](#1. 代码样例)
[2. 属性](#2. 属性)
[3. 关键理解](#3. 关键理解)
[4. 代码扩展:更完整的 metadata](#4. 代码扩展:更完整的 metadata)
[5. 直观比喻](#5. 直观比喻)
[✅ 总结](#✅ 总结)
[1. 流程](#1. 流程)
[2. 特性](#2. 特性)
[3. 常见问题与局限](#3. 常见问题与局限)
[✅ 总结](#✅ 总结)
[1. 代码与两种模式](#1. 代码与两种模式)
[2. elements 模式的核心特性](#2. elements 模式的核心特性)
[3. 代码解读](#3. 代码解读)
[4. 支持的元素类型(category 取值)](#4. 支持的元素类型(category 取值))
[5. 与 PyPDFLoader 的对比](#5. 与 PyPDFLoader 的对比)
[✅ 总结](#✅ 总结)
[为什么用 Token 拆分?](#为什么用 Token 拆分?)
[1. 写法一:基于 Token 计数(适配模型)](#1. 写法一:基于 Token 计数(适配模型))
[2. 写法二:基于字符计数(简单直观)](#2. 写法二:基于字符计数(简单直观))
[3. 共同点](#3. 共同点)
[4. 参数对比](#4. 参数对比)
[1. 流程总结](#1. 流程总结)
[2. 每步作用](#2. 每步作用)
[3. 目的](#3. 目的)
[向量存储在 RAG 中的位置](#向量存储在 RAG 中的位置)
核心组件(下)
输出解析器
Pydantic
python
from typing import Optional
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import PydanticOutputParser
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
# 1. 定义聊天模型
model = ChatOpenAI(model="gpt-4o-mini")
# 2. 定义 Pydantic 输出结构(约束模型输出格式)
class Joke(BaseModel):
"""给用户讲的一个笑话"""
setup: str = Field(description="这个笑话的开头")
punchline: str = Field(description="这个笑话的妙语")
rating: Optional[int] = Field(default=None, description="从1-10分,给这个笑话评分")
# 3. 定义 Pydantic 解析器
parser = PydanticOutputParser(pydantic_object=Joke)
# 4. 构建提示模板(自动注入格式要求)
prompt = PromptTemplate(
template="回复用户问题。\n返回结构说明:{format_instructions}\n用户问题:{query}\n",
partial_variables={"format_instructions": parser.get_format_instructions()},
input_variables=["query"],
)
# 5. 构建链:提示模板 → 模型 → 解析器
chain = prompt | model | parser
# 6. 调用链并获取结构化结果
result = chain.invoke({"query": "讲一个关于跳舞的笑话"})
print(result)PydanticOutputParser 是 LangChain 中用于将模型输出解析为 Pydantic 模型对象的工具,核心作用是:
- 强制模型输出严格结构化的 JSON,和定义的 Pydantic 类完全对齐。
- 自动把模型返回的 JSON 字符串转成可直接操作的 Python 对象,避免手动解析 JSON。
- 用
Field(description="...")给模型明确字段含义,减少输出歧义。
步骤拆解
1. 定义 Pydantic 模型(定格式)
2. 创建解析器(绑定模型)
python
parser = PydanticOutputParser(pydantic_object=Joke)- 解析器和
Joke类绑定,知道要把输出解析成这个结构。 parser.get_format_instructions():自动生成一段提示词,告诉模型必须返回什么样的 JSON 结构。
3. 注入提示模板(教模型怎么输出)
python
prompt = PromptTemplate(
template="回复用户问题。\n返回结构说明:{format_instructions}\n用户问题:{query}\n",
partial_variables={"format_instructions": parser.get_format_instructions()},
input_variables=["query"],
)- 把
parser.get_format_instructions()注入提示词,让模型在生成前就知道输出格式。 - 比如生成的提示会包含:
"返回一个JSON对象,包含setup、punchline、rating字段..."。
4. 链式调用(一键结构化)
python
chain = prompt | model | parser
result = chain.invoke({"query": "讲一个关于跳舞的笑话"})- 流程:
用户问题 → 提示模板 → 模型生成JSON → 解析器转成Joke对象。 - 最终
result是一个Joke实例,可以直接用result.setup、result.punchline访问字段。
运行示例
调用后模型会返回类似 JSON:
python
{
"setup": "为什么跳舞的人不喜欢下雨?",
"punchline": "因为怕踩到雷(蕾)!",
"rating": 8
}解析后 result 就是:
python
Joke(
setup="为什么跳舞的人不喜欢下雨?",
punchline="因为怕踩到雷(蕾)!",
rating=8
)可以直接 print(result.setup) 拿到笑话开头。
总结
✅ 格式严格:模型必须按你定义的结构输出,不会乱答。
✅ 自动解析:不用手动写 JSON 解析代码,直接用对象访问字段。
✅ 语义清晰 :Field(description) 让模型理解每个字段的用途,减少歧义。
✅ 类型安全 :Pydantic 会自动校验类型(比如 rating 必须是 int 或 None),避免格式错误。
和 with_structured_output 的对比
| 方式 | 实现 | 优点 | 缺点 |
|---|---|---|---|
PydanticOutputParser |
手动写提示 + 解析器 | 兼容性好,支持所有模型 | 代码稍多 |
model.with_structured_output |
模型原生结构化输出 | 代码极简,效果更稳 | 依赖模型对函数调用 / 结构化输出的支持 |
JSON

JsonOutputParser 是 LangChain 中专门用于解析 JSON 格式输出的工具,核心作用是将模型返回的 JSON 字符串转换为可操作的 Python 对象,并可通过 Pydantic 进行格式校验。
参数与用法
pydantic_object:可选,传入 Pydantic 模型后,解析器会自动验证输出是否符合结构;若为空则仅做 JSON 解析,不校验格式。invoke():将模型输出的 JSON 字符串转换为 Python 字典或 Pydantic 对象。get_format_instructions():关键方法,自动生成格式指令字符串,嵌入提示词中,明确告诉 LLM 必须返回指定结构的 JSON,避免格式混乱。
其他常见输出解析器
除了 JSON 解析器,LangChain 还提供了丰富的结构化输出解析器,覆盖不同格式场景:
| 解析器类型 | 类名 | 适用场景 |
|---|---|---|
| XML 解析器 | XMLOutputParser |
需要输出 XML 格式的场景 |
| YAML 解析器 | YamlOutputParser |
适合配置、层级化数据的 YAML 格式 |
| CSV 解析器 | CommaSeparatedListOutputParser |
输出逗号分隔的列表 / 表格数据 |
| 枚举解析器 | EnumOutputParser |
限定输出为预定义的枚举值(如分类标签) |
| 日期解析器 | DatetimeOutputParser |
强制输出为标准日期 / 时间格式 |
| 自定义解析器 | 自定义类 | 特殊格式需求,可继承基类实现自定义解析逻辑 |
特点
- 格式可控:通过提示词指令 + 解析器校验,保证模型输出严格符合目标格式,避免自由文本。
- 自动解析:无需手动写 JSON/XML 解析代码,直接拿到可操作的 Python 对象。
- 灵活扩展:支持多种格式,且可自定义解析器,适配复杂业务需求。
- 类型安全:结合 Pydantic 可实现字段类型、必填项等校验,提升数据可靠性。
文档加载器
RAG
RAG(Retrieval-Augmented Generation,检索增强生成)是一种 ** 让大模型 "读外部知识库再回答"** 的技术,解决模型 "知识陈旧、信息不准、无法回答私有数据" 的问题。
概念
1. RAG的流程拆解
RAG 的核心逻辑:
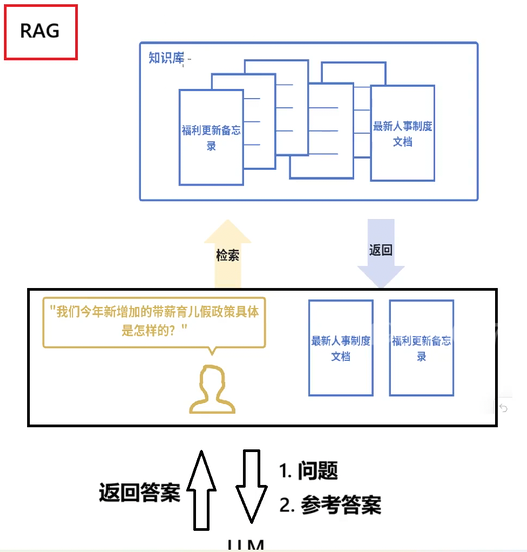
- 用户提问:比如「我们今年新增加的带薪育儿假政策具体是怎样的?」
- 检索知识库 :系统从内部知识库(福利更新备忘录、最新人事制度文档等)里,找出和问题最相关的文档片段。
- LLM 生成答案 :把检索到的文档片段作为「参考资料」,和用户问题一起喂给大模型,让模型基于这些资料总结出直接答案,而不是只返回文档链接。
2. 解决的痛点
- 传统检索:只返回相关文档,需要用户自己阅读总结,效率低。
- 纯大模型:知识截止到训练时间,**无法回答新政策、内部文档这类私有信息,**容易 "胡说八道"(幻觉)。
- RAG:既利用知识库的准确信息,又用大模型的语言能力生成自然答案,做到 "有据可查、直接可读"。
3. 核心流程(标准 RAG pipeline)
- 知识库构建 :把文档(本地PDF/Word/ 文本)切分成小块(以4主题,功能等不同特性进行切分) → 转成向量(调用嵌入模型将其转换成向量) → 存入向量数据库。
- 检索阶段 :用户问题转成向量 → 在向量库中相似度检索,找出最相关的文档片段。
- 生成阶段:将「问题 + 检索到的参考片段」拼到提示词里 → 大模型基于这些资料生成最终答案。
4. 特点
✅ 知识更新快:不需要重新训练模型,只要往知识库加新文档,就能回答新问题(比如新政策)。
✅ 减少幻觉:答案基于真实文档,能标注引用来源,更可信。
✅ 适配私有数据:企业内部文档、个人笔记都能作为知识库,不需要公开训练。
✅ 成本更低:相比微调大模型,RAG 实现简单、成本更低。
5. 比喻
如果把大模型比作「学生」:
- 纯大模型:闭卷考试,只能靠脑子里已有的知识答题,容易记错。
- RAG:开卷考试,允许你翻指定的参考书,然后用自己的话总结答案,既准确又流畅。
Document文档类
Document 是 LangChain 中承载文本内容与元数据的最小单位,在 RAG 流程里,它就是被切分、向量化、检索的 "文档片段"。
1. 代码样例
python
from langchain_core.documents import Document
# 手动定义的文档列表
documents = [
# 单个 Document 代表大文档的某个块/某一页
Document(
page_content="狗是忠实的伙伴", # 核心:文本内容
metadata={"source": "pets-doc"}, # 附加:元数据(来源、关系、属性等)
),
Document(
page_content="猫是很好的的宠物",
metadata={"source": "pets-doc"},
),
]2. 属性
| 属性名 | 作用 | 你的代码示例 |
|---|---|---|
page_content |
必填 ,存储文档的纯文本内容,是后续向量化和检索的主体 | "狗是忠实的伙伴" |
metadata |
可选 ,字典格式,存储附加信息(来源、作者、页码、时间等) | {"source": "pets-doc"} |
3. 关键理解
- 最小粒度 :一个
Document通常是大文档(如 PDF / 长文)切分后的片段,而不是整个文件。 - 元数据的价值 :
- 标注来源:方便后续引用溯源(比如告诉用户 "答案来自 pets-doc 文档")。
- 过滤检索:可以在检索时根据 metadata 筛选(比如只查来自 "pets-doc" 的内容)。
- RAG 中的角色 :
- 文档加载 → 切分成多个
Document - 向量化 → 把
page_content转成向量 - 检索 → 找到和问题最相似的
Document片段 - 生成 → 把
page_content喂给 LLM 做参考
- 文档加载 → 切分成多个
4. 代码扩展:更完整的 metadata
python
Document(
page_content="狗是忠实的伙伴,平均寿命约12-15年",
metadata={
"source": "pets-doc",
"author": "pet-expert",
"page": 5,
"category": "dog",
"created_at": "2025-05-22"
}
)这些元数据可以在检索时做更精细的控制,比如只返回 2025 年之后的文档。
5. 直观比喻
如果把知识库比作一本书:
- 整本书 = 原始文档(PDF/Word)
- 每一页 / 每一段 = 一个
Document page_content= 这一页的文字metadata= 这一页的页码、章节、作者等信息
✅ 总结
Document 是 LangChain 里文本的标准包装:
- 用
page_content存内容 - 用
metadata存上下文信息 - 是 RAG 流程里 "切分 → 入库 → 检索 → 生成" 的核心数据单元
加载PDF文档
1. 流程
python
from langchain_community.document_loaders import PyPDFLoader
# 1. 初始化加载器:指定 PDF 路径
loader = PyPDFLoader(file_path="你的pdf文档路径")
# 2. 执行加载:按页拆分成 Document 列表
docs = loader.load()loader.load():遍历 PDF 每一页,一页生成一个Document,最终docs的长度 = PDF 总页数。- 你的代码里
len(docs)就是总页数,比如 32 页就会得到 32 个Document。
2. 特性
-
按页拆分 :
PyPDFLoader只做物理分页拆分,不会按语义 / 字数拆分。 -
文本提取 :只提取纯文本内容,图片、图表、公式等非文本内容会被忽略(需要多模态 Loader 才能处理图片)。
-
元数据自动填充 :每个
Document的metadata会自动包含:source: PDF 文件路径page: 当前页码(从 0 开始计数)
python# 示例输出 print(docs[0].metadata) # {'source': 'xxx.pdf', 'page': 0}
3. 常见问题与局限
- 图片 / 图表去哪了?
PyPDFLoader是纯文本加载器 ,无法提取图片、矢量图、扫描版 PDF 的文字。如果需要处理图片,需要用:- 多模态加载器(如
AmazonTextractPDFLoader、PyMuPDFLoader配合 OCR) - 先把 PDF 转图片,再用视觉模型提取文字
- 多模态加载器(如
- 跨页语义被切断 一个完整知识点如果跨了 2~3 页,按页拆分后会被切成多个
Document,需要后续用文档拆分器做细粒度语义切割,才能保证 RAG 检索的完整性。 - 长页问题 单页文本过长时(比如几千字),需要用
RecursiveCharacterTextSplitter再切分成小块,才能适配模型上下文窗口和向量检索。
✅ 总结
PyPDFLoader 是 PDF 文本加载的基础工具:
- 核心:按页拆成
Document,文本提取 + 元数据自动管理 - 局限:只处理纯文本,不处理图片,粒度粗(整页)
- 定位:RAG 流程的第一步,后续必须配合文档拆分器才能用于生产环境
加载Markdown文件
UnstructuredMarkdownLoader 是专门加载 Markdown 文件 的加载器,最大特点是能按 Markdown 结构(标题、段落、列表等)智能拆分,比纯文本加载更贴合文档语义。
1. 代码与两种模式
python
from langchain_community.document_loaders import UnstructuredMarkdownLoader
# 初始化加载器
md_loader = UnstructuredMarkdownLoader(
file_path="test.md",
mode="elements", # 关键:拆分模式
# mode="single" # 默认:整个文档加载为 1 个 Document
)
# 执行加载 → 拆分后的 Document 列表
docs = md_loader.load()| 模式 | 行为 | 适用场景 |
|---|---|---|
single(默认) |
把整个 MD 文件读成 1 个 Document,不拆分 | 简单文档、不需要结构化拆分 |
elements |
按 MD 元素拆成多个 Document,保留结构信息 | 复杂文档、需要按标题 / 段落 / 列表精细管理 |
2. elements 模式的核心特性
mode="elements",这是最强大的模式:
- 按 Markdown 元素拆分 :标题、段落、列表、表格、图片等都会被拆成独立
Document。 - 保留结构关系 :通过
parent_id/element_id记录元素层级(比如子标题的parent_id指向父标题)。 - 元数据更丰富 :每个
Document的metadata包含:source: 文件路径category: 元素类型(Title/NarrativeText/ListItem/Table/Image等)element_id: 元素唯一 IDparent_id: 父元素 ID(用于还原文档结构)
python
# 示例元数据输出
print(docs[0].metadata)
# 输出类似:
# {
# 'source': '../Docs/markdown/xxx.md',
# 'category': 'Title',
# 'element_id': '3a0670f9bfd58576e430ef11def41593',
# 'parent_id': None
# }3. 代码解读
python
# 打印拆分后的 Document 总数(等于 MD 元素数量)
print(f"MD文档总数:\n{len(docs)}\n")
# 查看第一个 Document(通常是一级标题)
print(f"第一个文档的内容是:\n{docs[0].page_content}\n")
print(f"第一个文档的元数据字典是:\n{docs[0].metadata}\n")
# 查看第二个 Document(通常是二级标题,parent_id 指向一级标题)
print(f"第二个文档的内容是:\n{docs[1].page_content}\n")
print(f"第二个文档的元数据字典是:\n{docs[1].metadata}\n")
# 查看第三个 Document(通常是段落文本,category=UncategorizedText/NarrativeText)
print(f"第三个文档的内容是:\n{docs[2].page_content}\n")
print(f"第三个文档的元数据字典是:\n{docs[2].metadata}\n")
# 统计所有元素类型
print(f"当前MD文档的所有分类:{set(doc.metadata['category'] for doc in docs)}")4. 支持的元素类型(category 取值)
UnstructuredMarkdownLoader 能识别:
Title: 标题(#、##、###...)NarrativeText: 叙事性文本(普通段落)ListItem: 列表项(-、*、1. 等)Table: 表格Image: 图片UncategorizedText: 未分类文本
这些类型让我们可以精准过滤内容,比如只检索标题和段落,忽略表格 / 图片。
5. 与 PyPDFLoader 的对比
| 维度 | PyPDFLoader | UnstructuredMarkdownLoader (elements 模式) |
|---|---|---|
| 拆分依据 | 物理页码 | Markdown 语义元素(标题 / 段落 / 列表等) |
| 粒度 | 整页 | 细粒度元素(一个标题 / 一段文字 = 一个 Document) |
| 元数据 | 页码 + 来源 | 元素类型 + ID + 层级关系 |
| 适用场景 | PDF 纯文本提取 | Markdown 结构化文档,需要保留语义层级 |
✅ 总结
UnstructuredMarkdownLoader 是加载 Markdown 的专业工具:
- 核心:
mode="elements"能按语义结构拆分,保留文档层级和元素类型。 - 优势:比纯文本加载更智能,适合复杂 MD 文档(如技术文档、Q&A),方便后续检索和过滤。
- 定位:RAG 流程中处理结构化 Markdown 的首选。
文档分割器
概念
核心作用:把长文档切成语义完整、大小合适的小块(Chunk),适配模型上下文和向量检索。
要点
- 为什么要切 :
- 模型有 Token 上限,超长文本塞不下
- 太长会稀释语义,检索不准;太短会丢上下文
- 拆分原则 :
- 优先在自然边界(段落、换行、标点)处切,保证语义完整
- 用
chunk_size控制块大小,chunk_overlap保留相邻块上下文
- 最常用实现 :
RecursiveCharacterTextSplitter:按「段落→换行→空格→字符」递归拆分,通用且效果最好。 - 典型参数 :
chunk_size=1000:每块约 1000 字符chunk_overlap=200:相邻块重叠 200 字符,避免语义断裂
总结
文档分割器 = 长文本 → 小块(语义完整 + 长短合适),是 RAG 必用的 "切块工具"。
基于字符串长度拆分
按指定分隔符把长文本切成固定大小的块,是最基础的「字符串切割」分割器。
参数
python
text_splitter = CharacterTextSplitter(
separator="\n\n", # 分隔符:优先按双换行(段落)切
chunk_size=400, # 每块最大约400字符
chunk_overlap=50, # 相邻块重叠50字符,保证语义连贯
length_function=len, # 长度计算:按字符数
is_separator_regex=False, # 分隔符是否为正则表达式
)separator="\n\n":先在段落分隔处 拆分,尽量不拆碎完整段落;如果拆完还超过chunk_size,会继续按默认优先级(\n\n→\n→ 空格 → 字符)递归切。chunk_size=400:目标块大小,允许超过(为了保证句子 / 段落完整)。chunk_overlap=50:相邻块共享 50 字符,避免跨块语义断裂。length_function=len:默认按字符计数,也可以换成 Token 计数。
工作流程
- 把整个文档按
separator="\n\n"拆成段落。 - 若某段落长度 ≤400 → 直接作为一个块。
- 若某段落长度 >400 → 继续按
\n→ 空格 → 字符逐级拆分,直到块大小 ≤400。 - 相邻块重叠 50 字符,保证上下文不丢失。
适用场景
- 简单文本、Markdown 等有明显段落分隔的文档。
- 不需要复杂语义拆分,追求高效、直观的切块。
总结
CharacterTextSplitter = 按分隔符 + 块大小的「粗暴但好用」字符串切割,是 RAG 入门最易理解的分割器。
基于token长度拆分
CharacterTextSplitter.from_tiktoken_encoder 是按 Token 计数来切分文档,比按字符计数更贴合模型上下文限制。
参数解析
python
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", # tiktoken 编码方式(对应 GPT-3.5/4 等模型)
chunk_size=400, # 每块最大 400 Token
chunk_overlap=50, # 相邻块重叠 50 Token
)关键概念
- Token:模型处理文本的最小单位(1 个 Token ≈ 0.75 个英文单词,中文更接近 1:1)。
encoding_name="cl100k_base":OpenAI 模型用的分词编码,和模型上下文窗口完全对齐。chunk_size=400:块大小以 Token 数为单位,而非字符数,更精准控制模型输入长度。- 拆分逻辑 :和普通
CharacterTextSplitter一样按分隔符切,但长度判断用tiktoken分词计数,保证块大小不超过模型 Token 限制。
为什么用 Token 拆分?
- 精准适配模型:模型上下文是按 Token 算的(比如 4k/8k/32k Token),按字符切容易超限制。
- 避免截断语义:按 Token 切更贴合模型实际输入,不会出现「字符数够但 Token 超了」的问题。
- 兼容性更好:不同语言(中英混合)下,Token 计数比字符计数更稳定。
总结
Token 拆分 = 用 tiktoken 按模型原生 Token 计数切分,让块大小严格匹配模型上下文,是生产环境更可靠的拆分方式。
强制长度拆分
RecursiveCharacterTextSplitter是 LangChain 最通用的递归语义分割器 ,核心是「按自然边界优先拆分,保证语义完整」,两种写法只是计数方式不同。
1. 写法一:基于 Token 计数(适配模型)
python
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", # 对齐 GPT 模型的分词规则
chunk_size=100, # 每块最大 100 Token
chunk_overlap=0, # 块之间无重叠
)- 计数方式 :用
tiktoken按 Token 数 计算块大小,和模型上下文窗口完全对齐。 - 优势:精准控制输入长度,不会出现「字符数够但 Token 超了」的问题,适合生产环境。
- 适用场景:对接 OpenAI 系列模型(GPT-3.5/4、text-embedding-3 等)。
2. 写法二:基于字符计数(简单直观)
python
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", " "], # 分割符优先级:段落 → 换行 → 空格
chunk_size=100, # 每块最大 100 字符
chunk_overlap=0, # 块之间无重叠
length_function=len, # 长度计算:按字符数
is_separator_regex=False, # 分隔符不是正则表达式
)- 计数方式 :用
len()按 字符数 计算块大小,逻辑简单、易理解。 - 优势 :开箱即用,不需要额外依赖
tiktoken,适合调试 / 简单场景。 - 局限:字符数和 Token 数不完全等价,可能和模型上下文窗口有偏差。
3. 共同点
两种写法的拆分逻辑完全一致,都是递归尝试按分隔符切割:
- 先按
\n\n(段落)切,若块大小 ≤ 限制 → 保留。 - 若仍超长 → 按
\n(换行)切。 - 若仍超长 → 按空格切。
- 最后才按单个字符切。
- 目的:最大程度保留句子 / 段落的完整性,避免语义断裂。
4. 参数对比
| 参数 | Token 版 | 字符版 |
|---|---|---|
chunk_size |
单位:Token | 单位:字符 |
chunk_overlap |
单位:Token | 单位:字符 |
length_function |
内置 tiktoken 计数 |
显式指定 len |
| 依赖 | 需要 tiktoken 库 |
无额外依赖 |
| 精度 | 高(完全对齐模型) | 低(字符 ≠ Token) |
总结
- 字符版:简单直观,适合入门 / 调试。
- Token 版:精准适配模型,是生产环境的首选。
- 两者核心都是递归按语义边界拆分,只是「长度计算方式」不同。
文本向量
嵌入模型
嵌入(Embedding)的核心思想是将人类世界的符号(如单词、句子、产品、用户、图片)转换为计算机能够理解的数值形式(即向量,本质上是一个数字列表),并且要求这种转换能够保留原始符号的语义和关系。
- 嵌入模型 :属于表示型模型,目标不是生成文本,而是为输入的文本创建一个最佳的、富含语义的数值表示(向量)。
- 典型代表:OpenAI 的
text-embedding-3-large、Google 的gemini-embedding-001、阿里的Qwen3-Embedding-8B等。 - 与生成式模型的区别:大语言模型(生成式)以 "创造新文本" 为目标,内部会用嵌入理解输入;而嵌入模型专注于 "生成语义向量",本身不生成新内容。
简单定义:
python
from langchain_openai import OpenAIEmbeddings
# 定义嵌入模型
embeddings = OpenAIEmbeddings(
model="text-embedding-3-large", # 指定嵌入模型版本
)调用演示:
python
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import CharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
# 1. 加载 Markdown(single 模式 = 1 个大 Document)
loader = UnstructuredMarkdownLoader("test.md")
data = loader.load()
# 2. 按 Token 拆分文档
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=400,
chunk_overlap=50,
)
docs = text_splitter.split_documents(data)
# 3. 初始化嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 4. 把文档转成向量
texts = [doc.page_content for doc in docs]
docs_vector = embeddings.embed_documents(texts)
# 5. 查看结果
print(f"文档数量:{len(docs)},向量数量:{len(docs_vector)}")
print(f"第一个文档向量维度:{len(docs_vector[0])}")
print(f"第一个文档向量前五个值:{docs_vector[0][:5]}")1. 流程总结
Markdown 文件 → 加载成大文档 → 切成小块 → 转成语义向量
2. 每步作用
- 加载 :把整个 MD 文件读成 1 个
Document。 - 拆分 :按
cl100k_baseToken 切成 400 Token 左右的小块,保证语义完整。 - 嵌入 :调用 OpenAI 模型,把每块文本变成高维向量(比如 3072 维),计算机能通过向量计算相似度。
- 输出:验证「文档数 = 向量数」,并查看向量维度和内容。
3. 目的
为后续向量数据库入库 和检索做准备:向量才能让计算机知道「哪段文本和用户问题最像」。
向量存储
在大模型应用爆发的今天,RAG(检索增强生成) 已经成为解决「知识陈旧、幻觉」问题的核心方案。而向量存储(Vector Store),正是 RAG 流程中承上启下的关键组件 ------ 它让计算机能像人一样「理解语义」,实现高效的相似性检索。
概念
向量存储是什么?
传统数据库(如 MySQL)擅长精确匹配查询(比如「找名字叫张三的用户」),但无法回答「找和这段文本语义最像的内容」这类问题。
向量存储的核心使命,就是解决这个难题:
专门用于高效存储、管理和检索高维向量数据 ,实现基于内容的相似性搜索(Similarity Search)。
简单来说:
- 文本 / 图片 / 音频 → 嵌入模型 → 高维向量(比如 1536/3072 维的数字列表)
- 向量存储 → 把这些向量管起来,让你能快速找到「和查询向量最像」的那批数据
为什么它能搜得快?
面对百万甚至上亿级别的向量数据,暴力遍历对比显然不现实。向量数据库靠两大核心技术实现了高效检索:
1. 专门的索引:近似最近邻(ANN)搜索
这是向量数据库的「灵魂」。它不会遍历所有数据,而是预先构建特殊索引,把「全库搜索」缩小到「几个最可能的候选集」:
- 核心思想:牺牲一点点精度,换取极致速度。不保证找到绝对最相似的向量,但能以极高概率找到非常相似的向量。
- 类比:就像在图书馆找书,你不会从 A 到 Z 遍历所有书架,而是先按分类(文学 / 历史 / 科技)锁定大概区域,再在这个区域里仔细找,速度快得多。
- 常见索引技术 :
- 基于聚类:IVF(倒排文件)、K-Means
- 基于图结构:HNSW(分层导航小世界,工业界最常用)
2. 硬件加速:SIMD 与并行计算
向量数据库充分利用 CPU 的 SIMD(单指令多数据流) 指令集和 GPU 并行计算能力:
- 传统 SISD 指令:一条指令只能处理一组数据
- SIMD 指令:一条指令能同时处理多组数据,让大规模向量计算速度极快
这让高维向量之间的相似度计算(如余弦相似度)能在毫秒级完成。
不止是存储:完整的数据管理能力
现代向量数据库早已不是「只存向量」的简单工具,它提供了完整的企业级数据管理功能:
- CRUD 操作:支持增删改查,可动态更新向量数据,适配业务迭代。
- 元数据过滤:除了向量本身,还能管理文档元数据(创建时间、作者、类别等)。比如先过滤「2024 年以后的科技类文档」,再在这个子集里做相似性搜索,大幅提升准确性和效率。
- 可扩展性与持久化:支持分布式部署,轻松处理海量数据;同时保证数据持久化,不会像纯内存方案那样断电丢失。
- 便捷集成:提供 gRPC、RESTful 等友好 API,能和 LangChain、LlamaIndex 等大模型框架无缝集成,开发者无需关心底层细节。
向量存储在 RAG 中的位置
从 RAG 全流程看,向量存储是「离线处理」和「在线检索」的桥梁:
离线数据处理
- 文档加载:读取 PDF/Markdown/ 数据库等原始数据 → 生成 Document
- 文档拆分:把长文档切成适合模型的小块(Chunk)
- 向量入库:小块文本 → 嵌入模型 → 向量 → 存入向量存储
在线检索
- 问题向量化:用户问题 → 嵌入模型 → 查询向量
- 相似性搜索:查询向量 → 向量存储 → 找到最相似的文档小块
- 生成答案:相似文档 + 用户问题 → 大模型 → 最终回答
常见向量数据库选型
目前主流的向量数据库有很多,适配不同场景:
- 轻量开源:Chroma(内存级,适合入门 / 原型)、FAISS(Facebook 开源,高性能)
- 云原生 / 企业级:Pinecone、Weaviate、Qdrant、Milvus(支持分布式、高可用、元数据过滤)
- 多模态支持:Milvus、Weaviate 等,可同时处理文本、图片、音频向量
LangChain 已经和这些库深度集成,你只需要几行代码就能完成向量存储的接入,无需手动处理向量生成、存储和比较的复杂性。
总结
向量存储是大模型时代的「语义搜索引擎」:
- 它让计算机能理解语义,实现基于内容的相似性检索
- 它靠 ANN 索引 + 硬件加速 解决海量高维向量的高效检索问题
- 它是 RAG 流程的核心,让大模型能「读外部知识库」,从根本上缓解幻觉和知识陈旧问题
如果我们正在开发大模型应用,向量存储一定是你绕不开的关键组件 ------ 它让你的模型不仅能「生成」,更能「准确地生成」。
内存向量存储
CRUD
python
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import CharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma # 以 Chroma 为例
# 1. 加载 Markdown 文档
loader = UnstructuredMarkdownLoader("test.md")
data = loader.load()
# 2. 按 Token 拆分文档
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=400,
chunk_overlap=50,
)
docs = text_splitter.split_documents(data)
# 3. 初始化嵌入模型 + 向量存储
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
vector_store = Chroma(embedding_function=embeddings) # 内存版向量库
# 4. 批量添加文档到向量库(自动生成向量+索引)
ids = vector_store.add_documents(docs)
print(f"共有{len(docs)}个文档,编排了{len(ids)}个索引")
print(f"前三个文档的索引:{ids[:3]}")
# 5. 根据 ID 获取文档
doc_2 = vector_store.get_by_ids(ids[:2])
print(doc_2)
# 6. 删除指定 ID 的文档
vector_store.delete(ids=ids[:2])
# 7. 根据 ID 获取文档
doc_3 = vector_store.get_by_ids(ids[:3])
print(doc_3)检索
python
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
# 1. 加载 Markdown 文档
loader = UnstructuredMarkdownLoader("test.md")
data = loader.load()
# 2. 按 Token 切分文档
text_splitter = RecursiveCharacterTextSplitter(
encoding_name="cl100k_base",
chunk_size=400,
chunk_overlap=50
)
split_docs = text_splitter.split_documents(data)
# 3. 初始化向量库(以 Chroma 为例)
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
vector_store = Chroma.from_documents(documents=split_docs, embedding=embeddings)
# ------------------- 基础相似检索 -------------------
print("=== 基础相似检索结果 ===")
search_docs = vector_store.similarity_search(query="项目介绍", k=2)
for doc in search_docs:
print("*" * 30)
print(doc)
# ------------------- 元数据过滤检索 -------------------
# 定义过滤函数:匹配指定来源文件
def _filter_function(doc: Document) -> bool:
return doc.metadata.get("source") == "test.md"
print("\n=== 元数据过滤检索结果 ===")
search_docs = vector_store.similarity_search(
query="项目介绍",
k=2,
filter=_filter_function
)
for doc in search_docs:
print("*" * 30)
print(doc)执行流程是:
- 先去向量数据库 查出 相似度最高的 k 条数据(比如 k=2)
- 回到本地 Python 内存 把这 2 条数据一条一条拿出来遍历
- 挨个比对你的条件
source == "test.md"? - 符合就留下,不符合就丢掉
Redis向量存储
python
from langchain_openai import OpenAIEmbeddings
from langchain_redis import RedisVectorStore, RedisConfig
# 嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# Redis 配置
config = RedisConfig(
index_name="qa", # 定义索引名
redis_url="redis://192.168.100.238:6379",
metadata_schema=[
{"name": "category", "type": "tag"}, # 添加索引字段: 分类(标签类型)
{"name": "num", "type": "numeric"} # 添加索引字段: 编号(数值类型)
]
)
# 初始化 Redis 向量存储实例
vector_store = RedisVectorStore(
embeddings=embeddings,
config=config
)
# CRUD、检索(后续操作入口)RedisVectorStore:LangChain 对接 Redis 向量数据库的存储类,负责向量的增删查改。RedisConfig:Redis 向量库的配置类,用于定义索引、连接地址和元数据 schema。
Redis 向量库配置
python
config = RedisConfig(
index_name="qa", # 定义索引名
redis_url="redis://192.168.100.238:6379",
metadata_schema=[
{"name": "category", "type": "tag"}, # 标签类型,用于精确匹配过滤
{"name": "num", "type": "numeric"} # 数值类型,用于范围查询过滤
]
)index_name="qa":Redis 中向量索引的名称,用于区分不同业务的向量数据。redis_url:Redis 服务连接地址(IP + 端口),这里是192.168.100.238:6379。metadata_schema:定义元数据字段的索引类型,用于数据库层面的过滤检索 :category:tag类型 → 适合做标签匹配(如category="技术")。num:numeric类型 → 适合做数值范围查询(如num > 10)。
初始化向量存储实例
python
vector_store = RedisVectorStore(
embeddings=embeddings,
config=config
)- 作用:将嵌入模型和 Redis 配置绑定,生成可直接操作的向量存储对象。
- 后续可通过
vector_store执行:- 添加文档:
vector_store.add_documents(docs) - 相似检索:
vector_store.similarity_search(query, k=3, filter={"category": "技术"}) - 删除数据:
vector_store.delete(ids=[...])
- 添加文档:
使用提示
-
元数据过滤(数据库层面) 你定义的
metadata_schema支持在检索时直接传过滤条件,例如:vector_store.similarity_search( query="什么是向量数据库", k=2, filter={"category": "技术", "num": {"$gt": 5}} )这会先在 Redis 中过滤符合条件的文档,再做语义相似度计算,效率远高于本地过滤。
-
业务场景 这段代码是典型的 RAG(检索增强生成) 基础设施,适合做:
- 知识库问答
- 文档语义检索
- 带分类 / 编号筛选的精准搜索
CRUD
python
from langchain_openai import OpenAIEmbeddings
from langchain_redis import RedisVectorStore, RedisConfig
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import CharacterTextSplitter
# ---------------------- 1. 嵌入模型 & Redis 配置 ----------------------
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
config = RedisConfig(
index_name="qa",
redis_url="redis://ip+port",
metadata_schema=[
{"name": "category", "type": "tag"},
{"name": "num", "type": "numeric"}
]
)
# 初始化 Redis 向量存储
vector_store = RedisVectorStore(
embeddings=embeddings,
config=config,
)
# ---------------------- 2. 加载文档 & 分块 ----------------------
loader = UnstructuredMarkdownLoader("路径")
data = loader.load()
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=400,
chunk_overlap=50,
)
docs = text_splitter.split_documents(data)
# 标注元数据
for i, doc in enumerate(docs, start=1):
doc.metadata["category"] = "QA"
doc.metadata["num"] = i
# ---------------------- 3. 添加文档到 Redis ----------------------
ids = vector_store.add_documents(documents=docs)
print(f"编制了{len(ids)}个索引")
print(f"前三个索引是: {ids[:3]}")
# ---------------------- 4. CRUD 操作 ----------------------
# 查:根据 ID 获取
print(vector_store.get_by_ids(["01K85F9HDK4H98QK221YA2ZQ7E"]))
# 删:根据 ID 删除
vector_store.delete(["01K85F9HDK4H98QK221YA2ZQ7E"])
print(vector_store.get_by_ids(["01K85F9HDK4H98QK221YA2ZQ7E"]))
# 底层删除(Redis 原生 drop keys)
vector_store.index.drop_keys(["qa:01K85F9HDK4H98QK221YA2ZQ7E"])
# 全量删除(清空索引)
vector_store.index.delete(drop=True)流程讲解
-
环境初始化
- 用
OpenAIEmbeddings生成文本向量 - 用
RedisConfig配置 Redis 连接和元数据索引结构 - 初始化
RedisVectorStore实例
- 用
-
文档处理
UnstructuredMarkdownLoader读取本地 Markdown 文件CharacterTextSplitter按 token 切分长文档(chunk_size=400,重叠 50 token)- 给每个文档块添加
category和num元数据,方便检索过滤
-
数据入库
add_documents将文档向量化后存入 Redis,生成唯一索引 ID
-
CRUD 操作
- 查 :
get_by_ids按 ID 读取文档 - 删 :
delete按 ID 删除;index.drop_keys底层删除;index.delete(drop=True)清空全量数据
- 查 :
关键说明
- 这是标准 Redis 向量存储 方案,使用
langchain-redis库对接 Redis - 元数据
category(标签类型)和num(数值类型)会在 Redis 中建立索引,支持按分类 / 编号过滤检索 - 日志里的
chunk size > 400是正常提示:为保证段落完整,分词器会自动超出设定大小
检索
python
from langchain_redis import RedisVectorStore, RedisConfig, Tag, Num # 注意导入过滤类
from langchain_openai import OpenAIEmbeddings
# ---------------------- 1. 基础配置(复用之前的初始化) ----------------------
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
config = RedisConfig(
index_name="qa",
redis_url="redis://ip+port",
metadata_schema=[
{"name": "category", "type": "tag"},
{"name": "num", "type": "numeric"}
]
)
vector_store = RedisVectorStore(embeddings=embeddings, config=config)
# ---------------------- 2. 基础相似度检索 ----------------------
# 普通相似度检索(不带分数)
search_docs = vector_store.similarity_search(
query="项目介绍",
k=2 # 返回最相似的2条结果
)
# 带相似度分数的检索(分数越低,相似度越高)
search_docs_results = vector_store.similarity_search_with_score(
query="项目介绍",
k=2
)
# 遍历并打印带分数的结果
for doc, score in search_docs_results:
print("*" * 30)
print(f"文档分数: {score}")
print(f"文档内容: {doc.page_content}")
print(f"文档元数据: {doc.metadata}")
# ---------------------- 3. 带元数据过滤的检索 ----------------------
# 定义过滤条件:category == "QA" 且 num > 6
filter_condition = (Tag("category") == "QA") & (Num("num") > 6)
# 带过滤的相似度检索(带分数)
search_docs_results = vector_store.similarity_search_with_score(
query="项目介绍",
k=2,
filter=filter_condition
)
# 遍历并打印结果
for doc, score in search_docs_results:
print("*" * 30)
print(f"文档分数: {score}")
print(f"文档内容: {doc.page_content}")
print(f"文档元数据: {doc.metadata}")
# ---------------------- 4. MMR 多样性检索 ----------------------
# MMR(最大边际相关性)检索:先召回10条,再重排输出2条,保证结果多样性
search_docs = vector_store.max_marginal_relevance_search(
query="项目介绍",
k=2, # 最终返回2条
filter=filter_condition,
fetch_k=10 # 先从库中召回10条候选,再做多样性重排
)
# 遍历并打印MMR结果
for doc in search_docs:
print("*" * 30)
print(f"文档内容: {doc.page_content}")
print(f"文档元数据: {doc.metadata}")流程讲解
1. 基础检索
similarity_search:直接返回最相似的文档,不带分数。similarity_search_with_score:返回文档 + 相似度分数,分数越低表示和查询越相似。
2. 元数据过滤检索
- 用
Tag()处理标签类型字段(如category),用Num()处理数值类型字段(如num)。 - 过滤条件支持
&(且)、|(或)、~(非)逻辑组合,实现精准筛选。 - 示例:
(Tag("category") == "QA") & (Num("num") > 6)只检索分类为 QA 且编号大于 6 的文档。
3. MMR 多样性检索
max_marginal_relevance_search:在保证相关性的同时,最大化结果多样性,避免返回内容高度相似的文档。fetch_k:先从向量库中召回fetch_k条候选文档,再从中选出k条最具多样性的结果。- 适合需要结果覆盖面更广的场景(如问答系统、推荐系统)。
注意点
- 过滤类导入 :必须导入
Tag和Num,否则无法构建过滤条件。 - 元数据类型匹配 :过滤字段类型必须和
RedisConfig中定义的metadata_schema一致(tag/numeric)。 - 分数含义 :Redis 向量检索的分数是距离值,值越小表示向量越接近,相似度越高。
- MMR 适用场景:当你希望检索结果既相关又不重复时(比如避免多条内容讲同一个知识点),使用 MMR 更合适。
Pinecone向量存储
python
from langchain_pinecone import PineconeVectorStore
from pinecone import Pinecone, ServerlessSpec
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import CharacterTextSplitter
# ---------------------- 1. Pinecone 初始化 & 创建索引 ----------------------
pc = Pinecone() # 自动读取环境变量 PINECONE_API_KEY
index_name = "standard-dense-py"
# 如果索引不存在则创建
if not pc.has_index(index_name):
pc.create_index(
name=index_name,
vector_type="dense",
dimension=1536, # 与 text-embedding-3-large 向量维度一致
metric="cosine",
spec=ServerlessSpec(
cloud="aws",
region="us-east-1"
),
deletion_protection="disabled",
tags={
"environment": "development"
}
)
# 获取已存在的索引
index = pc.Index(index_name)
# ---------------------- 2. 嵌入模型 & 向量库初始化 ----------------------
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
vector_store = PineconeVectorStore(
embedding=embeddings,
index=index
)
# ---------------------- 3. 文档加载 & 分块 ----------------------
loader = UnstructuredMarkdownLoader("路径")
data = loader.load()
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=400,
chunk_overlap=50,
)
docs = text_splitter.split_documents(data)
# 标注元数据
for i, doc in enumerate(docs, start=1):
doc.metadata["category"] = "QA"
doc.metadata["num"] = i
# ---------------------- 4. 数据入库 ----------------------
ids = vector_store.add_documents(documents=docs)
print(f"编制了{len(ids)}个索引")
print(f"前三个索引是: {ids[:3]}")
# ---------------------- 5. CRUD 操作 ----------------------
# 全量删除
vector_store.delete(delete_all=True)
# 删除指定 ID 的文档
delete_ids = [] # 填入要删除的 ID 列表
vector_store.delete(ids=delete_ids)
# ---------------------- 6. 相似度检索 ----------------------
search_docs = vector_store.similarity_search(query="项目介绍", k=2)
# 遍历并打印检索结果
for doc in search_docs:
print("*" * 30)
print(f"文档内容: {doc.page_content}")
print(f"文档元数据: {doc.metadata}")流程讲解
1. Pinecone 环境初始化
Pinecone():创建客户端,自动读取PINECONE_API_KEY环境变量。create_index():创建无服务器向量索引,指定向量维度(需与嵌入模型匹配)、距离度量(cosine)和云服务商配置。Index(index_name):获取已创建的索引实例,用于后续数据操作。
2. 文档处理与入库
- 文档加载 :
UnstructuredMarkdownLoader读取本地 Markdown 文件。 - 文本分块 :
CharacterTextSplitter按 token 切分长文档,保证段落完整性。 - 元数据标注 :给每个文档块添加
category(分类)和num(编号),方便后续检索过滤。 - 数据入库 :
add_documents将文档向量化后存入 Pinecone,生成唯一索引 ID。
3. CRUD 操作
- 新增 :
add_documents→ 向向量库添加文档。 - 删除 :
delete(delete_all=True)→ 清空向量库所有数据。delete(ids=delete_ids)→ 删除指定 ID 的文档。
- 查询 :
similarity_search→ 按语义相似度检索文档,返回最相似的k条结果。
注意点
- 维度匹配 :
dimension=1536必须与text-embedding-3-large模型的输出维度一致,否则会报错。 - 环境变量 :需提前设置
PINECONE_API_KEY和PINECONE_ENVIRONMENT环境变量。 - 无服务器架构 :
ServerlessSpec是 Pinecone 的无服务器方案,按需计费,适合开发测试。 - 检索特性:Pinecone 原生支持高并发向量检索,适合生产环境部署。
检索器
在 RAG(检索增强生成)应用中,** 检索器(Retriever)** 的核心作用是:接收用户查询文本,从向量数据库中召回最相关的文档片段,为后续大模型生成回答提供上下文支撑。
LangChain 提供了两种主流的检索器实现方式,本文将结合 Redis 向量库的实践代码,做极简对比说明。
两种实现
1. 官方封装:as_retriever() 开箱即用
python
# 官方标准写法,LangChain 向量库通用接口
retriever = vector_store.as_retriever(search_kwargs={"k": 2})- 核心逻辑 :LangChain 为所有向量库(Redis、Chroma、FAISS 等)统一封装了
as_retriever()方法,直接生成符合Runnable规范的检索器。 - 调用方式 :和所有 LangChain 组件一致,使用
retriever.invoke("你的查询词")触发检索,返回List[Document]。 - 适用场景:简单检索需求,无需自定义逻辑,追求快速开发。
2. 自定义实现:@chain 装饰器手动包装
python
from langchain_core.runnables import chain
from langchain_core.documents import Document
from typing import List
@chain
def retriever(query: str) -> List[Document]:
return vector_store.similarity_search(query=query, k=2)- 核心逻辑 :用
@chain装饰器,把普通的向量库相似度搜索方法,包装成 LangChain 可识别的Runnable组件。 - 调用方式 :同样使用
retriever.invoke("你的查询词"),和官方检索器接口完全兼容。 - 适用场景:需要在检索前后加入自定义逻辑,比如元数据过滤、多数据源合并、结果改写等。
区别
| 维度 | as_retriever() |
@chain 自定义实现 |
|---|---|---|
| 代码量 | 一行代码,开箱即用 | 需定义函数,多写几行代码 |
| 灵活性 | 固定封装,仅支持基础检索参数(k、过滤条件等) | 可在函数内任意扩展逻辑 |
| 兼容性 | 所有向量库通用,符合 LangChain 规范 | 同样兼容 LangChain 链,可无缝替换官方实现 |
| 适用场景 | 快速开发、无自定义需求的基础 RAG | 复杂检索逻辑、多步骤处理的定制化场景 |
两种方式的底层执行流程完全一致:
- 调用
retriever.invoke("项目介绍"),传入用户查询; - 检索器接收查询,调用向量库的相似度搜索接口;
- 向量库将查询文本转为向量,匹配库中余弦相似度最高的前 2 条文档;
- 返回
List[Document]对象,循环打印doc.page_content即可获取检索结果。
总结
- 追求简单高效,直接用
vector_store.as_retriever(); - 需要定制化逻辑,用
@chain包装自定义函数,实现和官方检索器完全一致的调用体验。
两种方式在 LangChain 链中可以无缝替换,根据你的业务需求选择即可。