一、基础 Agent 的局限性与高级特性价值
1.1 基础 ReAct Agent 的三大致命缺陷
之前基础的 ReAct Agent,但它距离生产环境使用还有很大差距,存在以下无法忽视的问题:
- 无法人工干预:一旦启动就会自动执行到底,无法在关键步骤暂停等待人类确认或修正
- 代码复用性差:所有逻辑都在一个文件中,复杂 Agent 会变得难以维护和扩展
- 执行效率低:只能串行调用工具,无法同时执行多个独立的工具调用
- 无法回溯历史:只能看到最终结果,无法查看和回滚到之前的执行状态
- 错误处理能力弱:工具调用失败后没有自动重试和降级机制
- 缺乏安全控制:无法限制 Agent 的操作范围,存在安全风险
1.2 LangGraph 高级特性全景
LangGraph 提供了一整套高级特性,完美解决了基础 Agent 的所有问题:
| 高级特性 | 解决的问题 | 核心价值 |
|---|---|---|
| Checkpoint 高级操作 | 无法回溯历史、无法恢复状态 | 状态持久化、历史回溯、断点续跑、多会话管理 |
| 人类介入(Human-in-the-loop) | 无法人工干预 | 关键步骤审核、错误修正、信息补充、安全控制 |
| 子图(Subgraph) | 代码复用性差、难以维护 | 模块化设计、代码复用、分而治之、团队协作 |
| 并行工具调用 | 执行效率低 | 同时执行多个独立工具,大幅缩短任务完成时间 |
| 状态回溯与回滚 | 无法撤销错误操作 | 回滚到任意历史状态、修正错误、重新执行 |
| 高级错误处理 | 错误处理能力弱 | 自动重试、降级处理、异常捕获、优雅失败 |
1.3 工业级 Agent 的技术要求
一个真正能在生产环境使用的 Agent 必须满足以下要求:
- 可观测性:能追踪每一步执行过程,查看所有输入输出
- 可控制性:能在任意步骤暂停、继续、终止执行
- 可维护性:代码模块化、结构清晰、易于修改和扩展
- 可靠性:完善的错误处理和重试机制,99.9% 以上的可用性
- 安全性:严格的权限控制和操作限制,防止滥用和安全事故
- 交互性:支持与人类的自然交互,能在需要时请求人类帮助
1.4 今日学习路线图
Checkpoint高级操作 → 人类介入机制 → 子图模块化 → 并行工具调用 → 状态回溯与回滚 → 错误处理与重试 → 性能优化 → 项目整合
二、LangGraph 高级 API 详解
2.1 Checkpoint 深度解析:工业级状态管理的基石
2.1.1 Checkpoint 底层原理
Checkpoint 是 LangGraph 最核心的创新之一,它的本质是智能体执行状态的快照。每次节点执行完成后,LangGraph 会自动将当前状态保存到 Checkpoint 存储中。
Checkpoint 核心组成:
- Channel Values:状态的当前值(如 messages、iteration_count)
- Versions:每个状态字段的版本号,用于冲突检测
- Checkpoint ID:每个快照的唯一标识符
- Thread ID:会话的唯一标识符,用于隔离不同用户的会话
增量 Checkpoint 机制:LangGraph 1.2 + 采用增量 Checkpoint,只保存变化的状态字段,而不是完整状态,大幅减少了存储占用和 I/O 开销。
2.1.2 生产级 Checkpoint 存储后端对比
SQLite 只适合开发和测试环境,生产环境必须使用支持高并发和持久化的存储后端:
| 存储后端 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| SQLite | 开发测试、单用户 | 无需部署、零配置 | 不支持高并发、不支持分布式 |
| PostgreSQL | 生产环境、企业级 | 支持高并发、ACID 事务、分布式 | 需要部署和维护 |
| Redis | 高并发、低延迟 | 速度极快、支持集群 | 数据持久化能力弱 |
| DynamoDB | 云原生、无服务器 | 完全托管、无限扩展 | 成本较高、云厂商锁定 |
生产级推荐:PostgreSQL 15+,支持 JSONB 类型,性能和功能都能满足绝大多数企业需求。
2.1.3 实战:PostgreSQL Checkpoint 配置与高级操作
第一步:安装依赖
bash
pip install langgraph-checkpoint-postgres psycopg2-binary第二步:配置 PostgreSQL Checkpoint
python
# core/checkpoint.py
from langgraph.checkpoint.postgres import PostgresSaver
from config.settings import settings
def get_postgres_checkpointer():
"""获取PostgreSQL Checkpoint存储(生产级)"""
connection_string = f"postgresql://{settings.db_user}:{settings.db_password}@{settings.db_host}:{settings.db_port}/{settings.db_name}"
checkpointer = PostgresSaver.from_conn_string(connection_string)
# 初始化数据库表(只需要运行一次)
checkpointer.setup()
return checkpointer
# 全局单例
postgres_checkpointer = get_postgres_checkpointer()第三步:Checkpoint 高级操作实战
python
from core.checkpoint import postgres_checkpointer
from langchain_core.messages import HumanMessage
# 1. 列出所有活跃会话
def list_all_sessions():
"""列出所有用户会话"""
sessions = []
for thread in postgres_checkpointer.list_threads():
sessions.append({
"thread_id": thread["thread_id"],
"user_id": thread["metadata"].get("user_id", "unknown"),
"created_at": thread["created_at"],
"updated_at": thread["updated_at"],
"last_message": thread["channel_values"]["messages"][-1].content[:100] if thread["channel_values"]["messages"] else ""
})
return sessions
# 2. 获取指定会话的所有Checkpoint历史
def get_session_checkpoints(thread_id: str):
"""获取会话的所有状态快照"""
checkpoints = []
for checkpoint in postgres_checkpointer.list(thread_id):
checkpoints.append({
"checkpoint_id": checkpoint["id"],
"created_at": checkpoint["created_at"],
"step": checkpoint["step"],
"messages_count": len(checkpoint["channel_values"]["messages"]),
"iteration_count": checkpoint["channel_values"]["iteration_count"]
})
return checkpoints
# 3. 断点续跑实战:程序崩溃后恢复执行
def resume_session(thread_id: str):
"""从上次中断的地方恢复会话执行"""
config = {"configurable": {"thread_id": thread_id}}
# 获取当前状态
state = react_agent.get_state(config)
if state.next:
# 有未完成的节点,继续执行
print(f"恢复会话{thread_id},继续执行节点:{state.next}")
result = react_agent.invoke(None, config=config)
return result["messages"][-1].content
else:
# 会话已完成
return "会话已完成,无需恢复"
# 4. 会话归档与清理
def archive_old_sessions(days: int = 30):
"""归档30天未活动的会话"""
import datetime
cutoff = datetime.datetime.now() - datetime.timedelta(days=days)
archived_count = 0
for thread in postgres_checkpointer.list_threads():
if thread["updated_at"] < cutoff:
postgres_checkpointer.delete_thread(thread["thread_id"])
archived_count += 1
print(f"已归档{archived_count}个过期会话")
return archived_count2.1.4 Checkpoint 最佳实践与避坑指南
- 永远不要手动修改 Checkpoint 数据库:直接修改数据库可能导致状态不一致,应该使用 LangGraph 提供的 API
- 设置合理的会话过期时间:定期清理过期会话,避免数据库无限增长
- 不要在状态中存储大量数据:状态应该只存储必要的元数据和上下文,大量数据应该存储在外部数据库
- 使用事务保证原子性:PostgreSQL Checkpoint 支持事务,确保状态更新的原子性
- 监控 Checkpoint 性能:监控数据库的读写延迟和连接数,及时扩容
2.2 人类介入(Human-in-the-loop):工业级安全的核心
2.2.1 人类介入底层原理
人类介入的本质是在图的执行流程中插入中断点,当执行到中断点时,LangGraph 会暂停执行并保存当前状态,等待人类输入或确认后再继续执行。
人类介入的三种核心模式:
- 审核模式:Agent 执行高风险操作前,等待人类批准
- 信息补充模式:Agent 缺少必要信息时,向人类询问
- 修正模式:人类发现 Agent 的错误后,修正状态并重新执行
2.2.2 工业级人类介入完整流程
一个完整的工业级人类介入流程包括以下步骤:
Agent执行到中断点 → 保存状态 → 发送通知给人类 → 人类审核/补充/修正 → 更新状态 → 继续执行 → 记录审核日志
2.2.3 实战:三级审核流程实现
我们将实现一个支持工具调用审核→报告生成审核→最终发布审核的三级审核流程,这是企业中最常见的审批模式。
第一步:定义审核状态
python
from enum import Enum
class ApprovalStatus(str, Enum):
PENDING = "pending"
APPROVED = "approved"
REJECTED = "rejected"
class AgentState(BaseModel):
"""增强版Agent状态,支持审核流程"""
messages: Annotated[List[BaseMessage], operator.add] = Field(default_factory=list)
iteration_count: int = Field(default=0)
max_iterations: int = Field(default=5)
user_id: str = Field(default="default_user")
# 审核相关字段
approval_status: ApprovalStatus = Field(default=ApprovalStatus.PENDING)
approval_level: int = Field(default=0) # 0: 无需审核, 1: 一级审核, 2: 二级审核, 3: 三级审核
approver: str = Field(default="")
approval_comment: str = Field(default="")第二步:定义多级中断点
python
def build_approval_agent() -> StateGraph:
"""构建支持三级审核的Agent"""
builder = StateGraph(AgentState)
# 添加节点
builder.add_node("agent", agent_think)
builder.add_node("tools", ToolNode(PRODUCTION_TOOLS))
builder.add_node("generate_report", generate_report_node)
builder.add_node("publish_report", publish_report_node)
# 添加边
builder.add_edge("tools", "agent")
builder.add_edge("generate_report", "agent")
builder.add_edge("publish_report", END)
# 路由函数
def router(state: AgentState) -> str:
last_message = state.messages[-1]
if last_message.tool_calls:
# 工具调用需要一级审核
return "tools"
elif "生成报告" in last_message.content:
# 报告生成需要二级审核
return "generate_report"
elif "发布报告" in last_message.content:
# 报告发布需要三级审核
return "publish_report"
else:
return END
builder.add_conditional_edges("agent", router)
builder.set_entry_point("agent")
# 配置多级中断点
graph = builder.compile(
checkpointer=postgres_checkpointer,
interrupt_before=["tools", "generate_report", "publish_report"]
)
logger.info("✅ 三级审核Agent构建完成")
return graph
# 全局单例
approval_agent = build_approval_agent()第三步:审核流程 API 实现
python
# core/approval_service.py
from core.react_agent import approval_agent, ApprovalStatus
from langchain_core.messages import HumanMessage
from utils.logger import logger
class ApprovalService:
"""审核服务"""
@staticmethod
def submit_task(question: str, user_id: str) -> dict:
"""提交任务,进入审核流程"""
config = {"configurable": {"thread_id": f"task_{user_id}_{int(time.time())}"}}
result = approval_agent.invoke(
{"messages": [HumanMessage(content=question)], "user_id": user_id},
config=config
)
state = approval_agent.get_state(config)
if state.next:
return {
"task_id": config["configurable"]["thread_id"],
"status": "pending_approval",
"next_step": state.next[0],
"message": f"任务已提交,等待{state.next[0]}审核"
}
else:
return {
"task_id": config["configurable"]["thread_id"],
"status": "completed",
"answer": result["messages"][-1].content
}
@staticmethod
def approve_task(task_id: str, approver: str, comment: str = "") -> dict:
"""批准任务,继续执行"""
config = {"configurable": {"thread_id": task_id}}
# 更新审核状态
approval_agent.update_state(
config,
{
"approval_status": ApprovalStatus.APPROVED,
"approver": approver,
"approval_comment": comment
}
)
# 继续执行
result = approval_agent.invoke(None, config=config)
state = approval_agent.get_state(config)
if state.next:
return {
"task_id": task_id,
"status": "pending_approval",
"next_step": state.next[0],
"message": f"一级审核通过,等待{state.next[0]}审核"
}
else:
return {
"task_id": task_id,
"status": "completed",
"answer": result["messages"][-1].content
}
@staticmethod
def reject_task(task_id: str, approver: str, reason: str) -> dict:
"""拒绝任务,终止执行"""
config = {"configurable": {"thread_id": task_id}}
# 更新审核状态
approval_agent.update_state(
config,
{
"approval_status": ApprovalStatus.REJECTED,
"approver": approver,
"approval_comment": reason,
"messages": [HumanMessage(content=f"任务被拒绝,原因:{reason}")]
}
)
logger.info(f"任务{task_id}被{approver}拒绝,原因:{reason}")
return {
"task_id": task_id,
"status": "rejected",
"reason": reason
}2.2.4 人类介入最佳实践与避坑指南
- 只在必要时使用人类介入:过多的人类介入会降低效率,应该只在高风险操作和信息不足时使用
- 提供清晰的上下文:给审核人员提供足够的上下文信息,包括 Agent 的思考过程和工具调用详情
- 设置审核超时时间:如果审核人员在规定时间内没有响应,应该自动拒绝或升级审核
- 记录完整的审核日志:记录所有审核操作,包括审核人、审核时间、审核意见,便于审计和追溯
- 支持批量审核:对于大量的低风险审核任务,提供批量审核功能,提高效率
2.3 子图(Subgraph):复杂 Agent 的模块化解决方案
2.3.1 子图底层原理
子图的本质是一个完整的 StateGraph,可以作为节点嵌入到另一个 StateGraph 中。子图拥有自己的状态、节点和边,但可以与主图共享状态和 Checkpoint。
子图的核心优势:
- 模块化设计:将复杂系统拆分为多个独立的模块,每个模块负责一个单一功能
- 代码复用:通用子图可以在多个项目中复用,避免重复开发
- 团队协作:不同的团队可以并行开发不同的子图,提高开发效率
- 易于测试:每个子图可以单独测试和调试,降低测试难度
2.3.2 子图高级用法:输入输出映射与嵌套子图
LangGraph 支持子图的输入输出映射,可以将主图的状态字段映射到子图的状态字段,反之亦然。这使得子图可以完全独立于主图设计,提高了复用性。
实战:通用工具执行子图与嵌套子图
python
# core/subgraphs/tool_subgraph.py
from langgraph.graph import StateGraph
from langgraph.prebuilt import ToolNode
from core.tools import PRODUCTION_TOOLS
from core.react_agent import AgentState
from utils.logger import logger
# 定义工具子图的状态(可以与主图不同)
class ToolSubgraphState(BaseModel):
tool_calls: list = Field(default_factory=list)
tool_results: list = Field(default_factory=list)
def build_tool_subgraph() -> StateGraph:
"""构建通用工具执行子图(可复用)"""
def execute_tools(state: ToolSubgraphState) -> dict:
"""执行工具调用"""
tool_node = ToolNode(PRODUCTION_TOOLS)
results = tool_node.invoke({"tool_calls": state.tool_calls})
return {"tool_results": results["messages"]}
builder = StateGraph(ToolSubgraphState)
builder.add_node("execute_tools", execute_tools)
builder.set_entry_point("execute_tools")
builder.add_edge("execute_tools", END)
return builder.compile()
# core/subgraphs/report_subgraph.py
from langgraph.graph import StateGraph
from core.react_agent import AgentState
from core.llm_factory import LLMFactory
llm = LLMFactory.get_llm()
def build_report_subgraph() -> StateGraph:
"""构建报告生成子图(嵌套子图示例)"""
def generate_outline(state: AgentState) -> dict:
"""生成报告大纲"""
outline = llm.invoke(f"根据以下信息生成报告大纲:{state.messages[-1].content}")
return {"messages": [outline]}
def generate_content(state: AgentState) -> dict:
"""生成报告内容"""
content = llm.invoke(f"根据以下大纲生成报告内容:{state.messages[-1].content}")
return {"messages": [content]}
builder = StateGraph(AgentState)
builder.add_node("generate_outline", generate_outline)
builder.add_node("generate_content", generate_content)
builder.add_edge("generate_outline", "generate_content")
builder.add_edge("generate_content", END)
builder.set_entry_point("generate_outline")
return builder.compile()
# 主图中使用子图
def build_modular_agent() -> StateGraph:
"""构建模块化Agent"""
builder = StateGraph(AgentState)
# 添加子图作为节点
builder.add_node("agent", agent_think)
builder.add_node("tool_subgraph", build_tool_subgraph())
builder.add_node("report_subgraph", build_report_subgraph())
# 子图输入输出映射
# 将主图的tool_calls映射到子图的tool_calls
# 将子图的tool_results映射到主图的messages
builder.add_edge(
"agent",
"tool_subgraph",
input_map=lambda state: {"tool_calls": state.messages[-1].tool_calls},
output_map=lambda result: {"messages": result["tool_results"]}
)
builder.add_edge("tool_subgraph", "agent")
builder.add_edge("report_subgraph", END)
def router(state: AgentState) -> str:
last_message = state.messages[-1]
if last_message.tool_calls:
return "tool_subgraph"
elif "生成报告" in last_message.content:
return "report_subgraph"
else:
return END
builder.add_conditional_edges("agent", router)
builder.set_entry_point("agent")
graph = builder.compile(checkpointer=postgres_checkpointer)
logger.info("✅ 模块化Agent构建完成")
return graph2.3.3 子图最佳实践与避坑指南
- 单一职责原则:每个子图只负责一个单一的功能,不要让子图变得过于复杂
- 明确的接口定义:子图的输入输出应该清晰明确,使用 Pydantic 模型定义
- 独立测试:每个子图都应该有自己的单元测试,确保在集成到主图之前能够正常工作
- 避免过深的嵌套:子图的嵌套深度不要超过 3 层,否则会增加调试难度
- 版本管理:对子图进行版本管理,当子图发生变化时,能够方便地回滚到旧版本
2.4 并行工具调用:大幅提升 Agent 执行效率
2.4.1 并行工具调用底层原理
LangGraph 1.2 + 原生支持并行工具调用,当 LLM 返回多个工具调用时,ToolNode会自动使用线程池并行执行所有工具调用,然后将结果合并返回。
并行工具调用的前提条件:
- 工具调用之间没有依赖关系
- 工具是线程安全的
- 系统有足够的资源支持并行执行
2.4.2 实战:并行工具调用与依赖处理
第一步:支持并行工具调用的思考节点
python
def agent_think_with_parallel(state: AgentState) -> dict:
"""思考节点,支持并行工具调用"""
logger.info(f"Agent思考中,迭代次数:{state.iteration_count}/{state.max_iterations}")
messages = [system_message] + state.messages
# 明确告诉LLM可以同时调用多个工具
messages.append(SystemMessage(content="""
你可以同时调用多个独立的工具来完成任务。
如果多个工具之间没有依赖关系,请同时调用它们,以提高效率。
工具调用之间用逗号分隔。
"""))
response = llm_with_tools.invoke(messages)
if state.iteration_count >= state.max_iterations:
logger.warning("Agent超过最大迭代次数,强制结束")
return {
"messages": [response],
"iteration_count": state.iteration_count + 1
}
# 记录并行工具调用数量
if response.tool_calls:
logger.info(f"Agent决定并行调用{len(response.tool_calls)}个工具:{[tc['name'] for tc in response.tool_calls]}")
return {
"messages": [response],
"iteration_count": state.iteration_count + 1
}第二步:处理有依赖的工具调用 有些工具调用之间存在依赖关系,必须串行执行。我们可以通过条件边实现依赖处理:
python
def build_agent_with_dependency() -> StateGraph:
"""构建支持依赖工具调用的Agent"""
builder = StateGraph(AgentState)
builder.add_node("agent", agent_think_with_parallel)
builder.add_node("tools", ToolNode(PRODUCTION_TOOLS))
def router(state: AgentState) -> str:
last_message = state.messages[-1]
if not last_message.tool_calls:
return END
# 检查工具调用之间是否有依赖
# 例如:get_user_id必须在get_user_order之前执行
tool_names = [tc["name"] for tc in last_message.tool_calls]
if "get_user_id" in tool_names and "get_user_order" in tool_names:
# 有依赖,先执行get_user_id
return "execute_get_user_id"
else:
# 无依赖,并行执行所有工具
return "tools"
# 单独的节点执行有依赖的工具
def execute_get_user_id(state: AgentState) -> dict:
"""执行get_user_id工具"""
tool_call = next(tc for tc in state.messages[-1].tool_calls if tc["name"] == "get_user_id")
result = TOOL_MAP["get_user_id"].invoke(tool_call["args"])
return {"messages": [ToolMessage(content=result, tool_call_id=tool_call["id"])]}
builder.add_node("execute_get_user_id", execute_get_user_id)
builder.add_edge("tools", "agent")
builder.add_edge("execute_get_user_id", "agent")
builder.add_conditional_edges("agent", router)
builder.set_entry_point("agent")
graph = builder.compile(checkpointer=postgres_checkpointer)
return graph第三步:并行工具调用的错误处理 当并行执行多个工具时,可能会出现部分成功部分失败的情况。我们需要处理这种情况:
python
def execute_tools_with_error_handling(state: AgentState) -> dict:
"""执行工具调用,处理部分失败的情况"""
last_message = state.messages[-1]
tool_results = []
# 使用线程池并行执行工具
from concurrent.futures import ThreadPoolExecutor, as_completed
with ThreadPoolExecutor(max_workers=5) as executor:
futures = {}
for tool_call in last_message.tool_calls:
future = executor.submit(TOOL_MAP[tool_call["name"]].invoke, tool_call["args"])
futures[future] = tool_call
for future in as_completed(futures):
tool_call = futures[future]
try:
result = future.result()
tool_results.append(ToolMessage(
content=result,
tool_call_id=tool_call["id"],
name=tool_call["name"]
))
except Exception as e:
logger.error(f"工具{tool_call['name']}调用失败:{e}")
tool_results.append(ToolMessage(
content=f"工具调用失败:{str(e)},请尝试其他方法",
tool_call_id=tool_call["id"],
name=tool_call["name"]
))
return {"messages": tool_results}2.4.4 并行工具调用最佳实践与避坑指南
- 限制并行度:设置合理的最大并行数(建议不超过 5),避免资源耗尽
- 处理部分失败:不要因为一个工具调用失败而终止整个任务,应该让 Agent 根据失败结果调整策略
- 避免并行执行有副作用的工具:对于修改数据库、发送邮件等有副作用的工具,尽量串行执行
- 监控并行性能:监控工具调用的执行时间和成功率,及时发现性能瓶颈
- 使用异步工具:对于 I/O 密集型工具,使用异步实现可以进一步提高并行效率
2.5 状态回溯与回滚:系统容错性的终极保障
2.5.1 状态回溯与回滚底层原理
状态回溯是指查看历史上任意时刻的系统状态,状态回滚是指将系统状态恢复到历史上的某个时刻,然后重新执行。
回滚的两种核心策略:
- 硬回滚:删除当前状态之后的所有 Checkpoint,系统状态完全恢复到目标 Checkpoint
- 软回滚:创建一个新的 Checkpoint,将状态设置为目标 Checkpoint 的值,保留所有历史记录
工业级推荐:软回滚,保留所有历史记录,便于审计和调试。
2.5.2 实战:完整的状态回溯与回滚系统
python
from core.checkpoint import postgres_checkpointer
from core.react_agent import react_agent
from langchain_core.messages import HumanMessage
from utils.logger import logger
class RollbackService:
"""状态回溯与回滚服务"""
@staticmethod
def get_session_history(thread_id: str) -> list:
"""获取会话的完整历史记录"""
checkpoints = list(postgres_checkpointer.list(thread_id))
history = []
for checkpoint in checkpoints:
state = checkpoint["channel_values"]
history.append({
"checkpoint_id": checkpoint["id"],
"step": checkpoint["step"],
"timestamp": checkpoint["created_at"],
"messages": [
{"role": msg.type, "content": msg.content}
for msg in state["messages"]
],
"iteration_count": state["iteration_count"]
})
return history
@staticmethod
def rollback_to_checkpoint(thread_id: str, checkpoint_id: str, reason: str) -> dict:
"""
软回滚到指定的Checkpoint
保留所有历史记录,创建一个新的Checkpoint
"""
config = {"configurable": {"thread_id": thread_id}}
# 获取目标Checkpoint的状态
target_checkpoint = postgres_checkpointer.get(thread_id, checkpoint_id)
if not target_checkpoint:
raise ValueError(f"Checkpoint {checkpoint_id}不存在")
# 创建回滚消息
rollback_message = HumanMessage(
content=f"系统已回滚到步骤{target_checkpoint['step']},原因:{reason}。请从这里继续执行。"
)
# 更新状态到目标Checkpoint,并添加回滚消息
react_agent.update_state(
config,
{
"messages": target_checkpoint["channel_values"]["messages"] + [rollback_message],
"iteration_count": target_checkpoint["channel_values"]["iteration_count"]
}
)
logger.info(f"会话{thread_id}已回滚到Checkpoint {checkpoint_id},原因:{reason}")
return {
"thread_id": thread_id,
"rollback_to_checkpoint_id": checkpoint_id,
"reason": reason,
"current_step": target_checkpoint["step"]
}
@staticmethod
def reexecute_from_checkpoint(thread_id: str, checkpoint_id: str) -> str:
"""从指定的Checkpoint重新执行"""
# 先回滚到目标Checkpoint
RollbackService.rollback_to_checkpoint(thread_id, checkpoint_id, "重新执行")
# 继续执行
config = {"configurable": {"thread_id": thread_id}}
result = react_agent.invoke(None, config=config)
return result["messages"][-1].content
@staticmethod
def undo_last_action(thread_id: str) -> dict:
"""撤销上一步操作"""
checkpoints = list(postgres_checkpointer.list(thread_id))
if len(checkpoints) < 2:
raise ValueError("没有可撤销的操作")
# 回滚到上上个Checkpoint
target_checkpoint_id = checkpoints[-2]["id"]
return RollbackService.rollback_to_checkpoint(thread_id, target_checkpoint_id, "用户撤销操作")2.5.3 状态回溯与回滚最佳实践与避坑指南
- 优先使用软回滚:保留所有历史记录,便于审计和问题排查
- 明确回滚的边界:回滚只能撤销 Agent 的内部状态,无法撤销已经执行的外部操作(如发送邮件、修改数据库)
- 处理外部系统的一致性:对于有外部副作用的操作,回滚时需要手动补偿(如发送取消邮件、回滚数据库事务)
- 记录回滚日志:记录所有回滚操作,包括回滚时间、回滚人、回滚原因
- 限制回滚权限:只有授权用户才能执行回滚操作,防止滥用
三、项目整合:升级 RAGService 支持所有高级特性
3.1 升级 RAGService
代码位置 :core/rag_service.py
python
from core.react_agent import react_agent, approval_agent
from core.checkpoint import postgres_checkpointer
from core.approval_service import ApprovalService
from core.rollback_service import RollbackService
class RAGService:
"""完整的RAG+Agent问答服务(第8天高级特性版)"""
def __init__(self):
self.retriever = RAGRetriever()
self.prompt = PromptService()
self.approval_service = ApprovalService()
self.rollback_service = RollbackService()
logger.info("✅ RAG+Agent问答服务初始化完成(支持所有高级特性)")
# 原有query和stream_query方法保持不变
# 审核相关方法
def submit_approval_task(self, question: str, user_id: str) -> dict:
"""提交需要审核的任务"""
return self.approval_service.submit_task(question, user_id)
def approve_task(self, task_id: str, approver: str, comment: str = "") -> dict:
"""批准任务"""
return self.approval_service.approve_task(task_id, approver, comment)
def reject_task(self, task_id: str, approver: str, reason: str) -> dict:
"""拒绝任务"""
return self.approval_service.reject_task(task_id, approver, reason)
# 会话管理相关方法
def list_all_sessions(self) -> list:
"""列出所有会话"""
return list_all_sessions()
def get_session_history(self, thread_id: str) -> list:
"""获取会话历史"""
return self.rollback_service.get_session_history(thread_id)
def delete_session(self, thread_id: str) -> bool:
"""删除会话"""
try:
postgres_checkpointer.delete_thread(thread_id)
return True
except Exception as e:
logger.error(f"删除会话失败:{e}")
return False
# 回滚相关方法
def rollback_to_checkpoint(self, thread_id: str, checkpoint_id: str, reason: str) -> dict:
"""回滚到指定Checkpoint"""
return self.rollback_service.rollback_to_checkpoint(thread_id, checkpoint_id, reason)
def undo_last_action(self, thread_id: str) -> dict:
"""撤销上一步操作"""
return self.rollback_service.undo_last_action(thread_id)
def reexecute_from_checkpoint(self, thread_id: str, checkpoint_id: str) -> str:
"""从指定Checkpoint重新执行"""
return self.rollback_service.reexecute_from_checkpoint(thread_id, checkpoint_id)3.2 新增高级特性 API 接口
代码位置 :main8.py
python
from dotenv import load_dotenv
load_dotenv()
from core.rag_service import RAGService
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import uvicorn
app = FastAPI(title="企业级RAG+Agent API(Day8)", version="1.0.0")
rag_service = RAGService()
class QueryRequest(BaseModel):
question: str
user_id: str = "default_user"
use_agent: bool = False
class ToolCallApprovalRequest(BaseModel):
thread_id: str
approver: str = "admin"
reason: str = ""
class ApprovalRequest(BaseModel):
thread_id: str
approver: str = "admin"
reason: str = ""
class RollbackRequest(BaseModel):
thread_id: str
checkpoint_id: str
reason: str = "用户操作"
class QueryResponse(BaseModel):
answer: str
mode: str
@app.post("/api/query", response_model=QueryResponse)
async def query(request: QueryRequest):
"""通用问答接口,支持RAG和Agent两种模式"""
try:
answer = rag_service.query(
question=request.question,
user_id=request.user_id,
use_agent=request.use_agent
)
return QueryResponse(
answer=answer,
mode="agent" if request.use_agent else "rag"
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.post("/api/agent/approval/submit")
async def submit_approval_task(request: QueryRequest):
"""提交需要审核的任务"""
try:
return rag_service.submit_approval_task(
question=request.question,
user_id=request.user_id
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
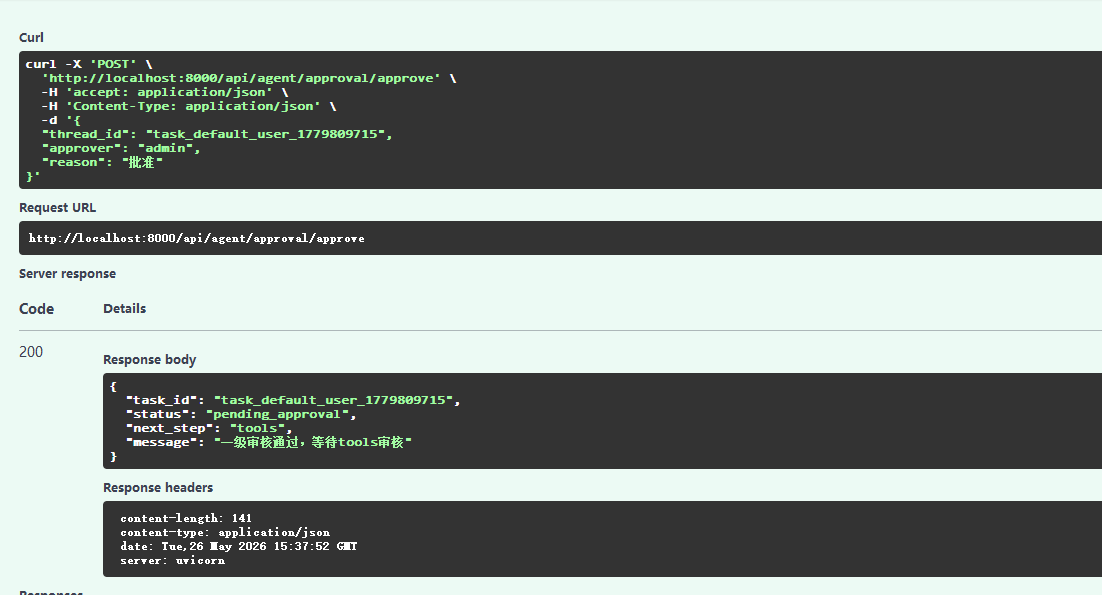
@app.post("/api/agent/approval/approve")
async def approve_approval(request: ApprovalRequest):
"""批准当前步骤的审核,继续执行"""
try:
return rag_service.approve_task(
task_id=request.thread_id,
approver=request.approver,
comment=request.reason
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.post("/api/agent/approval/reject")
async def reject_approval(request: ApprovalRequest):
"""拒绝当前步骤的审核,终止任务"""
try:
return rag_service.reject_task(
task_id=request.thread_id,
approver=request.approver,
reason=request.reason
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.post("/api/agent/rollback")
async def rollback_to_checkpoint(request: RollbackRequest):
"""回滚到指定Checkpoint"""
try:
return rag_service.rollback_to_checkpoint(
thread_id=request.thread_id,
checkpoint_id=request.checkpoint_id,
reason=request.reason
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.post("/api/agent/undo")
async def undo_last_action(thread_id: str):
"""撤销上一步操作"""
try:
return rag_service.undo_last_action(thread_id)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.post("/api/agent/reexecute")
async def reexecute_from_checkpoint(request: RollbackRequest):
"""从指定Checkpoint重新执行"""
try:
answer = rag_service.reexecute_from_checkpoint(
thread_id=request.thread_id,
checkpoint_id=request.checkpoint_id
)
return {"answer": answer}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/api/health")
async def health_check():
"""健康检查接口"""
return {"status": "healthy", "service": "rag-agent-api-day8"}
if __name__ == "__main__":
print("==> 第8天:Agent增强功能(审核、回滚、撤销)")
print("API服务启动中,访问 http://localhost:8000/docs 查看接口文档")
uvicorn.run(app, host="0.0.0.0", port=8000)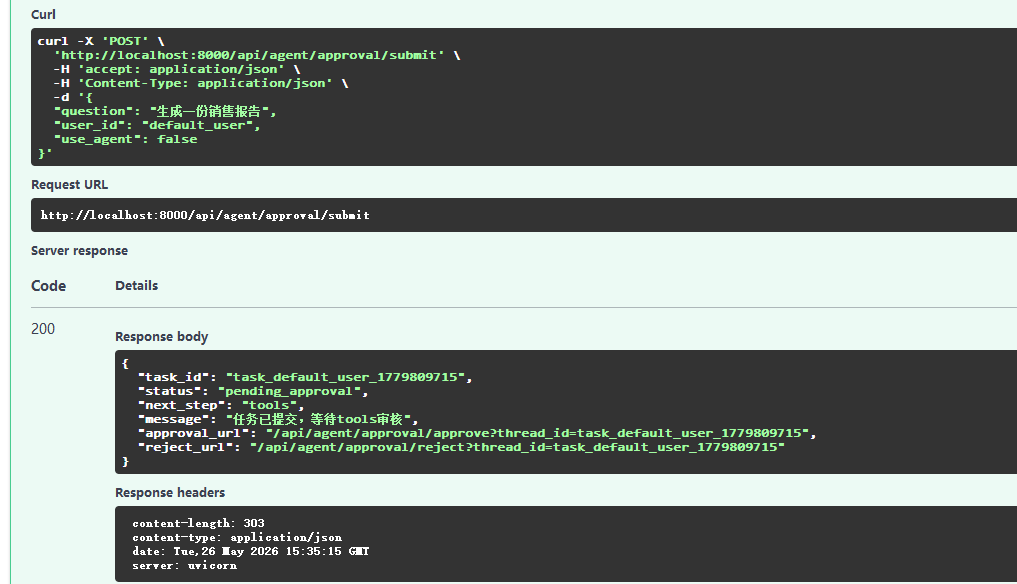
<这里还有个问题,重复调用工具>