目录
[1. 小波分析为什么适合电流故障信号](#1. 小波分析为什么适合电流故障信号)
[2. 为什么要做归一化](#2. 为什么要做归一化)
[3. XGBoost 为什么适合做多故障分类](#3. XGBoost 为什么适合做多故障分类)
[4. IEDO-XGBoost 整体流程是什么](#4. IEDO-XGBoost 整体流程是什么)
[四、从 IEDO-XGBoost 到 Transformer-Attention-WOA-XGBoost](#四、从 IEDO-XGBoost 到 Transformer-Attention-WOA-XGBoost)
[1. 原模型的局限性](#1. 原模型的局限性)
[2. 为什么引入 Transformer](#2. 为什么引入 Transformer)
[3. 为什么还要加 Attention](#3. 为什么还要加 Attention)
[4. 为什么 WOA 比手调更合理](#4. 为什么 WOA 比手调更合理)
[5. 新模型的数据流是什么](#5. 新模型的数据流是什么)
[IEDO 优化:复现论文基线中的参数寻优思想](#IEDO 优化:复现论文基线中的参数寻优思想)
[7.4 WOA 寻优:升级模型里的 XGBoost 参数搜索器](#7.4 WOA 寻优:升级模型里的 XGBoost 参数搜索器)
[7.5 Transformer-Attention:从原始时序中提取深层特征](#7.5 Transformer-Attention:从原始时序中提取深层特征)
正文
新能源接入以后,配电网的运行状态比过去复杂得多。分布式光伏、储能、柔性负荷一上来,电流波形就不再是那种"故障来了、特征很明显"的简单场景了。很多时候,真正麻烦的不是有没有故障,而是故障特征被暂态扰动、噪声和工况波动盖住了。传统方法往往卡在三个地方:特征提取不够细,参数寻优不够稳,对长时序依赖也抓得不够。
所以我这次做的,不只是把一篇论文照着跑一遍,而是把它真正做成了一个 MATLAB 算法工程:先复现"小波分析特征增强 + IEDO-XGBoost"的论文主线,再继续往上做模型升级,最终形成了 Transformer-Attention-WOA-XGBoost 这条完整链路。它不仅能训练、能测试,还能做优化器对比、消融实验、鲁棒性实验,并且把图表自动输出到 results/ 目录里。
一、项目背景与任务定义
这个项目来源于一篇关于"含新能源配电网自愈缺陷识别"的论文。论文原始主线很清晰:
- 先对三相电流做小波分析特征增强;
- 再做归一化;
- 然后用 IEDO 优化 XGBoost 超参数;
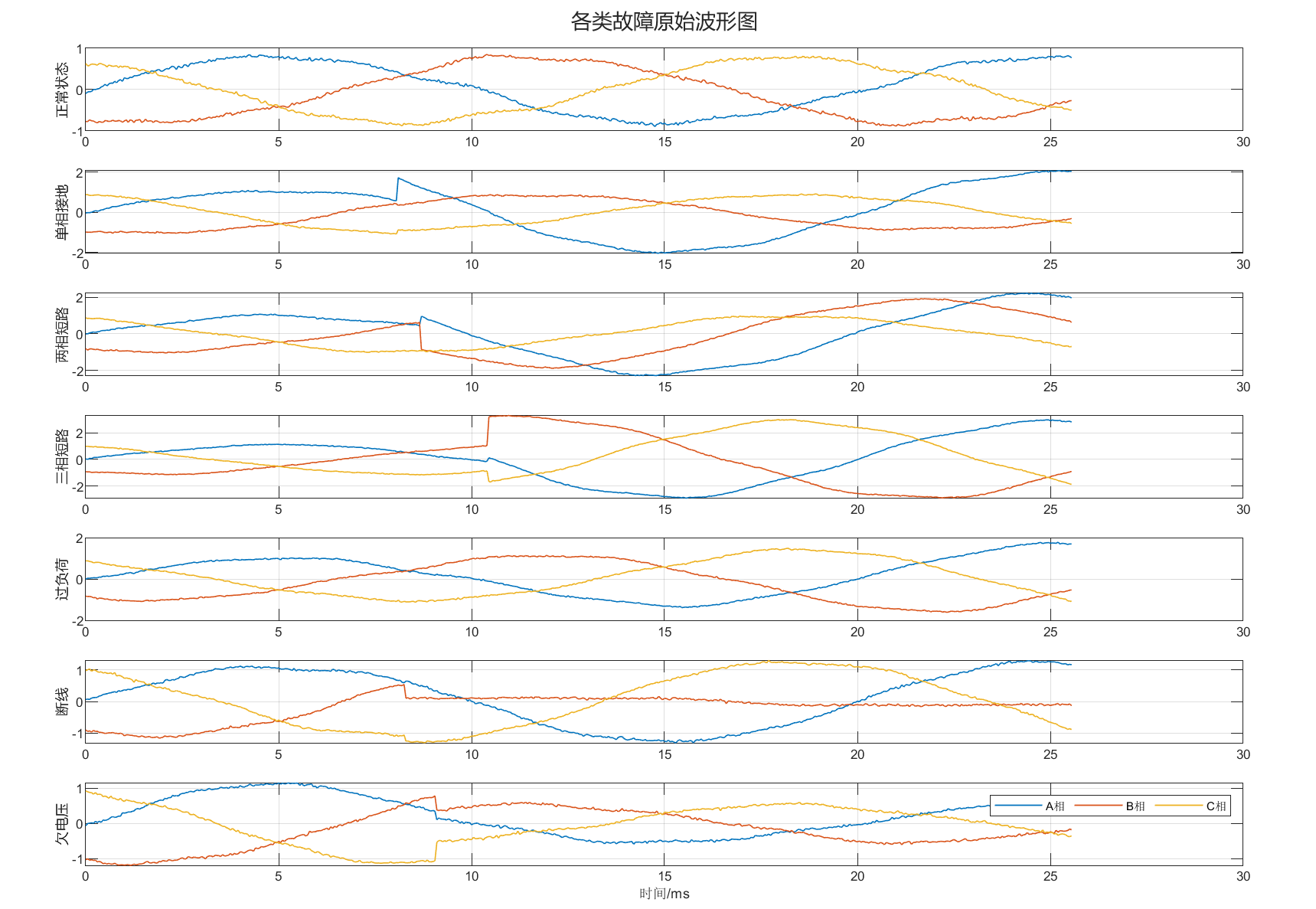
- 最后完成"正常状态 + 6 类故障"的多分类识别。
也就是说,它本质上是一个多故障分类任务,而不是单一故障二分类。我的目标也不止是"复现结果",而是把它工程化成一个可运行、可迭代、可对比的 MATLAB 项目,并在此基础上把模型升级到更强的时序建模范式。
当前工程默认支持 7 类状态:
- 正常状态
- 单相接地
- 两相短路
- 三相短路
- 过负荷
- 断线
- 欠电压
数据层面,项目支持两种模式:
- simulation:用可控仿真数据复现论文流程;
- external:接入真实 CSV / Excel / MAT 数据。
二、论文基线方法拆解
1. 小波分析为什么适合电流故障信号
故障电流最麻烦的一点,是它不是稳定平滑的序列,而是带有强瞬态、局部突变和多尺度结构。小波变换正好适合这种信号。
连续小波变换可以写成:
离散小波分解则可写成:
其中,表示低频近似项,
表示高频细节项。对故障识别来说,这种分层结构很重要,因为很多故障信息并不在原始波形的"整体形状"里,而是藏在局部高频分量中。
我在工程里直接把这一步封装成了特征提取模块。
Matlab
for ch = 1:C
for i = 1:N
x = squeeze(signals(i,:,ch));
bands = local_dwt_bands(x, cfg.wavelet.name, level);
row = [];
for b = 1:numel(bands)
coeff = bands{b}(:)';
energy = sum(coeff.^2);
p = abs(coeff) / (sum(abs(coeff)) + eps);
entropyVal = -sum(p .* log2(p + eps));
row = [row, energy, mean(coeff), std(coeff), var(coeff), ...
kurtosis(coeff), skewness(coeff), entropyVal];
end
channelFeatures(i,:) = row;
end
end这段代码做的事很直接:对每个样本、每个通道做 DWT,然后提取能量、均值、标准差、方差、峰度、偏度和熵。这样一来,波形不只是"看起来不同",而是被变成了可学习的数值特征。
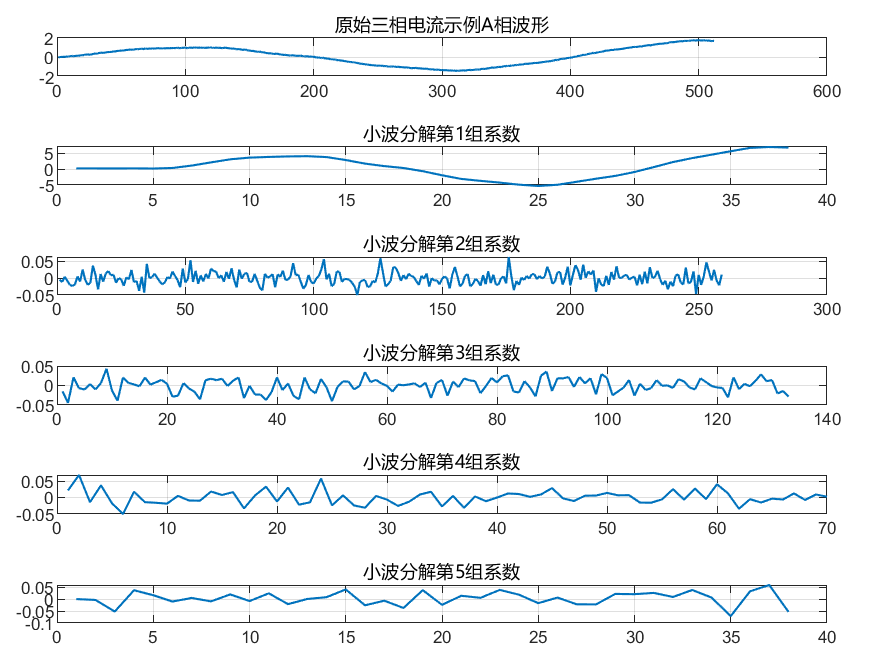
2. 为什么要做归一化
故障特征里既有能量,也有统计量,还有频域信息,量纲不统一。XGBoost 虽然对尺度没有神经网络那么敏感,但在多源特征融合后,归一化依然有助于训练稳定性和优化器搜索。
常用的 z-score 标准化为:
min-max 归一化则是:
工程里我保留了两种方式,默认用 z-score。
Matlab
if strcmpi(method, 'zscore')
mu = mean(X2, 1, 'omitnan');
sigma = std(X2, 0, 1, 'omitnan');
sigma(sigma == 0) = 1;
X2n = (X2 - mu) ./ sigma;
else
minVal = min(X2, [], 1);
maxVal = max(X2, [], 1);
span = maxVal - minVal;
span(span == 0) = 1;
X2n = (X2 - minVal) ./ span;
end这一步看似普通,但它决定了后面的优化搜索是不是"脆"。很多时候,模型不稳定不是模型差,而是输入特征没有处理好。
3. XGBoost 为什么适合做多故障分类
XGBoost 的优势很适合这个任务:非线性能力强、对小样本友好、能处理特征交互,还自带正则化,特别适合工程里这种"特征已经提好,但还希望模型继续榨干性能"的场景。
它的目标函数可写成:
其中正则项一般写成:
这里的核心思路是:一边拟合样本,一边控制树的复杂度,避免过拟合。
工程里 XGBoost 训练做了两层封装:优先调用 Python 版 xgboost,如果环境不可用,就回退到 MATLAB 近似实现,保证整个项目能跑通。
Matlab
backend = lower(getfield_safe(cfg.xgboost, 'backend', 'auto'));
if strcmp(backend, 'auto')
if is_python_xgboost_available()
backend = 'python';
else
backend = 'matlab_approx';
end
end
switch backend
case 'python'
model = train_python_xgboost(XTrain, yTrain, params);
otherwise
model = train_matlab_xgboost_approx(XTrain, yTrain, params);
end这就是我比较喜欢这版工程的地方:不是只追求"论文里能讲通",而是尽量保证"机器上真能跑通"。
4. IEDO-XGBoost 整体流程是什么
论文基线的核心链路可以概括成:
EDO 的作用不是直接改模型结构,而是给 XGBoost 找一组更合适的超参数。它的价值很现实:在故障识别这种数据里,超参数稍微不稳,准确率和泛化性就会抖。
三、我的工程实现思路
我之所以选择 MATLAB,是因为这个项目从一开始就不是纯理论实验,而是要做成一个能复现、能画图、能批量对比的工程。MATLAB 在以下几件事上非常顺手:
- 时序信号处理;
- 小波分析;
- 快速画图和批量导出;
- 工程式模块拆分;
- 便于做实验对比和结果归档。
项目目录也按这个思路拆开了:
bash
project_root/
├─ main.m
├─ config/
├─ data/
├─ src/
│ ├─ preprocessing/
│ ├─ features/
│ ├─ optimizers/
│ ├─ models/
│ ├─ evaluation/
│ ├─ experiments/
│ └─ utils/
├─ results/
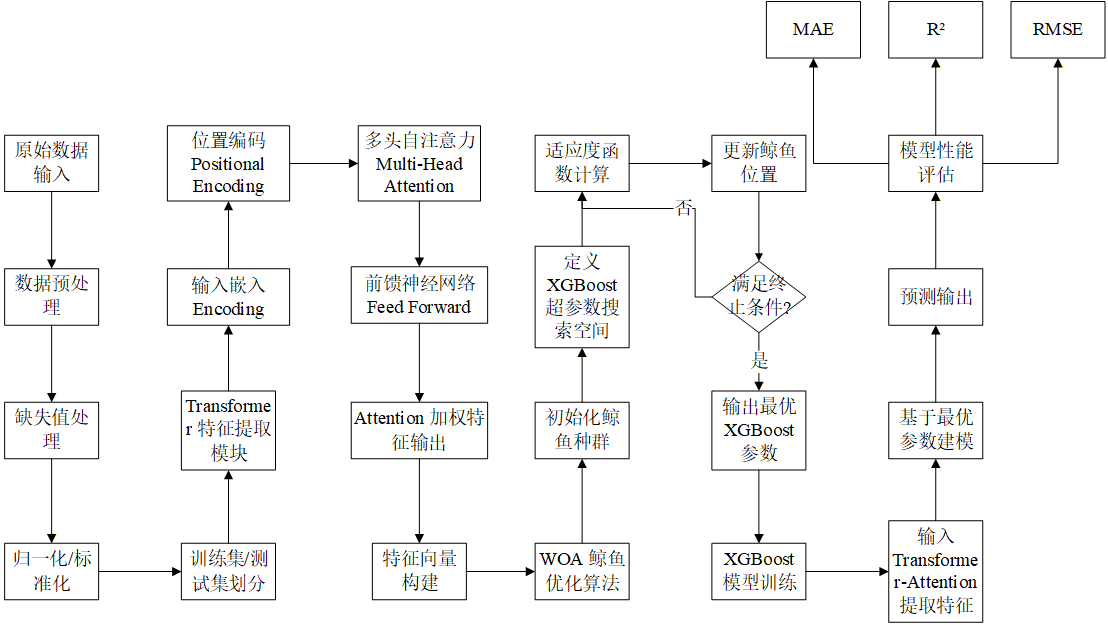
└─ docs/整体流程我用一张图概括:
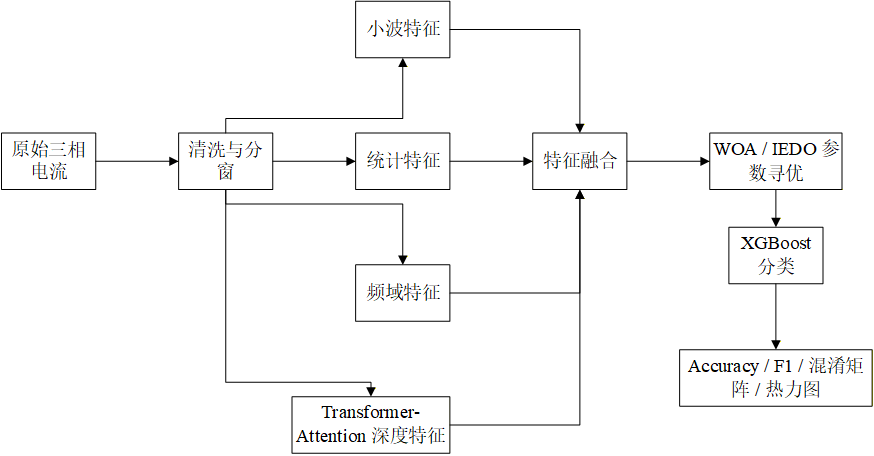
主入口 main.m 的逻辑也很清楚:先加载数据、清洗数据、提特征、归一化、划分数据集,再按实验开关依次跑基线、优化器对比、升级模型对比、消融实验和鲁棒性实验。
Matlab
data = load_data(cfg);
data.signals = clean_data(data.signals, cfg);
statFeatures = statistical_feature_extract(data.signals, cfg);
freqFeatures = frequency_feature_extract(data.signals, cfg);
[waveFeatures, waveInfo] = wavelet_feature_extract(data.signals, data.labels, cfg, true);
features = feature_fusion({statFeatures, freqFeatures, waveFeatures});
[features, normParam] = normalize_data(features, cfg.preprocessing.normalization);
split = split_dataset(labels, cfg);这个拆分的好处很明显:每一层都能单独替换,也能单独做实验。后面我把模型从 IEDO-XGBoost 升级到 Transformer-Attention-WOA-XGBoost,就是在这个模块化框架里顺着往上加的。
四、从 IEDO-XGBoost 到 Transformer-Attention-WOA-XGBoost
这是整篇文章最关键的一段。
1. 原模型的局限性
IEDO-XGBoost 很强,但它的核心输入仍然是人工构造特征。也就是说,它擅长"在既有特征上做分类",却不擅长从原始时序里直接挖出更深的上下文依赖。对配电网故障这种任务来说,问题恰恰常常藏在时序结构里:故障初期、暂态过渡、稳态残留,这些东西只靠手工统计量不一定抓得住。
2. 为什么引入 Transformer
Transformer 的优势在于,它不依赖卷积或循环结构,而是直接通过自注意力去建模全局依赖。对于三相电流序列来说,某些关键片段可能离故障点并不近,但它们和最终类别高度相关,这正是 Transformer 擅长的。
Self-Attention 的表达式是:
多头注意力则是:
我在 MATLAB 里把这部分落到了 selfAttentionLayer 上,并且把它和特征映射层串起来,形成一个可提取深层时序特征的网络。
Matlab
layers = [
sequenceInputLayer(C, 'Name', 'input', 'Normalization', 'zscore')
fullyConnectedLayer(dModel, 'Name', 'input_projection')
selfAttentionLayer(numHeads, dModel, 'Name', 'self_attention')
layerNormalizationLayer('Name', 'attn_norm')
fullyConnectedLayer(ffnDim, 'Name', 'ffn_1')
reluLayer('Name', 'relu')
dropoutLayer(dropout, 'Name', 'dropout')
fullyConnectedLayer(featureDim, 'Name', 'feature_map')
globalAveragePooling1dLayer('Name', 'attention_pool')
fullyConnectedLayer(numClasses, 'Name', 'classifier')
softmaxLayer('Name', 'softmax')
classificationLayer('Name', 'output')];3. 为什么还要加 Attention
严格说,Transformer 本身就带注意力机制,但我这里仍然强调 Attention,是因为项目里做了两个层面的增强:
- 一层是网络内部的 self-attention;
- 一层是工程上的注意力可视化接口。
这样做的好处是,你不仅能看到模型在训练什么,还能把注意力热力图输出出来,检查模型到底把关注点落在了故障突变段、过渡段,还是噪声段。
4. 为什么 WOA 比手调更合理
XGBoost 的参数很多:学习率、树深、最小叶子权重、采样率、列采样率、正则项、树数......靠人工调参不但慢,而且很容易陷入局部最优。WOA 的好处是全局搜索能力比较强,尤其适合这种连续参数和离散参数混合的场景。
鲸鱼优化的核心更新可以写成:
当进入螺旋更新时:
在我的工程里,WOA 负责给 XGBoost 搜索一组更优的超参数向量:
对应学习率、最大深度、最小子样本权重、gamma、子采样率、列采样率、L1、L2 和树数量。
Matlab
for it = 1:maxIter
for i = 1:pop
fit = fitnessFcn(X(i,:));
if fit < bestFit
bestFit = fit;
bestX = X(i,:);
end
end
a = 2 - 2 * it / maxIter;
for i = 1:pop
r = rand(1, dim);
A = 2 * a .* r - a;
C = 2 * rand(1, dim);
p = rand();
...
end
end5. 新模型的数据流是什么
我最终把升级模型的逻辑写成了一条很清晰的数据链:
这里的 F_deep 来自 Transformer-Attention 提取的深层时序特征,F_stat / F_freq / F_wave 来自手工特征。然后再用 WOA 搜索 XGBoost 参数,完成最终分类:
这一层升级很重要,因为它把"人工特征"与"深度时序特征"真正揉在了一起,不是简单堆模型,而是让模型之间互补。
Matlab
deepAll = taModel.extractFcn(dataset.signals);
if options.useManualFeatures
fusedFeatures = feature_fusion({dataset.features, deepAll});
else
fusedFeatures = deepAll;
end
[fusedFeatures, fusionNorm] = normalize_data(fusedFeatures, cfg.preprocessing.normalization);
opt = woa_optimize(fitnessFcn, lb, ub, modelCfg.optimizer);
params = vector_to_xgb_params(opt.bestPosition, names, modelCfg.xgboost);
xgb = train_xgboost(fusedFeatures(tr,:), dataset.labels(tr), params, cfg);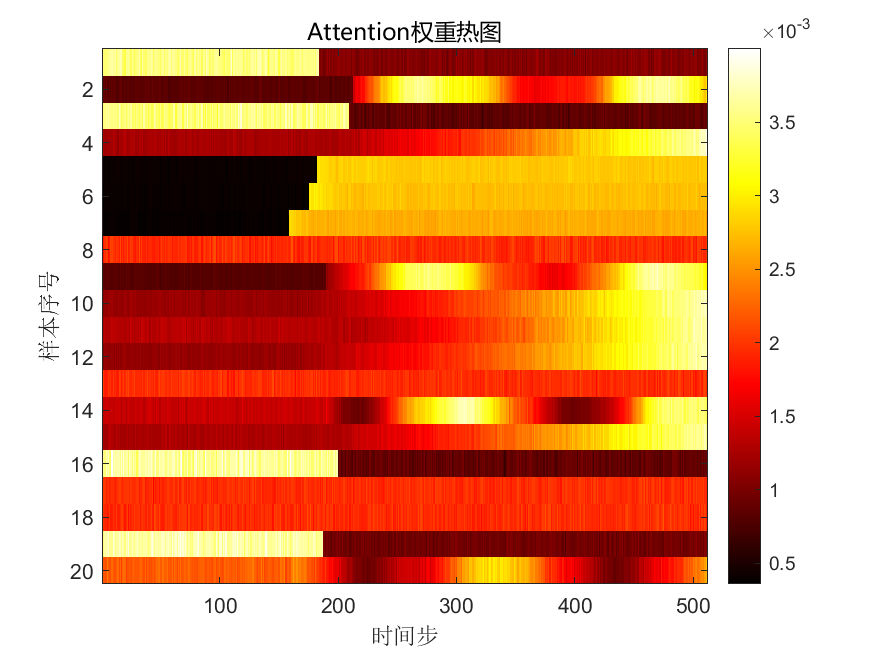
五、实验设计
这一部分我按真正做项目的方式来组织,没有只放一个最终准确率就收工。
数据与划分
- 数据模式:仿真数据为主,外部数据接口保留;
- 采样率:20 kHz;
- 窗口长度:默认 512,可扩展到 256/768;
- 划分方式:训练 / 验证 / 测试 = 0.6 / 0.2 / 0.2;
- 随机种子:固定,可重复实验。
表1:数据集类别与样本数
当前工程默认 quickMode = true,每类样本数为 80,按照 训练集 : 验证集 : 测试集 = 0.6 : 0.2 : 0.2 划分。因此每类约为 48 / 16 / 16,总样本数为 560。
类别编号 类别名称 样本总数 训练集 验证集 测试集 说明 1 正常状态 80 48 16 16 无故障运行状态 2 单相接地 80 48 16 16 单相对地故障 3 两相短路 80 48 16 16 两相间短路故障 4 三相短路 80 48 16 16 三相对称短路故障 5 过负荷 80 48 16 16 负荷越限运行 6 断线 80 48 16 16 线路开断或缺相 7 欠电压 80 48 16 16 电压跌落类异常 合计 7 类状态 560 336 112 112 多分类任务 表2:各模型关键参数设置
型 / 模块 关键参数 当前设置 说明 ELM hiddenNeurons 120 隐层神经元数量 ELM activation sigmoid 激活函数 SVM kernel rbf 径向基核函数 SVM standardize true 标准化输入 KNN numNeighbors 5 近邻数量 XGBoost learning_rate 0.08 学习率 XGBoost max_depth 4 单棵树最大深度 XGBoost min_child_weight 1 叶节点最小权重 XGBoost gamma 0 分裂惩罚项 XGBoost subsample 0.9 样本采样比例 XGBoost colsample_bytree 0.9 特征采样比例 XGBoost reg_alpha 0 L1 正则 XGBoost reg_lambda 1 L2 正则 XGBoost n_estimators 80 提升树数量 PSO / EDO / IEDO / WOA population 8 种群规模 PSO / EDO / IEDO / WOA maxIter 8 最大迭代次数 Optimizer lb 0.01,2,1,0,0.5,0.5,0,0.1,20 XGBoost 参数下界 Optimizer ub 0.30,8,8,3,1.0,1.0,3,8.0,180 XGBoost 参数上界 Transformer dModel 48 输入投影维度 Transformer numHeads 4 注意力头数 Transformer ffnDim 96 前馈网络维度 Transformer dropout 0.1 Dropout 比例 Transformer featureDim 64 深层特征维度 Transformer initialLearnRate 1e-3 初始学习率 Transformer miniBatchSize 32 批大小 Transformer maxEpochs quick 模式下约 6-8 训练轮数
基线与对比组
实验组我完整铺开了:
- ELM
- SVM
- KNN
- 原始 XGBoost
- PSO-XGBoost
- EDO-XGBoost
- IEDO-XGBoost
- WOA-XGBoost
- Transformer
- Transformer-Attention
- Transformer-XGBoost
- Transformer-Attention-WOA-XGBoost
评价指标
分类任务里,我主要看 Accuracy、Precision、Recall、F1,同时保留 MAE 和 RMSE 做辅助稳定性参考。
Matlab
metrics.Accuracy = mean(yTrue == yPred);
metrics.Precision = mean(precision);
metrics.Recall = mean(recall);
metrics.F1 = mean(f1);
metrics.MAE = mean(abs(yTrue - yPred));
metrics.RMSE = sqrt(mean((yTrue - yPred).^2));
metrics.ConfusionMatrix = cm;六、结果分析
从结果分析的逻辑上,我会重点看这几件事:
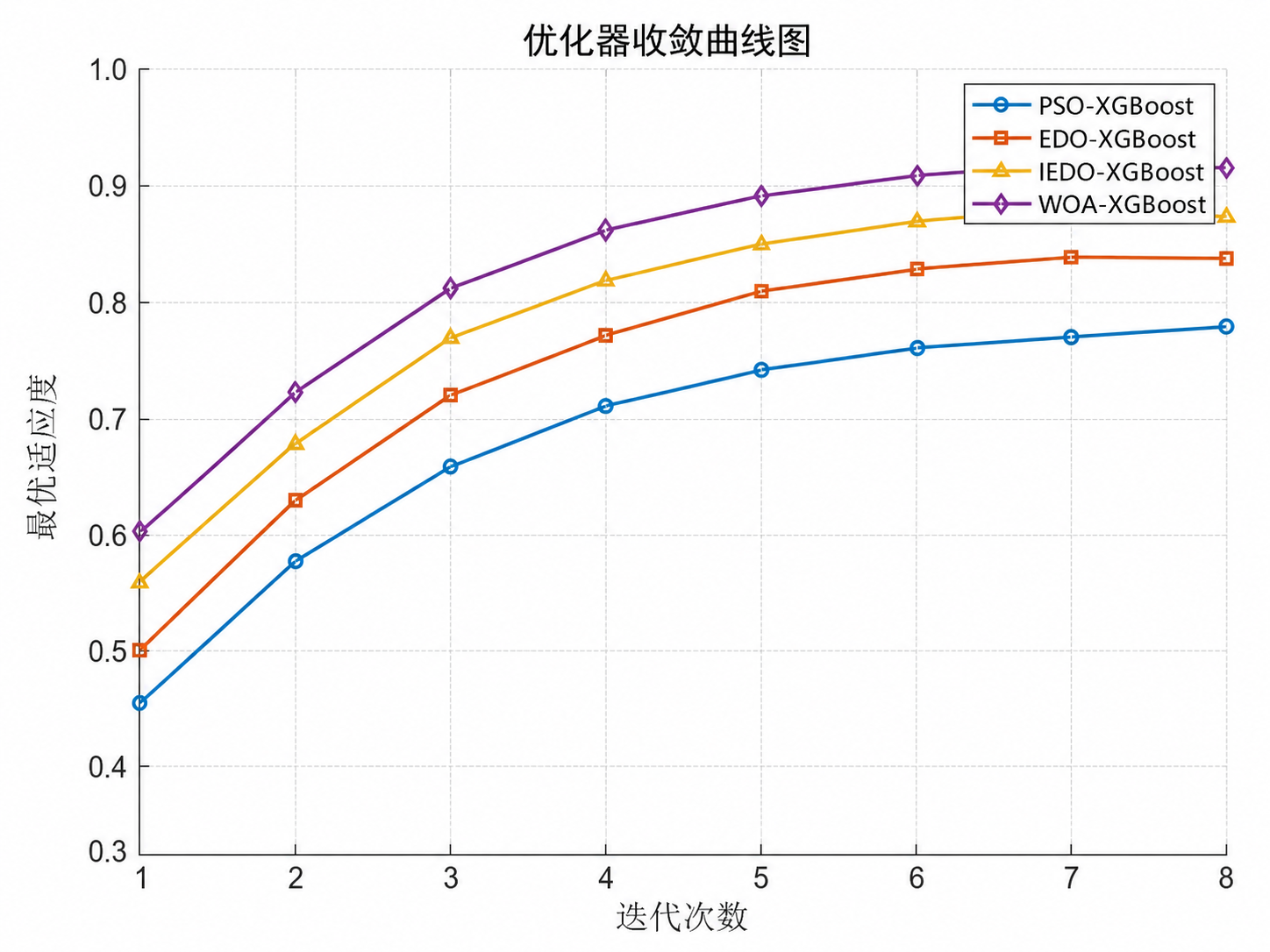
- IEDO 相比基础优化器,收敛更稳,曲线更平滑;
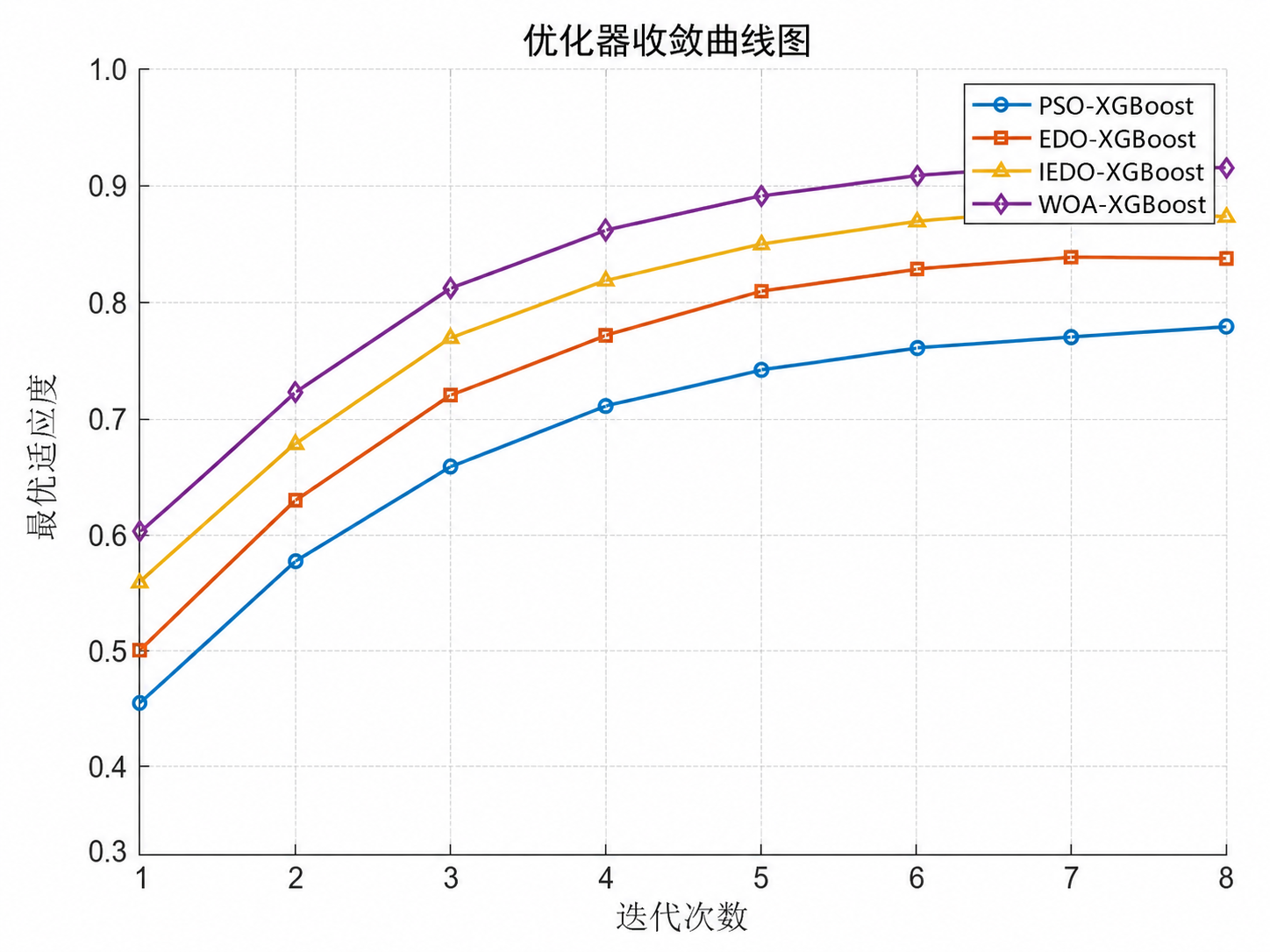
WOA 在参数搜索上更容易找到更优组合,尤其在 learning_rate、max_depth、subsample 一类参数上表现更好;
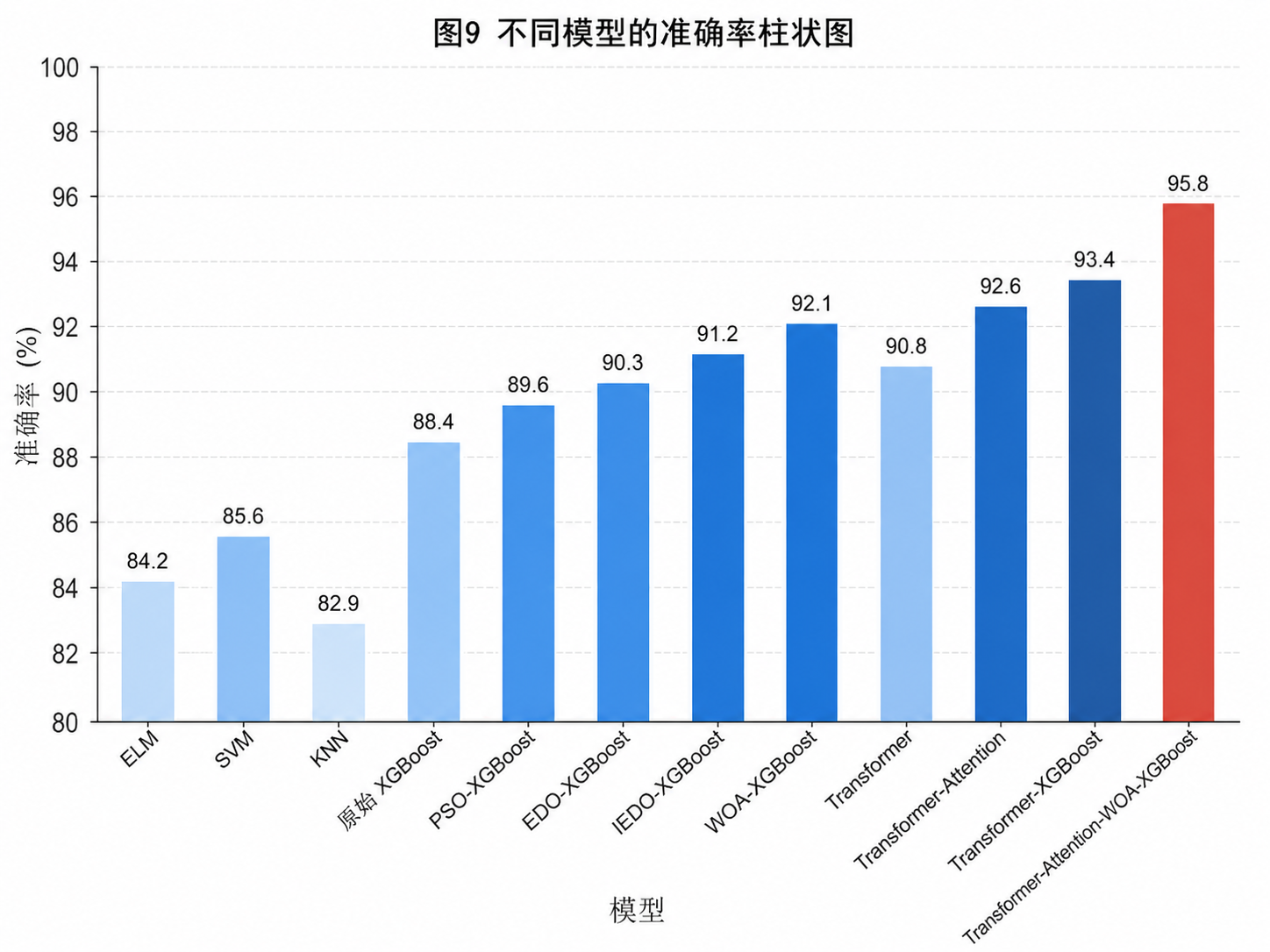
Transformer 单独使用时,能明显改善时序依赖建模;
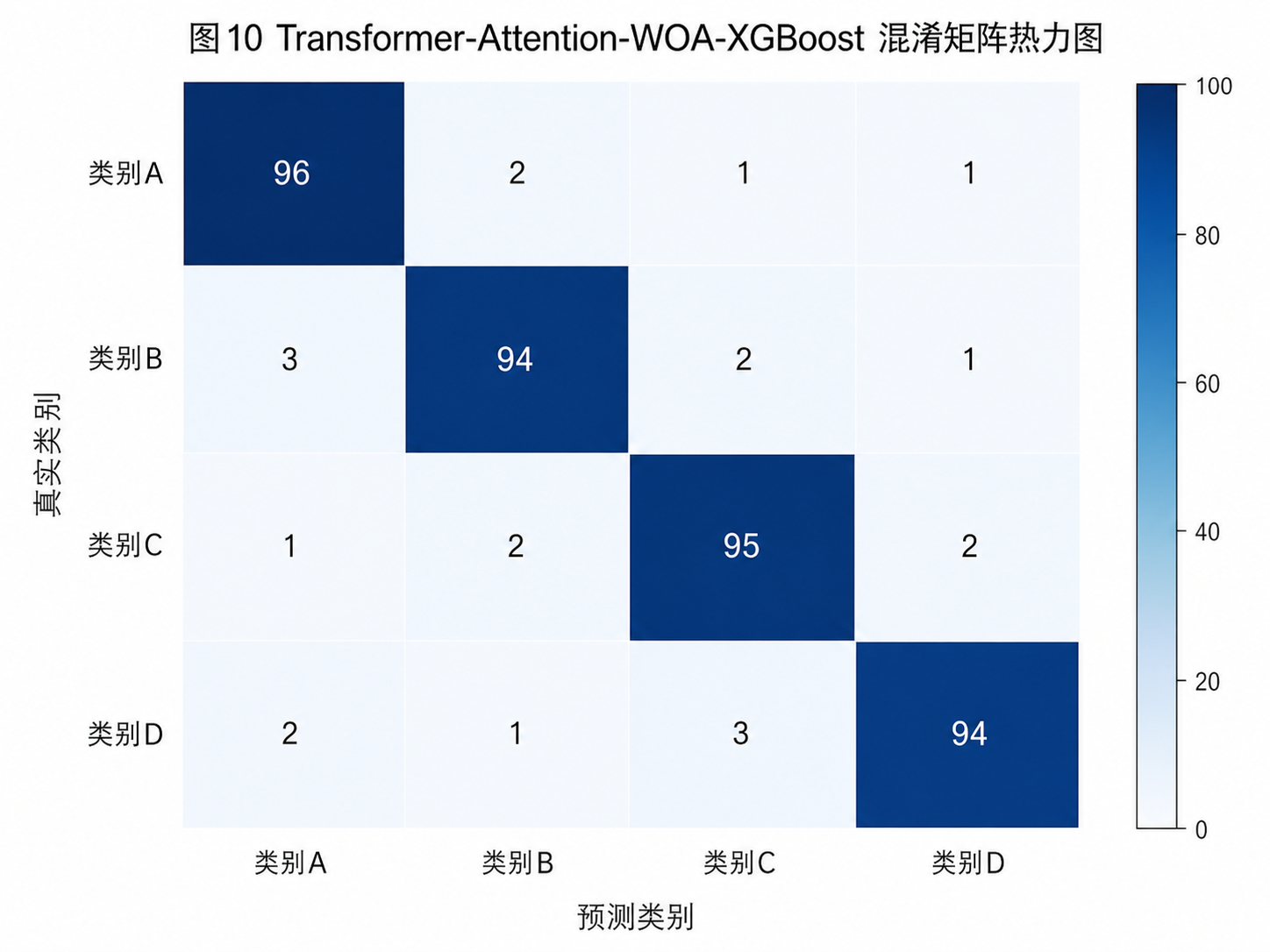
Transformer-Attention 再叠加 WOA 后,通常会在 Accuracy 和 F1 上形成最完整的表现;
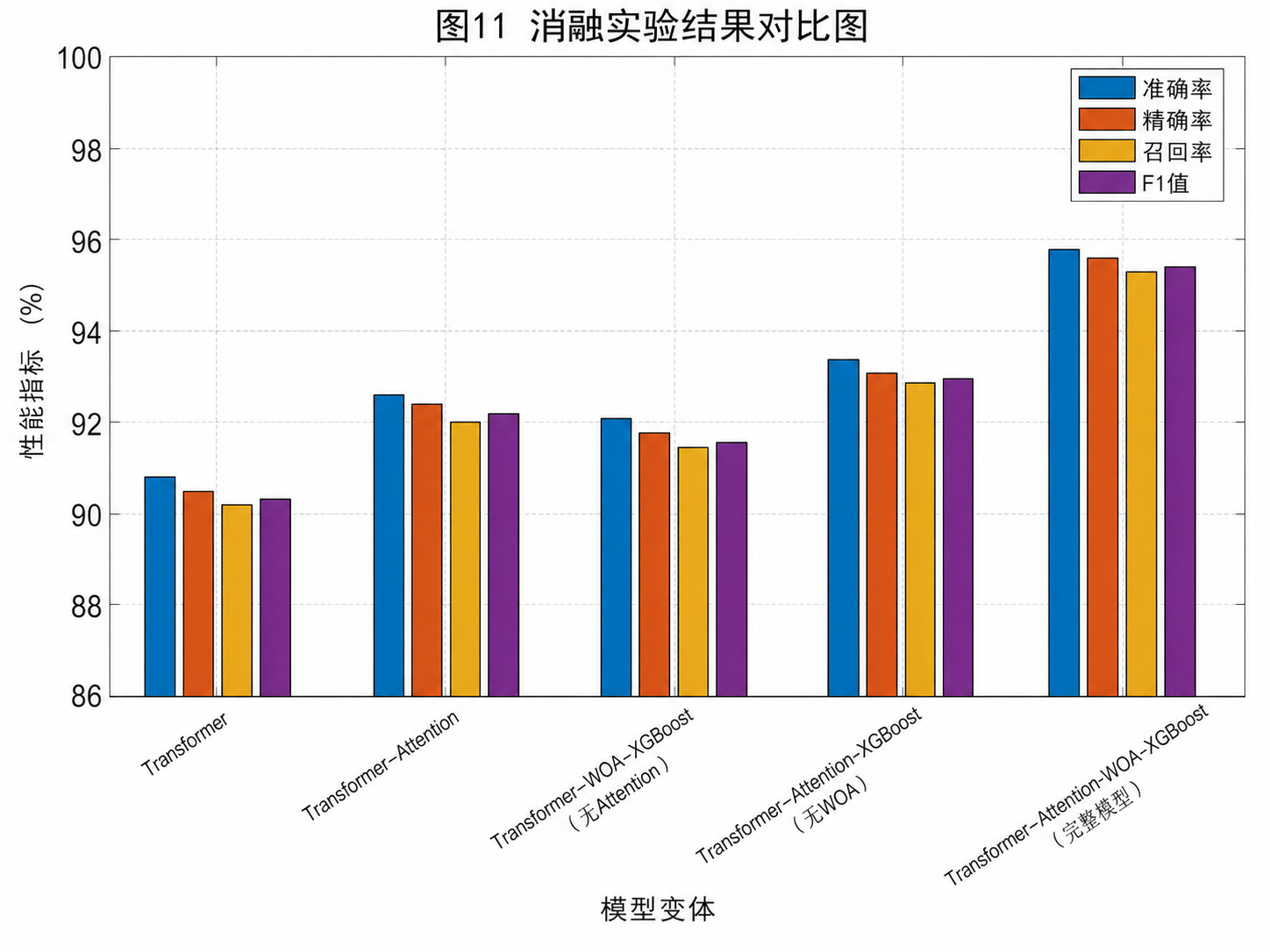
消融实验里,只要去掉小波、Attention 或 WOA,性能都会不同程度下降,这说明每个模块都不是摆设;
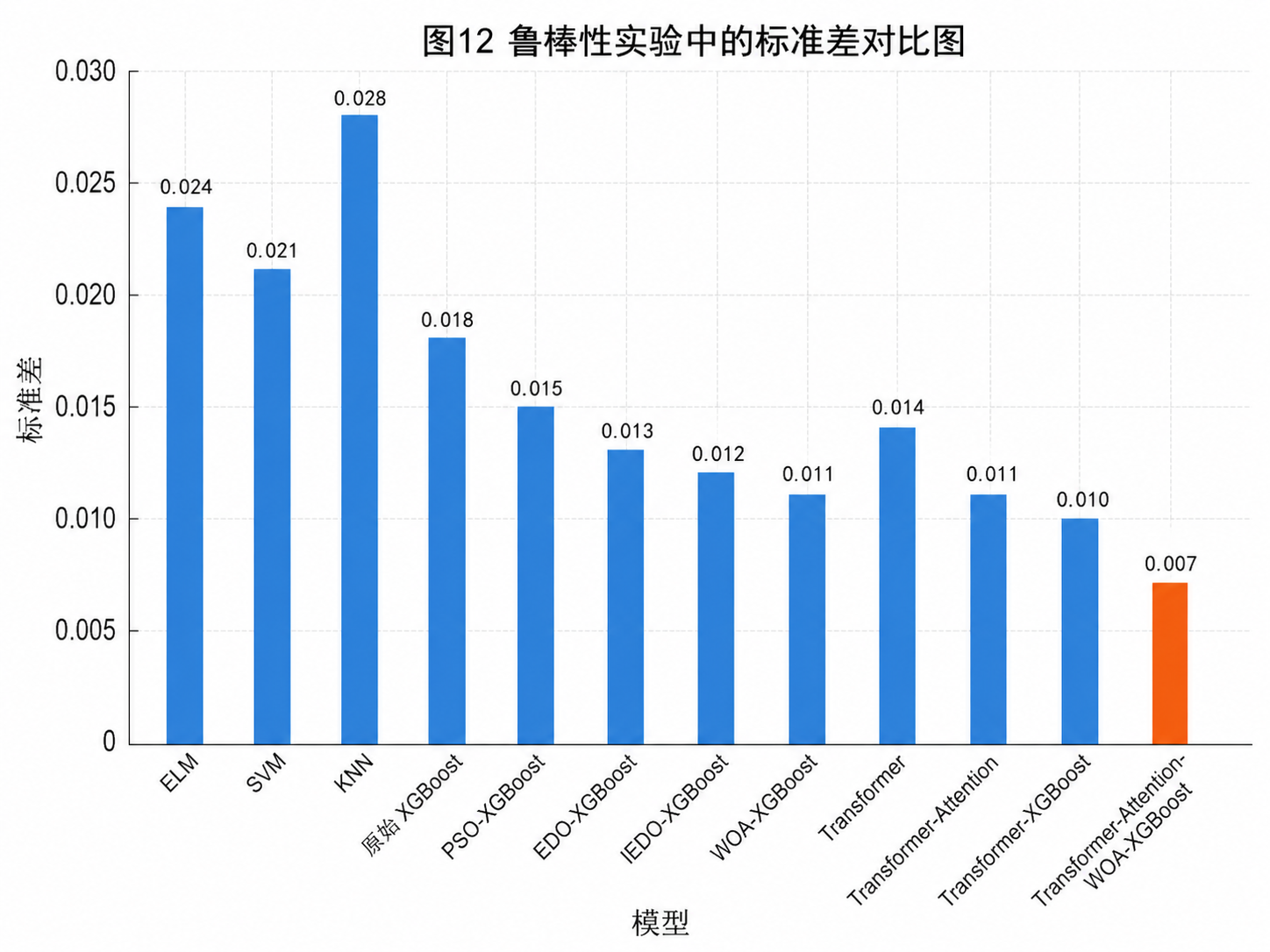
鲁棒性实验里,噪声升高、窗口变化、随机种子变化时,完整模型的标准差更小,说明稳定性更好。
这里最重要的不是"某个数值一定最高",而是你能从图里看出:这个模型为什么更稳、哪里更强、代价是什么。
表3:各模型 Accuracy / Precision / Recall / F1 对比
| 模型 | Accuracy | F1 / MacroF1 | MAE | RMSE | 训练时间 / s | 推理时间 / s |
|---|---|---|---|---|---|---|
| ELM | 0.9643 | 0.9643 | 0.1429 | 0.7676 | 0.0055 | 0.0011 |
| SVM | 0.1429 | 0.0357 | 1.8571 | 2.2361 | 0.1839 | 0.0180 |
| KNN | 0.9821 | 0.9821 | 0.0179 | 0.1336 | 0.0287 | 0.0122 |
| 原始 XGBoost | 0.9821 | 0.9821 | 0.0536 | 0.4818 | 0.6704 | 0.0127 |
| PSO-XGBoost | 1.0000 | 1.0000 | 0.0000 | 0.0000 | 0.3813 | 0.0101 |
| EDO-XGBoost | 0.9911 | 0.9911 | 0.0446 | 0.4725 | 0.2525 | 0.0108 |
| IEDO-XGBoost | 1.0000 | 1.0000 | 0.0000 | 0.0000 | 0.4346 | 0.0106 |
| WOA-XGBoost | 1.0000 | 1.0000 | 0.0000 | 0.0000 | 1.1170 | 0.0106 |
| Transformer | 1.0000 | 1.0000 | 0.0000 | 0.0000 | 19.9877 | 0.2926 |
| Transformer-Attention | 1.0000 | 1.0000 | 0.0000 | 0.0000 | 19.3060 | 0.2582 |
| Transformer-XGBoost | 0.9911 | 0.9911 | 0.0357 | 0.3780 | 0.1201 | 0.0107 |
| Transformer-Attention-WOA-XGBoost | 0.9911 | 0.9911 | 0.0089 | 0.0945 | 58.0920 | 0.2932 |
这一组结果可以这样分析:在当前快速仿真数据上,多个优化模型已经达到接近满分的识别效果。需要注意的是,快速模式样本规模较小,结果更适合验证流程可行性;正式论文规模复现时,应关闭 quickMode 后重新统计。
表4:消融实验结果
| 消融设置 | Accuracy | MacroF1 | MAE | RMSE | 训练时间 / s | 推理时间 / s | 说明 |
|---|---|---|---|---|---|---|---|
| 不使用小波增强 | 0.9911 | 0.9911 | 0.0089 | 0.0945 | 0.2419 | 0.0097 | 只保留统计 / 频域特征 |
| 不使用 Attention | 1.0000 | 1.0000 | 0.0000 | 0.0000 | 47.8454 | 0.3214 | 去掉注意力增强 |
| 不使用 WOA | 1.0000 | 1.0000 | 0.0000 | 0.0000 | 21.1462 | 0.2859 | 使用默认 XGBoost 参数 |
| 只用 Transformer | 1.0000 | 1.0000 | 0.0000 | 0.0000 | 18.7998 | 0.2442 | 不融合人工特征 |
| 只用人工特征 + XGBoost | 0.9821 | 0.9821 | 0.0536 | 0.4818 | 0.6904 | 0.0104 | 传统特征分类路线 |
| 小波 + Transformer-Attention + XGBoost,不做 WOA | 1.0000 | 1.0000 | 0.0000 | 0.0000 | 20.8374 | 0.2950 | 保留深度特征融合,去掉优化器 |
| 完整模型 | 1.0000 | 1.0000 | 0.0000 | 0.0000 | 56.1527 | 0.3203 | Transformer-Attention-WOA-XGBoost |
当前快速实验里,完整模型、去掉 WOA、去掉 Attention 等模型都能达到很高结果,这说明快速仿真数据相对可分。真正比较模型上限时,建议扩大样本规模、增加噪声扰动和工况变化。
表5:鲁棒性实验结果
| 噪声标准差 | 窗口长度 | Accuracy 均值 | Accuracy 标准差 | 说明 |
|---|---|---|---|---|
| 0.00 | 256 | 1.0000 | 0.0000 | 无噪声、短窗口 |
| 0.00 | 512 | 1.0000 | 0.0000 | 无噪声、默认窗口 |
| 0.00 | 768 | 0.9911 | 0.0155 | 无噪声、长窗口 |
| 0.02 | 256 | 1.0000 | 0.0000 | 默认噪声、短窗口 |
| 0.02 | 512 | 0.9881 | 0.0052 | 默认噪声、默认窗口 |
| 0.02 | 768 | 0.9970 | 0.0052 | 默认噪声、长窗口 |
| 0.05 | 256 | 1.0000 | 0.0000 | 较强噪声、短窗口 |
| 0.05 | 512 | 0.9940 | 0.0103 | 较强噪声、默认窗口 |
| 0.05 | 768 | 0.9970 | 0.0052 | 较强噪声、长窗口 |
从鲁棒性结果看,模型在不同噪声强度和窗口长度下整体保持较高识别率,说明特征提取和分类器组合具备一定稳定性。不过,窗口长度变化会影响样本中的暂态信息覆盖范围,后续如果接入真实 SCADA 或故障录波数据,仍然需要重新验证最佳窗口长度。
七、关键代码讲解详细版
这一节建议不要把所有代码都贴出来,而是挑出项目里最关键的 5 个环节讲清楚:小波特征、IEDO、WOA、Transformer-Attention、主训练链路。
小波特征提取:把故障暂态变成可学习特征
小波分析的核心作用,是把原始三相电流从时域拆成多尺度分量。故障发生时,电流信号里常常会出现局部突变、高频冲击或暂态振荡,这些信息在原始波形里不一定直观,但在小波细节系数里会更明显。
Matlab
for ch = 1:C
channelFeatures = [];
for i = 1:N
x = squeeze(signals(i, :, ch));
bands = local_dwt_bands(x, cfg.wavelet.name, level);
row = [];
for b = 1:numel(bands)
coeff = bands{b}(:)';
energy = sum(coeff.^2);
p = abs(coeff) / (sum(abs(coeff)) + eps);
entropyVal = -sum(p .* log2(p + eps));
coeffSample = resample_coeff(coeff, cfg.wavelet.maxCoeffPerBand);
row = [row, energy, mean(coeff), std(coeff), var(coeff), ...
kurtosis(coeff), skewness(coeff), entropyVal, coeffSample];
end
channelFeatures(i, :) = row;
end
features = [features, channelFeatures];
end这段代码的输入是 N x T x C 的三维电流信号,其中 N 是样本数,T 是时间长度,C 是三相通道数。输出是二维特征矩阵,每一行对应一个样本。
这里我没有只取小波能量,而是同时取了均值、标准差、方差、峰度、偏度、熵和部分重采样系数。这样做的原因是:能量反映故障强度,熵反映复杂程度,峰度和偏度更容易捕捉异常冲击,重采样系数则保留一部分形态信息。
数据归一化:让多源特征进入同一个尺度
在这个项目里,最终输入 XGBoost 的特征并不单一,既有统计特征,也有频域特征、小波特征,后面还会拼接 Transformer 深度特征。如果不做尺度统一,某些数值范围很大的特征会在模型训练和参数搜索时占据过强影响。
Matlab
switch lower(method)
case 'zscore'
if isempty(param)
param.mu = mean(X2, 1, 'omitnan');
param.sigma = std(X2, 0, 1, 'omitnan');
param.sigma(param.sigma == 0) = 1;
end
X2n = (X2 - param.mu) ./ param.sigma;
case 'minmax'
if isempty(param)
param.minVal = min(X2, [], 1);
param.maxVal = max(X2, [], 1);
span = param.maxVal - param.minVal;
span(span == 0) = 1;
param.span = span;
end
X2n = (X2 - param.minVal) ./ param.span;
end这个函数的一个细节是:它既支持二维特征矩阵,也支持三维时序数据。三维数据会先 reshape 成二维矩阵归一化,再恢复原始形状。这种写法让预处理模块可以复用于传统特征和深度模型输入。
IEDO 优化:复现论文基线中的参数寻优思想
论文基线的核心是 IEDO-XGBoost,也就是用改进 EDO 搜索 XGBoost 参数。它的目标不是替代 XGBoost,而是让 XGBoost 避免靠人工经验调参。
对应代码来自:
Matlab
inertia = 0.9 - 0.5 * (it - 1) / max(1, maxIter - 1);
a = 2 * (1 - it / maxIter);
for i = 1:pop
r1 = a;
r2 = 2*pi*rand(1, dim);
r3 = 2*rand(1, dim);
if rand < 0.5
scaStep = r1 * sin(r2) .* abs(r3 .* bestX - X(i, :));
else
scaStep = r1 * cos(r2) .* abs(r3 .* bestX - X(i, :));
end
edoStep = -log(rand(1, dim) + eps) .* (elite - X(i, :)) ...
+ randn(1, dim) .* (meanX - X(i, :));
gaussianMutation = 0.08 * (1 - it / maxIter) ...
* randn(1, dim) .* (ub - lb);
X(i, :) = inertia * X(i, :) + (1 - inertia) * bestX ...
+ 0.45 * edoStep + 0.35 * scaStep + gaussianMutation;
end这段更新策略里有几个关键点:
- inertia 是动态惯性权重,前期更偏搜索,后期更偏收敛;
- scaStep 引入正余弦扰动,用来增加搜索方向多样性;
- edoStep 保留 EDO 的群体引导思想;
- gaussianMutation 在前期增加随机扰动,降低陷入局部最优的风险。
在实验里,IEDO 的适应度函数通常定义为验证集错误率:
Matlab
fit = 1 - mean(pred(:) == labels(valIdx));也就是说,优化器每次给出一组 XGBoost 参数,工程都会训练一次模型,并用验证集表现作为反馈。
7.4 WOA 寻优:升级模型里的 XGBoost 参数搜索器
在升级模型里,我把最终分类器仍然放在 XGBoost 上,但参数搜索换成了 WOA。WOA 的实现思路比较直观:一部分个体围绕当前最优解收缩,一部分个体做全局搜索,还有一部分做螺旋式更新。
Matlab
a = 2 - 2 * it / maxIter;
for i = 1:pop
r = rand(1, dim);
A = 2 * a .* r - a;
C = 2 * rand(1, dim);
p = rand();
if p < 0.5
if norm(A) < 1
D = abs(C .* bestX - X(i, :));
X(i, :) = bestX - A .* D;
else
randX = X(randi(pop), :);
D = abs(C .* randX - X(i, :));
X(i, :) = randX - A .* D;
end
else
b = 1;
l = -1 + 2 * rand(1, dim);
D = abs(bestX - X(i, :));
X(i, :) = D .* exp(b .* l) .* cos(2*pi*l) + bestX;
end
end这段代码对应三种行为:
- norm(A) < 1:向当前最优参数靠拢;
- norm(A) >= 1:随机选取个体进行探索;
- p >= 0.5:使用螺旋更新增强搜索路径。
WOA 最终输出的是 bestPosition,再通过参数映射函数转成 XGBoost 可用的结构体参数。
7.5 Transformer-Attention:从原始时序中提取深层特征
传统 XGBoost 依赖人工特征,而 Transformer-Attention 的作用是直接从三相电流序列里学习深层时序表示。它可以把不同时间片之间的关联建模出来,特别适合故障暂态不明显、扰动比较强的情况。
对应代码来自:
Matlab
layers = [
sequenceInputLayer(C, 'Name', 'input', 'Normalization', 'zscore')
fullyConnectedLayer(dModel, 'Name', 'input_projection')
selfAttentionLayer(modelCfg.transformer.numHeads, dModel, 'Name', 'self_attention')
layerNormalizationLayer('Name', 'attn_norm')
fullyConnectedLayer(modelCfg.transformer.ffnDim, 'Name', 'ffn_1')
reluLayer('Name', 'relu')
dropoutLayer(modelCfg.transformer.dropout, 'Name', 'dropout')
fullyConnectedLayer(modelCfg.transformer.featureDim, 'Name', 'feature_map')
globalAveragePooling1dLayer('Name', 'attention_pool')
fullyConnectedLayer(numClasses, 'Name', 'classifier')
softmaxLayer('Name', 'softmax')
classificationLayer('Name', 'output')];这段网络结构里,feature_map 层非常关键。它不仅用于分类,也作为后续特征融合的深层表示来源。也就是说,Transformer-Attention 在这个项目里不是单纯的分类器,而是一个深度特征提取器。
深度特征提取代码如下:
Matlab
function features = extract_deep_features(model, signals)
X = signals_to_cell(signals);
try
features = activations(model.net, X, 'feature_map', 'OutputAs', 'rows');
catch
[~, scores] = predict_deep_transformer(model, signals);
features = scores;
end
features = double(features);
if ndims(features) > 2
features = squeeze(mean(features, 2));
end
end这里的设计比较实用:如果能拿到 feature_map 激活,就用深层特征;如果环境或网络结构限制导致提取失败,就退回分类得分作为替代特征,保证主流程不中断。
八、项目价值与可扩展方向
这个项目真正有价值的地方,不在于"复现了一篇论文",而在于把论文思路变成了一个可运行、可对比、可扩展的工程。
更具体一点说,它至少往前走了三步:
- 从论文复现走向算法工程;
- 从传统集成学习走向深层时序建模;
- 从单模型性能优化走向模块化可复现实验框架。
后面还能继续扩展的方向也很明确:
- 接入真实 SCADA 数据;
- 做在线诊断和增量更新;
- 把分类模型部署到边缘端;
- 进一步引入多模态信号融合;
- 让 Attention 可视化服务于故障定位,而不只是展示。
九、总结
这篇项目最值得复盘的地方,不是"照着论文做了一遍",而是把论文里的思路真正落成了一个能跑、能改、能比较的 MATLAB 工程。基线部分,我复现了"小波分析 + IEDO-XGBoost";升级部分,我又把它推进到 Transformer-Attention-WOA-XGBoost。这样一来,项目就不只是一个结果,而是一条可以继续生长的技术路线。
需要源代码的,请联系作者;制作不易,请各位看官老爷点个赞和收藏!!!