🙋
我是 Luhui Dev,一个长期拆解 Agent 工程、探索 AI 教育落地的开发者。关注 Agent Harness、LLM 应用工程、AI for Math 与教育 SaaS 产品化实践。
前言
做 coding agent,选择的基座模型能力是一部分。现在真实落地的业务场景中,同样重要的还有模型外面那层 **harness **(prompt、tools、middleware、memory、执行环境、trace 和评测流程)。
AHE 这篇论文解决的正是这个问题:如何让 coding agent 的 harness 像软件工程一样,被持续观察、持续修改、持续评测、持续回滚,甚至自动迭代。
论文全名是 《Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses》,作者来自复旦大学、北京大学和上海奇绩智峰有限公司。高校研究团队提供方法设计,产业团队则有 Agent / LLM Infra / Nex AGI 相关系统背景。
更棒的是,AHE 有开源仓库:china-qijizhifeng/agentic-harness-engineering。
这让它不只是一个论文概念,你可以直接看到 seed coding agent、evolve agent、实验配置、trace、manifest、rollback 这些工程结构。对正在做 coding agent、agent infra 或者更广义 agent 产品的人来说,这个仓库非常值得拆解研究。
本文将围绕三个问题展开:AHE 为什么有效,它如何演化 harness,以及如何基于这个仓库开始一个自己的小实验。
一、先简单讲讲 Harness Engineering
Harness 可以理解成让模型真正工作起来的外部工程壳层。在 coding agent 里,它通常包括:
-
system prompt:规定 agent 的基本工作方式;
-
tools:文件读写、shell、搜索、测试运行、代码修改等工具;
-
tool descriptions:模型看到的工具说明和参数 schema;
-
middleware:工具调用前后的拦截、检查、修正和日志处理;
-
memory:短期记忆、长期记忆、经验沉淀;
-
context management:上下文压缩、裁剪和召回;
-
execution environment: sandbox、权限和运行隔离;
-
evaluation / observability:测试、trace、log、reward、失败报告和回归记录。
这套结构决定了模型如何接触任务、如何调用工具、如何处理失败、如何判断完成。
比如在实际业务中 shell 卡死,不一定要靠 prompt 反复提醒"不要交互式命令"。更稳的办法是 shell tool 加 timeout,middleware 识别高风险命令,输出层截断长日志,任务完成前强制检查状态。
这就是 Harness Engineering 的重点:把 agent 的能力放进一套可维护的运行系统里。
这里就不详细介绍 Harness 这个概念了,如果想继续了解这个方向,可以搜索这些关键词:Harness Engineering、Agent Harness、Agent Runtime、Tool-use Agent、Agent Observability、Agent Evaluation、Coding Agent Infrastructure.
让我们进入本文的重点。
二、AHE 的核心定位:让 Coding Agent 的 Harness 自迭代
AHE,全称 Agentic Harness Engineering。
论文标题中的关键词是:Observability-Driven Automatic Evolution of Coding-Agent Harnesses。
这句话可以拆成三层:
第一,AHE 面向的是 coding agent 的 harness。它不训练新模型,也不修改 base model 参数。
第二,它做的是 automatic evolution。目标不是人工调一次 prompt,而是在多轮运行中持续演化 harness。
第三,它依赖 observability。改动来自 trace、log、reward、失败分析、change manifest 等证据,不靠一句提示中的"自我反思"。
所以,AHE 的准确定位是:
一个面向 coding agent 的 harness 自动演化框架。它通过可观测的运行证据,持续改进 agent 外围的 prompt、tools、middleware、memory、skills 和 sub-agents.
这也是它和普通 prompt optimization 的关键差异。AHE 会修改 prompt,但 action space 更大。它把 tools、middleware、memory 这些执行结构也纳入演化范围。
三、AHE 的实验结果
AHE 的主实验在 Terminal-Bench 2 上进行。论文报告里,AHE 经过 10 轮迭代,把 seed harness 的 pass @1 从 69.7% 提升到 77.0%。这个结果说明,在目标 benchmark 上,AHE 找到了有效的 harness 改动。
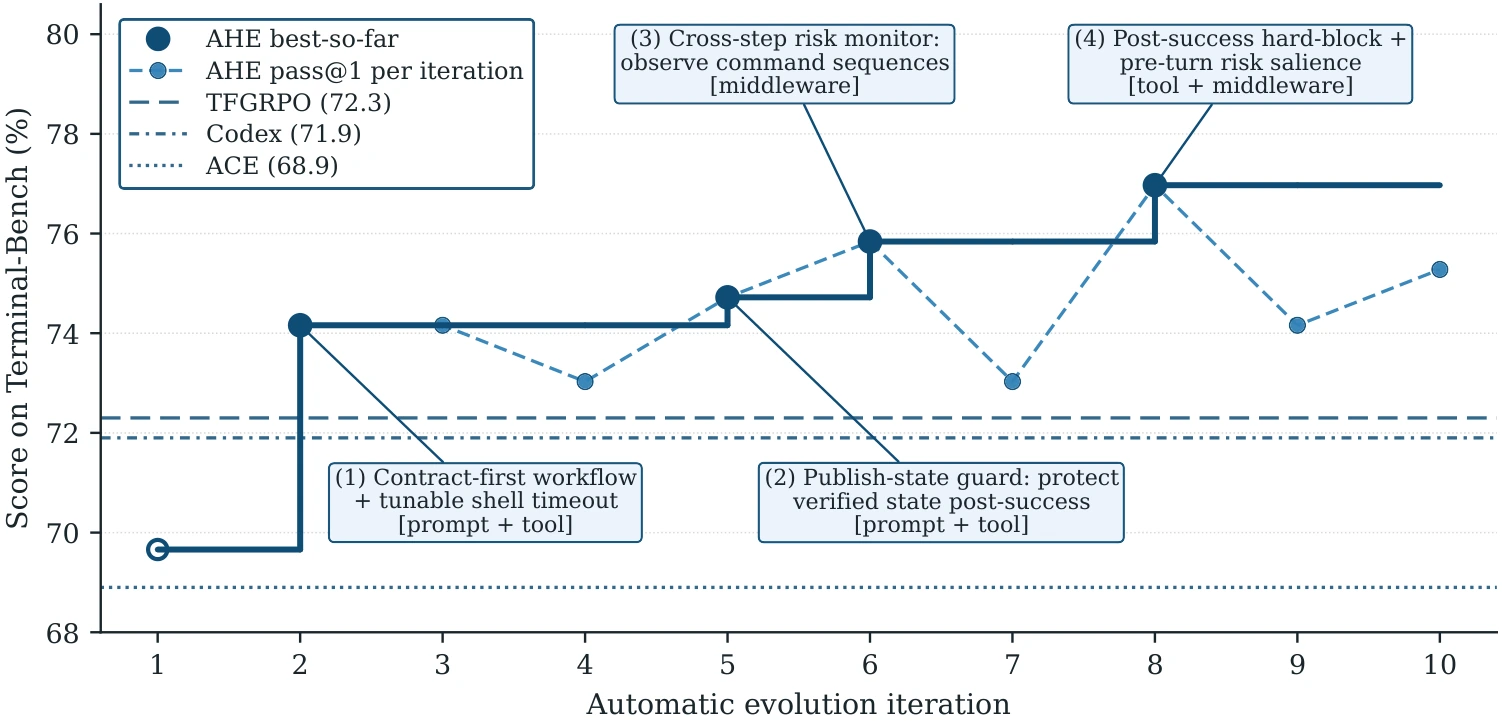
更值得看的是 ablation。论文把 full AHE 中不同组件单独替换回 seed harness,结果大致是:
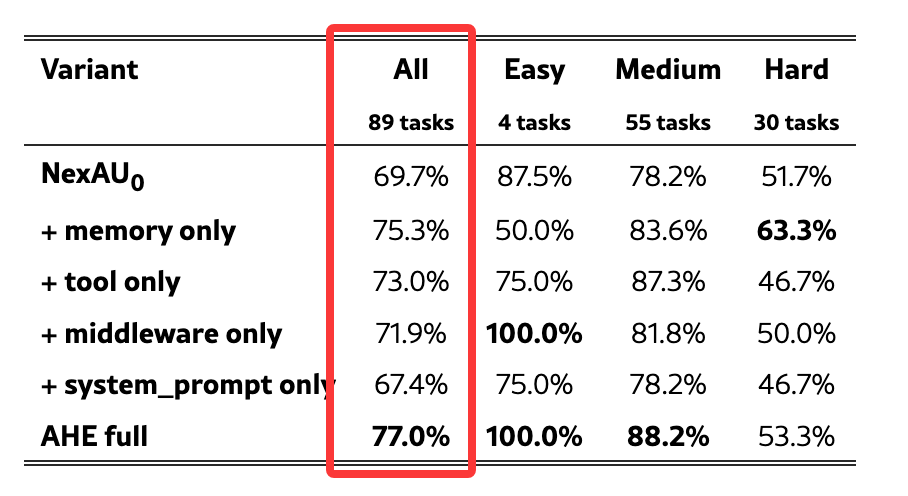
这个结果很有信息量。
如果收益主要来自更好的 system prompt,prompt-only 应该提升。但实验里 prompt-only 下降了,提升更明显的是 memory、tool 和 middleware。
这意味着 AHE 的关键收益来自结构性 harness 改动。也意味着从数据来看复杂任务里的 agent 失败,很多时候需要更硬(工程化)的机制:工具行为、运行时拦截、状态记录、长期经验、回归评测。
论文还做了迁移实验。演化后的 harness 迁移到 SWE-bench-verified 时,成功率提升很小,但 token 使用下降更明显。这说明 AHE 演化出的结构可能更擅长减少无效探索和上下文浪费。
跨模型迁移也值得注意。AHE 生成的 harness 放到多个 base model 上,论文报告都有正收益。这个结果说明,它学到的东西包含了一部分可迁移的工程结构。
我的判断是:AHE 对"哪些改动会修复问题"的预测明显好于随机,但对"哪些改动会导致退化"的预测还比较弱。它确实能证明 harness 可以被文件化、证据化、版本化地持续演化。
四、AHE 的关键流程:评测、诊断、修改、验证、回滚
AHE 的主流程:
当前 Harness
在 benchmark 上运行 Code Agent
收集 trace、log、reward
分析失败模式
让 Evolve Agent 修改 Harness 文件
写入 change_manifest
下一轮重新评测
验证修改是否有效,必要时回滚
这个闭环里有三个主要角色。
第一个是 Code Agent。
它是真正完成 coding task 的 agent,也是被优化的对象。在 AHE 仓库里,seed agent 很简单,基本是一个 bash-only coding agent。
第二个是 Agent Debugger。
它负责读取 Code Agent 的运行轨迹,把大量 trace 压缩成可读的失败报告。一个 benchmark 跑下来,原始 trace 可能非常长,直接交给模型读取成本太高。Agent Debugger 会把这些轨迹变成 overview 和 per-task analysis,让后续修改有证据可依。
第三个是 Evolve Agent。
它读取上一轮的运行结果、失败分析、历史修改记录,然后在 workspace 里修改 harness 文件。它能修改的对象包括 prompt、tools、middleware、memory、skills、sub-agent config 等。
AHE 给这个过程加了很强的工程约束:
每次修改必须落到文件。每次修改要写 manifest。下一轮要验证 manifest 里的预测。效果不好要能回滚。整个过程尽量留下可检查的证据链。
self-reflection agent 要求回答更具体的问题:改了哪个文件,为什么改,预计修哪些任务,可能伤害哪些任务,下一轮结果是否验证了这个判断。
五、AHE 把 Harness 拆成了哪些可演化组件
AHE 的第一步,是把 harness 拆成明确的组件。
论文中强调了几类可演化对象:
System Prompt:规定 Code Agent 的基本行为,比如非交互执行 shell、完成任务前检查状态、不要提前退出。
Tool Descriptions:模型看到的工具说明。工具本身可能没变,但工具说明变了,模型调用方式也会变。
Tool Implementations:工具的真实实现。比如 shell 工具如何执行命令,如何处理 timeout,如何截断输出,如何返回错误信息。
Middleware:运行时拦截层。它可以在工具调用前后做检查,比如识别危险命令、提醒任务未验证、阻止过早结束、记录风险状态。
Skills:可复用经验。可以理解为某些任务模式下的操作手册。
Sub-agents:子 agent 配置。复杂任务可以拆给不同角色处理。
Long-term Memory:长期记忆。用于跨任务、跨轮次沉淀经验。
这套拆分让 Evolve Agent 的 action space 更丰富。它可以根据失败证据选择合适的位置动手。
举个例子:Code Agent 总是在 shell 中卡死。最低效的处理方式是继续加 prompt 提醒。AHE 的路径更工程化:shell tool 加 timeout;middleware 检查明显交互式命令;返回信息里明确提示失败原因;system prompt 再补充行为约束。
这类结构性改动更稳定,也更容易被复用和回滚。
关键是搞清楚定位:prompt 是行为建议,tool、middleware、memory 是执行机制。
AHE 的价值就在于把这些执行机制也纳入演化范围。
六、三层可观测性:AHE 如何避免盲目搜索
只让一个 agent 随机改文件,再跑 benchmark,价值很有限。AHE 的核心设计是三层 observability。
1. Component Observability:组件可观测
组件可观测,指系统知道 harness 有哪些组成部分,也知道每一部分在哪里、怎么改、怎么注册。
在 AHE 仓库里,prompt、tool description、tool implementation、middleware、memory 等都以文件形式出现。新增工具要有 YAML 描述和 Python 实现,还要在配置里注册;新增 middleware 也要明确接入;新增 skill 或 sub-agent 同样要通过配置暴露。
2. Experience Observability:经验可观测
经验可观测,指 agent 运行之后,系统记录它是怎么成功、怎么失败的。
AHE 会收集每个任务的 trace、runtime log、reward 等信息。随后,Agent Debugger 会把这些原始轨迹压缩成分析报告。
一个 coding agent 失败时,单纯知道"失败了"没有太大用。真正需要定位的是失败层级:命令执行失败、依赖安装失败、测试没跑、文件路径错误、输出太长导致上下文污染、agent 提前判断任务完成、长任务中丢失前文状态。
AHE 通过 trace 和 analysis,把失败变成可以阅读、可以归纳、可以行动的证据。
3. Decision Observability:决策可观测
Evolve Agent 每次修改后,必须写一个 change_manifest.json。这个 manifest 会记录改了哪些文件、对应的失败模式是什么、为什么选择改这个组件、预计能修复哪些任务、可能会让哪些任务退化、修改的约束强度如何。
下一轮评测后,系统会对照这个 manifest,看预测是否兑现。
这一步让每次修改都变成一个可验证假设。哪怕不使用 AHE 的完整自动演化流程,只把 change manifest 这个习惯引入自己的 agent 团队,也会立刻提升工程透明度。
很多 agent 项目长期难以维护,根源就在这里:改了很多 prompt,调了很多工具,但没人知道每次改动到底解决了什么,也没人知道它有没有引入新问题。AHE 的 manifest 机制,至少让这个过程变得可审计。
七、从仓库看 AHE 的工程组织
AHE 仓库的主要入口是 evolve.py。它负责编排整个演化流程,包括初始化 workspace、运行评测、处理迭代目录、做归因、恢复和回滚。
被演化的 seed agent agents/code_agent_simple/,
里面包括:
code_agent.yaml 描述这个 agent 如何加载 prompt、使用哪些工具、用什么 tracer。
systemprompt.md 是初始系统提示词。
LongTermMEMORY.md 和 ShortTermMEMORY.md 分别对应长期和短期记忆界面。tool_descriptions/ 放工具说明,tools/ 放工具实现。
Evolve Agent agents/evolve_agent/,这里重点值得看的文件是:
evolve_agent.yaml 定义 Evolve Agent 自己可以使用哪些工具、middleware、skills.
evolve_prompt.md 一份演化契约:它规定 Evolve Agent 只能改 workspace,要基于证据修改,要写 summary 和 manifest,要遵守注册规则。
配置文件 configs/、configs/experiments/,其中 configs/base.yaml 是基础配置,configs/experiments/exp-simple-code-gpt54.yaml 是一个接近论文实验的配置 overlay。
启动脚本 scripts/,比如 scripts/evolve.sh 用来启动长时间实验,scripts/build_templates.py 用来为 E2B 构建任务模板。
如果只是想理解这个项目,不需要一开始就读所有文件。建议先按这个顺序看:
plaintext
README
↓
agents/code_agent_simple/code_agent.yaml
↓
agents/code_agent_simple/systemprompt.md
↓
agents/evolve_agent/evolve_prompt.md
↓
configs/base.yaml
↓
configs/experiments/exp-simple-code-gpt54.yaml
↓
evolve.py这个顺序能帮你先建立概念,再看执行细节。
八、如何上手这个仓库:先跑一个小尝试
AHE 不是轻量级 SDK。你不能期待 pip install 后立刻嵌进业务系统。
它更像一个研究型实验框架。完整跑论文级实验需要 LLM API、E2B sandbox、SERPER API、benchmark 数据、并发调度和不少 token 成本。
所以更现实的上手方式,是先跑一个最小闭环。
目标先设成:让 AHE 的核心链路跑起来。
也就是:
任务运行
trace 产生
analysis 生成
change_manifest 写入
下一轮重新评测
change_evaluation
判断改动效果
只要这条链路跑通,你就理解了 AHE 的实用价值。
1. 克隆仓库
官方仓库是:
plaintext
git clone https://github.com/china-qijizhifeng/agentic-harness-engineering.git
cd agentic-harness-engineering2. 安装依赖
项目使用 uv 管理 Python 依赖。
plaintext
uv sync3. 配置环境变量
复制环境变量模板:
plaintext
cp .env.example .env至少需要关注这些变量:
plaintext
LLM_API_KEY
LLM_BASE_URL
E2B_API_KEY
SERPER_API_KEY
GITHUB_TOKENAgent Debugger 也可以单独配置模型 endpoint。实际以 .env.example 为准。
这里要注意一点:AHE 的任务执行依赖 E2B sandbox。很多代码运行会在隔离的远程环境里完成。这对安全和复现有帮助,但也意味着你需要准备 E2B 账号和额度。
4. 准备 benchmark task templates
官方流程里,需要先构建任务模板。示例命令是:
plaintext
uv run python scripts/build_templates.py --dataset-dir /path/to/dataset -j 16这里的 /path/to/dataset 要换成自己的任务数据路径。
如果只是做小尝试,不建议一开始就准备完整 Terminal-Bench 2。先选几个任务,把流程跑通更重要。
5. 从小配置开始
论文实验配置可以参考:
plaintext
configs/experiments/exp-simple-code-gpt54.yaml直接跑完整配置成本比较高。可以复制一份小配置,例如:
plaintext
cp configs/experiments/exp-simple-code-gpt54.yaml configs/experiments/exp-mini.yaml然后把里面的参数调小:
plaintext
max_iterations: 2
harbor:
k: 2
n_concurrent: 4如果配置支持指定任务子集,可以只放 3 到 5 个任务。小实验的重点是验证流程,不是追求分数。
6. 启动演化实验
可以用脚本启动:
plaintext
./scripts/evolve.sh configs/experiments/exp-mini.yaml也可以直接看脚本内部如何调用 evolve.py,再按需手动启动。
完整实验可能会跑很久。小实验也要关注 API 成本、E2B 并发限制、网络稳定性。
7. 看实验产物,而不只看分数
跑完后,不要只看 pass rate。
更值得看的是这些产物:
plaintext
runs/iteration_*/
analysis/overview.md
analysis/detail/*.md
change_manifest.json
change_evaluation.json
agent/nexau_in_memory_tracer.cleaned.json
verifier/reward.txt跑起来后重点观察并回答几个问题:
-
这轮失败被归因成了什么模式?
-
Evolve Agent 改了哪些文件?
-
它为什么选择改这些文件?
-
manifest 里预测会修哪些任务?
-
下一轮有没有验证这个预测?
-
有没有出现修好一个任务、弄坏另一个任务的情况?
如果这些问题都能在产物里找到答案,说明 AHE 的核心闭环已经跑起来了。
九、AHE 还没有解决什么
AHE 很有价值,但边界也要说清楚。
第一,它仍然是研究型框架。完整运行成本不低,需要 benchmark、sandbox、LLM API 和较复杂的实验配置。
第二,论文中的有效性证据还需要更多重复实验。Terminal-Bench 2 上的提升很明确,但如果要作为强统计结论,还需要更多 seed、更多 campaign、更多置信区间报告。
第三,它对退化风险的预测还不够强。系统比较擅长解释这个修改可能修什么,但还不够擅长判断这个修改会伤害什么,这也是自动演化系统难的地方吧。
十、AHE 对 Agent 产品团队的启发
AHE 给产品型 agent 团队最大的启发,是把 agent 改进流程从"玄学调 prompt"拉回工程世界。
一个真实 agent 产品,迟早要面对这些问题:
-
用户报错后,如何复现?
-
失败原因如何聚合?
-
某次 prompt 修改到底有没有收益?
-
某个工具改动有没有让别的场景退化?
-
上线前有没有回归评测?
-
线上表现变差能不能回滚?
-
有效经验如何沉淀到 memory 或 skill?
这些问题都不是单个模型能替你解决的。
它们属于 harness engineering 的工作范围。
如果你也在做自己的 agent,这个仓库值得认真拆一遍。即使不完整运行它,也能学到很多关于 harness 组织、trace 设计、修改归因和回归验证的工程方法。
参考
-
Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses
-
AHE 官方代码仓库
GitHub: https://github.com/china-qijizhifeng/agentic-harness-engineering
-
Harness engineering: leveraging Codex in an agent-first world
OpenAI Engineering Blog: https://openai.com/index/harness-engineering/