作者:来自 Elastic Jeffrey Rengifo
学习如何通过将 BM25 词法搜索 与 Jina AI 向量嵌入 相结合,在 Elasticsearch 中衡量和提升搜索召回率,并使用 rank_eval API 用真实数值验证改进效果。
Elasticsearch 拥有丰富的新功能,帮助你为你的使用场景构建最佳搜索解决方案。学习如何在我们的动手实践网络研讨会中将它们付诸实践,构建现代 Search AI 体验。你也可以现在开始免费的云试用,或者在本地机器上尝试 Elastic。
使用 BM25 排序算法 的词法搜索成本低、速度快,并且对广泛的查询非常有效。但它有一个盲点:那些与你的文档不共享 token 的查询。在本文中,你将精确衡量 BM25 的不足之处。我们将使用 Elasticsearch 的排名评估 API( rank_eval ),并通过 Elastic Inference Service( EIS )引入 Jina AI 嵌入 来弥补这一差距。你将看到召回率评分从 0.43 提升到 0.75,并理解原因。
什么是召回率?
召回率 在 0 到 1 的范围内衡量用户实际想要的文档中,有多少出现在你的搜索结果中。如果一个查询应该返回三个产品,而你的搜索在前 10 个结果中只返回了其中两个,那么该查询的 recall@10 = 0.67。这是一个基于集合的指标:它不关心相关文档在这 k 个结果中的位置。位于第 10 位的相关文档与位于第 1 位的相关文档权重相同。拥有较高的召回率意味着你不会丢失相关结果。
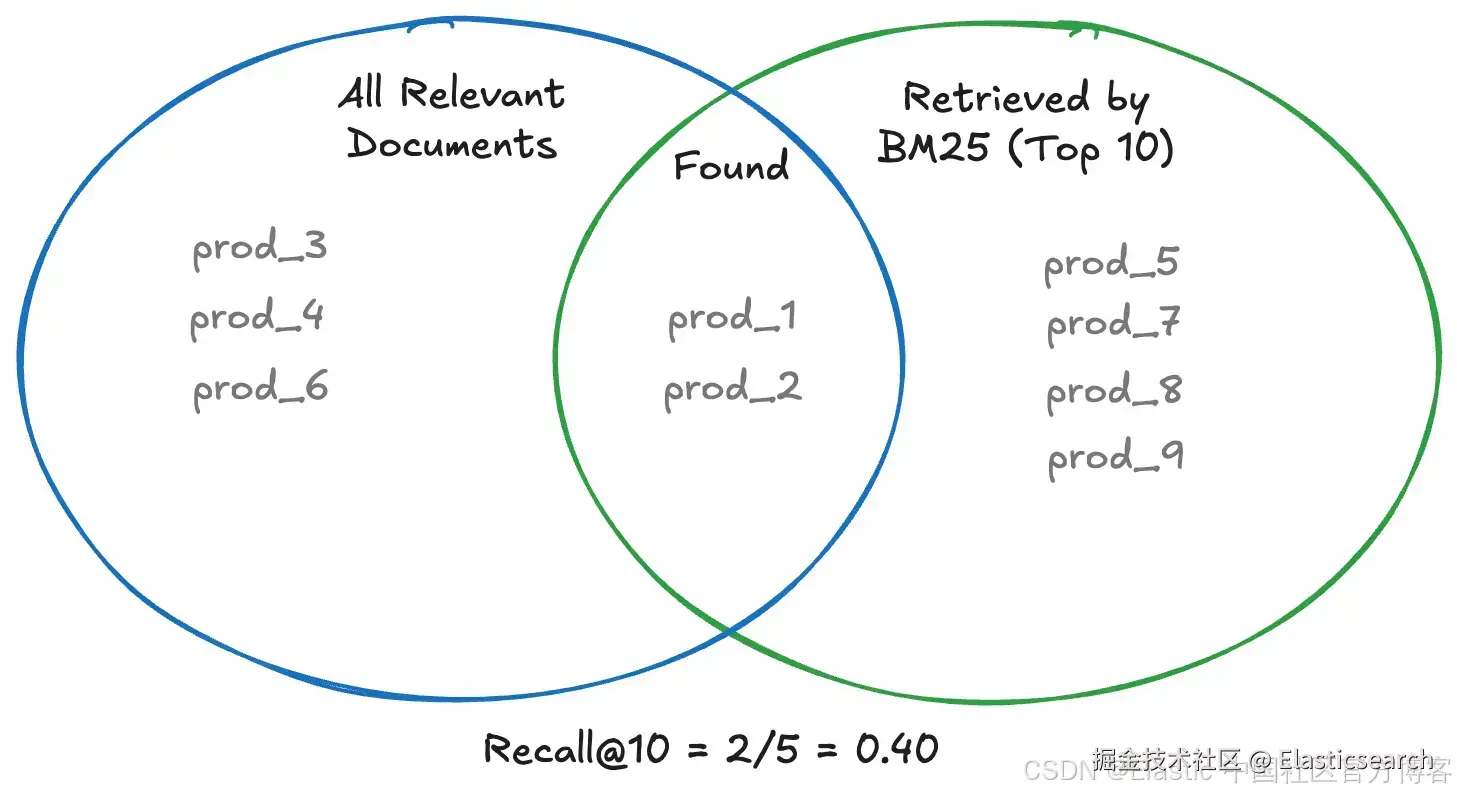
该图显示了两个集合:所有相关文档(左侧)以及 BM25 实际检索到的内容(前 10 个,右侧)。只有交集部分计入召回率,prod_1 和 prod_2 被找到,而 prod_3、prod_4 和 prod_6 完全未被检索到。结果: Recall@10 = 2/5 = 0.40。
前提条件
让我们开始动手,更好地理解召回率是如何工作的。本演示使用 Python。你可以在配套的 notebook( notebook.ipynb )中跟随操作,其中每个代码块都是一个可以直接运行的单元。
提供的代码使用以下环境:
- Elasticsearch 9.3+
- Python 3.10+
go
`pip install elasticsearch pandas plotly python-dotenv`AI写代码- 一个包含你的 Elasticsearch 凭证的 .env 文件
ini
`
1. ELASTICSEARCH_URL=https://your-cluster-url
2. ELASTICSEARCH_API_KEY=your-api-key
`AI写代码数据集
我们将使用一个包含 1000 个产品的产品目录,涵盖鞋类、电子产品、工具等多个类别。
每个文档包含四个字段:
| Field | Type |
|---|---|
| `title` | text |
| `description` | text |
| `brand` | keyword |
| `category` | keyword |
数据集从 dataset.csv 加载。
词法搜索的能力与局限
BM25 是 Elasticsearch 和大多数搜索引擎的默认排序算法。它根据查询词在文档中出现的频率进行评分,并结合文档长度以及这些词在整个索引中的出现频率进行调整。你还可以使用分析器:小写规范化、词干提取和停用词移除。对于查询 "running shoes",它会匹配 "Running Shoes",也很可能匹配 "run"。
这在大量查询场景中表现良好:
- "running shoes" 会立即匹配标题中包含这些精确 token 的产品。
- "bluetooth speaker" 会返回便携音频产品,因为这些 token 逐字出现。
结果是确定性且可解释的:一个文档排名靠前,是因为查询词出现在其中。调试相关性也很直接。
它的局限在哪里
现在让我们在相同的目录上尝试这些查询:
- "skincare routine":单词 "routine" 不会出现在任何产品标题中。BM25 可以对 "skincare" 进行部分匹配,但面部精华、身体油和保湿产品通常使用 "vitamin C"、"retinol" 或 "brightening" 等术语来描述,这些都与查询没有重叠。构成完整 护肤流程 的产品分散在整个索引中,没有共享的 token 来将它们关联起来。
yaml
`
1. ID: B06XX6DS3P, Score: 9.0552, Title: Replenix Retinol Smooth + Tighten Body Lotion - Collagen-Boosting, Regenerating Anti-Aging Body Cream, Reduces Appearance of Stretch Marks, 6.7 oz.
3. ID: B08XMPKJ1L, Score: 5.2699, Title: Bio-Oil Skincare Body Oil (Natural) Serum for Scars and Stretchmarks, Face and Body Moisturizer Hydrates Skin, with Organic Jojoba Oil and Vitamin E, For All Skin Types, 6.7 oz
5. ID: B01CY764KQ, Score: 5.0057, Title: Nike Up Or Down Men Deodorant - Pack of 2 | Long-Lasting Fragrance, Body Spray Combo for Men | Deodorant for Active Living | Nike Men's Deo Set | Ultimate Odor Protection | Grooming Essentials | Signature Nike Scent | High-Performance Men's Deodorant
`AI写代码- "pet travel accessories":这是一个用例级别的分组,而不是一个产品类别。狗背带、宠物汽车座椅以及旅行笼都相关,但它们的描述通常涉及便携性、安全性和舒适性,而不是"旅行配件"。BM25 会宽泛地匹配 "pet",但没有信号来区分哪些是与旅行相关的产品,而不是宠物目录中的其他商品。
yaml
`
1. ID: B0BVV7BKTW, Score: 7.4371, Title: Large Foldable Travel Duffel Bag with Shoes Compartment
3. ID: B07TNPHYNV, Score: 6.6455, Title: 40 Pieces Christmas Bronze Jingle Bells Craft Small Bells
5. ID: B08R8FRW53, Score: 6.6335, Title: CUBY Dog and Cat Sling Carrier
6. ID: B08QMCQYGM, Score: 6.5259, Title: YTFGGY Whiteboard Pinstripe Tape 6 Rolls 1/8"
7. ID: B0CP3LQSWM, Score: 6.2994, Title: Portable Dog Water Bottle 32 Oz
`AI写代码这是一个召回问题。相关文档确实存在于你的索引中,但 BM25 无法找到它们,因为用户的词语与文档中的词语匹配不够紧密。
添加同义词可以解决已知情况,但你无法穷举用户表达意图的所有方式。这正是向量(vectors)发挥作用的地方。
为什么你应该衡量召回率
在修复问题之前,你需要先量化它。
Recall@k 衡量的是:用户真正想要的文档中,有多少出现在你的搜索结果中。形式化定义如下:
ini
`Recall@k = (relevant documents found in top k) / (total relevant documents)`AI写代码Precision@k 衡量前 k 个结果中,有多少是真正相关的:
ini
`Precision@k = (relevant documents in top k) / k`AI写代码高精度意味着你返回的结果质量很高。在电商场景中,遗漏一个相关产品(低召回率)通常比展示一个略不完美的结果(较低精度)更糟,因为被隐藏的产品意味着一次潜在的销售流失。
Elasticsearch 的 rank_eval API 让你可以系统性地衡量这两者。你只需要提供一组查询,每个查询对应一组已评分的文档,Elasticsearch 就会自动帮你计算跨所有查询的指标。
设置评估
rank_eval API 需要一个评分数据集:将查询映射到每个查询的相关文档,并为其提供相关性等级(0 = 不相关,1 = 相关,2 = 高度相关)。
在 notebook 中,这对应 judgments 列表:
sql
`
1. judgments = [
2. # Query 1: "running shoes" BM25 handles well (tokens appear in product titles)
3. {"query_id": "q1", "doc_id": "B09NQJFRW6", "grade": 2, "query": "running shoes"},
4. {"query_id": "q1", "doc_id": "B08JMD4LMM", "grade": 2, "query": "running shoes"},
5. {"query_id": "q1", "doc_id": "B08VRJ6F2Q", "grade": 2, "query": "running shoes"},
6. {"query_id": "q1", "doc_id": "B07S8NRRWR", "grade": 2, "query": "running shoes"},
7. {"query_id": "q1", "doc_id": "B01HD620I8", "grade": 2, "query": "running shoes"},
8. {"query_id": "q1", "doc_id": "B07DX86321", "grade": 2, "query": "running shoes"},
9. {"query_id": "q1", "doc_id": "B0968YVLQ8", "grade": 1, "query": "running shoes"},
10. {"query_id": "q1", "doc_id": "B093QJ39ZS", "grade": 1, "query": "running shoes"},
11. {"query_id": "q1", "doc_id": "B096FGSC39", "grade": 1, "query": "running shoes"},
12. {"query_id": "q1", "doc_id": "B01GVQWVV2", "grade": 1, "query": "running shoes"},
14. # Query 2: "skincare routine" intent-based, "routine" never appears in product titles
15. {"query_id": "q2", "doc_id": "B08XMPKJ1L", "grade": 2, "query": "skincare routine"},
16. {"query_id": "q2", "doc_id": "B0BN3WQB92", "grade": 2, "query": "skincare routine"},
17. {"query_id": "q2", "doc_id": "B0BT7B7P5T", "grade": 2, "query": "skincare routine"},
18. {"query_id": "q2", "doc_id": "B00NPA2WEY", "grade": 2, "query": "skincare routine"},
19. {"query_id": "q2", "doc_id": "B06XX6DS3P", "grade": 1, "query": "skincare routine"},
20. {"query_id": "q2", "doc_id": "B07PDRD1KT", "grade": 1, "query": "skincare routine"},
21. {"query_id": "q2", "doc_id": "B074J7869B", "grade": 1, "query": "skincare routine"},
22. {"query_id": "q2", "doc_id": "B08JV31QW4", "grade": 1, "query": "skincare routine"},
23. {"query_id": "q2", "doc_id": "B00K3TVJMQ", "grade": 1, "query": "skincare routine"},
25. # Query 3: "study desk setup" intent-based, products are desks/stands/organizers
26. {"query_id": "q3", "doc_id": "B08CS35J2T", "grade": 2, "query": "study desk setup"},
27. {"query_id": "q3", "doc_id": "B09B3LFDXJ", "grade": 2, "query": "study desk setup"},
28. {"query_id": "q3", "doc_id": "B07W58LMND", "grade": 1, "query": "study desk setup"},
29. {"query_id": "q3", "doc_id": "B0CHYDX91L", "grade": 1, "query": "study desk setup"},
31. # Query 4: "pet travel accessories" use-case grouping, products are carriers/crates/seats
32. {"query_id": "q4", "doc_id": "B08R8FRW53", "grade": 2, "query": "pet travel accessories"},
33. {"query_id": "q4", "doc_id": "B01MYUYX33", "grade": 2, "query": "pet travel accessories"},
34. {"query_id": "q4", "doc_id": "B003C5RKE4", "grade": 2, "query": "pet travel accessories"},
35. {"query_id": "q4", "doc_id": "B09GF8GBF6", "grade": 1, "query": "pet travel accessories"},
36. {"query_id": "q4", "doc_id": "B0CP3LQSWM", "grade": 1, "query": "pet travel accessories"},
37. ]
`AI写代码这个组合是有意设计的:q1 是 BM25 表现良好的查询(产品标题中存在精确 token),而 q2、q3 和 q4 是基于意图的查询,用户的意图以概念形式表达,而不是具体的产品关键词。
衡量 BM25 基线召回率
首先,设置 Elasticsearch 客户端并索引原始文本数据:
python
`
1. import os
2. import json
3. import pandas as pd
4. import plotly.graph_objects as go
5. from elasticsearch import Elasticsearch, helpers
6. from dotenv import load_dotenv
8. load_dotenv()
10. es = Elasticsearch(
11. os.getenv("ELASTICSEARCH_URL"),
12. api_key=os.getenv("ELASTICSEARCH_API_KEY")
13. )
15. INDEX_NAME = "ecommerce-products"
`AI写代码现在构建 BM25 的 rank_eval 请求。列表中的每个请求都会将一个查询与其评分数据结合起来:
css
`
1. judgments_df = pd.DataFrame(judgments)
3. bm25_requests = []
4. for query_id, query_text in (
5. judgments_df[["query_id", "query"]].drop_duplicates().values
6. ):
7. relevant_docs = judgments_df[judgments_df["query_id"] == query_id]
8. ratings = [
9. {"_index": INDEX_NAME, "_id": row["doc_id"], "rating": row["grade"]}
10. for _, row in relevant_docs.iterrows()
11. ]
13. bm25_requests.append({
14. "id": query_id,
15. "request": {
16. "query": {
17. "multi_match": {
18. "query": query_text,
19. "fields": ["title", "description"]
20. }
21. }
22. },
23. "ratings": ratings,
24. })
26. bm25_eval = {
27. "requests": bm25_requests,
28. "metric": {"recall": {"k": 10, "relevant_rating_threshold": 1}},
29. }
31. bm25_result = es.rank_eval(index=INDEX_NAME, body=bm25_eval)
32. print("BM25 Recall@10:", bm25_result.body["metric_score"])
`AI写代码结果:
css
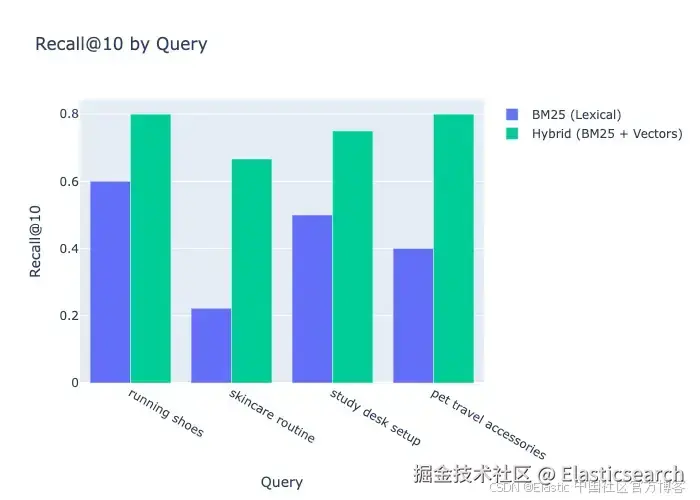
`BM25 Recall@10: 0.43`AI写代码0.43 表示在所有四个查询中,BM25 只找到了它本应找到的文档中的 43%。这个缺口主要集中在基于意图的查询上:"skincare routine" 会遗漏面部精华和身体油,因为 "routine" 从未出现在产品标题中;而 "pet travel accessories" 则会检索到一些无关的宠物产品,同时错过那些用便携性和安全性来描述的宠物背带和运输笼,而不是"旅行配件"这一词本身。
这就是我们的基线,现在我们有了一个需要超越的数值。
加入 Jina embeddings 的向量搜索
向量搜索 将文档和查询编码为高维向量 ------ 一种由数百或数千个数值组成的向量,每个数值都表示其所代表数据的某种特征。语义相近的文档会在向量空间中彼此靠近,即使它们没有共享任何词语。例如,"gym equipment"和"dumbbell set"会彼此接近,因为它们在概念上相关。我选择 Elasticsearch 作为向量数据库,因为它支持 混合搜索,可以同时提供语义理解和关键词精确匹配。
EIS(Elastic Inference Service)通过 inference API 原生支持嵌入模型。
步骤 1:将 Jina embeddings v5 作为推理端点使用
ini
`INFERENCE_ENDPOINT_ID = ".jina-embeddings-v5-text-small"`AI写代码如果你的集群具备 GPU 资源(在 Elastic Cloud 和 Elasticsearch 9.3+ 中可用),嵌入向量将在 GPU 上生成,这比 CPU 推理要快得多,并且消除了以往在大规模场景下向量计算成本过高的性能权衡。
为什么选择 Jina embeddings?jina-embeddings-v5-text 是一个多语言模型(支持 119+ 种语言),拥有 32,000 token 的上下文窗口,并支持面向特定任务的 LoRA(Low-Rank Adaptation)适配器。它在处理短产品描述时开箱即用效果很好。更多关于 jina-embeddings-v5-text 模型的信息可以在这里查看。
步骤 2:创建包含语义字段的索引
bash
`
1. index_mappings = {
2. "mappings": {
3. "properties": {
4. "title": {"type": "text", "copy_to": "semantic_field"},
5. "description": {"type": "text", "copy_to": "semantic_field"},
6. "brand": {"type": "keyword"},
7. "category": {"type": "keyword"},
8. "semantic_field": {
9. "type": "semantic_text",
10. "inference_id": INFERENCE_ENDPOINT_ID,
11. },
12. }
13. }
14. }
16. if not es.indices.exists(index=INDEX_NAME):
17. es.indices.create(index=INDEX_NAME, body=index_mappings)
18. print(f"Created index: {INDEX_NAME}")
`AI写代码semantic_text 字段类型 是这里的关键。它是对 dense_vector 的更高层抽象:你只需要将其指向一个 inference 端点,Elasticsearch 就会自动负责生成嵌入向量。
title 和 description 上的 copy_to 属性表示这两个字段的内容都会流入 semantic_field 用于生成 embedding,因此一个单一向量就可以捕获完整的产品表示。
步骤 3:索引产品
ini
`
1. def bulk_index(products, index_name):
2. actions = []
3. for product in products:
4. doc_id = product.get("_id")
5. source = {k: v for k, v in product.items() if k != "_id"}
6. action = {"_index": index_name, "_source": source}
7. if doc_id:
8. action["_id"] = doc_id
9. actions.append(action)
11. success, failed = helpers.bulk(es, actions, raise_on_error=False)
12. if failed:
13. for error in failed:
14. print(f"Error: {error}")
15. else:
16. print(f"Successfully indexed {success} documents")
18. bulk_index(products, INDEX_NAME)
`AI写代码在索引时,Elasticsearch 会为每个文档调用 inference 端点,并将生成的 embedding 存储在 semantic_field 中。你这边无需额外编写代码。
混合搜索:使用 RRF 结合 BM25 与向量
加入向量可以提升召回率,但如果只使用向量,又可能牺牲精确匹配查询的精度;例如 "running shoes" 仍然应该优先匹配字面一致的结果。混合搜索保留词法检索组件,正是为了维持这种精度。
使用 倒数排名融合(Reciprocal Rank Fusion, RRF) 的混合搜索可以兼顾两者优势:
- BM25 负责处理精确和近似精确的查询,保证高精度。
- 语义搜索 负责处理基于意图和多语言的查询,保证高召回率。
- RRF 将两个排序列表合并为一个统一排序结果。
RRF 公式会根据文档在每个结果列表中的排名为其分配一个分数:
ini
`score = sum(1 / (rank_constant + rank))`AI写代码在两个列表中排名都靠前的文档会获得更高的综合分数。rank_constant 用于控制低排名文档所获得的权重大小。
bash
`
1. hybrid_requests = []
3. for query_id, query_text in (
4. judgments_df[["query_id", "query"]].drop_duplicates().values
5. ):
6. relevant_docs = judgments_df[judgments_df["query_id"] == query_id]
7. ratings = [
8. {"_index": INDEX_NAME, "_id": row["doc_id"], "rating": row["grade"]}
9. for _, row in relevant_docs.iterrows()
10. ]
12. hybrid_requests.append({
13. "id": query_id,
14. "request": {
15. "retriever": {
16. "rrf": {
17. "retrievers": [
18. {
19. "standard": {
20. "query": {
21. "multi_match": {
22. "query": query_text,
23. "fields": ["title", "description"],
24. }
25. }
26. }
27. },
28. {
29. "standard": {
30. "query": {
31. "match": {
32. "semantic_field": {"query": query_text}
33. }
34. }
35. }
36. },
37. ],
38. "rank_window_size": 50,
39. "rank_constant": 5,
40. }
41. }
42. },
43. "ratings": ratings,
44. })
46. hybrid_eval = {
47. "requests": hybrid_requests,
48. "metric": {"recall": {"k": 10, "relevant_rating_threshold": 1}},
49. }
51. hybrid_result = es.rank_eval(index=INDEX_NAME, body=hybrid_eval)
52. print("Hybrid Recall@10:", hybrid_result.body["metric_score"])
`AI写代码收起代码块结果:
css
`Hybrid Recall@10: 0.75`AI写代码混合搜索在 BM25(0.43)的基础上有显著提升,并且在"running shoes"等精确匹配查询上保持了精度。
结果:前后对比
以下是三种方法的完整对比:
ini
`
1. methods = {
2. "BM25 (Lexical)": bm25_requests,
3. "Hybrid (BM25 + Vectors)": hybrid_requests,
4. }
6. recall_metric = {"recall": {"k": 10, "relevant_rating_threshold": 1}}
8. comparison_data = []
9. for method_name, requests in methods.items():
10. result = es.rank_eval(
11. index=INDEX_NAME,
12. body={"requests": requests, "metric": recall_metric}
13. )
14. comparison_data.append({
15. "method": method_name,
16. "recall@10": result.body["metric_score"]
17. })
19. comparison_df = pd.DataFrame(comparison_data)
20. print(comparison_df.to_string(index=False))
`AI写代码结果:
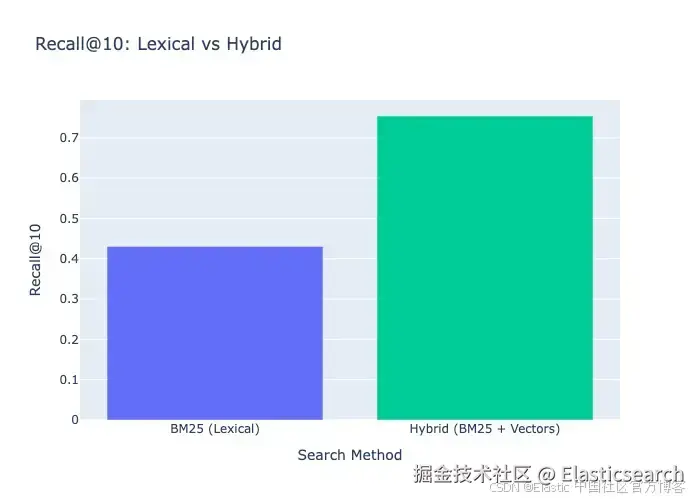
| 方法 | Recall@10 |
|---|---|
| BM25(词法) | 0.43 |
| 混合搜索(BM25 + 向量) | 0.75 |
按查询拆解:
结论
在整篇文章中,我们看到 BM25 词法搜索 在用户输入精确查询时是可靠的,但当用户基于意图而不是关键词进行搜索时,它的召回率会下降。通过 rank_eval,我们建立了一个可复现的基线,用真实数值来衡量这个差距。在此基础上,我们引入了由 Jina embeddings 驱动的 semantic_text 字段,并重新进行了评估。结果是:混合搜索 将召回率从 0.43 提升到 0.75,同时在精确匹配查询上保持了精度,不过实际提升幅度会取决于你的查询分布。
这个模式可以扩展到更广泛的场景:收集来自真实用户查询的 judgments,运行 rank_eval 作为基线,加入 semantic_text,然后再次测量。你将能够清楚地知道哪些地方得到了改进,以及改进了多少。
下一步
- 深入了解召回率与向量搜索:Recall 和向量搜索量化(Jeff Vestal)
- 添加 reranking 以进一步提升顶部结果的精度
- 探索 Elasticsearch 混合搜索文档
- 阅读更多关于 rank_eval API 的内容
这篇内容对你有帮助吗?