篇幅所限,本文只提供部分资料内容,完整资料请看下面链接
https://download.csdn.net/download/2501_92808859/92683933
资料解读:《工业大数据采集处理与应用》
详细资料请看本解读文章的最后内容
作为工业大数据领域的专业研究者,我有幸系统研读了《工业大数据采集处理与应用》这份重要文档。该文献全面系统地阐述了工业大数据的理论体系和技术实践,从基本概念到实际应用,构建了完整的知识框架,为工业企业推进数字化转型提供了重要参考。
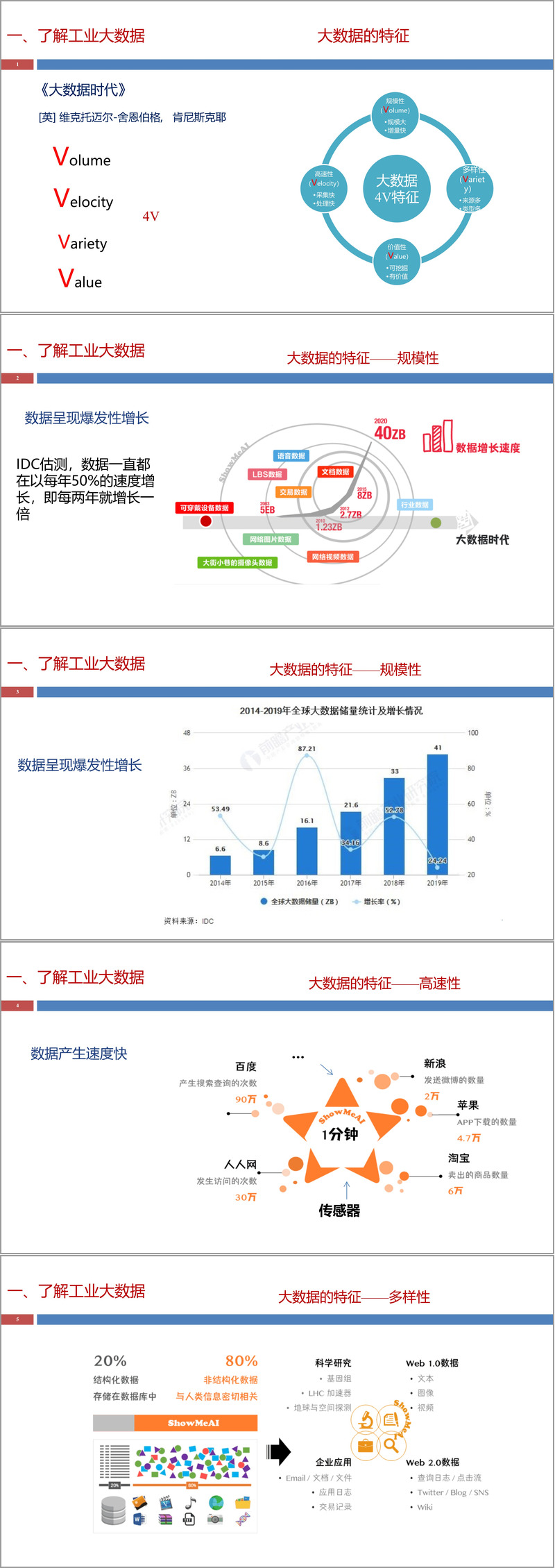
在开篇章节中,文献首先明确了工业大数据的基本概念和特征。工业大数据不仅具备传统大数据的4V特征------规模性、高速性、多样性和价值性,还具有时序性、实时性、高通量、高纬度、多尺度和高噪性等工业领域特有属性。这些特性决定了工业大数据处理需要采用与传统数据处理不同的技术路径和方法论。
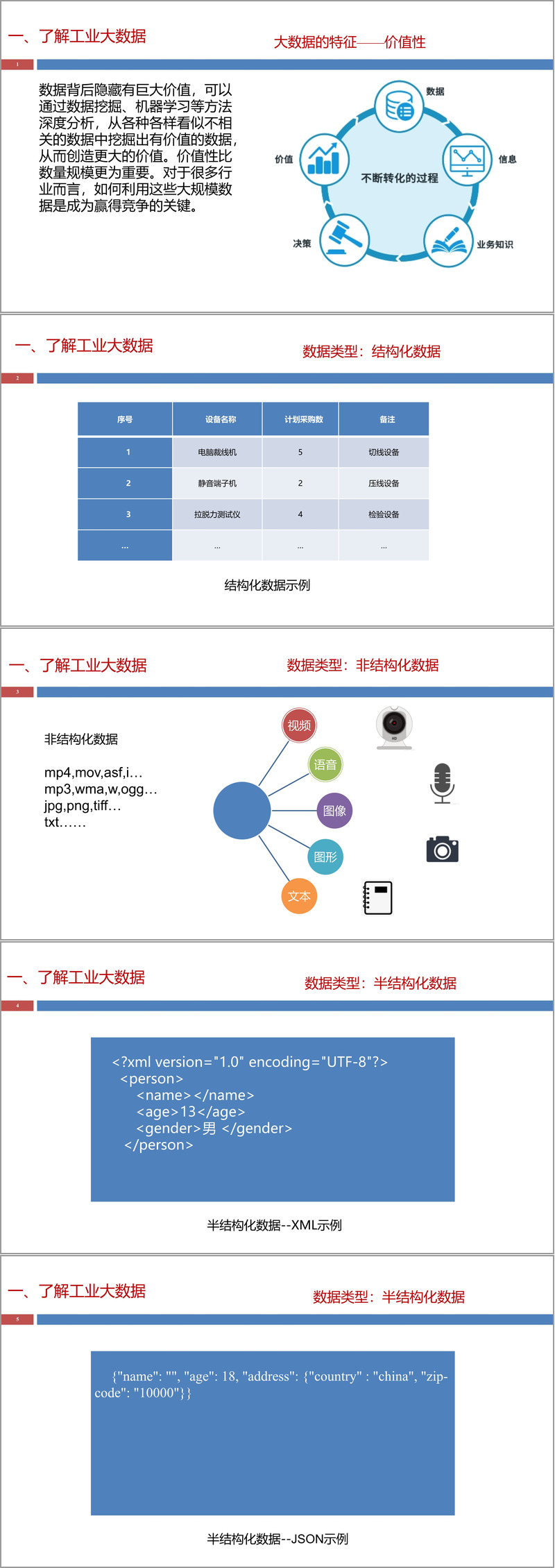
文献深入分析了工业大数据的主要来源,包括企业信息化系统数据、工业互联网设备数据和外部环境数据三大类别。其中,企业信息化数据涵盖产品数据管理、制造执行系统、企业资源计划等核心业务系统;工业互联网数据主要来自传感器、控制器、智能终端等现场设备;外部数据则包括市场信息、行业动态、环境因素等。这种多源异构的数据特征对数据采集技术提出了更高要求。
在技术架构方面,文献提出了完整的工业大数据平台体系,包括数据采集层、存储层、处理层和应用层。其中,分布式计算框架Hadoop和分布式文件系统HDFS构成了平台的技术基础,能够有效应对工业场景下的海量数据处理需求。文献特别强调了批量计算和流式计算两种模式在工业场景中的不同适用性,为实际应用提供了明确的技术选型指导。
数据采集作为工业大数据处理的首要环节,文献进行了详细阐述。从现场总线网络到工业以太网,从OPC UA协议到MQTT协议,文献系统梳理了工业现场的主流通信技术和标准。特别值得关注的是,文献详细介绍了PLC和PTL等工业控制设备的数据采集方法,包括数字量和模拟量信号的采集处理,为实际工程实施提供了具体的技术方案。
在数据预处理环节,文献重点介绍了ETL工具Kettle的应用方法。从数据抽取、转换到加载,形成了完整的数据处理流程。同时,文献还详细阐述了数据仓库工具Hive的使用,包括数据库创建、表结构设计、数据加载和查询分析等核心操作,为工业数据的规范化管理提供了实用指南。
数据建模部分,文献引入统一建模语言UML进行信息模型构建,通过类图详细描述了设备信息模型和生产过程信息模型的建立方法。这种基于面向对象思想的建模方法,能够有效支持复杂工业系统的数字化表达,为后续数据分析奠定基础。
在数据分析章节,文献系统介绍了回归分析、分类预测等机器学习算法在工业场景中的应用。通过具体案例,展示了如何利用Weka等工具进行设备状态预测、质量分析等实际应用。文献特别强调了模型评估的重要性,提供了相关系数、准确率、召回率等多种评估指标的选择指南。
数据可视化部分,文献介绍了IoTHub和Grafana两种主流工具的应用方法。通过仪表盘、趋势图、拓扑图等多种可视化形式,实现工业数据的直观展示。文献指出,有效的可视化设计能够帮助管理人员快速把握生产运行状态,支持决策优化。
在应用实践方面,文献以设备预测性维护为典型案例,详细阐述了数据驱动的设备健康状态评估方法。通过健康指数计算和等级划分,建立了科学的设备状态评价体系。此外,文献还介绍了质量检测和工艺优化的应用场景,展示了大数据技术在提升产品质量、优化生产流程方面的价值。
整体而言,这份文献构建了从数据采集、处理、分析到应用的完整技术体系,既包含理论基础,又注重实践指导。其内容涵盖工业大数据的全生命周期管理,为工业企业推进数字化转型提供了系统性的解决方案。特别是在技术选型、实施方法和应用场景方面,文献提供了大量实用性强、可操作性高的具体指导,具有重要的参考价值。
随着工业互联网的快速发展,大数据技术必将在工业领域发挥越来越重要的作用。这份文献所阐述的技术体系和方法论,将为推动工业企业智能化转型提供有力的理论支撑和实践指南。
接下来请您阅读下面的详细资料吧。