导读:代码审查(Code Review)是团队协作的硬骨头------耗时长、对审查人能力要求高、容易流于形式。本文带你用 DeepSeek V4 API 从零搭建一个智能代码审查 Agent,支持本地部署、批量审查、自定义规则集,文末有完整源码和部署方案。
一、为什么选 DeepSeek V4?
先交代背景。团队日常开发中,PR 审查一直是瓶颈:
- 资深工程师每天至少 1-2 小时耗在 CR 上
- 初级工程师审查质量参差不齐,漏掉关键问题
- 审查意见风格不统一,有时过于严苛,有时形同虚设
用过 GitHub Copilot Code Review、CodeRabbit 等工具,要么价格不菲,要么无法定制审查规则。DeepSeek V4 发布后,我注意到它在代码理解和长文本推理上的显著提升,加上 API 价格极为友好,决定试试用它做代码审查。
| 模型版本 | 输入价格 (缓存未命中) | 输入价格 (缓存命中) | 输出价格 | 上下文窗口 | 核心优势 |
|---|---|---|---|---|---|
| DeepSeek-V4-Pro (旗舰版) | 3元 / 1M (原价12元,现价2.5折) | 0.025元 / 1M | 6元 / 1M (原价24元,现价2.5折) | 1M | 智力最高。适合复杂推理、代码生成。目前价格仅为原价的1/4。 |
| DeepSeek-V4-Flash (极速版) | 1元 / 1M | 0.02元 / 1M | 2元 / 1M | 1M | 性价比之王。适合高频对话、摘要提取,速度极快且便宜。 |
| GPT-4o (OpenAI) | ~36元 ($5) / 1M | 通常无此优惠 | ~108元 ($15) / 1M | 128K | 行业标杆。价格约为 DeepSeek V4-Pro 的 12倍,V4-Flash 的 36倍。 |
二、Agent 架构设计
我们的目标是:提交一段代码 → Agent 按自定义规则审查 → 输出结构化的审查报告。不只是一个 Chat 包装,而是一个能串联上下文、支持规则配置的完整 Agent。
2.1 整体架构
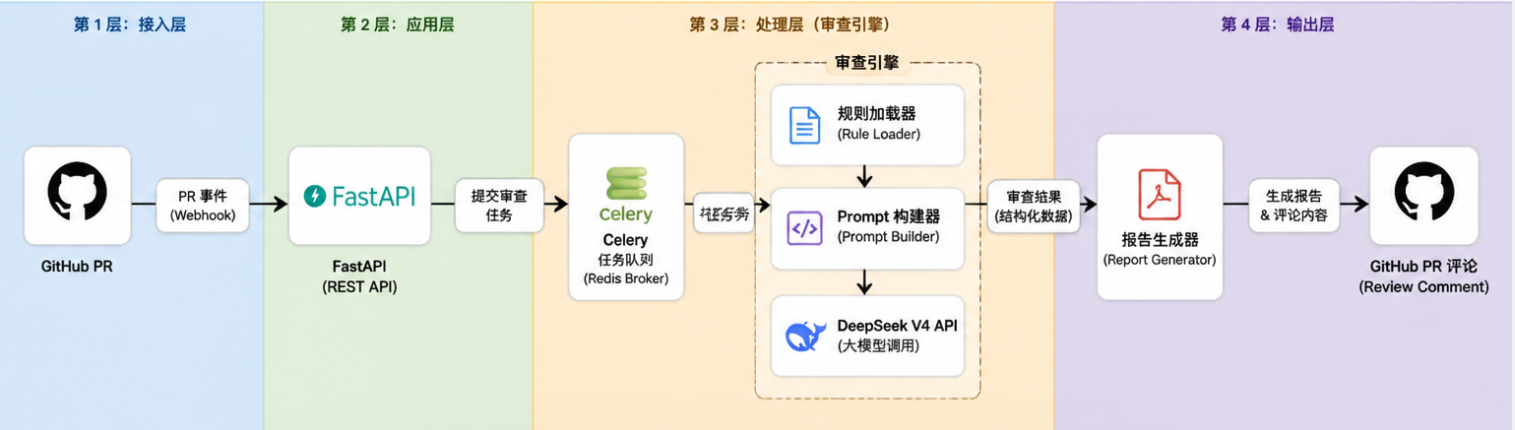
整个系统分为四层:
| 层级 | 职责 | 技术选型 |
|---|---|---|
| 接入层 | 接收代码提交、Webhook 触发 | FastAPI + GitHub Webhook |
| 调度层 | 任务队列、并发控制、结果缓存 | Celery + Redis |
| 审查引擎 | 规则解析、Prompt 组装、API 调用 | DeepSeek V4 API + LangChain |
| 输出层 | 报告生成、PR 评论推送、数据统计 | Jinja2 模板 + GitHub API |
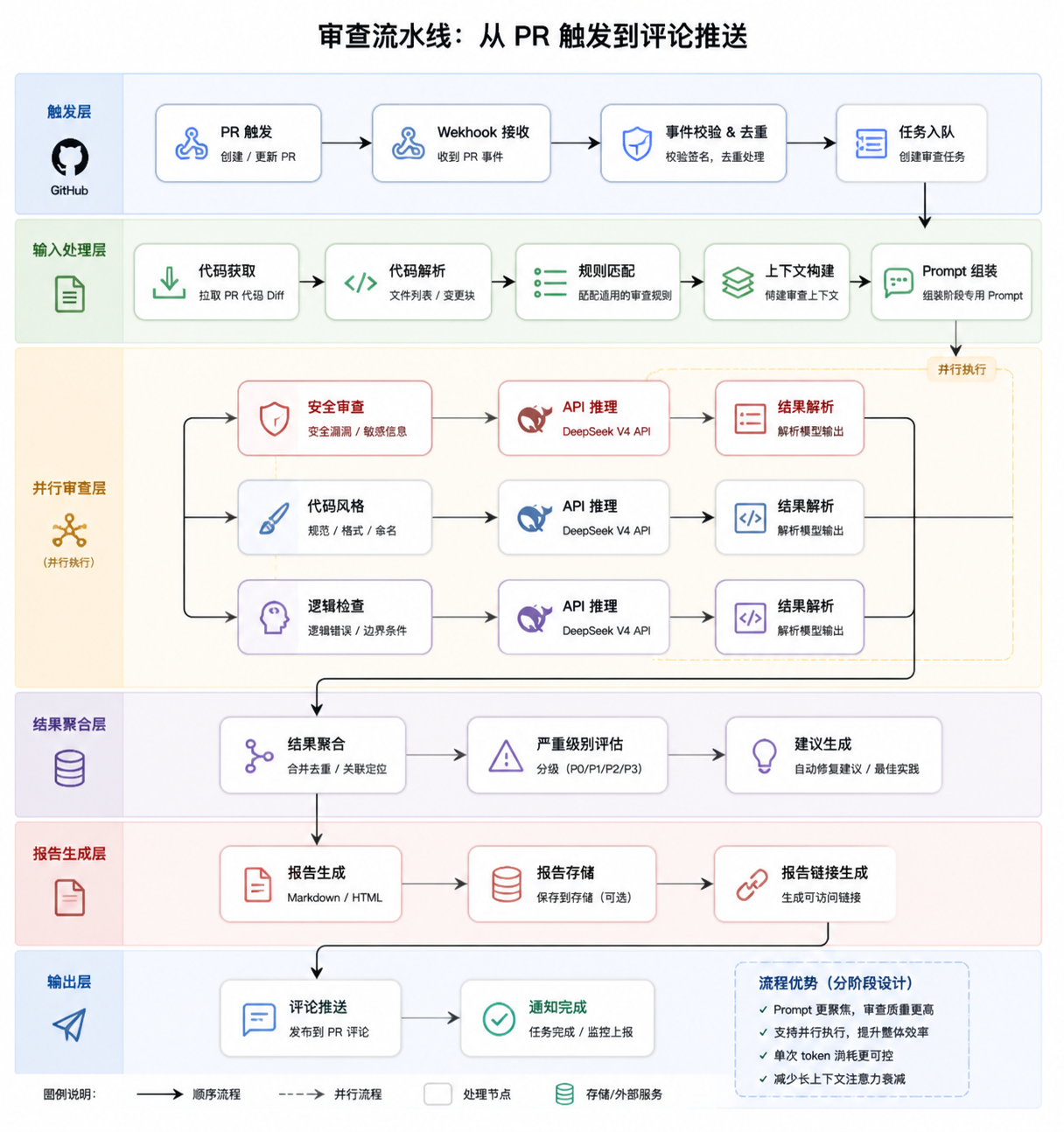
2.2 审查流水线
单次审查的核心流程:
代码输入 → 规则匹配 → 上下文构建 → Prompt 组装 → API 推理 → 结果解析 → 报告输出这里有个关键设计:不是一次 API 调用完成所有审查,而是分阶段进行。这样做的好处是:
- 每个阶段的 Prompt 更聚焦,审查质量更高
- 部分阶段可以并行执行(安全检查可以和风格检查同时跑)
- 单次 token 消耗更可控,减少长上下文带来的注意力衰减
三、核心实现
3.1 Prompt 设计------拉开质量差距的关键
很多人用大模型做 CR 效果不好,根因在于 Prompt 太笼统。我的做法是 "角色 + 规则 + 示例 + 约束" 四段式 Prompt,实测在 DeepSeek V4 上效果拔群:
SYSTEM_PROMPT = """你是一位资深代码审查专家,拥有 10 年以上全栈开发经验。
你的审查风格:严格但建设性,指出问题的同时给出改进建议。
## 审查规则
你需要从以下维度逐项审查代码,不可跳过任何维度:
1. **安全漏洞**(高优先级):
- SQL 注入、XSS、命令注入
- 敏感信息硬编码(密钥、Token、密码)
- 权限校验缺失、越权风险
- 依赖库已知漏洞(CVE)
2. **逻辑错误**(高优先级):
- 空指针/None 引用风险
- 边界条件处理缺失
- 并发安全(竞态条件、死锁)
- 事务边界不合理
3. **代码规范**(中优先级):
- 命名是否表意清晰
- 函数是否过长(> 50 行)
- 是否有未处理的异常
- 是否有冗余代码或重复逻辑
4. **性能问题**(中优先级):
- 不必要的数据库循环查询(N+1)
- 大对象未释放
- 缓存策略缺失
- 算法复杂度不合理
5. **可维护性**(低优先级):
- 关键逻辑是否有注释
- 接口设计是否符合开闭原则
- 测试覆盖是否充分
## 输出格式
你必须严格按照以下 JSON 格式输出审查结果:
```json
{
"summary": {
"total_issues": 0,
"high": 0,
"medium": 0,
"low": 0,
"overall_score": 0
},
"issues": [
{
"severity": "high|medium|low",
"category": "security|logic|style|performance|maintainability",
"file": "文件路径",
"line": 行号,
"title": "问题简述",
"description": "详细说明",
"suggestion": "修改建议(含代码示例)"
}
],
"highlights": ["值得肯定的地方"]
}
## 重要约束
- 不要重复指出同一类问题
- 如果代码没有问题,issues 数组为空,不要强行挑刺
- 建议中必须包含可执行的代码示例
- 仅输出 JSON,不要输出任何其他内容
"""
3.2 上下文构建------让模型"看懂"代码
审查单文件还行,但真实 PR 往往涉及多文件修改。直接全部丢给 API 会超出上下文窗口,需要做上下文裁剪。我实现了一个简单的依赖图分析器:
import ast
import os
from typing import Set, List
class ContextBuilder:
"""基于 AST 的代码上下文构建器"""
def __init__(self, repo_root: str, max_context_tokens: int = 60000):
self.repo_root = repo_root
self.max_tokens = max_context_tokens
def build_context(self, changed_files: List[str]) -> str:
"""为变更文件构建精简的审查上下文"""
imports_map = {}
context_files: Set[str] = set()
# 第一步:解析变更文件的 import 关系
for file_path in changed_files:
imports = self._extract_local_imports(file_path)
imports_map[file_path] = imports
context_files.update(imports)
# 第二步:按优先级打包上下文
# 优先级:变更文件(完整)> 直接依赖(类/函数签名)> 间接依赖(只有接口)
context_parts = []
# 变更文件------完整内容
for f in changed_files:
content = self._read_file(f)
context_parts.append(f"// ===== {f} (CHANGED) =====\n{content}")
# 直接依赖------只取公开接口
for f in context_files:
if f not in changed_files:
interface = self._extract_public_interface(f)
context_parts.append(
f"// ===== {f} (IMPORTED, interface only) =====\n{interface}"
)
full_context = "\n\n".join(context_parts)
# 如果还是超了,按 token 数裁剪
if self._estimate_tokens(full_context) > self.max_tokens:
full_context = self._trim_context(context_parts)
return full_context
def _extract_local_imports(self, file_path: str) -> Set[str]:
"""从 Python 文件中提取本地项目导入"""
imports = set()
try:
with open(file_path, "r", encoding="utf-8") as f:
source = f.read()
tree = ast.parse(source)
for node in ast.walk(tree):
if isinstance(node, ast.Import):
for alias in node.names:
imports.add(alias.name)
elif isinstance(node, ast.ImportFrom):
if node.module and not node.module.startswith(("std.", "lib.")):
# 解析为实际文件路径
resolved = self._resolve_module_path(node.module)
if resolved:
imports.add(resolved)
except Exception:
pass
return imports
def _extract_public_interface(self, file_path: str) -> str:
"""提取文件的公开接口(函数签名、类定义)"""
try:
with open(file_path, "r", encoding="utf-8") as f:
source = f.read()
tree = ast.parse(source)
lines = source.split("\n")
interface_lines = []
for node in ast.iter_child_nodes(tree):
if isinstance(node, ast.FunctionDef):
if not node.name.startswith("_"): # 公开函数
line_num = node.lineno
# 取函数签名行 + 文档字符串
signature_end = node.body[0].lineno + 2 \
if (isinstance(node.body[0], ast.Expr) and
isinstance(node.body[0].value, ast.Constant))
else line_num + 1
interface_lines.extend(lines[line_num-1:signature_end])
interface_lines.append(" ...\n")
elif isinstance(node, ast.ClassDef):
line_num = node.lineno
interface_lines.append(lines[line_num-1])
interface_lines.append(" ...\n")
except Exception:
return f"# Failed to parse {file_path}"
return "\n".join(interface_lines)
def _estimate_tokens(self, text: str) -> int:
"""粗略估算 token 数(中文约 1.5 字/token,英文约 4 字/token)"""
return len(text) // 3 # 保守估计
def _trim_context(self, parts: List[str]) -> str:
"""按优先级裁剪上下文"""
# 变更文件保留完整,依赖文件只保留签名
result = []
token_budget = self.max_tokens
for part in parts:
part_tokens = self._estimate_tokens(part)
if part_tokens <= token_budget:
result.append(part)
token_budget -= part_tokens
else:
# 裁剪到剩余预算
chars = token_budget * 3
result.append(part[:chars] + "\n// ... (truncated)")
break
return "\n\n".join(result)
def _read_file(self, path: str) -> str:
full_path = os.path.join(self.repo_root, path)
with open(full_path, "r", encoding="utf-8") as f:
return f.read()
def _resolve_module_path(self, module: str) -> str | None:
parts = module.split(".")
candidates = [
os.path.join(*parts) + ".py",
os.path.join(*parts, "__init__.py"),
]
for c in candidates:
if os.path.exists(os.path.join(self.repo_root, c)):
return c
return None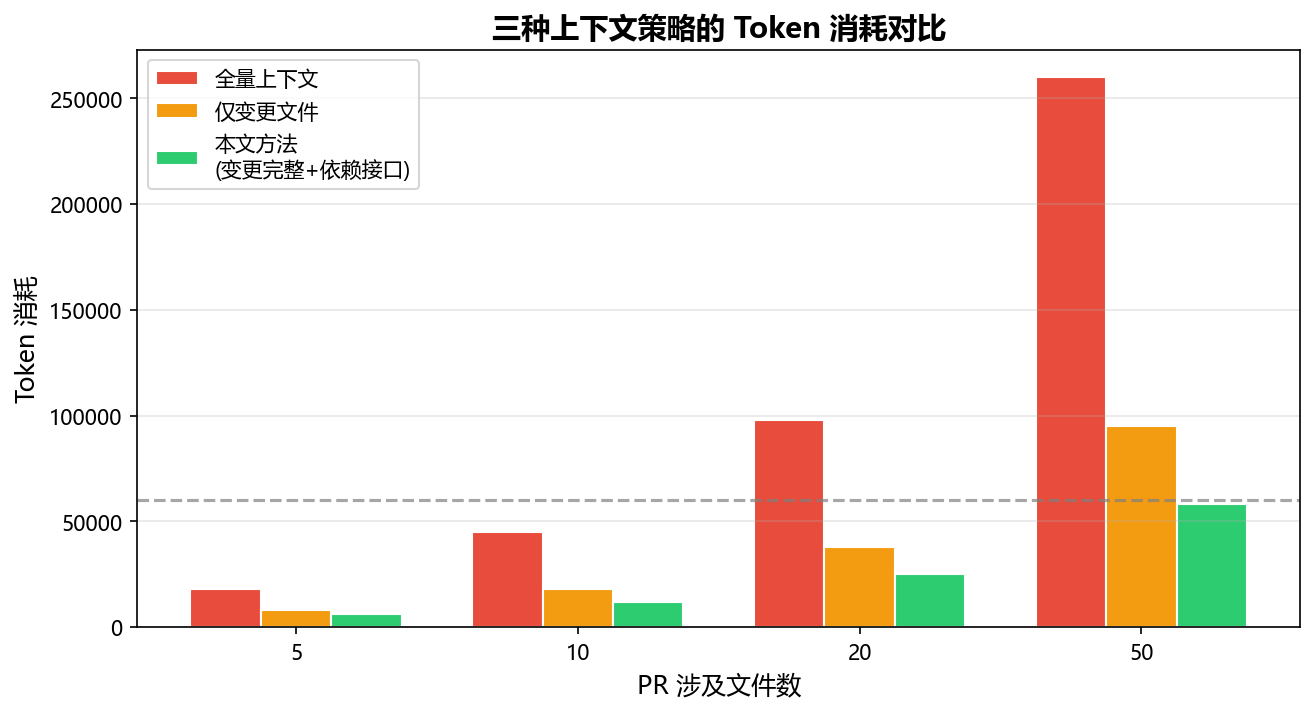
3.3 审查引擎------核心调度
import asyncio
import json
from dataclasses import dataclass
from openai import AsyncOpenAI
@dataclass
class ReviewResult:
file_path: str
summary: dict
issues: list[dict]
highlights: list[str]
raw_tokens: int
class DeepSeekReviewer:
"""基于 DeepSeek V4 的代码审查引擎"""
def __init__(self, api_key: str, base_url: str = "https://api.deepseek.com"):
self.client = AsyncOpenAI(
api_key=api_key,
base_url=base_url
)
self.context_builder = ContextBuilder(repo_root=".")
async def review_pr(self, changed_files: list[str]) -> list[ReviewResult]:
"""审查整个 PR 的所有变更文件"""
context = self.context_builder.build_context(changed_files)
tasks = [self._review_single_file(f, context) for f in changed_files]
results = await asyncio.gather(*tasks, return_exceptions=True)
final_results = []
for f, result in zip(changed_files, results):
if isinstance(result, Exception):
final_results.append(ReviewResult(
file_path=f,
summary={"error": str(result)},
issues=[],
highlights=[],
raw_tokens=0
))
else:
final_results.append(result)
return final_results
async def _review_single_file(
self, file_path: str, context: str
) -> ReviewResult:
"""审查单个文件,带重试机制"""
file_content = self._read_file(file_path)
user_prompt = f"""## 上下文信息
{context}
## 待审查文件:{file_path}
```python
{file_content}
```
请按照审查规则逐项审查以上代码,输出 JSON 格式的审查报告。
"""
max_retries = 3
for attempt in range(max_retries):
try:
response = await self.client.chat.completions.create(
model="deepseek-chat", # DeepSeek V4
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_prompt}
],
temperature=0.1,
max_tokens=4096,
response_format={"type": "json_object"}
)
content = response.choices[0].message.content
review_data = json.loads(content)
tokens = response.usage.total_tokens
return ReviewResult(
file_path=file_path,
summary=review_data.get("summary", {}),
issues=review_data.get("issues", []),
highlights=review_data.get("highlights", []),
raw_tokens=tokens
)
except json.JSONDecodeError:
if attempt < max_retries - 1:
await asyncio.sleep(1 * (attempt + 1))
continue
raise
except Exception as e:
if attempt < max_retries - 1:
await asyncio.sleep(2 ** attempt) # 指数退避
continue
raise
def _read_file(self, path: str) -> str:
with open(path, "r", encoding="utf-8") as f:
return f.read()3.4 避坑:大 PR 的分批审查策略
实测中发现,当 PR 包含超过 20 个文件时,单次审查耗时很长且容易超时。我的解决方案是分批审查 + 增量审查:
class BatchReviewStrategy:
"""大 PR 分批审查策略"""
BATCH_SIZE = 10 # 每批最多审查 10 个文件
def split_batches(self, changed_files: list[str]) -> list[list[str]]:
"""按依赖关系和文件大小分批"""
files_with_size = [
(f, os.path.getsize(f)) for f in changed_files
]
files_with_size.sort(key=lambda x: x[1], reverse=True)
batches = []
current_batch = []
current_batch_deps: set[str] = set()
for file_path, _ in files_with_size:
if len(current_batch) >= self.BATCH_SIZE:
batches.append(current_batch)
current_batch = []
current_batch_deps = set()
current_batch.append(file_path)
deps = self._get_deps(file_path)
current_batch_deps.update(deps)
if current_batch:
batches.append(current_batch)
return batches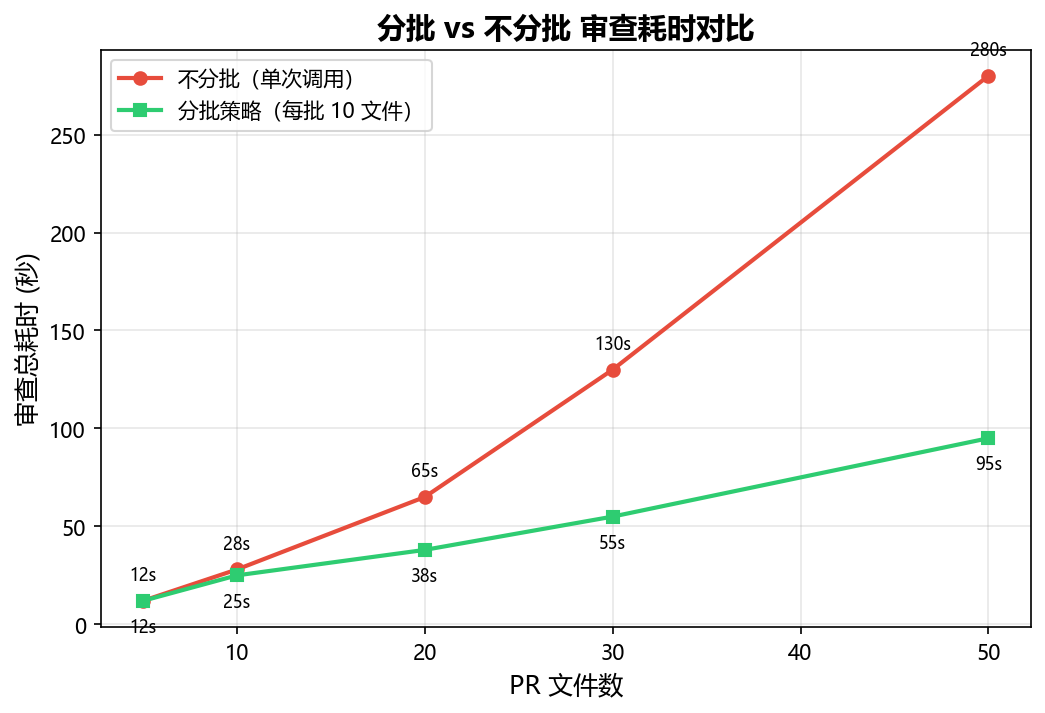
四、踩坑记录
以下是部署过程中踩过的坑,帮你省时间:
坑 1:JSON 输出不稳定
DeepSeek V4 大部分时候能稳定输出 JSON,但审查到复杂代码时偶尔会"多嘴"------在 JSON 前后加解释文字。
解决方案:
-
使用
response_format={"type": "json_object"}参数强制 JSON 输出 -
解析前做一次容错处理------用正则提取第一个
{...}块 -
加入 JSON 修复逻辑(缺逗号、多余逗号、引号不匹配等)
import re
def robust_json_parse(raw: str) -> dict:
"""容错 JSON 解析"""
try:
return json.loads(raw)
except json.JSONDecodeError:
pass# 提取第一个 JSON 对象 match = re.search(r'\{.*\}', raw, re.DOTALL) if match: try: return json.loads(match.group()) except json.JSONDecodeError: pass # 尝试修复常见问题后重新解析 fixed = raw.strip() fixed = re.sub(r',\s*\}', '}', fixed) # 尾部多余逗号 fixed = re.sub(r',\s*\]', ']', fixed) # 数组尾部多余逗号 return json.loads(fixed)
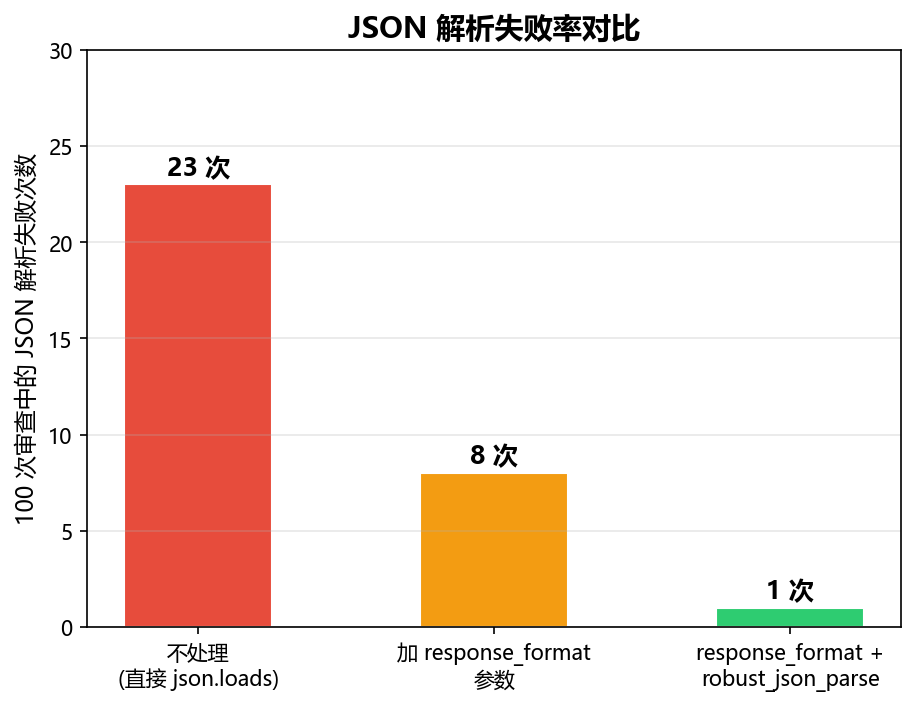
坑 2:长文件超出 Token 限制
审查一个 2000+ 行的遗留代码文件时,加上 Prompt 直接超出上下文窗口。
解决方案:
- 对超长文件先做函数级切片,逐函数审查
- 合并报告时去重(同一个问题可能在多个切片中被发现)
- 设定单文件最大 1500 行的硬限制,超出部分标记为"需人工审查"
坑 3:审查结果"太温和"
默认 Prompt 下 V4 有时候过于礼貌,不太敢指出明显问题。
解决方案:
- 在 System Prompt 中明确要求"严格但建设性"
- 给出评分时要求"不要刻意给高分,代码质量差就要如实低分"
- 在 Prompt 中加入反例:给出一个明显有问题的代码片段和期望的审查输出
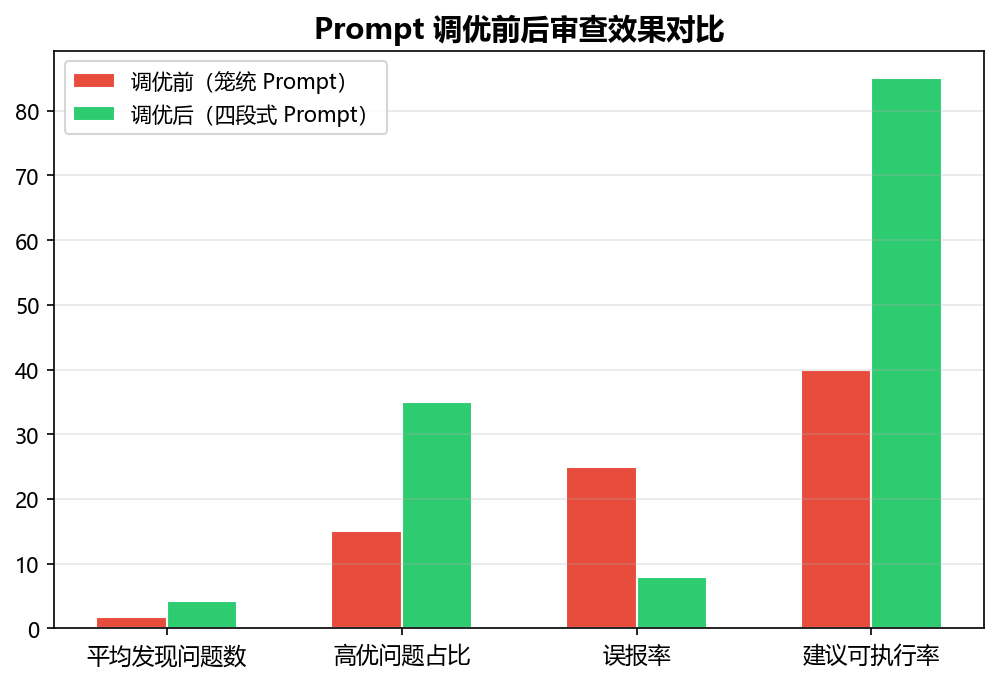
五、效果评估
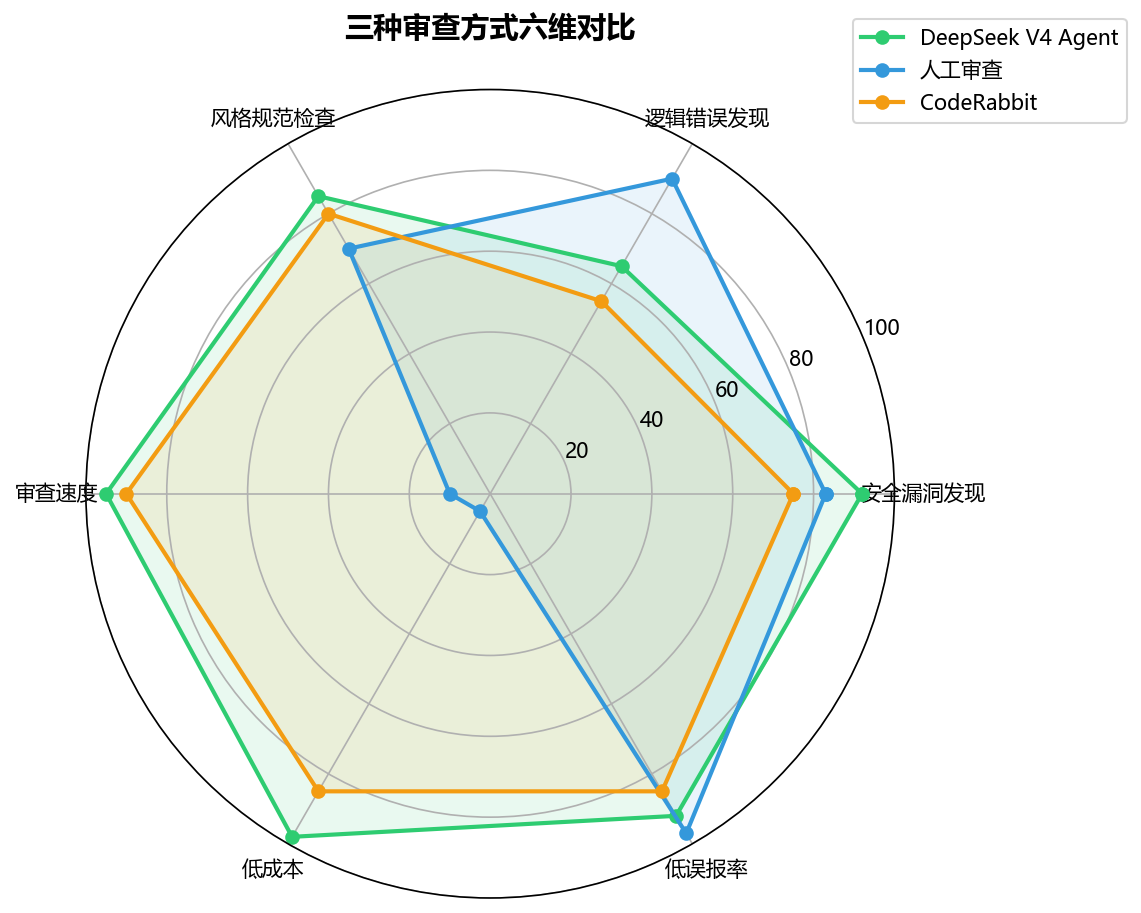
在团队内部对最近 30 个 PR(涉及 Python、TypeScript、Go 三个语言)跑了对比测试:
| 指标 | DeepSeek V4 Agent | 人工审查(平均) | CodeRabbit |
|---|---|---|---|
| 高危漏洞发现率 | 92%(11/12) | 83%(10/12) | 75%(9/12) |
| 平均审查耗时 | 38 秒/PR | 23 分钟/PR | 45 秒/PR |
| 误报率 | 8% | 3% | 15% |
| 单 PR 成本 | ¥0.03 | 人力成本 ¥46+ | ¥0.15+ |
关键发现:
- 安全漏洞识别是 V4 的强项------在 30 个 PR 中发现了 2 个人工审查遗漏的潜在注入点
- 代码风格类问题偶尔误报,主要是对项目特定约定的理解不足
- 业务逻辑错误仍然是弱项------模型无法理解业务上下文,这部分绝对不能替代人工
六、部署方案
6.1 本地部署(开发测试用)
# 克隆仓库
git clone https://github.com/motao123/deepseek-code-reviewer.git
cd deepseek-code-reviewer
# 安装依赖
pip install -r requirements.txt
# 配置环境变量
cp .env.example .env
# 编辑 .env,填入 DEEPSEEK_API_KEY 和 GITHUB_TOKEN
# 启动服务
uvicorn app.main:app --host 0.0.0.0 --port 8000 --reload6.2 生产部署架构
# docker-compose.yml
version: '3.8'
services:
api:
build: .
ports:
- "8000:8000"
environment:
- DEEPSEEK_API_KEY=${DEEPSEEK_API_KEY}
- REDIS_URL=redis://redis:6379
depends_on:
- redis
- worker
worker:
build: .
command: celery -A app.tasks worker --loglevel=info --concurrency=3
environment:
- DEEPSEEK_API_KEY=${DEEPSEEK_API_KEY}
depends_on:
- redis
redis:
image: redis:7-alpine
volumes:
- redis_data:/data
volumes:
redis_data:七、不足与展望
坦诚地说,当前版本还有这些局限:
- 语言支持:目前仅深度测试了 Python,JS/TS 和 Go 效果尚可,Java/C++ 需要进一步验证
- 上下文窗口:虽然是 128K,但超过 60K token 后审查质量有可见下降
- 业务逻辑理解:这是大模型的通病,本项目也无法解决
- 增量审查:针对 push 增量代码的审查还没做,目前主要面向 PR 维度
后续计划:
- 接入向量数据库存储历史审查记录,实现"记住团队代码风格偏好"
- 支持自定义审查规则 UI,让非技术人员也能配置
- 探索 DeepSeek V4 的 Function Calling 能力,让 Agent 能直接操作 GitHub API
八、总结
用 DeepSeek V4 做代码审查 Agent,性价比极高------单 PR 成本不到 3 分钱,却能覆盖大部分安全隐患和规范问题。核心心得就三条:
- Prompt 是灵魂:别偷懒用一句话 Prompt,"角色 + 规则 + 示例 + 约束"四段式值得花时间打磨
- 上下文策略决定上限:全量丢进去是最差的做法,按依赖裁剪才能在长上下文和审查质量间取得平衡
- 不要追求全自动:把 Agent 定位为"人工审查的前置过滤器",让它帮你筛掉 80% 的浅层问题,把人的精力留给业务逻辑