论文信息
- 标题:Transfer CLIP for Generalizable Image Denoising
- 会议:arXiv 2024
- 单位:Huazhong University of Science and Technology
- 代码:https://github.com/alwaysuu/CLIPDenoising
- 论文:https://arxiv.org/pdf/2403.15132.pdf
一、开篇唠唠:图像去噪的"泛化难题"
图像去噪作为计算机视觉底层核心任务,不管是手机拍照、医学影像还是监控画面,都离不开它。但传统深度学习去噪方法有个致命bug :在训练集噪声上表现拉满,碰到分布外(OOD)噪声直接拉胯,比如训练用高斯噪声,碰到真实相机噪声、CT噪声就歇菜。
最近爆火的CLIP模型,在开放世界识别、分割里杀疯了,可没人把它用到底层视觉去噪 上。这篇论文就干了件大事:把冻结的CLIP-ResNet编码器搬过来,靠它的抗畸变+内容关联特性,做了个只需要单噪声训练、就能通杀各类OOD噪声的去噪模型------CLIPDenoising。
二、核心发现:CLIP特征藏着"去噪密码"
作者先扒了CLIP的ResNet图像编码器,挖出两个王炸特性,这也是整个方法的根基。
1. 畸变不变性(Distortion-invariant)
简单说:加了噪声的图,和干净图抽出来的CLIP特征,相似度超高 ,噪声几乎不影响特征表达。
作者用余弦相似度验证,CLIP-RN50的前4层特征F1F^1F1~F4F^4F4,不管噪声强度多大,和干净图特征的余弦相似度都逼近1.0。
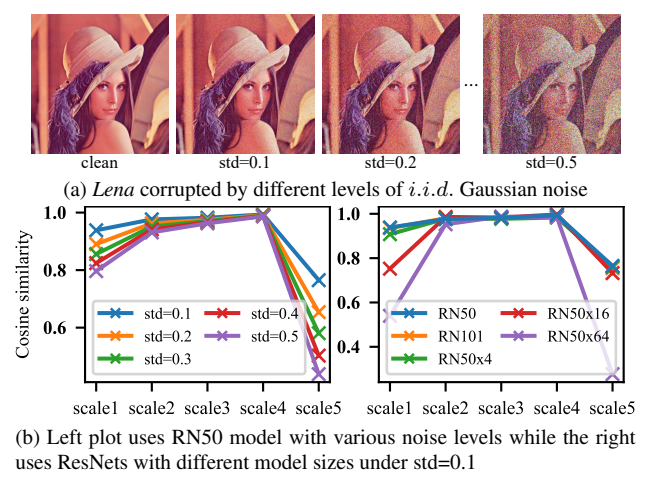
图片分析:左图是RN50在不同高斯噪声强度下的特征相似度,前4层特征始终保持高相似;右图是不同尺寸CLIP-ResNet在固定噪声下的表现,RN50的浅层特征抗噪性最优。
对比监督训练的ResNet50和Restormer,它们的特征受噪声影响极大,相似度暴跌,这说明抗畸变特性是CLIP预训练带来的专属buff。
2. 内容关联性(Content-related)
再简单点:不同内容的图像,CLIP特征差异极大 ,能精准区分图像语义和内容。
作者用t-SNE可视化不同图像的CLIP特征,不同内容的特征簇完全分离,哪怕加了噪声也不混淆。
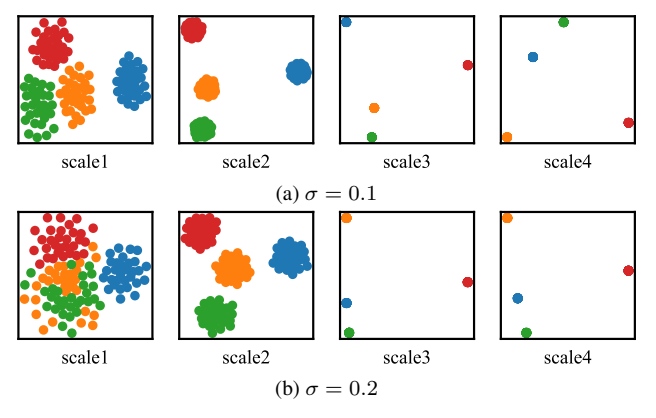
图片分析:不同颜色代表不同图像,不管噪声强度σ=0.1还是0.2,特征簇都清晰分离,证明特征和图像内容强绑定。
三、模型架构:CLIPDenoising 不对称编解码设计
基于上面两个特性,作者搭了个极简又能打的不对称编码器-解码器结构:
- 编码器:冻结CLIP的ResNet50,不参与训练,只抽多尺度抗噪特征;
- 解码器:4层可学习卷积解码器,逐步融合CLIP特征+原始噪声图,输出干净图。
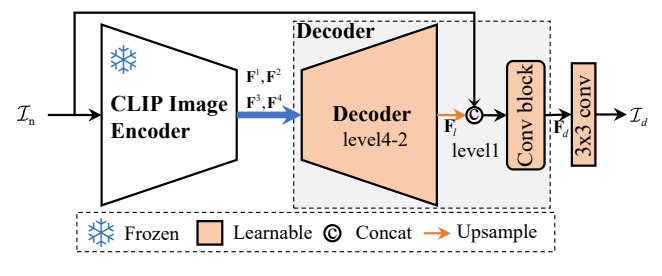
模型流程:
- 噪声图InI_nIn输入冻结CLIP-RN50,提取F1F^1F1~F4F^4F4四层多尺度特征;
- 解码器以F4F^4F4为起点,上采样时逐次拼接F3F^3F3、F2F^2F2、F1F^1F1;
- 最后一层拼接原始噪声图InI_nIn,经过卷积输出去噪图IdI_dId。
核心公式解析
模型训练用L1损失,公式如下:
L=Ep(Ic)∥Id−Ic∥1\mathcal{L}=E_{p(\mathcal{I}{c})}\left\| \mathcal{I}{d}-\mathcal{I}_{c}\right\| _{1}L=Ep(Ic)∥Id−Ic∥1
- L\mathcal{L}L:模型总损失
- Ep(Ic)E_{p(\mathcal{I}_{c})}Ep(Ic):对干净图像分布的期望
- Id\mathcal{I}_{d}Id:模型输出的去噪图像
- Ic\mathcal{I}_{c}Ic:真实干净图像
- ∥⋅∥1\left\| \cdot \right\| _{1}∥⋅∥1:L1范数,衡量去噪图和干净图的像素误差
通俗解释:让模型输出的图,和真实干净图的像素差异尽可能小。
四、进阶优化:渐进式特征增强(PFA)
冻结CLIP特征会带来特征过拟合 问题:训练集图像相似,特征多样性不足,模型泛化性下降。
作者提出渐进式特征增强,给不同层级特征加随机扰动,层级越深扰动越强。
增强公式
F^i=αi⊙Fi,αi∼N(1,(γ×i)2I),i∈{1,⋯4}\hat{F}^{i}=\alpha_{i} \odot F^{i}, \alpha_{i} \sim \mathcal{N}\left(1,(\gamma × i)^{2} I\right), i \in\{1, \cdots 4\}F^i=αi⊙Fi,αi∼N(1,(γ×i)2I),i∈{1,⋯4}
- F^i\hat{F}^{i}F^i:增强后的第i层特征
- αi\alpha_{i}αi:随机扰动因子,服从高斯分布
- ⊙\odot⊙:元素级乘法
- γ\gammaγ:扰动系数(论文设为0.025)
- iii:特征层级,越大扰动越强
- N(1,(γ×i)2I)\mathcal{N}\left(1,(\gamma × i)^{2} I\right)N(1,(γ×i)2I):均值为1,方差为(γ×i)2(\gamma × i)^2(γ×i)2的高斯分布
通俗解释:浅层特征保细节,少加扰动;深层特征学语义,多加扰动,既防过拟合又保特征有效性。
五、核心代码实现(PyTorch)
1. CLIP多尺度特征提取
python
# 核心:提取CLIP-RN50前4层多尺度特征(对应论文Alg.1)
import torch
import clip
from torch import nn
class CLIPFeatureExtractor(nn.Module):
def __init__(self):
super().__init__()
# 加载冻结的CLIP-RN50
self.clip_model, _ = clip.load("RN50", device="cuda")
self.encoder = self.clip_model.visual
# 冻结所有参数
for param in self.encoder.parameters():
param.requires_grad = False
def forward(self, x):
features = []
# 复刻CLIP-RN50前向,提取F1-F4
x = x.type(self.encoder.conv1.weight.dtype)
x = self.encoder.relu1(self.encoder.bn1(self.encoder.conv1(x)))
x = self.encoder.relu2(self.encoder.bn2(self.encoder.conv2(x)))
x = self.encoder.relu3(self.encoder.bn3(self.encoder.conv3(x)))
features.append(x) # F1
x = self.encoder.layer1(x)
features.append(x) # F2
x = self.encoder.layer2(x)
features.append(x) # F3
x = self.encoder.layer3(x)
features.append(x) # F4
# 返回F1-F4,顺序对应解码器输入
return features[::-1] # [F4,F3,F2,F1]2. 渐进式特征增强
python
def progressive_feature_augmentation(features, gamma=0.025):
"""
渐进式特征增强
features: list [F4,F3,F2,F1]
"""
aug_features = []
for i, feat in enumerate(features):
# 层级i+1,越深扰动方差越大
std = gamma * (i + 1)
alpha = torch.normal(1.0, std, size=feat.shape).to(feat.device)
aug_feat = alpha * feat
aug_features.append(aug_feat)
return aug_features3. 可学习解码器
python
class DenoiseDecoder(nn.Module):
def __init__(self, in_channels=64):
super().__init__()
# 4层卷积解码器,逐步上采样+特征拼接
self.decoder_layer4 = nn.Conv2d(2048, 512, 3, padding=1)
self.decoder_layer3 = nn.Conv2d(512+1024, 256, 3, padding=1)
self.decoder_layer2 = nn.Conv2d(256+512, 64, 3, padding=1)
self.decoder_layer1 = nn.Conv2d(64+64+3, 3, 3, padding=1)
self.upsample = nn.Upsample(scale_factor=2, mode='bilinear')
def forward(self, clip_features, noisy_img):
# clip_features: [F4,F3,F2,F1]
f4, f3, f2, f1 = clip_features
# 第4层
x = self.upsample(f4)
x = torch.cat([x, f3], dim=1)
x = self.decoder_layer4(x)
# 第3层
x = self.upsample(x)
x = torch.cat([x, f2], dim=1)
x = self.decoder_layer3(x)
# 第2层
x = self.upsample(x)
x = torch.cat([x, f1], dim=1)
feat = self.decoder_layer2(x)
# 第1层:拼接原始噪声图
x = self.upsample(feat)
x = torch.cat([x, noisy_img], dim=1)
denoised_img = self.decoder_layer1(x)
return denoised_img六、实验效果:通杀各类OOD噪声
作者在合成噪声、真实sRGB噪声、低剂量CT噪声三大场景测试,全方面吊打传统泛化去噪方法。
1. 合成噪声实验(表格1)
表格1出处:Transfer CLIP for Generalizable Image Denoising Table.1
| 噪声类型 | 数据集 | DnCNN | Restormer | MaskDenoising | HAT | DIL | Ours |
|---|---|---|---|---|---|---|---|
| 高斯σ=50 | CBSD68 | 19.84/0.363 | 19.92/0.365 | 20.68/0.432 | 20.95/0.441 | 26.43/0.717 | 26.69/0.731 |
| 空间高斯σ=55 | CBSD68 | 25.91/0.699 | 23.51/0.595 | 26.72/0.762 | 26.39/0.713 | 24.61/0.630 | 27.60/0.797 |
| 泊松α=3.5 | CBSD68 | 24.37/0.627 | 22.20/0.559 | 24.24/0.638 | 26.61/0.733 | 27.64/0.819 | 27.67/0.818 |
表格分析:
- 训练仅用单一种类、单一强度的高斯噪声(σ=15);
- 测试面对强高斯、空间高斯、泊松等OOD噪声,CLIPDenoising的PSNR/SSIM全维度第一;
- 传统方法仅在特定噪声上有效,本文方法无短板。
2. 真实场景噪声实验
- 真实sRGB噪声 :在SIDD、PolyU、CC数据集上,和无监督方法比不落下风,且不需要真实噪声数据训练;
- 低剂量CT噪声:无需医学影像预训练,直接用自然图像训练的模型,效果比肩专业CT去噪方法Noise2Sim。


图片分析:真实相机噪声下,本文方法去噪更干净,细节保留更完整,边缘无伪影。
七、消融实验:每一步优化都至关重要
表格2出处:Transfer CLIP for Generalizable Image Denoising Table.4
| 模型变体 | 高斯σ=15 | 高斯σ=50 | 散斑噪声 |
|---|---|---|---|
| 基线 | 34.69/0.922 | 26.87/0.692 | 30.60/0.871 |
| 无原始噪声图 | 30.37/0.888 | 21.76/0.413 | 26.93/0.761 |
| 加入PFA | 34.69/0.922 | 27.39/0.723 | 30.67/0.876 |
表格分析:
- 原始噪声图是关键:去掉后OOD性能暴跌,因为CLIP特征缺少细节,需要原始图补充;
- PFA有效提升泛化:不影响分布内性能,专门提升OOD噪声效果;
- 微调CLIP反而变差 :微调会破坏抗畸变特性,冻结才是最优解。
八、总结与展望
这篇论文首次把CLIP迁移到图像去噪,靠冻结编码器的天然抗噪特性,解决了底层视觉的OOD泛化难题,核心亮点:
- 发现CLIP-RN50前4层特征的畸变不变+内容关联特性;
- 极简不对称编解码,单噪声训练、多噪声通用;
- 渐进式特征增强,解决特征过拟合;
- 三大场景实验屠榜,兼顾自然图像与医学影像。
未来方向:
- 把CLIP-ViT适配到去噪任务;
- 扩展到超分、去模糊等其他底层视觉任务;
- 端到端训练CLIP+去噪解码器,进一步提升性能。
一句话总结:CLIP不只是做识别的,底层视觉泛化去噪,它照样是王者!