在大型语言模型(LLM)席卷全球的背景下,如何将拥有千亿参数的"巨兽"转化为能够适配垂直领域、且能在消费级显卡上流畅运行的"利器",已成为每一位深度学习工程师的核心课题。本文将深入探讨LLM从预训练、微调到量化的全生命周期技术路径,重点解析LoRA、QLoRA及主流量化方案的底层逻辑。
1. 什么是大模型微调与量化?
LLM的强大源于其在海量通用语料上的预训练,但通用性往往意味着在特定任务上的"泛而不精"。同时,庞大的参数量带来了极高的计算与存储门槛。微调(Fine-tuning)解决了模型能力的垂直化迁移,而量化(Quantization)则解决了模型部署的工程化难题。理解这两者的协同作用,是构建高效AI应用的基石。
大模型微调与量化是推动大模型从"通用智能"走向"专用落地"的两大核心技术。微调 是指在预训练模型的基础上,利用特定领域的数据进行二次训练,使其掌握特定任务(如医疗问答、代码生成)的能力,相当于让通才"进修"成为专才;而量化则是通过降低模型权重的数值精度(例如从16位浮点数转换为8位甚至4位整数),在尽量保持模型性能的前提下大幅压缩模型体积并降低显存占用,相当于为庞大的模型"瘦身"以便于在消费级硬件上高效运行。两者结合,极大地降低了高性能AI的应用门槛。
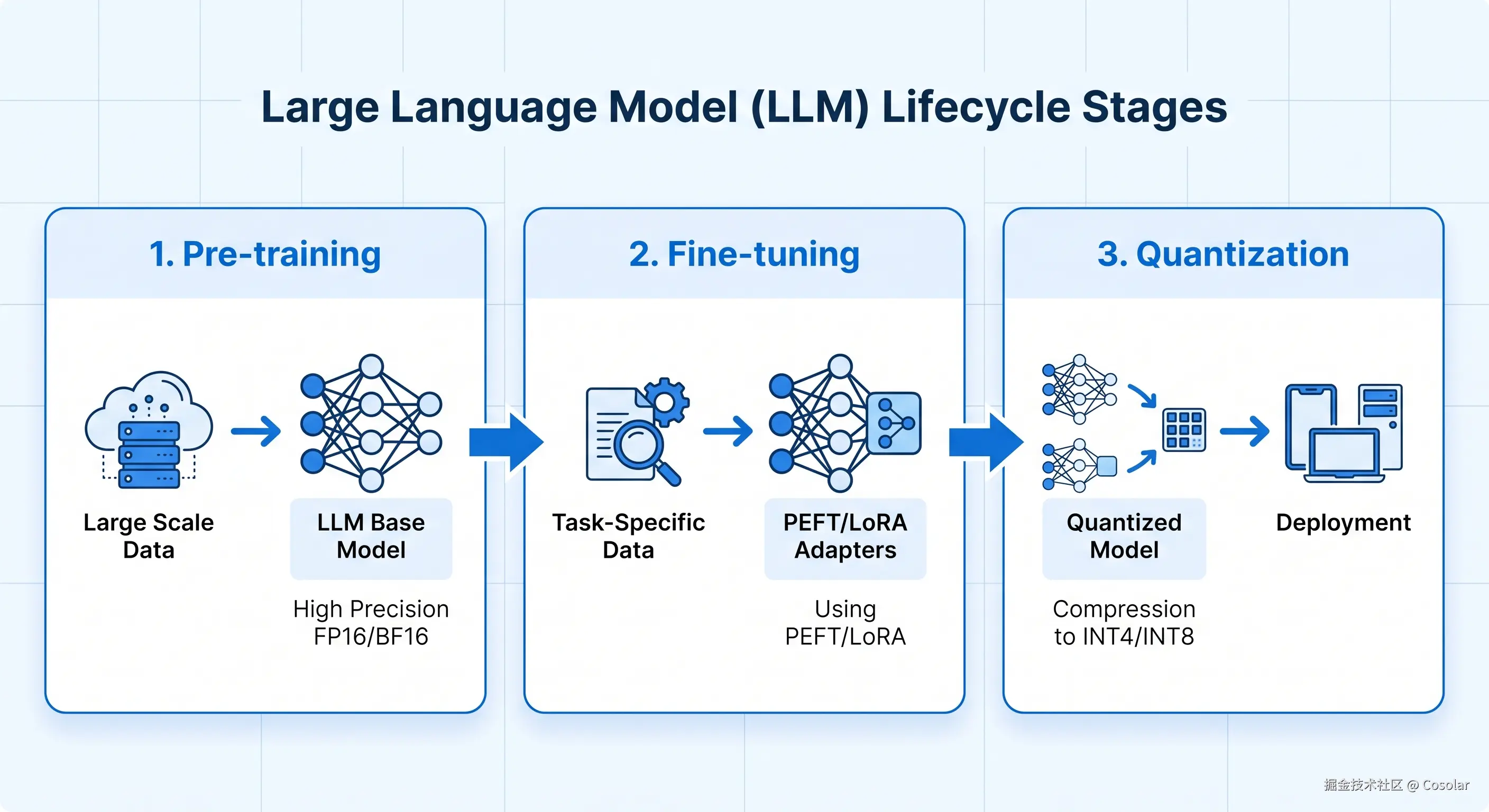
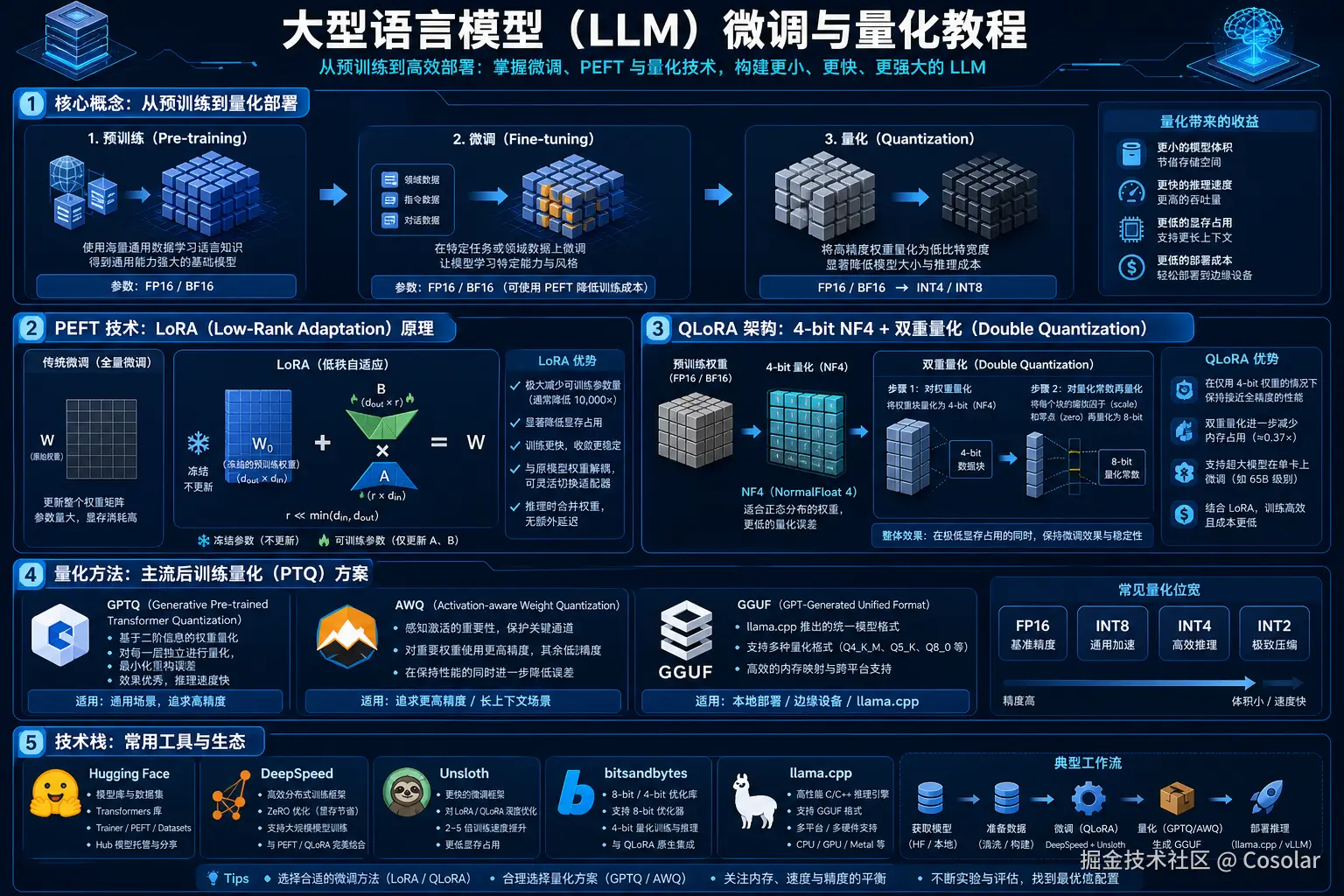
2. 核心流程:预训练 → 微调 → 量化
一个成熟的LLM部署流程通常经历以下三个阶段:
-
预训练 (Pre-training): 使用海量通用数据(如Common Crawl, Wikipedia)学习基础语言规律。此阶段模型通常采用 FP16/BF16 高精度存储,以保证梯度更新的稳定性,最终得到具备通用能力的基础模型(Base Model)。
-
微调 (Fine-tuning): 在特定领域数据(如医学、法律或特定指令集)上进行训练。为了降低成本,目前主流采用 PEFT(高效参数微调) 技术,仅更新极少数参数即可让模型掌握特定风格或知识。
-
量化 (Quantization): 推理阶段的"瘦身"过程。通过将 FP16/BF16 权重量化为 INT4/INT8,模型体积可缩小 2-4 倍。
- 核心收益: 显著降低显存占用、提升吞吐速度、降低硬件部署成本(如单张 24G 显存显卡即可运行 70B 模型)。
3. PEFT 技术:LoRA(Low-Rank Adaptation)深度解析
传统全量微调(Full Fine-tuning)需要更新模型的所有参数,这在显存和存储上是极其昂贵的。LoRA 提供了一种优雅的替代方案。
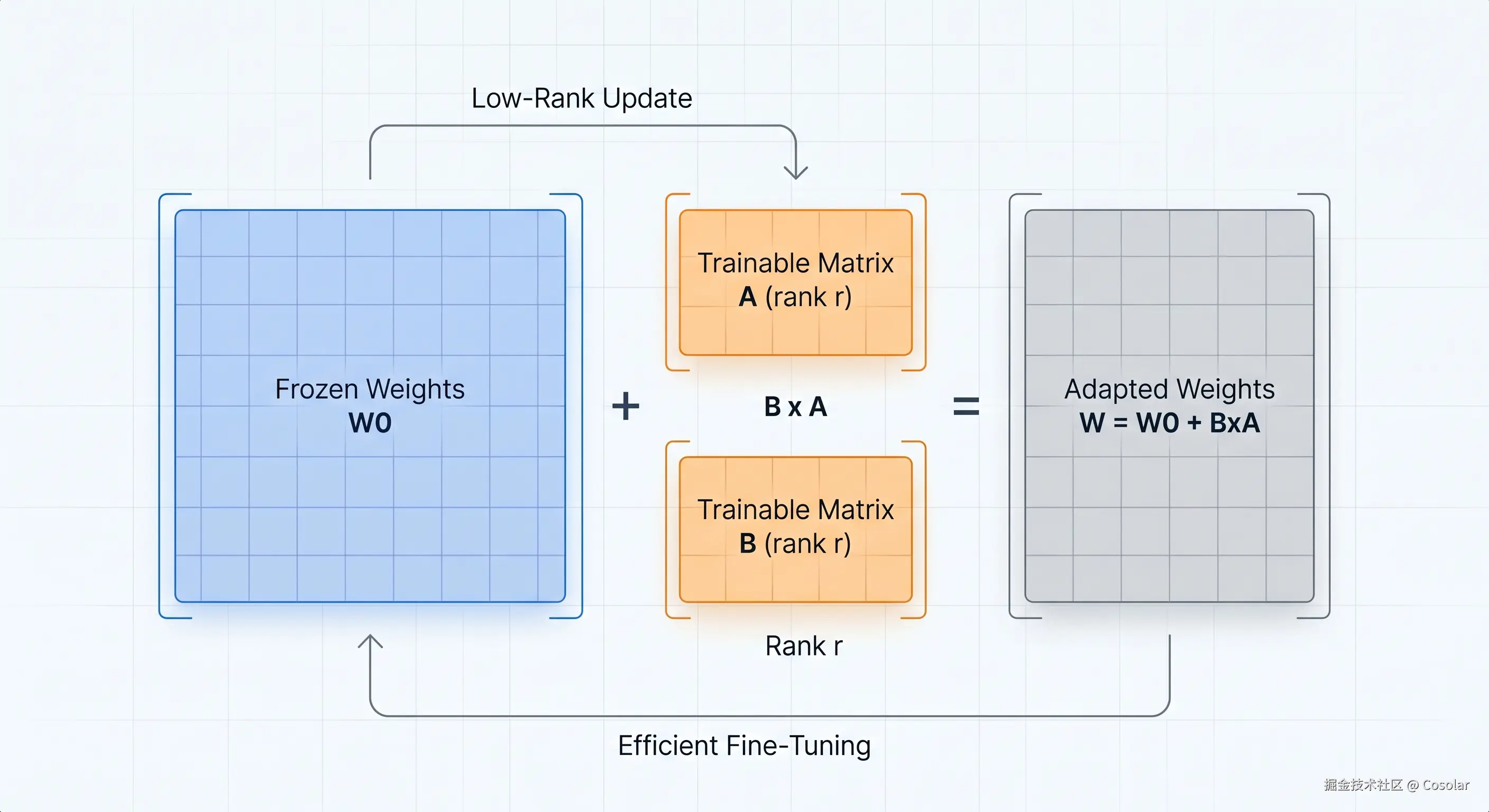
3.1 原理:低秩分解
LoRA 的理论基石源于一个深刻的洞察:大型预训练模型在适应新任务时,其权重的变化量 ΔW 并非随机分布,而是集中在某个低维子空间中。这意味着 ΔW 可以用一个低秩矩阵来高效近似。
LoRA 的核心思想是:模型在特定任务上的权重更新量 ΔW 实际上具有很低的"内在秩"(Intrinsic Rank)。因此,我们可以将 ΔW 分解为两个低秩矩阵的乘积:
W=W0+ΔW=W0+B×A
其中:
- W0∈Rd×k 是预训练权重,在训练期间被冻结。
- A∈Rr×k 和 B∈Rd×r 是可训练的低秩矩阵,秩 r≪min(d,k)。
这种近似的数学严谨性由 奇异值分解(Singular Value Decomposition, SVD) 提供。任何矩阵 W 都可以被分解,而根据 Eckart-Young-Mirsky 定理,其最佳的秩 r 近似 W_r 可以通过保留前 r 个最大的奇异值及其对应的奇异向量来构建。
LoRA 正是利用了这一特性,将更新量 ΔW 分解为两个更小的矩阵 A 和 B 的乘积:ΔW = B × A。
前向传播的重参数化
在实现中,LoRA 并不是直接修改原始权重矩阵 W0,而是在前向传播过程中注入低秩更新。对于输入向量 x,其输出 h 的计算方式如下:
h=W0x+ΔWx=W0x+BAx
为了进一步提升训练效率,通常会引入缩放因子 α。此时,更新公式变为:
h=W0x+rαBAx
其中 rα 被称为缩放系数,用于控制低秩更新的幅度。
梯度更新分析
由于 W0 被冻结,反向传播时梯度仅流向矩阵 A 和 B。 损失函数 L 对 A 和 B 的梯度可以通过链式法则计算:
假设 ∂h∂L 是上游传来的梯度,则:
- 对 B 的梯度: ∂B∂L=∂h∂L⋅rα⋅AxT
- 对 A 的梯度: ∂A∂L=∂h∂L⋅rα⋅BTx
推理时的权重合并
这是 LoRA 实现"零推理开销"的关键步骤。训练完成后,可以将低秩矩阵乘积加回原始权重中,得到一个等效的全秩权重 Wnew:
Wnew=W0+rαBA
合并后,模型的推理过程与原始模型完全一致,无需额外的计算图操作。
✨ 3.2 关键优势:为何 LoRA 成为主流?
LoRA 不仅仅是节省参数,它带来了一系列连锁优势,使其成为大模型微调的"事实标准"。
- 极高的参数效率
可训练参数通常仅为模型总量的 0.1% - 1% 。这使得在消费级显卡(如RTX 3090/4090)上微调数十亿参数的模型成为可能,将显存需求从几十GB降低到10-20GB。 - 训练稳定,避免"灾难性遗忘"
由于原始预训练权重W_0被完全冻结,模型在预训练阶段学到的通用知识和能力得以完整保留。这有效避免了全量微调中常见的"灾难性遗忘"问题,即模型在学习新任务时忘记了原有的通用能力。 - 推理零额外延迟
这是一个非常巧妙的设计。在训练完成后,可以将训练好的低秩矩阵B和A与原始权重W_0进行合并,得到最终的权重W = W_0 + BA。这样,在模型部署和推理时,其计算图和运行速度与原始模型完全一致,不会引入任何额外的计算开销。 - 模块化与快速切换
训练好的 LoRA 权重文件非常小(通常只有几MB到几十MB)。你可以为一个基座模型训练多个针对不同任务的 LoRA"插件"。在部署时,只需加载一次庞大的基座模型,然后根据需求动态加载不同的 LoRA 权重,即可快速切换模型能力,极大地节省了存储和部署成本。
🚀 演进生态:LoRA 的变体与改进
LoRA 的成功催生了许多优秀的改进版本,以应对更极致的场景。
| 变体 | 核心改进 | 适用场景 |
|---|---|---|
| QLoRA | 将基座模型进行 4-bit 量化,再应用 LoRA。 | 显存极度受限,希望在单张消费级显卡上微调 70B+ 的超大模型。 |
| DoRA | 将权重分解为 幅度(Magnitude) 和 方向(Direction) 两个分量,并分别进行适配。 | 追求比 LoRA 更高的精度和更稳定的收敛效果。 |
总而言之,LoRA 以其优雅的原理和卓越的性能,极大地降低了大模型的应用门槛,是当前参数高效微调领域最核心、最实用的技术之一。
4. QLoRA:4-bit NF4 + 双重量化
QLoRA 是 LoRA 的进阶版,它将量化与微调深度结合,使得在单张 RTX 3090/4090 上微调 65B 模型成为可能。
-
4-bit NF4 (NormalFloat 4): 针对正态分布的权重设计的一种信息论最优量化数据类型,比传统的 4-bit 整数量化误差更小。
-
双重量化 (Double Quantization):
-
对权重进行 4-bit 量化。
-
对量化过程中产生的缩放因子(Scales)再次进行 8-bit 量化。这进一步节省了显存(平均每参数节省约 0.37 bit)。
-
-
优势: 在几乎不损失微调精度的情况下,极大降低了硬件门槛。
5. 主流后训练量化(PTQ)方案对比
在模型微调完成后,我们需要选择合适的 PTQ 方案进行压缩部署。
| 方案 | 核心特点 | 适用场景 |
|---|---|---|
| GPTQ | 感知激活重要性,通过二阶信息最小化量化误差。 | 通用场景,追求极致的 INT4 推理精度。 |
| AWQ | 观察激活分布,通过缩放保护 1% 的显著权重通道。 | 保护长上下文能力,精度通常优于 GPTQ。 |
| GGUF | llama.cpp 专用格式,支持多种位宽(Q4_K, Q5_K)。 | 本地部署、CPU/GPU 混合推理、边缘设备。 |
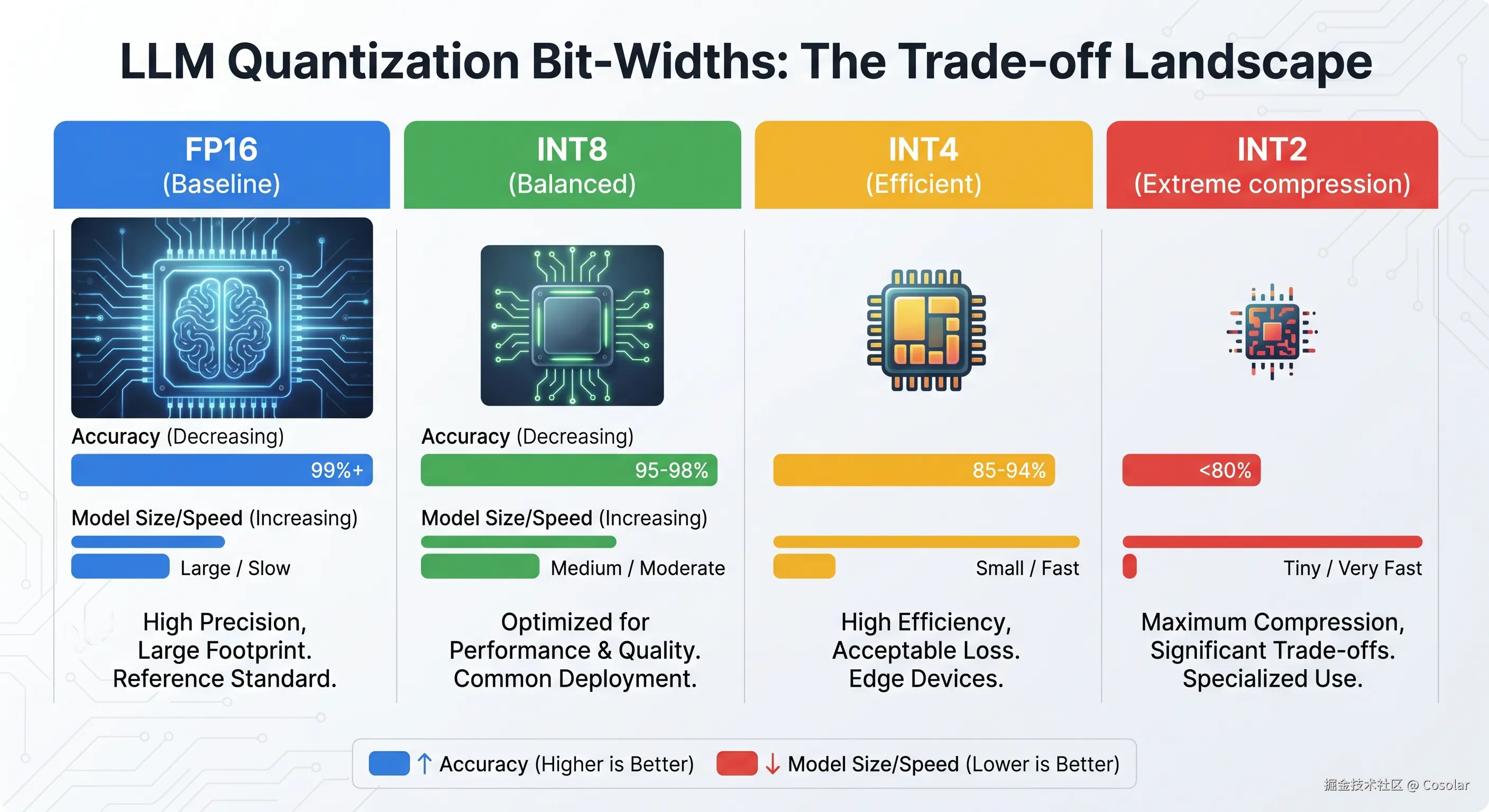
精度与速度的权衡:
-
FP16: 基准精度,显存占用最高。
-
INT8: 几乎无损,适合生产环境通用加速。
-
INT4: 目前最主流的部署方案,性能与体积的完美平衡。
-
INT2: 极致压缩,但通常伴随明显的精度下降。
6. 技术栈与生态工具
-
Hugging Face: 核心生态,提供
Transformers、PEFT和Datasets库。 -
DeepSpeed: 微软开源,通过 ZeRO 优化技术支持超大规模分布式训练。
-
Unsloth: 针对 LoRA/QLoRA 进行了底层内核优化,训练速度提升 2-5 倍,且显存占用更低。
-
bitsandbytes: QLoRA 的底层支撑库,负责 4-bit/8-bit 的高效算子实现。
-
llama.cpp: C++ 实现的推理引擎,是 GGUF 格式的最佳拍档,支持跨平台运行。
7. 典型工作流
-
获取模型: 从 Hugging Face 下载基础模型(如 Llama-3, Qwen-2)。
-
准备数据: 构建高质量的指令微调数据集(JSONL 格式)。
-
微调: 使用 Unsloth + LoRA 进行快速迭代,显存不足时开启 QLoRA。
-
量化: 使用 AutoGPTQ 或 AutoAWQ 将模型转为 4-bit,或导出为 GGUF。
-
部署: 使用 vLLM (高并发)或 llama.cpp(本地轻量级)进行推理。
8. 总结与选型建议
在实际工程中,没有绝对的最优解,只有最合适的平衡点:
-
追求训练速度? 首选
Unsloth+LoRA。 -
显存极度受限? 开启
QLoRA(4-bit 训练)。 -
本地私有化部署? 导出
GGUF配合llama.cpp。 -
云端高并发服务? 使用
AWQ量化配合vLLM框架。
核心原则: 优先保证数据质量,其次通过微调对齐能力,最后通过量化压榨硬件性能。在每一阶段都应进行严谨的 Benchmark 评估,确保精度损失在可接受范围内。