原文链接 https://doi.org/10.48550/arxiv.2308.07314
前言:
在学习本论文前,你需要先学习VQGAN模型和CILP模型。
整体架构图: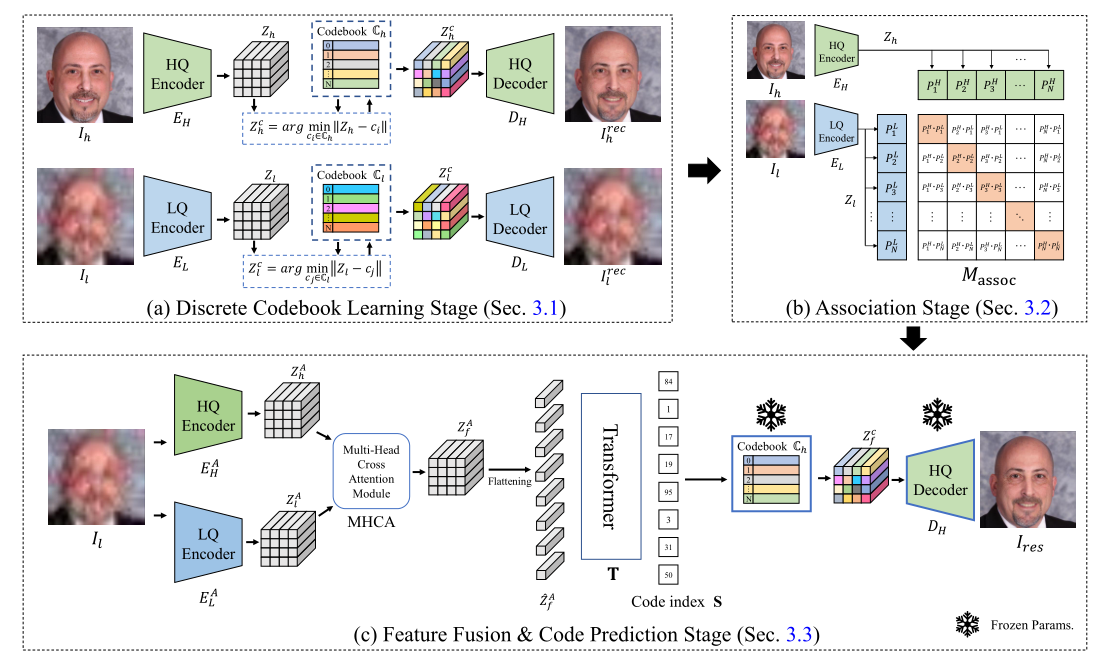
第一阶段:离散码本学习阶段
与 VQGAN类似,本阶段通过自编码器与可学习码本分别对高质量域(HQ)与低质量域(LQ)进行特征编码,在训练中捕获各自领域的专属特征。HQ 路径与 LQ 路径采用完全相同的结构与训练设置,以保证特征表示的一致性。以下以 HQ 重建路径为例进行说明,LQ 路径训练流程与其完全一致。
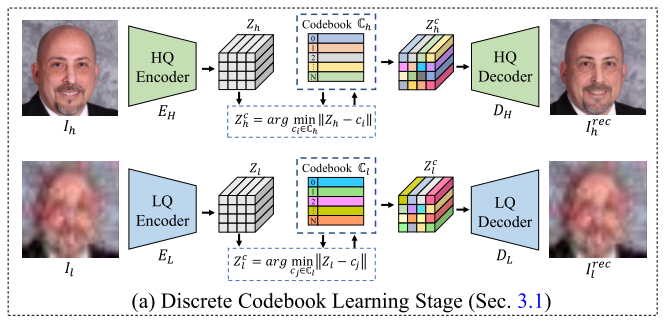
如图所示,编码器 E H E_H EH 将高质量人脸图像 I h ∈ R H × W × 3 I_h \in \mathbb{R}^{H \times W \times 3} Ih∈RH×W×3 编码为压缩特征 Z h ∈ R m × n × d Z_h \in \mathbb{R}^{m \times n \times d} Zh∈Rm×n×d。随后进行矢量量化:将 Z h Z_h Zh 中的每个特征向量,替换为可学习码本 C h = { c k ∈ R d } k = 0 N − 1 C_h = \{c_k \in \mathbb{R}^d\}{k=0}^{N-1} Ch={ck∈Rd}k=0N−1 中距离最近的码元,得到量化特征 Z h c ∈ R m × n × d Z_h^c \in \mathbb{R}^{m \times n \times d} Zhc∈Rm×n×d,计算方式为:
Z h c ( i , j ) = arg min c k ∈ C h ∥ Z h ( i , j ) − c k ∥ 2 2 Z_h^{c(i,j)} = \arg\min{c_k \in C_h} \left\| Z_h^{(i,j)} - c_k \right\|_2^2 Zhc(i,j)=argck∈Chmin Zh(i,j)−ck 22
最后,解码器 D H D_H DH 利用量化特征 Z h c Z_h^c Zhc 重建出高质量人脸图像 I h r e c I_h^{rec} Ihrec。
训练目标
与现有方法设置一致,本阶段采用四种损失进行训练,包括三种图像级重建损失与一种码本级损失:
L 1 = ∥ I h − I h r e c ∥ 1 , L p e r = ∥ Φ ( I h ) − Φ ( I h r e c ) ∥ 2 2 , L a d v = log D ( I h ) + log ( 1 − D ( I h r e c ) ) , L c o d e = ∥ sg ( Z h ) − Z h c ∥ 2 2 + β ∥ Z h − sg ( Z h c ) ∥ 2 2 . \begin{aligned} L_1 &= \| I_h - I_h^{rec} \|1, \\ L{per} &= \| \Phi(I_h) - \Phi(I_h^{rec}) \|2^2, \\ L{adv} &= \log D(I_h) + \log(1 - D(I_h^{rec})), \\ L_{code} &= \| \text{sg}(Z_h) - Z_h^c \|_2^2 + \beta \| Z_h - \text{sg}(Z_h^c) \|_2^2. \end{aligned} L1LperLadvLcode=∥Ih−Ihrec∥1,=∥Φ(Ih)−Φ(Ihrec)∥22,=logD(Ih)+log(1−D(Ihrec)),=∥sg(Zh)−Zhc∥22+β∥Zh−sg(Zhc)∥22.
其中, Φ \Phi Φ 为 VGG19 特征提取器, D D D 为基于补丁的判别器, sg ( ⋅ ) \text{sg}(\cdot) sg(⋅) 为停止梯度算子, β = 0.25 \beta = 0.25 β=0.25。
最终的码本学习总损失为:
L codebook = L 1 + λ p e r L p e r + λ a d v L a d v + L c o d e L_{\text{codebook}} = L_1 + \lambda_{per} L_{per} + \lambda_{adv} L_{adv} + L_{code} Lcodebook=L1+λperLper+λadvLadv+Lcode
其中 λ p e r = 1.0 \lambda_{per}=1.0 λper=1.0, λ a d v = 0.8 \lambda_{adv}=0.8 λadv=0.8。
第二阶段:关联阶段
如图所示,在上一阶段得到高质量域(HQ)与低质量域(LQ)的编码器( E H E_H EH 和 E L E_L EL)后,我们将输出特征( Z h Z_h Zh 和 Z l ∈ R m × n × d Z_l \in \mathbb{R}^{m \times n \times d} Zl∈Rm×n×d,如 Z h Z_h Zh 和 Z l ∈ R 16 × 16 × 256 Z_l \in \mathbb{R}^{16 \times 16 \times 256} Zl∈R16×16×256)展平为对应的特征块( P i H P_i^H PiH 和 P i L P_i^L PiL, i ∈ ( 1 , . . . , m × n ) i \in( 1, ..., m \\times n) i∈(1,...,m×n)。这种展平操作使我们能够构建相似度矩阵( M assoc ∈ R N × N M_{\text{assoc}} \in \mathbb{R}^{N \times N} Massoc∈RN×N,其中 N = m × n N = m \times n N=m×n),用于量化不同特征块之间的相似度。
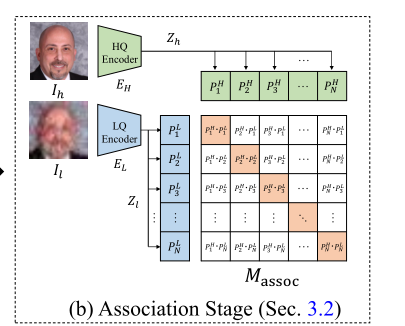
具体而言,我们计算每个特征块的余弦相似度,并约束矩阵对角线上的相似度最大化 ,(对角线为高质量图像和低质量图像空间位置对应的图像块),通过施加该约束,两个编码器会在空间位置与特征层级上都将相近的特征块关联起来,在整个关联过程中保持空间对应关系。融合来自两个编码器的特征块后,我们得到两个关联后的编码器 ,记为 E H A E_H^A EHA 和 E L A E_L^A ELA,它们融合了各自域的专属信息,将用于后续阶段。
训练目标
我们对高质量(HQ)与低质量(LQ)重建路径进行联合训练,并将特征关联模块纳入其中。为实现特征关联,我们采用交叉熵损失 ( L C E H L_{CE}^H LCEH 和 L C E L L_{CE}^L LCEL)对相似度矩阵 M a s s o c M_{assoc} Massoc 进行有效约束:
L C E H = − 1 N ∑ i = 1 N ∑ j = 1 C y i , j log ( p i , j h ) , L C E L = − 1 N ∑ i = 1 N ∑ j = 1 C y i , j log ( p i , j l ) , L_{CE}^H = -\frac{1}{N}\sum_{i=1}^N\sum_{j=1}^C y_{i,j}\log(p_{i,j}^h),\quad L_{CE}^L = -\frac{1}{N}\sum_{i=1}^N\sum_{j=1}^C y_{i,j}\log(p_{i,j}^l), LCEH=−N1i=1∑Nj=1∑Cyi,jlog(pi,jh),LCEL=−N1i=1∑Nj=1∑Cyi,jlog(pi,jl),
其中, N N N 表示特征块数量, C C C 表示类别数,在本文中 C = N C=N C=N。 y i , j y_{i,j} yi,j 为真实标签, p i , j h p_{i,j}^h pi,jh 为相似度矩阵 M a s s o c M_{assoc} Massoc 在高质量域的余弦相似度得分, p i , j l p_{i,j}^l pi,jl 为低质量域的得分。
补充真实标签 y i , j y_{i,j} yi,j :
我们把特征图切成了 N 个块(N = 16*16 = 256):
- HQ 第 1 块、HQ 第 2 块 ... HQ 第 N 块
- LQ 第 1 块、LQ 第 2 块 ... LQ 第 N 块
我们希望:HQ第i块 只和 LQ第i块 对应,HQ第i块 不应该和 LQ其他块 对应
所以真实标签 y i , j y_{i,j} yi,j 就是:
✔ 当 i = j(同一个空间位置), y i , j = 1 y_{i,j} = 1 yi,j=1 → 是"正确匹配", 当 i ≠ j(不同空间位置), y i , j = 0 y_{i,j} = 0 yi,j=0 → 是"错误匹配"
特征关联阶段的最终损失为:
L a s s o c = L 1 + λ p e r ⋅ L p e r + λ a d v ⋅ L a d v + L c o d e + ( L C E H + L C E L ) / 2 , L_{assoc} = L_1 + \lambda_{per}\cdot L_{per} + \lambda_{adv}\cdot L_{adv} + L_{code} + (L_{CE}^H + L_{CE}^L)/2, Lassoc=L1+λper⋅Lper+λadv⋅Ladv+Lcode+(LCEH+LCEL)/2,
我们沿用码本学习阶段的损失与权重,以保持特征表示的稳定性。(前四个损失和码本学习阶段一致,只有最后一个损失为该阶段特有。)
第三阶段 特征融合与码本预测阶段
在特征关联阶段得到两个关联后的编码器 E H A E_H^A EHA 与 E L A E_L^A ELA 后,如图所示,我们用两个编码器同时对低质量图像 I l I_l Il 进行编码。具体来说,分别用 E H A E_H^A EHA 和 E L A E_L^A ELA 从 I l I_l Il 中提取特征 Z h A ∈ R m × n × d Z_h^A\in\mathbb{R}^{m\times n\times d} ZhA∈Rm×n×d 与 Z l A ∈ R m × n × d Z_l^A\in\mathbb{R}^{m\times n\times d} ZlA∈Rm×n×d。
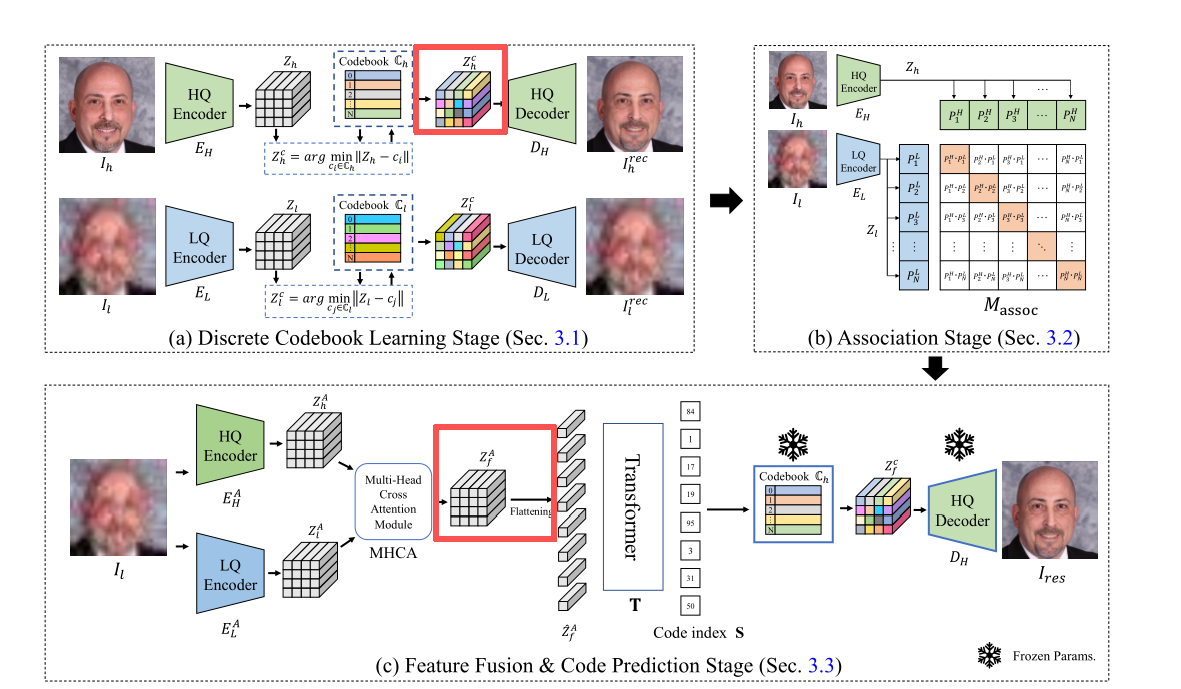
我们使用多头交叉注意力MHCA 模块融合两路特征,生成融合特征 Z f A ∈ R m × n × d Z_f^A\in\mathbb{R}^{m\times n\times d} ZfA∈Rm×n×d:
Z f A = MHCA ( Z h A , Z l A ) Z_f^A = \text{MHCA}(Z_h^A, Z_l^A) ZfA=MHCA(ZhA,ZlA)MHCA 使模型能关注特征空间的不同维度,更好地捕捉两路编码器的有效信息。
得到融合特征 Z f A Z_f^A ZfA 后,我们采用基于 Transformer 的分类方法预测对应的码本索引 s s s。首先将 Z f A ∈ R m × n × d Z_f^A\in\mathbb{R}^{m\times n\times d} ZfA∈Rm×n×d 展平为 Z ^ f A ∈ R ( m ⋅ n ) × d \hat{Z}_f^A\in\mathbb{R}^{(m\cdot n)\times d} Z^fA∈R(m⋅n)×d,输入 Transformer 得到预测索引 s ∈ { 0 , ... , N − 1 } m ⋅ n s\in\{0,\dots,N-1\}^{m\cdot n} s∈{0,...,N−1}m⋅n。
此过程中,码本学习阶段得到的高质量码本 C h C_h Ch 与高质量解码器 D H D_H DH 被冻结 。利用预测索引 s s s 在 C h C_h Ch 中检索对应特征 Z f c Z_f^c Zfc,输入解码器 D H D_H DH 生成最终高质量修复图像 I r e s I_{res} Ires。该步骤通过融合双域信息,有效提升人脸修复效果。
训练目标
我们使用两种损失函数来有效训练多头交叉注意力(MHCA)模块 和Transformer模块,以确保特征融合与码本索引预测的学习效果。
第一种是 L2 损失 L c o d e f e a t L_{code}^{feat} Lcodefeat,它用于约束融合特征 Z f A Z^A_f ZfA 尽可能接近来自高质量码本 C h C_h Ch 的量化特征 Z h c Z^c_h Zhc。该损失保证特征被合理融合,并同时保留来自高质量域(HQ)与低质量域(LQ)的有效信息。
第二种是用于码本索引预测的交叉熵损失 L c o d e i n d e x L_{code}^{index} Lcodeindex,使模型能够精准预测高质量码本 C h C_h Ch 中对应的码本索引 s s s。
L c o d e f e a t = ∥ Z f A − sg ( Z h c ) ∥ 2 2 , L c o d e i n d e x = ∑ i = 0 m n − 1 − s ^ i log ( s i ) L_{code}^{feat} = \| Z^A_f - \text{sg}(Z^c_h) \|2^2, \quad L{code}^{index} = \sum_{i=0}^{mn-1} -\hat{s}_i \log(s_i) Lcodefeat=∥ZfA−sg(Zhc)∥22,Lcodeindex=i=0∑mn−1−s^ilog(si)
其中,真实量化特征 Z h c Z^c_h Zhc 和真实码本索引 s ^ \hat{s} s^ 均来自码本学习阶段 ; Z h c Z^c_h Zhc 是通过真实索引 s ^ \hat{s} s^ 从高质量码本 C h C_h Ch 中检索得到的。
特征融合与码本预测的最终损失为:
L p r e d i c t = λ f e a t ⋅ L c o d e f e a t + L c o d e i n d e x L_{predict} = \lambda_{feat} \cdot L_{code}^{feat} + L_{code}^{index} Lpredict=λfeat⋅Lcodefeat+Lcodeindex
在实验中,我们设置 L2 损失的权重 λ f e a t = 10 \lambda_{feat} = 10 λfeat=10。
总结
本文提出一种三阶段递进式低质量人脸修复方案:首先借鉴VQGAN为高低质量人脸域分别训练带可学习码本的自编码器,挖掘双域独立特征;再通过特征块余弦相似度矩阵与位置约束交叉熵损失,完成双域特征空间对齐与关联;最后利用多头交叉注意力融合双域特征,结合Transformer预测高质量码本索引,依托冻结的高质量码本和解码器重建清晰人脸,通过多阶段专属损失协同优化,实现跨域人脸高质量修复。