单卡 RTX 4090 D · PyTorch 2.5 · CUDA 12.4 · TensorRT 10.x 面向:想从"会调 PyTorch"走到"能写算子、能上线模型"的工程师
不讲:玄学加速、贩卖焦虑、PPT 工程师才会写的"全栈优化"
0. 写在前面:为什么是这条路径
AI Infra 这个赛道,最近两年的招聘画像变得越来越清晰:上层会用 vLLM、SGLang、TensorRT-LLM 把模型跑起来;中层能写 Triton、能调 NCCL、能 profile 出热点;底层能下到 CUDA C++,知道一个 Kernel 在 SM 上是怎么排队执行的,也知道当 TensorRT 原生算子覆盖不到时,要怎么写一个 Plugin 把自己的 CUDA Kernel 接进推理引擎。
很多同学卡在第二层和第三层之间。看过 Kernel 教程、跑过 vector_add,但一被问到"你怎么把这个东西塞到一个真实的推理 pipeline 里去"就讲不清楚。这篇文章想做的事情很具体:用一张消费级的 RTX 4090 D,在不依赖 A100、不依赖云上集群的前提下,把 CUDA 编程 → 算子优化 → ONNX 自定义算子 → TensorRT Plugin 注册 → 端到端推理 这条链路完整跑通,并且每一步都讲清楚为什么这么做、什么时候不要这么做。
整篇文章大致分三段:
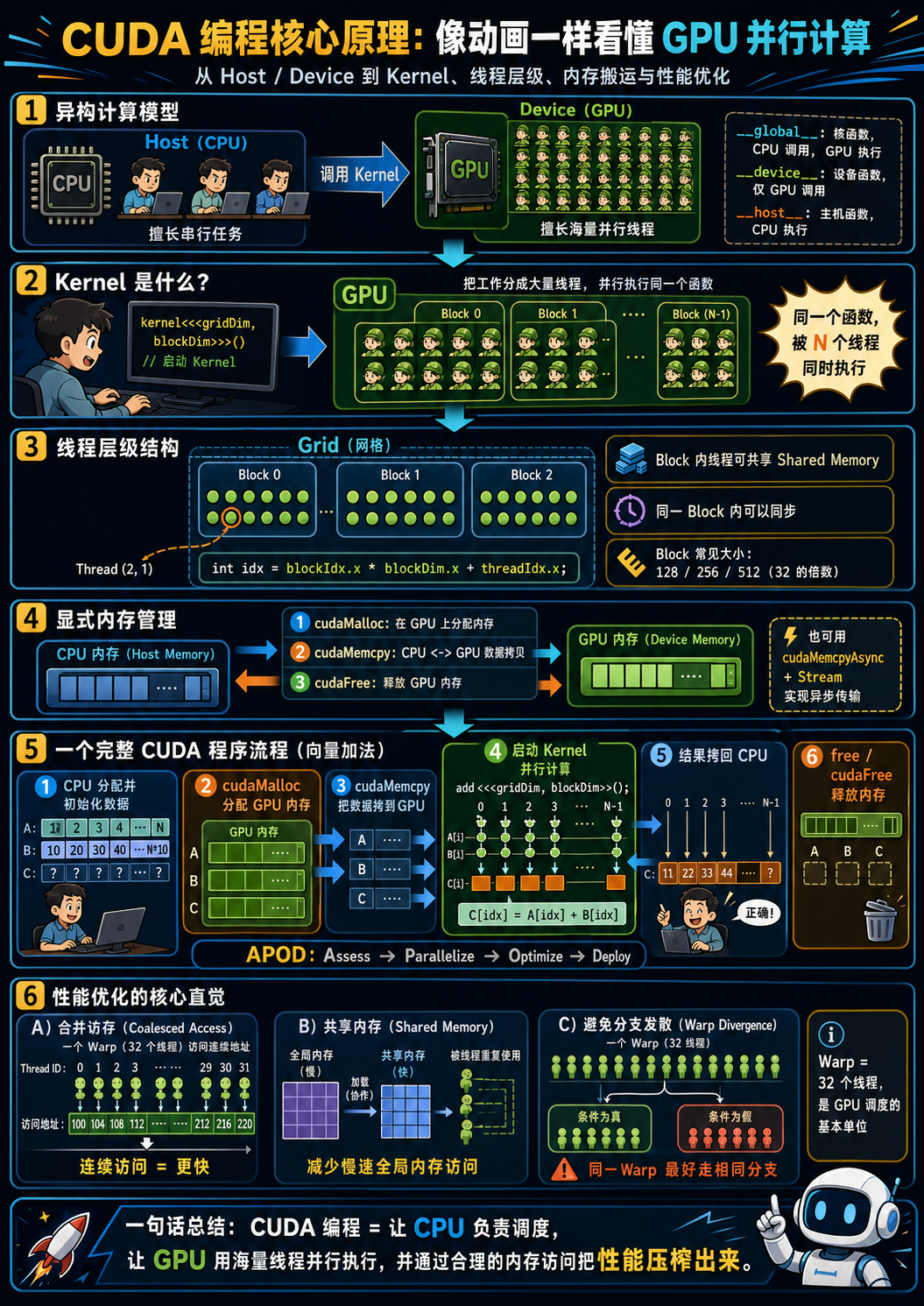
第一段是 CUDA 编程的最小心智模型。不会重复"GPU 有很多核心"这种废话,但会把 Grid/Block/Thread 这套抽象、显式内存管理、合并访存、Warp Divergence 这些概念,对应到 4090 这张卡的实际硬件参数上去。
第二段是工程化路径选择。Triton、PyTorch C++/CUDA Extension、纯 NVCC 这三条路在什么场景下分别是最优解,以及为什么我会推荐绝大多数人从 Triton 起步而不是直接啃 CUDA C++。
第三段是 Swin-Tiny 子图替换的 MVP。这是这篇文章最值得留意的部分------它不是在做"另一个 Swin-Tiny 推理加速",而是借 Swin-Tiny 这个真实模型,把 ONNX custom op → TensorRT Plugin 这条链路的每一个接缝都暴露出来。如果你打算把它写进简历,第八节有一份命名建议和面试追问清单。
声明:本文使用的环境是 Qwen3-ALL:v3.250810 镜像(Driver 580.76.05、CUDA 13.0、PyTorch 2.5.1+cu124、Python 3.12.3、单卡 RTX 4090 D 24GB),但所有代码片段在标准 CUDA 12.x + PyTorch 2.x 环境下都可以复现。
1. CUDA 的心智模型:异构计算到底在异构什么
绝大多数 CUDA 教程开头都会画一张 CPU 和 GPU 的对比图,然后说 "GPU has thousands of cores"。这话没错,但它会让初学者形成一个错误的直觉:以为 GPU 编程就是"把 for 循环并行化"。
更准确的心智模型是这样的:CPU 是一台延迟优化的机器,GPU 是一台吞吐量优化的机器。CPU 擅长在最短时间内处理一个串行任务(深分支预测、大缓存、乱序执行);GPU 擅长在单位时间内处理尽可能多的同质任务,但代价是单个任务的延迟可能比 CPU 还高。
这个差异决定了三件事:
第一,Host 和 Device 是物理上分离的两个世界 。CPU 看到的内存(DRAM)和 GPU 看到的显存(GDDR6X / HBM)是两套独立的物理设备,中间通过 PCIe 总线连接。这意味着任何一个 CUDA 程序的生命周期里,必然存在显式的"数据搬运"步骤------这是 Python/PyTorch 用户最容易忽视的成本。在 4090 这种消费卡上,PCIe Gen4 x16 的理论带宽大约 32 GB/s,而显存到 SM 的本地带宽是 1008 GB/s,差了 30 倍以上。换句话说,一次错误的 Host↔Device 拷贝可能就把你整个 Kernel 的优化白做了。
第二,GPU 的并行不是"自动并行",而是"显式分块"。你需要告诉 GPU:这个任务我打算切成多少个独立单元、每个单元负责处理哪部分数据、它们之间要不要通信。这就是 Grid/Block/Thread 这套层级。
第三,性能瓶颈几乎从来不是算力,而是访存 。这一点对所有现代 GPU 都成立,对 4090 尤其成立。RTX 4090(包括 4090 D)在 FP16 Tensor Core 上的理论算力高达约 165 TFLOPS(开启稀疏可达 330 TFLOPS),但显存带宽只有 1008 GB/s。换算一下:每读取 1 字节数据,理论上可以做 165 次 FP16 浮点运算才能"喂饱"算力。也就是说,只要你的 Kernel 算力密度不到这个数量级,性能就由访存决定。这就是为什么后面所有优化的核心都围绕"减少访存、合并访存、复用访存"这三件事。
记住这三个事实,你才会明白为什么 CUDA 编程的优化方向跟 CPU 完全不同。
2. 一个最小但完整的 CUDA Kernel:从代码到硬件
现在写一个最小但完整的 CUDA 程序。这部分代码不是为了"教学",而是为了把后面所有概念锚定到具体行号。
cpp
// vector_add.cu
#include <cuda_runtime.h>
#include <cstdio>
// __global__ 修饰符:声明这是一个核函数(Kernel)
// 由 CPU 调用、GPU 上的 N 个线程并行执行
__global__ void vector_add(const float* a, const float* b, float* c, int n) {
// 每个线程根据自己的全局 ID 决定处理哪个元素
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < n) {
c[idx] = a[idx] + b[idx];
}
}
int main() {
const int N = 1 << 20; // 1M 个元素
const size_t bytes = N * sizeof(float);
// 1) Host 内存分配与初始化
float *h_a = (float*)malloc(bytes);
float *h_b = (float*)malloc(bytes);
float *h_c = (float*)malloc(bytes);
for (int i = 0; i < N; ++i) { h_a[i] = 1.0f; h_b[i] = 2.0f; }
// 2) Device 内存分配
float *d_a, *d_b, *d_c;
cudaMalloc(&d_a, bytes);
cudaMalloc(&d_b, bytes);
cudaMalloc(&d_c, bytes);
// 3) Host → Device 拷贝
cudaMemcpy(d_a, h_a, bytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, bytes, cudaMemcpyHostToDevice);
// 4) 配置并行规模并启动 Kernel
int block_size = 256;
int grid_size = (N + block_size - 1) / block_size;
vector_add<<<grid_size, block_size>>>(d_a, d_b, d_c, N);
// 5) Device → Host 拷贝结果
cudaMemcpy(h_c, d_c, bytes, cudaMemcpyDeviceToHost);
// 6) 校验 + 释放
printf("c[0] = %f, c[N-1] = %f\n", h_c[0], h_c[N-1]);
cudaFree(d_a); cudaFree(d_b); cudaFree(d_c);
free(h_a); free(h_b); free(h_c);
return 0;
}编译命令(针对 4090 的 Ada Lovelace 架构 sm_89 显式指定):
bash
nvcc -O3 -arch=sm_89 vector_add.cu -o vector_add
./vector_add这段代码涵盖了 CUDA 编程的全部六个生命周期阶段:Host 分配 → Device 分配 → H2D 拷贝 → Kernel 启动 → D2H 拷贝 → 释放。任何一个 CUDA 程序,不管多复杂,都跑不出这个框架。
下面把里面的概念逐一拆开。
2.1 三种函数修饰符
CUDA 用三个修饰符标注函数运行的位置:
__global__:核函数。CPU 调用,GPU 上并行执行。返回值必须是void。__device__:设备函数。GPU 调用,GPU 上执行,可以有返回值,不能从 CPU 直接调用。__host__:主机函数。CPU 调用,CPU 上执行。这是默认值,平时不写也行。
__host__ __device__ 可以同时写,编译器会生成两份代码,让函数在 CPU 和 GPU 上都能调用------这在写一些通用工具函数(比如自定义的激活函数)时很有用。
2.2 Grid / Block / Thread 是什么
<<<grid_size, block_size>>> 这个看起来很奇怪的语法,是 CUDA 对 C++ 的扩展,叫 kernel launch configuration。它告诉 GPU:本次启动总共要起多少个线程、按什么形状组织。
层级关系是:
Grid ← 一次 Kernel 启动产生的所有线程
├── Block 0 ← 一组线程,可以共享 Shared Memory,可以同步
│ ├── Thread 0
│ ├── Thread 1
│ └── ... (最多 1024)
├── Block 1
└── ...这套抽象不是为了好看,它是 GPU 物理结构的直接映射:
- 一个 Block 会被调度到一个 SM(Streaming Multiprocessor)上执行,整个生命周期不会迁移到别的 SM。
- 一个 Block 内的线程被进一步切成若干个 Warp(32 个线程一组),Warp 是 GPU 真正的执行单位------一个 Warp 内的 32 个线程在同一个时钟周期执行同一条指令(SIMT,Single Instruction Multiple Threads)。
- 一个 SM 同时驻留多个 Block,通过快速切换来掩盖访存延迟。
RTX 4090 D 有 114 个 SM,每个 SM 上限 1536 个常驻线程、最多 1024 个线程一个 Block。这些数字决定了你 Block size 的合理范围:通常选 128、256 或 512,必须是 32 的倍数(不然最后一个 Warp 里有线程被浪费)。256 是一个工程上的甜点值,能在大多数 Kernel 上让 SM 占用率(occupancy)落在合理区间。
2.3 线程索引的真实含义
int idx = blockIdx.x * blockDim.x + threadIdx.x;这一行新手常常背下来但不理解。换种写法你就懂了:
全局线程 ID = 我所在 Block 的编号 × 每个 Block 的线程数 + 我在 Block 内的编号blockIdx、blockDim、threadIdx 都是 CUDA 提供的内置变量,类型是 dim3(有 .x .y .z 三个分量,对应一维、二维、三维的索引方式)。处理一维数组只用 .x;处理图像可以用 .x .y 二维;处理三维数据(比如视频或 3D 卷积)可以用上 .z。
2.4 显式内存管理的几个 API
| API | 作用 | 备注 |
|---|---|---|
cudaMalloc(&ptr, bytes) |
GPU 上分配 | 注意是 &ptr,传指针的指针 |
cudaMemcpy(dst, src, bytes, kind) |
同步拷贝 | kind 有 H2D / D2H / D2D / Default |
cudaMemcpyAsync(...) |
异步拷贝 | 配合 Stream 使用,可以与 Kernel 并发 |
cudaFree(ptr) |
GPU 上释放 | 与 cudaMalloc 配对 |
cudaMallocHost / cudaFreeHost |
Pinned Host 内存 | 拷贝带宽显著高于普通 malloc |
实战中有几个经常踩的坑:
cudaMalloc不便宜。它会触发驱动层的同步,大量频繁分配会显著拖慢主流程。生产代码里通常用内存池(cuMemPool / PyTorch 的 caching allocator)。- 同步拷贝会阻塞 Stream 。如果你想让拷贝和计算 overlap,必须用
cudaMemcpyAsync+cudaStream_t。 malloc出来的 Host 内存默认是 pageable 的 ,拷贝到 GPU 时会先经过一个隐藏的 pinned buffer,带宽打折。需要高带宽的场景用cudaMallocHost。
3. 性能优化的三把斧(针对 4090 的版本)
把上面那个 vector_add 跑起来不难,难的是写出一个真正能压榨 4090 的 Kernel。这一节讲三个最高优先级的优化点,每个都给出"为什么"以及"怎么做"。
3.1 合并访存
问题:GPU 访问全局显存时,硬件会以 32 字节、64 字节或 128 字节的事务为单位进行。如果一个 Warp 里 32 个线程访问的 32 个地址散落在多个事务中,硬件就需要发起多次访存,带宽利用率跌到地板。
怎么做 :让同一个 Warp 内的相邻线程访问相邻的内存地址。具体到代码,就是让你的 idx 沿着 threadIdx.x 连续递增,并且数据在内存里也是连续排布的。
举一个对比例子:
cpp
// ✅ 合并访存:相邻线程读相邻位置
int idx = blockIdx.x * blockDim.x + threadIdx.x;
float v = data[idx];
// ❌ 跨步访存:相邻线程读相隔很远的位置
int idx = (blockIdx.x * blockDim.x + threadIdx.x) * stride;
float v = data[idx]; // 当 stride > 1 时带宽利用率显著下降二维矩阵转置是这个问题的经典反例------不管你怎么写,读和写至少有一边不是合并访存。解法是用共享内存做"缓冲",下面就讲。
3.2 共享内存与 Tiling
Shared Memory 是每个 SM 上的一块片上 SRAM,访问延迟比全局显存低一个数量级(约 30 个时钟周期 vs 400+),带宽也高得多。但容量很小------4090 上每个 SM 大约 100 KB(与 L1 cache 共享),每个 Block 实际可用通常在 48~96 KB 之间。
怎么用 :把全局显存中需要重复访问的数据,先一次性加载到 Shared Memory,让 Block 内的线程在快内存里反复读写,最后再写回全局显存。这就是 Tiling(分块)思想。
矩阵乘法是最经典的应用。一个朴素的 C = A * B,每个 C 的元素都要从 A 读一行、从 B 读一列,存在大量重复读。Tiling 后每个 Block 协作加载 A 的一个子块和 B 的一个子块到 Shared Memory,然后 Block 内复用这些数据完成计算,全局访存量直接降一个数量级。
代码骨架(简化):
__global__ void matmul_tiled(const float* A, const float* B, float* C, int N) {
__shared__ float tile_A[TILE][TILE];
__shared__ float tile_B[TILE][TILE];
int row = blockIdx.y * TILE + threadIdx.y;
int col = blockIdx.x * TILE + threadIdx.x;
float acc = 0.0f;
for (int t = 0; t < N / TILE; ++t) {
tile_A[threadIdx.y][threadIdx.x] = A[row * N + (t * TILE + threadIdx.x)];
tile_B[threadIdx.y][threadIdx.x] = B[(t * TILE + threadIdx.y) * N + col];
__syncthreads(); // 等所有线程加载完成
for (int k = 0; k < TILE; ++k)
acc += tile_A[threadIdx.y][k] * tile_B[k][threadIdx.x];
__syncthreads(); // 等所有线程算完,再加载下一块
}
C[row * N + col] = acc;
}这里有两个细节值得记住:__syncthreads() 是 Block 内同步的栅栏,必须保证 Block 里所有线程都到达;Shared Memory 的访问也有"bank conflict"问题------32 个 bank,如果同一 Warp 内多个线程访问同一 bank 的不同地址,就会被串行化。绕开办法通常是给 Shared Memory 数组加 padding(比如 tile_A[TILE][TILE+1])。
3.3 避免 Warp Divergence
问题 :一个 Warp 内的 32 个线程是 SIMT 执行的------同一时刻执行同一条指令。如果这 32 个线程因为 if/else 走了不同分支,硬件会先执行其中一个分支(让另一部分线程闲置),再执行另一个分支。两条路径串行执行,吞吐直接腰斩。
怎么做:
- 把分支条件按 Warp 边界对齐。比如
if (threadIdx.x < 16)这种 Warp 内分裂的写法是最差的;if ((threadIdx.x / 32) % 2 == 0)这种以 Warp 为粒度的分支就没问题。 - 用算术替代分支。
y = (x > 0) ? x : 0可以写成y = max(x, 0.0f),让编译器用fmax指令而不是真的产生跳转。 - 数据预排序。比如稀疏计算里,按值的非零情况把数据先重排,让同一 Warp 处理同质数据。
3.4 4090 D 特有的精度陷阱
这是一条在数据中心卡上不会遇到、但在消费卡上必须知道的事实:RTX 4090 在使用 FP32 累加器的 Tensor Core 时,性能相对低。
具体来说:4090 的 Tensor Core 在 FP16 输入 + FP16 累加 时的算力,是 FP16 输入 + FP32 累加 的两倍左右。这个差异在 A100 上几乎不存在,因为 A100 的 FP32 累加是全速的,但 NVIDIA 在消费卡上对 FP32 累加路径做了限制。
实际影响:在写 Attention 这类对累加精度敏感的算子时,如果你照搬数据中心卡的"标准做法"(FP16 输入、FP32 累加),4090 上性能会被打折扣。FlashInfer 等推理引擎的实测结论是:在 RTX 4090 上把 Q·Kᵀ 阶段的累加精度从 FP32 切到 FP16,可以带来高达 50% 的端到端性能提升。代价是数值精度变差,需要做 mask 修正或重新校准 scaling,不是无脑切换。
记住这个事实,你会在调优时少走很多弯路。
4. 三条工程化路径:Triton、PyTorch Extension、纯 NVCC
到这里你已经能写一个独立的 .cu 文件。但在真实工作里,纯粹的 NVCC 路径不一定是最优解。下面把三条路径放在一起对比。
4.1 路径 A:OpenAI Triton
Triton 是这两年 AI Infra 领域最重要的工具变化之一。它让你用 Python 语法写 GPU Kernel,然后由 Triton 的编译器(基于 MLIR)生成 PTX。
最直观的好处:你不用手动管理 Shared Memory、不用手动算合并访存、不用关心 Warp 这一层抽象。Triton 在更高的抽象上做了这些自动化。
一个 vector_add 的 Triton 版本:
python
import torch
import triton
import triton.language as tl
@triton.jit
def vector_add_kernel(a_ptr, b_ptr, c_ptr, n, BLOCK_SIZE: tl.constexpr):
pid = tl.program_id(axis=0)
offsets = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
mask = offsets < n
a = tl.load(a_ptr + offsets, mask=mask)
b = tl.load(b_ptr + offsets, mask=mask)
tl.store(c_ptr + offsets, a + b, mask=mask)
def vector_add(a: torch.Tensor, b: torch.Tensor) -> torch.Tensor:
c = torch.empty_like(a)
n = a.numel()
BLOCK_SIZE = 1024
grid = (triton.cdiv(n, BLOCK_SIZE),)
vector_add_kernel[grid](a, b, c, n, BLOCK_SIZE=BLOCK_SIZE)
return c注意几个对比 CUDA C++ 的差异:
- 没有
__global__修饰,用@triton.jit装饰器。 - 没有
cudaMalloc / cudaMemcpy,直接吃 PyTorch Tensor。 - 一个 Triton "program" 不是一个线程,而是一个 Block------你处理的是向量化的数据,长度由
BLOCK_SIZE决定。 - 编译时常量用
tl.constexpr标注,方便 Triton 做特化。
实测下来,Triton 写出来的 Kernel 性能能稳定达到手写 CUDA 的 80%~100%,而开发效率高 3~10 倍。对绝大多数 AI Infra 工程师来说,Triton 是默认选项。只有以下几种情况才需要下到 CUDA C++:
- 需要使用 CUTLASS 这类 C++ 模板库做极致 GEMM 优化。
- 需要深度控制 Tensor Core 的 mma 指令(Triton 在某些 layout 上仍有限制)。
- 需要写 TensorRT Plugin(Plugin 必须是 C++/CUDA,这是后面的核心场景)。
4.2 路径 B:PyTorch C++/CUDA Extension
PyTorch Extension 是把原生 CUDA Kernel 接入 Python 生态的标准方式。它让你写 .cu 文件,然后被 PyTorch 当作一个普通的 op 调用,甚至可以被 torch.compile / autograd 识别。
典型项目结构:
my_op/
├── setup.py # 编译入口
├── csrc/
│ ├── my_op.cpp # C++ wrapper(绑定到 Python)
│ └── my_op_kernel.cu # CUDA Kernel 实现
└── my_op/
└── __init__.py # Python 接口核心是 setup.py 里用 torch.utils.cpp_extension.CUDAExtension:
python
from setuptools import setup
from torch.utils.cpp_extension import BuildExtension, CUDAExtension
setup(
name="my_op",
ext_modules=[
CUDAExtension(
name="my_op._C",
sources=["csrc/my_op.cpp", "csrc/my_op_kernel.cu"],
extra_compile_args={
"cxx": ["-O3"],
"nvcc": ["-O3", "-arch=sm_89"], # 4090 D 显式指定架构
},
)
],
cmdclass={"build_ext": BuildExtension},
)C++ wrapper 大致长这样:
#include <torch/extension.h>
void my_op_cuda(torch::Tensor a, torch::Tensor b, torch::Tensor c);
torch::Tensor my_op(torch::Tensor a, torch::Tensor b) {
TORCH_CHECK(a.is_cuda(), "a must be on CUDA");
TORCH_CHECK(a.is_contiguous(), "a must be contiguous");
auto c = torch::empty_like(a);
my_op_cuda(a, b, c);
return c;
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("my_op", &my_op, "Custom CUDA op");
}如果不想搞 setup.py,PyTorch 还提供了 torch.utils.cpp_extension.load_inline,可以在 Python 脚本里就地编译------非常适合实验和快速迭代。
4.3 路径 C:纯 NVCC
最朴素的方式:写 .cu,用 nvcc 编译成可执行文件或 .so,独立运行。
适用场景就两类:第一是学习 CUDA 语法本身,需要一个干净的环境;第二是给 Nsight Compute / Nsight Systems 做 profiling,因为剥离掉 Python 框架后,profiler 的输出更干净,更容易定位 SM 上发生了什么。
针对 RTX 4090 D 的标准编译命令:
bash
nvcc -O3 -arch=sm_89 \
--use_fast_math \
-lineinfo \
my_kernel.cu -o my_kernel-arch=sm_89 是 Ada Lovelace 架构的代号,必须显式指定,否则 nvcc 默认编出来的二进制可能跑在 4090 上不能享受新架构特性(比如新的 LOP3 指令、新的 mma 指令)。-lineinfo 让 Nsight 能把 SASS 反汇编对应回源码行,profile 时非常有用。
4.4 决策矩阵
把三条路径放在一起:
| 场景 | 推荐路径 | 原因 |
|---|---|---|
| 实现一个新算子,需要在 PyTorch 训练里用 | Triton | 开发效率最高,自动接 autograd |
| 给 vLLM / SGLang 写定制 Kernel | Triton 优先,CUTLASS 兜底 | 这两个框架 Kernel 主体已经 Triton 化 |
| 写 TensorRT Plugin | CUDA C++ | TensorRT Plugin API 是 C++,没得选 |
| 调用 CUTLASS 做极致 GEMM | PyTorch Extension | CUTLASS 是 C++ 模板库 |
| 学习 CUDA、做 profiling 实验 | 纯 NVCC | 最干净的环境 |
| Kernel 需要稀有指令(如 ldmatrix, cp.async) | CUDA C++ | Triton 还没完全覆盖 |
这篇文章后半段要走的 TensorRT Plugin 路径,必然要用 CUDA C++,因为 TensorRT 的 Plugin API 没有 Python 入口。但写 Plugin 之前,先用 Triton 验证算法正确性、再翻译成 CUDA C++ 是一条稳妥的工程路径。
5. 从 CUDA Kernel 到 TensorRT Plugin:为什么要做这一跃迁
到目前为止,我们写出来的 Kernel 都是被 PyTorch 直接调用的。这在训练阶段没问题,但推理阶段------尤其是要做线上部署的推理------通常会换一个推理引擎,TensorRT 是其中最常见的一个。
TensorRT 做了什么?它接受一个模型描述(最常见的输入格式是 ONNX),做图优化(算子融合、常量折叠、精度选择、Layer 排布),然后为目标 GPU 生成一个序列化的 engine 文件。运行时直接 deserialize 这个 engine 进行推理,省去了所有 Python overhead 和动态 dispatch。
但 TensorRT 不是无所不能的。它内置的算子集合是有限的,主要覆盖 CV/NLP 里的高频算子(Conv、MatMul、LayerNorm、Softmax、Attention 的部分变种、各种 Elementwise、Reduction 等)。当你的模型里出现一个 TensorRT 不认识的算子,或者你想用一个比 TensorRT 内置实现更快的算子,怎么办?
答案就是 Plugin:TensorRT 给你开的一个口子,让你把自己写的 CUDA Kernel 包装成一个"假装是原生算子"的东西,注册到 TensorRT 的运行时,让 ONNX parser 在解析模型时能够识别并使用它。
整条链路是这样的:
PyTorch Model
│ torch.onnx.export
▼
ONNX Graph (含一个或多个 custom op 占位节点)
│ trtexec / TensorRT API
▼
TensorRT ONNX Parser (查找 plugin registry)
│
▼
TensorRT Plugin (你写的 C++/CUDA 实现)
│ build_engine
▼
Serialized Engine (.engine / .plan)
│ runtime
▼
Inference关键的接缝有三个,每一个都可能让一个新手卡两天:
- PyTorch 怎么把一个普通子图导出成 ONNX 里的"自定义节点"? 默认导出会把每个算子展开成 ONNX 标准算子,你需要主动告诉 PyTorch:"这一段子图,请用我指定的 op_type 打包"。
- ONNX 里的自定义节点怎么对应到 TensorRT Plugin? 通过名字匹配------你的 ONNX 节点 op_type 必须等于 TensorRT Plugin 注册时的 plugin_name,并且 plugin 必须先注册到 plugin registry。
- Plugin 自己要正确实现一组生命周期接口:构造、序列化、反序列化、shape 推导、执行(这才是真正调你的 CUDA Kernel 的地方)。
后面几节会把这些接缝一一打开。
6. Swin-Tiny 子图 MVP:靶场模型怎么用
很多人选错模型,导致项目卡死。这一节先讲清楚为什么用 Swin-Tiny,以及怎么用。
6.1 为什么是 Swin-Tiny
swin-tiny 全名是 swin_tiny_patch4_window7_224,是微软 Swin Transformer 的最小尺寸版本,输入 224×224、参数量约 28M,用作 ImageNet 分类 backbone。它有三种主流来源:
python
# 来源一:torchvision
from torchvision.models import swin_t, Swin_T_Weights
model = swin_t(weights=Swin_T_Weights.IMAGENET1K_V1)
# 来源二:timm(社区最常用)
import timm
model = timm.create_model("swin_tiny_patch4_window7_224", pretrained=True)
# 来源三:Hugging Face(适合标准对齐)
# microsoft/swin-tiny-patch4-window7-224我推荐用 torchvision 版本------权重加载稳定,导出 ONNX 的兼容性最好。
为什么是它,不是 ResNet 也不是 LLaMA?
ResNet 系列在 ONNX 里展开后基本只有 Conv / BN / ReLU / Add / Pool / Gemm 这些 TensorRT 完美支持的算子。你写 Plugin 没有动机------TensorRT 原生跑得已经很好了,做 Plugin 反而更慢。
LLM Attention 又是另一个极端。FlashAttention / PagedAttention 这种东西,dynamic shape、KV cache 管理、causal mask 一上来全是工程细节,一个 MVP 根本做不完。
Swin-Tiny 卡在中间这个甜点位置:它既有 TensorRT 原生支持得好的部分(Conv、LayerNorm、MatMul),也有大量 Window Attention、Patch Merging、Roll/Slice 这类需要展开成几十个小算子的子图------这些子图正好是 Plugin 介入的理想场景。
6.2 一个常见的误解
不要把目标定成"把整个 Swin-Tiny 做成一个 Plugin"。这会让你的项目变成一个庞大但虚的工程。Swin-Tiny 在这个项目里的角色是靶场------一个真实的 ONNX 图,让你能在里面挑一个合适的子图,证明 ONNX custom op → TensorRT Plugin 这条链路能跑通。
更准确的项目命名应该是:
基于 Swin-Tiny 子图的 ONNX 自定义算子到 TensorRT Plugin 接入验证
ONNX Custom Op to TensorRT Plugin MVP based on a Swin-Tiny Subgraph
6.3 子图选择:不要选 WindowAttention
新手最容易犯的错:上来就想把 Window Attention 做成 Plugin。一天的 MVP 时间里,你大概率会卡在这些坑里:
- Window partition / reverse 的 dynamic shape 处理
- Relative position bias 的 broadcast
- Attention mask 的拼接
- Reshape / Transpose 的 layout 选择
- FP16 下的精度对齐
更务实的选择有三个,按推荐度排序:
- LayerNorm 子图 (最推荐)。Swin 的 Block 里反复出现 LayerNorm,子图边界极其清晰:输入一个
[B, N, C]Tensor,输出一个相同 shape 的 Tensor,参数是 weight 和 bias。Plugin 实现可以只用一个 Kernel。 - GELU + Bias 融合 。Swin 的 MLP 里典型的
Linear → Bias Add → GELU → Linear结构,把中间的Bias + GELU融合成一个 op,可以省一次全局显存读写。 - Patch Merging 中的 Slice + Concat 子图。这是 Swin 特有的下采样操作,TensorRT 原生支持但生成的 Layer 比较多,融合成一个 op 有性能空间。
下面以 LayerNorm Plugin 为例走完整条链路,因为它最具教学价值------既简单到一天能做完,又涵盖了 Plugin 开发的全部接口。
6.4 阶段拆解:六步 MVP
阶段 1:导出 baseline ONNX,验证 TensorRT 能原生跑通
阶段 2:用 PyTorch symbolic 把目标子图替换成 custom op
阶段 3:实现 TensorRT Plugin(C++/CUDA)
阶段 4:把 Plugin 注册到 plugin registry 并编译成 .so
阶段 5:用注册后的 Plugin 重新 build engine
阶段 6:三方对齐 PyTorch / ONNXRuntime / TensorRT 输出下面分阶段讲关键代码。
阶段 1:导出 baseline
import torch
from torchvision.models import swin_t, Swin_T_Weights
model = swin_t(weights=Swin_T_Weights.IMAGENET1K_V1).eval().cuda()
x = torch.randn(1, 3, 224, 224, device="cuda")
torch.onnx.export(
model, x, "swin_tiny_baseline.onnx",
input_names=["input"], output_names=["logits"],
opset_version=17,
dynamic_axes={"input": {0: "batch"}, "logits": {0: "batch"}},
)然后用 trtexec 验证能不能 build engine:
bash
trtexec --onnx=swin_tiny_baseline.onnx \
--saveEngine=swin_tiny_baseline.engine \
--fp16 \
--memPoolSize=workspace:2048如果这一步就报 unsupported op,先把 TensorRT 升级到 10.x 再说。
阶段 2:替换为 custom op
PyTorch 的 torch.onnx 提供了 symbolic 注册机制,可以让你在导出时把某个 Python 函数替换成自定义 ONNX 节点:
python
import torch
from torch.onnx import register_custom_op_symbolic
# 自定义算子:行为上等价于 nn.LayerNorm,但导出时打成 custom op
class CustomLayerNorm(torch.autograd.Function):
@staticmethod
def forward(ctx, x, weight, bias, eps):
return torch.nn.functional.layer_norm(
x, weight.shape, weight, bias, eps
)
@staticmethod
def symbolic(g, x, weight, bias, eps):
# 关键:op_type 写成 "CustomLayerNorm",命名空间 "trt"
return g.op(
"trt::CustomLayerNorm",
x, weight, bias,
eps_f=eps,
)
# 在模型里把所有 nn.LayerNorm 替换成 CustomLayerNorm.apply
def replace_layernorm(module):
for name, child in module.named_children():
if isinstance(child, torch.nn.LayerNorm):
ln = child
class _Wrap(torch.nn.Module):
def forward(self, x):
return CustomLayerNorm.apply(x, ln.weight, ln.bias, ln.eps)
setattr(module, name, _Wrap())
else:
replace_layernorm(child)
replace_layernorm(model)再次导出 ONNX,你会看到原本展开成十几个节点的 LayerNorm 现在变成了一个 trt::CustomLayerNorm 节点。
阶段 3:实现 TensorRT Plugin
TensorRT 10.x 推荐用 IPluginV3 接口(旧版的 IPluginV2DynamicExt 还能用但已不推荐)。Plugin 类需要实现的核心方法:
cpp
class CustomLayerNormPlugin : public nvinfer1::IPluginV3,
public nvinfer1::IPluginV3OneCore,
public nvinfer1::IPluginV3OneBuild,
public nvinfer1::IPluginV3OneRuntime {
public:
// 1) Core 接口
char const* getPluginName() const noexcept override { return "CustomLayerNorm"; }
char const* getPluginVersion() const noexcept override { return "1"; }
char const* getPluginNamespace() const noexcept override { return "trt"; }
// 2) Build 接口:输入输出形状推导
int32_t getNbOutputs() const noexcept override { return 1; }
int32_t getOutputShapes(
nvinfer1::DimsExprs const* inputs, int32_t nbInputs,
/*...*/ ) noexcept override {
// LayerNorm 输出 shape == 输入 shape
outputs[0] = inputs[0];
return 0;
}
// 3) Runtime 接口:真正执行 Kernel
int32_t enqueue(
nvinfer1::PluginTensorDesc const* inputDesc,
nvinfer1::PluginTensorDesc const* outputDesc,
void const* const* inputs, void* const* outputs,
void* workspace, cudaStream_t stream) noexcept override {
auto const& dims = inputDesc[0].dims;
int B = dims.d[0], N = dims.d[1], C = dims.d[2];
layernorm_kernel_launch(
(const float*)inputs[0],
(const float*)inputs[1], // weight
(const float*)inputs[2], // bias
(float*)outputs[0],
B * N, C, mEps, stream);
return 0;
}
// 4) 序列化:用于 engine 持久化
nvinfer1::PluginFieldCollection const* getFieldsToSerialize() noexcept override {
// 把 mEps 等参数打包返回
}
private:
float mEps;
};而真正的 LayerNorm Kernel(CUDA 部分)是这样的------每个 Block 处理一个 token,Block 内的线程协作完成 mean/var 的 reduction:
cpp
__global__ void layernorm_kernel(
const float* __restrict__ x,
const float* __restrict__ weight,
const float* __restrict__ bias,
float* __restrict__ y,
int N, int C, float eps) {
int row = blockIdx.x;
if (row >= N) return;
extern __shared__ float smem[];
const float* x_row = x + row * C;
float* y_row = y + row * C;
// 第一遍:求 mean 和 var(用 Welford 算法可以更稳,这里写朴素版)
float sum = 0.0f, sq_sum = 0.0f;
for (int i = threadIdx.x; i < C; i += blockDim.x) {
float v = x_row[i];
sum += v;
sq_sum += v * v;
}
// Block 内 reduce ------ 这里省略了 warp shuffle 的实现,生产代码用 cub::BlockReduce
sum = block_reduce_sum(sum, smem);
sq_sum = block_reduce_sum(sq_sum, smem);
__shared__ float mean, rstd;
if (threadIdx.x == 0) {
mean = sum / C;
float var = sq_sum / C - mean * mean;
rstd = rsqrtf(var + eps);
}
__syncthreads();
// 第二遍:归一化 + affine
for (int i = threadIdx.x; i < C; i += blockDim.x) {
float v = (x_row[i] - mean) * rstd;
y_row[i] = v * weight[i] + bias[i];
}
}工程细节:生产代码会用 __half2 做向量化访存、用 cub::BlockReduce 替代手写 reduce、用 Welford 算法保持数值稳定。但这个版本足够通过对齐验证。
阶段 4:注册 Plugin
Plugin 必须注册到 TensorRT 的 Plugin Registry,ONNX parser 才能找到它。注册有两种方式:
方式一 :在你的 .so 库里实现 IPluginCreatorV3One,然后在 .so 加载时通过 REGISTER_TENSORRT_PLUGIN(...) 宏自动注册。运行时只要 dlopen 这个 .so,Plugin 就在 registry 里了。
方式二 :用 --plugins 参数让 trtexec 自动加载:
bash
trtexec --onnx=swin_tiny_custom.onnx \
--plugins=./libcustom_layernorm.so \
--saveEngine=swin_tiny_custom.engine \
--fp16注册时最关键的两个名字必须严格对齐:ONNX 节点的 op_type 是 CustomLayerNorm,命名空间是 trt,那 Plugin Creator 返回的 getPluginName() 必须返回 "CustomLayerNorm"、getPluginNamespace() 必须返回 "trt"。一个字母不对,parser 就报 unsupported op,新手最常死在这里。
阶段 5:构建 engine
跑通 trtexec 命令,看到 &&&& PASSED 就算成功。
阶段 6:三方对齐
最后一步,也是简历项目里最值钱的一步:用同一份输入,跑三遍,对比输出。
python
import torch, numpy as np, onnxruntime as ort
import tensorrt as trt
x = torch.randn(1, 3, 224, 224)
# 1. PyTorch baseline
y_torch = model(x.cuda()).cpu().numpy()
# 2. ONNXRuntime(不依赖 TensorRT,验证 ONNX 图本身正确)
sess = ort.InferenceSession("swin_tiny_baseline.onnx", providers=["CUDAExecutionProvider"])
y_ort = sess.run(None, {"input": x.numpy()})[0]
# 3. TensorRT with Plugin
y_trt = run_trt_engine("swin_tiny_custom.engine", x.numpy()) # 自己实现的 helper
# 三方对齐
print("ORT vs Torch:", np.max(np.abs(y_ort - y_torch)))
print("TRT vs Torch:", np.max(np.abs(y_trt - y_torch)))FP32 下能对齐到 1e-4 量级;FP16 下能对齐到 5e-3 量级。如果差太多,多半是 Plugin 里 Kernel 的累加精度或者 mean/var 的实现写错了。
7. 踩坑清单(按出现频率排序)
这一节把我和身边同事在做这条链路时踩过的坑集中列出来,作为对照:
坑 1:ONNX export 报 "Couldn't export operator" 通常是因为 PyTorch 的某个算子没有 ONNX symbolic。解法是升级 opset_version(17 通常够用)、或者用 torch.onnx.register_custom_op_symbolic 手动注册一个 symbolic。
坑 2:trtexec 报 "No importer registered for op: CustomLayerNorm" 99% 是 Plugin 没注册成功。检查三件事:.so 是否被 --plugins 加载、getPluginName/getPluginNamespace 是否和 ONNX 节点完全一致、Creator 类是否通过 REGISTER_TENSORRT_PLUGIN 宏注册。
坑 3:Plugin enqueue 报 misaligned address CUDA Kernel 用 vectorized load(比如 float4、__half2)时,要求地址对齐。解法是加一行 assert(reinterpret_cast<uintptr_t>(ptr) % 16 == 0) 或者退化到标量 load。
坑 4:FP16 精度差很多 LayerNorm 在 FP16 下要求 mean/var 用 FP32 累加,最后再 cast 回 FP16。这是常识但很多人写第一版会忘。
坑 5:dynamic shape 下 engine 反复 rebuild Plugin 的 getOutputShapes 必须用 DimsExprs 表达 symbolic 形状,不能写成具体数字,否则一换 batch size 就重新构建。
坑 6:engine 反序列化失败 Plugin 的 getFieldsToSerialize 和反序列化构造函数必须严格对应。mEps 序列化成什么类型,反序列化就要按什么类型读,连字节序都一致。
坑 7:Workspace 不够 Plugin 如果需要临时显存,要正确实现 getWorkspaceSize,并且在 trtexec 里用 --memPoolSize=workspace:N 给够。
坑 8:4090 的 FP16 累加问题(前面提过) Attention 类 Plugin 在消费卡上需要权衡 FP16 vs FP32 累加,不要照搬 A100 的实现。
8. 把这个项目写进简历:命名、追问、答案
最后讲一个很多技术博客不愿意讲、但对求职最有价值的事:怎么把这个项目写得让面试官一眼就知道你做了什么、做到了什么深度。
8.1 不好的命名 vs 好的命名
❌ "Swin-Tiny TensorRT 推理加速" 让人误以为你做了完整模型加速,但你只做了一个子图,会被追问到爆。
❌ "基于 CUDA 的 Transformer 算子优化" 太大太空,没有任何信息量。
✅ "基于 Swin-Tiny 子图的 ONNX 自定义算子到 TensorRT Plugin 接入验证(LayerNorm Plugin MVP)" 精确到具体子图、具体接入路径、具体规模。
8.2 简历句式模板
在 RTX 4090 D(CUDA 12.4 / TensorRT 10.x)上完成 Swin-Tiny 模型的 ONNX 导出与 TensorRT Plugin 接入实验:用
torch.onnxsymbolic 机制将模型中所有 LayerNorm 子图替换为命名空间为trt的自定义节点;基于IPluginV3实现 LayerNorm Plugin(含 Welford reduction、FP32 累加路径、FP16 输入输出),完成 Plugin Registry 注册、engine 构建、序列化/反序列化全流程;在 PyTorch / ONNXRuntime / TensorRT 三端做精度对齐,FP16 下输出最大绝对误差控制在 5e-3。
这段文字大约 200 字,但每一个名词都能对应一个面试追问点。
8.3 面试官会追问的问题(附答案要点)
Q1:你为什么选 LayerNorm 而不是 Window Attention?
一天 MVP 的工程边界考虑:LayerNorm 子图边界清晰、shape 静态、数值稳定容易做、能在最短时间证明完整链路通了。Window Attention 涉及 dynamic shape、relative position bias 和 attention mask,会把验证时间拖到一周以上,但这些细节并不能比 LayerNorm 更好地证明"我会写 Plugin"这件事。
Q2:IPluginV3 比 IPluginV2DynamicExt 好在哪?
V3 把生命周期拆成 Core / Build / Runtime 三个独立接口,职责更清晰;显式区分 build 阶段和 runtime 阶段的状态,避免 V2 里
clone()何时调、状态复制不完整这类隐蔽 bug;序列化通过PluginField表达,类型安全,比 V2 的裸serialize/deserialize字节流更鲁棒。
Q3:你的 LayerNorm Plugin 比 TensorRT 自带的快吗?
这是一个陷阱问题。诚实回答是不一定快。TensorRT 内置 LayerNorm 已经做得很优秀。这个项目的目标不是性能击败原生算子,而是验证 ONNX custom op → Plugin 这条接入链路本身。真要打性能,应该选一个 TensorRT 没原生支持或支持得差的子图(比如 Swin 的 Patch Merging)。
Q4:4090 上做 Plugin 和 A100 有什么区别?
主要是精度路径选择。4090 的 Tensor Core 在 FP32 累加时性能打折,写 Attention 类 Plugin 时如果照搬 A100 的 FP32 累加,性能会被打约 50% 折扣,需要按数值容忍度评估能否切到 FP16 累加。另外 4090 显存只有 24GB,Workspace 要省着用。
Q5:你怎么 debug Plugin 里的 CUDA Kernel?
三个手段:第一,先把 Kernel 抠出来在 PyTorch Extension 里跑通,确认数值正确;第二,用
compute-sanitizer检查内存越界和 race condition;第三,用 Nsight Compute profile,看 SM 占用率、L1/L2 hit rate、内存吞吐,判断瓶颈在哪里。Plugin 内部直接 print 是不可行的,因为 enqueue 期间 stream 是异步的。
把这五个问题答好,"我做过 TensorRT Plugin"这件事在面试里就立得住了。
9. 收尾:从"会调 PyTorch"到"会写算子"
回头看这条路径:从 vector_add 的六步生命周期,到 4090 上的 Tile + Shared Memory,到 Triton vs CUDA C++ 的取舍,到 Swin-Tiny 子图替换 + Plugin 注册的全链路 MVP------表面上是一组技术点的串联,但本质上是一个工程师的能力跃迁。
跃迁的标志不是"会写一个 Kernel",而是当一个真实的模型跑得不够快、跑不动、或者根本跑不起来时,你能:
- 用 Nsight 定位到瓶颈在哪个算子;
- 判断这个算子用 Triton 写还是用 CUDA C++ 写;
- 把它接到推理引擎里(PyTorch / TensorRT / vLLM 都有不同的接入方式);
- 跑通三方对齐,证明它是对的;
- 用一句话给 PM 解释这次优化省了多少延迟、多少显存。
这五件事是 AI Infra 工程师的真正护城河。它们不能被 Python 调包替代,也很难被 LLM 替代------因为每一步都需要对硬件、对编译器、对推理引擎的具体约束有手感。
最后一句话:4090 是一张特别适合学 AI Infra 的卡。它的算力、显存带宽、消费卡精度限制都和数据中心卡有显著差异,正好能逼你跳出"教程里的标准做法",去思考为什么这么做、什么时候不能这么做。如果你有一张 4090 闲着,不要只用它跑 SD 出图------把它当成一个微缩的 AI Infra 实验台,用一周时间走完这条链路,你的简历会从此不一样。
附:参考资料
- NVIDIA, CUDA C++ Programming Guide(最权威的语言规范,对 sm_89 的章节直接读 Ada Lovelace 部分)
- NVIDIA, TensorRT Developer Guide 中 "Extending TensorRT with Custom Layers" 章节
- OpenAI, Triton Documentation(开发体验最好的一份 GPU 编程文档)
- Liu et al., Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, ICCV 2021
- FlashInfer, RTX 4090 Tensor Core FP16 vs FP32 Accumulation Benchmark
- vLLM, PagedAttention: Memory Management for LLM Serving