核心知识点
一、核心:队列 + BFS 的通用框架
这几道题本质上都是层序遍历(BFS)的变形,核心模板只有一套:
cpp
queue<Node*> q;
q.push(root);
while (!q.empty()) {
int sz = q.size(); // 当前层节点数
for (int i = 0; i < sz; ++i) {
auto t = q.front(); q.pop();
// 1. 处理当前节点(核心逻辑在这里变化)
// 2. 把左右子节点入队
if (t->left) q.push(t->left);
if (t->right) q.push(t->right);
}
// 可选:每层结束后做额外操作(反转、记录结果等)
}所有题目,都是在这个框架里,改「处理当前节点」和「每层结束后的操作」这两处。
二、这类题的「通用解题步骤」
-
初始化:定义结果容器,创建队列,根节点入队。
-
层循环:while (!q.empty()),每次处理一层。
-
当前层大小:sz = q.size(),确保 for 循环只处理当前层。
-
遍历当前层:
取出队首节点,做题目要求的处理(收集值/更新最大值/记录下标)。
非空子节点入队。
-
收尾操作:当前层处理完,按题目要求更新结果(反转/保存最大值/计算宽度)。
-
返回结果。
题目1:N叉树的层序遍历(LeetCode 429)
- 题目描述
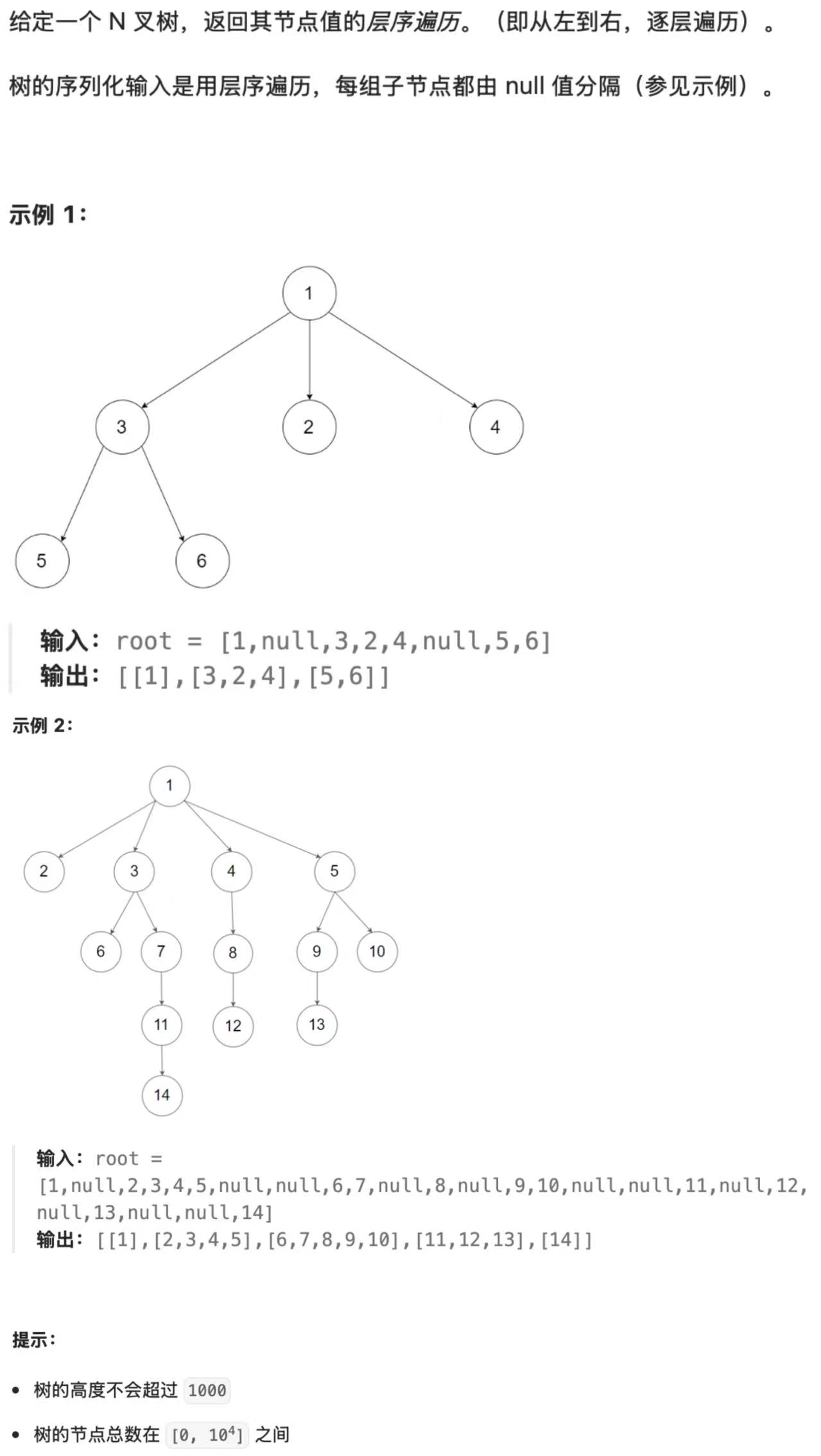
- 核心知识点:层序遍历(BFS)
1) 算法思想
层序遍历,也叫广度优先搜索(BFS),核心是按"层"处理节点:
从根节点开始,先处理第1层(根节点所在层),再处理第2层(根节点的所有子节点),接着处理第3层......直到遍历完所有节点。
关键技巧:用队列记录每一层的节点,用变量记录当前层的节点数量,以此区分不同层的节点,将每层节点值分别存入结果列表。
2) 核心步骤拆解
初始化:创建结果列表ret和队列q,若根节点为空直接返回空结果;否则将根节点入队。
循环处理每一层:当队列不为空时,获取当前队列的大小sz(即当前层的节点总数)。
遍历当前层:循环sz次,依次取出队首节点,将节点值存入当前层的临时列表tmp;同时将该节点的所有子节点依次入队(非空节点)。
保存当前层结果:将当前层的临时列表tmp加入最终结果ret中。
循环结束:队列空时,所有层处理完毕,返回ret。
cpp
/*
// Definition for a Node.
class Node {
public:
int val;
vector<Node*> children;
Node() {}
Node(int _val) {
val = _val;
}
Node(int _val, vector<Node*> _children) {
val = _val;
children = _children;
}
};
*/
class Solution
{
public:
vector<vector<int>> levelOrder(Node* root)
{
// 1. 定义最终结果容器,存储每层节点值
vector<vector<int>> ret;
// 2. 定义队列,用于层序遍历(BFS)
queue<Node*> q;
// 边界处理:如果根节点为空,直接返回空结果
if(root == nullptr) return ret;
// 3. 将根节点入队,开始遍历
q.push(root);
// 4. 循环处理队列,直到队列为空(所有层遍历完成)
while(q.size())
{
// 关键步骤:记录当前层的节点总数
int sz = q.size();
// 临时容器,存储当前层的所有节点值
vector<int> tmp;
// 遍历当前层的所有节点
for(int i = 0; i < sz; i++)
{
// 取出队首节点
Node* t = q.front();
q.pop();
// 将当前节点的值加入临时容器
tmp.push_back(t->val);
// 将当前节点的所有子节点依次入队(为下一层遍历做准备)
for(Node* child : t->children)
{
// 仅入队非空节点
if(child != nullptr)
q.push(child);
}
}
// 将当前层的节点值列表,加入最终结果
ret.push_back(tmp);
}
// 返回最终的层序遍历结果
return ret;
}
};- 关键细节与易错点
1) 队列的作用
队列是BFS的核心,它保证了节点按"先进先出"的顺序处理,也就是按层、从左到右的顺序遍历节点。
2) sz = q.size()的作用
每次进入while循环时,队列里的节点都是当前层的节点,此时队列的大小就是当前层的节点数。
后续循环sz次,刚好处理完当前层的所有节点,同时将下一层的节点全部入队,实现了"分层"的效果。
3) 子节点入队的处理
N叉树的节点有children数组,遍历该数组时,要判断子节点是否为空,避免入队空指针导致程序报错。
4) 边界情况处理
根节点为空:直接返回空结果,避免空指针访问。
单节点树:仅返回包含根节点值的列表。
- 复杂度分析
1)时间复杂度:O(n)
分析:每个节点都会被恰好访问一次:入队1次、出队1次,同时节点值被存入结果列表1次。所有操作(入队、出队、遍历子节点、存入列表)都是常数时间 O(1)。设树的节点总数为 n,总操作次数为 O(n),因此时间复杂度为 O(n)。
2)空间复杂度:O(n)
分析:
空间主要由两部分组成:
-
队列的额外空间:队列中最多会存储某一层的所有节点。对于一棵N叉树,最坏情况是完全N叉树,其最后一层的节点数接近 n,此时队列的最大长度为 O(n)。
-
结果列表的空间:题目要求返回所有节点的值,因此结果列表必须存储 n 个节点值,这部分空间是题目要求的输出,不计入算法的额外空间复杂度。
因此,算法的额外空间复杂度由队列决定,为 O(n)。
题目2:二叉树的锯齿形层序遍历(LeetCode 103)
- 题目描述
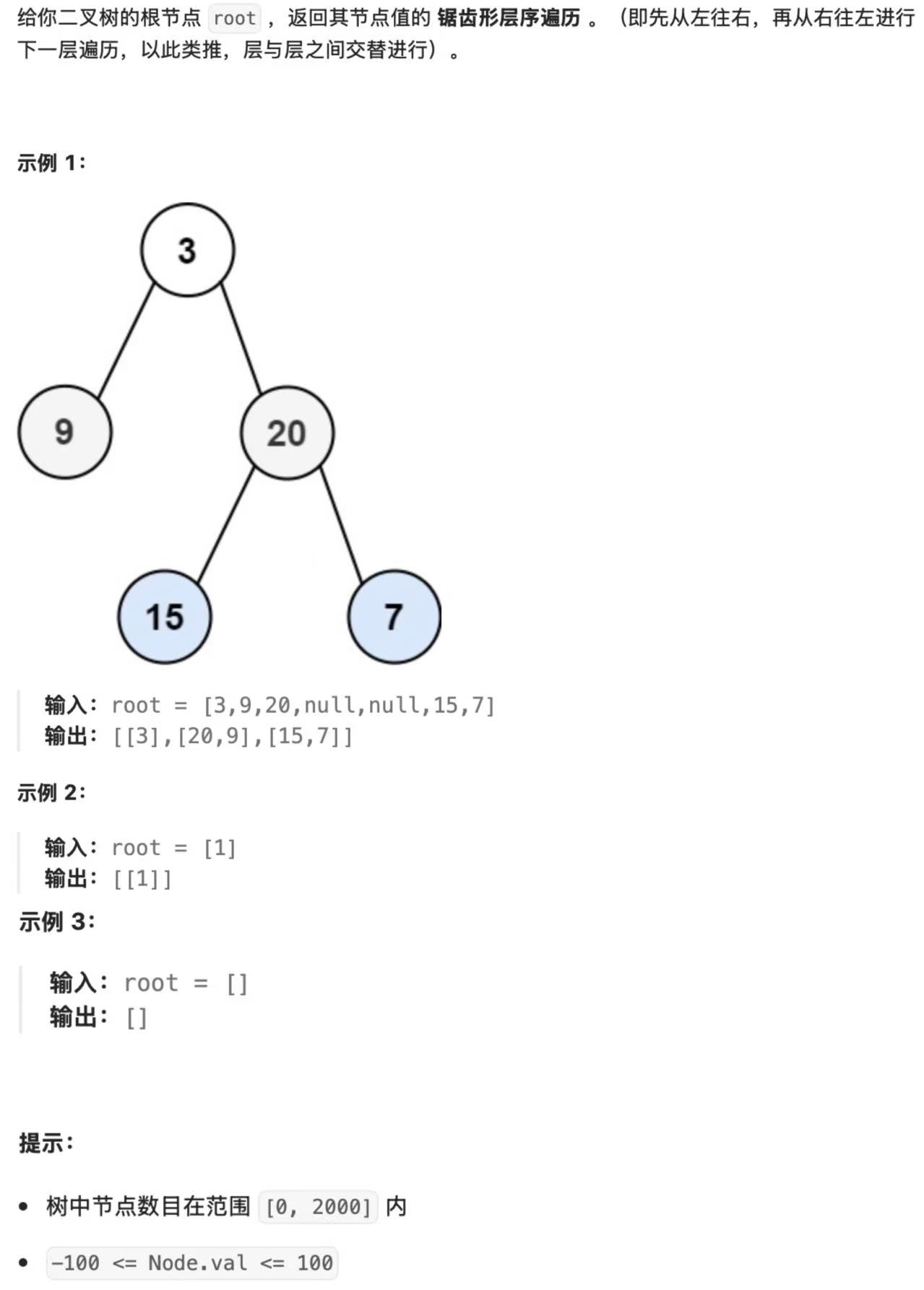
- 核心知识点:层序遍历 + 奇偶层反转
1) 算法思路
锯齿形层序遍历本质上是基础层序遍历(BFS)的变形:
基础层序遍历:按层从左到右遍历节点,每层结果直接存入列表。
锯齿形遍历:在基础层序遍历的基础上,根据当前层的奇偶性,决定是否反转该层的节点值列表:
奇数层(第1、3、5...层):保持从左到右的顺序。
偶数层(第2、4、6...层):反转列表,实现从右到左的顺序。
2) 核心步骤拆解
初始化:创建结果列表ret和队列q,若根节点为空直接返回空结果;否则将根节点入队。
循环处理每一层:用变量level记录当前层数,初始为1。当队列不为空时,获取当前队列的大小sz(当前层节点总数)。
遍历当前层:循环sz次,依次取出队首节点,将节点值存入临时列表tmp;同时将节点的左、右子节点(非空)依次入队。
判断并反转:若当前层数为偶数,使用reverse()函数反转临时列表tmp。
保存结果:将处理后的tmp加入最终结果ret,层数level自增1。
循环结束:队列空时,返回ret。
cpp
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution
{
public:
vector<vector<int>> zigzagLevelOrder(TreeNode* root)
{
// 1. 定义最终结果容器,存储每层节点值
vector<vector<int>> ret;
// 边界处理:如果根节点为空,直接返回空结果
if(root == nullptr) return ret;
// 2. 定义队列,用于层序遍历(BFS)
queue<TreeNode*> q;
// 将根节点入队,开始遍历
q.push(root);
// 3. 记录当前层数,用于判断是否需要反转
int level = 1;
// 4. 循环处理队列,直到队列为空(所有层遍历完成)
while(q.size())
{
// 关键步骤:记录当前层的节点总数
int sz = q.size();
// 临时容器,存储当前层的所有节点值
vector<int> tmp;
// 遍历当前层的所有节点
for(int i = 0; i < sz; i++)
{
// 取出队首节点
auto t = q.front();
q.pop();
// 将当前节点的值加入临时容器
tmp.push_back(t->val);
// 将当前节点的左、右子节点依次入队(为下一层遍历做准备)
if(t->left) q.push(t->left);
if(t->right) q.push(t->right);
}
// 关键:判断当前层数是否为偶数,偶数层反转列表
if(level % 2 == 0)
reverse(tmp.begin(), tmp.end());
// 将处理后的当前层节点值列表,加入最终结果
ret.push_back(tmp);
// 层数自增,处理下一层
level++;
}
// 返回最终的锯齿形层序遍历结果
return ret;
}
};- 复杂度分析
1) 时间复杂度:O(n)
每个节点被访问一次,入队/出队操作均为常数时间。 每层的反转操作:所有节点总共被反转一次,总时间为O(n)。 整体时间复杂度为 O(n)。
2) 空间复杂度:O(n)
队列的额外空间:最坏情况下(完全二叉树),队列中最多存储一层的节点,空间为O(n)。 结果列表为题目要求的输出,不计入额外空间复杂度。 整体额外空间复杂度为 O(n)。
- 关键细节与易错点
1) 层数的起始值:代码中level初始化为1,对应根节点所在的第一层(奇数层,不反转),需注意与题目描述的"交替遍历"顺序一致。
2) 反转操作的时机:反转操作必须在当前层所有节点值存入tmp之后执行,不能边遍历边反转,否则会打乱队列中节点的入队顺序。
3) 空节点处理:子节点入队前必须判断是否为空,避免空指针访问导致程序崩溃。
4) 边界情况:
空树(root == nullptr):直接返回空列表。
单节点树:仅返回包含根节点值的列表。
题目3:二叉树的最大宽度(LeetCode 662)
- 题目描述
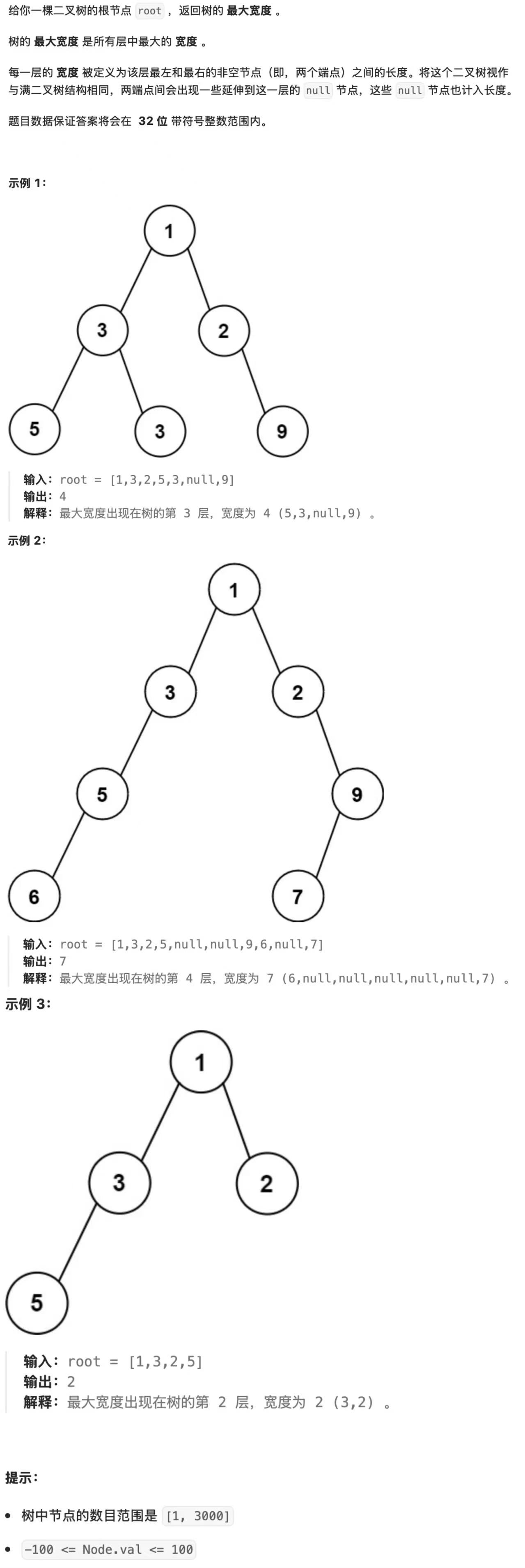
- 核心解法:层序遍历 + 节点下标标记
1) 算法思路
直接把空节点存入队列会导致内存溢出(极端情况会产生上亿个空节点),因此采用节点下标标记法。
利用满二叉树的数组存储性质:若父节点的下标为 idx,则左孩子下标为 2*idx,右孩子下标为 2*idx+1。
层序遍历每一层时,记录该层最左节点和最右节点的下标,宽度 = 最右下标 - 最左下标 + 1,遍历过程中更新最大值。
2) 核心步骤拆解
-
初始化:创建队列,存储 (节点指针, 下标) 对,根节点的下标为 1;初始化最大宽度为 0。
-
循环处理每一层:当队列不为空时,获取当前层的所有节点。
-
计算当前层宽度:取当前层第一个节点的下标 left_idx 和最后一个节点的下标 right_idx,计算宽度 right_idx - left_idx + 1,更新全局最大宽度。
-
生成下一层节点:遍历当前层节点,计算每个节点的左、右孩子下标,将非空孩子加入临时队列。
-
更新队列:将临时队列赋值给原队列,进入下一层循环。
cpp
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution
{
public:
int widthOfBinaryTree(TreeNode* root)
{
vector<pair<TreeNode*, unsigned int>> q; // 用数组模拟队列
q.push_back({root, 1});
unsigned int ret = 0;
while(q.size())
{
// 先更新这一层的宽度
auto& [x1, y1] = q[0];
auto& [x2, y2] = q.back();
ret = max(ret, y2 - y1 + 1);
// 让下一层进队
vector<pair<TreeNode*, unsigned int>> tmp; // 让下一层进入这个队列
for(auto& [x, y] : q)
{
if(x->left) tmp.push_back({x->left, y * 2});
if(x->right) tmp.push_back({x->right, y * 2 + 1});
}
q = tmp;
}
return ret;
}
};- 复杂度分析
时间复杂度:O(n),每个节点被访问一次,下标计算、队列操作均为常数时间,总时间复杂度为 O(n)。
空间复杂度:O(n),队列中最多存储某一层的所有节点,最坏情况(完全二叉树)下队列大小为 O(n),空间复杂度为 O(n)。
- 关键细节与易错点
1) 下标溢出问题:极端情况下下标会超出 int 范围,因此使用 unsigned int 存储下标,利用无符号数的环形溢出特性,保证差值计算的正确性。
2) 空节点处理:不将空节点入队,仅通过父节点下标计算孩子下标,避免内存溢出。
3) 宽度计算:宽度为 最右下标 - 最左下标 + 1,必须加1,因为下标差是端点间的"间隔数",节点数为间隔数+1。
4) C++17 的结构化绑定(Structured Bindings)
auto& x1, y1 = q0;
等价于下面这段传统写法:
pair<TreeNode*, unsigned int>& p = q0;
TreeNode* x1 = p.first;
unsigned int y1 = p.second;
也就是说:
q0 是队列里的第一个元素,类型是 pair<TreeNode*, unsigned int>
x1 绑定到 pair 的第一个成员:TreeNode* 类型的节点指针
y1 绑定到 pair 的第二个成员:unsigned int 类型的节点下标
auto& 表示引用绑定,x1 和 y1 是对 q0 内部成员的引用,而不是拷贝。
为什么用 auto& 而不是 auto?
auto&:绑定到 pair 的引用,不会拷贝对象,效率更高,也可以修改原对象(这里只是读)。
如果写 auto x1, y1 = q0;:会拷贝 pair,x1 和 y1 是副本,不会影响原对象,效率稍低,但功能上在这里也能跑。
5) for(auto& x, y : q):遍历并"拆包"当前层节点
for(auto& x, y : q)
这同样是 C++17 结构化绑定的用法,它等价于下面这段传统写法:
for (auto& p : q) {
TreeNode* x = p.first; // 节点指针
unsigned int y = p.second; // 节点在满二叉树中的下标
// ... 循环体
}
auto&:引用遍历,避免拷贝队列里的 pair,效率更高。
x, y:把 q 里每个 pair<TreeNode*, unsigned int> 拆成两个变量:
x:节点的指针(类型是 TreeNode*) y:节点的下标(类型是 unsigned int)
循环体:计算子节点下标,加入下一层队列
if(x->left) tmp.push_back({x->left, y * 2});
if(x->right) tmp.push_back({x->right, y * 2 + 1});
这两行利用了满二叉树的下标规则:
若父节点下标为 y,则: 左孩子下标 = 2 * y 右孩子下标 = 2 * y + 1
if(x->left) / if(x->right):只把非空的子节点加入下一层队列,避免处理空指针,也不会把空节点压入队列浪费空间。
tmp.push_back(...):把 (子节点指针, 子节点下标) 组成的 pair,加入临时队列 tmp。
q = tmp;:更新队列,进入下一层;把下一层的节点队列 tmp 赋值给 q,while 循环下一次就会处理这一层。这行代码相当于"切换到下一层",是层序遍历的关键步骤。
题目4:在每个树行中找最大值(LeetCode 515)
- 题目描述
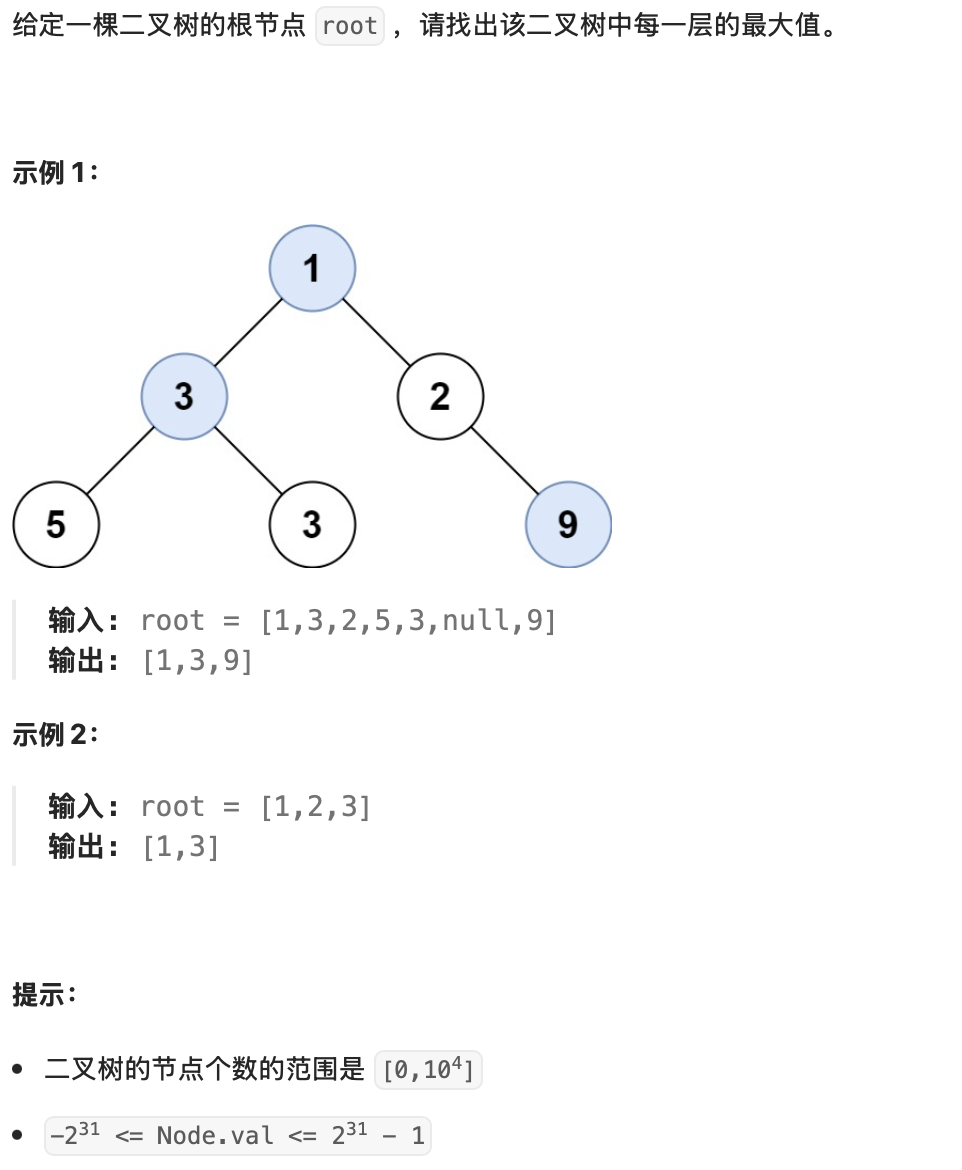
二、核心解法:层序遍历(BFS)求每层最大值
1) 算法思路
这道题是基础层序遍历(BFS)的直接应用:
层序遍历二叉树的每一层,在遍历过程中统计当前层所有节点的最大值。
遍历完一层后,将该层的最大值存入结果列表,继续处理下一层。
2) 核心步骤拆解
-
初始化:创建结果列表ret和队列q,若根节点为空直接返回空结果;否则将根节点入队。
-
循环处理每一层:当队列不为空时,获取当前队列的大小sz(当前层节点总数),初始化当前层最大值tmp为INT_MIN。
-
遍历当前层:循环sz次,依次取出队首节点,更新当前层最大值tmp;同时将节点的左、右子节点(非空)依次入队。
-
保存结果:将当前层最大值tmp加入最终结果ret。
-
循环结束:队列空时,返回ret。
cpp
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution
{
public:
vector<int> largestValues(TreeNode* root)
{
vector<int> ret;
if(root == nullptr) return ret;
queue<TreeNode*> q;
q.push(root);
while(q.size())
{
int sz = q.size();
int tmp = INT_MIN;
for(int i = 0; i < sz; i++)
{
auto t = q.front();
q.pop();
tmp = max(tmp, t->val);
if(t->left) q.push(t->left);
if(t->right) q.push(t->right);
}
ret.push_back(tmp);
}
return ret;
}
};- 复杂度分析
时间复杂度:O(n),每个节点被访问一次,入队/出队、最大值更新操作均为常数时间,总时间复杂度为 O(n)。
空间复杂度:O(n),队列的额外空间:最坏情况下(完全二叉树),队列中最多存储一层的节点,空间为O(n)。结果列表为题目要求的输出,不计入额外空间复杂度。整体额外空间复杂度为 O(n)。
- 关键细节与易错点
1) 初始最大值的设置:必须将tmp初始化为INT_MIN,而不是0,否则如果某一层的节点值全为负数,结果会出错。
2) 当前层节点数的获取:sz = q.size()必须写在while循环内、for循环外,确保它是当前层的节点总数,而不是后续变化的队列大小。
3) 空节点处理:子节点入队前必须判断是否为空,避免空指针访问导致程序崩溃。
4) 边界情况:
空树(root == nullptr):直接返回空列表。
单节点树:仅返回包含根节点值的列表。