****论文题目:****Cross-Domain Fault Diagnosis Method of Rotating Machinery Based on Classifier Prediction Consistency and Domain Generalization(基于分类器预测一致性和领域泛化的旋转机械跨域故障诊断方法)
****期刊:****IEEE TRANSACTIONS ON INSTRUMENTATION AND MEASUREMENT
****摘要:****为了提高有限同分布标记数据和未知诊断目标的故障诊断的准确性和鲁棒性,本文提出了一种将分类器预测一致性与领域泛化(CPC-DG)相结合的故障诊断方法。首先,与传统的基于分类器的故障诊断不同,该方法主要关注全局特征分布,忽略类间边界模糊,而我们的方法采用双分类器对抗训练策略。该算法通过最大化分类器在边界样本上的预测散度来细化决策边界,并引导共享特征提取器学习更多的判别特征,特别是在移动目标域下保持鲁棒的。其次,为了减轻与传统伪标记技术相关的噪声,传统伪标记技术通常依赖于单个分类器的置信度输出,我们开发了一种基于双分类器共识的伪标记生成和验证技术。该方法将伪标签仅分配给未标记的样本,通过迭代更新来过滤掉可能损害模型性能的不可靠标签,从而在分类器之间表现出高预测一致性。第三,将边界细化和高质量伪标记机制与基于最大平均差异(MMD)的全局对齐策略相结合,以最小化跨多个源域的分布差异。最后,在凯斯西储大学(CWRU)和PU轴承基准数据集上进行了大量实验,验证了该方法在标签稀缺性和未知目标域的情况下具有较高的诊断准确性。
用双分类器共识破解跨域故障诊断难题:CPC-DG 方法详解
一、背景:工业故障诊断面临的真实困境
在现代工业系统中,旋转机械(如轴承、齿轮箱)的健康监测至关重要。一旦发生故障,轻则停产损失,重则安全事故。数据驱动的智能故障诊断因此成为研究热点。
然而,实验室里跑得好的模型,一旦部署到真实工厂就"水土不服"------这背后是三个棘手的现实问题:
1.1 标签稀缺:打标签太贵了
深度学习模型需要大量带标注的故障样本,但在真实工业环境中,获取故障数据需要人为制造故障(代价极高),且专家标注耗时耗力。实际上,大量数据是无标签的,如何利用这些"沉默的数据"是核心挑战之一。
1.2 域偏移:工况一变,模型就瞎
轴承在不同转速、负载下运行,其振动信号的统计分布截然不同------这就是**域偏移(Domain Shift)**问题。训练时见过的工况(源域),和实际部署时遇到的工况(目标域)往往大相径庭。
领域自适应(Domain Adaptation, DA)虽然能缓解这一问题,但它要求在训练时就能访问目标域数据,这在很多场景下根本做不到。**域泛化(Domain Generalization, DG)**则更进一步,要求模型在完全未见过目标域的情况下仍能泛化------难度更高,但更贴近实际。
1.3 现有方法的两大盲区
即使在DG框架下,现有方法也存在两个关键缺陷:
- 忽视决策边界模糊问题:大多数DG方法专注于全局特征分布对齐,但靠近决策边界的样本(边界样本)天然容易被错分,在未见过的目标域上尤为脆弱。
- 伪标签质量低:利用无标签数据时,通常只用单个分类器来生成伪标签,单一分类器的预测可靠性有限,错误标签会积累放大,最终导致模型崩溃(即"确认偏差",Confirmation Bias)。
二、方法:CPC-DG 框架总览
针对上述问题,论文提出了 CPC-DG(Classifier Prediction Consistency + Domain Generalization)框架。
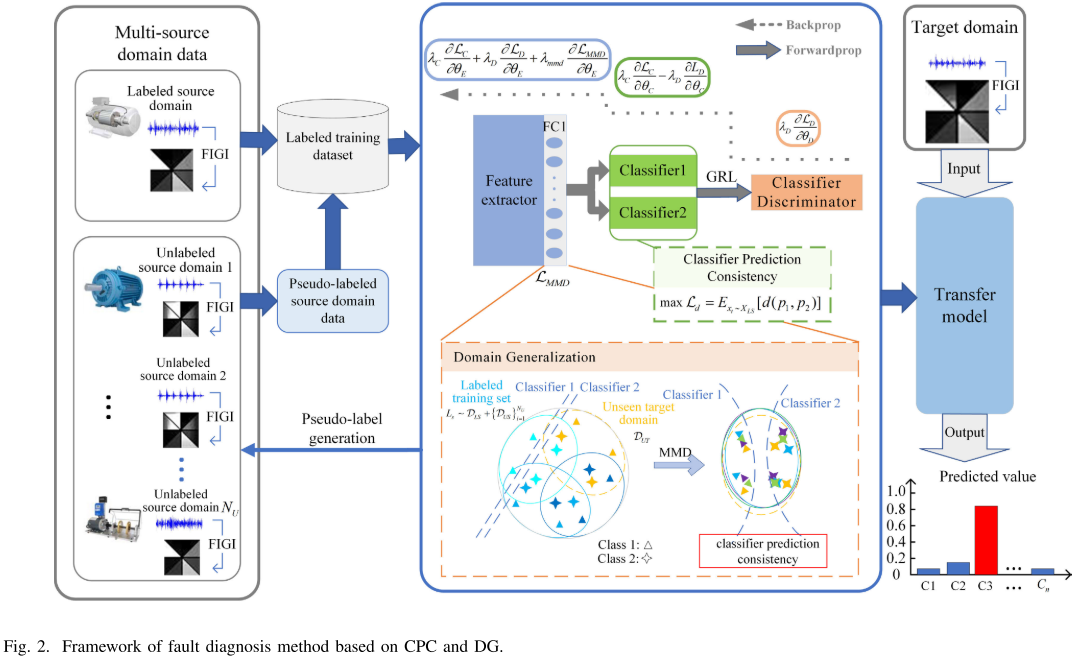
【图2:CPC-DG 整体框架图】
整体框架由两大核心模块构成:
- 基于双分类器共识的伪标签生成(CPC Pseudo-Labeling)
- 多源域泛化与对抗学习(Multi-source DG)
训练数据包含:一个有标签的源域(提供有监督信号)+ 多个无标签的辅助源域(通过伪标签机制被利用)。目标域在训练阶段完全不可见。
三、创新点一:双分类器对抗训练------精化决策边界
3.1 核心思想
传统方法用一个分类器,CPC-DG 用两个 分类器 C1 和 C2。这两个分类器被有意设计成学习互补的决策边界,从而能相互检验彼此的预测,识别出那些处于"灰色地带"的边界样本。
3.2 三步对抗训练流程
Step 1 ------ 有监督初始化
特征提取器E和双分类器 在有标签源域上联合训练,建立初始判别能力,损失函数为交叉熵损失:
Step 2 ------ 最大化分类器分歧
固定特征提取器参数,训练两个分类器使其对相同输入给出尽量不同的预测。分歧度量函数为两个分类器输出概率之差的绝对值均值:
这一步迫使两个分类器识别出决策边界附近的"危险样本"。
Step 3 ------ 最小化特征分歧
固定分类器参数,训练特征提取器最小化上述分歧,将边界样本的特征表示推向特征空间中更明确的区域,远离决策边界。
这三步循环交替,类似 GAN 的对抗训练机制,最终使决策边界更清晰、特征表示更具判别性。
3.3 分类器-判别器结构
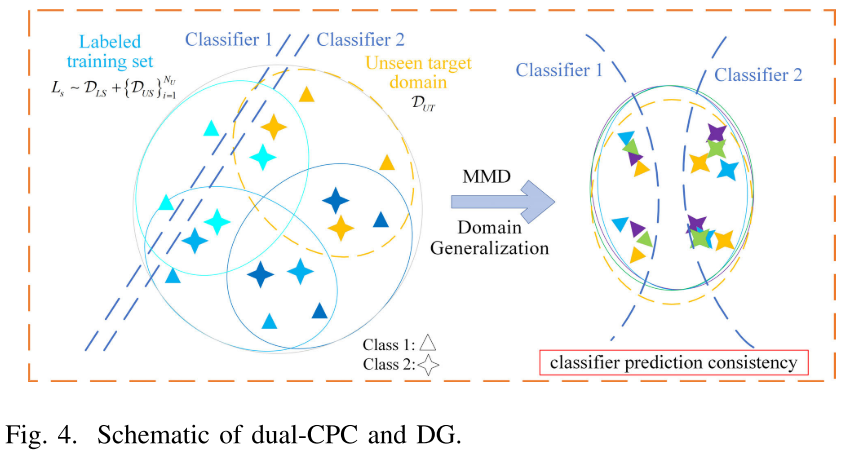
【图4:dual-CPC与DG机制示意图】
为进一步强化两分类器的结构差异,论文还引入了一个分类器判别器 D ,它接受 C1 和 C2 的概率输出向量,尝试区分它们来自哪个分类器。通过梯度反转层(GRL),C1 和 C2 被迫与判别器对抗训练,从而增强了分类器间的结构不相似性,进一步提升预测鲁棒性。
四、创新点二:基于双分类器共识的高质量伪标签生成
4.1 共识伪标签策略
仅当 C1 和 C2 对同一无标签样本的预测一致时,才为其分配伪标签:
这一机制天然过滤掉两个分类器"意见不合"的样本,只保留高置信度的标注,有效抑制标签噪声。
4.2 四阶段迭代验证机制
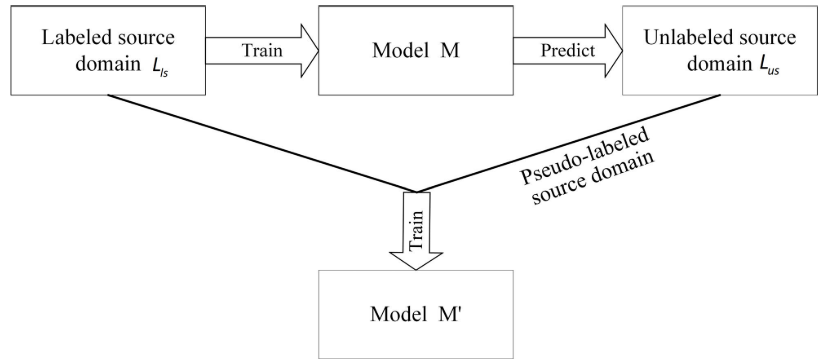

【图3 :伪标签生成结构示意图】 【Algorithm 1:迭代伪标签生成算法】
整个伪标签生成过程分为四个阶段循环执行:
| 阶段 | 操作 |
|---|---|
| Phase I:数据划分 | 将有标签源域分为训练子集和测试子集,测试子集用于验证 |
| Phase II:伪标签生成 | 模型对一个无标签源域进行双分类器共识预测,生成伪标签 |
| Phase III:模型验证 | 将伪标签域加入训练集,训练新模型 M';若 M' 在测试集上优于旧模型 M,则保留;否则丢弃该伪标签域 |
| Phase IV:循环优化 | 对下一个无标签源域重复 Phase II 和 III,直至所有域处理完毕 |
这种**"生成→验证→保留/丢弃"**的机制确保了模型只从高质量伪标签中学习,防止错误标签积累导致的模型退化。
4.3 联合损失函数
伪标签生成阶段,训练目标融合了有标签数据和伪标签数据的监督信号(为权衡因子):
- 特征提取器优化:
- 分类器优化:
五、创新点三:MMD全局分布对齐------打通域间鸿沟
5.1 为什么单靠边界精化不够?
决策边界精化(CPC)关注的是条件分布 的局部调整,但如果不同源域的边缘分布
差异过大,精化后的边界在目标域上仍会"失效"。
因此,论文引入 MMD(Maximum Mean Discrepancy,最大均值差异) 来度量并最小化不同源域之间的分布距离,将所有源域的特征映射到一个统一的隐空间中对齐:
MMD 计算在特征提取器的全连接层(FC1)输出上进行,利用高斯核函数衡量特征分布距离。
5.2 CPC与MMD的协同效应
两种机制的分工非常明确:
- MMD:处理"非边界"的高密度样本区域,通过全局分布对齐提升主体识别率
- CPC对抗训练:专注于 MMD 无法覆盖到的少数边界样本,精细化决策边界
两者形成互补,缺一不可。
5.3 统一优化目标
通过 SGD 反向传播更新各模块参数,三个损失项的权重 通过超参数搜索确定。
六、网络架构设计
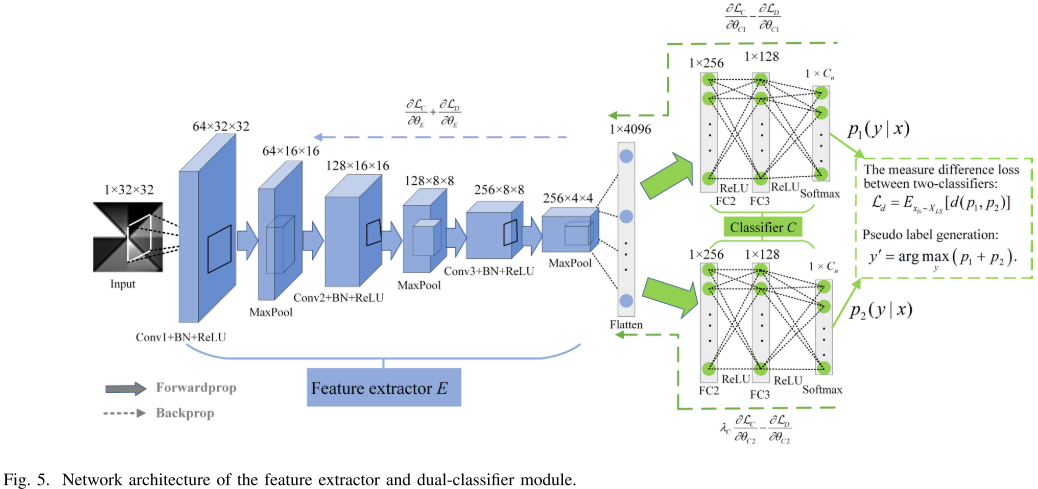
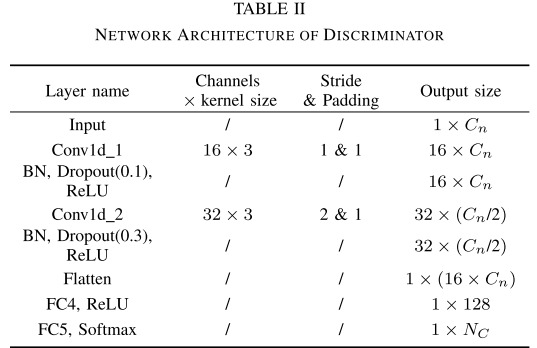
【图5 :特征提取器与双分类器模块网络架构图】 【此处配 Table II:判别器网络架构表】
特征提取器 E 由三个一维卷积层 + 一个全连接层构成,能从原始振动信号中自动提取多层次特征。两个分类器 C1 和 C2 结构相同,各包含两个全连接层 + Softmax,输出类别概率向量。
分类器判别器 D 以 C1 和 C2 的概率向量为输入,通过两个一维卷积层和两个全连接层判断概率向量来自哪个分类器。
振动信号在送入网络前,通过 FIGI(Feature Indicator Grayscale Images) 方法转换为 32×32 的灰度图像,每种故障类型生成100张图像。
七、实验设置
7.1 实验环境
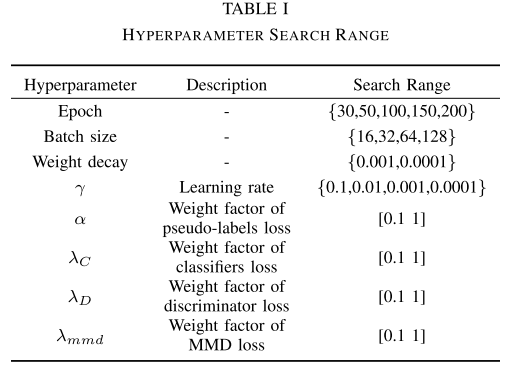
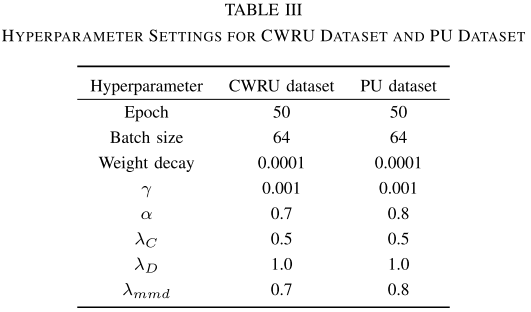
【Table I :超参数搜索范围表】 【Table III:CWRU与PU数据集超参数设置表】
- 硬件:Intel Xeon Gold 5220R CPU(2.20 GHz)、64GB RAM、NVIDIA 3090 GPU
- 框架:PyTorch
- 实验重复次数:每组配置重复5次,取平均值
7.2 数据集
CWRU 数据集(凯斯西储大学)
- 采样频率:12kHz,采集驱动端轴承振动信号
- 4个工况域(A、B、C、D),每域10种故障类型
- 实验设计:12个跨域任务,用
ABC → D表示(加粗字母为有标签源域,非加粗为无标签辅助域,右侧为未见目标域)
PU 数据集(帕德博恩大学)

【图7 :PU数据集轴承测试台图】 【图8:PU数据集加速寿命测试台图】
- 采样频率:64kHz,模拟三种损伤类型(正常、人工缺陷、自然疲劳失效)
- 4个工况域(E、F、G、H),每域10种故障类型
- 实验设计:同样12个跨域任务
7.3 对比模型
| 模型 | 描述 |
|---|---|
| M1(基线) | 仅使用分类损失 |
| M2 | |
| M3 | |
| M4(DSDGN) | 对比方法,使用 WGAN-GP 进行特征对齐 + 半监督伪标签 |
| M5(CPC-DG) | 完整模型, |
八、实验结果与分析
8.1 CWRU 数据集消融实验
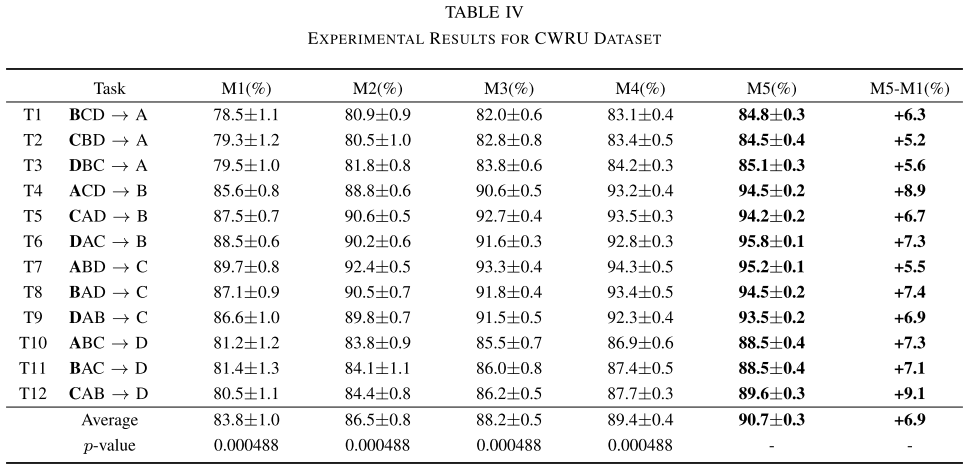
【Table IV:CWRU数据集实验结果表】
12个跨域任务的平均准确率结果如下:
| 模型 | 平均准确率 | 相对M1提升 |
|---|---|---|
| M1(基线) | 83.8% | --- |
| M2(+判别器) | 86.5% | +2.7% |
| M3(+MMD) | 88.2% | +4.4% |
| M4(DSDGN) | 89.4% | --- |
| M5(CPC-DG) | 90.7% | +6.9% |
关键发现:
- MMD(M3)带来的提升(+4.4%)显著大于单纯加入判别器损失(M2,+2.7%),说明全局分布对齐是跨域任务中最主要的改进驱动力。这是因为非边界样本在数量上占主导,MMD 优化主要提升这部分样本的识别率。
- M5 完整模型比 M1 提升 6.9% ,超越了所有消融版本和对比方法(DSDGN),验证了联合优化的协同增效。
- 所有 M5 vs M1~M4 的比较均通过 Wilcoxon 符号秩检验(p = 0.000488),具有统计显著性。
8.2 PU 数据集结果
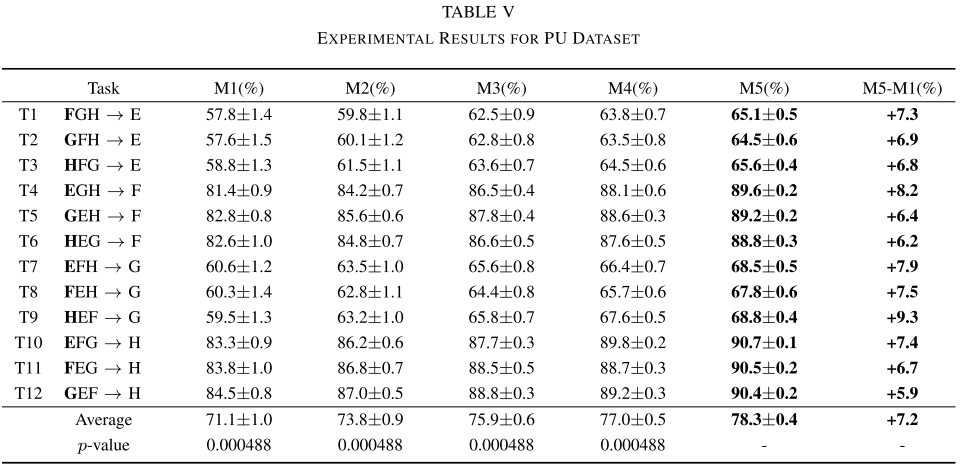
【Table V:PU数据集实验结果表】
| 模型 | 平均准确率 | 相对M1提升 |
|---|---|---|
| M1(基线) | 71.1% | --- |
| M2(+判别器) | 73.8% | +2.7% |
| M3(+MMD) | 75.9% | +4.8% |
| M4(DSDGN) | 77.0% | --- |
| M5(CPC-DG) | 78.3% | +7.2% |
PU 数据集包含真实疲劳失效样本,难度更高,但 CPC-DG 仍取得了 7.2% 的显著提升,p 值同样为 0.000488,验证了方法的稳健性。
8.3 混淆矩阵与 T-SNE 可视化分析
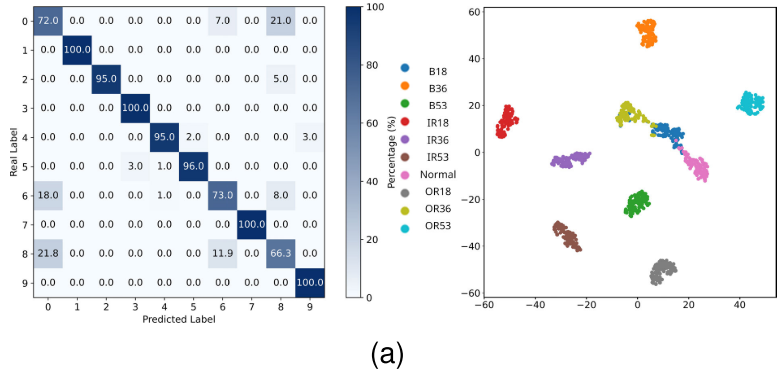
【图6:CWRU数据集任务T7的混淆矩阵和T-SNE可视化(a)M1~(e)M5】(提供了(a))
以 CWRU 数据集任务 T7(ABD → C)为例:
- M1:特征空间存在明显的类间重叠(如第0、6、8类),说明 domain-specific 特征干扰了判别
- M2:通过对抗正则化减少了边界混淆
- M3:类内聚集更紧密,但仍存在边界模糊
- M5(CPC-DG):类间分离最清晰,误分类率最低
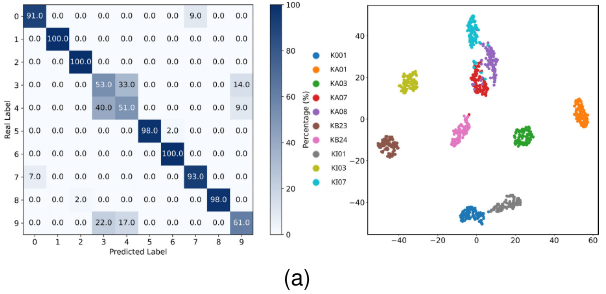
【图9:PU数据集任务T12的混淆矩阵和T-SNE可视化(a)M1~(e)M5】(提供了(a)
PU 数据集任务 T12 的可视化结果同样印证了相同规律:M5 在所有模型中实现了最优的类别可分性。
可视化结论:MMD 主要改善了高密度非边界区域的聚类质量;CPC 对抗损失专门针对剩余边界样本,两者协同实现了鲁棒的域不变特征表示。
8.4 计算与存储开销
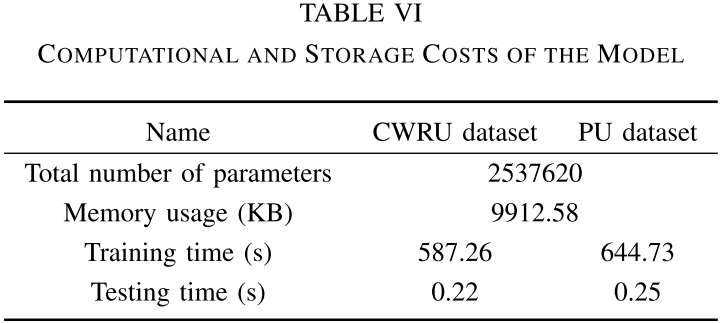
【Table VI:模型计算与存储开销表】
虽然多模块集成导致训练时间较长,但测试时间仅约0.22秒,不增加实际部署的推理负担。对于模型体积,论文指出可通过知识蒸馏进一步压缩,以适配嵌入式设备部署。
九、总结与展望
9.1 核心贡献回顾
CPC-DG 框架的成功在于系统性地解决了三个相互关联的问题:
| 问题 | 解决方案 | 效果 |
|---|---|---|
| 标签稀缺 | 双分类器共识伪标签 + 迭代验证 | 充分利用无标签辅助域 |
| 边界模糊 | 三步对抗训练 + 分类器判别器 | 精化决策边界,降低边界误分 |
| 域偏移 | MMD全局分布对齐 | 构建统一域不变特征空间 |
9.2 重要启示
论文通过消融实验揭示了一个重要规律:在跨域故障诊断任务中,全局分布对齐(MMD)的贡献大于局部边界精化(CPC对抗训练)。这是因为非边界样本在数量上占绝对多数,全局对齐优先受益的正是这一多数群体。但两者缺一不可------边界样本虽少,却是跨域泛化的"短板"。
9.3 未来方向
论文展望了两个实际应用方向:
- 在真实测试台上采集数据验证方法
- 将训练好的模型部署到嵌入式设备,实现真正的工业落地