****论文题目:****SPR-YOLO:面向模糊场景的轻量级交通流检测算法
****期刊:****Arabian Journal for Science and Engineering(综合性 四区/三区)
****摘要:****高效、高精度的车辆检测在智能交通中起着至关重要的作用。然而,在夜晚和雨天等模糊场景中,噪声干扰和低分辨率等因素往往会限制检测效果。因此,本文提出了一种用于模糊场景的轻量级网络体系结构SPR-YOLO。该模型基于YOLOv8,重新设计了轻量级网络的主干和颈部模块,采用SPD_Conv挖掘更深层次的语义信息,面对模糊场景下的特征提取。任务。为了进一步增强模型的特征聚合能力,我们提出了SECA关注模块,提高了模型在通道和空间两个维度上对信息的关注能力,从而更好地提取语义特征。此外,为了在低分辨率和模糊场景下也能达到高细粒度的融合效果,我们提出DY_GELAN聚合网络,实现高保真融合和低参数平衡,进一步增强了网络表达深度信息的能力。最后,我们利用ByteTracker进行车辆跟踪,并利用自定义区域的目标统计方法实现模糊场景下的交通流检测。该网络在UA-DETRAC数据集上进行训练和评估。结果表明,本文提出的网络结构参数与YOLOv8基本相同,但mAP50和FPS分别提高了6.4%和7.68%。与其他主流模型相比,该模型有效地平衡了轻量化、高效率和高精度的优点。
SPR-YOLO:面向模糊场景的轻量级交通流检测算法详解
一、背景与问题
随着城市交通压力的持续增加,车辆检测与交通流统计已成为智能交通系统(ITS)的核心任务。早期的传感器方法(激光雷达、感应线圈、雷达等)虽然有效,但成本高昂、维护困难,且极易受到环境因素的干扰。基于计算机视觉和深度学习的方法因此成为主流选择。
然而,现有的深度学习检测算法在模糊场景(夜间、雨天、大雾、沙尘等)中普遍面临以下几个核心问题:
1.1 低分辨率与噪声干扰问题
在夜间或恶劣天气下,相机采集到的图像往往分辨率低、噪声多。主流的 CNN 架构(包括 YOLOv8)普遍依赖步长卷积(strided convolution)或 池化层(pooling layer)进行下采样,这会导致细粒度信息的丢失,从而在模糊图像中表现出明显的性能下降。
1.2 特征聚合能力不足
传统的通道注意力机制(如 ECA)仅关注通道间的信息,忽略了空间维度的信息,导致在特征聚合时对关键区域的感知能力有限,无法充分利用图像中的空间语义信息。
1.3 特征融合精度不足
现有的特征融合网络通常采用简单的求和或拼接操作,在经过一系列特征提取和空间变换后,大量关键信息丢失,无法在低分辨率模糊图像中实现高保真的特征融合。
1.4 遮挡场景下的跟踪误差
在实际交通视频中,车辆遮挡现象十分普遍。一旦车辆被短暂遮挡后重新出现,系统往往会为其分配新的 ID,导致重复计数,使统计数据与实际不符。
1.5 通用性不足的流量统计方法
传统的"划线计数"方法(line crossing count)依赖特定视频流中固定检测线的位置,当视频流发生变化时,检测线可能超出画面范围,导致方法失效,无法满足高通用性需求。
二、SPR-YOLO 的创新点
针对上述问题,论文提出了 SPR-YOLO 这一轻量级检测网络,基于 YOLOv8 进行了全面改进。整体架构由三部分组成:Backbone(主干网络)、Neck(颈部特征融合网络)、Detection Head(检测头),并结合 ByteTracker 实现端到端的交通流检测。
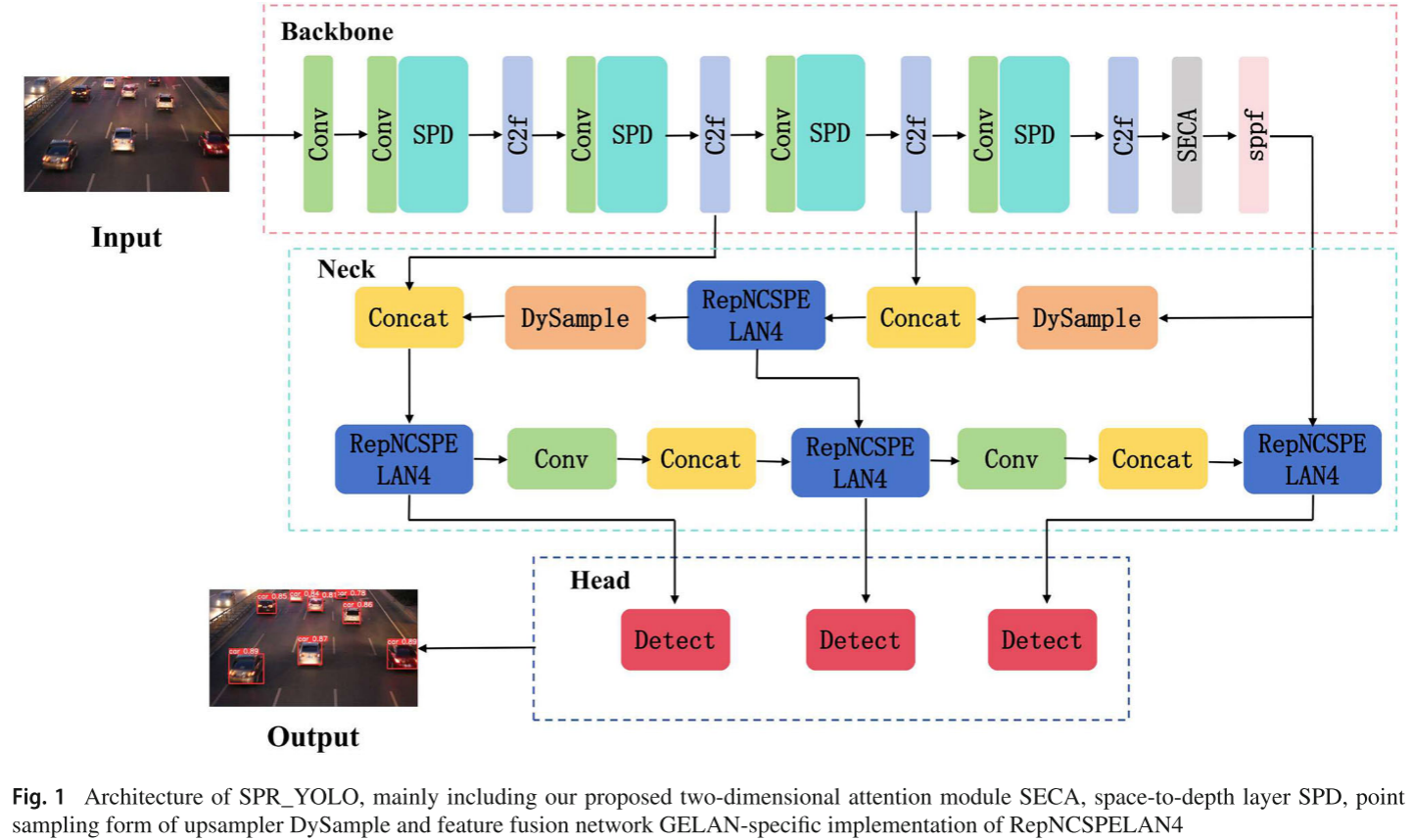
📷 【配图:图1 --- SPR-YOLO 整体网络架构图】
对应论文 Figure 1,展示 Backbone(Conv + SPD + C2f + SECA + SPPF)、Neck(DySample + RepNCSPELAN4 + Concat)及 Head(Detect)的完整结构。
2.1 创新点一:双维度注意力模块 SECA
问题根源:ECA 等经典通道注意力机制仅考虑通道间关系,忽视空间维度,特征聚合能力有限。
解决方案 :提出 SECA(Spatial-Enhanced Channel Attention) ,在 ECA 通道维度推理的基础上,并行增加 SPA(Spatial Attention)分支进行空间维度推理。
SECA 的算法流程如下:
- 通道维度 :通过全局平均池化(GAP)生成通道描述子
,经一维卷积处理后,利用 Sigmoid 激活函数生成通道权重
- 空间维度 :通过最大池化和平均池化进行通道聚合,将特征图从
- 融合输出 :将
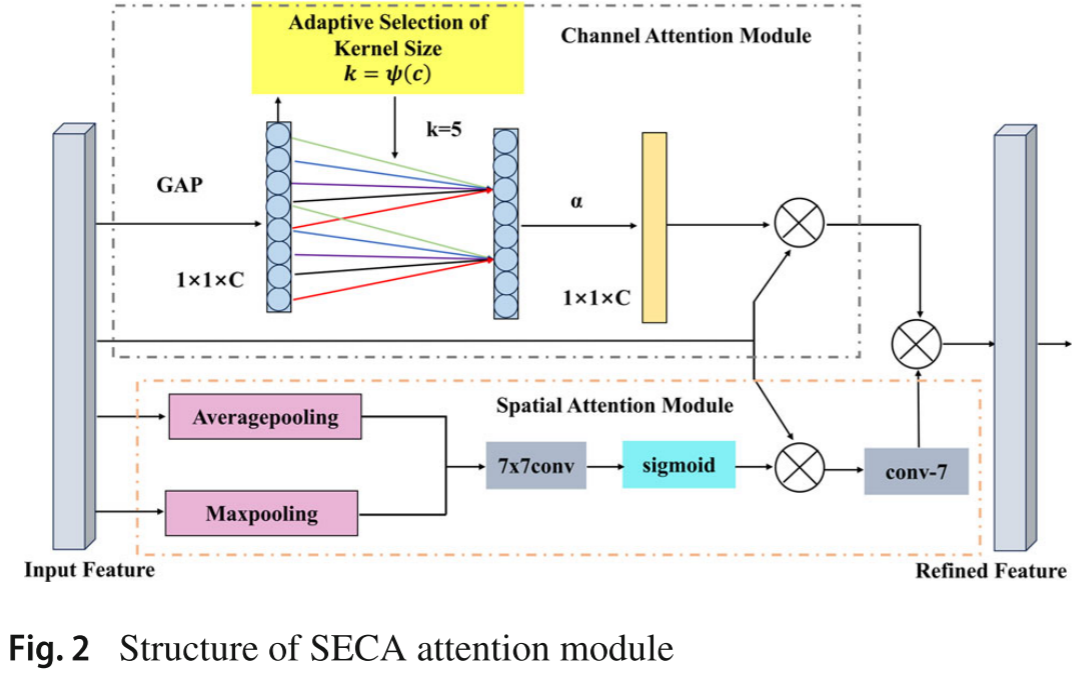
📷 【配图:图2 --- SECA 注意力模块结构图】
对应论文 Figure 2,展示 GAP、1×C、7×7conv、sigmoid 及各路分支的并行连接方式。
效果(消融实验数据) :在 UA-DETRAC 数据集上,单独引入 SECA 后,mAP@0.5 达到 61.6% ,FPS 达到 207.62 ,相比使用 ECA 模块分别提升 0.9% 和 1.7%。
2.2 创新点二:改进的 Backbone --- SECA_SPD_Conv
问题根源:步长卷积和池化层的使用导致细粒度信息丢失,YOLOv8 原始 Backbone 在低分辨率和模糊场景下感受野受限。
解决方案 :将 YOLOv8 的 Backbone 替换为集成了 SECA 注意力模块的 SPD-Conv。
SPD-Conv(Space-to-Depth Convolution)的核心思想是:用空间到深度(SPD)层替换每个步长卷积层和池化层,后接无步长卷积层(Non-strided Conv)。
以 scale=2 为例,给定大小为 S \\times S \\times C_1 的特征图 X,SPD 操作生成四个子特征图:
每个子图形状为 ,通过拼接将特征图转换为
,再经无步长卷积得到最终特征图
。
这种方式保留了所有细粒度信息,避免了传统下采样方式的信息损失,使模型在处理低分辨率输入时能更有效地整合局部特征到全局特征。
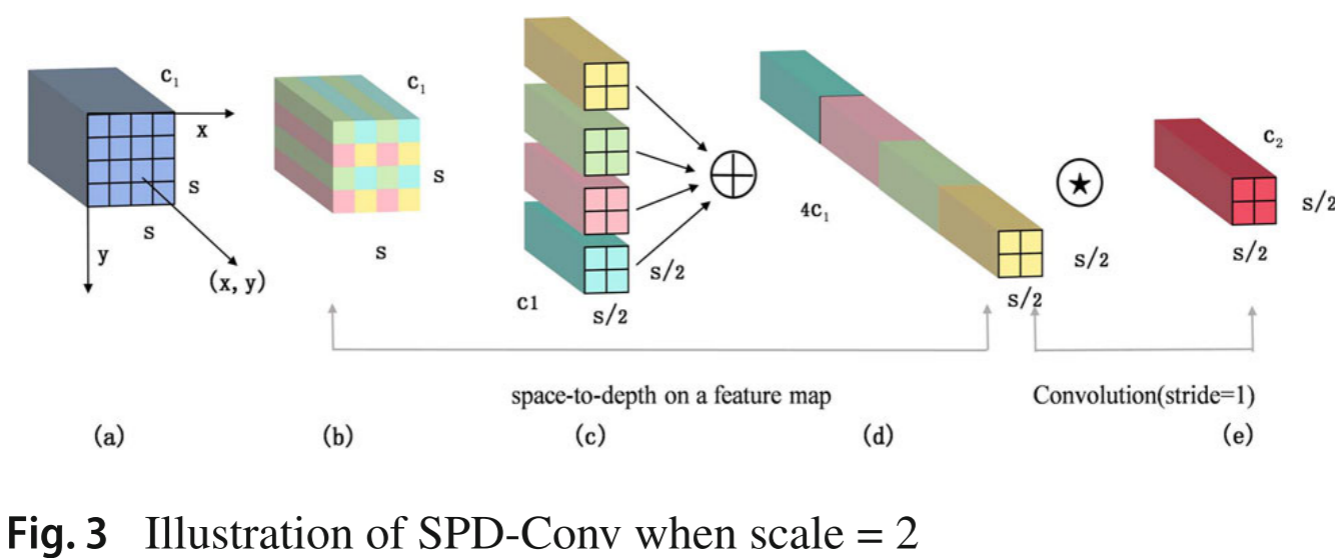
📷 【配图:图3 --- SPD-Conv 结构示意图(scale=2)】
对应论文 Figure 3,展示 space-to-depth 操作过程及子特征图的生成方式(a-e)。
效果(消融实验数据) :单独使用 SPD_Conv 替换 Backbone 后,mAP@0.5 和 FPS 分别达到 61.2% 和 206.97 ,相比 YOLOv8 基线分别提升 3.3% 和 3.8% 。当 SECA 与 SPD_Conv 同时使用时,mAP@0.5 达到 62.7% ,FPS 达到 224.65 ,相比 YOLOv8 基线分别提升 4.8% 和 7.68%。
2.3 创新点三:高精细粒度特征融合网络 DY_GELAN
问题根源:现有融合方法(简单求和或拼接)导致大量关键信息在特征提取和空间变换过程中丢失,无法在低分辨率下实现高保真融合。
解决方案 :将 Neck 部分替换为 DY_GELAN ,即将动态上采样方法 DySample 与通用高效层聚合网络 GELAN 相结合:
- DySample :一种基于采样点的动态上采样方法,通过采样点生成器(Sample Point Generator)学习采样偏移 O 和原始网格 G,利用网格采样函数对输入特征进行重采样。相比双线性插值等固定方式,DySample 能更好地分离目标与背景,提升特征图分辨率,恢复空间细节,同时有效降低模型参数量。
- GELAN(Generalized Efficient Layer Aggregation Network) :通用高效层聚合网络,其具体实现为 RepNCSPELAN4 。该模块采用深度可分离卷积(将标准卷积分解为逐深度卷积和逐点卷积),每层卷积后应用批归一化(Batch Normalization),有效降低模型复杂度,并通过重复使用相同卷积模块来增强特征提取的多样性和深度。
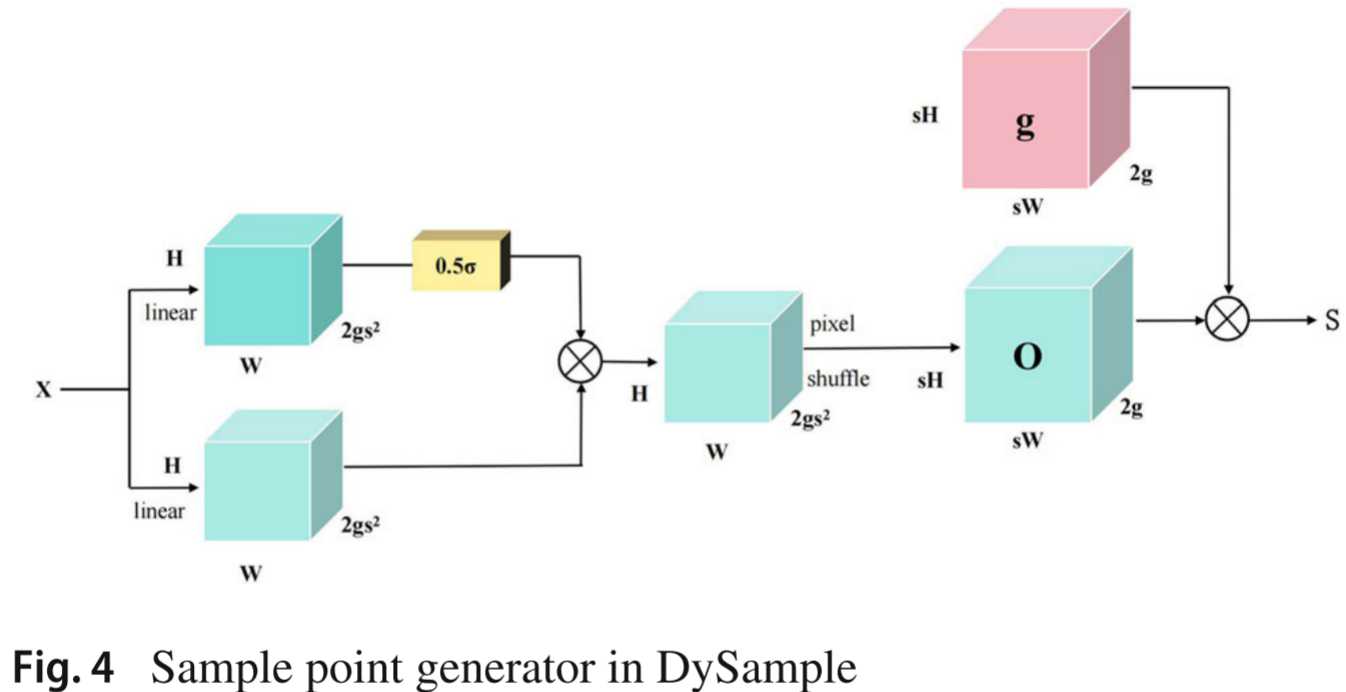
📷 【配图:图4 --- DySample 采样点生成器结构图】
对应论文 Figure 4,展示输入特征 X、偏移量 O、原始网格 G 及 Sigmoid 函数的连接关系。
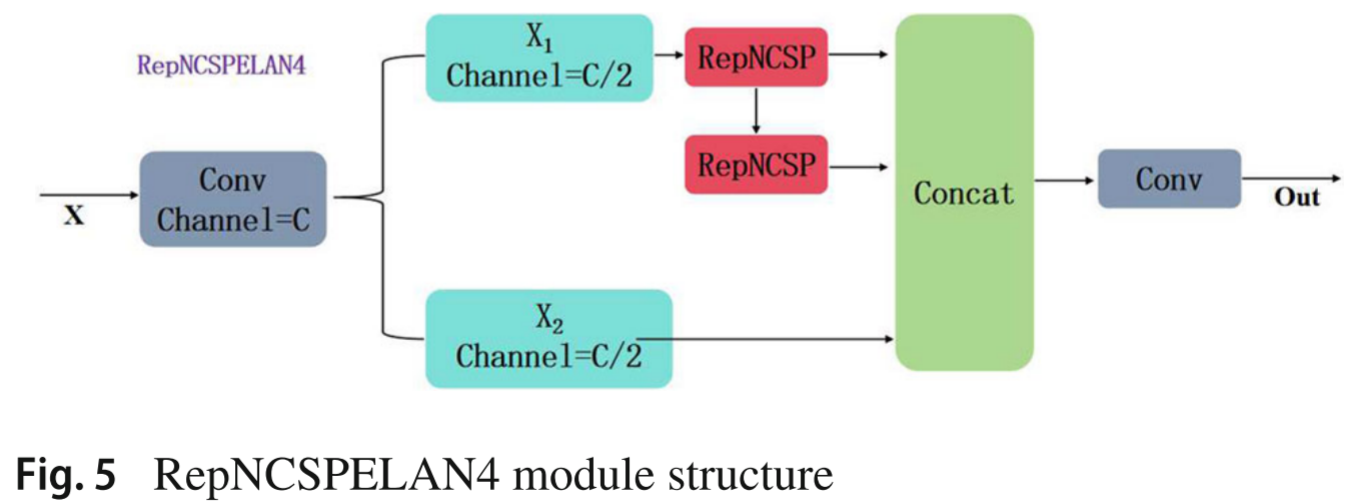
📷 【配图:图5 --- RepNCSPELAN4 模块结构图】
对应论文 Figure 5,展示 Channel1=C、Channel1=C/2、RepNCSP、Concat 及 Conv 的组合方式。
效果(消融实验数据):
| 配置 | mAP@0.5 (%) | Params (M) | FPS |
|---|---|---|---|
| YOLOv8 + GELAN | 62.9 | 3,721,148 | 228.89 |
| YOLOv8 + DY_GELAN | 62.6 | 3,182,108 | 221.37 |
| YOLOv8 + SECA + SPD_Conv + DY_GELAN(SPR-YOLO) | 64.3 | 3,942,129 | 214.68 |
DySample 在仅损失 0.3% 精度的情况下,显著降低了参数量 ;GELAN 相比 YOLOv8 原始 Neck 提升 mAP50 达 5%。
2.4 创新点四:Inner_CIOU 损失函数
问题根源:YOLOv8 使用的 CIoU 损失函数对宽高比过于敏感,在目标形状因噪声而变化较大的模糊场景(如雨雾、夜间)中,容易产生不良的边框预测结果。
解决方案 :引入 Inner_CIOU,通过引入缩放因子 ratio(通常范围 0.5, 1.5),计算辅助内部边框的大小,重点评估重叠区域内部质量,避免宽高比差异过大导致的评估偏差:
最终的 Inner_CIOU 损失定义为:
效果 :Inner_CIOU 损失函数收敛速度更快,检测精度相比 CIOU 提升 0.7%。
2.5 创新点五:ByteTracker 跟踪与自定义区域流量检测
跟踪方案 :采用 ByteTracker 多目标跟踪算法,结合匈牙利算法和卡尔曼滤波,优化目标匹配与位置预测,并加入动态目标管理策略,有效应对遮挡导致的目标丢失问题。
流量检测方案 :提出自定义区域交通检测方法,替代传统的划线计数法:
- 用户可灵活定义检测范围(每个区域由五个点定义),系统自动校准坐标并计算中心位置。
- 车辆进入检测区域时被识别,由 ByteTracker 持续跟踪;当车辆越过中心点定义的水平面时进行分类,对应车辆类别计数加 1。
- 将车辆分为三类(轿车、公共汽车、大型卡车),在左右双向车道分别计数。
三、实验设置
- 训练数据集:UA-DETRAC(北京/天津 24 地点采集,共 140,000+ 帧,8,250 辆车,1.21 百万标注框,包含晴天、阴天、夜间、雨天及遮挡场景);DAWN 数据集(1,000 张图像,涵盖雾、雪、雨、沙尘四种天气)
- 数据集划分:训练集与测试集比例 4:1
- 训练参数:训练轮数 150 epochs,输入尺寸 640×640,批量大小 16,初始学习率 0.01
- 硬件环境:NVIDIA GeForce RTX 2080Ti GPU
- 软件环境:Python 3.9.19,PyTorch 2.0.1,CUDA 11.7
四、实验结果
4.1 UA-DETRAC 数据集对比实验
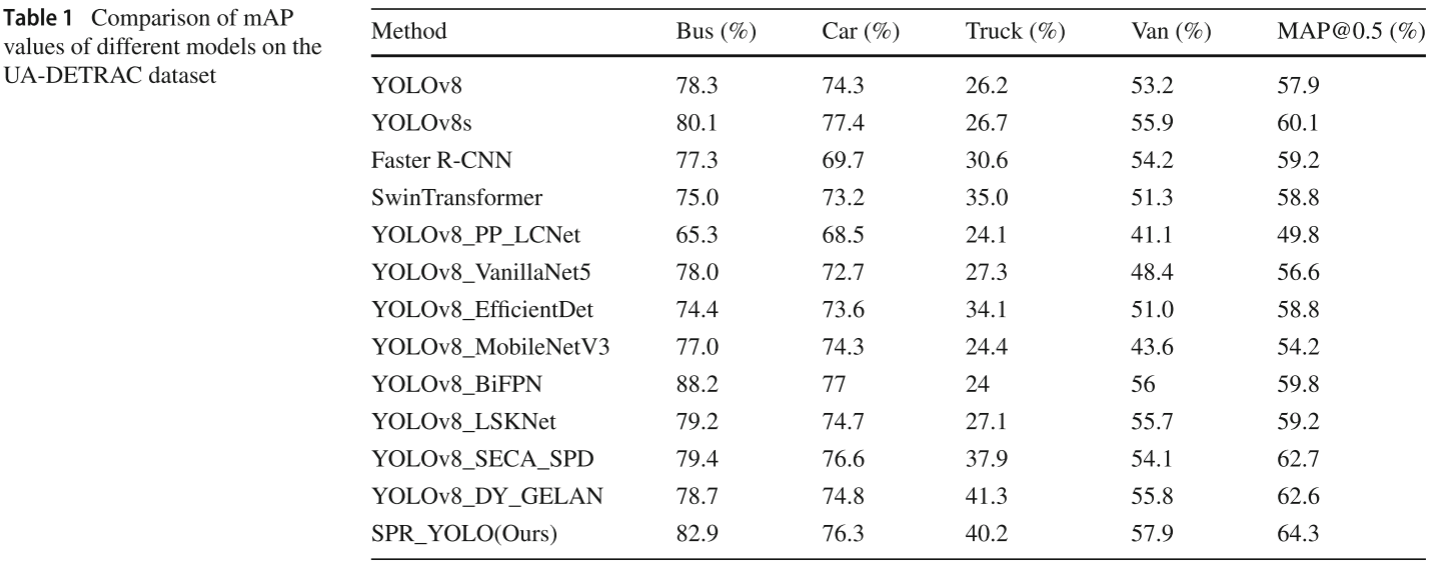
📋 【配表:表1 --- 不同模型在 UA-DETRAC 数据集上各车辆类别的 mAP 对比】
对应论文 Table 1,包含 Bus、Car、Truck、Van 四类别 MAP@0.5 及总体 MAP@0.5(%)。
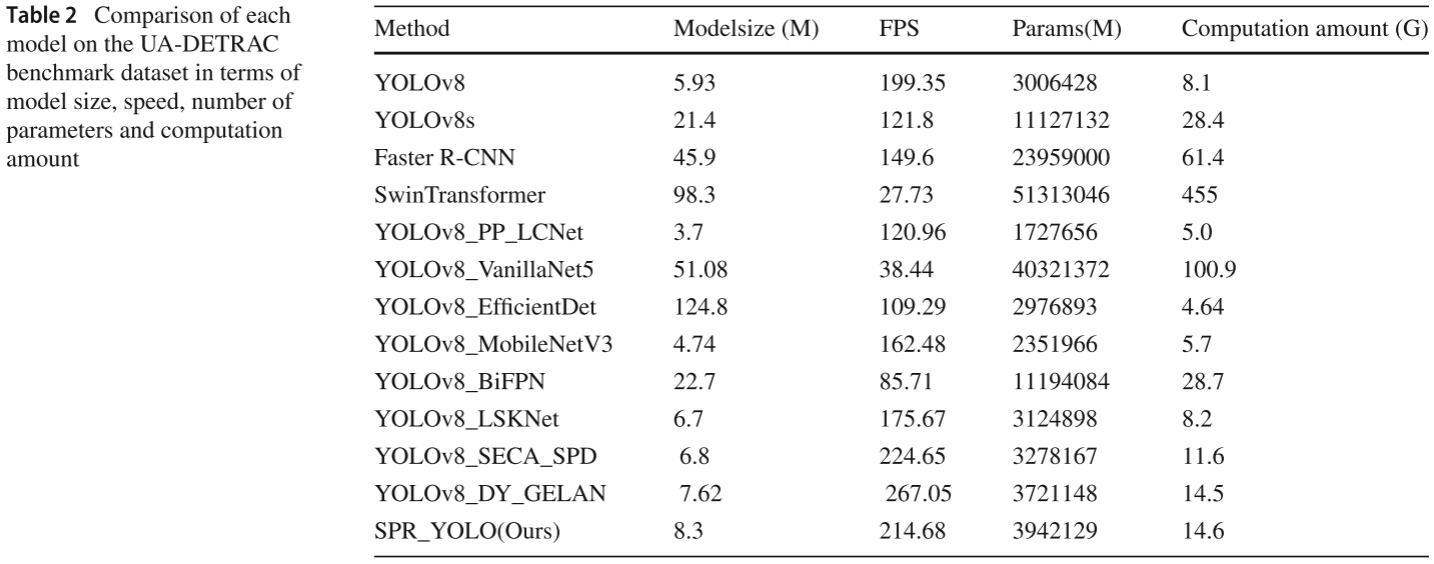
📋 【配表:表2 --- 不同模型在 UA-DETRAC 数据集上的模型大小、速度、参数量及计算量对比】
对应论文 Table 2,包含 Modelsize (M)、FPS、Params(M)、Computation amount (G)。
核心结论(相比 YOLOv8 基线):
- mAP@0.5 提升 6.4%(57.9% → 64.3%)
- FPS 提升 7.68%(199.35 → 214.68)
- 相比 YOLOv8s 提升 4.2% ;相比 EfficientDet 提升 5.52% ;相比 MobileNetV3 提升 10.1%
- 相比 YOLOv8 MobileNetV3,FPS 提升 32.12%
- 相比 SwinTransformer(参数量 51.3M,FPS 仅 27.73),SPR-YOLO 以 3.94M 参数量、214.68 FPS 实现了性能的全面超越
4.2 DAWN 数据集验证实验
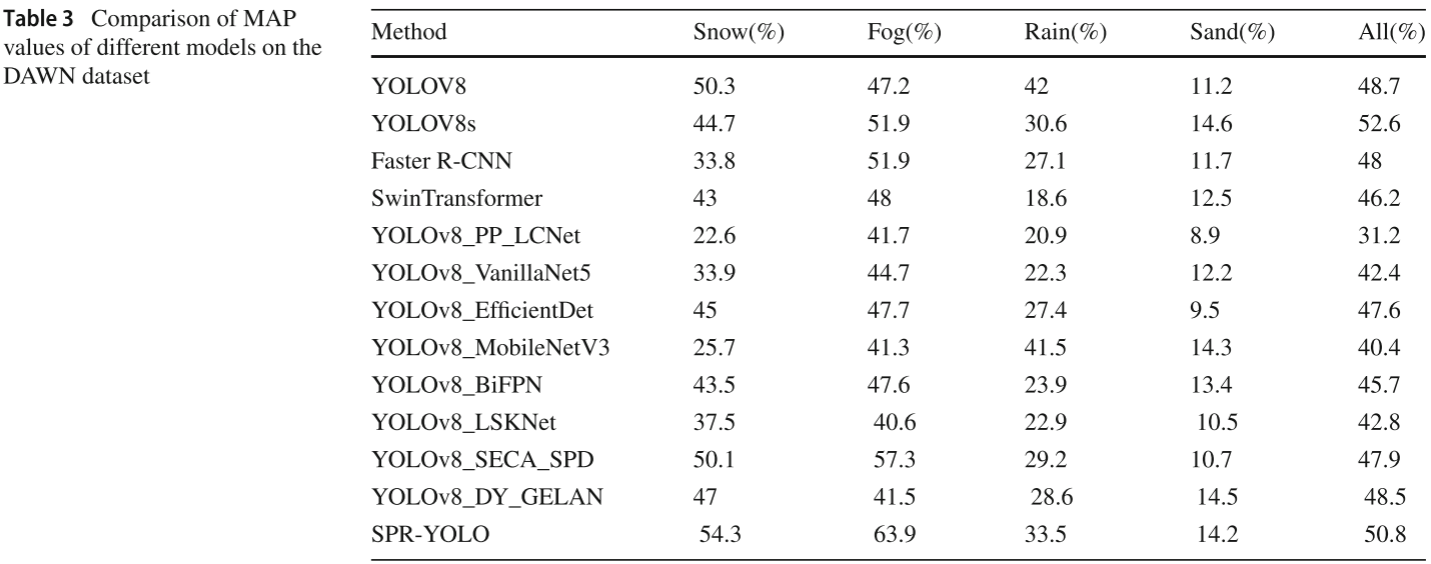
📋 【配表:表3 --- 不同模型在 DAWN 数据集四种天气条件下的 MAP 对比】
对应论文 Table 3,包含 Snow、Fog、Rain、Sand 及综合 All(%)。
核心结论(相比 YOLOv8 基线):
- 雪天(Snow) :提升 7.9%(50.3% → 54.3%)
- 大雾(Fog) :提升 35.38%(47.2% → 63.9%),提升最为显著
- 雨天(Rain):33.5%,略低于 YOLOv8 基线(42%),存在一定差距
- 沙尘(Sand):14.2%,与 YOLOv8s 和 Faster R-CNN 持平
- 综合(All) :相比 YOLOv8 提升 4.31%(48.7% → 50.8%)
4.3 消融实验

📋 【配表:表4 --- SECA_SPD_Conv 消融实验结果】
对应论文 Table 4,包含各模块组合的 MAP50 (%)、Params(M)、FPS。
4.4 可视化结果对比
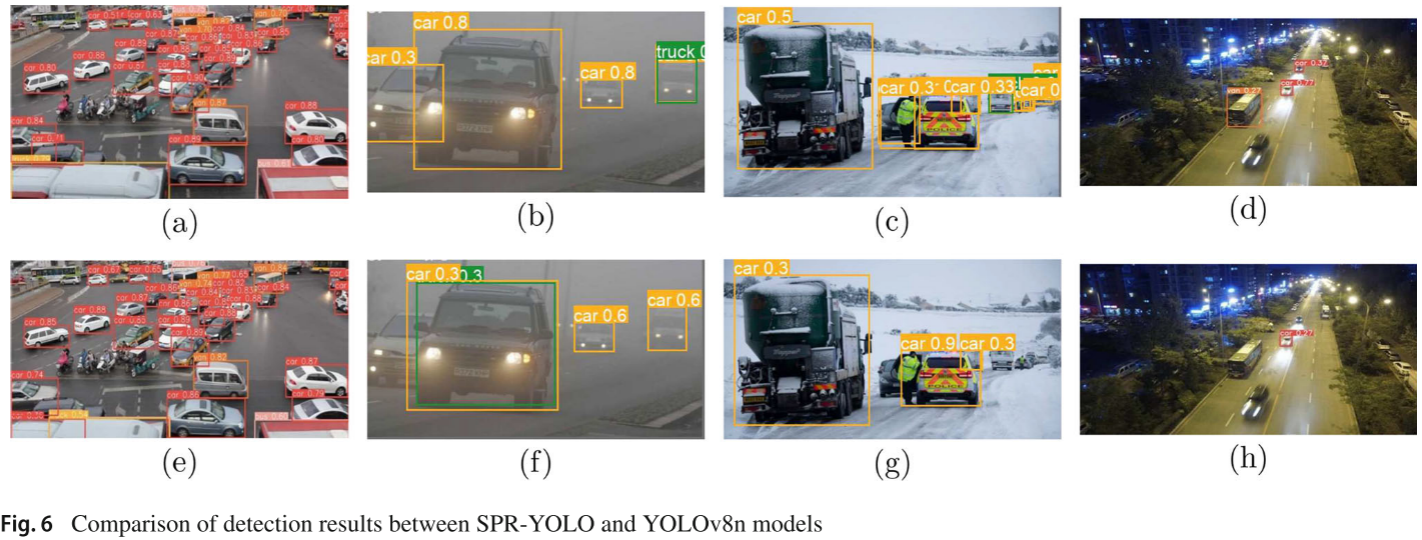
📷 【配图:图6 --- SPR-YOLO 与 YOLOv8n 检测结果可视化对比】
对应论文 Figure 6,展示密集场景(a/e)、大雾(b/f)、雪天(c/g)、夜间(d/h)四种场景下两模型的检测效果对比。
从可视化结果来看:
- 在密集场景下,YOLOv8n 无法识别右侧及远处密集的车辆,SPR-YOLO 则可以完成该任务。
- 在雾天和雪天场景下,YOLOv8n 在噪声干扰下性能显著下降,对小目标和遮挡目标的检测明显较差。
- 在低光照(夜间)场景下,YOLOv8n 性能同样大幅下滑,而 SPR-YOLO 保持较好的检测能力。
4.5 自定义区域交通流检测效果
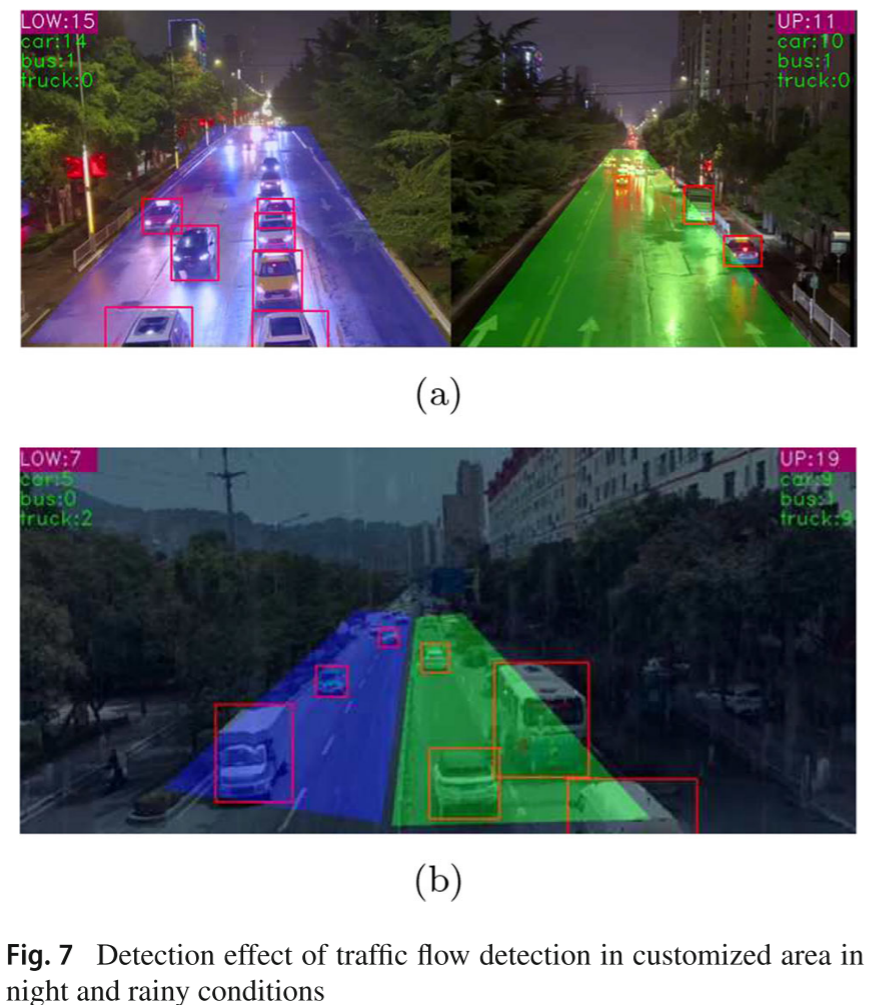
📷 【配图:图7 --- 夜间与雨天场景下自定义区域交通流检测效果示意图】
对应论文 Figure 7(a/b),展示梯形检测区域设置及上下行车辆统计计数的实际效果。
在两段各 3 分钟的真实路况视频(雨天 + 夜间)上,通过模型估计与人工统计对比,得到以下精度数据:
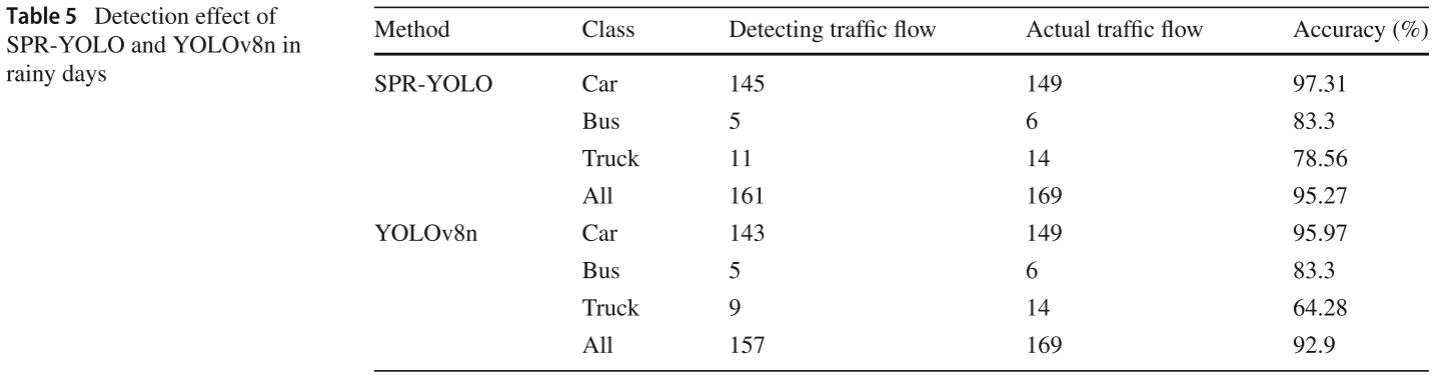
📋 【配表:表5 --- SPR-YOLO 与 YOLOv8n 在雨天场景的交通流检测精度对比】
对应论文 Table 5,含 Car/Bus/Truck 三类检测流量、实际流量及精度(%)。
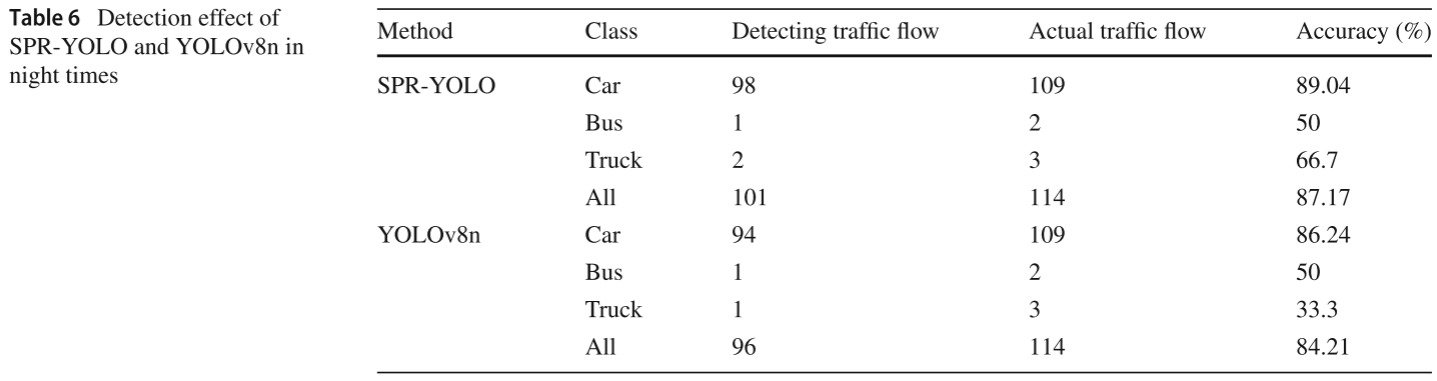
📋 【配表:表6 --- SPR-YOLO 与 YOLOv8n 在夜间场景的交通流检测精度对比】
对应论文 Table 6,含 Car/Bus/Truck 三类检测流量、实际流量及精度(%)。
| 场景 | SPR-YOLO 精度 | YOLOv8n 精度 |
|---|---|---|
| 雨天 | 95.27% | 92.9% |
| 夜间 | 87.17% | 84.21% |
五、总结与不足
主要贡献回顾
SPR-YOLO 通过以下组合创新,在轻量级(约 3.94M 参数)的前提下,实现了对 YOLOv8 在模糊场景下的全面超越:
- SECA:双维度注意力机制,同步强化通道与空间特征感知。
- SPD_Conv Backbone:替代步长卷积,保留低分辨率图像中的细粒度信息。
- DY_GELAN Neck:动态采样上采样 + 高效层聚合,实现高保真特征融合。
- Inner_CIOU:更适合模糊场景的边框回归损失,加速收敛。
- ByteTracker + 自定义区域检测:端到端的交通流跟踪与统计方案。
现存不足与未来方向
- 当图像极低分辨率或噪声极强时,模型性能仍受到一定约束。
- 自定义区域统计方法目前仅针对双向双车道进行优化,通用性有待提升。
- 模型尚未在嵌入式设备或移动端完成部署,计算需求对边缘设备仍是挑战。
- 未来计划将模型应用于显著性目标检测或遥感图像目标检测,并迁移至嵌入式平台,进一步逼近交通流的实时检测。