引言
在前面的树系列中,我们学习的 BST、AVL 树、红黑树都是二叉树------每个节点最多两个子节点。当数据量小、能全部放进内存时,二叉树足够高效。
但现实是:数据库和文件系统的索引数据动辄几十 GB,远远超出内存容量,必须存储在磁盘上。磁盘 I/O 的速度比内存慢了几十万倍,传统的二叉树高度太高,一次查找需要访问几十个磁盘页,完全不可接受。
B 树 正是为此而生。它是一种多路平衡搜索树 ,每个节点可以存储多个键、拥有多个子节点,通过"矮胖"的结构大幅降低树的高度,从而减少磁盘 I/O 次数。

第一部分:B 树的基本概念
一、什么是 B 树
B 树(B-Tree)是一种自平衡的多路搜索树,由 Rudolf Bayer 和 Edward McCreight 于 1971 年提出。
B 树的定义(m 阶 B 树):

二、B 树节点的内部结构

三、B 树 vs 二叉树的高度对比

第二部分:B 树的查找
一、查找过程
B 树的查找和 BST 类似,区别在于每个节点内有多个键,需要在节点内找到正确的区间。
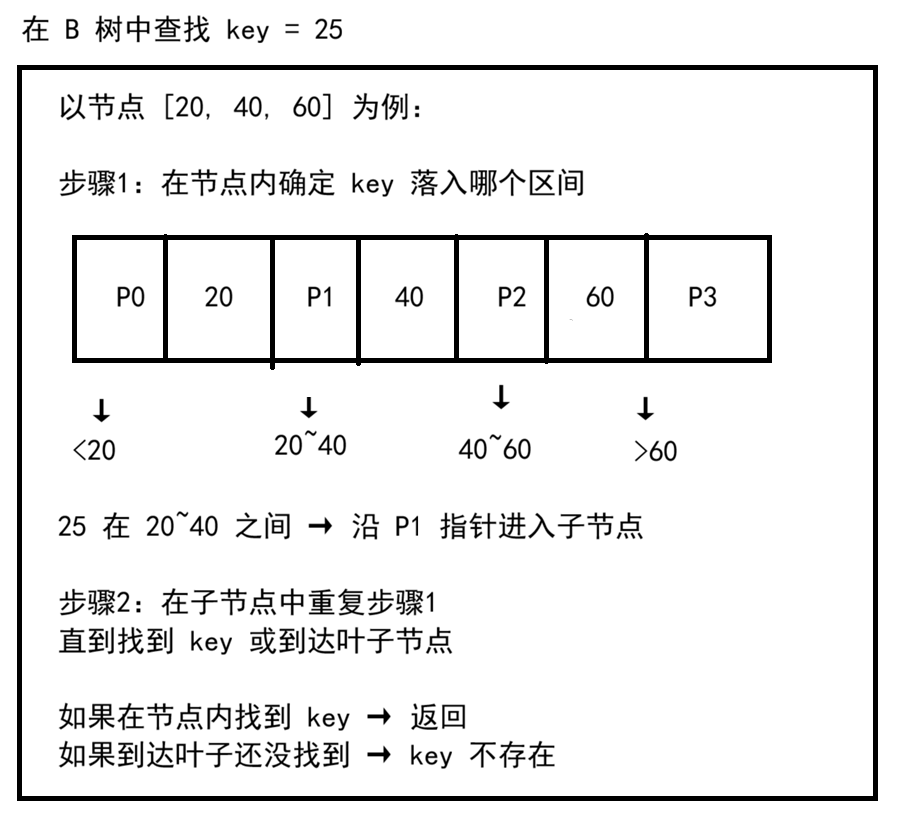
二、查找代码
cpp
#define M 5 // B 树的阶
typedef struct BTreeNode {
int keys[M - 1]; // 键数组(最多 M-1 个键)
struct BTreeNode* children[M]; // 子节点指针数组(最多 M 个)
int n; // 当前键的数量
int isLeaf; // 是否为叶子节点(1=叶子,0=内部节点)
} BTreeNode;
// 在节点 node 内查找 key
// 找到返回 1 并设置 *pos 为 key 的下标
// 未找到返回 0 并设置 *pos 为应该进入的子节点下标
int searchInNode(BTreeNode* node, int key, int* pos) {
int i = 0;
while (i < node->n && key > node->keys[i]) {
i++;
}
if (i < node->n && key == node->keys[i]) {
*pos = i;
return 1; // 找到了
}
*pos = i; // 没找到,返回应进入的子节点下标
return 0;
}
// 在 B 树中查找 key
BTreeNode* search(BTreeNode* root, int key) {
if (root == NULL) return NULL;
int pos;
if (searchInNode(root, key, &pos)) {
return root; // 在当前节点找到了
}
if (root->isLeaf) {
return NULL; // 叶子节点,不存在
}
return search(root->children[pos], key); // 进入子节点继续找
}第三部分:B 树的插入
一、插入策略
B 树的插入比二叉树复杂很多,因为节点有容量上限。核心策略 :始终插入到叶子节点;如果节点满了就分裂。

二、分裂过程(5 阶 B 树,M=5,每节点最多 4 键)

三、插入代码
cpp
// 分裂节点 node 的第 childIndex 个子节点(该子节点已满)
void splitChild(BTreeNode* parent, int childIndex) {
BTreeNode* child = parent->children[childIndex];
BTreeNode* newChild = (BTreeNode*)malloc(sizeof(BTreeNode));
newChild->isLeaf = child->isLeaf;
int mid = (M - 1) / 2; // 中间键的位置
// 右半部分的键复制到新节点
newChild->n = child->n - mid - 1;
for (int j = 0; j < newChild->n; j++) {
newChild->keys[j] = child->keys[mid + 1 + j];
}
// 如果不是叶子,复制子指针
if (!child->isLeaf) {
for (int j = 0; j <= newChild->n; j++) {
newChild->children[j] = child->children[mid + 1 + j];
}
}
child->n = mid; // 左半部分保留在原节点
// 父节点腾出位置,插入中间键
for (int j = parent->n; j > childIndex; j--) {
parent->keys[j] = parent->keys[j - 1];
parent->children[j + 1] = parent->children[j];
}
parent->keys[childIndex] = child->keys[mid];
parent->children[childIndex + 1] = newChild;
parent->n++;
}
// 向非满节点插入 key(递归辅助函数)
void insertNonFull(BTreeNode* node, int key) {
int i = node->n - 1;
if (node->isLeaf) {
// 叶子节点:找到位置直接插入
while (i >= 0 && key < node->keys[i]) {
node->keys[i + 1] = node->keys[i];
i--;
}
node->keys[i + 1] = key;
node->n++;
} else {
// 内部节点:找到应该进入的子节点
while (i >= 0 && key < node->keys[i]) i--;
i++; // 子节点下标
// 如果子节点满了,先分裂
if (node->children[i]->n == M - 1) {
splitChild(node, i);
if (key > node->keys[i]) i++; // 确定分裂后进入哪个子节点
}
insertNonFull(node->children[i], key);
}
}
// B 树插入主函数
BTreeNode* insert(BTreeNode* root, int key) {
if (root == NULL) {
BTreeNode* node = (BTreeNode*)malloc(sizeof(BTreeNode));
node->keys[0] = key;
node->n = 1;
node->isLeaf = 1;
return node;
}
if (root->n == M - 1) {
// 根满了,创建新根
BTreeNode* newRoot = (BTreeNode*)malloc(sizeof(BTreeNode));
newRoot->isLeaf = 0;
newRoot->n = 0;
newRoot->children[0] = root;
splitChild(newRoot, 0);
insertNonFull(newRoot, key);
return newRoot;
}
insertNonFull(root, key);
return root;
}第四部分:B 树的删除
B 树的删除是最复杂的操作,核心原则是:删除后每个节点仍满足最少键数的要求(根除外,内部节点至少 ⌈M/2⌉-1 个键)。
一、删除的三种情况

二、删除后的"借"与"合并"
当节点删除后键数不足最少要求时


第五部分:B 树的性能分析
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
| 查找 | O(log n) | 每层在节点内二分查找 O(log m) + 树高 O(logₘ n) = O(log n) |
| 插入 | O(log n) | 可能向上分裂,最坏到根 |
| 删除 | O(log n) | 可能借键或合并,最坏到根 |
| 空间 | O(n) | 每节点有 M-1 个键和 M 个指针 |
总结
一、B 树核心要点
| 要点 | 内容 |
|---|---|
| 核心思想 | 多路搜索,"矮胖"结构减少磁盘 I/O |
| 节点结构 | 键 + 子指针,键在节点内有序 |
| 插入 | 总是插入叶子,满了就分裂,可能向上递归 |
| 删除 | 删内部节点用前后继替代,删叶子可能借或合并 |
| 平衡性 | 所有叶子在同一层 |
| 应用 | 数据库索引(B+ 树变体)、文件系统 |
二、B 树 vs 二叉树
| 对比 | 二叉树 | B 树 |
|---|---|---|
| 子节点数 | 2 | M 个 |
| 树高 | 高(log₂n) | 矮(logₘn) |
| 磁盘 I/O | 多 | 少 |
| 适用场景 | 内存 | 磁盘 |
三、一句话记忆
B 树是多路平衡搜索树,每个节点存多个键、有多个子节点,通过"矮胖"结构大幅降低树高,从而减少磁盘 I/O 次数,是数据库和文件系统索引的底层基石。