基于 YOLO 的小麦麦穗检测系统的设计与实现
摘要
小麦是重要的粮食作物之一,麦穗数量与小麦产量估测、品种筛选和田间长势分析密切相关。传统麦穗计数主要依赖人工观察与人工标注,存在效率低、主观性强、难以批量处理等问题。随着深度学习目标检测技术的发展,利用计算机视觉方法对麦穗进行自动识别与计数,已经成为智慧农业和作物表型分析中的重要研究方向。
本文围绕 Global Wheat Detection 数据集,设计并实现了一套基于 YOLO 的小麦麦穗智能检测系统。系统采用 Python 语言开发,后端使用 FastAPI 框架提供接口服务,前端采用原生 HTML、CSS 和 JavaScript 实现交互界面,目标检测与模型训练基于 Ultralytics YOLO 框架完成。系统实现了数据集格式转换、单张图片检测、批量图片检测、摄像头实时检测、模型训练控制、训练日志查看、训练结果可视化和权重切换等功能。针对项目所在环境可能存在多个 Python 或 Conda 环境的问题,系统还在启动脚本中实现了 CUDA 环境自动检测与优先切换机制,以提升 GPU 资源利用率。
系统开发过程中,本文重点完成了 Kaggle 原始 CSV 标注到 YOLO 标注格式的转换、FastAPI 接口设计、YOLO 推理结果可视化、批量检测结果压缩导出、MJPEG 实时视频流输出以及前端田间检测主题界面设计。经测试,系统能够正确读取数据集统计信息,完成 147793 个标注框的格式转换,保持转换前后标注数量一致;单图检测接口、批量检测接口、实时摄像头接口、训练管理接口均能按预期响应。该系统具有较好的实用性和可扩展性,可作为小麦麦穗检测算法验证、田间演示和本科阶段智能农业应用开发的基础平台。
关键词: 小麦麦穗检测;YOLO;FastAPI;目标检测;智慧农业;深度学习
在这里插入图片描述
第 1 章 绪论
1.1 研究背景
小麦是世界范围内广泛种植的粮食作物,其产量稳定性直接关系到粮食安全。麦穗作为小麦生长后期的重要表型特征,能够反映植株生长状态、成穗情况和潜在产量。在农业科研和生产管理中,研究人员常常需要通过麦穗数量统计来辅助分析小麦品种表现、田间管理效果和产量水平。
传统麦穗统计方式主要依赖人工计数或人工标注图像。人工方式虽然直观,但在大面积田间环境和大规模图像样本中效率较低,且容易受到观察者经验、光照条件、麦穗遮挡和拍摄角度等因素影响。随着无人机、移动终端和田间摄像设备的普及,麦田图像采集成本逐渐降低,如何利用计算机视觉技术从图像中自动识别麦穗并进行计数,成为智慧农业应用中的现实需求。
近年来,深度学习目标检测算法快速发展,YOLO 系列算法因检测速度快、工程部署简洁、训练和推理流程成熟,被广泛用于农业目标检测任务。Global Wheat Detection 数据集提供了大量小麦麦穗图像及边界框标注,为构建麦穗检测系统提供了可靠数据基础。本文所实现的系统正是围绕该数据集和 YOLO 模型展开,通过 Web 应用形式将数据处理、模型训练、图片检测和实时识别集成到一个可运行的平台中。
1.2 研究意义
1.2.1 理论意义
从理论层面看,本文将深度学习目标检测方法应用于小麦麦穗识别任务,体现了计算机视觉技术在农业场景中的应用过程。项目围绕目标检测任务中的数据格式转换、边界框归一化、模型推理、检测结果后处理和可视化等环节展开,能够加深对 YOLO 检测模型工作流程的理解。同时,系统在工程实现中涉及前后端交互、异步训练任务管理、实时图像流输出等内容,有助于将本科阶段学习的 Web 开发、图像处理和人工智能相关知识进行综合运用。
1.2.2 实际应用意义
从实际应用层面看,系统能够对小麦图像中的麦穗进行自动检测和计数,减少人工统计工作量。单张图片检测适用于单样本分析,批量图片检测适用于数据集快速筛查,实时摄像头识别适用于田间演示和现场监测。系统提供模型训练入口和训练结果查看功能,使用户能够基于现有数据继续训练和优化模型。该系统虽然规模适中,但具有清晰的功能闭环,能够作为小麦表型分析、农业视觉检测教学实验和毕业设计项目的基础平台。
1.3 国内外研究现状
在国外研究中,深度学习已广泛应用于农业图像分析,包括作物病害识别、果实检测、杂草识别和作物表型测量等方向。Global Wheat Detection 竞赛推动了小麦麦穗检测任务的发展,不少研究者使用 Faster R-CNN、EfficientDet、YOLO、RetinaNet 等模型进行实验,并通过数据增强、多尺度训练和模型融合提高检测精度。
在国内研究中,智慧农业与作物表型分析逐渐受到重视。针对小麦、水稻、玉米等作物,研究人员利用卷积神经网络进行目标检测和图像分割,以辅助产量估测和长势监测。YOLO 系列算法由于推理速度快、部署难度较低,在农业实时检测场景中具有较高应用价值。国内不少本科和工程实践项目也开始采用 YOLOv5、YOLOv8 等模型完成农作物目标检测系统。
总体来看,现有研究多关注算法精度提升,而完整的工程系统往往涉及数据转换、模型训练、接口封装、结果可视化和运行环境适配等多个环节。本文不以提出全新检测算法为目标,而是围绕现有 YOLO 框架和真实数据集,完成一个能够运行、能够训练、能够展示结果的麦穗检测应用系统,重点体现算法工程化落地过程。
1.4 研究内容与研究方法
本文主要研究内容包括以下几个方面:
- 分析 Global Wheat Detection 数据集结构,读取
train.csv中的图像编号、尺寸、边界框和数据来源字段,统计训练图像数量、标注框数量和数据分布情况。 - 设计并实现数据集转换脚本,将 Kaggle CSV 格式中的
[x, y, w, h]标注转换为 YOLO 所需的归一化中心点格式。 - 基于 FastAPI 设计后端接口,实现数据集统计、模型状态查询、单图检测、批量检测、摄像头实时检测、模型训练启动与停止、训练日志读取和训练结果查询等功能。
- 基于原生 HTML、CSS 和 JavaScript 实现前端界面,提供小麦田间检测主题的操作页面和友好的交互反馈。
- 实现 CUDA 环境检测和优先使用 GPU 的启动机制,提高系统在多 Python 环境中的可运行性。
- 对系统关键功能进行测试,验证数据转换正确性、接口响应情况和核心功能可用性。
本文采用的研究方法主要包括文献调研法、需求分析法、模块化设计法、实验验证法和代码分析法。文献调研用于了解目标检测和农业视觉检测背景;需求分析用于明确系统功能边界;模块化设计用于拆分数据处理、后端服务、前端交互和模型训练模块;实验验证用于检查数据转换和接口功能;代码分析法用于解释关键函数和实现逻辑。
1.5 论文结构安排
本文共分为七章。第 1 章为绪论,介绍研究背景、意义、现状、研究内容和论文结构。第 2 章介绍系统涉及的相关技术基础,包括 Python、FastAPI、YOLO、OpenCV、前端技术和 CUDA。第 3 章进行系统需求分析,从功能性需求和非功能性需求两个方面说明系统目标。第 4 章进行系统总体设计,包括系统架构、模块划分、数据设计和交互流程。第 5 章详细说明系统实现,结合项目代码分析核心模块与关键函数。第 6 章进行系统测试与结果分析。第 7 章总结本文工作并提出后续改进方向。
第 2 章 相关技术基础
2.1 Python 语言
Python 具有语法简洁、第三方库丰富、适合快速开发和数据处理等特点,在人工智能和 Web 后端开发中应用广泛。本项目后端服务、数据集转换脚本和训练脚本均采用 Python 实现。项目中的 backend/main.py 负责 FastAPI 服务与 YOLO 推理,scripts/prepare_yolo_dataset.py 负责数据转换,scripts/train_yolo.py 负责模型训练,scripts/run_server.py 负责服务启动与环境切换。选择 Python 的原因在于其与 PyTorch、OpenCV、Ultralytics 等深度学习和图像处理库结合紧密,能够降低开发复杂度。
2.2 FastAPI 框架
FastAPI 是一个基于 Python 类型注解的高性能 Web 框架,支持快速定义 RESTful 接口,能够自动处理请求参数、文件上传和 JSON 响应。本项目使用 FastAPI 构建后端接口,例如 POST /api/detect/image 用于单图检测,POST /api/detect/batch 用于批量检测,GET /api/video/camera/stream 用于实时摄像头流,POST /api/train/start 用于启动训练任务。FastAPI 在本系统中的作用是连接前端界面、YOLO 模型和本地文件系统,使用户能够通过浏览器完成检测与训练操作。
2.3 YOLO 目标检测算法
YOLO 是一种单阶段目标检测算法,其核心思想是将目标定位和类别预测整合到一次前向推理中,具有较快的检测速度。相较于两阶段目标检测方法,YOLO 更适合实时检测和工程部署。本项目使用 Ultralytics YOLO 框架完成模型加载、训练和推理。在代码中,YOLO(str(selected)) 用于加载权重,model.predict(...) 用于对上传图片或摄像头帧进行检测,model.train(...) 用于模型训练。
本项目检测对象只有一类,即 wheat_head。因此模型输出结果中的类别字段主要用于保持 YOLO 标准格式,业务重点集中在边界框位置、置信度和目标数量统计上。
2.4 OpenCV 与 Pillow
OpenCV 是常用的计算机视觉库,适合图像读取、绘制、视频流处理和编码输出。本项目使用 OpenCV 完成检测框绘制、摄像头读取和 MJPEG 图像编码。函数 draw_boxes 使用 cv2.rectangle 和 cv2.putText 绘制边界框和置信度文本;实时识别接口使用 cv2.VideoCapture(camera) 获取摄像头帧,并使用 cv2.imencode(".jpg", rendered) 将图像帧编码为 JPEG。
Pillow 主要用于处理用户上传的图片。后端函数 read_upload_image 使用 Image.open(io.BytesIO(data)).convert("RGB") 读取上传文件并转换为 RGB 图像,再转为 OpenCV 使用的 BGR 数组格式。这种处理方式可以兼容 JPG、PNG、WEBP 等常见图片格式。
2.5 前端原生技术
本项目未使用 Vue、React 等前端框架,而是采用原生 HTML、CSS 和 JavaScript。这样可以减少构建依赖,避免 Node 环境配置问题。frontend/index.html 定义页面结构,frontend/styles.css 实现小麦田间检测主题样式,frontend/app.js 负责前端交互、接口请求、按钮状态、Toast 提示和结果渲染。原生前端方案结构简单,便于本科毕业设计展示和维护。
2.6 PyTorch 与 CUDA
PyTorch 是深度学习模型训练和推理的重要框架。Ultralytics YOLO 底层依赖 PyTorch 完成模型计算。CUDA 是 NVIDIA 提供的并行计算平台,能够显著提升深度学习训练和推理速度。本系统在 backend/main.py 和 scripts/train_yolo.py 中均定义了 preferred_device 函数,当 torch.cuda.is_available() 为真时优先使用 GPU 设备 0,否则回退 CPU。scripts/run_server.py 进一步检测 Conda 环境,若当前 Python 是 CPU 版 PyTorch,但存在 CUDA 可用且依赖完整的环境,则自动切换运行。
2.7 本项目技术选型总结
本项目技术选型服务于"可运行、可训练、可展示"的目标。Python 与 YOLO 适合目标检测开发,FastAPI 适合快速构建后端接口,OpenCV 适合图像和实时流处理,原生前端适合降低部署复杂度。整体技术路线与本科毕业设计的开发规模相匹配,既能体现人工智能应用开发能力,也能保证系统真实可落地。
第 3 章 系统需求分析
3.1 系统用户分析
系统主要面向三类用户:
- 农业视觉检测研究或学习人员:需要快速查看麦穗检测效果,进行模型训练和结果分析。
- 本科毕业设计演示人员:需要通过 Web 页面展示数据集、检测结果、训练日志和实时识别功能。
- 田间采集或实验辅助人员:需要对单张或多张麦田图片进行检测计数,并通过摄像头进行实时预览。
3.2 功能性需求
3.2.1 数据集统计需求
系统应能够读取 Global Wheat Detection 数据集,并展示训练图像数量、测试图像数量、标注框数量、标注分布和 YOLO 数据集是否准备完成。该需求对应后端 GET /api/dataset/summary 接口,由 dataset_summary 函数实现。前端通过 refreshDataset 函数调用该接口,并将训练图像数、标注框数和数据状态显示在首页指标卡中。
3.2.2 数据集转换需求
原始数据集标注保存在 train.csv 中,格式为 [x, y, w, h],不能直接被 YOLO 训练脚本使用。因此系统需要提供数据集转换功能,将原始标注转换为 YOLO 格式。该需求由 scripts/prepare_yolo_dataset.py 实现,同时后端提供 POST /api/dataset/prepare 接口调用该脚本。转换后的数据保存在 workspace/yolo_wheat/ 中。
3.2.3 单张图片检测需求
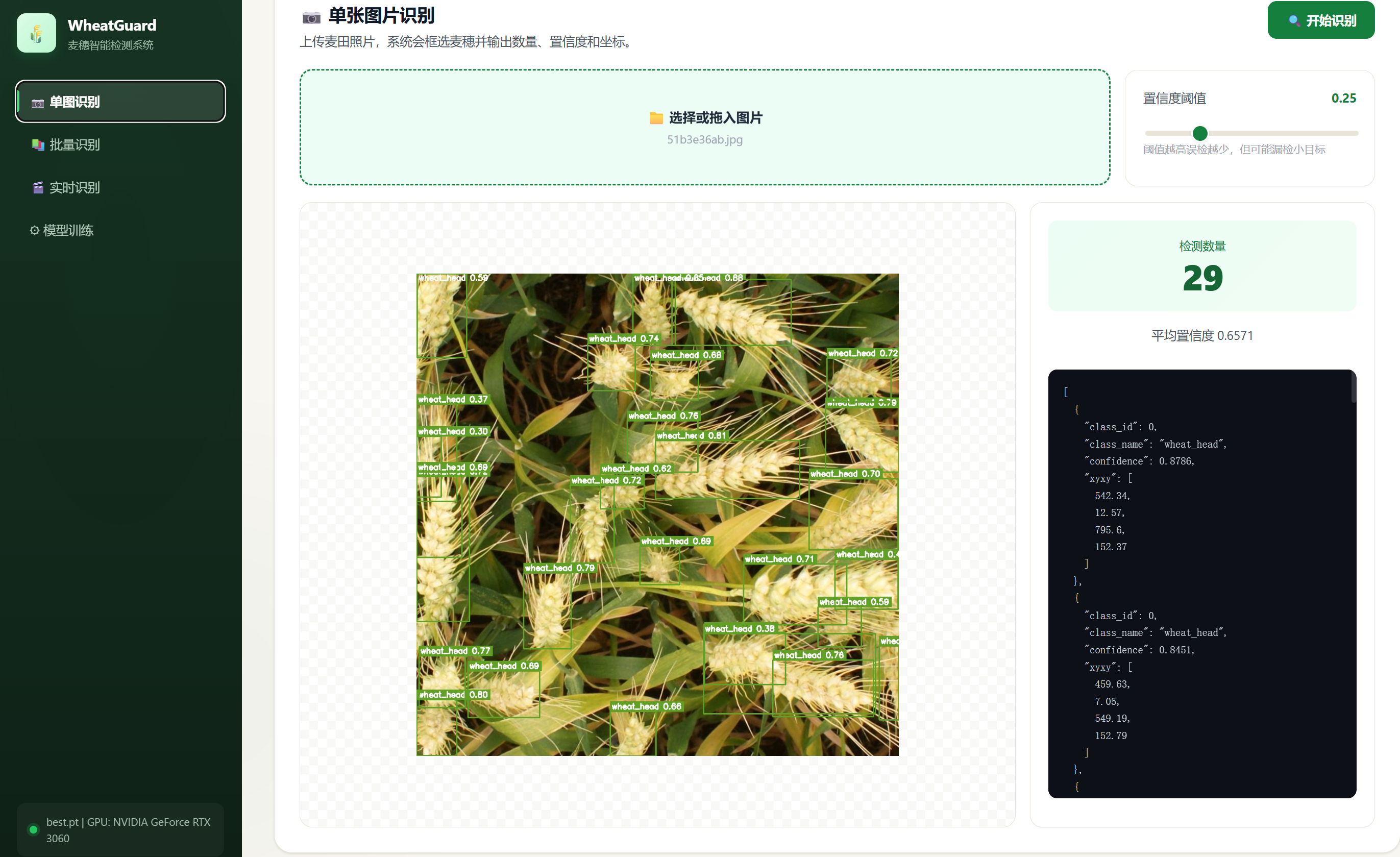
用户应能够上传一张图片,系统返回检测后的图片、麦穗数量、平均置信度和边界框 JSON 数据。该需求对应后端 POST /api/detect/image 接口,由 detect_image 函数实现。前端对应"单图识别"页面,使用 detectImageBtn 的点击事件上传图片并展示结果。
3.2.4 批量图片检测需求
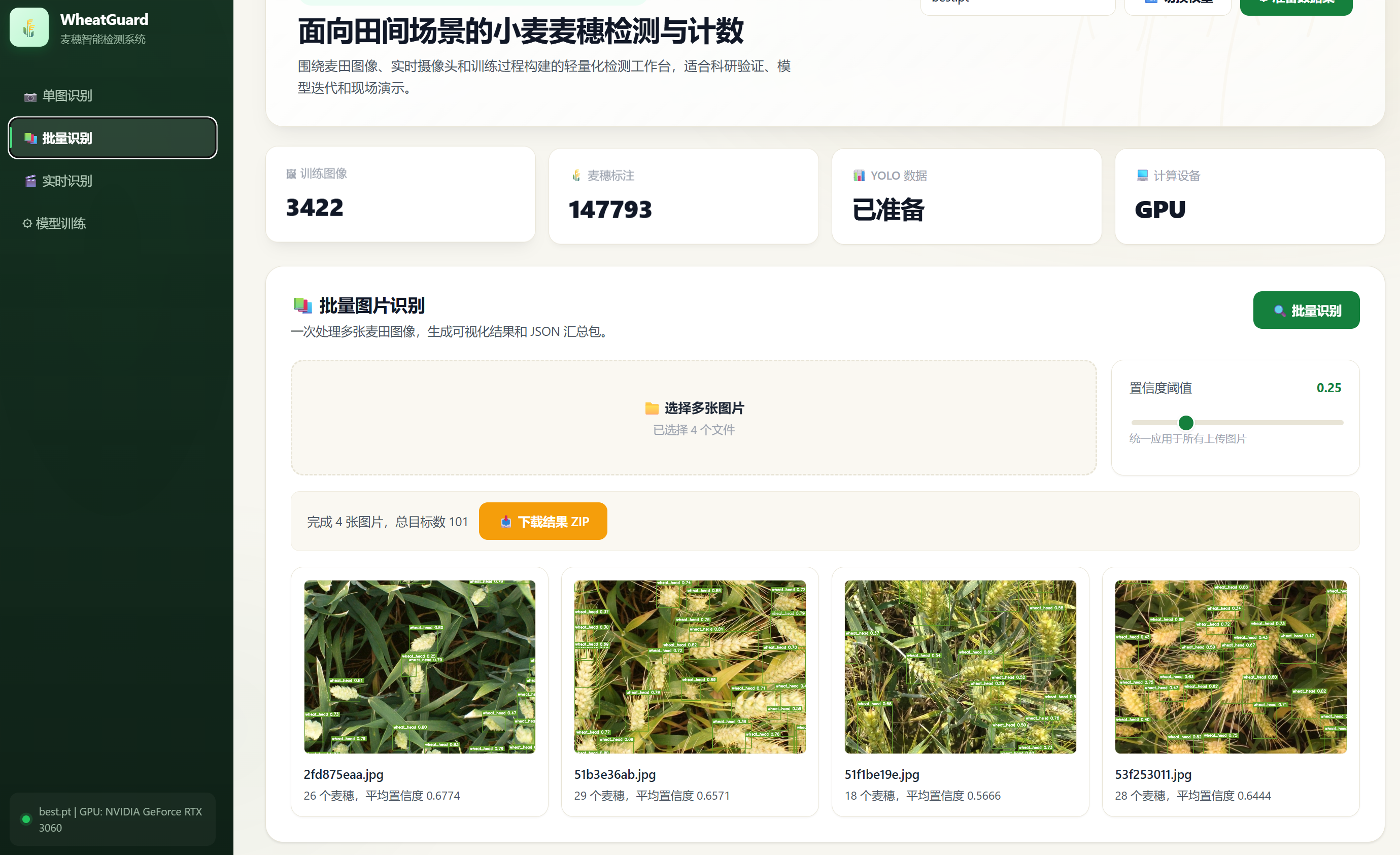
用户应能够一次上传多张图片,系统逐张检测后生成可视化结果,并提供 ZIP 文件下载。该需求对应后端 POST /api/detect/batch 接口,由 detect_batch 函数实现。该函数将每张图片的检测结果保存到 workspace/runs/batch/<run_id>/,并使用 zipfile.ZipFile 打包为 ZIP 文件。
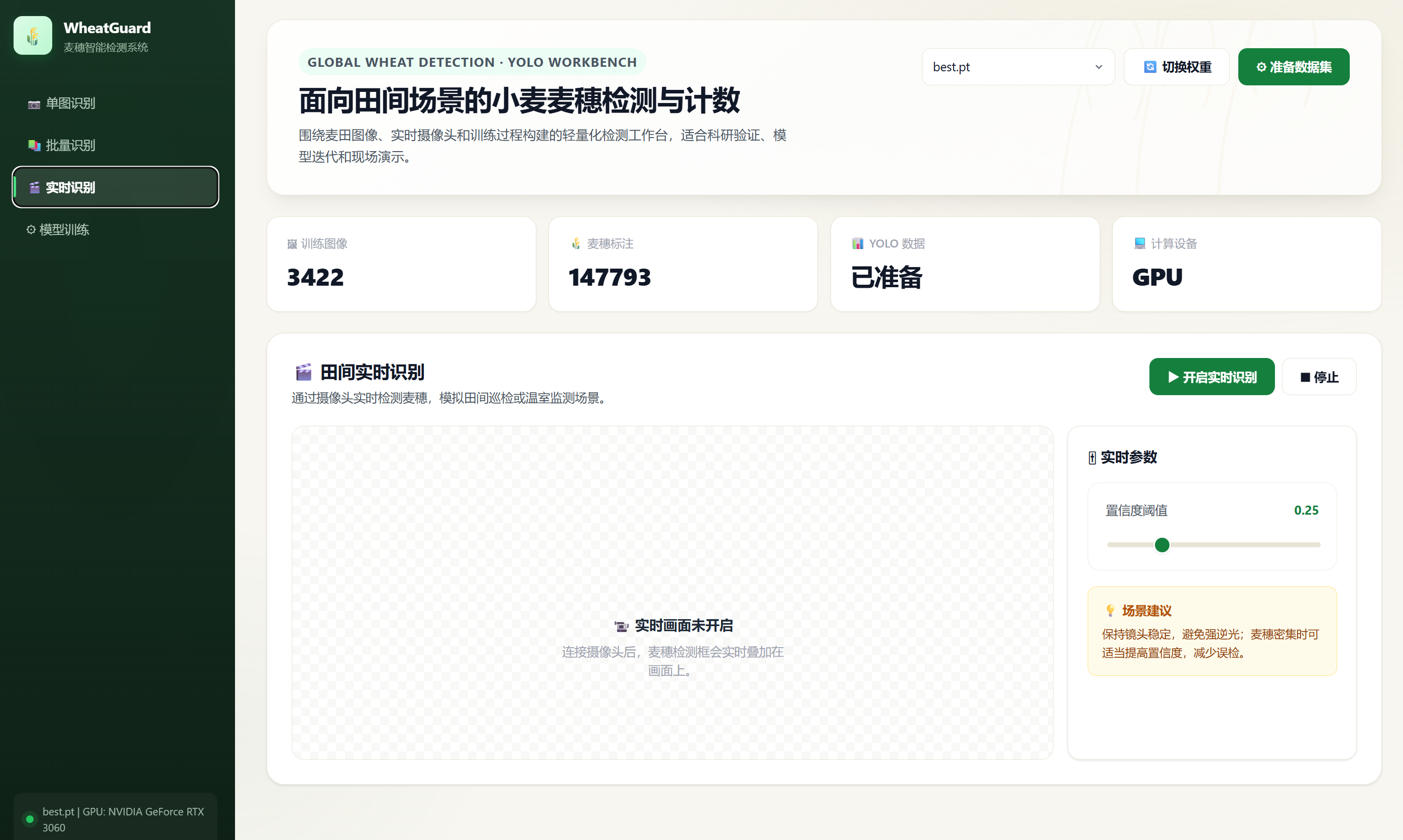
3.2.5 实时摄像头识别需求
系统应保留实时识别能力,支持通过本机摄像头获取画面并实时叠加检测框。该需求对应后端 GET /api/video/camera/stream 接口,由 camera_stream 函数实现。前端"实时识别"页面通过设置 cameraStream 图片元素的 src 为该接口地址来显示 MJPEG 流。根据项目当前需求,上传视频离线检测功能已移除。
3.2.6 模型管理需求
系统应自动发现可用模型权重,并允许用户在前端切换当前推理权重。该需求对应 GET /api/model/weights、GET /api/model/status 和 POST /api/model/reload 接口。后端 ModelManager 类负责权重发现、模型加载和状态返回。
3.2.7 模型训练需求
系统应支持从前端启动训练任务、停止训练任务、查看训练状态和读取实时日志。该需求对应 TrainingManager 类以及 /api/train/start、/api/train/stop、/api/train/status、/api/train/logs、/api/train/runs 等接口。训练实际由 scripts/train_yolo.py 调用 Ultralytics YOLO 完成。
3.3 非功能性需求
3.3.1 易用性需求
系统应通过浏览器提供清晰的操作入口,用户无需直接修改代码即可完成数据准备、模型切换、图片检测和训练启动。前端界面采用小麦田间主题设计,导航分为单图识别、批量识别、实时识别和模型训练,降低操作复杂度。
3.3.2 可靠性需求
系统应对空文件、非图片文件、缺失权重、摄像头不可用等情况进行处理。例如 read_upload_image 在文件为空或无法解析时抛出 HTTP 异常;ModelManager.load 在找不到权重时返回 409 错误;camera_stream 在摄像头不可用时返回占位帧而不是直接崩溃。
3.3.3 可扩展性需求
系统模块划分应清晰,便于后续扩展更多模型或检测类别。当前系统将数据转换、模型训练、后端接口和前端交互拆分到不同目录,后续可以在现有接口基础上增加更多检测算法、更多数据增强策略或用户管理功能。
3.3.4 性能需求
目标检测任务对计算资源要求较高。系统通过 preferred_device 函数优先使用 CUDA GPU,训练脚本和推理接口均支持 GPU 优先。在没有 CUDA 的环境中,系统仍可回退 CPU 运行,保证基本可用性。
3.4 用例分析
系统核心用例包括数据集准备、单图检测、批量检测、实时识别、模型训练、查看训练结果和切换权重。用例图如下:
用户
准备 YOLO 数据集
单张图片识别
批量图片识别
摄像头实时识别
启动/停止模型训练
查看训练日志与结果
切换模型权重
该用例图与前端导航和后端接口保持一致,反映了当前代码已经实现的主要功能。
第 4 章 系统总体设计
4.1 系统设计目标
系统总体设计目标包括:第一,能够基于原始数据集完成 YOLO 数据准备;第二,能够通过 Web 界面完成图片检测和实时检测;第三,能够管理模型训练过程和训练结果;第四,能够在存在 GPU 环境时优先使用 GPU;第五,系统结构清晰,便于本科毕业设计展示和后续维护。
4.2 系统总体架构
本系统采用轻量级前后端分离思想,但前端静态资源由 FastAPI 后端统一托管。整体架构可分为四层:前端交互层、后端接口层、模型与图像处理层、文件与数据层。
浏览器前端
HTML/CSS/JavaScript
FastAPI 后端接口
YOLO 推理与训练
Ultralytics + PyTorch
OpenCV 图像处理
绘框、摄像头、MJPEG
文件系统 workspace
权重、结果、日志、YOLO 数据集
global-wheat-detection
原始数据集
prepare_yolo_dataset.py
前端负责用户操作和结果展示;后端负责请求处理、模型调用和文件管理;YOLO 和 OpenCV 负责核心检测与图像处理;文件系统负责保存数据集转换结果、检测结果、训练输出和状态文件。
4.3 项目目录设计
项目目录与系统模块对应关系如下:
| 目录或文件 | 作用 |
|---|---|
backend/main.py |
FastAPI 应用入口,包含接口、模型管理、训练任务管理和实时流输出 |
frontend/index.html |
页面结构,包含四个核心功能页面 |
frontend/styles.css |
页面样式,小麦田间检测主题设计 |
frontend/app.js |
前端交互逻辑,负责调用后端接口和渲染结果 |
scripts/prepare_yolo_dataset.py |
将 Kaggle CSV 标注转换为 YOLO 格式 |
scripts/train_yolo.py |
调用 Ultralytics YOLO 训练模型 |
scripts/run_server.py |
启动服务并自动切换 CUDA Conda 环境 |
configs/default_train.yaml |
默认训练参数 |
configs/wheat.yaml |
YOLO 数据集配置模板 |
workspace/ |
系统运行时生成目录 |
4.4 后端模块设计
后端主要包含以下模块:
- 模型管理模块:由
ModelManager类实现,负责发现默认权重、加载 YOLO 模型和返回模型状态。 - 训练管理模块:由
TrainingManager类实现,负责启动训练进程、读取训练日志、停止训练和返回训练状态。 - 数据集模块:由
dataset_summary和prepare_dataset接口实现,负责数据统计和数据转换。 - 检测模块:由
detect_image、detect_batch、predict_image和draw_boxes实现,负责图像推理、绘制检测框和结果保存。 - 实时识别模块:由
camera_stream实现,负责读取摄像头帧并输出 MJPEG 流。 - 模型权重模块:由
model_status、model_weights和reload_model实现,负责前端权重显示与切换。
4.5 前端模块设计
前端页面分为四个主视图:
- 单图识别:上传单张图片,展示检测图和检测 JSON。
- 批量识别:上传多张图片,展示每张图片的检测结果卡片和 ZIP 下载链接。
- 实时识别:开启或停止摄像头 MJPEG 流,并调整置信度阈值。
- 模型训练:填写训练参数,启动训练,查看实时日志和训练结果。
前端交互由 app.js 实现,核心方式是使用 fetch 调用后端接口,并根据返回 JSON 更新 DOM。为了提升易用性,前端实现了按钮忙碌状态、Toast 提示和训练日志轮询。
4.6 数据设计
本系统没有使用传统关系型数据库。系统数据主要由原始数据集文件、YOLO 格式数据、模型权重和运行结果构成,存储在文件系统中。原因是本系统主要面向单机实验和毕业设计演示,文件系统已经能够满足需求,避免引入额外数据库增加部署复杂度。
主要数据文件如下:
| 数据文件或目录 | 说明 |
|---|---|
global-wheat-detection/train.csv |
原始标注文件,包含 image_id、width、height、bbox、source |
global-wheat-detection/train/ |
原始训练图像 |
workspace/yolo_wheat/images/train |
YOLO 训练图像 |
workspace/yolo_wheat/images/val |
YOLO 验证图像 |
workspace/yolo_wheat/labels/train |
YOLO 训练标签 |
workspace/yolo_wheat/labels/val |
YOLO 验证标签 |
workspace/training/ |
Ultralytics 训练输出 |
workspace/runs/ |
检测结果输出 |
workspace/state.json |
当前模型权重状态 |
由于没有数据库,本文不设计 ER 图。系统的数据关系可以理解为原始数据集经过转换脚本生成 YOLO 数据集,YOLO 数据集经过训练生成权重文件,权重文件再被后端推理接口调用生成检测结果。
第 5 章 系统详细实现
5.1 数据集转换模块实现
数据集转换功能位于 scripts/prepare_yolo_dataset.py。Global Wheat Detection 的原始标注采用 CSV 格式,其中 bbox 字段为 [x, y, w, h],表示边界框左上角坐标和宽高。YOLO 训练要求标签格式为:
text
class_id x_center y_center width height其中坐标和宽高均需归一化到 0 到 1 之间。项目中核心转换函数为 convert_bbox_to_yolo:
python
def convert_bbox_to_yolo(bbox, width, height):
x, y, w, h = bbox
xc = (x + w / 2.0) / width
yc = (y + h / 2.0) / height
nw = w / width
nh = h / height
return xc, yc, nw, nh该函数体现了目标检测标注格式转换的基本原理。原始标注以左上角为基准,而 YOLO 以目标中心点为基准,因此需要将 x + w/2 和 y + h/2 作为中心点,再除以图像宽高进行归一化。由于本数据集图像尺寸均为 1024×1024,转换过程较为统一,但代码仍然读取每行中的 width 和 height 字段,以保证对其他尺寸数据也具有一定兼容性。
转换脚本还处理了无标注图片。项目统计发现训练目录中共有 3422 张图片,其中 3373 张在 CSV 中有标注,49 张没有标注。脚本对无标注图片生成空标签文件,使 YOLO 训练时能够识别这些图像为无目标样本。这一处理有助于降低模型误检概率,也保证图像和标签文件数量一致。
数据集划分采用固定随机种子和约 8:2 的训练验证比例。脚本按照 source 字段分组后随机划分,能够在一定程度上保持不同数据来源在训练集和验证集中的分布。转换完成后,脚本生成 dataset.yaml,供 YOLO 训练使用。
5.2 CUDA 环境自动选择实现
项目运行环境中可能存在多个 Python 或 Conda 环境,有的环境安装 CPU 版 PyTorch,有的环境安装 CUDA 版 PyTorch。为避免用户启动错误环境导致 GPU 无法使用,项目在 scripts/run_server.py 中实现了环境自动检测。
脚本首先通过 current_python_has_cuda 判断当前 Python 是否可以使用 CUDA。如果当前环境不可用,则调用 choose_cuda_conda_env 遍历优先环境列表和 Conda 环境列表,并通过 conda_env_has_cuda 检测该环境是否同时满足两个条件:一是 torch.cuda.is_available() 为真;二是项目依赖如 fastapi、uvicorn、ultralytics、cv2 等存在。如果找到合适环境,脚本使用 conda run --no-capture-output -n <env> python scripts/run_server.py 重新启动服务。
这种实现方式解决了"系统有显卡但当前 Python 检测不到 CUDA"的常见问题。后端 backend/main.py 和训练脚本 scripts/train_yolo.py 中也都定义了 preferred_device 函数,保证训练和推理阶段都优先使用 GPU 设备 0。
5.3 模型管理模块实现
模型管理由 backend/main.py 中的 ModelManager 类完成。该类保存当前模型对象、当前权重路径和线程锁。其核心方法包括 discover_default_weight、load 和 status。
discover_default_weight 的查找顺序如下:
- 如果
workspace/state.json中记录的current_weight存在,则优先使用。 - 查找
workspace/training/**/weights/best.pt,选择修改时间最新的最佳权重。 - 查找项目根目录下的
yolov8n.pt作为默认初始权重。
这种设计符合实际使用流程:用户训练模型后,系统自动优先使用最新训练权重;如果尚未训练,则使用预训练权重进行流程验证。
load 方法负责实际加载 YOLO 模型。为了避免重复加载权重,代码判断当前模型为空或权重路径发生变化时才重新执行 YOLO(str(selected))。该设计减少了重复推理时的模型加载开销。
status 属性返回当前模型状态,包括是否加载、当前权重、默认权重、CUDA 是否可用、推荐设备、PyTorch 版本和 Python 路径。这些信息会被前端显示,方便用户判断系统是否运行在正确环境中。
5.4 图像读取与检测实现
单图和批量检测都依赖 read_upload_image、predict_image 和 draw_boxes 三个函数。
read_upload_image 负责读取上传文件。它首先读取二进制数据,判断文件是否为空,然后使用 Pillow 将文件转换为 RGB 图像,最后转为 OpenCV 使用的 BGR 数组。这样可以兼容不同图片格式,并为后续 OpenCV 绘图做准备。
predict_image 是推理核心函数。函数首先通过 model_manager.load() 获取当前 YOLO 模型,然后调用:
python
model.predict(source=image, conf=conf, iou=iou, device=preferred_device(), verbose=False)其中 conf 为置信度阈值,iou 为非极大值抑制相关阈值,device=preferred_device() 确保可用时使用 GPU。推理后,函数从 YOLO 返回结果中读取 boxes.xyxy、boxes.conf 和 boxes.cls,整理为前端可读的 JSON 结构。
draw_boxes 负责在原图上绘制检测框。函数遍历每个检测结果,使用绿色矩形框出麦穗位置,并在框上方绘制类别名和置信度。绘图后的图像会保存到 workspace/runs/images/ 或批量结果目录中,再通过 /outputs/ 静态资源路径提供给前端访问。
5.5 单图检测接口实现
单图检测接口定义为:
python
@app.post("/api/detect/image")
def detect_image(file: UploadFile = File(...), conf: float = Form(0.25), iou: float = Form(0.45)):该接口接收一个上传图片文件和检测参数。实现流程为:读取图片、调用 YOLO 推理、绘制检测框、保存结果图片、返回检测数量、检测框列表、结果图片地址和平均置信度。前端在 app.js 中通过 FormData 上传图片,并将返回的 image_url 设置到 imageResult 图片元素中,同时把检测 JSON 显示在结果面板中。
5.6 批量检测接口实现
批量检测接口定义为:
python
@app.post("/api/detect/batch")
def detect_batch(files: list[UploadFile] = File(...), conf: float = Form(0.25), iou: float = Form(0.45)):该接口接收多个图片文件。代码为每次批量任务生成唯一 run_id,在 workspace/runs/batch/<run_id>/ 下保存每张图片的检测图和 JSON 文件。全部图片处理完成后,接口生成 summary.json,并使用 Python 标准库 zipfile 将结果目录打包为 ZIP。前端展示每张图片的结果卡片,并显示 ZIP 下载链接。
该模块体现了从单样本推理到批处理任务的扩展思路。相比单图检测,批量检测更关注文件组织、结果汇总和下载体验。
5.7 摄像头实时识别实现
实时识别由 camera_stream 接口实现:
python
@app.get("/api/video/camera/stream")
def camera_stream(conf: float = 0.25, iou: float = 0.45, camera: int = 0):函数内部使用生成器 generate 持续读取摄像头画面。每读取一帧,就调用 predict_image 进行检测,并将绘制后的图像编码为 JPEG。接口返回类型为 StreamingResponse,媒体类型为 multipart/x-mixed-replace; boundary=frame,浏览器可通过 <img> 标签持续显示该 MJPEG 流。
如果摄像头不可用,代码会生成一张黑色占位图并写入 "Camera unavailable",避免接口异常退出。这一处理提升了系统可靠性,也符合现场演示时对异常情况的处理需求。
根据最新需求,系统已经移除上传视频离线检测功能,只保留摄像头实时识别。这使系统视频相关功能更加聚焦于实时场景,与田间监测背景更加一致。
5.8 训练任务管理实现
训练任务由 TrainingManager 类管理。由于训练过程耗时较长,不能在接口中同步执行,因此系统使用 subprocess.Popen 启动独立训练进程。训练命令调用 scripts/train_yolo.py,并传入模型、轮数、图片尺寸、批大小、设备和任务名等参数。
TrainingManager.start 在启动训练前会检查是否已有训练进程正在运行,避免重复启动。训练进程的标准输出被管道捕获,后台线程 _read_logs 持续读取日志并保存到 log_lines 列表中。前端通过 /api/train/logs?since=<cursor> 轮询获取新增日志,实现实时日志展示。
TrainingManager.stop 用于停止训练进程。在 Windows 环境中使用 process.terminate(),在其他系统中使用进程组信号。TrainingManager.status 返回当前是否运行、进程号、开始时间、返回码和日志数量。
5.9 训练脚本实现
训练脚本 scripts/train_yolo.py 首先检查 workspace/yolo_wheat/dataset.yaml 是否存在,如果不存在则提示先运行数据转换脚本。随后通过 YOLO(args.model) 加载模型,并调用 model.train(...) 开始训练。训练参数包括数据集路径、训练轮数、图片尺寸、批大小、设备、工作线程数、输出目录和任务名称。
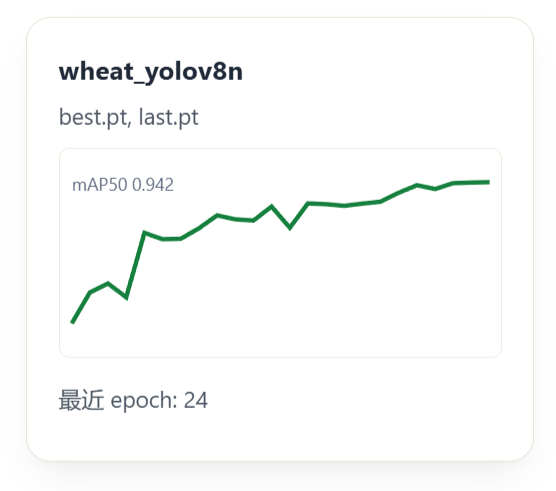
训练完成后,脚本将最佳权重路径写入 workspace/state.json。这样后端模型管理模块下次会优先发现并使用最新训练权重,形成训练与推理之间的自动衔接。
5.10 前端交互实现
前端由 frontend/index.html、frontend/styles.css 和 frontend/app.js 构成。页面采用小麦田间检测主题,整体包含侧边导航、顶部 Hero 区、数据指标卡和四个功能面板。CSS 中使用绿色和麦黄色作为主色,结合麦穗线稿背景,使界面与系统应用场景保持一致。
app.js 中封装了 api 函数用于统一发送请求和处理错误;showToast 用于显示操作提示;setBusy 用于设置按钮加载状态;bindRange 用于同步置信度滑块显示。单图检测、批量检测、实时识别和训练任务分别绑定对应按钮事件。前端没有复杂框架依赖,结构清晰,便于调试和展示。
5.11 开发中遇到的问题及解决方法
开发过程中遇到的主要问题包括:
- CSV 字段解析问题。由于
bbox字段内部包含逗号,不能使用简单字符串分割。最终采用 Pythoncsv.DictReader和ast.literal_eval正确解析。 - PyTorch CUDA 环境问题。系统存在 NVIDIA 显卡,但 base 环境中 PyTorch 为 CPU 版,导致
torch.cuda.is_available()为假。最终通过run_server.py自动查找可用 CUDA Conda 环境并重启服务。 - Ultralytics 配置目录权限问题。Ultralytics 默认尝试写入用户目录,部分环境权限不足。项目通过设置
YOLO_CONFIG_DIR到workspace/ultralytics解决。 - 实时摄像头异常问题。摄像头不存在或被占用时,OpenCV 可能无法打开设备。系统在
camera_stream中返回占位帧,提升鲁棒性。 - 前端中文乱码问题。后续重新整理前端文件为 UTF-8 内容,并减少复杂构建流程,保证页面文本可读和脚本可维护。
第 6 章 系统测试与结果分析
6.1 测试环境
系统测试环境如下:
| 项目 | 内容 |
|---|---|
| 操作系统 | Windows |
| 开发语言 | Python、HTML、CSS、JavaScript |
| 后端框架 | FastAPI |
| 模型框架 | Ultralytics YOLO、PyTorch |
| 图像处理 | OpenCV、Pillow |
| 数据集 | Global Wheat Detection |
| GPU | NVIDIA GeForce RTX 3060 |
实际测试发现,base Python 环境中的 PyTorch 版本为 CPU 版,而 Conda 环境 PDDI 中 PyTorch 为 2.1.2+cu118,能够检测到 RTX 3060。因此系统启动脚本的 CUDA 环境切换具有实际意义。
6.2 数据集转换测试
数据集转换测试主要验证转换前后标注数量是否一致。运行:
powershell
python scripts\prepare_yolo_dataset.py输出统计结果显示:
| 指标 | 数值 |
|---|---|
| 原始训练图片 | 3422 |
| 有标注图片 | 3373 |
| 无标注图片 | 49 |
| 训练集图片 | 2738 |
| 验证集图片 | 684 |
| 原始 CSV 标注框 | 147793 |
| YOLO 标签框 | 147793 |
| 越界修正框 | 0 |
测试结果说明数据转换过程没有丢失标注框,且边界框归一化后没有越界情况。无标注图片也被正确纳入数据集。
6.3 接口功能测试
后端使用 FastAPI TestClient 进行了基础接口测试。测试结果如下:
| 测试项 | 接口 | 预期结果 | 实际结果 |
|---|---|---|---|
| 首页加载 | GET / |
返回 200 | 通过 |
| 数据统计 | GET /api/dataset/summary |
返回标注统计 | 返回 147793 个框 |
| 单图检测 | POST /api/detect/image |
返回检测 JSON | 通过 |
| 实时流接口 | GET /api/video/camera/stream |
返回 MJPEG 流 | 通过 |
| 离线视频接口 | POST /api/detect/video |
已移除,返回 404 | 通过 |
| 前端脚本语法 | node --check frontend/app.js |
无语法错误 | 通过 |
| Python 编译 | python -m py_compile backend/main.py |
无语法错误 | 通过 |
测试结果说明系统主要接口能够正常响应。由于测试环境中摄像头可能不可用,实时流接口在无摄像头时会返回占位帧,这是代码中预期设计。
6.4 单图检测测试
单图检测测试使用数据集测试目录中的图片进行上传。接口返回字段包括 count、detections、image_url 和 average_confidence。在使用预训练权重而非针对麦穗训练后的权重时,检测数量可能为 0,这是符合预期的,因为通用预训练权重并不一定包含麦穗类别。系统功能测试的重点是验证接口流程、文件上传、模型调用、结果保存和前端展示是否正常。
6.5 批量检测测试
批量检测测试验证多文件上传、逐张推理、结果保存和 ZIP 打包功能。接口能够为每次任务生成唯一 run_id,并在 workspace/runs/batch/ 下保存检测图、单图 JSON 和 summary.json,最后生成 ZIP 文件。该测试说明批量任务的数据组织方式合理,便于用户下载和后续分析。
6.6 实时识别测试
实时识别测试主要验证 MJPEG 流接口是否可访问,以及前端是否能够通过 <img> 标签显示流。接口使用 OpenCV 读取摄像头帧,并对每帧调用 YOLO 推理。如果摄像头不可用,接口返回占位图。该设计保证即使硬件条件不足,系统也能给出可理解反馈,不会导致页面崩溃。
6.7 训练功能测试
训练功能测试主要包括数据集是否准备、训练任务是否能够启动、日志是否能够读取、训练结果是否能够列出。后端在启动训练前检查 workspace/yolo_wheat/dataset.yaml 是否存在,避免用户未准备数据集就启动训练。训练日志通过轮询方式返回,前端能够持续追加到日志面板。训练完成后,/api/train/runs 读取训练目录中的权重、曲线图片和 results.csv 指标。
6.8 测试结果分析
综合测试结果表明,系统已经完成预期核心功能。数据转换结果准确,接口设计与前端功能对应,图像检测流程完整,实时识别接口可用,训练管理功能具备基本可操作性。系统不足之处在于检测精度依赖后续训练权重,如果仅使用通用预训练权重,麦穗检测效果有限。因此,在实际应用中应使用转换后的 YOLO 数据集进行充分训练,并根据验证集结果调整训练轮数、输入尺寸和置信度阈值。
6.9 项目结构
text
wheat/
├─ backend/
│ └─ main.py # FastAPI 接口、YOLO 推理、训练任务管理
├─ frontend/
│ ├─ index.html # 前端页面结构
│ ├─ styles.css # 小麦田间主题界面样式
│ └─ app.js # 前端交互逻辑
├─ scripts/
│ ├─ prepare_yolo_dataset.py # Kaggle CSV 到 YOLO 格式转换
│ ├─ train_yolo.py # YOLO 训练脚本
│ └─ run_server.py # 服务启动与 CUDA 环境自动切换
├─ configs/
│ ├─ default_train.yaml # 默认训练参数
│ └─ wheat.yaml # YOLO 数据集配置模板
├─ global-wheat-detection/ # 原始数据集
├─ workspace/ # 运行时生成目录
└─ 本科毕业设计论文_小麦麦穗YOLO智能检测系统.md环境要求
- Python 3.9 或以上
- FastAPI
- Uvicorn
- Ultralytics
- PyTorch
- OpenCV
- Pillow
- NumPy
如果系统存在 CUDA 版 PyTorch 环境,推荐使用:
powershell
python scripts\run_server.pyscripts/run_server.py 会检查当前 Python 是否支持 CUDA。如果当前环境是 CPU 版 PyTorch,但存在可用 CUDA Conda 环境且依赖完整,脚本会自动切换到该环境运行。
数据集准备
powershell
python scripts\prepare_yolo_dataset.py转换后生成:
text
workspace/yolo_wheat/
├─ images/train
├─ images/val
├─ labels/train
├─ labels/val
└─ dataset.yaml已验证转换结果:
- 原始训练图片:3422 张
- 有标注图片:3373 张
- 无框训练图片:49 张
- 原始标注框:147793 个
- YOLO 标签框:147793 个
启动系统
powershell
python scripts\run_server.py打开:
text
http://127.0.0.1:8000第 7 章 总结与展望
7.1 工作总结
本文围绕小麦麦穗检测任务,设计并实现了一套基于 YOLO 的智能检测系统。系统以 Global Wheat Detection 数据集为基础,完成了从原始 CSV 标注到 YOLO 格式数据集的转换,构建了 FastAPI 后端接口和原生前端界面,实现了单图检测、批量检测、摄像头实时识别、模型训练、训练日志查看、训练结果可视化和模型权重切换等功能。
在实现过程中,本文重点解决了标注格式转换、YOLO 模型调用、检测框可视化、批量结果打包、MJPEG 实时流输出和 CUDA 环境选择等问题。系统没有使用数据库,而是采用文件系统保存数据集、权重、结果和状态,符合本项目单机实验和毕业设计展示的实际需求。测试结果表明,系统能够稳定完成主要功能,具有一定实用价值。