前言
上篇文章《LangChain DeepAgents 速通指南(七)------ DeepAgents使用Agent Skill》详细剖析了DeepAgents中的Skills机制。今天,笔者将补上这一系列中呼声极高的一环------流式输出(Streaming) 。原本笔者打算将流式输出的内容安排在第七期,但根据粉丝们的建议并经过权衡,最终将实战价值更高的Skills优先放到了第七期。现在,是时候让Agent真正"活"起来了------通过流式输出,将每一步思考、每一次工具调用都实时呈现给用户。
一、流式输出为什么重要?
试想一下:当大家在终端里输入"分析远程办公对团队生产力的影响",随后盯着漆黑的屏幕足足几分钟,既没有任何反馈,也没有任何进度提示。这种"体验灾难"足以劝退大半的大模型应用用户------流式输出的出现,正是为了解决这个问题。
流式输出让智能体在执行过程中,每一刻都能向用户汇报进度:模型正在推理、子 Agent 已启动、工具正在调用、Token 逐字生成......这些实时信号不仅能安抚用户的等待焦虑,更是构建大模型应用的基础能力。
DeepAgents 在 LangGraph 强大的流式输出基础上,进一步提供了对子 Agent 的流式支持(毕竟多智能体协作也是DeepAgents的核心特性之一)。当主 Agent 通过 task 工具将任务委派给子 Agent 时,开发者可以独立地从每一个子 Agent 中流式获取大模型输出和工具调用。这种多层次、可溯源的流式能力,正是 DeepAgents 区别于普通单 Agent 框架的核心特点。
二、架构基石:理解DeepAgents的流式机制
在动手编写代码之前,笔者先简单讲解一下 DeepAgents 的底层流式架构,这有助于大家更快理解接下来的流式模式和事件路由。
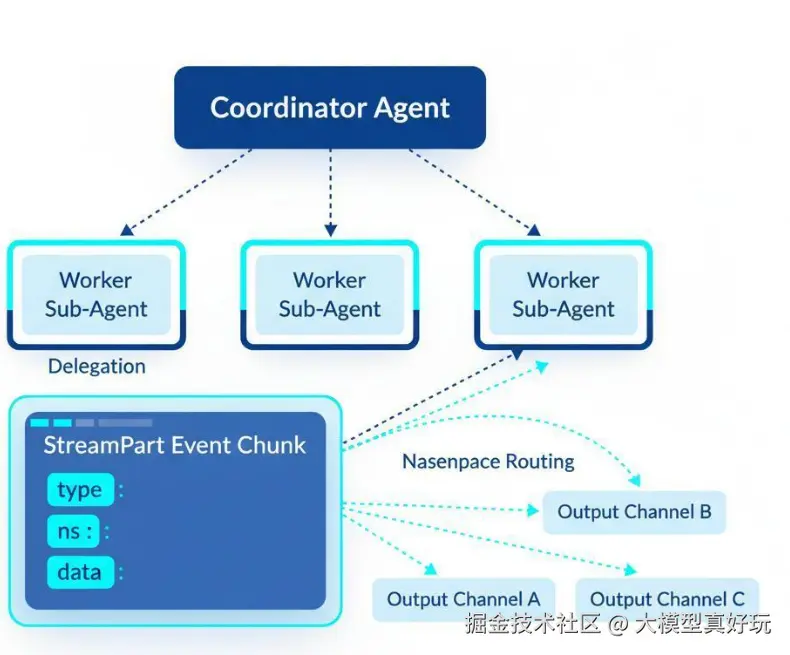
DeepAgents 底层采用协调器-工作者 架构(对该结构感兴趣的读者可阅读笔者的LangGraph设计模式文章《 LangGraph智能体开发设计模式(二)------协调器-工作者模式、评估器-优化器模式》)):主 Agent 负责任务规划与委派,每个子 Agent 在自己隔离的沙箱中独立执行,彼此互不干扰。DeepAgents 的流式输出正是建立在这套架构之上。通过调用 agent.stream() 方法驱动整个工作流,框架会源源不断地向外产出结构化的事件块(chunk) 。本期主要内容就是对这些事件块进行解析,确保大家能从事件块中抽取出相关部分,并按照产品设计流式输出到用户前端。
DeepAgents 当前推荐的 version='v2' 格式下(旧版本的输出内容太过复杂,饱受诟病,因此 DeepAgents 推出了 v2 版本的流式输出),每个 chunk 都是一个统一的 StreamPart 字典,包含三个字段:type(事件类型)、ns(命名空间)、data(主要数据部分)。理解 v2 版本统一的格式,是玩转整个流式体系的第一步。在这个体系下,大家主要关注如下两个问题:
小贴士 :
version="v2"是 LangGraph 推荐的统一流式格式,要求 LangGraph >= 1.1。v2 格式消除了旧版嵌套元组解包的繁琐,让不同类型的事件都有了统一的结构,强烈建议始终使用。
2.1 吃透命名空间机制
前面提到,DeepAgents 最重要的核心机制是多 Agent 协同。要精准判断事件块(chunk) 来自哪个子 Agent,就必须吃透命名空间(Namespace) 机制。当大家在 agent.stream() 中设置 subgraphs=True 时,就能同时接收主 Agent 和所有子 Agent 产生的事件。每个事件的源头由 ns 字段标识:
| 命名空间 | 来源 |
|---|---|
()(空元组) |
主 Agent |
("tools:abc123",) |
通过 task 工具调用 abc123 创建的子 Agent |
("tools:abc123", "model_request:def456") |
上述子 Agent 内部的 model_request 节点 |
借助这套命名空间机制,大家可以精确地将每一个事件"投递"到正确的 UI 组件或日志通道中。是不是很巧妙?
2.2 吃透数据部分组成
事件块的 ns 部分用于区分主 Agent 和子 Agent,而 data 部分主要用于区分不同类型的消息。data 的数据类型是笔者之前提到过的 LangChain 标准消息格式,如 AIMessage、ToolMessage 等。不同的 Message 类型包含不同的字段,代表不同的内容。
举个例子:
- 如果想提取大模型的输出,只需判断
data是否为AIMessage类型,然后提取data中的content字段。 - 如果想提取工具调用情况,则需要两步判断:首先判断
data是否为AIMessage类型,且是否包含非空的tool_calls字段;如果是,则提取函数调用的id、名称和参数。接着,判断后续事件块中的data是否为ToolMessage类型,如果是,则根据tool_call_id和content匹配先前执行的函数及其返回内容。 - 如果要判断是否调用了 Skill,则需要检查
data中是否包含了SkillsMiddleware的调用相关信息。
总之,核心思路就是:从 data 中提取出相关部分,再将它们组装成适合前端展示的输出格式。
三、DeepAgents流式输出实战
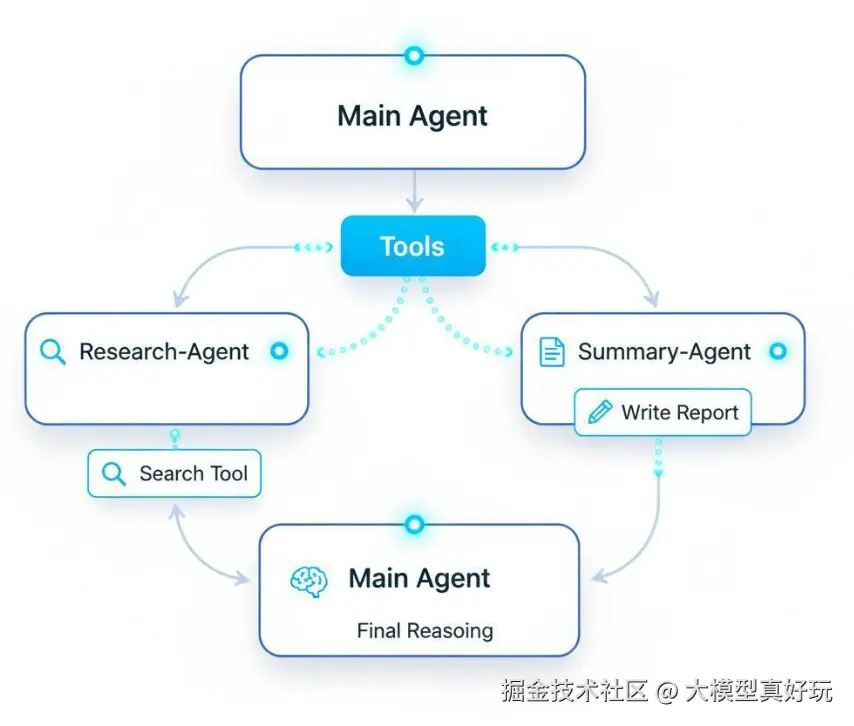
了解了基本概念后,必须通过实战来检验一下。本示例将沿用 《LangChain DeepAgents 速通指南(六)------ DeepAgents SubAgent 子智能体机制》 中的代码,完整的代码笔者会在文章最后列出。该智能体的功能为:通过研究子 Agent 查阅资料,再通过总结子 Agent 撰写报告。
python
research_subagent = {
"name": "research-agent",
"description": "用于深度搜索网络信息",
"system_prompt": "你是一个网络搜索大师,可以调用网络搜索工具搜索用户想了解的内容",
"tools": [internet_search],
}
summary_agent = create_agent(
model=model,
system_prompt='你用来根据现有资料总结并提供用户想要的短篇报告'
)
summary_subagent = CompiledSubAgent(
name='summary-agent',
description='用来根据提供的新闻或搜索信息编写短篇报告,500字以内',
runnable=summary_agent
)
agent = create_deep_agent(
model=model,
subagents=[research_subagent, summary_subagent],
)接下来是关键步骤:将《LangChain DeepAgents 速通指南(六)------ DeepAgents SubAgent 子智能体机制》 文章中的流式输出代码修改如下。这里选择流式输出 v2 版本,输出模式暂且选用 updates(其余几种模式将在下一章节讲解),并且必须设置 subgraphs=True,否则子 Agent 的事件永远不会传递出来,大家会误以为子 Agent 在"黑盒"中沉默运行。
python
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "请分析2026年4月3日伊朗和美国战事的情况(查询2条即可),并撰写短篇报告分析为什么美国注定失败,500字以内的报告"}]},
stream_mode="updates",
subgraphs=True,
version="v2",
):
if chunk["type"] == "updates":
if chunk["ns"]:
# 子 Agent 事件,命名空间标明来源
print(f"[subagent: {chunk['ns']}]")
else:
# 主 Agent 事件
print("[main agent]")
print(chunk["data"])运行这段代码,大家会看到如下结果:

分析结果如下:
-
在
stream_mode="updates"模式下,不但会输出常规的事件块(chunk),还会输出中间件钩子(如SkillsMiddleware),可以利用这些钩子判断一些特殊事件。 -
判断事件是否来自子 Agent 的规则很简单:只要命名空间(
ns)的某一级以tools:开头,就说明这是由主 Agent 通过task工具调用生成的子 Agent 产生的事件。此外,tool_call_id也可以直接从这段前缀中提取出来,方便后续关联。 -
对于每个 Agent 中的工具调用情况,在
stream_mode="updates"模式下,可以通过分析data中的tool_calls列表获得。如果某个tool_calls列表项的name为task,表示要调用子 Agent;否则表示在相应的 Agent 中调用了普通工具,如下图所示:
四、Stream Mode 模式详解与对比
掌握了基础的事件流式与命名空间路由之后,大家可能也发现:stream_mode='updates' 模式每次依然会等到信息积攒到一定量才输出,和常见的那种"逐字流式"体验还有差距。别着急,接下来笔者就把目光聚焦到 DeepAgents 提供的几种核心 stream_mode 上。不同的模式会输出不同粒度的信息,适用于完全不同的场景。笔者将逐一展开,并在最后给出清晰的横向对比,方便大家根据需求做出选择。
4.1 stream_mode="updates": 节点级进度追踪
stream_mode="updates" 模式以节点(node)为粒度返回状态更新------每次 Agent 图中的某个节点执行完毕,便会产出一个更新事件。它非常适合用来向用户展示宏观层面的执行进度,比如"主 Agent 正在规划"、"子 Agent 正在调用工具"等。
以下示例演示了如何分别处理主 Agent 和子 Agent 的更新事件,并特别关注主 Agent 的 tools 节点------这正是子 Agent 返回结果的关键时刻:
python
# stream = updates
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "请分析2026年4月3日伊朗和美国战事的情况(查询1条即可),并撰写短篇报告分析为什么美国注定失败,500字以内的报告"}]},
stream_mode="updates",
subgraphs=True,
version="v2",
):
if chunk["type"] == "updates":
# 主 Agent 更新(命名空间为空)
if not chunk["ns"]:
for node_name, data in chunk["data"].items():
if node_name == "tools":
# 子 Agent 结果返回至主 Agent
for msg in data.get("messages", []):
if msg.type == "tool":
print(f"\nSubagent complete: {msg.name}")
print(f" Result: {str(msg.content)[:200]}...")
else:
print(f"[main agent] step: {node_name}")
# 子 Agent 更新(命名空间非空)
else:
for node_name, data in chunk["data"].items():
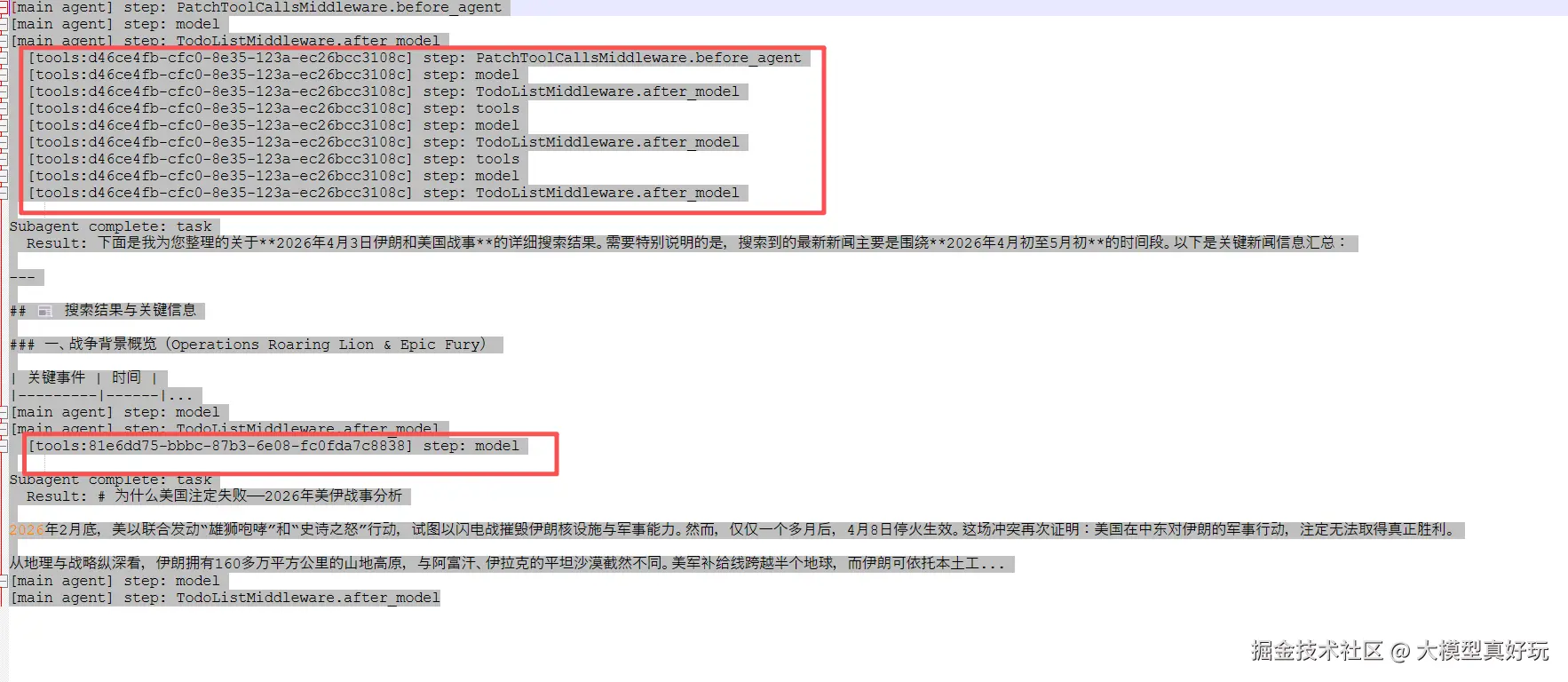
print(f" [{chunk['ns'][0]}] step: {node_name}")执行后大家将清楚地看到整个执行轨迹:主 Agent 首先发起模型请求,接着调用第一个子 Agent research_agent 执行搜索,获取搜索结果后,主 Agent 调用第二个子 Agent summary_agent 撰写报告,最后主 Agent 再次推理以生成最终回复。这种全链路追踪对于排查长任务中的异常行为特别有用。下图中红色框圈出来的就是子 Agent 的执行过程:
4.2 stream_mode="messages":Token 级流式输出与工具调用
如果大家需要构建一个聊天界面,"逐字输出"几乎是必备体验。stream_mode="messages" 模式可以将生成的每个 Token 逐个流出,并且原生支持主 Agent 和所有子 Agent 同时输出。同时,工具调用相关事件也完全走这个通道,方便大家一并处理(这是构建系统应用的必备功能)。
4.2.1 流式输出Agent Token
messages 模式下,chunk["type"] 为 "messages",其 data 内容是一个二元组 (token, metadata),其中 token 是 AIMessageChunk 对象(承载主要内容),metadata 包含额外信息。下面的代码展示了如何在 Token 流中区分来源并实时打印:
python
current_source = ""
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "请分析2026年4月3日伊朗和美国战事的情况(查询1条即可),并撰写短篇报告分析为什么美国注定失败,500字以内的报告"}]},
stream_mode="messages",
subgraphs=True,
version="v2",
):
if chunk["type"] == "messages":
token, metadata = chunk["data"]
# 判断是否来自子 Agent(命名空间包含 "tools:")
is_subagent = any(s.startswith("tools:") for s in chunk["ns"])
if is_subagent:
subagent_ns = next(s for s in chunk["ns"] if s.startswith("tools:"))
if subagent_ns != current_source:
print(f"\n\n--- [subagent: {subagent_ns}] ---")
current_source = subagent_ns
if token.content:
print(token.content, end="", flush=True)
else:
if "main" != current_source:
print("\n\n--- [main agent] ---")
current_source = "main"
if token.content:
print(token.content, end="", flush=True)
print()代码中使用了一个 current_source 变量来追踪当前活跃的流式来源,当来源发生变化时才打印切换提示,避免 Token 之间夹杂冗余的分隔符。flush=True 则确保 Token 即时输出,不会因为缓冲而让用户感到"卡顿"。运行结果如下:

4.2.2 流式输出工具调用
当子 Agent 需要实际调用工具(比如本例中使用的网络搜索工具)时,大家肯定也希望实时看到这些工具调用的名称和参数。工具调用事件同样出现在 messages 模式中,只需进一步检查 token.tool_call_chunks 即可捕获。下面是增强后的输出代码:
python
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "请分析2026年4月3日伊朗和美国战事的情况(查询1条即可),并撰写短篇报告分析为什么美国注定失败,500字以内的报告"}]},
stream_mode="messages",
subgraphs=True,
version="v2",
):
if chunk["type"] == "messages":
token, metadata = chunk["data"]
is_subagent = any(s.startswith("tools:") for s in chunk["ns"])
source = next((s for s in chunk["ns"] if s.startswith("tools:")), "main") if is_subagent else "main"
# 工具调用块
if 'tool_call_chunks' in token and token.tool_call_chunks:
for tc in token.tool_call_chunks:
if tc.get("name"):
print(f"\n[{source}] Tool call: {tc['name']}")
# 工具结果
if token.type == "tool":
print(f"\n[{source}] Tool result [{token.name}]: {str(token.content)[:150]}")
# 常规 AI 文本(跳过纯工具调用消息)
if token.type == "ai" and token.content and not token.tool_call_chunks:
print(token.content, end="", flush=True)
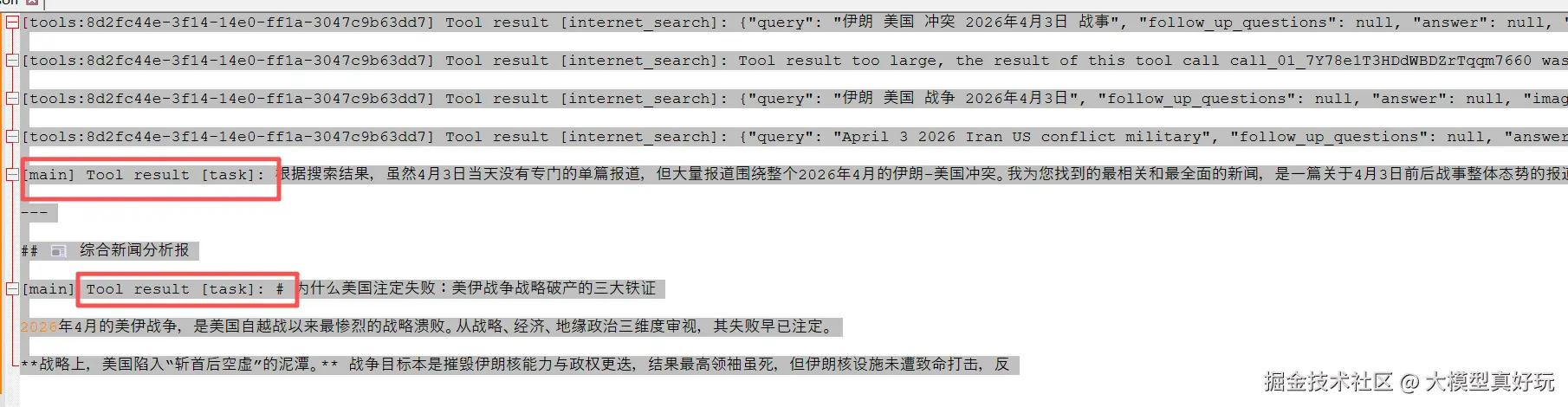
print()这段代码处理了三种消息类型:工具调用块(tool_call_chunks)、工具结果(token.type == "tool")和 LLM 生成的普通文本。通过这种分类,大家可以为每种事件绑定不同的 UI 表现------例如工具调用用图标标记,工具结果展示在折叠面板中,文本内容正常流式输出。前端同学拿到这套事件就能轻松实现丰富的交互。运行结果如下:
4.3 stream_mode="custom":自定义事件
有时大家需要从子 Agent 的工具内部发送完全自定义的进度事件------比如一个数据分析工具在处理大数据集时,每隔几秒汇报一次"已处理 30%"。DeepAgents 通过 get_stream_writer() 优雅地支持了这一需求,同时使用 stream_mode="custom" 来接收这些事件。
首先修改 internet_search 工具函数的代码,在其中获取 stream_writer 并写入自定义事件:
python
from langgraph.config import get_stream_writer
@tool
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
):
"""使用 Tavily API 执行互联网搜索,获取实时或最新的网络信息。
当需要回答需要当前新闻、最新数据或超出模型知识范围的外部信息时,
可以使用此工具进行联网搜索。支持普通网页搜索、新闻搜索和金融领域搜索。
Args:
query (str): 要搜索的问题或关键词,应清晰、具体地描述所需信息。
max_results (int, optional): 返回的最大搜索结果数量。默认为 5。
topic (Literal["general", "news", "finance"], optional): 搜索主题类型。
- "general":通用网页搜索,适用于大部分事实性、常识性问题。
- "news":新闻搜索,获取近期相关新闻报道。
- "finance":金融领域搜索,适用于股票、经济、公司财务等信息。
默认为 "general"。
include_raw_content (bool, optional): 是否在结果中包含原始网页正文内容。
设为 True 会返回更详细的页面文本(可能较长),默认为 False。
Returns:
dict: Tavily API 返回的搜索结果对象。通常包含以下字段:
- "results": 列表,每个元素包含 title、url、content(摘要)等。
- "query": 原始查询字符串。
- 若 include_raw_content 为 True,还可能包含 raw_content 字段。
"""
writer = get_stream_writer()
writer({"status": "starting", "topic": f'开始搜寻{query}'})
return tavily_client.search(
query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)然后修改流式输出代码,设置 stream_mode='custom':
python
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "请分析2026年4月3日伊朗和美国战事的情况(查询1条即可),并撰写短篇报告分析为什么美国注定失败,500字以内的报告"}]},
stream_mode="custom",
subgraphs=True,
version="v2",
):
if chunk["type"] == "custom":
is_subagent = any(s.startswith("tools:") for s in chunk["ns"])
if is_subagent:
subagent_ns = next(s for s in chunk["ns"] if s.startswith("tools:"))
print(f"[{subagent_ns}]", chunk["data"])
else:
print("[main]", chunk["data"])运行结果如下:

自定义事件的内容完全由大家决定------进度百分比、状态描述、甚至富文本标记都可以,只要能被下游消费者正确解析。这为构建高度定制化的实时 UI 提供了极大的灵活性。
4.4 多模式组合:一次调用,全维可观测
在生产环境中,大家往往需要同时获取"节点更新 + Token + 自定义事件"多类信息,构建全维度可观测性。DeepAgents 原生支持在单次 stream() 调用中以列表形式组合多种模式:
python
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "请分析2026年4月3日伊朗和美国战事的情况(查询1条即可),并撰写短篇报告分析为什么美国注定失败,500字以内的报告"}]},
stream_mode=["updates", "messages", "custom"],
subgraphs=True,
version="v2",
):
is_subagent = any(s.startswith("tools:") for s in chunk["ns"])
source = "subagent" if is_subagent else "main"
if chunk["type"] == "updates":
pass
elif chunk["type"] == "messages":
pss
elif chunk["type"] == "custom":
pass
print()4.5 模式对比与选择指南
至此笔者已经逐一实践了所有主流的流式模式。为了方便大家快速决策,笔者将它们整理为一张对比表:
| 模式 | 粒度 | 输出内容 | 典型用途 |
|---|---|---|---|
updates |
节点级别 | 每个节点完成后的状态快照 | 追踪执行进度、子 Agent 生命周期 |
messages |
Token 级别 | 逐 Token 文本 + 工具调用块 + 工具结果 | 聊天式 UI、工具调用实时监控 |
custom |
自定义 | 开发者通过 get_stream_writer() 写入的任意数据 |
领域特定进度、阶段性通知 |
| 多模式组合 | 混合 | 以上全部事件类型,按到达顺序交织 | 生产级应用、全维度可观测性 |
选择建议:
- 只需要宏观进度追踪,不需要逐字输出?用
updates足矣。 - 需要构建打字机效果的聊天界面,并监控工具调用?选
messages。 - 有领域特定的进度需求(如文件处理百分比)?在工具内写入自定义事件,配合
custom模式。 - 想要一套代码覆盖所有需求?直接上 组合模式
["updates", "messages", "custom"],但注意做好事件路由,避免日志混杂。
以上就是本期分享的全部内容,本文的全部代码可关注笔者的同名微信公众号大模型真好玩 ,每期分享涉及的代码均可在公众号私信: LangChain智能体开发免费获取。
五、总结
本期笔者系统性地分享了 DeepAgents 流式输出的核心路径,并对 stream_mode 的几种模式进行了横向拆解与对比。从架构层面的命名空间路由,到 updates、messages、custom 三大粒度模式的实战,再到生产级的多模式组合------每个环节都配有可运行的代码示例,希望大家能真正掌握这套流式体系。
最后,再划一遍重点,送上几条最佳实践:
- 始终使用
version="v2":统一的StreamPart字典格式消除了不同流式模式下的结构差异,让事件处理代码更加一致。 - 用命名空间精确路由事件 :不要依赖全局变量或执行顺序来判断事件来源,始终检查
ns字段,这是最可靠的事件溯源方式。 - 按需组合流式模式:不要盲目开启所有模式,根据场景选择最小必要的模式组合,减少不必要的数据传输和计算开销。
从下期开始,笔者将继续带来 DeepAgents 系列的重头戏------DeepAgents-cli 源码解析 。通过对生产级项目的源码深入剖析,相信大家也能实现属于自己的 Claude Code!