前言
本篇文章主要梳理一下,SpringCloud的一些知识的掌握及使用,这一部分知识所使用到的中间组件很多,要完成一个完整的微服务项目,难点在于这些中间组件具体是实现什么功能的、怎么把这些中间组件加入到项目中,至于这些组件在代码中具体怎么使用,在AI时代,并不是那么重要
SpringCloud的学习,主要是学习两个内容,第一个就是微服务的思想,第二个就是中间件
微服务思想
微服务思想就是把一个完整的单体项目,划分为多个子项目,每个子项目负责一部分功能,其实就是实现模块之间的高聚与解耦,这就是微服务思想。
我们在学习java后端架构时,以我为例子,写项目时有三个阶段
一:所有的功能都写在一个SpringBoot项目中,然后所有功能的代码都放在一个包甚至一个类下
二:项目进行了初步的划分,先创建一个空项目,然后在空项目中创建子项目,一个common,一个pojo,一个server
三:将项目进行微服务划分,先创建一个空项目,然后在空项目中创建子项目,每个子项目都实现一个功能,然后在这个子项目中,再编写有关负责功能的所有代码。除此之外,不同子模块使用不同的数据库,严谨来说,是不同子模块使用不同的数据库管理系统,但是我们在实际项目书写时,还是使用相同的数据库管理系统,使用不同的数据库来实现
第三个阶段就是微服务架构,这个思想看起来很简单,把业务拆分开来就完成了,确实,但是我们来看第二阶段和第三阶段,从第二阶段到第三阶段,其实架构复杂了很多,就会出现很多重复的工作
比如:每个子模块都要写配置文件
除此之外,模块与模块之间的调用也是一个问题
因此,我们下边将要学习微服务项目中,架构升级改进所带来的问题的解决办法,这些解决办法已经被很多中间件封装了,所以我们需要学习中间件的使用
实现
我们来具体看看一个微服务架构
这个架构初始的构建是:
首先先创建一个SpringBoot项目,删除一些不需要的东西
在这个项目中,创建java项目,勾选maven模块
创建完子项目之后,在java包下创建新包,这个包名尽量与父模块的包名前缀相同
这样一个完整的架构就创建出来了,我们后续所有的中间件的学习都基于这个架构来讲
我们上述是创建了一个基础的架构,仅仅做了业务模块的拆分,但是拆分之后,我们还要对其继续进行完善,确保架构的低耦合,也就是我们的中间件的功能
Nacos
我们把一个单体项目拆解成了多个项目,那么运行时, 也要运行多个项目,它们运行在不同的端口,那么如何管理?它们之间怎么通信?
服务注册与拉取
首先我们需要知道,在微服务远程调用的过程中,包括两个角色:
-
服务提供者:提供接口供其它微服务访问
-
服务消费者:调用其它微服务提供的接口
在大型微服务项目中,服务提供者的数量会非常多,为了管理这些服务就引入了**注册中心(Nacos)**的概念。注册中心、服务提供者、服务消费者之间的流程是这样的:
-
服务启动时就会注册自己的服务信息(服务名、IP、端口)到注册中心
-
调用者可以从注册中心订阅想要的服务,获取服务对应的实例列表(1个服务可能多实例部署)
-
调用者自己对实例列表负载均衡,挑选一个实例
-
调用者向该实例发起远程调用
当服务提供者的实例宕机或者启动新实例时,调用者如何得知呢?
-
服务提供者会定期向注册中心发送请求,报告自己的健康状态(心跳请求)
-
当注册中心长时间收不到提供者的心跳时,会认为该实例宕机,将其从服务的实例列表中剔除
-
当服务有新实例启动时,会发送注册服务请求,其信息会被记录在注册中心的服务实例列表
-
当注册中心服务列表变更时,会主动通知微服务,更新本地服务列表
因此,我们要学习Nacos,它就是一个注册中心,有了Nacos,我们就知道有哪些服务启动了,并且实现负载均衡与动态加载
有了Nacos之后,我们只需要把每个组件在运行时,都注册进Nacos的服务列表
注册流程是这样的:
-
引入依赖
-
配置Nacos地址
-
重启
至于具体的下载方法与注册、使用方法,不同版本的中间件是不同的,因此我不再具体的写依赖与配置的内容,大家可直接复制,去AI中,附上自己的Spring、jdk版本,即可得到正确的
服务的消费者想要使用某个组件中的内容,要去nacos订阅服务,这个过程就是服务发现,步骤如下:
-
引入依赖
-
配置Nacos地址
-
发现并调用服务
通过DiscoveryClient发现服务实例列表,然后通过负载均衡算法,选择一个想要使用的服务的实例去调用即可(这个调用是HTTP请求)
上述我们实现了,服务启动时在注册中心注册,成功注册之后,后续想要调用它的服务,就可以在注册中心先拉取服务列表,查看有哪些服务可供调用,然后选择需要调用的服务,通过HTTP请求向服务的Controller中开发好的API发送请求即可拿到结果
但是在Java中发送HTTP请求,虽然不是一件麻烦的事,但是Nacos提供了更简便的做法,就是OpenFeign
OpenFeign
OpenFeign,就是在上述Nacos的基础上,提供的更简便的服务间相互调用的方式
使用方式:
-
引入依赖
<!--openFeign--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency> <!--负载均衡器--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-loadbalancer</artifactId> </dependency> -
启用OpenFeign
在每个需要使用OpenFeign的模块的启动类的加入注解@EnableFeignClients
-
编写OpenFeign客户端
@FeignClient("模块名")
public interface Test1Client {@GetMapping("/test") List<ItemDTO> queryItemByIds(@RequestParam("ids") Collection<Long> ids);}
这样写就代表向指定的模块中发送Get请求
-
使用FeignClient
private final Test1Client test1client;
testclient1.queryItemByIds(ids);
这就是整个使用流程
除此之外,openfeign还有其他配置:
Feign底层发起http请求,依赖于其它的框架。其底层支持的http客户端实现包括:
-
HttpURLConnection:默认实现,不支持连接池
-
Apache HttpClient :支持连接池
-
OKHttp:支持连接池
因此我们通常会使用带有连接池的客户端来代替默认的HttpURLConnection。比如,我们使用OK Http.
使用流程:
-
引入依赖
io.github.openfeign feign-okhttp -
开启链接池(在配置文件中配置即可)
这样使得openfeign更加高效
此时,我们发现,如果项目足够复杂,那么每个模块都需要定义一个client类,而且每个类都需要配置连接池,因此,我们再做拆分
现在我们创建一个新的模块,模块名是统一的,就是api,代表我们后续模块间的通信
在这个模块中,我们引入openfeign的依赖,引入OKHttp的依赖,配置所有类的client
后续有哪个模块需要openfeign的功能时,只需将这个模块的依赖导入即可
注:使用OpenFeign的模块的启动类上一定要加注解,并且在注解中配置,client的位置
@EnableFeignClients(basePackages = "com.mihuxiaobaigao.api.client")这样才能正确使用
有关日志:
OpenFeign只会在FeignClient所在包的日志级别为DEBUG时,才会输出日志。而且其日志级别有4级:
-
NONE:不记录任何日志信息,这是默认值。
-
BASIC:仅记录请求的方法,URL以及响应状态码和执行时间
-
HEADERS:在BASIC的基础上,额外记录了请求和响应的头信息
-
FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据。
Feign默认的日志级别就是NONE,所以默认我们看不到请求日志。
如果想要规定日志,在api模块下新建一个配置类,定义Feign的日志级别:
public class DefaultFeignConfig {
@Bean
public Logger.Level feignLogLevel(){
return Logger.Level.FULL;
}
}同时要将其生效
@EnableFeignClients(basePackages = "com.mihuxiaobaigao.api.client",defaultConfiguration = DefaultFeignConfig.class)到这里,我们的OpenFeign的基础学习就完成了
配置管理
我们可以把微服务共享的配置抽取到Nacos中统一管理,这样就不需要每个微服务都重复配置了。分为两步:
- 在Nacos中添加共享配置
需要打开Nacos网站,然后在配置列表中添加统一格式的配置内容即可
- 微服务拉取配置
我们要在微服务拉取共享配置。将拉取到的共享配置与本地的application.yaml配置合并,完成项目上下文的初始化。
不过,需要注意的是,读取Nacos配置是SpringCloud上下文(ApplicationContext)初始化时处理的,发生在项目的引导阶段。然后才会初始化SpringBoot上下文,去读取application.yaml。
SpringCloud在初始化上下文的时候会先读取一个名为bootstrap.yaml(或者bootstrap.properties)的文件,如果我们将nacos地址配置到bootstrap.yaml中,那么在项目引导阶段就可以读取nacos中的配置了
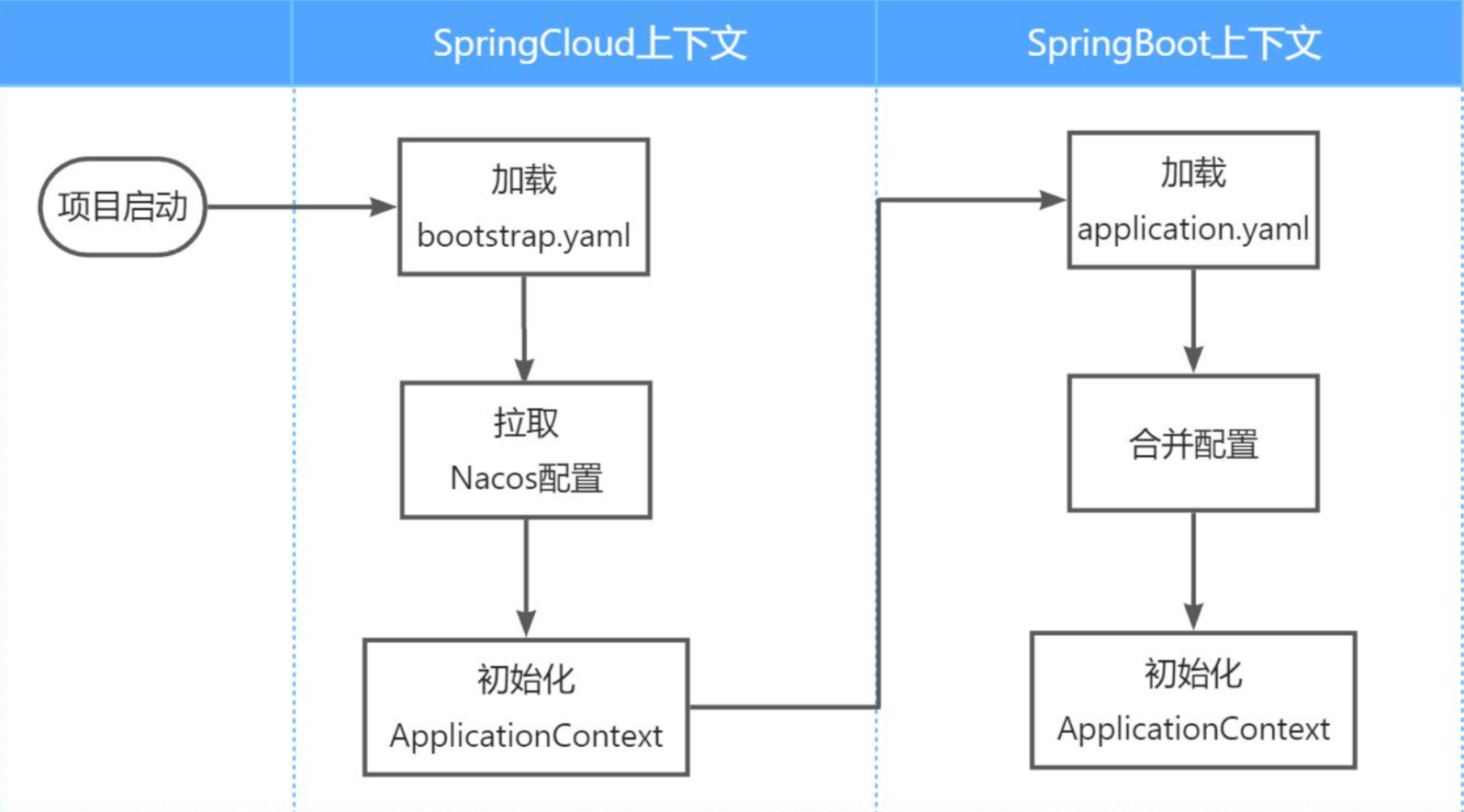
因此,微服务整合Nacos配置管理的步骤如下:
-
引入依赖
<!--nacos配置管理--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency> <!--读取bootstrap文件--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-bootstrap</artifactId> </dependency> -
新建bootstrap.yaml
把有关的nacos的信息填写进bootstrap中,这样,就实现了配置的热更新
但是,现在又有了新的问题,那就是,这么多服务,我们的登录校验怎么做,前端无法调用nacos,它怎么知道调用我们后端的哪个端口呢?
下边我们开始讲述有关网关的配置
SpringCloudGateway
在以前的项目中,我们只有一个后端项目,启动时只有一个端口,前端也就只需要请求一个地方,但是现在,我们有多个端口,前端也不知道自己需要请求哪个,因此,我们需要定义一个新的模块gateway,这个模块的作用就是:拦截前端的请求,根据nacos判断前端请求的是哪个模块,然后把请求转发到那个模块去
配置流程:
-
创建模块(gateway)
-
引入依赖
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> </dependency> <!--nacos discovery--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> <!--负载均衡--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-loadbalancer</artifactId> </dependency> -
创建启动类
-
书写配置文件
spring:
application:
name: gateway
cloud:
nacos:
server-addr: 111.111.111.111:8848
gateway:
routes:
- id: test1 # 路由规则id,自定义,唯一
uri: lb://test1 # 路由的目标服务,lb代表负载均衡,会从注册中心拉取服务列表
predicates: # 路由断言,判断当前请求是否符合当前规则,符合则路由到目标服务
- Path=/test1/,/test/ # 这里是以请求路径作为判断规则
这个配置文件很重要,它规定了,前端的请求转发到哪个模块去
这个predicates有很多的配置,SpringCloudGateway中支持的断言类型有很多,我这里不一一列举了
配置成功之后,我们就实现了前端请求的转发,但是现在问题是,单体架构时我们只需要完成一次用户登录、身份校验,就可以在所有业务中获取到用户信息。而微服务拆分后,每个微服务都独立部署,不再共享数据。也就意味着每个微服务都需要做登录校验,这显然不可取。
我们的登录是基于JWT来实现的,校验JWT的算法复杂,而且需要用到秘钥。如果每个微服务都去做登录校验,这就存在着两大问题:
-
每个微服务都需要知道JWT的秘钥,不安全
-
每个微服务重复编写登录校验代码、权限校验代码,麻烦
既然网关是所有微服务的入口,一切请求都需要先经过网关。我们完全可以把登录校验的工作放到网关去做,这样之前说的问题就解决了:
-
只需要在网关和用户服务保存秘钥
-
只需要在网关开发登录校验功能
登录校验必须在请求转发到微服务之前做,否则就失去了意义。而网关的请求转发是GateWay内部代码实现的,要想在请求转发之前做登录校验,就必须了解GateWay内部工作的基本原理。
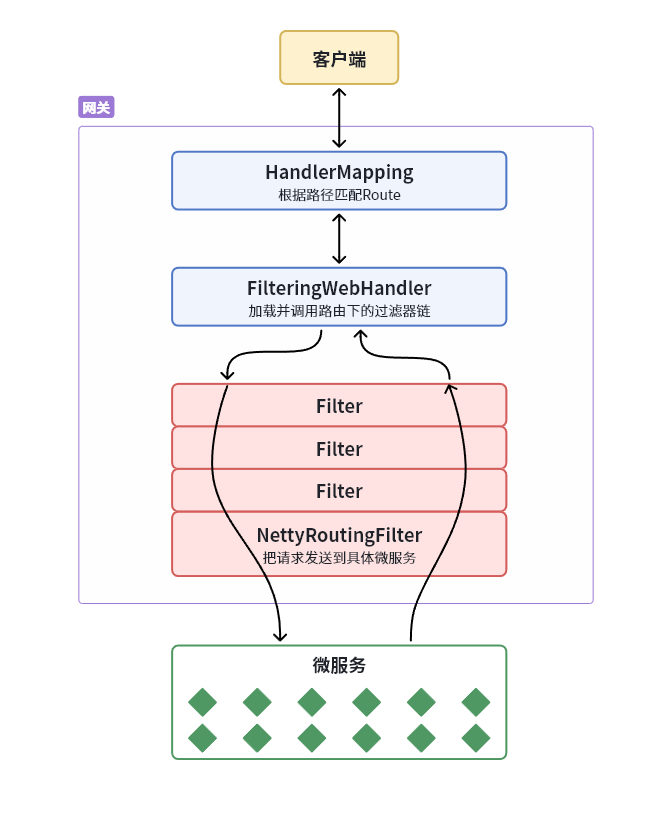
如图所示:
-
客户端请求进入网关后由
HandlerMapping对请求做判断,找到与当前请求匹配的路由规则(Route),然后将请求交给WebHandler去处理。 -
WebHandler则会加载当前路由下需要执行的过滤器链(Filter chain),然后按照顺序逐一执行过滤器(后面称为**Filter**)。 -
图中
Filter被虚线分为左右两部分,是因为Filter内部的逻辑分为pre和post两部分,分别会在请求路由到微服务之前 和之后被执行。 -
只有所有
Filter的pre逻辑都依次顺序执行通过后,请求才会被路由到微服务。 -
微服务返回结果后,再倒序执行
Filter的post逻辑。 -
最终把响应结果返回。
因此我们只需要根据官方语法,创建一个拦截器并且启用,就完成了登录拦截
具体的拦截器的实现不再过多描述
由于网关发送请求到微服务依然采用的是Http请求,因此我们可以将用户信息以请求头的方式传递到下游微服务。然后微服务可以从请求头中获取登录用户信息。考虑到微服务内部可能很多地方都需要用到登录用户信息,因此我们可以利用SpringMVC的拦截器来实现登录用户信息获取,并存入ThreadLocal,方便后续使用。
然后我们在业务模块中,只需要定义一个拦截器,当请求到达时,根据网关存入请求头的名称,取出解析后的用户的信息,存入ThreadLocal,并且在请求结束后,将这个信息删除
这样我们就实现了前端到后端微服务的网关路由与登录
但是模块与模块之间的通信呢?
由于微服务获取用户信息是通过拦截器在请求头中读取,因此要想实现微服务之间的用户信息传递,就必须在微服务 发起调用 时把用户信息存入请求头。
微服务之间调用是基于OpenFeign来实现的,并不是我们自己发送的请求。我们如何才能让每一个由OpenFeign发起的请求自动携带登录用户信息呢?
这里要借助Feign中提供的一个拦截器接口:feign.RequestInterceptor
我们就在api模块中定义一个配置类:
@Bean
public RequestInterceptor userInfoRequestInterceptor(){
return new RequestInterceptor() {
@Override
public void apply(RequestTemplate template) {
// 获取登录用户
Long userId = UserContext.getUser();
if(userId == null) {
// 如果为空则直接跳过
return;
}
// 如果不为空则放入请求头中,传递给下游微服务
template.header("user-info", userId.toString());
}
};
}这样,在模块与模块之间发送请求时,也会带有token中解析的用户的信息
我们通过SpringCloudGateway实现了完整的请求拦截、与token解析、用户信息传递
网关的配置其实也能通过nacos进行热更新的,实现动态路由,这里不再叙述
Sentinel
经过我们上述的配置,每个模块之间都是基本都是有关联的,而且是有层级关系的,一定是从网关先进入,再进入其他模块,然后可能再调用其他模块,这样一层一层的调用
但是如果某一层的服务崩溃,就会引起连锁反应,导致上一层的服务崩溃,这样一层接一层的崩溃,就是雪崩问题,因此我们要做一些保护措施
微服务保护的方案有很多,比如:
- 请求限流
服务故障最重要原因,就是并发太高!解决了这个问题,就能避免大部分故障。当然,接口的并发不是一直很高,而是突发的。因此请求限流,就是限制或控制接口访问的并发流量,避免服务因流量激增而出现故障。
- 线程隔离
当一个业务接口响应时间长,而且并发高时,就可能耗尽服务器的线程资源,导致服务内的其它接口受到影响。所以我们必须把这种影响降低,或者缩减影响的范围。线程隔离正是解决这个问题的好办法。为了避免某个接口故障或压力过大导致整个服务不可用,我们可以限定每个接口可以使用的资源范围,也就是将其"隔离"起来。
- 服务熔断
线程隔离虽然避免了雪崩问题,但故障服务依然会拖慢服务调用方的接口响应速度。
所以,我们要做两件事情:
-
编写服务降级逻辑:就是服务调用失败后的处理逻辑,根据业务场景,可以抛出异常,也可以返回友好提示或默认数据。
-
异常统计和熔断:统计服务提供方的异常比例,当比例过高表明该接口会影响到其它服务,应该拒绝调用该接口,而是直接走降级逻辑。
下边,我们通过Sentinel来实现上述功能
Sentinel 的使用可以分为两个部分:
-
核心库(Jar包):不依赖任何框架/库,能够运行于 Java 8 及以上的版本的运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。在项目中引入依赖即可实现服务限流、隔离、熔断等功能。
-
控制台(Dashboard):Dashboard 主要负责管理推送规则、监控、管理机器信息等。
在代码中配置使用:
-
引入依赖
com.alibaba.cloud spring-cloud-starter-alibaba-sentinel -
配置控制台
spring:
cloud:
sentinel:
transport:
dashboard: localhost:8090
http-method-specify: true # 开启请求方式前缀
配置完成之后,就可以在sentinel控制台中看到配置的请求
同时就可以在控制台配置:
在请求路径后的流控按钮中,配置QPS就是限流配置,配置并发线程数就是线程隔离
但是配置完成之后还有几个几个问题:
第一,超出的QPS上限的请求就只能抛出异常,从而请求失败。但从业务角度来说,请求失败,也应该展示给用户错误信息,用户体验更好。也就是给请求失败设置一个降级处理逻辑。
第二,由于某些请求的延迟较高(模拟的500ms),从而导致请求的响应时间也变的很长。这样不仅拖慢了请求,消耗了更多资源,而且用户体验也很差。对于服务这种不太健康的接口,我们应该直接停止调用,直接走降级逻辑,避免影响到当前服务。也就是将商品查询接口熔断。
触发限流或熔断后的请求不一定要直接报错,也可以返回一些默认数据或者友好提示,用户体验会更好。
给FeignClient编写失败后的降级逻辑有两种方式:
-
方式一:FallbackClass,无法对远程调用的异常做处理
-
方式二:FallbackFactory,可以对远程调用的异常做处理,我们一般选择这种方式。
实现流程:
-
在api模块中给给某个模块定义降级处理类,实现
FallbackFactory@Slf4j
public class Test1ClientFallback implements FallbackFactory{
@Override
public Test1Client create(Throwable cause) {
return new Test1Client() {
@Override
public ListqueryItemByIds(Collection ids) {
log.error("远程调用Test1Client#queryItemByIds方法出现异常,参数:{}", ids, cause);
// 查询失败,返回空集合
return CollUtils.emptyList();
}@Override public void deductStock(List<OrderDetailDTO> items) { // 库存扣减业务需要触发事务回滚,查询失败,抛出异常 throw new BizIllegalException(cause); } }; }}
-
在config中,将其注册为一个Bean
-
在Test1Client的类中,在FeignClient注解中,配置fallbackFactory
上边我们配置了错误处理,但是对于商品服务这种不太健康的接口,我们应该停止调用,直接走降级逻辑,避免影响到当前服务。也就是将商品查询接口熔断 。当商品服务接口恢复正常后,再允许调用。这其实就是断路器的工作模式了。
Sentinel中的断路器不仅可以统计某个接口的慢请求比例 ,还可以统计异常请求比例 。当这些比例超出阈值时,就会熔断该接口,即拦截访问该接口的一切请求,降级处理;当该接口恢复正常时,再放行对于该接口的请求。
状态机包括三个状态:
-
closed:关闭状态,断路器放行所有请求,并开始统计异常比例、慢请求比例。超过阈值则切换到open状态
-
open :打开状态,服务调用被熔断,访问被熔断服务的请求会被拒绝,快速失败,直接走降级逻辑。Open状态持续一段时间后会进入half-open状态
-
half-open:半开状态,放行一次请求,根据执行结果来判断接下来的操作。
-
请求成功:则切换到closed状态
-
请求失败:则切换到open状态
-
配置方法:在控制台中,请求后的按钮中,点击熔断,然后配置熔断规则即可
这样我们就实现了分布式中服务安全的配置
Seata
Seata主要处理分布式事务,我们思考一下,我们以前的事务管理都是在一个数据库中操作的,但是在微服务架构下,每个模块都有自己的数据库,那么我们的以前的事务管理@Transtional就不管用了,就需要Seata来帮我们做分布式事务
整个业务中,各个本地事务是有关联的。因此每个微服务的本地事务,也可以称为分支事务 。多个有关联的分支事务一起就组成了全局事务。我们必须保证整个全局事务同时成功或失败。
其实分布式事务产生的一个重要原因,就是参与事务的多个分支事务互相无感知,不知道彼此的执行状态。因此解决分布式事务的思想非常简单:
就是找一个统一的事务协调者,与多个分支事务通信,检测每个分支事务的执行状态,保证全局事务下的每一个分支事务同时成功或失败即可。大多数的分布式事务框架都是基于这个理论来实现的。
Seata也不例外,在Seata的事务管理中有三个重要的角色:
-
TC ( Transaction Coordinator ) - **事务协调者:**维护全局和分支事务的状态,协调全局事务提交或回滚。
-
TM (Transaction Manager) - **事务管理器:**定义全局事务的范围、开始全局事务、提交或回滚全局事务。
-
RM (Resource Manager) - **资源管理器:**管理分支事务,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
Seata的工作架构如图所示:
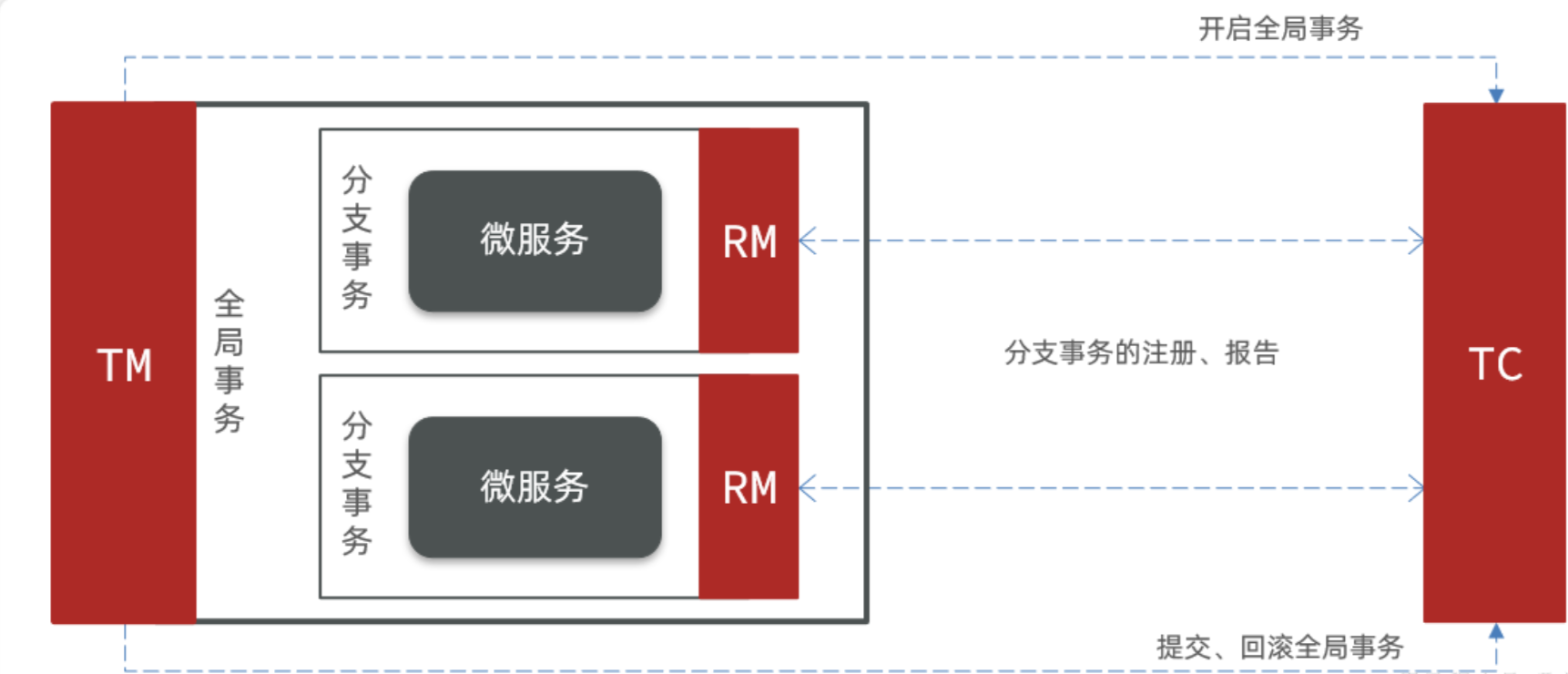
其中,TM 和RM 可以理解为Seata的客户端部分,引入到参与事务的微服务依赖中即可。将来TM 和RM 就会协助微服务,实现本地分支事务与TC之间交互,实现事务的提交或回滚。
而TC服务则是事务协调中心,是一个独立的微服务,需要单独部署。
使用流程:
-
引入依赖(每个参与事务管理的都要引)
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency> <!--读取bootstrap文件--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-bootstrap</artifactId> </dependency> <!--seata--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-seata</artifactId> </dependency> -
改造配置(我们前边在nacos中配置了共享配置,因此我们这里在nacos中添加配置即可)
-
把需要使用@Transtional注解的地方,改为@GlobalTranstional即可
Seata支持四种不同的分布式事务解决方案:
-
XA
-
TCC
-
AT
-
SAGA
大家有兴趣的自己了解一下
RabbitMQ
我们上边基于OpenFeign的调用都属于是同步调用,相当于我们模块间的通信都是同步进行的,按着顺序,先执行这个,再执行下一个,如果上一个没有执行完,那么有可能下一个就不会执行
同步调用的问题就是:
- 拓展性差
- 性能下降
由于我们采用了同步调用,调用者需要等待服务提供者执行完返回结果后,才能继续向下执行,也就是说每次远程调用,调用者都是阻塞等待状态。最终整个业务的响应时长就是每次远程调用的执行时长之和
- 级联失效
由于我们是基于OpenFeign调用交易服务、通知服务。当交易服务、通知服务出现故障时,整个事务都会回滚,交易失败。
而要解决这些问题,我们就必须用异步调用 的方式来代替同步调用。
异步调用方式其实就是基于消息通知的方式,一般包含三个角色:
-
消息发送者:投递消息的人,就是原来的调用方
-
消息Broker:管理、暂存、转发消息,你可以把它理解成微信服务器
-
消息接收者:接收和处理消息的人,就是原来的服务提供方
在异步调用中,发送者不再直接同步调用接收者的业务接口,而是发送一条消息投递给消息Broker。然后接收者根据自己的需求从消息Broker那里订阅消息。每当发送方发送消息后,接受者都能获取消息并处理。
这样,发送消息的人和接收消息的人就完全解耦了。
异步调用的优势包括:
-
耦合度更低
-
性能更好
-
业务拓展性强
-
故障隔离,避免级联失败
当然,异步通信也并非完美无缺,它存在下列缺点:
-
完全依赖于Broker的可靠性、安全性和性能
-
架构复杂,后期维护和调试麻烦
我们这里要讲述的,也就是用的最多的就是RabbitMQ
RabbitMQ其中包含几个概念:
-
publisher:生产者,也就是发送消息的一方 -
consumer:消费者,也就是消费消息的一方 -
queue:队列,存储消息。生产者投递的消息会暂存在消息队列中,等待消费者处理 -
exchange:交换机,负责消息路由。生产者发送的消息由交换机决定投递到哪个队列。 -
virtual host:虚拟主机,起到数据隔离的作用。每个虚拟主机相互独立,有各自的exchange、queue
我们在使用RabbitMQ时,其实所有的功能都可以在网站上,图形化界面实现
实现的流程:
- 创建一个exchange
- 创建一个queue
- 将exchange与queue binding起来
这样就能够通过exchange向queue发送信息了
注意:Exchange( 交换机 ) 只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
在Java代码中,是通过SpringAMQP实现的
发送信息实现流程:
-
引入依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> </dependency> -
书写配置
-
编写测试类
@SpringBootTest
public class SpringAmqpTest {@Autowired private RabbitTemplate rabbitTemplate; @Test public void testSimpleQueue() { // 队列名称 String queueName = "simple.queue"; // 消息 String message = "hello, spring amqp!"; // 发送消息 rabbitTemplate.convertAndSend(queueName, message); }}
接收信息实现流程:
-
书写配置
-
编写测试
package com.itheima.consumer.listener;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;@Component
public class SpringRabbitListener {
// 利用RabbitListener来声明要监听的队列信息
// 将来一旦监听的队列中有了消息,就会推送给当前服务,调用当前方法,处理消息。
// 可以看到方法体中接收的就是消息体的内容
@RabbitListener(queues = "simple.queue")
public void listenSimpleQueueMessage(String msg) throws InterruptedException {
System.out.println("spring 消费者接收到消息:【" + msg + "】");
}
}
这就是最简单的使用
我们还可以定义多个queue接受信息,这叫做WorkQueues
但是需要注意:如果exchange发送了50条消息,此时有两个queue,那么每个queue只能拿到25条,与速度无关
这两个queue接收信息是这样的,第一个接收第一条,第二个接收第二条,然后第一个再接收第三条,这样的,但是如果两个queue的速度差距特别大,也需要先等待速度慢的接收之后,速度快的再接收。
不过我们可以在配置文件中书写相关配置,使得能者多劳,不用再等待
下边我们讲exchange
交换机的类型有四种:
-
Fanout:广播,将消息交给所有绑定到交换机的队列。我们最早在控制台使用的正是Fanout交换机
- 1) 可以有多个队列
- 2) 每个队列都要绑定到Exchange(交换机)
- 3) 生产者发送的消息,只能发送到交换机
- 4) 交换机把消息发送给绑定过的所有队列
- 5) 订阅队列的消费者都能拿到消息
-
Direct:订阅,基于RoutingKey(路由key)发送给订阅了消息的队列
在Direct模型下:
- 队列与交换机的绑定,不能是任意绑定了,而是要指定一个RoutingKey(路由key)
- 消息的发送方在 向 Exchange发送消息时,也必须指定消息的 RoutingKey。
- Exchange不再把消息交给每一个绑定的队列,而是根据消息的Routing Key进行判断,只有队列的Routingkey与消息的 Routing key完全一致,才会接收到消息
-
Topic:通配符订阅,与Direct类似,只不过RoutingKey可以使用通配符
Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。
只不过Topic类型Exchange可以让队列在绑定BindingKey 的时候使用通配符!BindingKey 一般都是有一个或多个单词组成,多个单词之间以.分割,例如: item.insert
通配符规则:
- #:匹配一个或多个词
- *:匹配不多不少恰好1个词
举例:
- item.#:能够匹配item.spu.insert 或者 item.spu
- item.*:只能匹配item.spu
-
Headers:头匹配,基于MQ的消息头匹配,用的较少,不再过多讲述。
在java代码中,这些exchange的实现,也都有专门的类,并不困难
注意:如果使用exchange发送了一个复杂的类型,比如Map等,那么得到的结果很难理解,因此可以使用json序列化转换器得到最后的结果
这就是RabbitMQ的基础使用
下边我们讲解一些高级的,看看如何确保生产者一定能把消息发送到MQ
首先第一种情况,就是生产者发送消息时,出现了网络故障,导致与MQ的连接中断。
为了解决这个问题,SpringAMQP提供的消息发送时的重试机制。即:当RabbitTemplate与MQ连接超时后,多次重试。
修改publisher模块的application.yaml文件即可
spring:
rabbitmq:
connection-timeout: 1s # 设置MQ的连接超时时间
template:
retry:
enabled: true # 开启超时重试机制
initial-interval: 1000ms # 失败后的初始等待时间
multiplier: 1 # 失败后下次的等待时长倍数,下次等待时长 = initial-interval * multiplier
max-attempts: 3 # 最大重试次数一般情况下,只要生产者与MQ之间的网路连接顺畅,基本不会出现发送消息丢失的情况,因此大多数情况下我们无需考虑这种问题。
不过,在少数情况下,也会出现消息发送到MQ之后丢失的现象,比如:
-
MQ内部处理消息的进程发生了异常
-
生产者发送消息到达MQ后未找到
Exchange -
生产者发送消息到达MQ的
Exchange后,未找到合适的Queue,因此无法路由
针对上述情况,RabbitMQ提供了生产者消息确认机制,包括Publisher Confirm和Publisher Return两种。在开启确认机制的情况下,当生产者发送消息给MQ后,MQ会根据消息处理的情况返回不同的回执。
总结如下:
-
当消息投递到MQ,但是路由失败时,通过Publisher Return返回异常信息,同时返回ack的确认信息,代表投递成功
-
临时消息投递到了MQ,并且入队成功,返回ACK,告知投递成功
-
持久消息投递到了MQ,并且入队完成持久化,返回ACK ,告知投递成功
-
其它情况都会返回NACK,告知投递失败
其中ack和nack属于Publisher Confirm 机制,ack是投递成功;nack是投递失败。而return则属于Publisher Return机制。
默认两种机制都是关闭状态,需要通过配置文件来开启。
实现生产者确认机制:
-
配置文件书写
spring:
rabbitmq:
publisher-confirm-type: correlated # 开启publisher confirm机制,并设置confirm类型
publisher-returns: true # 开启publisher return机制
这里publisher-confirm-type有三种模式可选:
-
none:关闭confirm机制 -
simple:同步阻塞等待MQ的回执 -
correlated:MQ异步回调返回回执
一般我们推荐使用correlated,回调机制。
- 定义ReturnCallback
每个RabbitTemplate只能配置一个ReturnCallback,因此我们可以在配置类中统一设置。我们在publisher模块定义一个配置类:
package com.itheima.publisher.config;
import lombok.AllArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.ReturnedMessage;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.context.annotation.Configuration;
import javax.annotation.PostConstruct;
@Slf4j
@AllArgsConstructor
@Configuration
public class MqConfig {
private final RabbitTemplate rabbitTemplate;
@PostConstruct
public void init(){
rabbitTemplate.setReturnsCallback(new RabbitTemplate.ReturnsCallback() {
@Override
public void returnedMessage(ReturnedMessage returned) {
log.error("触发return callback,");
log.debug("exchange: {}", returned.getExchange());
log.debug("routingKey: {}", returned.getRoutingKey());
log.debug("message: {}", returned.getMessage());
log.debug("replyCode: {}", returned.getReplyCode());
log.debug("replyText: {}", returned.getReplyText());
}
});
}
}- 定义ConfirmCallback
由于每个消息发送时的处理逻辑不一定相同,因此ConfirmCallback需要在每次发消息时定义。具体来说,是在调用RabbitTemplate中的convertAndSend方法时,多传递一个参数
@Test
void testPublisherConfirm() {
// 1.创建CorrelationData
CorrelationData cd = new CorrelationData();
// 2.给Future添加ConfirmCallback
cd.getFuture().addCallback(new ListenableFutureCallback<CorrelationData.Confirm>() {
@Override
public void onFailure(Throwable ex) {
// 2.1.Future发生异常时的处理逻辑,基本不会触发
log.error("send message fail", ex);
}
@Override
public void onSuccess(CorrelationData.Confirm result) {
// 2.2.Future接收到回执的处理逻辑,参数中的result就是回执内容
if(result.isAck()){ // result.isAck(),boolean类型,true代表ack回执,false 代表 nack回执
log.debug("发送消息成功,收到 ack!");
}else{ // result.getReason(),String类型,返回nack时的异常描述
log.error("发送消息失败,收到 nack, reason : {}", result.getReason());
}
}
});
// 3.发送消息
rabbitTemplate.convertAndSend("hmall.direct", "q", "hello", cd);
}注意:
开启生产者确认比较消耗MQ性能,一般不建议开启。而且大家思考一下触发确认的几种情况:
-
路由失败:一般是因为RoutingKey错误导致,往往是编程导致
-
交换机名称错误:同样是编程错误导致
-
MQ内部故障:这种需要处理,但概率往往较低。因此只有对消息可靠性要求非常高的业务才需要开启,而且仅仅需要开启ConfirmCallback处理nack就可以了。
消息到达MQ以后,如果MQ不能及时保存,也会导致消息丢失,所以MQ的可靠性也非常重要。
为了提升性能,默认情况下MQ的数据都是在内存存储的临时数据,重启后就会消失。为了保证数据的可靠性,必须配置数据持久化,包括:
-
交换机持久化
-
队列持久化
-
消息持久化
配置交换机与队列持久化时,只需要在创建时,使用Durable
配置消息持久化时,只需要在创建时,使用Persistent
说明:在开启持久化机制以后,如果同时还开启了生产者确认,那么MQ会在消息持久化以后才发送ACK回执,进一步确保消息的可靠性。
不过出于性能考虑,为了减少IO次数,发送到MQ的消息并不是逐条持久化到数据库的,而是每隔一段时间批量持久化。一般间隔在100毫秒左右,这就会导致ACK有一定的延迟,因此建议生产者确认全部采用异步方式。
在默认情况下,RabbitMQ会将接收到的信息保存在内存中以降低消息收发的延迟。但在某些特殊情况下,这会导致消息积压,比如:
-
消费者宕机或出现网络故障
-
消息发送量激增,超过了消费者处理速度
-
消费者处理业务发生阻塞
一旦出现消息堆积问题,RabbitMQ的内存占用就会越来越高,直到触发内存预警上限。此时RabbitMQ会将内存消息刷到磁盘上,这个行为成为PageOut. PageOut会耗费一段时间,并且会阻塞队列进程。因此在这个过程中RabbitMQ不会再处理新的消息,生产者的所有请求都会被阻塞。
为了解决这个问题,从RabbitMQ的3.6.0版本开始,就增加了Lazy Queues的模式,也就是惰性队列。惰性队列的特征如下:
-
接收到消息后直接存入磁盘而非内存
-
消费者要消费消息时才会从磁盘中读取并加载到内存(也就是懒加载)
-
支持数百万条的消息存储
而在3.12版本之后,LazyQueue已经成为所有队列的默认格式。因此官方推荐升级MQ为3.12版本或者所有队列都设置为LazyQueue模式。
在利用SpringAMQP声明队列的时候,添加x-queue-mod=lazy参数可设置队列为Lazy模式
也可以在控制台在添加队列的时候,添加x-queue-mod=lazy参数
对于已经存在的队列,也可以配置为lazy模式,但是要通过设置policy实现。
当RabbitMQ向消费者投递消息以后,需要知道消费者的处理状态如何。因为消息投递给消费者并不代表就一定被正确消费了,可能出现的故障有很多,比如:
-
消息投递的过程中出现了网络故障
-
消费者接收到消息后突然宕机
-
消费者接收到消息后,因处理不当导致异常
-
...
一旦发生上述情况,消息也会丢失。因此,RabbitMQ必须知道消费者的处理状态,一旦消息处理失败才能重新投递消息。
但问题来了:RabbitMQ如何得知消费者的处理状态呢?
消费者确认机制
为了确认消费者是否成功处理消息,RabbitMQ提供了消费者确认机制(Consumer Acknowledgement)。即:当消费者处理消息结束后,应该向RabbitMQ发送一个回执,告知RabbitMQ自己消息处理状态。回执有三种可选值:
-
ack:成功处理消息,RabbitMQ从队列中删除该消息
-
nack:消息处理失败,RabbitMQ需要再次投递消息
-
reject:消息处理失败并拒绝该消息,RabbitMQ从队列中删除该消息
一般reject方式用的较少,除非是消息格式有问题,那就是开发问题了。因此大多数情况下我们需要将消息处理的代码通过try catch机制捕获,消息处理成功时返回ack,处理失败时返回nack.
由于消息回执的处理代码比较统一,因此SpringAMQP帮我们实现了消息确认。并允许我们通过配置文件设置ACK处理方式,有三种模式:
-
none:不处理。即消息投递给消费者后立刻ack,消息会立刻从MQ删除。非常不安全,不建议使用 -
manual:手动模式。需要自己在业务代码中调用api,发送ack或reject,存在业务入侵,但更灵活 -
auto:自动模式。SpringAMQP利用AOP对我们的消息处理逻辑做了环绕增强,当业务正常执行时则自动返回ack. 当业务出现异常时,根据异常判断返回不同结果:-
如果是业务异常 ,会自动返回
nack; -
如果是消息处理或校验异常 ,自动返回
reject;
-
后续还有很多方式,来确保各个环节的稳定,到这里篇幅已经很长了,我就不再过多叙述
EleasticSearch
这个中间件主要解决搜素问题,普通的数据库的查询都是走的数据库的模糊查询,性能差,并且随着数据量的增大,查询速度会越来越慢,EleasticSearch就是解决这个问题
elasticsearch之所以有如此高性能的搜索表现,正是得益于底层的倒排索引技术。倒排 索引的概念是基于MySQL这样的正向索引而言的。
倒排索引中有两个非常重要的概念:
-
文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息 -
词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
创建倒排索引是对正向索引的一种特殊处理和应用,流程如下:
-
将每一个文档的数据利用分词算法根据语义拆分,得到一个个词条
-
创建表,每行数据包括词条、词条所在文档id、位置等信息
-
因为词条唯一性,可以给词条创建正向索引
此时形成的这张以词条为索引的表,就是倒排索引表
那么为什么一个叫做正向索引,一个叫做倒排索引呢?
-
正向索引 是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
-
而倒排索引 则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
倒排索引:
-
优点:
- 根据词条搜索、模糊搜索时,速度非常快
-
缺点:
-
只能给词条创建索引,而不是字段
-
无法根据字段做排序
-
这就是对于EleasticSearch的介绍,并且我们知道了为什么要用它

那是不是说,我们学习了elasticsearch就不再需要mysql了呢?
并不是如此,两者各自有自己的擅长之处:
-
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
-
Elasticsearch:擅长海量数据的搜索、分析、计算
因此在企业中,往往是两者结合使用:
-
对安全性要求较高的写操作,使用mysql实现
-
对查询性能要求较高的搜索需求,使用elasticsearch实现
-
两者再基于某种方式,实现数据的同步,保证一致性
后续的学习就是对DSL查询语句的使用,以及IK分词器
分词器的作用是什么?
-
创建倒排索引时,对文档分词
-
用户搜索时,对输入的内容分词
IK分词器有两种模式:
-
ik_smart:智能切分,粗粒度 -
ik_max_word:最细切分,细粒度
IK分词器如何拓展词条?如何停用词条?
-
利用config目录的
IkAnalyzer.cfg.xml文件添加拓展词典和停用词典 -
在词典中添加拓展词条或者停用词条
具体的DSL的语句的使用不再说明
总结
这篇文章对于Nacos、OpenFeign、SpringCloudGateway、Sentinel、Seata的讲述还是很清晰的
至于RabbitMQ、EleasticSearch的描述中,有部分内容做了省略
不过如果能够仔细看完这篇文章,我相信,你对于微服务的了解就很深刻了
------迷糊小白告