一、原型链
js中没有传统的类继承,实现继承的方式就是通过原型链。理解原型链,是真正掌握 JS 继承、this、对象机制的关键。
1、核心概念
(1)每一个对象的内部都有一个\[Prototype],也就是它的原型
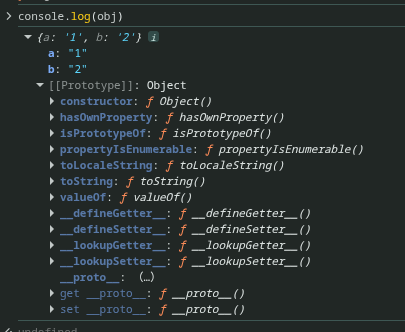
在标准实现中,该属性是不可访问的,但是浏览器提供了 proto(非标准) 和 Object.getPrototypeOf()(标准方法) 来获取和访问它的原型。
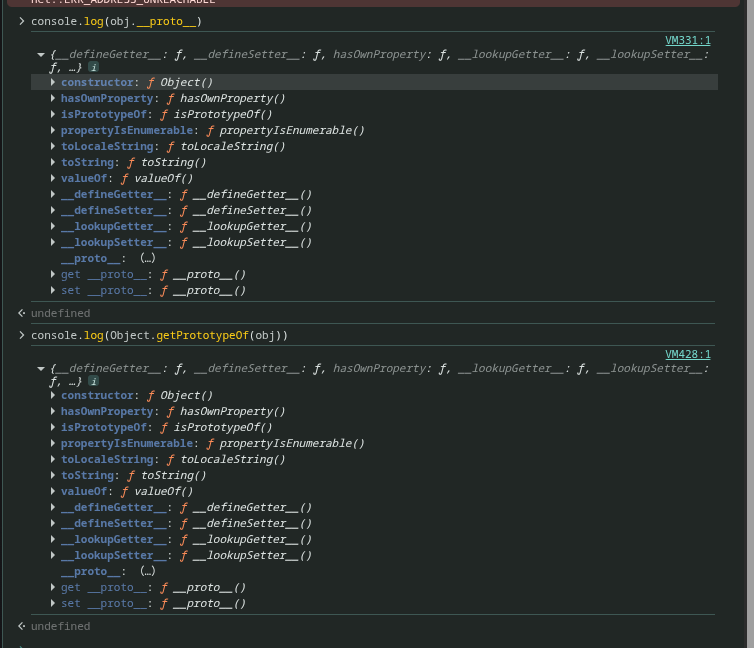
通过打印原型,我们可以看到,有一个constructor属性,这个属性指回构造函数本身。
这里我们可以思考一下,普通函数、通过字面量直接创建的函数,并没有调用new去构造函数,为什么也能这样访问?答案就是:虽然我们没有手动去new,但底层js引擎帮我们自动完成了这一步,事实上都是通过new来实现的,只是通过字面量创建的对象,new的是Object这个对象(Object同时也是函数)。
(2)函数特有的属性------prototype 属性(除了箭头函数和某些内置函数)
该属性指向一个对象,称其为"原型对象"。
当该函数作为构造函数(执行new操作)时,新创建的对象的\[Prototype] 会指向构造函数的 prototype 对象。
补充面试题 :在一个函数作为构造函数被new的时候,都发生了哪些事情?
答案 :(1)在一个构造函数被new的时候,首先js引擎在内存开辟一个新的空间,创建一个空对象
javascriptlet obj = {};(2)将这个新对象的\[Prototype]属性指向构造函数的 prototype 属性,建立原型链关系(这一步使得新对象能访问构造函数原型上的所有属性和方法)
javascriptobj.__proto__ = Constructor.prototype; // 或使用更现代的写法 Object.setPrototypeOf(obj, Constructor.prototype);(3)将构造函数内部的this关键字绑定到这个新创建的对象上,然后使用传入的参数执行构造函数体内的代码
javascriptConstructor.call(obj, arg); // 或 Constructor.apply(obj, [arg]);(4)最后js引擎检查构造函数的返回值:如果没有返回值,或者返回一个基本数据类型,那么new就会忽略这个返回值,直接返回创建的对象;如果返回值是一个引用类型,那么new表达式就会放弃之前创建的对象,直接返回这个引用类型的对象
javascriptreturn (typeof result === 'object' && result !== null) ? result : obj;
(3)原型对象本身也是一个对象
所以它也有自己的 \[Prototype],形成链式结构。
(4)原型链的终点
Object.prototype 的原型是 null,表示原型链的终点。null 没有任何属性,因此查找失败时返回 undefined。
代码示例
javascript
function Person(name) {
this.name = name;
}
Person.prototype.sayHello = function() {
console.log(`Hello, I'm ${this.name}`);
};
const alice = new Person('Alice');
// alice.__proto__ === Person.prototype
// Person.prototype.__proto__ === Object.prototype
// Object.prototype.__proto__ === null原型链示意图
alice → Person.prototype → Object.prototype → null
2、属性查找的过程
当访问 alice.sayHello 时:
-
先查找 alice 自身是否有 sayHello(没有)
-
沿着 proto 到 Person.prototype,找到了,调用它。
-
如果还没找到,继续到 Object.prototype,再没有则返回 undefined。
注意:设置属性(如 alice.age = 20)永远是在对象自身创建属性,不会修改原型链上的同名属性。
3、最容易混淆的点
(1)prototype 和 \[Prototype] 的区别

(2)Object、Function 特殊关系
js
// 1
Function.__proto__ === Function.prototype
// 2
Object.__proto__ === Function.prototype
// 3
Function.prototype.__proto__ === Object.prototype
// 4
Object.prototype.__proto__ === null到这里可能很多人还是不理解原型链,特别懵逼,没关系,我来解释几个比较难理解的地方:
- 首先js中,一切皆对象(基本类型除外),所以不管是函数还是数组等都是具有\[Prototype]的,我们都可以通过__proto__或者Object.getPrototypeOf()去访问它的原型。
- 原型是什么呢?原型实际上就是构造函数 prototype 属性所指向的那个对象。这个属性的作用主要是挂载一些公共的方法、属性,实现复用。
- constructor在原型对象上,也就是在构造函数的prototype属性上,指回构造函数本身。
我们可以尝试手动画一个原型链出来,帮助更好的理解原型链:
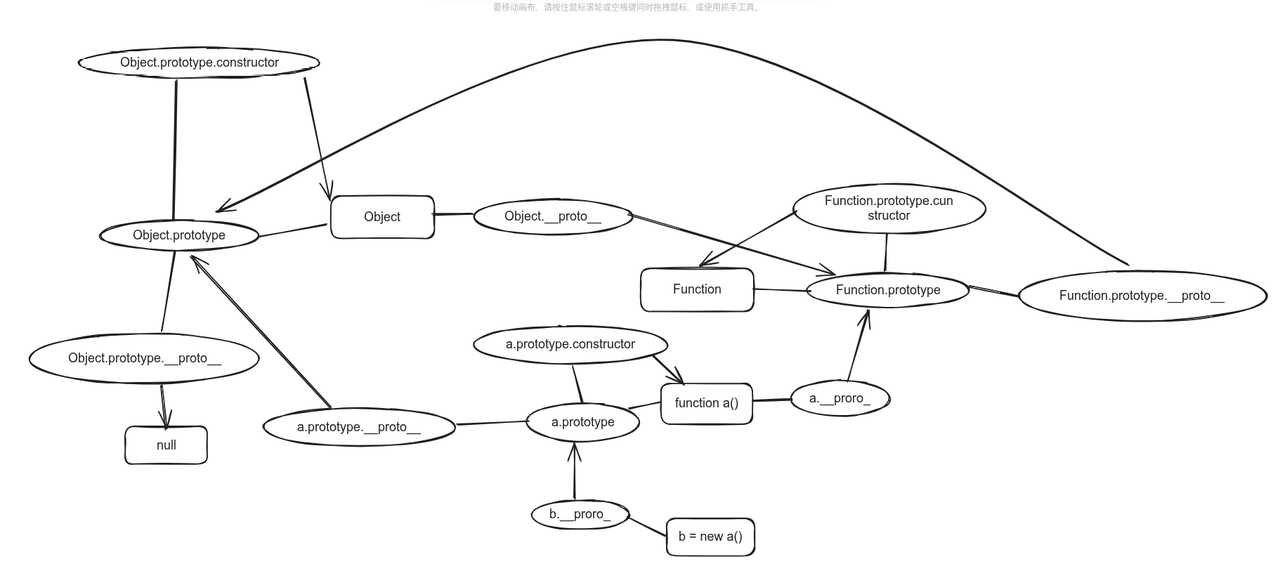
这个是我画的原型链,看着可能费劲点,原型链本身也比较复杂,所以还是建议自己尝试着画一画。
个人建议使用Mermaid语法尝试去画,因为它是代码形式,逻辑更清晰,画完之后还能让AI帮忙检查;如果直接画图,AI识别效果可能不好,再加上自己逻辑不清晰,容易出错(这里我就吃了个大亏)。
4、原型链常见面试考点
考点1:原型链的基本结构
题目形式:问 实例.proto === 构造函数.prototype 是否成立;或者画原型链关系图。
核心:
-
每个对象都有 proto(即 \[Prototype])。
-
每个函数(除箭头函数等)都有 prototype 属性,指向其实例的原型对象。
-
构造函数.prototype.proto === Object.prototype,Object.prototype.proto === null。
常考示例:
javascript
function Foo() {}
const obj = new Foo();
console.log(obj.__proto__ === Foo.prototype); // true
console.log(Foo.prototype.__proto__ === Object.prototype); // true
console.log(Object.prototype.__proto__); // null考点2:属性查找与遮蔽(遮蔽效应)
题目形式:访问对象属性时,JS 引擎如何查找?如何判断属性是自身还是继承来的?
核心:
-
先找自身属性,没有则沿原型链向上找。
-
自身设置属性不会影响原型(除非同名属性已存在于原型上,但赋值仍是在自身创建或覆盖自身属性)。
考点示例:
javascript
const parent = { a: 1, b: 2 };
const child = Object.create(parent);
child.a = 100;
console.log(child.a); // 100(自身属性)
console.log(child.b); // 2(继承自 parent)
delete child.a;
console.log(child.a); // 1(又回到 parent.a)考点3:hasOwnProperty 与 in 操作符
题目形式:判断某属性是自身属性还是继承属性?in 和 hasOwnProperty 的区别。
核心:
-
obj.hasOwnProperty('prop'):只检查自身属性。
-
'prop' in obj:检查整个原型链。
示例:
javascript
function Person(name) { this.name = name; }
Person.prototype.age = 18;
const p = new Person('Tom');
console.log(p.hasOwnProperty('name')); // true
console.log(p.hasOwnProperty('age')); // false
console.log('age' in p); // true考点4:instanceof 原理
题目形式:手写 instanceof;或者问 \[\] instanceof Array、\[\] instanceof Object 的结果及原因。
核心:
-
A instanceof B:检查 B.prototype 是否出现在 A 的原型链上。
-
对于基本类型(非对象)始终返回 false。
手写版本:
javascript
function myInstanceof(left, right) {
let proto = Object.getPrototypeOf(left);
const prototype = right.prototype;
while (proto) {
if (proto === prototype) return true;
proto = Object.getPrototypeOf(proto);
}
return false;
}考点5:创建对象与原型关系的多种方式
题目形式:列举创建对象的方法,并说明其原型指向。
常见方法:
-
字面量:{} → Object.prototype
-
new Object() → 同字面量
-
构造函数 new Foo() → Foo.prototype
-
Object.create(proto) → 指定原型
-
Object.setPrototypeOf(obj, proto)(不推荐)
-
ES6 class(本质同构造函数)
考点:Object.create(null) 创建的对象没有原型,也没有 hasOwnProperty 等方法。
考点6:原型链继承的实现方式与问题
题目形式:如何实现继承?组合继承与寄生组合继承的区别?Class 继承的本质?
常见错误:
-
直接 Child.prototype = Parent.prototype:父子构造函数原型指向同一个对象,子类添加方法会污染父类。
-
只调用父构造函数 Parent.call(this) 但没有继承原型上的方法。
-
没有修复 constructor 指向。
标准寄生组合继承:
javascript
function inherit(Child, Parent) {
Child.prototype = Object.create(Parent.prototype);
Child.prototype.constructor = Child;
}
function Parent(name) { this.name = name; }
Parent.prototype.say = function() {};
function Child(name, age) {
Parent.call(this, name);
this.age = age;
}
inherit(Child, Parent);考点7:修改原型的影响
题目形式:在实例创建后修改构造函数的 prototype,已有实例能否访问到新添方法?
核心:
-
实例的 proto 指向的是构造函数当时的 prototype 对象(该对象本身可动态添加属性)。
-
直接替换构造函数的 prototype 为新对象,旧实例的原型链仍然指向旧对象,不会自动更新。
示例:
javascript
function Dog() {}
const d1 = new Dog();
Dog.prototype.bark = () => console.log('woof');
d1.bark(); // 可以(原型对象没变,只是添加了方法)
Dog.prototype = { jump: () => console.log('jump') };
const d2 = new Dog();
d2.jump(); // 可以
d1.jump(); // 报错,d1 的原型仍然是旧的 Dog.prototype考点8:Function 与 Object 的原型关系(终极绕点)
题目形式:Function instanceof Object 和 Object instanceof Function 分别是什么?为什么?
核心:
-
Function.prototype 是函数原型对象,所有函数(包括 Object、Function 自身)的 proto 都指向它。
-
Function.prototype.proto === Object.prototype(因为函数原型对象也是普通对象)。
-
Object 本身是函数,所以 Object.proto === Function.prototype。
因此:
-
Function instanceof Object → Function.proto === Function.prototype,Function.prototype.proto === Object.prototype,所以 true。
-
Object instanceof Function → Object.proto === Function.prototype,Function.prototype 在 Object 的原型链上,所以 true。
口诀:万物皆对象,函数皆函数;所有函数 proto 都指向 Function.prototype,Object.prototype 是最后的 null。
考点9:Object.getPrototypeOf 与 proto 的区别与规范
题目形式:不使用 proto,如何获取或设置原型?
答案:
-
获取:Object.getPrototypeOf(obj)(ES5)
-
设置:Object.setPrototypeOf(obj, proto)(不推荐,性能差)或创建时用 Object.create(proto)
考点10:原型链与性能/内存
题目形式:过多层级的原型链有什么问题?为什么通常不建议动态修改原型?
要点:
-
原型链越长,属性查找越慢。
-
修改原型会影响所有实例,可能导致意外副作用。
-
引擎难以优化(隐藏类失效)。
二、AI:LLM 基础概念(仅作为了解,不必深入)
1、LLM 到底是什么?
大语言模型:一个超大规模的神经网络,训练语料包含互联网上的海量文本(网页、书籍、代码、论文等)。
本质工作方式:根据给定的上文,预测下一个最可能出现的 token(类似手机输入法的"联想输入",但强大无数倍)。
训练好之后,它不再学习新东西,完全靠"记忆"中的知识来回答。
2、Token ------ 一切计量的基础
模型不识别字符或单词,只识别 token。一个 token 大约对应:
-
英文:0.75 个单词(例如 "ChatGPT" 是一个 token)
-
中文:一个字可能占 1~2 个 token
为什么重要:
-
定价按 token 数(输入 token + 输出 token)。
-
上下文窗口限制也是 token 数。
-
前端小工具:很多模型提供商提供 token 计数器,可预估花费。
3、上下文窗口(Context Window)
模型一次能"看到"的最大 token 数量(包括你的提问和它生成的回答)。
例如 8K = 约 6000 个汉字,128K ≈ 一本《三体》第一部。
超出窗口的内容会被截断,模型完全遗忘。长对话时需要自己裁剪历史。
4、调用 LLM API 时的核心参数
json
{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "你好"}],
"temperature": 0.7,
"max_tokens": 500,
"top_p": 0.9,
"stream": false
}参数说明:
-
messages:对话数组,包含 system(系统指令)、user(用户)、assistant(模型回复)。
-
temperature:范围 0~2。
-
0:最确定,每次回复都差不多。
-
1:平衡。
-
2:想象力爆炸,可能跑题。
-
-
max_tokens:最多生成多少个 token(不是字数)。
-
top_p:核采样,与 temperature 类似,通常只调其中一个。
-
stream:是否流式输出(逐字显示,体验更好)。
5、角色(Role)体系
-
system:设定模型的"人设"或规则(例如:"你是一个客服助手,只回答产品问题")。
-
user:用户输入。
-
assistant:模型的回复(在 API 调用中,需要把历史回复也传回去,以维持对话记忆)。
6、常见模型家族(前端看到的名字)
| 模型 | 提供方 | 特点 |
|---|---|---|
| GPT-3.5 / GPT-4 | OpenAI | 闭源,API 成熟 |
| DeepSeek | 深度求索 | 国内,性价比高,长上下文 |
| LLaMA 2/3 | Meta | 开源可本地部署 |
| Claude 3 | Anthropic | 安全、长上下文 |
| Gemini | 多模态 |
7、提示工程 ------ 前端也能用的技巧
-
少样本:在提问前给 1~3 个示例,模型模仿能力很强。
-
思维链:加上一句"让我们一步一步思考",数学/推理任务效果提升明显。
-
结构化提示:用 --- 或 XML 标签分隔示例和真实输入。
-
角色扮演:system 中写"你是一名资深前端工程师,解释概念时喜欢举例"。
8、流式响应(Streaming)
-
普通 API 请求会等待所有 token 生成完才返回(几秒到几十秒)。
-
流式响应:模型每生成一个 token 就发送一个 chunk,前端可以逐字显示,体验类似 ChatGPT 打字效果。
实现方式:EventSource 或 fetch + 读取 ReadableStream(各大 SDK 都有支持)。
9、函数调用(Function Calling / Tool Use)
以前端为例:你想让模型查询天气,它自己不知道实时天气,但可以输出一个结构化请求(如 { name: "get_weather", args: { city: "北京"} }),前端收到后调用真实天气 API,再把结果返回给模型。
这让 LLM 能操作外部系统,是Agent的基础。
10、常见坑与建议
- 模型会幻觉:尤其问"有没有某个 npm 包"时可能编出来。
应对:让模型给出参考来源,或使用 RAG(检索增强生成,后面可了解)。
-
计费不便宜:大模型 API 请求可能一次花几分钱,注意限制 max_tokens。
-
安全性:用户可能尝试"提示注入"(让模型忽略你的系统指令)。
对策:对用户输入做清洗,或使用独立会话。
- 长上下文不代表无限记忆:即使支持 128K,模型对中间部分的注意力会减弱("迷失在中间"现象)。
11、前端集成 LLM 的典型流程
plain
用户输入 → 前端拼接 messages(含 system + 历史对话)→ 调用 API → 显示回复(流式)→ 保存 assistant 回复到历史历史管理要控制在窗口限制内(先进先出截断或使用滑动窗口)。
注意:敏感信息(如 API Key)绝不能放在前端,应由后端代理请求。
作为前端,你并不需要训练模型或了解反向传播,但搞懂这些概念能让你自信地对接任何 LLM API、调试 prompt 以及评估模型能力是否满足业务需求。