背景
日常跑批中一个 SparkSQL 任务突然报错失败,该任务之前一直稳定运行。任务逻辑比较见到那,并且涉及的数据量和 SQL 逻辑近期没有变动。
现象
任务执行约 7 分钟后抛出异常,关键报错信息如下:
vbscript
26/05/06 14:52:25 ERROR BroadcastExchangeExec: Could not execute broadcast in 300 secs.Spark 在执行 BroadcastHashJoin 时,等待广播变量超过了默认的 300 秒超时阈值。
排查过程
第一步:确认广播超时的对象
看到 BroadcastExchangeExec 超时,第一反应是:哪张表被广播了?为什么超时?
Spark 在执行 left JOIN 时,如果一侧的表大小低于 spark.sql.autoBroadcastJoinThreshold(默认 10MB),会自动选择 BroadcastHashJoin,将小表广播到所有 Executor。
按理说小表广播应该很快(并且确认了left join的都是产品级别的维表),300 秒超时不太正常。
第二步:日志中寻找线索
在 ERROR 级别的日志中只能看到超时的结论,没有直接给出是哪张表导致的。
这里走了一点弯路------一开始只关注了 ERROR 和 WARN 级别的日志,没办法继续往下定位
后来定位到失败task的INFO 级别日志, 确认108这个task从开始到结束大概5min, 是executor自行kill了
yaml
*26/05/06 14:47:19* INFO Executor: Running task 108.0 in stage 5.0 (TID 578)
26/05/06 14:47:19 INFO ShuffleBlockFetcherIterator: Getting 1 (97.0 B) non-empty blocks including 1 (97.0 B) local and 0 (0.0 B) host-local and 0 (0.0 B) remote blocks
26/05/06 14:47:19 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 0 ms
.......
26/05/06 14:52:25 INFO Executor: Running task 108.0 in stage 9.0 (TID 2516)
26/05/06 14:52:25 INFO ShuffleBlockFetcherIterator: Getting 1709 (380.0 KiB) non-empty blocks including 388 (85.7 KiB) local and 0 (0.0 B) host-local and 1321 (294.3 KiB) remote blocks
26/05/06 14:52:25 INFO ShuffleBlockFetcherIterator: Started 5 remote fetches in 5 ms
*26/05/06 14:52:25* INFO *Executor: Executor is trying to kill task 108.0* in stage 9.0 (TID 2516), reason: Stage cancelled
26/05/06 14:52:25 INFO Executor: Executor interrupted and killed task 108.0 in stage 9.0 (TID 2516), reason: Stage cancelled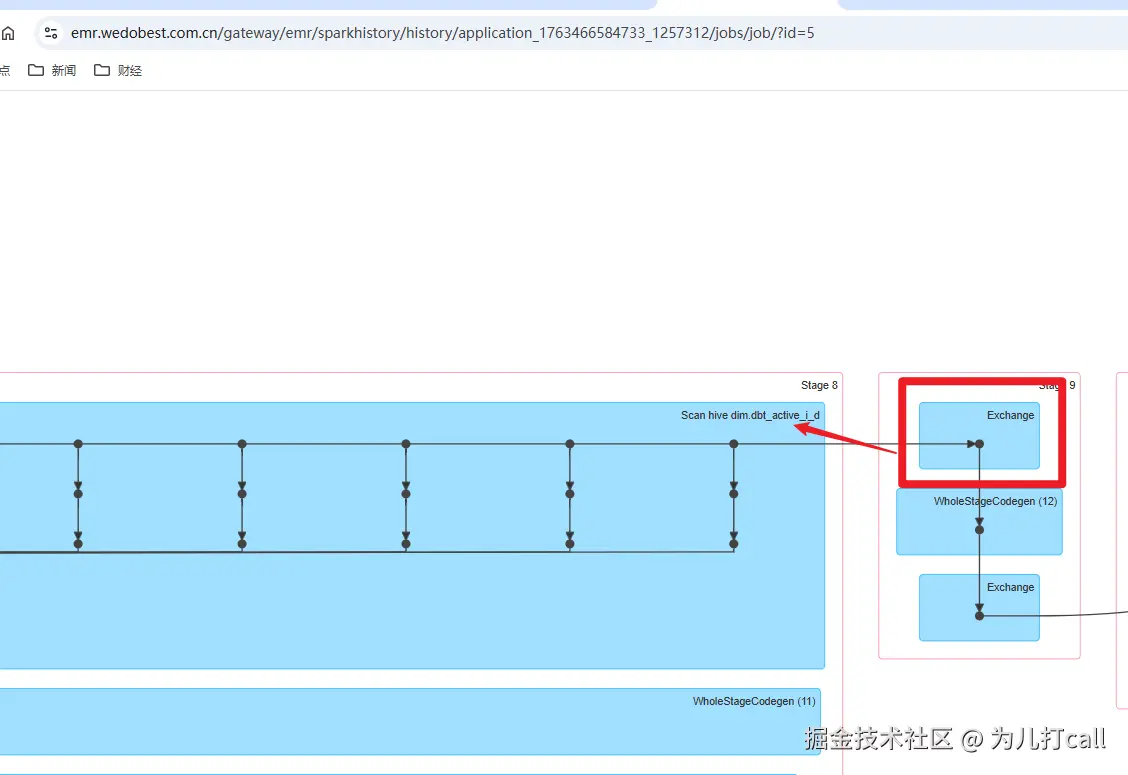
再根据失败job的DAG定位到源头的表, 这个表的分区因业务需求扫描了一千多个分区
第三步:定位根因
问题明确了:
被广播的 Hive 表数据量小(满足广播阈值),但分区数极多(1000+)。
Spark 在广播前需要做以下工作:
- 列举所有分区目录(FileStatusCache / InMemoryFileIndex)
- 读取每个分区下的文件元数据
- 合并数据并序列化为广播变量分发到各 Executor
当分区数达到千级别时,步骤 1 和 2 的 文件列举开销会非常大,尤其是在 HDFS 上需要大量 RPC 调用。这个阶段是在 Driver 端串行执行的,最终导致整体广播时间超过了 300 秒的限制。
核心矛盾 :Spark 的自动广播判断只看数据量大小 ,不考虑分区数量。一张数据量 < 10MB 但有 1000+ 分区的表,会被判定为"小表"触发广播,但实际广播成本远超预期。
解决方案
短期:调大广播超时阈值
properties
spark.sql.broadcastTimeout=1200将超时时间从默认 300 秒调大到 600 秒,确保有足够时间完成分区文件的列举和广播。
长期建议(可选)
| 方案 | 做法 | 适用场景 |
|---|---|---|
| 禁用该表的广播 | SQL 中使用 /*+ SHUFFLE_HASH(t) */ 或 /*+ SHUFFLE_MERGE(t) */ 强制走 SortMergeJoin |
明确知道某张表不适合广播 |
| 降低广播阈值 | spark.sql.autoBroadcastJoinThreshold=-1 或设更小值 |
全局禁用/收紧自动广播 |
| 合并小分区 | 对该表做分区治理,合并过多的细碎分区 | 从源头解决问题 |
总结
| 项目 | 内容 |
|---|---|
| 现象 | BroadcastExchangeExec 300 秒超时 |
| 根因 | 小表分区数过多(1000+),分区文件列举耗时超限 |
| 关键排查手段 | 查看 INFO 级别日志,发现大量分区扫描记录 |
| 修复 | 调大 spark.sql.broadcastTimeout |
| 教训 | 自动广播只看数据量不看分区数,多分区小表是隐藏的坑 |
延伸思考
"小表"不等于"广播成本低"。在评估 BroadcastJoin 是否合适时,除了数据量,还需要关注:
- 分区数量(影响文件列举速度)
- 小文件数量(影响 I/O 次数)
遇到类似场景,值得在数仓治理层面定期巡检分区数异常的表,从源头避免此类问题。