从零到一:用 Vue3 + Kimi 大模型打造「拍照记单词」AI 应用
本文适合有一定 Vue3 基础、想了解如何将大模型 API 集成到前端项目的开发者。完整项目已开源,文末附链接。
前言
在 AI 时代,"一个人的公司"(OPC)正在成为可能。本文将带你从零搭建一个 拍照记单词 的前端 AI 应用------用户拍一张照片,AI 自动识别图片内容并生成一个英文单词、例句和发音。
这个项目的核心价值在于:它不是一个 Demo,而是一个可以落地的产品原型。你会学到:
- 如何用 Vue3 Composition API 组织复杂业务逻辑
- 如何调用多模态大模型(Kimi Vision)解析图片
- 如何集成 TTS 语音合成
- 如何设计一个对用户友好的 Prompt
一、项目架构总览
bash
vue3-ts-cameraword/
├── src/
│ ├── App.vue # 主页面,核心业务逻辑
│ ├── components/
│ │ └── PictureCard.vue # 拍照卡片组件
│ ├── lib/
│ │ └── audio.ts # TTS 语音合成模块
│ └── main.ts # 入口文件
├── .env.local # 环境变量(API Key 等)
└── vite.config.ts # Vite 配置技术栈:Vue3 + TypeScript + Vite + Kimi Vision API + 火山引擎 TTS
二、核心功能实现
2.1 图片上传:FileReader 的妙用
传统文件上传需要后端配合,但多模态大模型可以直接接收 Base64 编码的图片。我们用 FileReader 在前端完成图片转码:
typescript
// PictureCard.vue
const updateImageData = async (e: Event): Promise<any> => {
const file = (e.target as HTMLInputElement).files?.[0];
if (!file) return;
return new Promise((resolve, reject) => {
const reader = new FileReader();
reader.readAsDataURL(file); // 转为 Base64
reader.onload = () => {
const data = reader.result as string;
imgPreview.value = data; // 本地预览
emit('updateImage', data); // 传给父组件
resolve(data);
};
reader.onerror = (error) => reject(error);
});
};关键点:
readAsDataURL()将文件转为data:image/png;base64,...格式的字符串- 这个字符串可以直接作为
<img>的src实现预览 - 同时可以直接传给大模型的
image_url字段
2.2 调用 Kimi Vision:多模态 API 实战
这是整个项目的核心。Kimi 的 moonshot-v1-8k-vision-preview 模型支持图片+文字的混合输入:
typescript
// App.vue
const update = async (imageDate: string) => {
const endpoint = import.meta.env.VITE_KIMI_API_ENDPOINT + '/chat/completions';
const headers = {
'Content-Type': 'application/json',
'Authorization': `Bearer ${import.meta.env.VITE_KIMI_API_KEY}`
};
word.value = '分析中...';
const response = await fetch(endpoint, {
method: 'POST',
headers,
body: JSON.stringify({
model: 'moonshot-v1-8k-vision-preview',
messages: [{
role: 'user',
content: [
{
type: 'image_url',
image_url: { url: imageDate } // Base64 图片
},
{
type: 'text',
text: userPrompt // 文字指令
}
]
}],
stream: false
})
});
const data = await response.json();
const replyData = JSON.parse(data.choices[0].message.content);
// 处理返回数据...
};这里的 content 是一个数组,可以同时包含图片和文字。这是多模态 API 的标准用法。
2.3 Prompt 设计:决定产品质量的关键
Prompt 是 AI 产品的灵魂。一个好的 Prompt 需要:
- 清晰的指令:告诉模型你要什么
- 明确的输出格式:JSON 格式便于前端解析
- 约束条件:限制词汇难度、输出长度等
typescript
const userPrompt = `
分析图片内容,找出最能描述图片的一个英文单词,尽量选择更简单的A1~A2的词汇。
返回JSON 数据:
{
"image_discription": "图片描述",
"representative_word": "图片代表的英文单词",
"example_sentence": "结合英文单词和图片描述,给出一个简单的例句",
"explaination": "结合图片解释英文单词,段落以Look at ...开头,
将段落分句,每一句单独一行,
解释的最后给一个日常生活有关的问句",
"explanation_replys": ["根据explaination给出的回复1",
"根据explaination给出的回复2"]
}
`;设计要点:
- A1~A2 级别:控制词汇难度,适合初学者
- JSON 格式 :
OutputParser的思想,让返回数据结构化,便于业务处理 Look at ...开头:引导模型用"看图说话"的方式解释,更生动- 问句结尾:制造对话感,增强学习互动性
2.4 TTS 语音合成:让单词"说出来"
学英语离不开发音。我们集成火山引擎的 TTS 服务,将例句转为语音:
typescript
// lib/audio.ts
export const generateAudio = async (text: string) => {
const endpoint = '/tts/api/v1/tts';
const headers = {
'Content-Type': 'application/json',
'Authorization': `Bearer;${token}`
};
const payload = {
app: { appid: appId, token, cluster: clusterId },
user: { uid: 'bearbobo' },
audio: {
voice_type: voiceName, // 音色:en_female_anna_mars_bigtts
encoding: 'ogg_opus', // 音频编码格式
speed_ratio: 1.0, // 语速
emotion: 'happy', // 情绪
},
request: {
reqid: Math.random().toString(36).substring(7),
text, // 要合成的文本
text_type: 'plain',
operation: 'query',
},
};
const res = await fetch(endpoint, {
method: 'POST',
headers,
body: JSON.stringify(payload)
});
const data = await res.json();
return createBlobURL(data.data); // 转为可播放的 URL
};Base64 转 Blob URL 的工具函数:
typescript
function createBlobURL(base64AudioData: string): string {
const byteArrays: number[] = [];
const byteCharacters = atob(base64AudioData); // 解码 Base64
for (let offset = 0; offset < byteCharacters.length; offset++) {
byteArrays.push(byteCharacters.charCodeAt(offset));
}
const audioBlob = new Blob([new Uint8Array(byteArrays)], {
type: 'audio/mp3'
});
return URL.createObjectURL(audioBlob); // 生成临时播放 URL
}播放逻辑很简单:
typescript
// PictureCard.vue
const playAudio = () => {
const audio = new Audio(props.audio);
audio.play();
};三、Vite 代理配置:解决跨域问题
前端直接调用第三方 API 会遇到跨域。用 Vite 的 server.proxy 解决:
typescript
// vite.config.ts
export default defineConfig({
plugins: [vue()],
server: {
host: '0.0.0.0', // 允许局域网访问
proxy: {
'/tts': {
target: 'https://openspeech.bytedance.com',
changeOrigin: true,
rewrite: path => path.replace(/^\/tts/, ''),
}
},
},
});host: '0.0.0.0':让手机等设备也能访问开发服务器/tts代理:将/tts/api/v1/tts转发到火山引擎的 API
四、无障碍设计:被忽略的细节
这个项目有一个亮点:支持读屏器的无障碍访问。
传统的 <input type="file"> 样式很难控制。我们的做法是:
html
<!-- 隐藏原生 input,用 label 触发 -->
<input type="file" id="selecteImage" class="input"
accept="image/*" @change="updateImageData">
<label for="selecteImage" class="upload">
<img :src="imgPreview" alt="camera" class="img"/>
</label>
css
.input {
display: none; /* 隐藏原生控件 */
}for="selecteImage"关联id,点击 label 等同于点击 inputaccept="image/*"限制只能选择图片- 读屏器可以通过 label 的文本识别按钮用途
效果
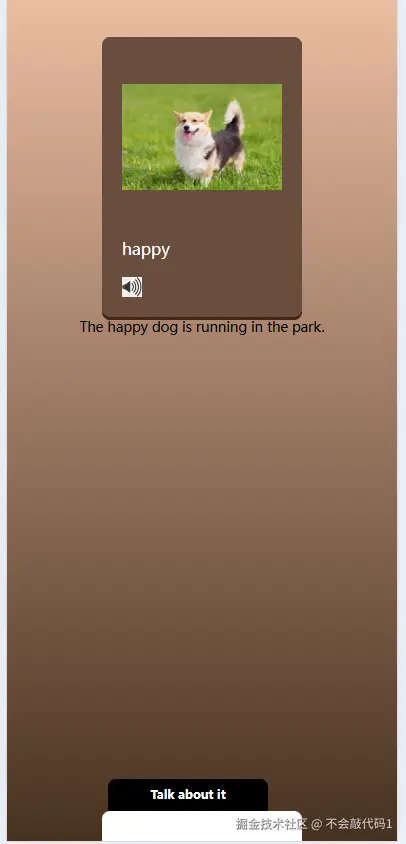
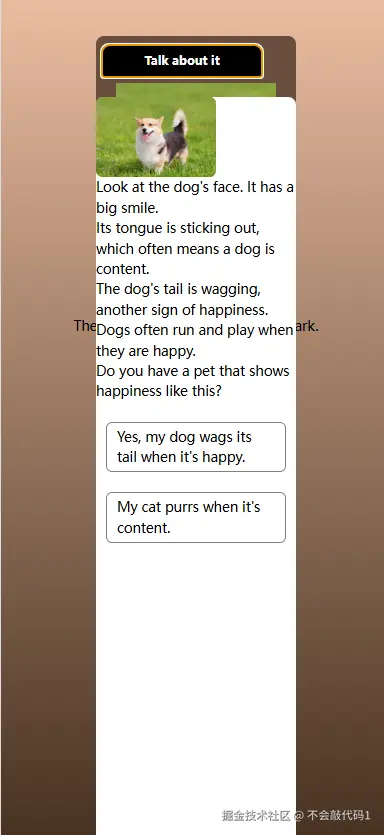
五、项目总结与思考
学到了什么
- 多模态 API 的调用方式 :
content字段是数组,图片用 Base64 编码传入 - Prompt 工程:JSON 输出格式、难度约束、引导性描述
- 前端音频处理:Base64 → Blob → ObjectURL 的完整链路
- Vite 代理:一行配置解决跨域
可以改进的方向
- 加入流式输出 (
stream: true),让分析过程可视化 - 增加单词本功能,收藏学过的单词
- 接入语音识别,支持跟读打分
- 用 IndexedDB 本地存储学习记录
六、环境配置
创建 .env.local 文件:
env
VITE_KIMI_API_KEY=sk-xxxxx # Kimi API Key
VITE_KIMI_API_ENDPOINT=https://api.moonshot.cn/v1
VITE_AUDIO_APP_ID=xxxxx # 火山引擎 TTS 配置
VITE_AUDIO_ACCESS_TOKEN=xxxxx
VITE_AUDIO_CLUSTER_ID=volcano_tts
VITE_AUDIO_VOICE_NAME=en_female_anna_mars_bigtts启动项目:
bash
npm install
npm run dev写在最后
这个项目虽然代码量不大,但覆盖了前端 AI 应用的核心链路:图片输入 → 多模态理解 → 结构化输出 → 语音合成。
AI 时代,前端工程师的价值不只是写页面,更是用 AI 能力重新定义产品体验。希望这篇文章能给你一些启发。
项目地址:[project/capture_word /lesson_zp - 码云 - 开源中国](https://link.juejin.cn?target=https%3A%2F%2Fgitee.com%2Fzuo-zi-han%2Flesson_zp%2Ftree%2Fmaster%2Fproject%2Fcapture_word "https://gitee.com/zuo-zi-han/lesson_zp/tree/master/project/capture_word") 欢迎 Star 和 PR!