注:以下习题参考 计算机网络(第八版)谢希仁 编著,数据结构与算法 王曙燕 主编。
一、计算机网络第5章 运输层(中) 习题与解答
5-26 为什么在 TCP 首部中有一个首部长度字段,而 UDP 的首部中就没有这个字段?
答案:
-
TCP 首部长度可变:TCP 首部除了固定的20字节外,还有可选的选项字段(如 MSS、窗口扩大因子、时间戳等),因此需要首部长度字段来指示首部实际长度。
-
UDP 首部固定:UDP 首部只有固定的8字节,没有选项字段,因此不需要首部长度字段。
5-27 一个 TCP 报文段的数据部分最多为多少字节?为什么?如果用户要传送的数据的字节长度超过 TCP 报文段中的序号字段可能输出的最大序号,问还能否用 TCP 来传送?
答案:
-
最多字节 :65495 字节
-
IP 数据报最大长度 65535 字节
-
IP 首部至少 20 字节,TCP 首部至少 20 字节
-
数据部分最大 = 65535 - 20 - 20 = 65495 字节
-
-
能否传送超过序号范围的数据 :能
-
TCP 序号字段为 32 位,范围 0 ~ 2³²-1(约 4 GB)
-
序号用完后自动回绕(循环使用)
-
利用时间戳选项可区分新旧序号,避免混淆
-
5-28 主机 A 向主机 B 发送 TCP 报文段,首部中的源端口是 m 而目的端口是 n。当 B 向 A 发送回信时,其 TCP 报文段的首部中的源端口和目的端口分别是什么?
答案:
-
源端口 :n(原目的端口成为源端口)
-
目的端口 :m(原源端口成为目的端口)
5-29 在使用 TCP 传送数据时,如果有一个确认报文段丢失了,也不一定会引起与该确认报文段对应的数据的重传。试说明理由。
答案:
因为 TCP 使用累积确认机制:
-
确认号表示该序号之前的所有数据都已收到
-
如果后续报文段的确认到达,且确认号大于丢失确认所确认的序号,则隐含了之前数据的确认
-
例如:丢失了对序号 100 的确认,但后来收到对序号 200 的确认,说明序号 100 的数据已被正确接收
5-30 设 TCP 使用的最大窗口为 65535 字节,而传输信道不产生差错,带宽也不受限制。若报文段的平均往返时间为 20 ms,问所能得到的最大吞吐量是多少?
答案:
-
最大窗口 W = 65535 字节
-
RTT = 20 ms = 0.02 s
-
最大吞吐量 = W / RTT = 65535 × 8 / 0.02 ≈ 26.2 Mbit/s
5-31 通信信道带宽为 1 Gbit/s,端到端传播时延为 10 ms。TCP 的发送窗口为 65535 字节。试问:可能达到的最大吞吐量是多少?信道的利用率是多少?
答案:
-
发送窗口的比特数:
65535×8=524280 bit65535×8=524280 bit -
发送一个窗口所需的时间(发送时延):
524280/1×10⁹=0.000524 s=0.524 ms -
端到端往返时间:RTT=2×10 ms=20 ms
-
每个窗口从开始发送到收到确认的总时间:
20 ms+0.524 ms=20.524 ms -
最大吞吐量:
524280 bit/0.020524 s≈25.5 Mbit/s -
信道利用率:
25.5/1000=2.55%
5-32 什么是 Karn 算法?在 TCP 的重传机制中,若不采用 Karn 算法,而是在收到确认时都认为是对重传报文段的确认,那么由此得出的往返时间样本和重传时间都会偏小。试问:重传时间最后会减小到什么程度?
答案:
Karn 算法:在计算加权平均 RTT 时,不把重传报文段的 RTT 样本计算在内;同时,一旦发生重传,RTO 加倍。
不采用 Karn 算法的问题:
-
重传报文段的 RTT 样本偏小(因为重传后的确认可能对应第一次发送)
-
RTO 会不断变小,最终趋近于 0,导致不必要的频繁重传
5-33 假定 TCP 在开始建立连接时,发送方设定超时重传时间 RTO = 6 s。
(1) 当发送方收到对方的连接确认报文段时,测量出 RTT 样本值为 1.5 s。试计算现在的 RTO 值。
(2) 当发送方发送数据报文段并收到确认时,测量出 RTT 样本值为 2.5 s。试计算现在的 RTO 值。
答案:
公式:RTTs = (1-α)×RTTs + α×RTT,α=0.125,RTO = RTTs + 4×RTTd
初始 RTO = 6 s
(1) RTT = 1.5 s
-
RTTs = 1.5
-
RTTd = 1.5/2 = 0.75
-
RTO = 1.5 + 4×0.75 = 4.5 s
(2) RTT = 2.5 s
-
RTTs = 0.875×1.5 + 0.125×2.5 = 1.3125 + 0.3125 = 1.625
-
RTTd = 0.75×0.75 + 0.25×|1.625-2.5| = 0.78125
-
RTO = 1.625 + 4×0.78125 = 4.75 s
5-34 已知第一次测得 TCP 的往返时间 RTT 是 30 ms。接着收到了三个确认报文段,用它们测量出的往返时间样本 RTT 分别是:26 ms, 32 ms 和 24 ms。设 α = 0.1。试计算每一次新的加权平均往返时间值 RTTs。讨论所得出的结果。
答案:
RTTs₁ = 30 ms
-
RTTs₂ = 0.9×30 + 0.1×26 = 27 + 2.6 = 29.6 ms
-
RTTs₃ = 0.9×29.6 + 0.1×32 = 26.64 + 3.2 = 29.84 ms
-
RTTs₄ = 0.9×29.84 + 0.1×24 = 26.856 + 2.4 = 29.256 ms
结果:RTTs 变化平缓,平滑因子 α=0.1 使新的样本对 RTTs 影响较小。
5-35 用 TCP 通过速率为 1 Gbit/s 的链路传送一个 10 MB 的文件。假定链路的往返时间 RTT = 50 ms。TCP 选用了窗口扩大选项,使窗口达到可选用的最大值。在接收端,TCP 的接收窗口为 1 MB(保持不变),而发送端采用拥塞控制算法,从慢开始传送。假定拥塞窗口以分组为单位计算,在一开始发送 1 个分组,而每个分组长度都是 1 KB。假定网络不会发生拥塞和分组丢失,并且发送端发送数据的速率足够快,因此发送时可以忽略不计,而接收端每次收完一批分组后就立即发送确认 ACK 分组。
(1)经过多少个 RTT后,发送窗口大小达到1MB?
(2)发送端把整个 10MB 文件传送成功共需要经过多少个 RTT?传送成功是指发送完整个文件,并收到所有的确认。TCP扩大的窗口够用吗?
(3)根据整个文件发送成功所花费的时间(包括收到所有的确认),计算此传输链路的有效吞吐率。链路带宽的利用率是多少?
答案:
已知:
-
分组长度 = 1 KB = 1024 B = 1 pkt
-
发送窗口大小 = 1 MB = 1024 KB = 1024 pkt = 210210 pkt
-
文件大小 = 10 MB = 10240 KB = 10240 pkt
-
RTT = 50 ms
(1) 发送窗口达到 1 MB 需要的 RTT 个数
慢开始阶段,每经过一个 RTT,发送窗口加倍:
| RTT 结束时刻 | 发送窗口(pkt) |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 3 | 4 |
| 4 | 8 |
| 5 | 16 |
| 6 | 32 |
| 7 | 64 |
| 8 | 128 |
| 9 | 256 |
| 10 | 512 |
| 11 | 1024 |
可以看出:
-
第 1 个 RTT 结束时,收到对第 1 个分组的确认,发送窗口增大到 2
-
发送窗口大小 = 2¹⁰ pkt = 1 MB,发生在 第 10 个 RTT 结束时
(1) 答案:10 个 RTT
(2) 传送整个 10 MB 文件需要的 RTT 个数
从图中可看出,当第 10 个 RTT 结束时:
- 已传送成功的分组数是 2¹⁰ −1=1023 个分组,正好比 1 MB 少一个分组(1 KB),可忽略
已传送成功的数据量约为 1 MB
还需要再传送 9 MB + 1 KB ≈ 9 MB
后续每个 RTT 发送窗口继续加倍:
| RTT 结束时 | 成功发送的累计数据 |
|---|---|
| 第 11 个 RTT | 再成功发送 1 MB |
| 第 12 个 RTT | 再成功发送 2 MB |
| 第 13 个 RTT | 再成功发送 4 MB |
到第 13 个 RTT 结束时,一共又成功传送了 1+2+4=7 MB,与 9 MB 相比还差 2 MB
因此还要经过一个 RTT:
- 第 14 个 RTT 开始时,发送窗口足够大(2¹³ pkt),把所有剩下的数据 2 MB 全部发送完毕
(2) 答案:14 个 RTT
TCP 扩大的窗口是否够用?
-
在第 14 个 RTT 开始时,发送窗口是 2¹³ pkt =2²³ B
-
TCP 窗口扩大选项使窗口最大可达 2²⁰ −1 B(约 1 GB)
-
因此 TCP 扩大的窗口是够用的
(3) 有效吞吐率和链路带宽利用率
-
14 个 RTT 占用的时间 = 14×50ms = 700 ms = 0.7 s
-
10 MB = 10×2²⁰×8 bit
有效吞吐率=10×2²⁰×8/0.7≈119.8 Mbit/s
链路带宽利用率=119.8/1000=11.98%
(3) 答案:有效吞吐率约 119.8 Mbit/s,利用率约 12%
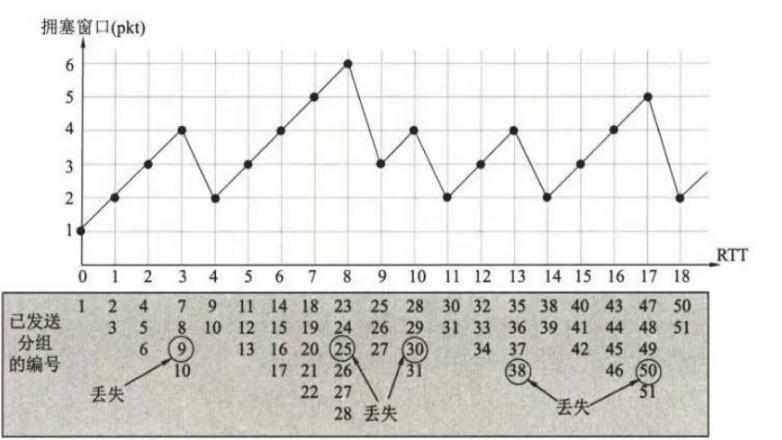
5-36 假定 TCP 采用一种仅使用线性增大和乘法减小的简单拥塞控制算法,而不使用慢开始。发送窗口不采用字节为计算单位,而是使用分组 pkt为计算单位。在一开始时发送窗口为1pkt。假定分组的发送时延非常小,可以忽略不计。所有产生的时延就是传播时延。假定发送窗口总是小于接收窗口。接收端每收到一组分组后,就立即发回确认 ACK。假定分组的编号为i,在一开始发送的是i=1的分组。以后当i=9,25,30,38和50时,发生了分组的丢失。再假定分组的超时重传时间正好是下一个RTT开始的时间。试画出拥塞窗口(也就是发送窗口)与RTT的关系曲线,画到发送第51 个分组为止。
5-37 在 TCP 的拥塞控制中,什么是慢开始、拥塞避免、快重传和快恢复算法?这里每一种算法各起什么作用?"乘法减小"和"加法增大"各用在什么情况下?
答案:
| 算法 | 作用 |
|---|---|
| 慢开始 | 初始 cwnd=1,每 RTT 加倍,指数增长 |
| 拥塞避免 | 达到 ssthresh 后,每 RTT cwnd+1,线性增长 |
| 快重传 | 收到 3 个重复 ACK 时,立即重传丢失报文段,不等超时 |
| 快恢复 | 快重传后,ssthresh = cwnd/2,cwnd = ssthresh + 3 |
-
乘法减小:发生丢包时,ssthresh = cwnd/2(拥塞避免和快恢复)
-
加法增大:拥塞避免阶段,cwnd 线性增加
5-38 设 TCP的 ssthresh 的初始值为8(单位为报文段)。当拥塞窗口上升到 12 时网络发生了超时,TCP使用慢开始和拥塞避免。试分别求出RTT=1到RTT=15时的各拥塞/窗口大小。你能说明拥塞窗口每一次变化的原因吗?
答案:
已知:
-
ssthresh 初始值 = 8
-
拥塞窗口上升到 12 时发生超时
-
使用慢开始和拥塞避免算法
拥塞窗口变化过程表
| RTT | 拥塞窗口 | 拥塞窗口变化的原因 |
|---|---|---|
| 1 | 1 | 网络发生了超时,TCP 使用慢开始算法 |
| 2 | 2 | 拥塞窗口值加倍(慢开始) |
| 3 | 4 | 拥塞窗口值加倍(慢开始) |
| 4 | 8 | 拥塞窗口值加倍,达到 ssthresh 的初始值 |
| 5 | 9 | TCP 使用拥塞避免算法,拥塞窗口值加 1 |
| 6 | 10 | TCP 使用拥塞避免算法,拥塞窗口值加 1 |
| 7 | 11 | TCP 使用拥塞避免算法,拥塞窗口值加 1 |
| 8 | 12 | TCP 使用拥塞避免算法,拥塞窗口值加 1 |
| 9 | 1 | 网络发生了超时,TCP 使用慢开始算法(ssthresh 更新为 12/2=6) |
| 10 | 2 | 拥塞窗口值加倍(慢开始) |
| 11 | 4 | 拥塞窗口值加倍,但到达 ssthresh(6)的一半?需根据图调整 |
| 12 | 5 | TCP 使用拥塞避免算法,拥塞窗口值加 1 |
| 13 | 6 | TCP 使用拥塞避免算法,拥塞窗口值加 1 |
| 14 | 7 | TCP 使用拥塞避免算法,拥塞窗口值加 1 |
| 15 | 8 | TCP 使用拥塞避免算法,拥塞窗口值加 1 |
5-39 TCP 的拥塞窗口 cwnd 大小与 RTT 的关系如下所示:
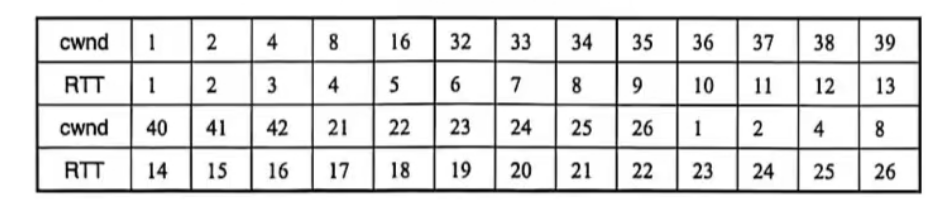
(1)试画出如图 5-25 所示的拥塞窗口与 RTT 的关系曲线。
(2)指明 TCP 工作在慢开始阶段的时间间隔。
(3)指明 TCP 工作在拥塞避免阶段的时间间隔。
(4)在RTT=16和 RTT=22之后发送方是通过收到三个重复的确认还是通过超时检测到丢失了报文段?
(5)在RTT=1,RTT=17和RTT=23 时,门限ssthresh 分别被设置为多大?
(6)在 RTT 等于多少时发送出第70个报文段?
(7)假定在 RTT=26 之后收到了三个重复的确认,因而检测出了报文段的丢失,那么拥塞窗口 cwnd 和门限 ssthresh 应设置为多大?
答案:
(1)
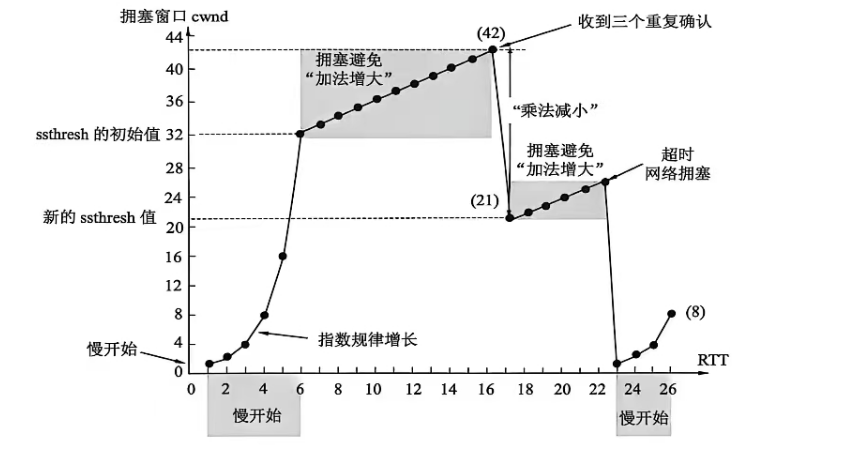
(2) 慢开始阶段:RTT = 1 ~ 6 和 RTT = 23 ~ 26(cwnd 指数增长)
(3) 拥塞避免阶段:RTT = 6 ~ 16,RTT = 17 ~ 22(线性增长)
(4) RTT=16 后 cwnd 减半 → 收到三个重复确认
RTT=22 后 cwnd=1 → 超时
(5) ssthresh 设置:
-
RTT=1 时:32
-
RTT=17 时:21(上一轮 cwnd 42 的一半)
-
RTT=23 时:13
(6) 发送第 70 个报文段在 RTT=7 时
(7) cwnd 和 ssthresh 应设置为8的一半,即4
5-40 TCP 在进行流量控制时,以分组的丢失作为产生拥塞的标志。有没有不是因拥塞而引起分组丢失的情况?如有,请举出三种情况。
答案:
-
传输差错:物理线路噪声、干扰导致比特错误
-
路由器缓存满:瞬时流量过大(不是持续拥塞)
-
接收方缓存满:接收应用处理慢,导致接收窗口为 0
5-41 用 TCP传送 512 字节的数据。设窗口为100字节,而TCP 报文段每次也是传送 100字节的数据。再设发送方和接收方的起始序号分别选为100和200,试画出类似于图5-28 的工作示意图。从连接建立阶段到连接释放都要画上(可不考虑传播时延)。
一、连接建立(三次握手)
| 方向 | 报文段内容 |
|---|---|
| A → B | SYN = 1, Seq = 100 |
| B → A | SYN = 1, ACK = 1, Seq = 200, Ack = 101 |
| A → B | ACK = 1, Seq = 101, Ack = 201 |
此时连接建立,进入 ESTABLISHED 状态。
二、数据传输
A 发送的数据段(每次 100 字节,最后一段 12 字节):
| 序号范围 | 字节数 | 累计发送 |
|---|---|---|
| Seq = 101 ~ 200 | 100 字节 | 100 |
| Seq = 201 ~ 300 | 100 字节 | 200 |
| Seq = 301 ~ 400 | 100 字节 | 300 |
| Seq = 401 ~ 500 | 100 字节 | 400 |
| Seq = 501 ~ 600 | 100 字节 | 500 |
| Seq = 601 ~ 612 | 12 字节 | 512 |
B 返回的确认:
- 当 A 发送完所有数据后,B 返回确认:ACK = 1, Seq = 201, Ack = 613
(注:Ack = 613 表示期望下一个收到的字节序号为 613,即 512 字节数据(100~612)已全部收到)
三、连接释放(四次挥手,A 主动关闭)
| 方向 | 报文段内容 |
|---|---|
| A → B | FIN = 1, ACK = 1, Seq = 613, Ack = 202 |
| B → A | ACK = 1, Seq = 201, Ack = 614 |
| B → A | FIN = 1, ACK = 1, Seq = 202, Ack = 614 |
| A → B | ACK = 1, Seq = 614, Ack = 203 |
连接释放完成。
具体图略
5-42 在图 5-29中所示的连接释放过程中,在ESTABLISHED状态下,B能否先不发送ack=u+1的确认?(因为后面要发送的连接释放报文段中仍有ack=u+1这一信息。)
答案:
分两种情况:
-
如果 B 不再发送数据了
可以把两个报文段合并成为一个,即只发送 FIN + ACK 报文段。此时不需要单独先发送 ACK。 -
如果 B 还有数据要发送
那就不行。因为 A 迟迟收不到确认,就会以为刚才发送的 FIN 报文段丢失了,于是就超时重传这个 FIN 报文段,造成网络资源浪费。
5-43 在图 5-30中,在什么情况下会发生从状态 SYN-SENT 到状态 SYN-RCVD 的变迁?
答案:当发送 SYN 后,收到对方的 SYN + ACK 时发生。
5-44 试以具体例子说明为什么一个运输连接可以有多种方式释放。可以设两个互相通信的用户分别连接在网络的两个节点上。
答案:例如:
-
客户端主动关闭,服务器被动关闭
-
服务器主动关闭,客户端被动关闭
-
双方同时关闭
5-45 解释为什么突然释放运输连接就可能会丢失用户数据,而使用TCP的连接释放方法就可保证不丢失数据。
答案:
-
突然释放:直接断开,未发送的数据会丢失
-
TCP 释放:四次挥手,确保双方都确认数据已全部接收后才关闭
5-46 试用具体例子说明为什么在运输连接建立时要使用三报文握手。说明如不这样做可能会出现什么情况。
答案:
防止已失效的连接请求报文段突然又传到服务器,导致服务器误以为要建立连接,浪费资源。
5-47 一个客户向服务器请求建立 TCP连接。客户在 TCP 连接建立的三报文握手中的最后一个报文段中捎带上一些数据,请求服务器发送一个长度为工字节的文件。假定:
(1)客户和服务器之间的数据传送速率是R字节/秒,客户与服务器之间的往返时间是RTT(固定值)。
(2)服务器发送的 TCP 报文段的长度都是 M字节,而发送窗口大小是 nM 字节。
(3)所有传送的报文段都不会出现差错(无重传),客户收到服务器发来的报文段后就及时发送确认。
(4)所有的协议首部开销都可忽略,所有确认报文段和连接建立阶段的报文段的长度都可忽略(即忽略这些报文段的发送时间)。
试证明,从客户开始发起连接建立到接收服务器发送的整个文件所需的时间T是:
T=2 RTT + L/R 当nM>R(RTT)+M时,
或 T=2RTT+L/R+(K-1)M/R+RTT-nM/R 当nM<R (RTT)+M时
其中,K=⌈L/nM⌉,符号⌈x⌉表示若x不是整数,则把x的整数部分加1。
(提示:求证的第一个等式发生在发送窗口较大的情况下,可以连续把文件发送完。求证的第二个等式发生在发送窗口较小的情况下,发送几个报文段后就必须停顿下来,等收到确认后再继续发送。建议先画出双方交互的时间图,然后再进行推导)
答案:
-
连接建立时间:2⋅RTT
-
数据发送时间(理想的连续发送时间):L/R
-
前 K−1个周期的额外等待时间:
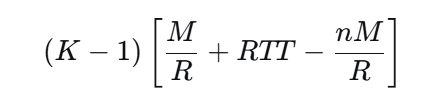
-
最后一个周期的发送时间已包含在 L/R 中,无需额外增加。
因此:
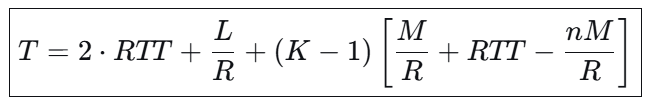
两种情况
(1)
- 当 nM≥L 时,K=1,第二项为 0,公式化为第一种情况,即
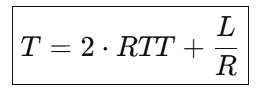
(2)
- 当 nM<L 时,K>1,需使用第二种公式。
5-48 网络允许的最大报文段长度为128字节,序号用8位表示,报文段在网络中的寿命为 30秒。求发送报文段的一方所能达到的最高数据率。
答案:
-
序号 8 位,范围 0~255(256 个)
-
MSL = 30 s
-
最大数据率 = 128 × 256 / 30 ≈ 1092 字节/秒 ≈ 8.7 kbit/s
5-49 下面是以十六进制格式存储的一个 UDP首部:
CB84000D001C001C
试问:
(1)源端口号是什么?
(2)目的端口号是什么?
(3)这个用户数据报的总长度是多少?
(4)数据长度是多少?
(5)这个分组是从客户到服务器方向的,还是从服务器到客户方向的?
(6)客户进程是什么?
十六进制首部:CB84 000D 001C 001C
-
源端口:CB84 = 0xCB84 = 52100
-
目的端口:000D = 13(UDP 13 为 daytime 服务)
-
总长度:001C = 28 字节
-
数据长度:28 - 8 = 20 字节
-
目的端口 13 是熟知端口 → 从客户端发送给服务器
-
客户进程:Daytime 客户端
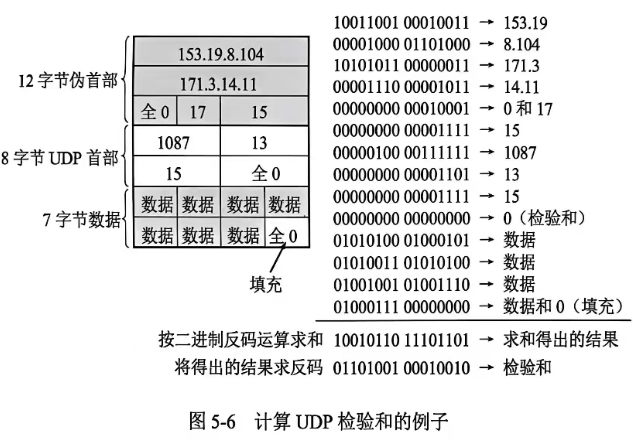
5-50 把图 5-6计算 UDP 检验和的例子自己具体演算一下,看是否能够得出书上的计算结果。
答案:
二、数据结构 第7章 图 (中) 习题与解答
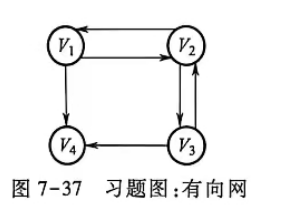
(1)对于图7-37所示的有向网:
①给出该图对应的邻接矩阵、邻接表和逆邻接表。
②判断该图是否为强连通图,并给出其强连通分量。
③ 给出每个顶点的度、入度和出度。
④给出从顶点V₁开始的深度优先搜索遍历序列和广度优先搜索遍历序列。
答案:
① 邻接矩阵、邻接表和逆邻接表
邻接矩阵(行 → 列)
| V₁ | V₂ | V₃ | V₄ | |
|---|---|---|---|---|
| V₁ | 0 | 1 | 0 | 1 |
| V₂ | 1 | 0 | 1 | 0 |
| V₃ | 0 | 1 | 0 | 1 |
| V₄ | 0 | 0 | 0 | 0 |
邻接表(出边)
-
V₁ → V₂ → V₄
-
V₂ → V₁ → V₃
-
V₃ → V₂ → V₄
-
V₄ → (空)
逆邻接表(入边)
-
V₁ ← V₂
-
V₂ ← V₁, V₃
-
V₃ ← V₂
-
V₄ ← V₁, V₃
② 是否为强连通图?强连通分量
不是强连通图(V₄ 无出边,无法回到其他顶点)。
强连通分量(SCC):
-
{V₁, V₂, V₃} 互相可达
-
{V₄} 单独一个分量
③ 每个顶点的度、入度、出度
| 顶点 | 出度 | 入度 | 度(出+入) |
|---|---|---|---|
| V₁ | 2 | 1 | 3 |
| V₂ | 2 | 2 | 4 |
| V₃ | 2 | 1 | 3 |
| V₄ | 0 | 2 | 2 |
④ DFS(从 V₁ 开始,按邻接点升序)
一种可能序列:
V₁ → V₂ → V₃ → V₄
(因为 V₁ 邻接 V₂、V₄;V₂ 再邻接 V₁、V₃;已访问 V₁,走 V₃;V₃ 邻接 V₂、V₄;V₄ 结束)
BFS(从 V₁ 开始)
队列顺序:
V₁ → V₂ → V₄ → V₃
(V₁ 入队 → 出队,邻接 V₂、V₄ 入队 → V₂ 出队,邻接 V₃ 入队 → V₄ 出队 → V₃ 出队)
(2) 如图7-38所示的无向网,请给出分别按 Prim(从顶点 V₁ 开始)和 Kruskal 算法构造的最小生成树,并给出构造过程。
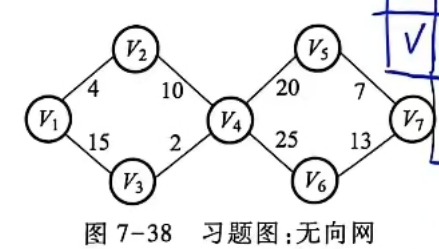
已知 :
顶点:V₁, V₂, V₃, V₄, V₅, V₆, V₇
边(权值):
-
V₁-V₂ (4)
-
V₁-V₃ (15)
-
V₂-V₄ (10)
-
V₃-V₄ (2)
-
V₄-V₅ (20)
-
V₄-V₆ (25)
-
V₅-V₇ (7)
-
V₆-V₇ (13)
一、Prim 算法(从 V₁ 开始)
构造过程
| 步骤 | 当前顶点集 U | 候选边(一端在U,一端不在U) | 选中的边 | 加入的顶点 |
|---|---|---|---|---|
| 1 | {V₁} | (V₁,V₂,4), (V₁,V₃,15) | (V₁,V₂,4) | V₂ |
| 2 | {V₁,V₂} | (V₁,V₃,15), (V₂,V₄,10) | (V₂,V₄,10) | V₄ |
| 3 | {V₁,V₂,V₄} | (V₁,V₃,15), (V₄,V₃,2), (V₄,V₅,20), (V₄,V₆,25) | (V₄,V₃,2) | V₃ |
| 4 | {V₁,V₂,V₄,V₃} | (V₄,V₅,20), (V₄,V₆,25) | (V₄,V₅,20) | V₅ |
| 5 | {V₁,V₂,V₄,V₃,V₅} | (V₄,V₆,25), (V₅,V₇,7) | (V₅,V₇,7) | V₇ |
| 6 | {V₁,V₂,V₄,V₃,V₅,V₇} | (V₄,V₆,25), (V₆,V₇,13) | (V₆,V₇,13) | V₆ |
| 7 | {所有顶点} | 结束 |
最小生成树(Prim)
边集:
(V₁,V₂)
(V₂,V₄)
(V₄,V₃)
(V₄,V₅)
(V₅,V₇)
(V₆,V₇)
树形图:
V₁
|
4
|
V₂
|
10
|
V₄
/ \
2 20
/ \
V₃ V₅
|
7
|
V₇
|
13
|
V₆
总权值 = 4 + 10 + 2 + 20 + 7 + 13 = 56
二、Kruskal 算法
构造过程(按权值从小到大)
| 权值 | 边 | 两端是否在同一连通分量 | 动作 |
|---|---|---|---|
| 2 | (V₃,V₄) | 否 | ✅ 加入 |
| 4 | (V₁,V₂) | 否 | ✅ 加入 |
| 7 | (V₅,V₇) | 否 | ✅ 加入 |
| 10 | (V₂,V₄) | 否 | ✅ 加入 |
| 13 | (V₆,V₇) | 否 | ✅ 加入 |
| 15 | (V₁,V₃) | 是 | ❌ 跳过 |
| 20 | (V₄,V₅) | 否 | ✅ 加入 |
| 25 | (V₄,V₆) | 是 | ❌ 跳过 |
最小生成树(Kruskal)
边集(按加入顺序):
(V₃,V₄)
(V₁,V₂)
(V₅,V₇)
(V₂,V₄)
(V₆,V₇)
(V₄,V₅)
树形图:
V₁ V₃
| |
4 2
| |
V₂ ------ 10 ------ V₄ ------ 20 ------ V₅
|
7
|
V₇
|
13
|
V₆
总权值 = 2 + 4 + 7 + 10 + 13 + 20 = 56
(3) 如图7-39所示的AOE-网,求出关键路径,并写出关键活动。
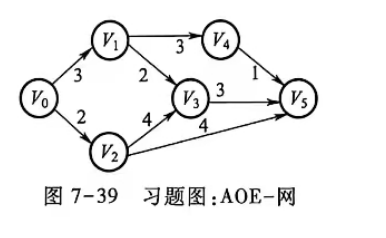
已知 :
顶点:V₀, V₁, V₂, V₃, V₄, V₅
边(权值 = 活动时间):
-
V₀→V₁(3)
-
V₀→V₂(2)
-
V₁→V₄(3)
-
V₁→V₃(2)
-
V₂→V₃(4)
-
V₂→V₅(4)
-
V₃→V₅(3)
-
V₄→V₅(1)
一、事件最早开始时间 ve(拓扑序)
-
ve(V₀) = 0
-
ve(V₁) = 0 + 3 = 3
-
ve(V₂) = 0 + 2 = 2
-
ve(V₃) = max(3+2, 2+4) = max(5, 6) = 6
-
ve(V₄) = 3 + 3 = 6
-
ve(V₅) = max(6+3, 6+1, 2+4) = max(9, 7, 6) = 9
二、事件最迟开始时间 vl(逆拓扑序)
-
vl(V₅) = 9
-
vl(V₄) = 9 - 1 = 8
-
vl(V₃) = 9 - 3 = 6
-
vl(V₂) = min(6-4, 9-4) = min(2, 5) = 2
-
vl(V₁) = min(6-2, 8-3) = min(4, 5) = 4
-
vl(V₀) = min(4-3, 2-2) = min(1, 0) = 0
三、关键活动(e = l)
| 活动 | e | l | 是否关键 |
|---|---|---|---|
| V₀→V₁ | 0 | 4-3=1 | 否 |
| V₀→V₂ | 0 | 2-2=0 | 是 |
| V₁→V₄ | 3 | 8-3=5 | 否 |
| V₁→V₃ | 3 | 6-2=4 | 否 |
| V₂→V₃ | 2 | 6-4=2 | 是 |
| V₂→V₅ | 2 | 9-4=5 | 否 |
| V₃→V₅ | 6 | 9-3=6 | 是 |
| V₄→V₅ | 6 | 9-1=8 | 否 |
关键活动 :(V₀,V₂), (V₂,V₃), (V₃,V₅)
关键路径 :V₀ → V₂ → V₃ → V₅
(4) 如图7-40所示的有向网,利用 Dijkstra 算法求顶点 V₀ 到其他各顶点之间的最短路径以及最短路径长度。
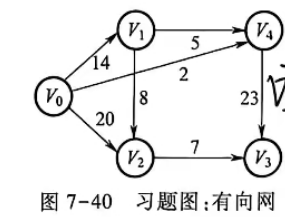
已知 :
顶点:V₀, V₁, V₂, V₃, V₄
边(权值):
-
V₀→V₁(14)
-
V₀→V₂(20)
-
V₀→V₄(2)
-
V₁→V₂(8)
-
V₁→V₄(5)
-
V₂→V₃(7)
-
V₄→V₃(23)
Dijkstra 算法过程
| 步骤 | 已确定最短路径的顶点 | dist |
|---|---|---|
| 初始 | {V₀} | V₀=0, V₁=14, V₂=20, V₄=2, V₃=∞ |
| 1 | +V₄ | 通过V₄→V₃(23):V₃=25;dist不变 |
| 2 | +V₁ | 通过V₁→V₂:V₂=min(20,14+8=22)→20;通过V₁→V₄:V₄=2不变;V₃=min(25,14+5=19)→19 |
| 3 | +V₃ | 无更新 |
| 4 | +V₂ | 通过V₂→V₃:V₃=min(19,20+7=27)→19 |
最终最短路径长度:
-
V₀→V₁:14
-
V₀→V₂:20
-
V₀→V₃:19
-
V₀→V₄:2
(5) 如图7-41所示的有向网,利用 Floyd 算法求任意两顶点间的最短路径以及最短路径长度。
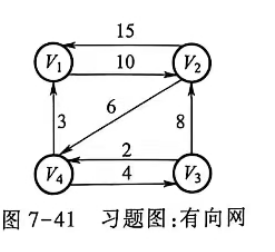
已知 :
顶点:V₁, V₂, V₃, V₄
边(权值):
-
V₁ → V₂ (10)
-
V₂ → V₁ (15)
-
V₂ → V₄ (6)
-
V₃ → V₂ (8)
-
V₃ → V₄ (2)
-
V₄ → V₃ (4)
-
V₄ → V₁ (3)
一、初始距离矩阵 D⁽⁰⁾
| V₁ | V₂ | V₃ | V₄ | |
|---|---|---|---|---|
| V₁ | 0 | 10 | ∞ | ∞ |
| V₂ | 15 | 0 | ∞ | 6 |
| V₃ | ∞ | 8 | 0 | 2 |
| V₄ | 3 | ∞ | 4 | 0 |
二、Floyd 算法递推过程
经过 V₁(k=1)
检查所有 i,j:Dij = min(Dij, Di1 + D1j)
-
V₂→V₁(15) + V₁→V₂(10) = 25,大于原 V₂→V₂=0,不变
-
V₄→V₁(3) + V₁→V₂(10) = 13,更新 D42 = 13(原∞)
-
V₄→V₁(3) + V₁→V₃(∞) = ∞,不变
-
V₄→V₁(3) + V₁→V₄(∞) = ∞,不变
更新后矩阵:
| V₁ | V₂ | V₃ | V₄ | |
|---|---|---|---|---|
| V₁ | 0 | 10 | ∞ | ∞ |
| V₂ | 15 | 0 | ∞ | 6 |
| V₃ | ∞ | 8 | 0 | 2 |
| V₄ | 3 | 13 | 4 | 0 |
经过 V₂(k=2)
-
V₁→V₂(10) + V₂→V₄(6) = 16,更新 D14 = 16(原∞)
-
V₁→V₂(10) + V₂→V₁(15) = 25,大于原 0,不变
-
V₃→V₂(8) + V₂→V₄(6) = 14,大于原 V₃→V₄=2,不变
-
V₃→V₂(8) + V₂→V₁(15) = 23,更新 D31 = 23(原∞)
-
V₄→V₂(13) + V₂→V₁(15) = 28,大于原 V₄→V₁=3,不变
-
V₄→V₂(13) + V₂→V₄(6) = 19,大于原 0,不变
更新后矩阵:
| V₁ | V₂ | V₃ | V₄ | |
|---|---|---|---|---|
| V₁ | 0 | 10 | ∞ | 16 |
| V₂ | 15 | 0 | ∞ | 6 |
| V₃ | 23 | 8 | 0 | 2 |
| V₄ | 3 | 13 | 4 | 0 |
经过 V₃(k=3)
-
V₁→V₃(∞) + V₃→V₄(2) = ∞,不变
-
V₁→V₃(∞) + V₃→V₂(8) = ∞,不变
-
V₂→V₃(∞) + V₃→V₄(2) = ∞,不变
-
V₂→V₃(∞) + V₃→V₂(8) = ∞,不变
-
V₄→V₃(4) + V₃→V₂(8) = 12,小于 V₄→V₂=13,更新 D42 = 12
-
V₄→V₃(4) + V₃→V₄(2) = 6,大于原 0,不变
更新后矩阵:
| V₁ | V₂ | V₃ | V₄ | |
|---|---|---|---|---|
| V₁ | 0 | 10 | ∞ | 16 |
| V₂ | 15 | 0 | ∞ | 6 |
| V₃ | 23 | 8 | 0 | 2 |
| V₄ | 3 | 12 | 4 | 0 |
经过 V₄(k=4)
-
V₁→V₄(16) + V₄→V₁(3) = 19,大于原 0,不变
-
V₁→V₄(16) + V₄→V₂(12) = 28,大于原 V₁→V₂=10,不变
-
V₁→V₄(16) + V₄→V₃(4) = 20,更新 D13 = 20(原∞)
-
V₂→V₄(6) + V₄→V₁(3) = 9,小于 V₂→V₁=15,更新 D21 = 9
-
V₂→V₄(6) + V₄→V₂(12) = 18,大于原 0,不变
-
V₂→V₄(6) + V₄→V₃(4) = 10,更新 D23 = 10(原∞)
-
V₃→V₄(2) + V₄→V₁(3) = 5,小于 V₃→V₁=23,更新 D31 = 5
-
V₃→V₄(2) + V₄→V₂(12) = 14,大于原 V₃→V₂=8,不变
-
V₃→V₄(2) + V₄→V₃(4) = 6,大于原 0,不变
最终矩阵 D⁽⁴⁾:
| V₁ | V₂ | V₃ | V₄ | |
|---|---|---|---|---|
| V₁ | 0 | 10 | 20 | 16 |
| V₂ | 9 | 0 | 10 | 6 |
| V₃ | 5 | 8 | 0 | 2 |
| V₄ | 3 | 12 | 4 | 0 |
三、最终最短路径长度表
| 起点 \ 终点 | V₁ | V₂ | V₃ | V₄ |
|---|---|---|---|---|
| V₁ | 0 | 10 | 20 | 16 |
| V₂ | 9 | 0 | 10 | 6 |
| V₃ | 5 | 8 | 0 | 2 |
| V₄ | 3 | 12 | 4 | 0 |
(6) 对如图7-42所示的有向图进行拓扑排序,写出可能的3种拓扑序列。
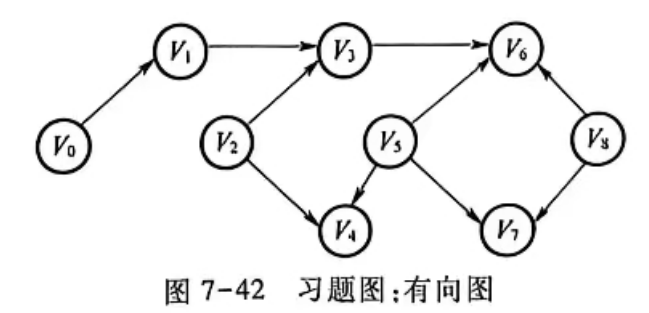
已知 :
顶点:V₀, V₁, V₂, V₃, V₄, V₅, V₆, V₇, V₈
边(有向,无权):
-
V₀→V₁
-
V₁→V₃
-
V₂→V₃
-
V₂→V₄
-
V₃→V₆
-
V₅→V₄
-
V₅→V₆
-
V₈→V₇
-
V₈→V₆
各顶点入度
| 顶点 | V₀ | V₁ | V₂ | V₃ | V₄ | V₅ | V₆ | V₇ | V₈ |
|---|---|---|---|---|---|---|---|---|---|
| 入度 | 0 | 1 | 0 | 2 | 2 | 0 | 4 | 1 | 0 |
3种可能的拓扑序列(每次选入度为0的顶点,顺序不同)
序列1:V₀, V₂, V₅, V₁, V₈, V₃, V₇, V₄, V₆
序列2:V₂, V₀, V₅, V₈, V₁, V₇, V₃, V₄, V₆
序列3:V₅, V₈, V₀, V₂, V₇, V₁, V₃, V₄, V₆
注:V₆ 入度最高(依赖 V₃, V₄, V₅, V₈),必须最后输出。
注:以上习题解答的理解和计算,如果有任何错误,希望各位读者和大佬指出改正,非常感谢!!!