一、初识Redis
1.1 关系型与非关系型数据库的核心差异
1.1.1 数据组织方式不同
关系型数据库采用结构化存储,数据必须按照预定义的表结构组织。以用户表为例,每张表有固定的列:
| id | name | age |
|---|---|---|
| 1 | 张三 | 18 |
| 2 | 李四 | 20 |
非关系型数据库采用非结构化存储,数据以键值对或文档形式存在,没有固定的列约束:
键值形式:
| key | value |
|---|---|
| 1001 | {id: 1, name: "张三", age: 21} |
1.1.2 数据关联方式不同
关系型数据库通过外键建立表与表之间的关联。查询用户订单需要三表连接:
sql
SELECT u.name, i.title, i.price
FROM tb_user u
JOIN tb_order o ON u.id = o.user_id
JOIN tb_item i ON o.item_id = i.id
WHERE u.id = 1;非关系型数据库采用无关联设计,将相关数据嵌套存储在同一结构中:
json
{
"id": 1,
"name": "张三",
"orders": [
{"id": 1, "item": {"id": 10, "title": "荣耀6", "price": 4999}},
{"id": 2, "item": {"id": 20, "title": "小米11", "price": 3999}}
]
}1.1.3 查询语言不同
关系型数据库使用标准SQL进行查询:
sql
SELECT id, name, age FROM tb_user WHERE id = 1;非关系型数据库使用各自特有的查询方式:
cmd
Redis: get user:1
MongoDB: db.users.find({_id: 1})
Elasticsearch: GET http://localhost:9200/users/11.1.4 事务特性不同
关系型数据库遵循ACID原则,保证事务的原子性、一致性、隔离性、持久性,适合对数据安全性要求高的场景。
非关系型数据库遵循BASE理论,追求基本可用、软状态、最终一致性,适合对性能要求高、可接受短暂不一致的场景。
1.2 NoSQL的四种主流类型
- 键值类型:以key-value形式存储,代表产品Redis,适合缓存、会话管理
- 文档类型:以JSON/BSON文档存储,代表产品MongoDB,适合内容管理、用户画像
- 列类型:按列族组织数据,代表产品HBase,适合海量数据离线分析
- 图类型:以节点和边表示关系,代表产品Neo4j,适合社交网络、推荐系统
1.3 Redis的核心定位
Redis诞生于2009年,全称Remote Dictionary Server(远程词典服务器),是一个基于内存的键值型NoSQL数据库。
1.3.1 六大核心特征
键值存储且value类型丰富
Redis的key通常是String类型,但value支持多种数据结构。同一个Redis实例中,不同key可以对应完全不同的数据类型:
cmd
msg → "hello world" # String类型
user:1 → {name:"Jack"} # Hash类型
queue → [A, B, C] # List类型
friends → {A, B, C} # Set类型
ranking → {A:1, B:2, C:3} # SortedSet类型单线程模型保证命令原子性
Redis采用单线程处理命令请求,每个命令执行过程中不会被其他命令打断,天然具备原子性,无需额外加锁机制。
低延迟高性能的三重保障
- 基于内存操作,避免磁盘IO瓶颈
- 采用IO多路复用技术,单线程高效处理海量连接
- 针对不同数据类型采用最优编码策略,减少内存占用
支持数据持久化
虽然数据存储在内存中,但Redis提供机制将数据保存到磁盘,重启后可恢复数据,避免内存断电导致数据丢失。
支持集群架构
- 主从集群:实现数据备份和读写分离
- 分片集群:实现数据水平扩展,支撑更大存储容量和并发流量
多语言客户端支持
官方提供Java、Python、Go、Node.js等多种语言的客户端库,方便不同技术栈的项目集成使用。
二、Redis数据结构与命令详解
2.1 数据结构总览
Redis是一个key-value的数据库,key一般是String类型,不过value的类型多种多样,分为基本类型和特殊类型:
| 类型分类 | 数据类型 | 示例 | 结构说明 |
|---|---|---|---|
| 基本类型 | String | hello world |
字符串,最基础的存储单元,底层为字节数组 |
| Hash | {name:"Jack", age: 21} |
哈希,无序字典,类似Java的HashMap结构 | |
| List | [A -> B -> C -> C] |
列表,双向链表结构,元素有序且可重复 | |
| Set | {A, B, C} |
集合,无序不重复的hash表,value恒为null | |
| SortedSet | {A: 1, B: 2, C: 3} |
有序集合,每个元素带score属性,按分数自动排序 | |
| 特殊类型 | GEO | {A: (120.3, 30.5)} |
地理空间索引,存储经纬度坐标,支持距离计算 |
| BitMap | 0110110101110101011 |
位图,用二进制位表示状态,适合签到、在线统计 | |
| HyperLogLog | 0110110101110101011 |
基数统计,用极小内存估算去重数量,允许微小误差 |
注意:基本类型是日常开发中最常用的5种数据结构,特殊类型适用于特定场景,如地理位置、大规模统计等。
Redis为了方便学习,将操作不同数据类型的命令做了分组,在官网可以查看到不同的命令。
使用help命令可以查看命令帮助:
1234567
通过help @可以查看某个命令组的所有命令,例如:
这样可以查看通用命令(generic)组的所有命令列表。
2.2 通用命令:跨数据类型的基础操作
通用命令适用于所有数据类型的key,用于管理key本身而非其内部数据。
2.2.1 查看符合模式的key
cmd
KEYS test:user:*该命令返回所有匹配test:user:*模式的key,例如test:user:1、test:user:2。

通配符规则:
*匹配任意长度字符?匹配单个字符[abc]匹配指定字符之一
注意:该命令会遍历整个数据库,数据量大时可能阻塞服务,仅建议在调试环境使用。
2.2.2 删除指定key
cmd
DEL test:user:1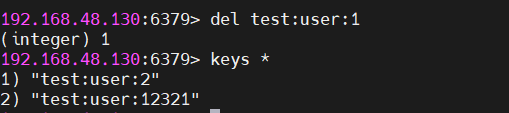
执行后返回实际删除的key数量。支持一次删除多个key:
cmd
DEL test:user:2 test:user:12321
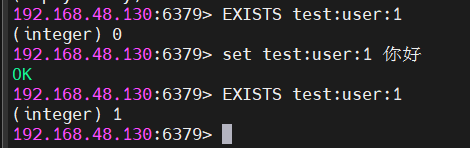
2.2.3 判断key是否存在
cmd
EXISTS test:user:1返回整数:1 表示存在,0 表示不存在。常用于缓存穿透防护场景。
2.2.4 设置key的有效期
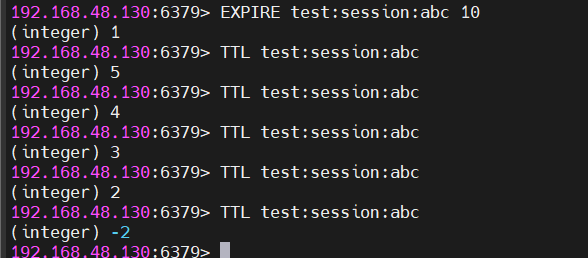
cmd
EXPIRE test:session:abc 10
表示该key在10秒后自动删除,适合存储会话、验证码等临时数据。
2.2.5 查看key的剩余有效期
cmd
TTL test:session:abc返回值含义:
- 正整数:剩余存活秒数
-1:该key永不过期-2:该key已过期或不存在

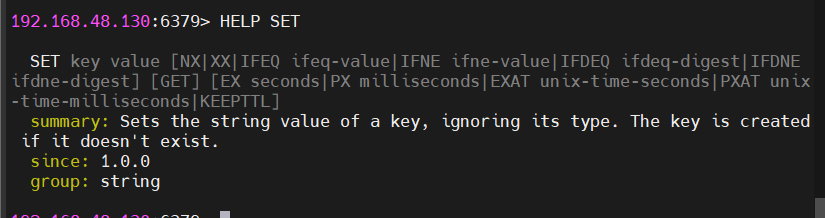
2.2.6 查看命令用法帮助
cmd
HELP @string # 查看String类型所有命令
HELP SET # 查看SET命令详细参数帮助信息包含命令语法、参数说明、返回值类型、时间复杂度等。
2.3 String类型:最基础的存储单元
2.3.1 三种数据格式
虽然都叫String,但根据内容格式可分为三类,每类支持不同的操作:
普通字符串
存储任意文本内容:
cmd
SET msg "hello world"
GET msg → 返回 "hello world"
整数类型
存储整数值,支持原子自增自减:
cmd
SET num 10
INCR num → num变为11,返回11
INCRBY num 5 → num变为16,返回16
DECR num → num变为15,返回15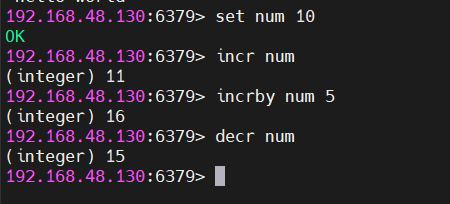
浮点数类型
存储小数值,支持精度自增:
cmd
SET score 92.5
INCRBYFLOAT score 0.3 → score变为92.8,返回92.8
注意:无论哪种格式,底层都是字节数组存储,只是编码方式不同。单个value最大不能超过512MB。
2.3.2 核心命令详解
基础读写
cmd
SET key value # 设置值,存在则覆盖
GET key # 获取值,不存在返回nil
MSET k1 v1 k2 v2 # 批量设置多个键值对
MGET k1 k2 # 批量获取多个键的值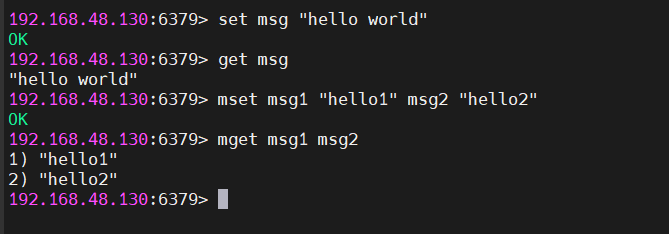
原子计数
cmd
INCR counter # 整型值+1,返回新值
INCRBY views 10 # 整型值+10
INCRBYFLOAT price 0.5 # 浮点值+0.5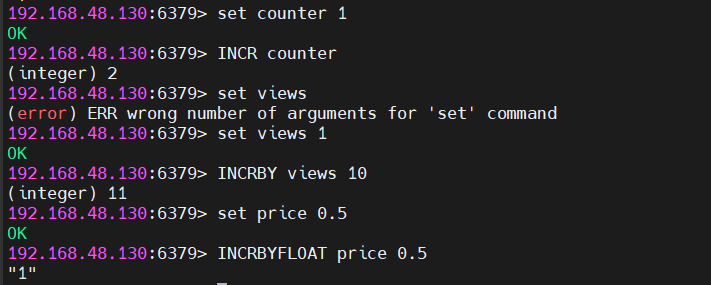
条件设置
SETNX: 仅当key不存在时设置,若存在则不能设置,常用于分布式锁
cmd
# 场景1:key不存在,设置成功
127.0.0.1:6379> SETNX mylock "user1"
(integer) 1
127.0.0.1:6379> GET mylock
"user1"
# 场景2:key已存在,设置失败
127.0.0.1:6379> SETNX mylock "user2"
(integer) 0
127.0.0.1:6379> GET mylock
"user1"在分布式锁的应用原理
cmd
# 线程A尝试获取锁
127.0.0.1:6379> SETNX lock:order:1001 "threadA"
(integer) 1 # 成功,获得锁
# 线程B尝试获取同一个锁
127.0.0.1:6379> SETNX lock:order:1001 "threadB"
(integer) 0 # 失败,锁已被占用
# 线程A释放锁
127.0.0.1:6379> DEL lock:order:1001
(integer) 1
# 线程B再次尝试
127.0.0.1:6379> SETNX lock:order:1001 "threadB"
(integer) 1 # 成功,获得锁- SETNX不会覆盖已存在的key
- 需要配合EXPIRE设置过期时间,防止死锁
- 现代Redis推荐使用SET key value NX EX seconds替代
2.3.3 Key的命名规范
Redis没有数据库和表的概念,所有key平铺存储。为避免不同业务冲突,建议采用层级命名:
格式:项目名:业务名:类型:id
示例:
test:user:1 # 用户信息,id=1
test:product:1 # 商品信息,id=1存储对象时,先序列化为JSON字符串:
cmd
SET test:user:1 '{"id":1,"name":"Jack","age":21}'2.4 Hash类型:对象字段的精细化管理
2.4.1 为什么需要Hash
如果用String存储用户对象:
cmd
SET test:user:1 '{"id":1,"name":"Jack","age":21}'当只需修改年龄时,必须:获取完整字符串→反序列化→修改字段→重新序列化→写回,流程繁琐且浪费带宽。
Hash类型将对象的每个字段独立存储,支持字段级操作:
cmd
# 存储字段
HSET test:user:1 name "Jack"
HSET test:user:1 age 21
# 修改单个字段(不影响其他字段)
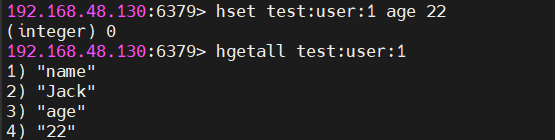
HSET test:user:1 age 22
# 获取单个字段
HGET test:user:1 name → 返回 "Jack"
# 获取全部字段
HGETALL test:user:1 → 返回 {name:"Jack", age:22}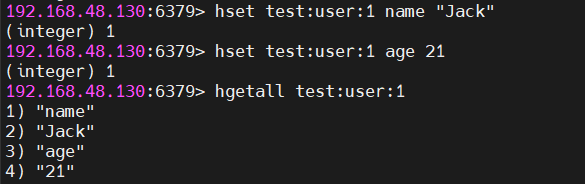

2.4.2 核心命令详解
字段增删改查
cmd
HSET key field value # 设置字段值,存在则更新
HGET key field # 获取字段值
HMSET key f1 v1 f2 v2 # 批量设置多个字段
HMGET key f1 f2 # 批量获取多个字段值
HGETALL key # 获取所有字段及值
HDEL key field # 删除指定字段遍历与统计
cmd
HKEYS test:user:1 # 获取所有字段名 [name, age]
HVALS test:user:1 # 获取所有字段值 [Jack, 21]
HLEN test:user:1 # 统计字段数量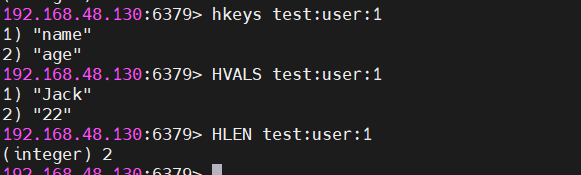
原子计数
cmd
HINCRBY test:user:1 age 1 # 字段值+1
条件设置
cmd
HSETNX test:user:1 created_at "2024-01-01" # 字段不存在时才设置
2.5 List类型:有序可重复的双向链表
2.5.1 结构特征
List底层是双向链表,具备四个核心特征:
有序性
元素按插入顺序排列,可通过索引访问:
cmd
LPUSH list "C" "B" "A" # 列表: [A, B, C]
LRANGE list 0 1 # 返回 [A, B]
元素可重复
相同值可多次插入,不会自动去重:
cmd
RPUSH tags "java" "java" "python" # 列表: [java, java, python]
插入删除快
头部尾部操作时间复杂度O(1):
cmd
LPUSH queue "task1" # 头部插入,极快
RPOP queue # 尾部移除,极快
查询速度一般
按索引查询需遍历链表,时间复杂度O(n):
cmd
LRANGE list 100 200 # 获取列表中索引从100到200的元素(包含两端)2.5.2 核心命令详解
两端插入与移除
cmd
# 左侧(头部)操作
LPUSH list "A" "B" # 列表变为 [B, A]
LPOP list # 移除并返回 "B"
# 右侧(尾部)操作
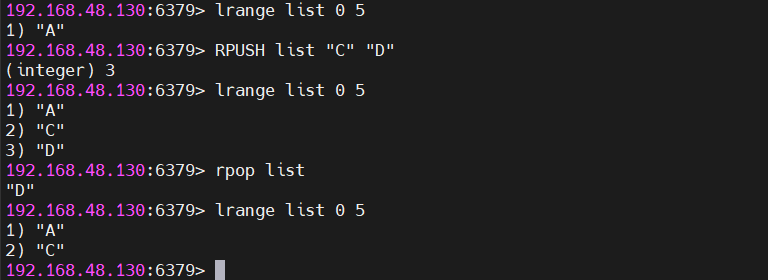
RPUSH list "C" "D" # 列表变为 [A, C, D]
RPOP list # 移除并返回 "D"
范围查询
cmd
LRANGE list 0 2 # 获取索引0到2的元素(包含两端)
LRANGE list -3 -1 # 获取最后3个元素(负数表示倒数)阻塞操作
cmd
BLPOP queue 5 # 左侧弹出,无元素时最多等待5秒
BRPOP queue 5 # 右侧弹出,无元素时最多等待5秒
2.5.3 模拟经典数据结构
栈(LIFO):入口出口同侧
cmd
入栈:LPUSH stack item
出栈:LPOP stack队列(FIFO):入口出口异侧
cmd
入队:RPUSH queue item
出队:LPOP queue阻塞队列:消费者无数据时等待
cmd
入队:RPUSH queue item
出队:BRPOP queue 10 # 无元素时阻塞等待10秒2.6 Set类型:无序不重复的集合运算
2.6.1 结构特征
Set底层是value恒为null的hash表,具备四个核心特征:
无序性
元素无固定顺序,遍历结果顺序不确定:
cmd
SADD tags "java" "python" "go"
SMEMBERS tags → 返回顺序是无序的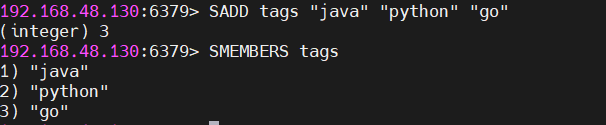
元素不可重复
重复添加相同元素自动去重:
cmd
SADD users "alice" "alice" "bob" # 实际存储: {alice, bob}
查找速度快
判断元素是否存在时间复杂度O(1):
cmd
SISMEMBER users "alice" → 快速返回1或0
支持集合运算
原生支持交集、并集、差集,无需客户端计算:
SINTER set1 set2 # 交集
SUNION set1 set2 # 并集
SDIFF set1 set2 # 差集2.6.2 实战案例:好友关系管理
数据准备
cmd
# 张三的好友
SADD test:friend:zhangsan "lisi" "wangwu" "zhaoliu"
# 李四的好友
SADD test:friend:lisi "wangwu" "mazi" "ergou"
需求1:统计张三好友数量
cmd
SCARD test:friend:zhangsan → 返回 3
需求2:找出共同好友(交集)
cmd
SINTER test:friend:zhangsan test:friend:lisi → 返回 ["wangwu"]
需求3:张三是好友但李四不是(差集)
cmd
SDIFF test:friend:zhangsan test:friend:lisi → 返回 ["zhangsan", "zhaoliu"]
需求4:两人好友合并去重(并集)
cmd
SUNION test:friend:zhangsan test:friend:lisi
→ 返回 ["lisi", "wangwu", "zhaoliu", "mazi", "ergou"]
需求5:判断李四是否是张三的好友
cmd
SISMEMBER test:friend:zhangsan "lisi" → 返回 1(存在)
需求6:判断张三是否是李四的好友
cmd
SISMEMBER test:friend:lisi "zhangsan" → 返回 0(不存在)
需求7:将李四从张三好友中移除
cmd
SREM test:friend:zhangsan "lisi"
2.6.3 核心命令汇总
cmd
# 增删查
SADD key member [member...] # 添加元素(自动去重)
SREM key member [member...] # 删除元素
SMEMBERS key # 获取所有元素
SISMEMBER key member # 判断元素是否存在
SCARD key # 统计元素个数
# 集合运算
SINTER key1 key2 [key3...] # 交集
SUNION key1 key2 [key3...] # 并集
SDIFF key1 key2 [key3...] # 差集2.7 SortedSet类型:带权重的有序集合
2.7.1 结构原理
SortedSet每个元素关联一个score(双精度浮点数),系统根据score自动排序。底层采用跳表+hash表双结构:
- 跳表:支持按分数范围快速查询、按排名访问
- hash表:支持按成员快速查找分数
具备四个核心特征:
可排序
插入时按score升序排列,score相同时按member字典序:
cmd
ZADD ranking 85 "Jack" 89 "Lucy" 82 "Rose"
ZRANGE ranking 0 -1 → 返回 [Rose, Jack, Lucy] # -1表示最后一个元素的索引,0 -1表示获取从第一个到最后一个的所有元素 
元素不重复
相同member自动更新score,不会重复存储:
cmd
ZADD scores 90 "Alice"
ZADD scores 95 "Alice" # Alice的score更新为95
查询速度快
按分数范围、按排名范围查询均高效:
ZRANGEBYSCORE scores 80 90 # 分数范围查询
ZRANGE scores 0 2 # 排名范围查询分数可更新
支持原子增减,适合实时排行榜:
cmd
ZINCRBY scores 5 "Alice" # Alice分数+52.7.2 实战案例:班级成绩排行榜
数据准备
cmd
ZADD test:score:class1 85 "Jack" 89 "Lucy" 82 "Rose" 95 "Tom" 78 "Jerry" 92 "Amy" 76 "Miles"需求1:删除Tom同学
cmd
ZREM test:score:class1 "Tom"需求2:获取Amy同学的分数
cmd
ZSCORE test:score:class1 "Amy" → 返回 92需求3:获取Rose同学的排名
cmd
ZRANK test:score:class1 "Rose" → 返回 2(升序第3名,从0开始)
ZREVRANK test:score:class1 "Rose" → 返回 4(降序第5名)需求4:查询80分以下有几个学生
cmd
ZCOUNT test:score:class1 0 80 → 返回 2(Jerry和Miles)需求5:给Amy同学加2分
cmd
ZINCRBY test:score:class1 2 "Amy" # Amy分数变为94需求6:查出成绩前3名的同学
cmd
ZREVRANGE test:score:class1 0 2 WITHSCORES
→ 返回: ["Tom", "95", "Amy", "94", "Lucy", "89"]需求7:查出成绩80分以下的所有同学
cmd
ZRANGEBYSCORE test:score:class1 0 80 WITHSCORES
→ 返回: ["Miles", "76", "Jerry", "78"]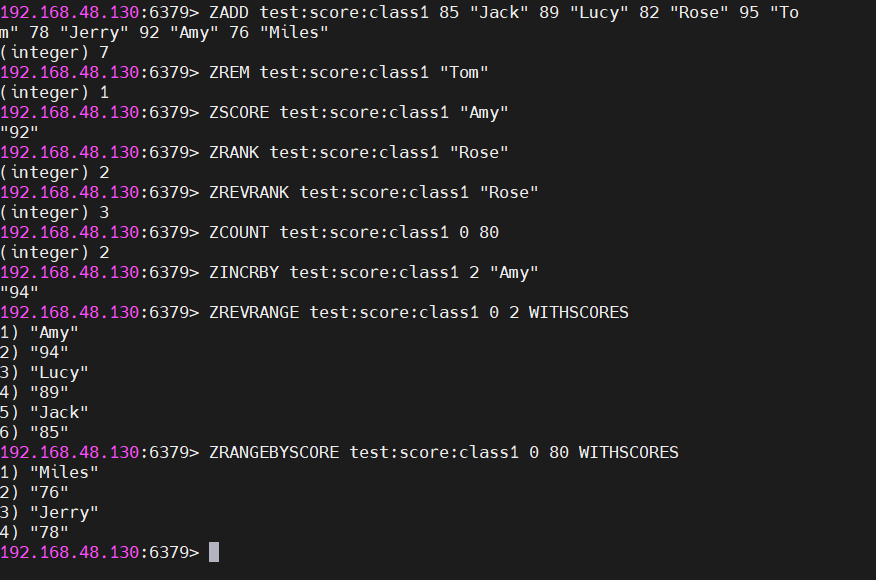
2.7.3 核心命令分类
基础操作
cmd
ZADD key score member [score member...] # 添加/更新元素
ZREM key member [member...] # 删除元素
ZSCORE key member # 获取元素分数
ZCARD key # 统计元素总数排名查询
cmd
ZRANK key member # 升序排名(从0开始)
ZREVRANK key member # 降序排名
ZRANGE key start stop [WITHSCORES] # 按排名获取(升序)
ZREVRANGE key start stop [WITHSCORES] # 按排名获取(降序)分数范围查询
cmd
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]
ZCOUNT key min max # 统计分数区间元素个数分数更新
cmd
ZINCRBY key increment member # 分数原子增减集合运算
cmd
ZDIFF key1 key2 ... # 差集
ZINTER key1 key2 ... # 交集
ZUNION key1 key2 ... # 并集注意:所有范围命令默认升序,需降序时在Z后加REV;WITHSCORES参数可同时返回元素和分数
三、学习要点回顾
3.1 五种核心数据结构对比
| 类型 | 有序性 | 可重复 | 核心优势 | 典型场景 |
|---|---|---|---|---|
| String | - | - | 读写最快,支持原子计数 | 缓存、计数器、分布式锁 |
| Hash | - | - | 字段级操作,节省序列化开销 | 对象存储、用户信息 |
| List | ✓ | ✓ | 两端操作高效,支持阻塞 | 消息队列、时间线 |
| Set | ✗ | ✗ | 自动去重,集合运算原生支持 | 标签、好友、去重统计 |
| SortedSet | ✓ | ✗ | 自动排序,双维度查询 | 排行榜、带权任务队列 |
3.2 Key命名规范
推荐格式:项目名:业务名:类型:id
示例:
test:user:1 # 用户信息
test:product:1001 # 商品信息
test:cart:user:1 # 用户购物车3.3 命令学习技巧
- 使用
HELP @类型查看某类数据结构的所有命令 - 使用
HELP 命令名查看具体命令的详细用法 - 先掌握每种结构的3-5个高频命令,再逐步扩展
- 结合业务场景练习,如用Set实现好友管理、用SortedSet实现排行榜