本文基于 MCat 完整教程ySQL 运维实战,详细讲解分库分表为什么要分、怎么分、用什么分、怎么配、怎么测,从理论到配置一站式学会,可直接用于项目落地。
一、为什么要分库分表?
随着业务增长,单库单表会遇到明显瓶颈:
- IO 瓶颈:数据量过大,磁盘 IO、网络 IO 飙升
- CPU 瓶颈:排序、分组、联表查询压力巨大
- 查询变慢:单表千万 / 亿级数据,索引失效、查询超时
- 扩容困难:单机硬件资源有限,无法无限升级
分库分表核心思想:把数据分散存储,降低单库 / 单表压力,提升并发、查询、写入性能。
二、分库分表两种核心策略
垂直分表分的是结构,水平分表分的是内容!!
1. 垂直拆分(按业务 / 字段拆分)
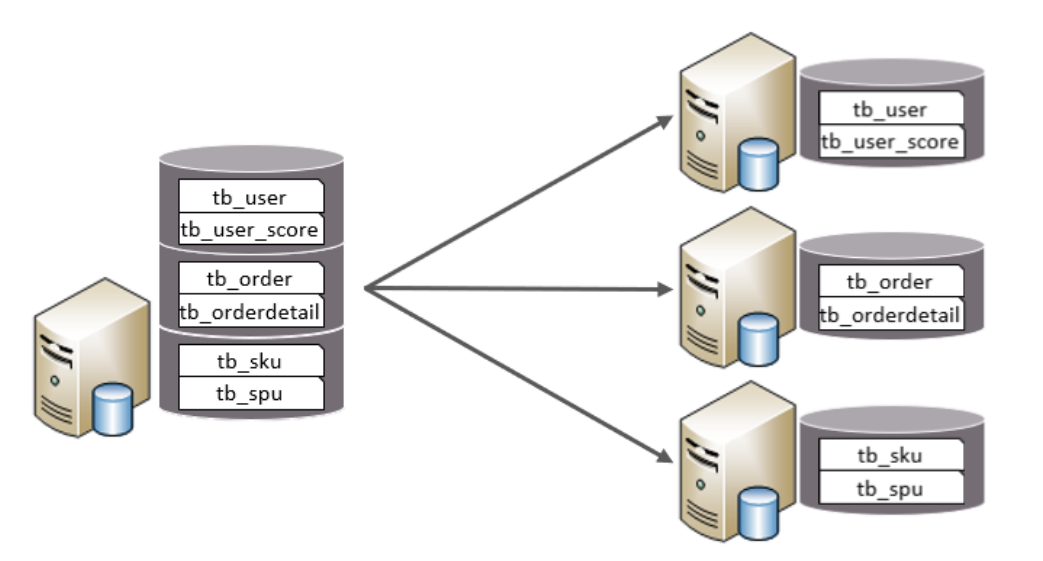
(1)垂直分库
按业务模块把不同表分到不同库。
- 商品表 → 商品库
- 订单表 → 订单库
- 用户表 → 用户库
特点:
- 库结构不同
- 数据不重复
- 合起来是全量数据
适用场景:业务模块清晰、表数量多、耦合低的系统。
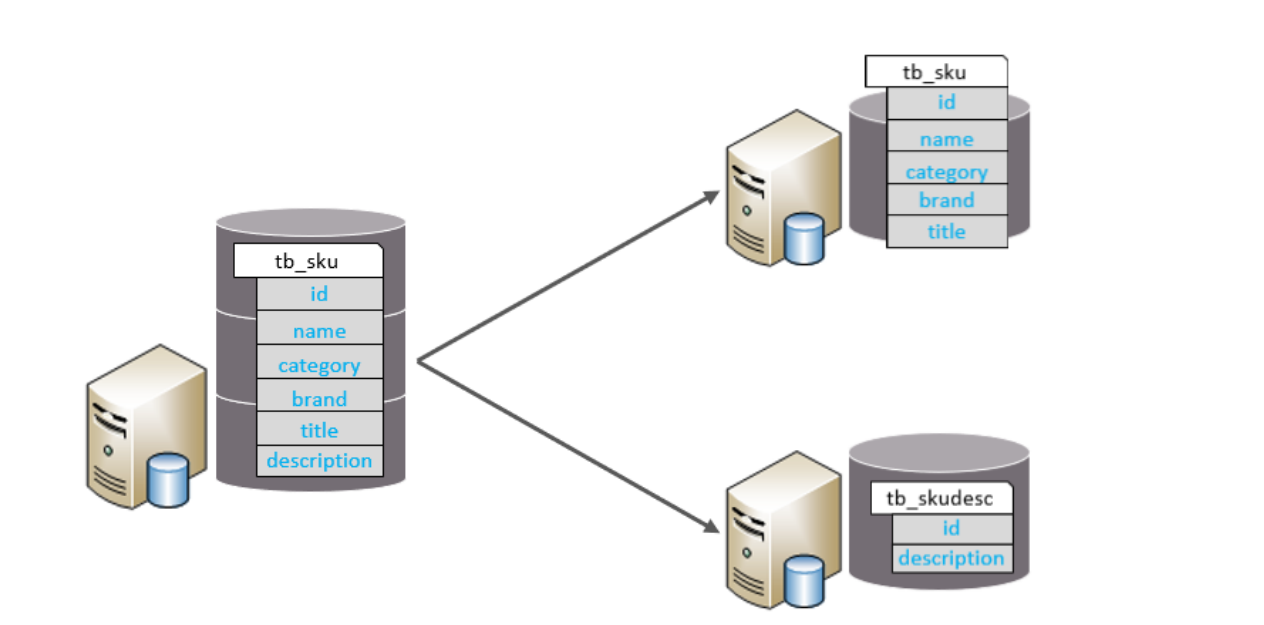
(2)垂直分表
把大字段、不常用字段 拆分成副表。例如:把商品表的 description 大文本拆成商品详情表。
特点:
- 表结构不同
- 通过主键关联
- 降低单表宽度,提升查询速度
2. 水平拆分(按数据行拆分)
最常用、最核心 的拆分方式:同一张表,按某字段规则把行数据分散到多个库 / 多个表。
(1)水平分库
同一个表结构,分散到多个库。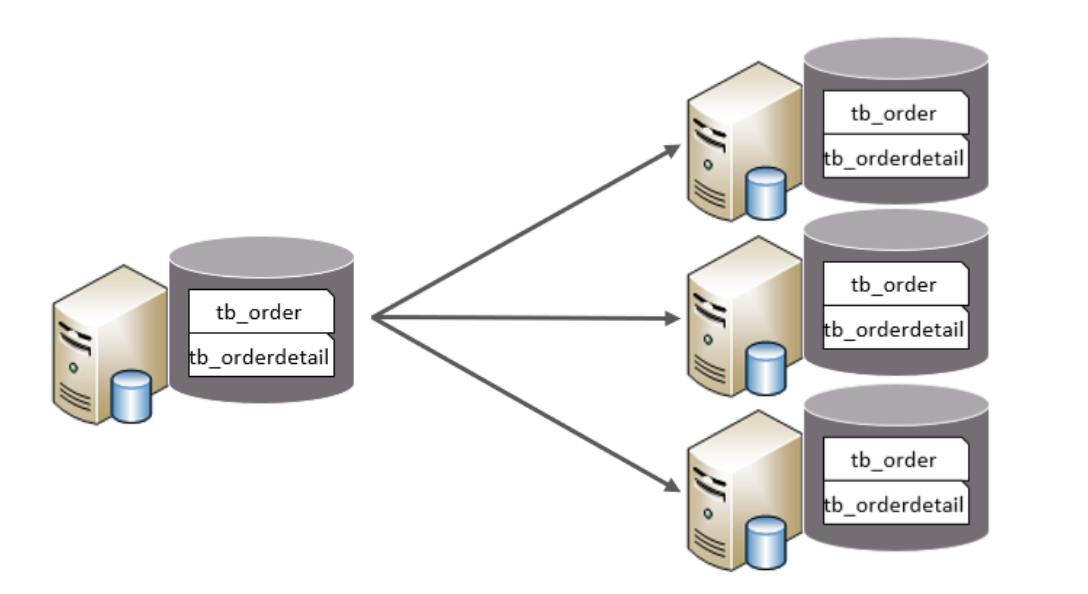
(2)水平分表
同一个库内,一个表拆成多个结构相同的表。
水平拆分特点:
- 所有表结构完全一样
- 数据不重复
- 合起来是全量数据
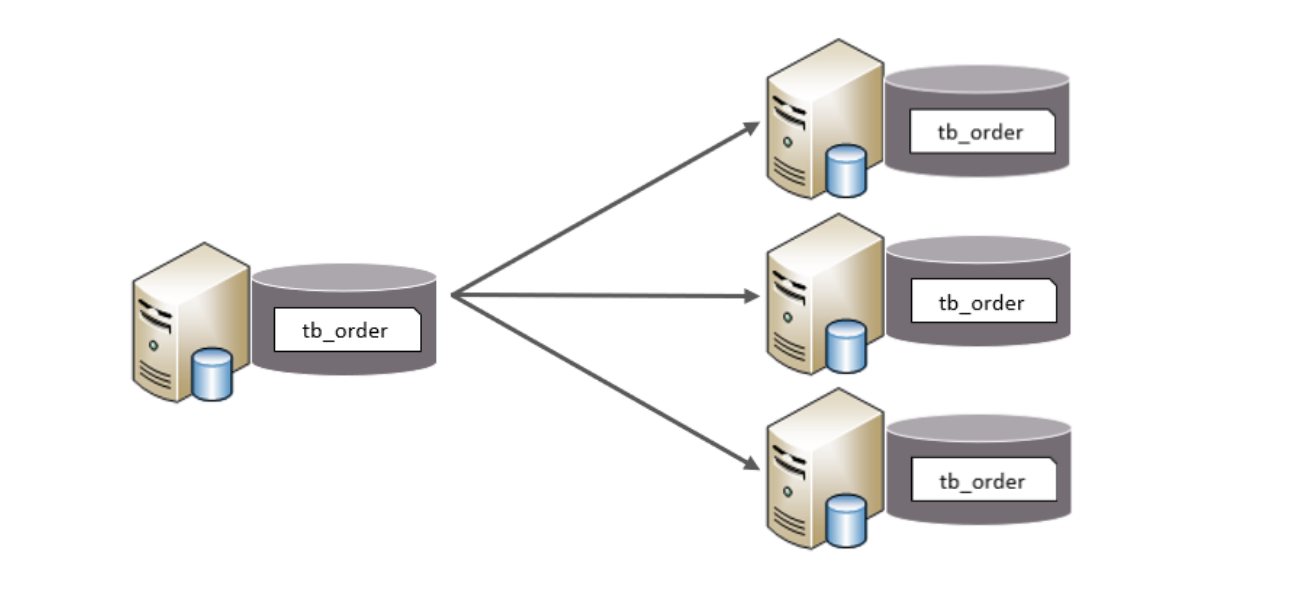
适用场景:单表数据超 2000 万、高并发写入、查询压力大。
三、分库分表实现方案对比
主流方案有两种,按需选择:
表格
| 方案 | 代表 | 特点 | 适用场景 |
|---|---|---|---|
| 客户端分片 | ShardingJDBC | Java 应用内嵌入,性能高,代码侵入 | 纯 Java 技术栈,追求高性能 |
| 中间件分片 | MyCat | 独立中间件,无代码侵入,支持多语言 | 多语言技术栈,运维友好 |
本文使用 MyCat 实战讲解,是企业级分库分表最常用的方案。
四、MyCat 基础介绍
MyCat 是基于 MySQL 协议的**开源分布式数据库中间件(**基于MySQL协议,开发人员只需要像使用MySQL一样使用MyCat)。
对于MyCat,需要掌握的是如何对其进行配置。
核心端口
- 8066:数据端口(增删改查)
- 9066:管理端口(监控、状态、配置重载)
核心配置文件
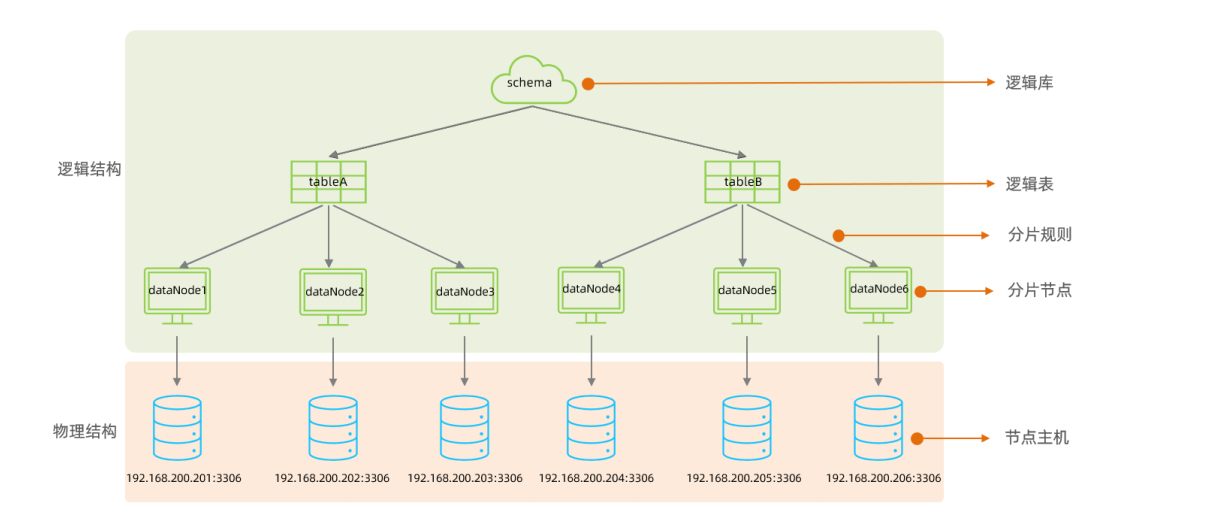
schema.xml:逻辑库、逻辑表、分片、数据源配置,包含三个标签:schema,dataNode,dataHost(可参考下面结构图)rule.xml:分片规则server.xml:用户、权限、端口
MyCat整体结构:
五、MyCat 分库分表实战(3 套核心方案)
方案 1:垂直分库实战(按业务拆分)
1. 结构设计
dn1:商品相关表dn2:订单相关表dn3:用户 + 省市区表
2. schema.xml 配置
<schema name="SHOPPING" checkSQLschema="true" sqlMaxLimit="100">
<!-- 商品模块 -->
<table name="tb_goods_base" dataNode="dn1" primaryKey="id"/>
<table name="tb_goods_brand" dataNode="dn1" primaryKey="id"/>
<!-- 订单模块 -->
<table name="tb_order_master" dataNode="dn2" primaryKey="order_id"/>
<table name="tb_order_item" dataNode="dn2" primaryKey="id"/>
<!-- 用户+地区 -->
<table name="tb_user" dataNode="dn3" primaryKey="id"/>
<table name="tb_user_address" dataNode="dn3" primaryKey="id"/>
<!-- 全局表(字典表) -->
<table name="tb_areas_provinces" dataNode="dn1,dn2,dn3" type="global"/>
<table name="tb_areas_city" dataNode="dn1,dn2,dn3" type="global"/>
</schema>
<dataNode name="dn1" dataHost="dhost1" database="shopping"/>
<dataNode name="dn2" dataHost="dhost2" database="shopping"/>
<dataNode name="dn3" dataHost="dhost3" database="shopping"/>
<dataHost name="dhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master" url="jdbc:mysql://IP:3306/shopping" user="root" password="123456"/>
</dataHost>3. 关键点:全局表(global)
字典表(省市区、枚举)在所有分片都存一份,解决跨库 join 问题,避免频繁跨库查询。
方案 2:水平分表 ------ 范围分片(auto-sharding-long)
按 ID 范围分段存储,适合订单、日志等 ID 连续增长的场景。
1. schema.xml 配置
<table name="TB_ORDER" dataNode="dn1,dn2,dn3" rule="auto-sharding-long"/>2. rule.xml 配置
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>3. autopartition-long.txt 规则文件
0-5000000=0
5000001-10000000=1
10000001-15000000=2适用场景:订单 ID、日志 ID 等自增、连续增长的数据。
方案 3:水平分表 ------ 取模分片(mod-long)(生产最常用)
根据 ID % 节点数均匀分片,数据分布最均匀,高并发场景推荐。
1. schema.xml 配置
<table name="tb_log" dataNode="dn4,dn5,dn6" rule="mod-long"/>2. rule.xml 配置
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<property name="count">3</property>
</function>特点:数据分布均匀,写入性能高,缺点是扩容时需要数据迁移。
六、MyCat 常用分片规则速查(开发必备)
| 分片规则 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 范围分片 | 订单、日志 | 扩容简单,连续查询友好 | 数据分布不均,热点节点 |
| 取模分片 | 高并发业务 | 数据分布均匀 | 扩容需全量迁移 |
| 一致性 Hash | 需平滑扩容 | 扩容只迁移少量数据 | 实现复杂 |
| 枚举分片 | 状态 / 省份字段 | 配置简单,按字段直接路由 | 字段值有限,扩展性差 |
| 按天 / 月分片 | 日志、流水数据 | 归档方便,按时间查询快 | 冷热数据分布不均 |
七、MyCat + MySQL 读写分离实战
1. 一主一从读写分离(最常用)
<dataHost name="dhost7" balance="3" writeType="0" switchType="1">
<heartbeat>select user()</heartbeat>
<writeHost host="master1" url="jdbc:mysql://IP:3306/db" user="root" password="123456">
<readHost host="slave1" url="jdbc:mysql://IP:3307/db" user="root" password="123456"/>
</writeHost>
</dataHost>2. balance 参数说明
0:不分离,读也走主库1:双主双从模式,所有从库 + 备主参与读2:读写随机分发3:读只走从库(生产最常用)
八、MyCat 常用管理命令(9066 端口)
连接 MyCat 管理端口:
mysql -uroot -p123456 -h127.0.0.1 -P9066常用命令:
show @@help; -- 查看帮助
show @@version; -- 查看版本
show @@datasource; -- 查看数据源状态
show @@datanode; -- 查看分片节点
reload @@config; -- 重载配置(修改配置后生效)
show @@sql; -- SQL 监控
show @@sql.sum; -- SQL 执行统计九、分库分表避坑指南(生产必看)
- 必须指定分片键:不指定分片键会触发全表路由,性能爆炸
- 避免跨分片事务:尽量用本地事务 + 消息队列实现最终一致性
- 跨库 join 问题:使用全局表冗余数据,或在业务层组装数据
- 分页查询陷阱 :深度分页(
offset很大)性能差,推荐用where id > ? limit ?实现 - 扩容问题:取模分片扩容需迁移数据,一致性 Hash 扩容更平滑
- 唯一 ID 问题:必须使用分布式 ID(雪花算法、MyCat 全局序列),避免主键冲突
十、总结
- 垂直拆分:先按业务拆,降低耦合,优先解决业务复杂度
- 水平拆分:再按数据量拆,解决性能瓶颈,单表超 2000 万再考虑
- MyCat:无侵入、易运维,是中小团队落地分库分表的首选方案
- 分片规则:取模均匀、范围简单、一致性 Hash 便于扩容,按需选择
- 读写分离:分担读压力,一主一从够用,高可用场景用双主双从
能单库单表解决就不要过度设计。只有当单表数据量达到 2000 万~5000 万 或 QPS 持续走高时,再落地分库分表不迟。